
Was ist Modellquantisierung: Erklärung der Datentypen FP32, FP16, INT8, INT4
Leitfaden (z. B. Buch oder anderes gedrucktes Material)
Im weiten Sternenhimmel der KI-Technologie treiben Deep-Learning-Modelle mit ihrer hervorragenden Leistung Innovation und Entwicklung in vielen Bereichen voran. Die kontinuierliche Erweiterung des Modellumfangs ist jedoch ein zweischneidiges Schwert, das bei gleichzeitiger Leistungsverbesserung einen starken Anstieg des Rechenaufwands und des Speicherdrucks mit sich bringt. Vor allem in ressourcenbeschränkten Anwendungsszenarien stehen die Bereitstellung und der Betrieb von Modellen vor großen Herausforderungen.
Angesichts dieses Dilemmas hat sich eine Technologie namens "Quantisierung" herausgebildet, die wie ein feines Skalpell wirkt, die Modellgröße geschickt reduziert, die Rechengeschwindigkeit verbessert und den Energieverbrauch innerhalb des akzeptablen Bereichs der Modellgenauigkeit erheblich verringert. Die Quantisierungstechnik kann die hochpräzisen FP32-Daten im Modell in niedrigpräzise INT4-Daten umwandeln und so die "Verschlankung" und "Beschleunigung" des Modells bewirken. In diesem Artikel werden wir die Grundsätze und Methoden der Quantisierung und ihre Anwendung im Bereich des Deep Learning analysieren, so dass auch Anfänger ihr Wesen leicht verstehen können.
1. die Grundlagen der numerischen Darstellung
1.1 Umwandlung von Binär- in Dezimalzahlen
In der Informatik, dem Grundstein der digitalen Welt, werden alle Daten in binärer Form gespeichert. Das Binärsystem besteht aus nur zwei Zahlen, 0 und 1, während das Dezimalsystem, das wir in unserem täglichen Leben verwenden, zehn Zahlen von 0 bis 9 enthält. Die Konvertierung zwischen diesen beiden Systemen ist, wie die Übersetzung zwischen verschiedenen Sprachen, der Schlüssel zum Verständnis der Darstellung von Daten in Computern.
Die Dezimalzahl 13 wird z. B. in die Binärform 1101 umgewandelt. Der Umwandlungsprozess ist vergleichbar mit der Zerlegung des dezimalen "Ganzen" in seine binären "Komponenten". Die Schritte sind wie folgt:
13 Dividiert durch 2 ist der Quotient 6 und der Rest 1 (kleinste binäre Ziffer)
6 geteilt durch 2 ergibt den Quotienten von 3 und den Rest von 0.
3 geteilt durch 2, Quotient 1, Rest 1
1 geteilt durch 2, Quotient ist 0, Rest ist 1 (höchste binäre Ziffer)
Die Residuen werden von unten nach oben aufgelistet:
↑1
↑0
↑1
↑1
Binäres Ergebnis erhalten: 1101
Umgekehrt ist die Konvertierung von binär 1101 zurück nach dezimal so, als würde man die "Teile" wieder zum "Ganzen" zusammensetzen. Von rechts nach links erhöht sich die Gewichtung jedes Bits um Zweierpotenzen, wobei das Bit ganz rechts eine Gewichtung von , , hat und so weiter nach links. Die Binärzahl 1101 wird also wie folgt in Dezimalzahlen umgewandelt: 1× + 1× + 0× + 1× = 8 + 4 + 0 + 1 = 13.
1.2 Unterschied zwischen Fließkommazahlen und ganzen Zahlen
(i) Ganzzahlige Typen (INT)
INT ist eine Abkürzung für Integer, was für den Typ der ganzen Zahl steht. Ganzzahlen sind, wie der Name schon sagt, Zahlen, die keine Dezimalstellen enthalten, wie z.B. 1, 2, 3, usw.
INT4 bedeutet, dass eine 4-Bit-Binärzahl zur Darstellung einer ganzen Zahl verwendet wird, während INT8 eine 8-Bit-Binärzahl zur Darstellung einer ganzen Zahl verwendet. Die Anzahl der Bits bestimmt den Bereich der Ganzzahlendarstellung.
Der Bereich der Ganzzahlen, die durch INT4 dargestellt werden können, ist begrenzt, da eine 4-Bit-Binärzahl bis zu einer anderen Zahl darstellen kann. Für INT4 mit Vorzeichen ist der Bereich in der Regel -8 bis 7 und für INT4 ohne Vorzeichen 0 bis 15. Das Gleiche gilt für INT8, das von -128 bis 127 reicht, und INT8 ohne Vorzeichen, das von 0 bis 255 reicht, da eine 8-Bit-Binärzahl = 256 verschiedene Zahlen darstellen kann.
(ii) Fließkommatyp (FP)
FP steht für Floating Point, den Fließkomma-Typ. Fließkommazahlen werden im Gegensatz zu Ganzzahlen verwendet, um Zahlen mit Bruchteilen darzustellen.
