
OpenAI Release: Anwendungen und Best Practices für die Modellierung von KI-Inferenzen
Im Bereich der KI ist die Wahl des Modells von entscheidender Bedeutung. openAI, ein Branchenführer, bietet eine Familie von Modellen mit zwei Haupttypen an:Inferenzmodell (Reasoning Models) und GPT-Modell (GPT-Modelle). Ersteres wird durch die Modelle der o-Reihe repräsentiert, wie z. B. o1 im Gesang antworten o3-miniLetztere ist bekannt für ihre GPT-Modellfamilie, wie z. B. die GPT-4o. Um das Potenzial der KI voll ausschöpfen zu können, ist es entscheidend, die Unterschiede zwischen diesen beiden Modelltypen und die Anwendungsszenarien zu verstehen, in denen sie sich jeweils auszeichnen.
Dieser Artikel wird sich damit befassen:
- Hauptunterschiede zwischen OpenAI-Inferenzmodellen und GPT-Modellen.
- Wann die Nutzung der Inferenzmodelle von OpenAI Priorität haben sollte.
- Wie man Inferenzmodelle für eine optimale Leistung effektiv einsetzt.
Neulich haben Microsoft-Ingenieure eine Hint Engineering für OpenAI O1 und O3-mini Inferenzmodelle kann man die Unterschiede in der Anwendung zwischen den beiden vergleichen.
Reasoning-Modelle vs. GPT-Modelle: Strategen vs. Exekutoren
Die Inferenzmodelle der o-Serie von OpenAI weisen im Gegensatz zu den bekannten GPT-Modellen ihre eigenen Stärken bei verschiedenen Aufgabentypen auf und erfordern unterschiedliche Cueing-Strategien. Es ist wichtig zu verstehen, dass diese beiden Modelltypen nicht einfach besser oder schlechter sind, sondern einen unterschiedlichen Fokus auf ihre Fähigkeiten haben. Dies spiegelt die kontinuierlichen Bemühungen von OpenAI wider, die Grenzen der Fähigkeiten seiner Modelle zu erweitern, um den Anforderungen immer komplexerer Anwendungen gerecht zu werden, die tiefgreifende Schlussfolgerungen erfordern.
OpenAI hat die Modelle der o-Serie, die intern den Codenamen Planners tragen, speziell darauf trainiert, länger und tiefer zu denken, so dass sie sich in Bereichen wie der Strategieformulierung, der Planung komplexer Probleme und der Entscheidungsfindung auf der Grundlage großer Mengen mehrdeutiger Informationen auszeichnen können. Die Fähigkeit dieser Modelle, Aufgaben mit einem hohen Maß an Präzision und Genauigkeit zu erledigen, macht sie ideal für Bereiche, die traditionell auf menschliche Experten angewiesen sind, wie z. B. spezialisierte Bereiche der Mathematik, der Wissenschaft, des Ingenieurwesens, der Finanzdienstleistungen und des Rechtswesens.
Auf der anderen Seite sind die GPT-Modelle von OpenAI (mit dem internen Codenamen "Workhorses") latenzärmer und kostengünstiger und für die direkte Ausführung von Aufgaben konzipiert. In der Praxis wird häufig eine Kombination dieser beiden Modelltypen verwendet: Die Modelle der o-Serie werden zur Formulierung einer Makrostrategie für die Problemlösung verwendet, während die GPT-Modelle spezifische Teilaufgaben effizient ausführen, insbesondere in Szenarien, in denen Geschwindigkeit und Kosteneffizienz wichtiger sind als absolute Genauigkeit. Diese Arbeitsteilung spiegelt die Reife der Philosophie der KI-Modellentwicklung wider, die die Planung von der Ausführung trennt.
Wie wählt man das richtige Modell? Verstehen Sie Ihre Bedürfnisse
Bei der Auswahl eines Modells kommt es darauf an, die Kernanforderungen Ihres Anwendungsszenarios zu definieren:
- Geschwindigkeit und Kosten. Wenn Geschwindigkeit und Kosteneffizienz Ihre Prioritäten sind, dann ist das GPT-Modell in der Regel die schnellere und wirtschaftlichere Wahl.
- Klar definierte Aufgaben. Bei Anwendungen mit klaren Zielen und genau definierten Aufgabengrenzen kann das GPT-Modell bei der Ausführung von Aufgaben glänzen.
- Genauigkeit und Verlässlichkeit. Wenn Ihre Anwendung extreme Genauigkeit und Zuverlässigkeit der Ergebnisse erfordert, sind die Modelle der o-Serie die zuverlässigeren Entscheidungsträger.
- Komplexe Problemlösung. Angesichts der hohen Mehrdeutigkeit und Komplexität sind die Modelle der o-Reihe in der Lage, effektiv mit ihnen umzugehen.
Wenn also Geschwindigkeit und Kosten im Vordergrund stehen und Ihre Anwendungsfälle in erster Linie einfache, klar definierte Aufgaben umfassen, dann sind die GPT-Modelle von OpenAI ideal. Wenn jedoch Genauigkeit und Zuverlässigkeit entscheidend sind und Sie komplexe, mehrstufige Probleme lösen, dann sind die Modelle der o-Serie von OpenAI möglicherweise besser für Ihre Bedürfnisse geeignet.
In vielen realen KI-Arbeitsabläufen ist es am besten, eine Kombination dieser beiden Modelle zu verwenden: Die o-Modellfamilie fungiert als "Planer", der für die Planung und Entscheidungsfindung des Agenten verantwortlich ist, während die GPT-Modellfamilie als "Ausführer" fungiert, der für die Ausführung bestimmter Aufgaben zuständig ist. Durch diese Kombinationsstrategie werden die Stärken beider Modelltypen optimal genutzt.

