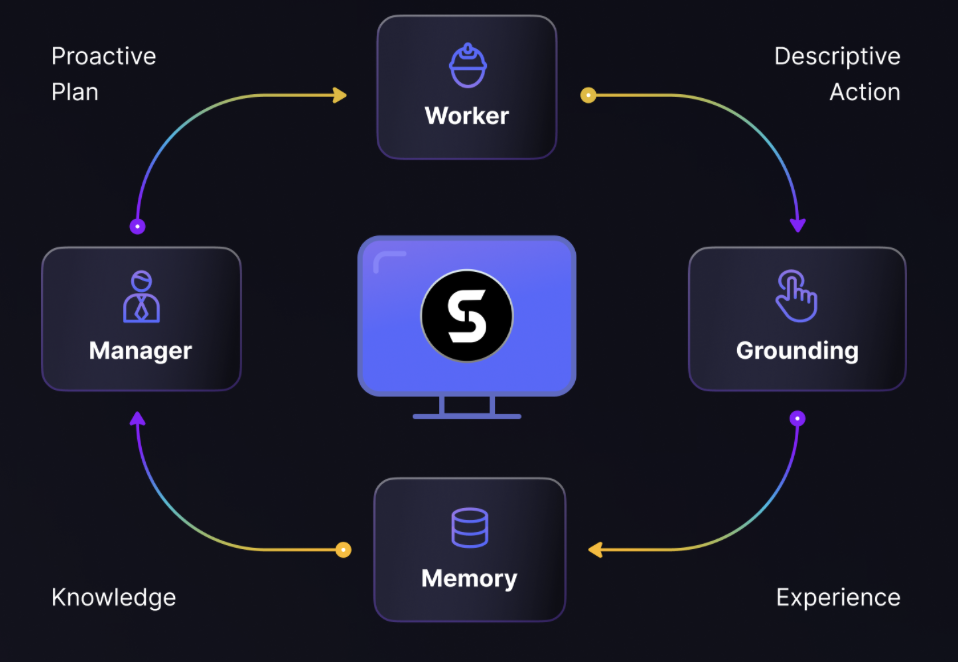
OmniSQL: Ein Modell zur Umwandlung natürlicher Sprache in qualitativ hochwertige SQL-Abfragen

Allgemeine Einführung
OmniSQL ist ein Open-Source-Projekt, das vom RUCKBReasoning-Team entwickelt und auf GitHub gehostet wird. Seine Hauptfunktion ist die Umwandlung von vom Benutzer eingegebenen Fragen in natürlicher Sprache in hochwertige SQL-Abfrageanweisungen, um den Benutzern die Interaktion mit Datenbanken zu erleichtern. Basierend auf einem automatisierten Framework zur Generierung von Text-zu-SQL-Daten hat das Projekt den SynSQL-2.5M-Datensatz mit 2,5 Millionen Beispielen veröffentlicht, der der größte domänenübergreifende synthetische Text-zu-SQL-Datensatz ist. OmniSQL bietet drei Modellgrößen, 7B, 14B und 32B, die für Benutzer mit unterschiedlichen Bedürfnissen geeignet sind. OmniSQL bietet drei Modellgrößen, 7B, 14B und 32B, die für Benutzer mit unterschiedlichen Anforderungen geeignet sind. Es bietet leistungsstarke Unterstützung für Datenanalyse, Datenbankmanagement und Modellforschung. Das Projekt verwendet das Apache 2.0-Protokoll, Benutzer können es kostenlos herunterladen und an der Verbesserung teilnehmen.