Eine Gleitkommazahl besteht aus einem Vorzeichenbit, einem Exponentenbit und einem Mantissenbit. Eine 32-Bit-Gleitkommazahl (FP32) besteht zum Beispiel aus 1 Vorzeichenbit, 8 Exponentenbits und 23 Mantissenbits. Dank dieses cleveren Designs können Fließkommazahlen eine extrem große Bandbreite an Werten darstellen, von sehr kleinen Zahlen bis hin zu sehr großen Zahlen wie einem Maßband.
FP32 kann zum Beispiel sehr kleine Zahlen (ungefähr) und sehr große Zahlen (ungefähr) darstellen. INT8 (8-Bit-Ganzzahlen) kann nur Ganzzahlen zwischen -128 und 127 darstellen. Dieser Unterschied ist vergleichbar mit dem Messen von Längen mit einem Lineal fester Länge (Ganzzahlen) im Vergleich zu einem skalierbaren Maßband (Fließkommazahlen), wobei die Fließkommazahlen den Ganzzahlen in Bezug auf die Flexibilität und den Bereich der numerischen Darstellung weit überlegen sind.
(iii) Häufig verwendete Datentypen
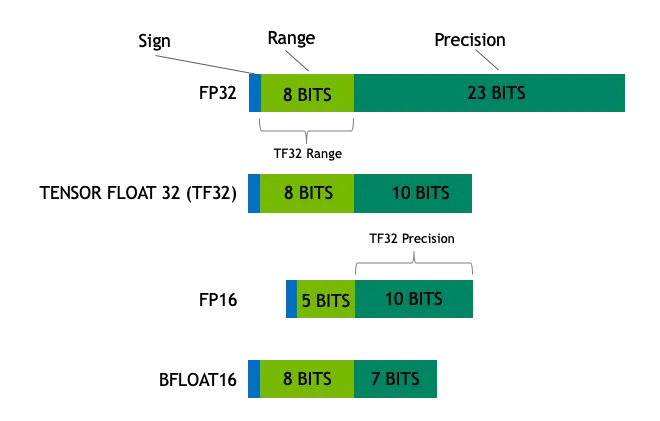
Zu den gängigen Datentypen für Deep Learning und allgemeine Datenverarbeitung gehören:
- Float32 (FP32)Dies ist das standardmäßige 32-Bit-Gleitkommaformat, das für seine hohe Genauigkeit und seinen großen Wertebereich bekannt ist. FP32-Operationen dominieren das Modelltraining und die Inferenz aufgrund ihrer Vielseitigkeit, die von einer breiten Palette von Hardware unterstützt wird.
- Float16 (FP16)FP16 ist eine 16-Bit-Gleitkommazahl mit halber Genauigkeit, die im Vergleich zu FP32 eine geringere Genauigkeit, aber einen deutlich geringeren Speicherbedarf und eine wesentlich höhere Rechengeschwindigkeit aufweist. FP16 hat einen relativ engen Bereich numerischer Darstellungen, bei denen die Gefahr eines Über- oder Unterlaufs besteht. Bei Deep Learning-Verfahren wie z. B.Verlustskalierung Die Anwendung von Techniken wie diesen kann diese Probleme wirksam lindern.
- BFloat16 (BF16)BF16 ist ein weiteres 16-Bit-Gleitkommaformat. Es ist insofern einzigartig, als BF16 das gleiche 8-Bit-Exponenten-Bit wie FP32 beibehält und somit den gleichen dynamischen Bereich wie FP32 hat, das Schlepp-Bit jedoch nur 7 Bits beträgt, was weniger präzise ist als FP16. BF16 hat jedoch nur 7 nachgestellte Bits, was weniger genau ist als FP16. BF16 ist in Szenarien mit einem breiten Wertebereich gut, aber bei präzisionssensiblen Aufgaben kann es zu Kompromissen kommen.
- Int8INT8 ist ein 8-Bit-Integer-Typ mit einer begrenzten Bandbreite an numerischen Darstellungen, aber sehr geringem Speicherbedarf. INT8 wird hauptsächlich in Modellquantisierungsverfahren verwendet, bei denen die Konvertierung von Modellparametern von hochpräzisen FP32- oder FP16- in INT8 den Speicherplatzbedarf und die Rechenkomplexität des Modells erheblich reduziert und so den Weg für einen effizienten Einsatz des Modells auf Geräten mit begrenzten Ressourcen ebnet.
2) Quantitative Konzepte
2.1 Quantitative Definitionen
Quantisierung bezieht sich auf die Umwandlung von Daten in einem Modell von einer hochpräzisen Darstellung in eine niedrigpräzise Darstellung, wie im Fall derAbwägung zwischen Bildqualität und DateigrößeBeim Deep Learning ist die Quantisierung der Prozess der Komprimierung eines hochpräzisen Bildes in ein JPEG-Bild mit geringerer Genauigkeit, wodurch die Dateigröße erheblich reduziert wird, während die wichtigsten Informationen des Bildes erhalten bleiben. Im Bereich des Deep Learning bezieht sich die Quantisierung in der Regel auf die Reduzierung der Modellgewichte und Aktivierungswerte von FP32 (32-Bit-Gleitkomma) auf FP16 (16-Bit-Gleitkomma) oder sogar INT8 (8-Bit-Ganzzahl) oder eine geringere Präzision.