Die OpenAI-Modelle GPT-4o und GPT-4o mini können beispielsweise in Kundendienstszenarien eingesetzt werden, in denen Kundeninformationen zunächst zur Klassifizierung von Bestelldetails, zur Identifizierung von Bestellproblemen und Rückgaberichtlinien verwendet werden. Diese Datenpunkte werden dann in das o3-mini-Modell eingespeist, das die endgültige Entscheidung über die Durchführbarkeit einer Rückgabe auf der Grundlage vorgegebener Richtlinien trifft.
Anwendungsszenarien für Inferenzmodelle: Komplexität und Mehrdeutigkeit ausreizen
OpenAI hat durch die Zusammenarbeit mit Kunden und interne Beobachtungen einige typische Muster für erfolgreiche Anwendungen von Inferenzmodellen entwickelt. Die unten aufgeführten Anwendungsszenarien sind nicht erschöpfend, sondern stellen vielmehr praktische Anleitungen dar, die Ihnen helfen sollen, die Modelle der o-Serie von OpenAI besser zu bewerten und zu testen.
1. mehrdeutige Aufgaben navigieren: Absicht aus fragmentierten Informationen verstehen
Reasoning-Modelle sind besonders gut in der Lage, Aufgaben mit unvollständigen oder verstreuten Informationen zu bewältigen. Selbst wenn nur begrenzte Informationen zur Verfügung stehen, können Inferenzmodelle die wahren Absichten des Benutzers effektiv verstehen und mit Mehrdeutigkeiten in den Anweisungen angemessen umgehen. Es ist erwähnenswert, dass Inferenzmodelle in der Regel keine unklugen Vermutungen anstellen oder versuchen, Informationslücken selbst zu schließen, sondern proaktiv klärende Fragen stellen, um sicherzustellen, dass die Aufgabenanforderungen richtig verstanden werden. Dies ist ein gutes Beispiel für die Vorteile von Schlussfolgerungsmodellen beim Umgang mit Unsicherheit und komplexen Aufgaben.
Hebbia, eine KI-Wissensplattform für den Rechts- und Finanzsektor, sagte: "Die überlegenen Inferenzfähigkeiten von o1 ermöglichen es Matrix, der Multi-Agenten-Plattform von OpenAI, komplexe Dokumente effizient zu verarbeiten und detaillierte, gut strukturierte und informative Antworten zu generieren. Mit o1 ist es für Matrix zum Beispiel ein Leichtes, mit einfachen Eingabeaufforderungen den Geldbetrag zu ermitteln, der im Rahmen eines Kreditvertrags mit eingeschränkter Zahlungsfähigkeit zur Verfügung steht. Kein anderes Modell hat bisher dieses Leistungsniveau erreicht. In den intensiven Tests von 52% zu komplexen Kreditverträgen erzielte o1 im Vergleich zu anderen Modellen signifikantere Ergebnisse."
Hebbia, ein Unternehmen für eine KI-Wissensplattform für den Rechts- und Finanzsektor
2. die Informationsbeschaffung: die Nadel im Heuhaufen finden, den Ort lokalisieren
Wenn es mit großen Mengen unstrukturierter Informationen konfrontiert wird, zeigt das Inferenzmodell ein starkes Informationsverständnis und ist in der Lage, die für die Frage relevantesten Informationen genau zu extrahieren und so die Frage des Nutzers effizient zu beantworten. Dies unterstreicht die überlegene Leistung von Inferenzmodellen bei der Informationsbeschaffung und der Filterung von Schlüsselinformationen, insbesondere bei großen Datenmengen.
Endex, die KI-Finanzintelligenzplattform, teilt mit: "Um Unternehmensübernahmen eingehend zu analysieren, wurde das o1-Modell verwendet, um Dutzende von Unternehmensdokumenten, einschließlich Verträgen und Mietvereinbarungen, zu überprüfen, mit dem Ziel, potenzielle Klauseln zu finden, die sich nachteilig auf das Geschäft auswirken könnten. Das Modell hatte die Aufgabe, Schlüsselklauseln zu markieren. Dabei identifizierte o1 eine wichtige "Change of Control"-Klausel in einer Fußnote: eine Klausel, die die sofortige Rückzahlung eines 75-Millionen-Dollar-Darlehens verlangte, falls das Unternehmen verkauft werden sollte. o1s Detailgenauigkeit war auch entscheidend für die Identifizierung einer Schlüsselklausel in der Fußnote: eine Klausel, die die sofortige Rückzahlung eines 75-Millionen-Dollar-Darlehens verlangte, falls das Unternehmen verkauft werden sollte. Die hohe Detailgenauigkeit von o1 ermöglicht es den KI-Agenten von OpenAI, die Arbeit von Finanzexperten effektiv zu unterstützen, indem sie geschäftskritische Informationen genau identifizieren."
-Endex, KI-Plattform für finanzielle Intelligenz
3. die Entdeckung von Beziehungen und die Identifizierung von Nuancen: den Wert von Daten tiefer ergründen
OpenAI hat herausgefunden, dass Inferenzmodelle besonders gut bei der Analyse von dichten, unstrukturierten Dokumenten von Hunderten von Seiten Länge, wie z. B. Rechtsverträgen, Finanzberichten und Versicherungsansprüchen, sind. Diese Modelle sind in der Lage, Informationen aus komplexen Dokumenten zu extrahieren, Verbindungen zwischen verschiedenen Dokumenten herzustellen und Schlussfolgerungsentscheidungen auf der Grundlage von in den Daten enthaltenen Fakten zu treffen. Dies zeigt, dass Inferenzmodelle erhebliche Vorteile bei der Verarbeitung komplexer Dokumente und der Gewinnung tiefgreifender Informationen haben.