Funktionsliste
- Natürliche Sprache in SQL umwandeln: Der Benutzer gibt eine Frage ein und das Modell generiert eine genaue SQL-Abfrage.
- Unterstützung komplexer Abfragen: Generieren Sie erweitertes SQL, von einfachen Abfragen für eine Tabelle bis hin zu Joins für mehrere Tabellen.
- Datensatzerstellung: SynSQL-2.5M wird bereitgestellt, das 2,5 Millionen qualitativ hochwertige Proben enthält.
- Mehrskalenmodell: Bietet Modelle mit drei Parameterskalen: 7B, 14B und 32B.
- Open Source und kostenlos: Der Code und der Datensatz sind auf GitHub frei verfügbar.
Hilfe verwenden
OmniSQL ist ein codebasiertes Tool für Benutzer mit einigen Programmierkenntnissen. Nachfolgend finden Sie eine detaillierte Installations- und Nutzungsanleitung, die Ihnen einen schnellen Einstieg ermöglicht.
Einbauverfahren
- Vorbereiten der Umgebung
Stellen Sie sicher, dass auf Ihrem Computer Python 3.8 oder höher installiert ist. Öffnen Sie die Befehlszeile und geben Siepython --versionPrüfen. Wenn Sie es nicht installiert haben, können Sie es von der Python-Website herunterladen. - Projekt herunterladen
Interviewshttps://github.com/RUCKBReasoning/OmniSQLKlicken Sie auf die Schaltfläche "Code" und wählen Sie "Download ZIP", um die Zip-Datei des Projekts herunterzuladen. Entpacken Sie es und erhalten Sie den Projektordner. Oder Sie können ihn mit dem Git-Befehl klonen:
git clone https://github.com/RUCKBReasoning/OmniSQL.git
- Installation von Abhängigkeiten
Wechseln Sie in das Projektverzeichnis und führen Sie es über die Befehlszeile aus:
pip install -r requirements.txt
Dadurch werden die für die Ausführung erforderlichen Python-Bibliotheken installiert. Wenn Sie die Modellinferenz benötigen, müssen Sie auch die vLLM oder Transformers mit dem folgenden Befehl:
pip install vllm
vielleicht
pip install transformers torch
- Modelle und Datensätze herunterladen
OmniSQL bietet drei Modelle und den SynSQL-2.5M-Datensatz an, die unter den folgenden Links heruntergeladen werden können:
- SynSQL-2.5M. HuggingFace
- OmniSQL-7B. HuggingFace
- OmniSQL-14B. HuggingFace
- OmniSQL-32B. HuggingFace
Nach dem Herunterladen legen Sie die Datei im Projektverzeichnis ab.
- Laufende Projekte
Wechseln Sie in das Projektverzeichnis und führen Siepython omnisql.pyPrüfen Sie, ob die Umgebung in Ordnung ist. Das Modell muss für die tatsächliche Verwendung geladen werden, siehe unten.
Hauptfunktionen
1. natürliche Sprache in SQL umwandeln
Die Hauptfunktion von OmniSQL besteht darin, Fragen in SQL-Abfragen zu übersetzen. Führen Sie unter Verwendung von vLLM als Beispiel den folgenden Code aus:
from vllm import LLM, SamplingParams
from transformers import AutoTokenizer
# 定义提示模板
prompt = '''Task Overview:
You are a data science expert. Below, you are provided with a database schema and a natural language question. Your task is to generate a valid SQL query.
Database Engine: SQLite
Database Schema:
CREATE TABLE users (id INTEGER PRIMARY KEY, name TEXT, age INTEGER);
Question:
查找 users 表中年龄大于 30 的人的名字
Instructions:
- 只输出问题要求的信息。
- 逐步思考后生成 SQL。
Output Format:
-- Ihre SQL-Abfrage
'''
# 加载模型
model_path = "seeklhy/OmniSQL-7B" # 替换为你的模型路径
tokenizer = AutoTokenizer.from_pretrained(model_path)
llm = LLM(model=model_path, dtype="float16")
# 生成 SQL
sampling_params = SamplingParams(temperature=0, max_tokens=2048)
chat_prompt = tokenizer.apply_chat_template([{"role": "user", "content": prompt}], add_generation_prompt=True, tokenize=False)
outputs = llm.generate([chat_prompt], sampling_params)
print(outputs[0].outputs[0].text)
Die Ausgabe kann sein:
SELECT name FROM users WHERE age > 30;
2. die Verwendung des SynSQL-2.5M-Datensatzes
Der Datensatz enthält 2,5 Millionen Beispiele, die jeweils eine Datenbankstruktur, Fragen, SQL-Abfragen und Denkprozesse enthalten. Sie können sie herunterladen und direkt zu Schulungs- oder Forschungszwecken verwenden. Beispiele ansehen:
- Entpacken Sie die Dataset-Datei.
- Öffnen einer beliebigen JSON-Datei im Format
{"db": ..., "question": ..., "sql": ..., "cot": ...}.
3. die Ausbildung und Bewertung
Das Projekt bietet Schulungsskripte, die in der train_and_evaluate Ordner. Führen Sie das Beispiel aus:
python train.py --model OmniSQL-7B --data SynSQL-2.5M
Die Auswertungsskripte befinden sich ebenfalls in demselben Ordner, um die offiziellen Ergebnisse zu reproduzieren.
Tipps und Tricks
- Datenbank-UnterstützungDerzeit wird nur SQLite unterstützt; wenn andere Datenbanken benötigt werden, kann das Data Generation Framework verwendet werden, um neue Daten zu synthetisieren.
- Hardware-VoraussetzungDas Modell 7B benötigt etwa 14 GB Videospeicher, das Modell 32B eine höhere Konfiguration.
- Beispiel ansehen: Projekte
examplesDer Ordner enthält Beispiele für Prompt-Vorlagen.
Mit diesen Schritten können Sie schnell SQL mit OmniSQL erzeugen oder Text-to-SQL-Techniken untersuchen.
Anwendungsszenario
- Datenanalyse
Datenanalysten geben eine Frage ein, z. B. "Finden Sie die 10 meistverkauften Artikel", und OmniSQL generiert die entsprechende SQL, was Zeit spart. - Modellierungsstudien
Forscher trainieren neues Modell mit SynSQL-2.5M, um die Text-zu-SQL-Fähigkeit zu verbessern. - Pädagogisches Lernen
Die Schüler lernen Datenbankoperationen kennen, indem sie Fragen eingeben und das generierte SQL beobachten.
QA
- Welche Datenbanken werden von OmniSQL unterstützt?
Derzeit wird nur SQLite unterstützt, das in Zukunft um synthetische Daten erweitert werden kann. - Wie groß ist der Datensatz?
SynSQL-2.5M enthält 2,5 Millionen Beispiele für 16.000 Datenbanken. - Wie stark sind die Modelle?
OmniSQL übertrifft Modelle wie GPT-4o in Benchmarks wie Spider und BIRD.
© urheberrechtliche Erklärung
Artikel Copyright AI-Austauschkreis Alle, bitte nicht ohne Erlaubnis vervielfältigen.
Verwandte Beiträge



Keine Kommentare...