FP32 ist ein hochpräzises Fließkommaformat, das Werte in 32-Bit-Binärwerten (1 Vorzeichenbit, 8 Exponentenbits und 23 Mantissenbits) genau darstellt. FP32 ist eine Präzisionsskala, mit der kleine bis große Werte gemessen werden können, aber die hohe Präzision geht mit einem hohen Speicheraufwand und einer relativ langsamen Berechnungsgeschwindigkeit einher.
FP16 ist ein halbpräzises Gleitkommaformat, das nur 16 Binärbits (1 Vorzeichenbit, 5 Exponentenbits, 10 Mantissenbits) zur Darstellung eines Wertes benötigt. Im Vergleich zu FP32 opfert FP16 die Präzision für die Hälfte des Speicherplatzes und eine verbesserte Berechnungseffizienz und ist wie eine etwas dickere Skala, die ein gutes Gleichgewicht zwischen Präzision und Effizienz schafft.
INT8 ist ein 8-Bit-Integer-Typ, der nur ganze Zahlen im Bereich von -128 bis 127 darstellen kann. INT8 hat den Vorteil, dass er sehr wenig Speicherplatz benötigt und sehr schnell rechnet, aber auch die geringste numerische Genauigkeit hat. INT8 ist ähnlich wie ein einfacher Zähler, der nur ganze Zahlen zählt, aber er ist schnell und praktisch.
2.2 Quantitativer Zweck
Der zentrale Zweck der Quantifizierung besteht darinGeringerer Speicherbedarf und geringere Rechenkomplexität der Modelleund ist gleichzeitig bestrebt, den Verlust an Präzision in akzeptablen Grenzen zu halten. Mit der Quantifizierung sollen insbesondere die folgenden Ziele erreicht werden:
Geringerer SpeicherbedarfModerne Deep-Learning-Modelle, insbesondere groß angelegte Modelle mit riesigen Parametergrößen, haben oft Hunderte von Millionen oder sogar Hunderte von Milliarden von Parametern, was einen enormen Druck auf den Speicherplatz ausübt. Nimmt man ein FP32-Modell als Beispiel, so belegt jeder Parameter 4 Byte Speicherplatz. Wird das Modell auf FP16 quantisiert, benötigt jeder Parameter nur 2 Byte, was den Speicherbedarf um die Hälfte reduziert. Wenn das Modell weiter auf INT8 quantisiert wird, benötigt jeder Parameter nur noch 1 Byte, und der Speicherplatz kann um 75% reduziert werden.
Steigerung der rechnerischen EffizienzDas quantisierte Modell ist in der Inferenzphase deutlich weniger rechenintensiv, was zu einer höheren Inferenzgeschwindigkeit führt. Wenn beispielsweise ein FP32-Modell auf einer GPU läuft, kann die Berechnungsgeschwindigkeit durch die Speicherbandbreite begrenzt sein. Bei FP16- oder INT8-Modellen hingegen kann die Berechnungsgeschwindigkeit dank der optimierten Beschleunigung von Berechnungen mit geringer Genauigkeit durch die Hardware erheblich gesteigert werden. Die Leistungsverbesserung durch Quantisierung ist besonders in Szenarien von Bedeutung, in denen die Rechenressourcen begrenzt sind, wie z. B. bei Edge-Geräten oder mobilen Geräten.
den Stromverbrauch zu senkenDie Verringerung des Ressourcenbedarfs von Modellrechnern führt direkt zu einer Verringerung des Energieverbrauchs. Für mobile Geräte und eingebettete Systeme ist der Stromverbrauch ein entscheidender Faktor. Quantifizierungstechniken können den Stromverbrauch von Modellen wirksam reduzieren, die Lebensdauer von Geräten verlängern und die Anforderungen an die Wärmeableitung verringern.
Geringerer Bandbreitenbedarf:: In verteilten Computersystemen bedeutet die Verringerung der Modellgröße auch eine Verringerung der Datenübertragungsbandbreite. In einem Szenario mit mehreren Servern können quantitative Modelle schneller verteilt und synchronisiert werden, wodurch sich die Effizienz der Datenübertragung insgesamt verbessert.
3. INT4, INT8 Quantifizierung
3.1 INT4 und INT8 Darstellungsbereich
INT4 und INT8 sind beides ganzzahlige Quantisierungsmethoden, die Daten in binärer Form in Computersystemen speichern, sich aber durch den Bereich und die Genauigkeit der numerischen Darstellung unterscheiden.