Blue J, die KI-Plattform für die Steuerrecherche, erklärt: "Bei der Steuerrecherche müssen oft Informationen aus mehreren Dokumenten integriert werden, um eine endgültige, überzeugende Schlussfolgerung zu ziehen. Nachdem wir das GPT-4o-Modell durch das o1-Modell ersetzt hatten, stellte OpenAI fest, dass o1 besser in der Lage ist, die Wechselwirkungen zwischen den Dokumenten zu erkennen und logische Schlussfolgerungen zu ziehen, die in keinem einzelnen Dokument ersichtlich sind. Infolgedessen konnte OpenAI durch den Wechsel zum o1-Modell eine beeindruckende 4-fache Verbesserung der End-to-End-Leistung feststellen."
--Blue J, KI-Plattform für Steuerforschung
Denkmodelle sind ebenso gut in der Lage, nuancierte Strategien und Regeln zu verstehen und sie auf spezifische Aufgaben anzuwenden, um zu vernünftigen Schlussfolgerungen zu gelangen.
BlueFlame AI, eine KI-Plattform für die Vermögensverwaltung, gibt ein Beispiel: "Im Bereich der Finanzanalyse müssen Analysten oft mit komplexen Situationen im Zusammenhang mit Aktionärsrechten umgehen und ein tiefes Verständnis der damit verbundenen rechtlichen Komplexität haben. OpenAI testete etwa 10 Modelle verschiedener Anbieter anhand einer anspruchsvollen, aber allgemeinen Frage: Wie wirkt sich das Finanzierungsverhalten auf die bestehenden Aktionäre aus, insbesondere wenn sie ihr Verwässerungsschutzrecht ausüben? Diese Frage erfordert Überlegungen zu den Unternehmensbewertungen vor und nach der Finanzierung und zur Komplexität der zyklischen Verwässerung - eine Frage, für die selbst ein Top-Finanzanalyst 20-30 Minuten brauchen würde, um sie zu verstehen. OpenAI fand heraus, dass die o1- und o3-mini-Modelle dieses Problem perfekt lösen! Die Modelle generierten sogar eine übersichtliche Berechnungstabelle, die die Auswirkungen des Finanzierungsverhaltens auf die 100.000-Dollar-Aktionäre im Detail zeigt."
--BlueFlame AI, eine KI-Plattform für die Vermögensverwaltung
4. mehrstufige Planung der Agentur: ein strategischer Plan für den Betrieb, eine Strategie für den Erfolg
Inferenzmodelle spielen eine entscheidende Rolle bei der Planung und Strategieformulierung von Agenten. OpenAI hat festgestellt, dass Inferenzmodelle, wenn sie als "Planer" eingesetzt werden, in der Lage sind, detaillierte, mehrstufige Lösungen für komplexe Probleme zu generieren. Anschließend kann das System das am besten geeignete GPT-Modell ("Executor") für die Ausführung jedes Schritts auswählen und zuweisen, basierend auf den unterschiedlichen Anforderungen an Latenz und Intelligenz. Dies verdeutlicht die Vorteile einer Kombination von Modellen, wobei das Inferenzmodell als "Gehirn" für die Strategieplanung und das GPT-Modell als "Arme und Beine" für die Ausführung fungiert.
Argon AI, eine KI-Wissensplattform für die pharmazeutische Industrie, verrät: "OpenAI verwendet das o1-Modell als Planer in seiner Agenteninfrastruktur, der es ermöglicht, andere Modelle im Workflow zu orchestrieren, um mehrstufige Aufgaben effizient zu erledigen. OpenAI hat festgestellt, dass das o1-Modell sehr gut darin ist, die richtige Art von Daten auszuwählen und große, komplexe Probleme in kleinere, überschaubare Module zu zerlegen, so dass sich andere Modelle auf spezifische Ausführungen konzentrieren können."
--Argon AI, eine KI-Wissensplattform für die Pharmaindustrie
Lindy.AI, ein KI-Arbeitsassistent, teilte mit: "Das o1-Modell bietet leistungsstarke Unterstützung für die vielen Agenten-Workflows von Lindy, dem KI-Arbeitsassistenten von OpenAI. Das Modell ist in der Lage, über Funktionsaufrufe Schlüsselinformationen aus dem Kalender oder der E-Mail eines Benutzers zu extrahieren, um ihn automatisch bei der Planung von Besprechungen, dem Versenden von E-Mails und der Verwaltung anderer Aspekte seiner täglichen Aufgaben zu unterstützen. OpenAI hat alle bisherigen Agentenschritte von Lindy, die Probleme verursachten, auf das o1-Modell umgestellt und festgestellt, dass die Agentenfunktionalität von Lindy fast über Nacht einwandfrei funktionierte!"
--Lindy.AI, Arbeits-KI-Assistentin
5 Visual Reasoning: Einsicht in die Informationen hinter dem Bild
Von heute an.o1 ist das einzige Inferenzmodell, das visuelle Inferenzmöglichkeiten unterstützt. o1 zusammen mit GPT-4o Der signifikante Unterschied zwischen dero1 Selbst die schwierigsten visuellen Informationen, wie komplex strukturierte Diagramme, Tabellen oder Fotos mit schlechter Bildqualität, können effektiv verarbeitet werden. Dies unterstreicht die Bedeutung von o1 Einzigartige Vorteile im Bereich der visuellen Informationsverarbeitung.
Safetykit, eine KI-Plattform zur Überwachung von Händlern, erklärt: "OpenAI hat sich der Automatisierung von Risiko- und Compliance-Prüfungen für Millionen von Online-Produkten verschrieben, darunter Luxus-Schmuckrepliken, gefährdete Arten und regulierte Artikel. Bei OpenAIs anspruchsvollster Bildklassifizierungsaufgabe war das GPT-4o-Modell nur bei 50% genau. und
o1Das Modell erreicht eine beeindruckende Genauigkeit von bis zu 88% ohne Änderungen an den bestehenden Prozessen von OpenAI."-Safetykit, KI-Plattform zur Überwachung von Händlern
OpenAIs eigene interne Tests haben außerdem gezeigt, dasso1 Die Modelle sind in der Lage, Einbauten und Materialien aus sehr detaillierten Architekturzeichnungen zu identifizieren und umfassende Stücklisten zu erstellen. Eines der überraschendsten Phänomene, die OpenAI beobachtet hat, ist, dass dieo1 Das Modell ist in der Lage, Verbindungen zwischen verschiedenen Bildern herzustellen - es kann zum Beispiel die Legende auf einer Seite einer Architekturzeichnung nehmen und sie ohne ausdrückliche Anweisungen exakt auf eine andere Seite übertragen. Im folgenden Beispiel sehen wir, dass für die "4x4 PT Holzsäule" dieo1 Das Modell war in der Lage, korrekt zu erkennen, dass "PT" laut Legende für "pressure treated" steht. Dies ist eine gute Demonstration der o1 die Leistungsfähigkeit des Modells beim Verstehen komplexer visueller Informationen und beim dokumentenübergreifenden Schlussfolgern.