- INT8INT8 ist ein 8-Bit-Integer-Typ mit einem Darstellungsbereich von -128 bis 127. Er kann mit einem 8-Bit-Zähler verglichen werden, bei dem jedes Bit entweder 0 oder 1 sein kann und verschiedene Integer-Werte durch verschiedene Kombinationen von 0/1 dargestellt werden können. Zum Beispiel, in dernotiert INT8 bedeutet mittel, im Bereich von -128 bis 127, und 11111111 in binärer Darstellung bedeutet -1 in dezimaler Darstellung. Wenn es sich umohne Vorzeichen (d.h. der absolute Wert, unabhängig vom Vorzeichen) INT8, das von 0 bis 255 reicht, wobei 11111111 für 255 in Dezimalzahlen steht, reicht aus, um die Anforderungen vieler Anwendungsszenarien zu erfüllen, wie z. B. Pixelwerte in der Bildverarbeitung, die normalerweise im Bereich von 0 bis 255 liegen und durch INT8 effektiv dargestellt werden können.
- INT4INT4 ist ein 4-Bit-Integer-Typ mit einem kleineren Darstellungsbereich von -8 bis 7 als INT8. INT4 opfert den numerischen Bereich für einen geringeren Speicherbedarf und schnellere Berechnungen. INT4 ist wie ein kleinerer Zähler, mit einem begrenzten numerischen Bereich, aber einem kleineren "Fußabdruck", der ressourceneffizienter ist. Es ist ressourceneffizienter. In einigen Anwendungsszenarien mit relativ geringen Genauigkeitsanforderungen, wie z. B. bei einigen leichtgewichtigen neuronalen Netzschichten, kann die Verwendung der INT4-Quantisierung die Speicher- und Rechenkosten erheblich senken.Beim Einsatz eines leichtgewichtigen Bildklassifizierungsmodells auf mobilen Geräten können beispielsweise Modellparameter und Zwischenergebnisse im INT4-Format gespeichert und berechnet werden, um den Speicherbedarf zu verringern und die Schlussfolgerungen zu beschleunigen.
3.2 Quantitative Formeln und Beispiele
Der Prozess der Quantisierung ist im Wesentlichen die Umwandlung einer hochpräzisen Fließkommazahlentabelle in eine niedrigpräzise Ganzzahl. Am Beispiel der Quantisierung von FP32 in INT8 lautet die Quantisierungsformel wie folgt:
ist die ursprüngliche Fließkommazahl.
ist eine quantisierte ganze Zahl.
ist der Skalierungsfaktor, der verwendet wird, um Fließkommazahlen auf Ganzzahlbereiche abzubilden.
Gibt die Rundung auf die nächste ganze Zahl an.
Gibt an, dass das Ergebnis auf den Bereich von INT8, d.h. [-128, 127], begrenzt ist.
Berechnung des Skalierungsfaktors
Der Skalierungsfaktor wird in der Regel als Maximum des Absolutwerts der Fließkommazahl berechnet. Unter der Annahme, dass es eine Menge von Fließkommazahlen gibt, ist das Verfahren wie folgt:
- Ermitteln Sie den maximalen absoluten Wert der Gruppe von Fließkommazahlen:
- Berechnen Sie den Skalierungsfaktor: .
In der Praxis gibt es mehrere Möglichkeiten, den Skalierungsfaktor zu berechnen, z. B. Maximalquantisierung, Mittelwert-Std.-Quantisierung usw. Bei der Max-Quantisierung wird der maximale Absolutwert des Tensors zur Berechnung des Skalierungsfaktors herangezogen, was einfach zu implementieren ist, aber empfindlich auf Ausreißer reagieren kann. Die Mean-Std-Quantisierung verwendet die Informationen über den Mittelwert und die Standardabweichung der Daten, um den Skalierungsfaktor auf eine robustere Art und Weise zu bestimmen, aber der Rechenaufwand ist etwas höher. Die Wahl der geeigneten Methode zur Berechnung des Skalierungsfaktors erfordert eine Abwägung zwischen Genauigkeit und Rechenaufwand.
typisches Beispiel
Angenommen, wir haben einen Satz von Fließkommazahlen [-0,5, 0,3, 1,2, -2,1], so wird im Folgenden der Quantisierungsprozess Schritt für Schritt demonstriert:
1. berechnen Sie den maximalen absoluten Wert:
2. die Berechnung des Skalierungsfaktors:
3. jede Gleitkommazahl quantifizieren:
- Für -0,5.
- Für 0.3.
- Für 1.2.
- Für -2.1.
Die endgültige, quantisierte INT8-Darstellung ist [-1, 1, 4, -7].
Anhand der obigen Schritte wird deutlich, wie die Quantisierungstechnik Gleitkommazahlen in ganze Zahlen umwandelt. Obwohl der Quantisierungsprozess unweigerlich einen gewissen Präzisionsverlust mit sich bringt, kann durch eine kluge Wahl des Skalierungsfaktors das Leistungsniveau des Modells maximal beibehalten und gleichzeitig die Speicher- und Berechnungskosten erheblich reduziert werden. Um Quantisierungsfehler weiter zu reduzieren, kann auch eine Nullpunktquantisierung eingeführt werden. Die Nullpunktquantisierung fügt der Quantisierungsformel einen Nullpunkt-Offset hinzu, der es ermöglicht, Fließkomma-Nullen genau auf Ganzzahl-Nullen abzubilden, wodurch die Quantisierungsgenauigkeit verbessert wird, insbesondere wenn der Aktivierungswert eine große Anzahl von Nullen enthält.
4. die Quantifizierung von FP8, FP16 und FP32
4.1 FP8, FP16, FP32 Darstellungen
FP8, FP16 und FP32 sind Fließkommazahlen, die in binärer Form im Computer gespeichert werden, aber mit unterschiedlichen Bitbreiten und daher unterschiedlichen Bereichen und Genauigkeiten.
FP32
FP32, das standardmäßige 32-Bit-Gleitkommaformat, besteht aus den folgenden drei Teilen:
- Vorzeichen Bit (1 Bit)0 steht für eine positive Zahl und 1 für eine negative Zahl.
- Exponentiale Ziffern (8 Ziffern): wird verwendet, um den Größenbereich eines Wertes zu definieren, so dass FP32 Werte von sehr klein bis sehr groß darstellen kann.
- Letzte Ziffer (23 Bits)Genauigkeit: Dient zur Bestimmung der Genauigkeit eines Wertes; je mehr Nachkommastellen, desto höher die Genauigkeit.
Mit einem weiten Wertebereich von ca. bis und einer Genauigkeit von ca. 6 Dezimalstellen ist das FP32 wie ein hochpräzises Maßband, das Größenordnungen so klein wie ein Staubkorn und Entfernungen so groß wie ein Berg messen kann. FP32 ist ein unverzichtbarer Datentyp für wissenschaftliche Berechnungen, Finanzmodellierung und andere Bereiche, die ein hohes Maß an Genauigkeit erfordern.
FP16

FP16 ist ein halbpräzises Fließkommaformat, das nur 16 Bits im Speicher belegt und damit halb so groß ist wie FP32:
- Vorzeichen Bit (1 Bit)Identifiziert positive und negative Werte.
- Exponentialziffer (5 Ziffern): Legt einen Bereich von Wertgrößen fest.
- Letzte Ziffer (10 Ziffern)Bestimmt die numerische Genauigkeit.
Der Bereich von FP16 reicht von etwa bis, und die Genauigkeit ist im Vergleich zu FP32 auf etwa 3 Dezimalstellen reduziert. FP16 ist wie ein Lineal mit einer etwas dickeren Skala, die eine geringere Genauigkeit hat, aber es hat mehr Vorteile in Bezug auf Speicherplatz und Berechnungseffizienz. FP16 wird häufig für das Training und die Inferenz von Deep-Learning-Modellen verwendet, die eine hohe Rechengeschwindigkeit und Speicherbandbreite erfordern. Insbesondere in Szenarien mit GPU-Beschleunigung kann FP16 Hardware-Beschleunigungseinheiten wie Tensor Core voll ausnutzen, um erhebliche Leistungssteigerungen zu erzielen.
FP8
FP8 ist ein aufstrebendes Format für niedrigpräzise Gleitkommazahlen, das hauptsächlich im Bereich des Deep Learning verwendet wird und auf eine effiziente Berechnung abzielt.8 Die typische Struktur von FP8 ist wie folgt:
- Vorzeichen Bit (1 Bit)Identifiziert positive und negative Werte.
- Exponentiale Ziffern (3 oder 4 Ziffern)FP8: Definieren Sie eine Reihe von Wertgrößen (es gibt zwei FP8-Varianten).
- Letzte Ziffer (4 oder 3 Ziffern)Legt die numerische Genauigkeit fest (entspricht der Anzahl der Indexziffern).
Der Bereich und die Genauigkeit der numerischen Darstellung des FP8 sind weiter reduziert, aber die Vorteile sind ein kleinerer Speicherbedarf und schnellere Berechnungsgeschwindigkeiten. Wenn FP32 ein Präzisionsbandmaß ist und FP16 ein Lineal mit einer etwas dickeren Skala, dann ist FP8 ein präziseres Bandmaß. Es ist wie ein einfaches Lineal mit einer Zentimeterskala.Darüber hinaus werden die Reichweite und die Genauigkeit weiter reduziert, aber die Messaufgabe kann in einer bestimmten Situation immer noch schnell erledigt werden. Als extrem ungenauer Datentyp zeigt FP8 großes Potenzial in Szenarien mit extremen Latenz- und Durchsatzanforderungen, wie z. B. Echtzeit-Inferenz, Edge Computing usw. FP8 stellt jedoch auch höhere Anforderungen an Hardware und Algorithmen. Die Anwendung von FP8 stellt jedoch auch höhere Anforderungen an Hardware und Algorithmen und erfordert spezielle Hardwareunterstützung und Quantisierungsstrategien zur Gewährleistung der Genauigkeit.
4.2 Quantifizierungsverfahren und Formeln
Unter Quantisierung versteht man die Umwandlung einer hochpräzisen Gleitkommazahl in eine niedrigpräzise Gleitkommazahl oder Ganzzahl. Am Beispiel der Quantisierung von FP32 in FP16 lautet die Formel für die Quantisierung wie folgt:
ist die ursprüngliche Fließkommazahl.
ist eine quantisierte niedrigpräzise Gleitkommazahl.
ist der Skalierungsfaktor, der verwendet wird, um Fließkommazahlen auf Bereiche mit geringerer Genauigkeit abzubilden.