6 Code-Review, Debugging und Qualitätsverbesserung: Streben nach Exzellenz, Code-Optimierung
Inferenzmodelle eignen sich hervorragend für die Codeüberprüfung und -verbesserung und sind besonders gut für den Umgang mit großen Codebasen geeignet. Angesichts der relativ hohen Latenzzeit von Inferenzmodellen werden Code-Review-Aufgaben in der Regel im Hintergrund ausgeführt. Dies deutet darauf hin, dass Inferenzmodelle trotz der Latenzzeit wichtige Anwendungen in der Codeanalyse und Qualitätskontrolle haben, insbesondere für Szenarien, die keine hohe Echtzeitleistung erfordern.
Das KI-Code-Review-Startup CodeRabbit verrät: "OpenAI bietet automatisierte KI-Code-Review-Dienste auf Code-Hosting-Plattformen wie GitHub und GitLab. Der Code-Review-Prozess ist von Natur aus unempfindlich gegenüber Latenzzeiten, erfordert aber ein tiefes Verständnis von Codeänderungen über mehrere Dateien hinweg. Hier zeichnet sich das o1-Modell aus - es erkennt zuverlässig subtile Änderungen in der Codebasis, die von einem menschlichen Prüfer leicht übersehen werden könnten. Nach der Umstellung auf die Modelle der o-Serie konnte OpenAI einen dreifachen Anstieg der Produktkonversionen verzeichnen."
CodeRabbit, das Startup für KI-Codeprüfung
auch wenn GPT-4o im Gesang antworten GPT-4o mini Modell besser für Codierungsszenarien mit niedriger Latenz geeignet sein, aber OpenAI stellt auch fest, dass o3-mini Modell eignet sich hervorragend für latenzunabhängige Codegenerierungsanwendungen. Das bedeutet, dass die o3-mini Auch im Bereich der Codegenerierung birgt sie Potenzial, insbesondere in Anwendungsszenarien, die eine hohe Codequalität erfordern und relativ latenzarm sind.
Startups mit KI-gesteuerter Code-Vervollständigung Codeium kommentierte: "Selbst angesichts der anspruchsvollen Codierungsaufgaben ist die
o3-miniModelle sind auch in der Lage, durchgängig hochwertigen, schlüssigen Code zu erzeugen, und liefern sehr häufig die richtige Lösung, wenn das Problem gut definiert ist. Andere Modelle eignen sich vielleicht nur für kleine, schnelle Iterationen des Codes, aber dieo3-miniDie Modelle sind auf die Planung und Ausführung komplexer Software-Design-Systeme spezialisiert."--Codeium, das Startup für KI-gesteuerte Code-Erweiterung
7. modellhafte Bewertung und Benchmarking: objektive Bewertung und Auswahl der Besten der Besten
OpenAI stellte außerdem fest, dass die Inferenzmodelle beim Benchmarking und der Bewertung anderer Modellantworten gut abschnitten. Die Datenvalidierung ist entscheidend, um die Qualität und Zuverlässigkeit von Datensätzen zu gewährleisten, insbesondere in sensiblen Bereichen wie dem Gesundheitswesen. Herkömmliche Validierungsmethoden stützen sich auf vordefinierte Regeln und Muster, aber Methoden wie o1 im Gesang antworten o3-mini Solche fortgeschrittenen Modelle sind in der Lage, den Kontext zu verstehen und daraus Schlüsse zu ziehen, was flexiblere und intelligentere Überprüfungsmethoden ermöglicht. Dies deutet darauf hin, dass Inferenzmodelle als "Schiedsrichter" fungieren können, um die Qualität der Ergebnisse anderer Modelle zu bewerten, was für die iterative Optimierung von KI-Systemen entscheidend ist.
Braintrust, die KI-Bewertungsplattform, stellt fest: "Viele Kunden nutzen die LLM-as-a-judge-Funktion in der Braintrust-Plattform als Teil ihres Bewertungsprozesses. Ein Unternehmen aus dem Gesundheitswesen könnte zum Beispiel ein Tool wie
gpt-4oEin solches Mastermodell fasst das Problem der Patientengeschichte zusammen und verwendet dann dieo1Modell zur Bewertung der Qualität von Zusammenfassungen. Ein Braintrust-Kunde stellte fest, dass die Verwendung4oDer F1-Wert beträgt 0,12, wenn das Modell als Schiedsrichter verwendet wird, und der Wechsel zumo1Nach der Modellierung stieg der F1-Wert auf 0,74! In diesen Anwendungsfällen wurde festgestellt, dass dieo1Die Argumentationskraft des Modells ist entscheidend für die Erfassung der Nuancen der Endergebnisse, insbesondere bei den schwierigsten und komplexesten Bewertungsaufgaben."--Braintrust, eine KI-Bewertungsplattform
Tipps für effektive Prompting-Reasoning-Modelle: Einfachheit steht an erster Stelle
Denkmodelle erbringen in der Regel die besten Leistungen, wenn sie klare und prägnante Anweisungen erhalten. Einige herkömmliche Cue-Engineering-Techniken, wie z. B. die Anweisung an das Modell, "Schritt für Schritt zu denken", können die Leistung nicht effektiv verbessern und sind manchmal sogar kontraproduktiv. Im Folgenden finden Sie einige bewährte Verfahren, oder Sie können sich einfach an den Beispielen für Cueing orientieren.