Gibt die Rundung auf den nächsten Wert an.
Berechnung des Skalierungsfaktors
Der Skalierungsfaktor wird in der Regel als Maximum des Absolutwerts der Fließkommazahl berechnet. Unter der Annahme, dass es eine Menge von Fließkommazahlen gibt, ist das Verfahren wie folgt:
- Ermitteln Sie den maximalen absoluten Wert der Gruppe von Fließkommazahlen:
- Berechnung des Skalierungsfaktors: , wobei das Maximum des Zielformats mit niedriger Genauigkeit istKann als absoluter Wert ausgedrückt werden. Für FP16 beträgt dieser Wert ungefähr 65504.
Ähnlich wie bei der INT8-Quantifizierung können die Skalierungsfaktoren bei der FP16-Quantifizierung auf verschiedene Arten berechnet werden, die je nach den unterschiedlichen Anforderungen an Genauigkeit und Leistung gewählt werden können. Darüber hinaus wird die FP16-Quantisierung häufig in Verbindung mit Mixed Precision Training (MPT) verwendet. Während des Modelltrainings wird FP16 für einige rechenintensive Operationen (z. B. Matrixmultiplikation, Faltung) verwendet, während FP32 für Operationen verwendet wird, die eine höhere Genauigkeit erfordern (z. B. Verlustberechnung, Gradientenaktualisierung), um den Trainingsprozess zu beschleunigen und den Speicherverbrauch zu reduzieren, während die Genauigkeit des Modells gewährleistet wird.
typisches Beispiel
Angenommen, wir haben einen Satz von FP32-Fließkommazahlen [-0,5, 0,3, 1,2, -2,1], so wird im Folgenden Schritt für Schritt die Quantisierung von FP32 nach FP16 demonstriert:
1. berechnen Sie den maximalen absoluten Wert:
2. die Berechnung des Skalierungsfaktors:
3. jede Gleitkommazahl quantifizieren:
- Für -0,5.
- Für 0.3.
- Für 1.2.
- Für -2.1.
Das endgültige, quantifizierte FP16 wird ausgedrückt als [-0,5, 0,3, 1,2, -2,1].
Anhand der obigen Schritte kann man sehen, wie Quantisierungstechniken hochpräzise Gleitkommazahlen in niedrigpräzise Gleitkommazahlen umwandeln. Die Quantisierung bringt sicherlich einen gewissen Präzisionsverlust mit sich, aber durch eine kluge Wahl des Skalierungsfaktors kann die Leistung des Modells so weit wie möglich beibehalten und gleichzeitig die Speicher- und Berechnungskosten gesenkt werden. Um die Genauigkeit der FP16-Quantisierung weiter zu verbessern, kann die dynamische Quantisierung verwendet werden. Die dynamische Quantisierung passt den Skalierungsfaktor dynamisch an den tatsächlichen Bereich der Eingabedaten während des Ableitungsprozesses an, um sich besser an die Änderungen der Datenverteilung anzupassen und den Quantisierungsfehler zu verringern.
5) Quantitative Anwendungen und Vorteile
5.1 Anwendungen im Deep Learning
Quantitative Techniken haben ein breites Spektrum an vielversprechenden Anwendungen im Deep Learning, insbesondere in den Phasen des Modelltrainings und der Inferenz, wo sie zunehmend wertvoll sind. Im Folgenden werden einige wichtige Anwendungen von Quantisierungstechniken beim Deep Learning vorgestellt:
Beschleunigung der Modellausbildung
Während der Trainingsphase des Modells kann die Berechnung mit Datentypen niedriger Präzision wie FP16 oder FP8 den Trainingsprozess erheblich beschleunigen. Die NVIDIA-GPUs der Hopper-Architektur unterstützen beispielsweise Tensor Core-Operationen mit FP8-Präzision. FP8-Training kann 2 bis 3 Mal schneller sein als herkömmliches FP32-Training. Diese Trainingsbeschleunigung ist besonders wichtig für Modelle mit großen Parametern, da sie die Trainingszeit und den Verbrauch von Rechenressourcen erheblich reduziert. Beim Training von großen Sprachmodellen wie GPT-3 kann beispielsweise die Verwendung von FP16- oder BF16-Training mit gemischter Genauigkeit die Trainingszeit erheblich verkürzen und eine Menge Rechenressourcen sparen.
laut Inflection AI Inflection-2 wurde beispielsweise auf 5.000 NVIDIA-Grafikprozessoren der Hopper-Architektur mit einer FP8-Trainingsstrategie mit gemischter Genauigkeit trainiert, was insgesamt FLOPs an Fließkommaoperationen ergab. In einer Reihe von Standard-KI-Leistungsbenchmarks zeigte Inflection-2 eine überlegene Leistung gegenüber Googles Flaggschiff-Modell PaLM 2, das ebenfalls in der Kategorie der Trainingsberechnungen liegt. In einer Reihe von Standard-KI-Leistungsbenchmarks zeigte Inflection-2 einen signifikanten Leistungsvorteil gegenüber dem Google-Flaggschiff PaLM 2 in derselben Kategorie für Trainingsberechnungen.
Optimierung der Modellinferenz
In der Phase der Modellinferenz können Quantisierungstechniken den Speicherbedarf und die Rechenkomplexität des Modells erheblich reduzieren und damit die Inferenzeffizienz verbessern. So kann beispielsweise durch die Quantisierung eines FP32-Modells auf INT8 der Speicherplatz des Modells um 75% reduziert und die Inferenzgeschwindigkeit um ein Vielfaches erhöht werden. Dies ist von entscheidender Bedeutung für den Einsatz von Deep-Learning-Modellen auf Edge- oder Mobilgeräten, die häufig mit begrenzten Rechenressourcen und Speicherplatz konfrontiert sind. Beim Einsatz von Bilderkennungsmodellen auf Mobiltelefonen beispielsweise kann die Quantisierung des Modells als INT8 die Größe des Modells effektiv verringern, den Speicherverbrauch reduzieren, die Inferenz beschleunigen und die Benutzerfreundlichkeit verbessern.
So hat Google beispielsweise eng mit dem NVIDIA-Team zusammengearbeitet, um die TensorRT-LLM-Optimierungstechnik auf das Gemma-Modell anzuwenden und sie mit der FP8-Technologie zu kombinieren, um die Inferenz zu beschleunigen. Experimentelle Ergebnisse zeigen, dass FP8 im Vergleich zu FP16 eine mehr als dreifache Verbesserung des Durchsatzes erzielt, wenn Hopper-GPUs für Inferenzen verwendet werden.
Modellkomprimierung und -bereitstellung
Quantisierungsverfahren können auch zur Modellkomprimierung und -bereitstellung eingesetzt werden. Durch die Quantisierung von Modellen mit hoher Genauigkeit in Modelle mit niedriger Genauigkeit kann die Modellgröße effektiv reduziert werden, so dass облегчить Modelle in Umgebungen mit begrenzten Ressourcen eingesetzt werden können. Zum Beispiel, Null-Eins-Allesnutzen. Der kombinierte Hardware- und Software-Technologie-Stack von NVIDIA hat das Training und die Validierung von großen Modellen in FP8 abgeschlossen, mit einer 1,3-fachen Steigerung des Trainingsdurchsatzes für große Modelle im Vergleich zu BF16. Neben der INT8- und FP16/FP8-Quantisierung gibt es auch INT4- und noch niedrigere Bit-Quantisierungstechniken, wie z. B. Binary Neural Network (BNN) und Ternary Neural Network (TNN). Diese Quantisierungstechniken mit sehr niedrigen Bits können das Modell extrem komprimieren, allerdings in der Regel mit einem großen Verlust an Genauigkeit, und eignen sich für Szenarien mit extremen Anforderungen an die Modellgröße und Geschwindigkeit.
Darüber hinaus kann das quantisierte Modell mit Hilfe spezieller Hardware-Beschleunigungstechniken weiter verbessert werden. Zum Beispiel, NVIDIA Transformator Engine wurde in gängige Deep-Learning-Frameworks wie PyTorch, JAX, PaddlePaddle usw. integriert und bietet effiziente Unterstützung auf Hardware-Ebene für die Inferenz von quantitativen Modellen. Neben den NVIDIA-Grafikprozessoren sind auch andere Hardwareplattformen wie CPUs mit ARM-Architektur und mobile NPUs für quantitative Berechnungen optimiert und beschleunigt und bieten so eine Hardwaregrundlage für den breiten Einsatz quantitativer Modelle.
5.2 Stärken und Grenzen
Schneidkante
Verbesserung der rechnerischen EffizienzSowohl FP16 als auch FP8 haben einen um ein Vielfaches höheren Rechendurchsatz als FP32. Dieser Beschleunigungseffekt ist besonders ausgeprägt beim Training und der Inferenz von Modellen in großem Maßstab.
Geringerer LagerbedarfQuantisierungsverfahren können den Speicherbedarf von Modellen erheblich reduzieren. Zum Beispiel reduziert die Quantisierung eines FP32-Modells auf INT8 den Speicherplatz um 75%, was für den Einsatz von Modellen in Umgebungen mit begrenzten Speicherressourcen wichtig ist.
Geringerer Stromverbrauch:: Für Berechnungen mit geringer Genauigkeit werden weniger Rechenressourcen benötigt, was den Stromverbrauch von Geräten verringert. Bei mobilen Geräten und eingebetteten Systemen ist der Stromverbrauch ein wichtiger Faktor bei der Entwicklung. Quantisierte Modelle tragen dazu bei, die Lebensdauer der Gerätebatterie zu verlängern und die Anforderungen an die Wärmeableitung zu verringern.