- Entwicklermeldungen ersetzen Systemmeldungen. durch (eine Lücke)
o1-2024-12-17Version begann das Inferenzmodell damit, Entwicklernachrichten anstelle der traditionellen Systemnachrichten zu unterstützen, um dem Verhalten der in der Modellspezifikation beschriebenen Befehlskette zu entsprechen. - Halten Sie die Aufforderungen einfach und direkt. Denkmodelle sind gut im Verstehen und Reagieren auf klare und präzise Anweisungen. Daher sind klare und direkte Anweisungen für Denkmodelle effektiver als komplexe Cue-Engineering-Techniken.
- Tipp zur Vermeidung von Gedankenketten. Es besteht keine Notwendigkeit, das Argumentationsmodell aufzufordern, "Schritt für Schritt zu denken" oder "Ihren Argumentationsprozess zu erklären", da es intern bereits über Argumentationsfähigkeiten verfügt. Diese überflüssige Aufforderung kann die Leistung des Modells eher beeinträchtigen.
- Verwenden Sie Trennzeichen, um die Klarheit zu verbessern. Die Verwendung von Trennzeichen wie Markdown, XML-Tags und Abschnittsüberschriften zur eindeutigen Kennzeichnung verschiedener Teile des Inputs hilft dem Modell, den Inhalt der verschiedenen Abschnitte genau zu verstehen.
- Versuchen Sie vorrangig, Nullproben zu finden, bevor Sie geringere Proben in Betracht ziehen: die Inferenzmodelle liefern in der Regel gute Ergebnisse, ohne dass einige wenige Beispiele benötigt werden. Daher ist es empfehlenswert, dass Sie zunächst versuchen, Hinweise ohne Beispiele zu schreiben. Wenn Sie komplexere Anforderungen an die Ausgabeergebnisse haben, kann es hilfreich sein, einige Beispiele für Eingaben und gewünschte Ausgaben in Ihre Hinweise aufzunehmen. Es ist jedoch wichtig, dass die Beispiele in hohem Maße mit Ihren Aufforderungsanweisungen übereinstimmen, da Abweichungen zwischen beiden zu schlechten Ergebnissen führen können.
- Geben Sie klare und spezifische Leitlinien vor. Wenn es explizite Einschränkungen gibt, die die Bandbreite der Antworten des Modells einschränken können (z. B. "Schlagen Sie eine Lösung mit einem Budget von weniger als 500 $ vor"), sollten Sie diese Einschränkungen in der Aufforderung klar formulieren.
- Klärung des Endziels. Beschreiben Sie in den Anweisungen so genau wie möglich die Kriterien, nach denen erfolgreiche Antworten beurteilt werden, und ermutigen Sie das Modell, so lange zu argumentieren und zu iterieren, bis Ihre Erfolgskriterien erfüllt sind.
- Steuerung der Markdown-Formatierung. durch (eine Lücke)
o1-2024-12-17Ab Version 1 vermeiden die Inferenzmodelle in der API standardmäßig die Erzeugung von Antworten mit Markdown-Formatierung. Wenn Sie möchten, dass das Modell Markdown-Formatierung in seine Antworten einschließt, fügen Sie die ZeichenfolgeFormatting re-enabled.
Beispiele für die Verwendung der Inferenzmodell-API
Schlussfolgerungsmodelle sind einzigartig in ihrem "Denkprozess". Im Gegensatz zu herkömmlichen Sprachmodellen denken Inferenzmodelle intern tiefgründig und bauen eine lange Kette von Schlussfolgerungen auf, bevor sie eine Antwort geben. Wie es in der offiziellen OpenAI-Beschreibung heißt, denken diese Modelle gründlich nach, bevor sie dem Benutzer antworten. Dieser Mechanismus verleiht Inferenzmodellen die Fähigkeit, sich bei Aufgaben wie dem Lösen komplexer Rätsel, der Codierung, dem wissenschaftlichen Denken und der mehrstufigen Planung von Agenten-Workflows auszuzeichnen.
Ähnlich wie das GPT-Modell von OpenAI bietet OpenAI zwei Inferenzmodelle an, um unterschiedlichen Anforderungen gerecht zu werden:o3-mini Das Modell zeichnet sich durch seine geringere Größe und höhere Geschwindigkeit aus, während das Token Die Kosten sind ebenfalls relativ niedrig; und o1 Modelle hingegen bieten einen Ausgleich zwischen größerem Umfang und etwas geringerer Geschwindigkeit für eine bessere Problemlösung.o1 Modelle erzeugen in der Regel qualitativ bessere Antworten bei komplexen Aufgaben und zeigen eine bessere Generalisierungsleistung in verschiedenen Bereichen.