Modell-OptimierungQuantisierungstechniken treiben die Modelloptimierung und -komprimierung während des Trainings und der Inferenz voran, wodurch die Einsatzkosten weiter gesenkt werden. Die Anwendung von FP8 ermöglicht es den Modellen beispielsweise, während der Trainingsphase verfeinerte Quantisierungsstrategien zu erkunden und so die Gesamteffizienz des Modells zu verbessern.
Einschränkungen
Verlust an PräzisionDer Quantisierungsprozess geht zwangsläufig mit einem Präzisionsverlust einher, der insbesondere bei der Verwendung von Formaten mit sehr geringer Genauigkeit (z. B. FP8) erheblich sein kann und zu einer Verschlechterung der Leistung des Modells bei einer bestimmten Aufgabe führen kann. Der Präzisionsverlust lässt sich zwar bis zu einem gewissen Grad abmildern, z. B. durch eine sorgfältige Wahl der Skalierungsfaktoren, aber eine vollständige Beseitigung des Präzisionsverlusts ist oft schwer zu erreichen. Um den durch die Quantisierung verursachten Genauigkeitsverlust abzumildern, kann Quantisierungs-bewusstes Training (QAT) verwendet werden. QAT simuliert den Quantisierungsvorgang während des Modelltrainings und berücksichtigt den Quantisierungsfehler beim Training, so dass ein Modell trainiert wird, das robuster gegenüber Quantisierung ist. QAT kann die Genauigkeit von Quantisierungsmodellen in der Regel erheblich verbessern, allerdings steigen die Trainingskosten entsprechend.
Hardware-UnterstützungNicht alle Hardware-Plattformen unterstützen Berechnungen mit geringer Genauigkeit vollständig. Beispielsweise erfordern FP8- und FP16-Berechnungen oft spezielle Hardware (z. B. NVIDIA-GPUs der Hopper-Architektur). Wenn die Hardwareplattform nicht für Berechnungen mit geringer Genauigkeit optimiert ist, können die Vorteile der Quantisierung nicht voll ausgeschöpft werden. Mit der Popularität des Low-Precision Computing beginnen immer mehr Hardwareplattformen, Low-Precision-Datentypen wie FP16, BF16 und sogar FP8 zu unterstützen, was eine solidere Hardwaregrundlage für die breite Anwendung von Quantisierungsverfahren bietet.
Erhöhte Komplexität:: Der Quantifizierungsprozess selbst kann die Modellentwicklung komplexer machen. Zum Beispiel erfordert der Quantifizierungsprozess eine feinkörnige Berechnung von Skalierungsfaktoren und kann eine zusätzliche Kalibrierung und Feinabstimmung des Modells erfordern. Dies erhöht definitiv die Schwierigkeit der Modellentwicklung und -einführung. Um die Komplexität der Quantisierungsimplementierung zu verringern, sind in der Branche viele automatisierte Quantisierungswerkzeuge und -plattformen entstanden, wie NVIDIA TensorRT, Qualcomm AI Engine usw., die Entwicklern helfen, Modelle schnell und einfach zu quantisieren und auf Zielhardwareplattformen einzusetzen.
Anwendungsszenario:: Quantisierungsverfahren sind nicht für alle Anwendungsszenarien geeignet. Bei Aufgaben, die eine sehr hohe Präzision erfordern (z. B. wissenschaftliche Berechnungen, Finanzmodellierung usw.), kann die Quantisierung zu einem inakzeptablen Verlust an Präzision führen. Bei genauigkeitssensiblen Aufgaben kann eine gemischte Präzisionsquantisierungsstrategie ausprobiert werden, bei der unterschiedliche Quantisierungsgenauigkeiten auf verschiedene Schichten oder Parameter im Modell angewendet werden, z. B. FP32 oder FP16 für wichtige Schichten oder Parameter und INT8 oder niedriger für andere Schichten oder Parameter, um ein besseres Gleichgewicht zwischen Genauigkeit und Effizienz zu erreichen.
Zusammenfassend lässt sich sagen, dass Quantisierungsverfahren als Schlüsseltechnologie im Bereich des Deep Learning ein großes Potenzial zur Verbesserung der Recheneffizienz, zur Verringerung des Speicherbedarfs und des Stromverbrauchs aufweisen. Quantisierungstechniken haben jedoch auch Einschränkungen, wie z. B. Genauigkeitsverluste und Hardware-Abhängigkeit. Daher sollten Quantisierungsstrategien in praktischen Anwendungen sorgfältig nach den spezifischen Anwendungsanforderungen und Szenariomerkmalen ausgewählt werden, um ein optimales Gleichgewicht zwischen Modellleistung und Effizienz zu erreichen. Mit der kontinuierlichen Entwicklung von Hardware und Algorithmen wird die quantitative Technologie in Zukunft eine wichtigere Rolle im Bereich des Deep Learning spielen und die Anwendung von künstlicher Intelligenz in einem breiteren Spektrum von Szenarien fördern.
© urheberrechtliche Erklärung
Artikel Copyright AI-Austauschkreis Alle, bitte nicht ohne Erlaubnis vervielfältigen.
Ähnliche Artikel



Keine Kommentare...