Schnellstart
Um Entwicklern einen schnellen Einstieg zu ermöglichen, bietet OpenAI eine einfach zu bedienende API-Schnittstelle. Hier ist ein Schnellstart-Beispiel für die Verwendung des Inferenzmodells in Chatverläufen:
Verwendung von Inferenzmodellen in Chatverläufen
import OpenAI from "openai";
const openai = new OpenAI();
const prompt = `
编写一个 bash 脚本,该脚本接收一个以字符串形式表示的矩阵,
格式为 '[1,2],[3,4],[5,6]',并以相同的格式打印转置矩阵。
`;
const completion = await openai.chat.completions.create({
model: "o3-mini",
reasoning_effort: "medium",
messages: [
{
role: "user",
content: prompt
}
],
});
console.log(completion.choices[0].message.content);
from openai import OpenAI
client = OpenAI();
prompt = """
编写一个 bash 脚本,该脚本接收一个以字符串形式表示的矩阵,
格式为 '[1,2],[3,4],[5,6]',并以相同的格式打印转置矩阵。
"""
response = client.chat.completions.create(
model="o3-mini",
reasoning_effort="medium",
messages=[
{
"role": "user",
"content": prompt
}
]
);
print(response.choices[0].message.content);
curl https://api.openai.com/v1/chat/completions \
-H "Content-Type: application/json" \
-H "Authorization: Bearer $OPENAI_API_KEY" \
-d '{
"model": "o3-mini",
"reasoning_effort": "medium",
"messages": [
{
"role": "user",
"content": "编写一个 bash 脚本,该脚本接收一个以字符串形式表示的矩阵,格式为 \"[1,2],[3,4],[5,6]\",并以相同的格式打印转置矩阵。"
}
]
}'
Intensität des Denkens: Kontrolle der Tiefe des Denkens im Modell
Im obigen Beispiel ist diereasoning_effort Der Parameter (während der Entwicklung dieser Modelle liebevoll als "Saft" bezeichnet) wird verwendet, um dem Modell vorzuschreiben, wie viele Schlussfolgerungsberechnungen es durchführt, bevor es eine Antwort erzeugt. Der Benutzer kann für diesen Parameter angeben lowundmedium vielleicht high Einer der drei Werte. Wo.low Modell legt den Schwerpunkt auf Geschwindigkeit und niedrigere Token-Kosten, während das high führt zu tieferen und umfassenderen Überlegungen des Modells, erhöht aber den Tokenverbrauch und die Reaktionszeit. Der Standardwert ist festgelegt auf mediumzielt darauf ab, ein Gleichgewicht zwischen Geschwindigkeit und Ableitungsgenauigkeit zu erreichen. Die Entwickler können die Intensität der Schlussfolgerungen flexibel an die Anforderungen der tatsächlichen Anwendungsszenarien anpassen, um eine optimale Leistung und Kosteneffizienz zu erreichen.
Wie das Denken funktioniert: Eine eingehende Analyse des "Denk"-Prozesses von Modellen
Das Inferenzmodell baut auf den traditionellen Eingabe- und Ausgabe-Tokens auf, indem es die Argumentation über Token Dieses Konzept. Diese Inferenz-Token entsprechen dem "Denkprozess" des Modells, und das Modell nutzt sie, um sein Verständnis der Hinweise des Benutzers zu zerlegen und mehrere mögliche Wege zur Generierung von Antworten zu erkunden. Erst wenn die Generierung der Inferenz-Token abgeschlossen ist, gibt das Modell die endgültige Antwort aus, ein komplementäres Token, das für den Benutzer sichtbar ist, und verwirft das Inferenz-Token aus dem Kontext.
Die folgende Abbildung zeigt ein Beispiel für einen mehrstufigen Dialog zwischen einem Benutzer und einem Assistenten. Bei jedem Schritt des Dialogs werden Eingabe- und Ausgabe-Token beibehalten, während Inferenz-Token vom Modell verworfen werden.
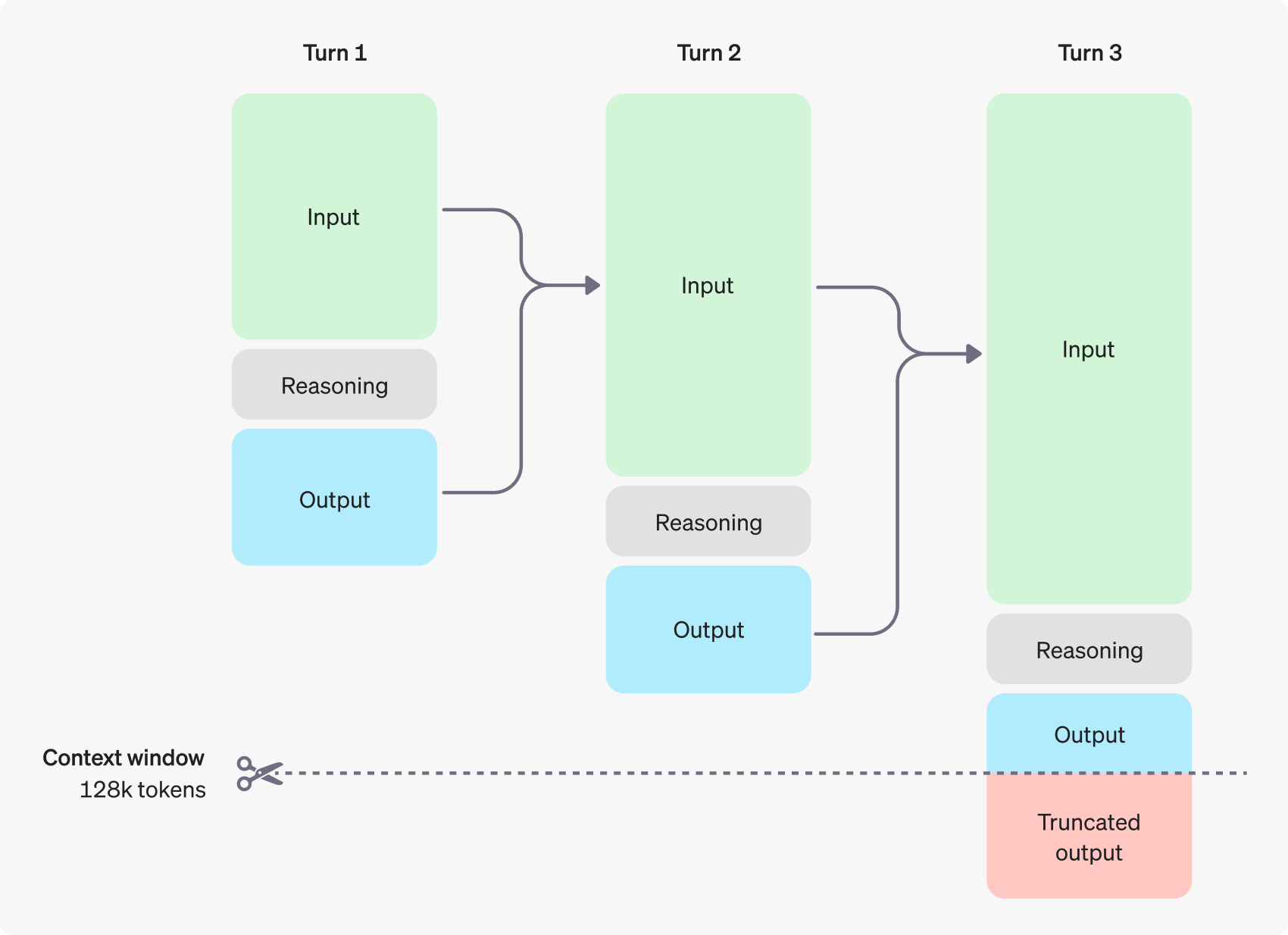
Es ist erwähnenswert, dass Inferenz-Token zwar nicht über die API-Schnittstelle sichtbar sind, aber dennoch den Platz im Kontextfenster des Modells einnehmen und für die gesamte Token-Nutzung zählen und genau wie Ausgabe-Token bezahlt werden müssen. Daher müssen die Entwickler in der Praxis die Auswirkungen von Inferenz-Token berücksichtigen und das Kontextfenster des Modells und den Token-Verbrauch entsprechend verwalten.
Kontextabhängiges Fenstermanagement: Sicherstellen, dass die Modelle genügend "Raum zum Denken" haben
Bei der Erstellung einer Vervollständigungsanfrage muss sichergestellt werden, dass das Kontextfenster genügend Platz für die vom Modell generierten Inferenz-Token bietet, die je nach Komplexität des Problems Hunderte bis Zehntausende von Inferenz-Token erfordern können. Der Benutzer kann Inferenz-Token über das Verwendungsobjekt des Chat-Vervollständigungsobjekts in der Datei completion_tokens_details um die genaue Anzahl der vom Modell für eine bestimmte Anfrage verwendeten Inferenz-Token zu sehen:
{
"usage": {
"prompt_tokens": 9,
"completion_tokens": 12,
"total_tokens": 21,
"completion_tokens_details": {
"reasoning_tokens": 0,
"accepted_prediction_tokens": 0,
"rejected_prediction_tokens": 0
}
}
}
Die Länge des Kontextfensters für verschiedene Modelle kann der Benutzer auf der Seite Modellreferenz einsehen. Die ordnungsgemäße Bewertung und Verwaltung des Kontextfensters ist für ein effizientes Funktionieren des Inferenzmodells unerlässlich.
Kostenkontrolle: Feinabstimmung und Optimierung des Tokenverbrauchs
Um die Kosten des Inferenzmodells effektiv zu verwalten, können Benutzer die Funktion max_completion_tokens Parameter, der die Gesamtzahl der vom Modell erzeugten Token begrenzt, einschließlich der Inferenz-Token und der Komplementär-Token.
Bei früheren Modellen war diemax_tokens Der Parameter steuert sowohl die Anzahl der vom Modell erzeugten Token als auch die Anzahl der für den Benutzer sichtbaren Token, die immer gleich sind. Bei Inferenzmodellen kann jedoch die Gesamtzahl der vom Modell erzeugten Token die Zahl der Token übersteigen, die der Benutzer letztendlich sieht, da interne Inferenz-Token eingeführt werden.
Bedenken Sie, dass einige Anwendungen auf max_tokens Parameter mit der Anzahl der von der API zurückgegebenen Token übereinstimmt, hat OpenAI einen speziellen max_completion_tokens Diese explizite Parametrisierung gewährleistet einen reibungslosen Übergang für bestehende Anwendungen, die das neue Modell verwenden, und vermeidet potenzielle Kompatibilitätsprobleme. Bei allen früheren Modellen wurde diemax_tokens Die Funktion des Parameters bleibt unverändert.
Dem Denken Raum geben: Unterbrechungen des "Denkens" vermeiden
Erreicht die Anzahl der erzeugten Token das Limit des Kontextfensters oder die vom Benutzer festgelegte max_completion_tokens Wert, gibt die API eine Antwort auf den Chatabschluss mit dem finish_reason Das Feld ist gesetzt auf length. Dies kann geschehen, bevor das Modell für den Benutzer sichtbare ergänzende Token erzeugt, was bedeutet, dass der Benutzer möglicherweise für Eingabe- und Schlussfolgerungs-Token bezahlen muss, aber letztendlich keine sichtbaren Antworten erhält.
Um dies zu vermeiden, stellen Sie sicher, dass im Kontextfenster genügend Platz zur Verfügung steht, oder platzieren Sie die max_completion_tokens wird auf einen höheren Wert eingestellt. openAI empfiehlt, beim ersten Ausprobieren dieser Inferenzmodelle Platz für mindestens 25.000 Token für die Inferenz- und Ausgabeprozesse zu reservieren. Wenn sich die Benutzer mit der Anzahl der für ihre Prompts benötigten Inferenz-Token vertraut gemacht haben, kann diese Puffergröße für eine feinere Kostenkontrolle angepasst werden.
Tipp: Entfaltung des Potenzials von Argumentationsmodellen
Es gibt einige wichtige Unterschiede, die der Benutzer bei der Eingabeaufforderung für Inferenzmodelle und GPT-Modelle beachten sollte. Insgesamt liefert das Inferenzmodell tendenziell bessere Ergebnisse bei Aufgaben, bei denen nur übergeordnete Anweisungen gegeben werden. Dies steht im Gegensatz zum GPT-Modell, das in der Regel besser abschneidet, wenn sehr präzise Anweisungen gegeben werden.
- Argumentationsmodelle wie erfahrene ältere Kollegen -- Die Benutzer können sich darauf verlassen, dass sie die spezifischen Details selbständig ausarbeiten, indem sie ihnen einfach sagen, was sie erreichen wollen.
- Das GPT-Modell entspricht eher einem Junior-Assistenten -- Sie funktionieren am besten, wenn sie klare und detaillierte Anweisungen für die Erstellung eines bestimmten Ergebnisses enthalten.
Weitere Informationen über bewährte Verfahren zur Verwendung von Inferenzmodellen finden Sie im offiziellen OpenAI-Leitfaden.
Tipp Beispiel: Demonstration eines Anwendungsszenarios
Kodierung (Code-Refactoring)
Die Modelle der o-Serie von OpenAI bieten leistungsstarke Funktionen für das algorithmische Verständnis und die Codegenerierung. Das folgende Beispiel zeigt, wie das o1-Modell für das Refactoring nach bestimmten Kriterien verwendet werden kann Reagieren Sie Bauteil.
Code neu strukturieren
import OpenAI from "openai";
const openai = new OpenAI();
const prompt = `
指令:
- 给定以下 React 组件,修改它,使非小说类书籍显示红色文本。
- 回复中仅返回代码
- 不要包含任何额外的格式,例如 markdown 代码块
- 对于格式,使用四个空格缩进,并且不允许任何代码行超过 80 列
const books = [
{ title: 'Dune', category: 'fiction', id: 1 },
{ title: 'Frankenstein', category: 'fiction', id: 2 },
{ title: 'Moneyball', category: 'nonfiction', id: 3 },
];
export default function BookList() {
const listItems = books.map(book =>
<li>
{book.title}
</li>
);
return (
<ul>{listItems}</ul>
);
}
`.trim();
const completion = await openai.chat.completions.create({
model: "o3-mini",
messages: [
{
role: "user",
content: prompt,
},
],
});
console.log(completion.usage.completion_tokens_details);
from openai import OpenAI
client = OpenAI();
prompt = """
指令:
- 给定以下 React 组件,修改它,使非小说类书籍显示红色文本。
- 回复中仅返回代码
- 不要包含任何额外的格式,例如 markdown 代码块
- 对于格式,使用四个空格缩进,并且不允许任何代码行超过 80 列
const books = [
{ title: 'Dune', category: 'fiction', id: 1 },
{ title: 'Frankenstein', category: 'fiction', id: 2 },
{ title: 'Moneyball', category: 'nonfiction', id: 3 },
];
export default function BookList() {
const listItems = books.map(book =>
<li>
{book.title}
</li>
);
return (
<ul>{listItems}</ul>
);
}
"""
response = client.chat.completions.create(
model="o3-mini",
messages=[
{
"role": "user",
"content": prompt
}
]
);
print(response.choices[0].message.content);
Code (Projektplanung)
Das o-Serienmodell von OpenAI eignet sich auch gut für die Entwicklung von mehrstufigen Projektplänen. Das folgende Beispiel zeigt, wie das o1-Modell verwendet wird, um eine vollständige Dateisystemstruktur für eine Python-Anwendung zu erstellen und Python-Code zu erzeugen, der die erforderliche Funktionalität implementiert.
Planen und Erstellen eines Python-Projekts
import OpenAI from "openai";
const openai = new OpenAI();
const prompt = `
我想构建一个 Python 应用程序,它可以接收用户的问题,并在数据库中查找答案。
数据库中存储了问题到答案的映射关系。如果找到密切匹配的问题,则检索匹配的答案。
如果没有找到,则要求用户提供答案,并将问题/答案对存储在数据库中。
为我创建一个目录结构计划,我需要这个结构,然后完整地返回每个文件中的代码。
只在开头和结尾提供你的推理过程,不要在代码中穿插推理。
`.trim();
const completion = await openai.chat.completions.create({
model: "o3-mini",
messages: [
{
role: "user",
content: prompt,
},
],
});
console.log(completion.usage.completion_tokens_details);
from openai import OpenAI
client = OpenAI();
prompt = """
我想构建一个 Python 应用程序,它可以接收用户的问题,并在数据库中查找答案。
数据库中存储了问题到答案的映射关系。如果找到密切匹配的问题,则检索匹配的答案。
如果没有找到,则要求用户提供答案,并将问题/答案对存储在数据库中。
为我创建一个目录结构计划,我需要这个结构,然后完整地返回每个文件中的代码。
只在开头和结尾提供你的推理过程,不要在代码中穿插推理。
"""
response = client.chat.completions.create(
model="o3-mini",
messages=[
{
"role": "user",
"content": prompt
}
]
);
print(response.choices[0].message.content);
MINT-Forschung
Die Modelle der o-Serie von OpenAI haben hervorragende Leistungen in der MINT-Forschung (Wissenschaft, Technologie, Ingenieurwesen und Mathematik) gezeigt. Diese Modelle liefern oft beeindruckende Ergebnisse bei Aufforderungen zur Unterstützung grundlegender Forschungsaufgaben.
Fragen im Zusammenhang mit der Forschung in den Grundlagenwissenschaften aufwerfen
import OpenAI from "openai";
const openai = new OpenAI();
const prompt = `
为了推进新型抗生素的研究,我们应该考虑研究哪三种化合物?
为什么我们应该考虑它们?
`;
const completion = await openai.chat.completions.create({
model: "o3-mini",
messages: [
{
role: "user",
content: prompt,
}
],
});
console.log(completion.choices[0].message.content);
from openai import OpenAI
client = OpenAI();
prompt = """
为了推进新型抗生素的研究,我们应该考虑研究哪三种化合物?
为什么我们应该考虑它们?
"""
response = client.chat.completions.create(
model="o3-mini",
messages=[
{
"role": "user",
"content": prompt
}
]
);
print(response.choices[0].message.content);
offizielles Beispiel
© urheberrechtliche Erklärung
Artikel Copyright AI-Austauschkreis Alle, bitte nicht ohne Erlaubnis vervielfältigen.
Ähnliche Artikel


Keine Kommentare...