MiniMax-M1 - Open-Source-Inferenzmodell von MiniMax
Was ist MiniMax-M1
MiniMax-M1 ist ein Open-Source-Inferenzmodell des MiniMax-Teams, das auf einer Kombination aus der Mixed Expert Architecture (MoE) und dem Lightning Attention-Mechanismus mit insgesamt 456 Milliarden Parametern basiert. Das Modell unterstützt 1 Million Token MiniMax-M1 hat eine lange Kontexteingabe und eine Ausgabe von 80.000 Token, wodurch es sich für lange Dokumente und komplexe Schlussfolgerungen eignet. Das Modell ist in Versionen mit 40.000 und 80.000 Token verfügbar, um die Rechenressourcen zu optimieren und die Kosten für die Argumentation zu senken. miniMax-M1 übertrifft mehrere Open-Source-Modelle bei Aufgaben wie Software-Engineering, Verstehen von langem Kontext und Tool-Nutzung. Die effiziente Rechenleistung und die robusten Argumentationsfähigkeiten des Modells machen es zu einer leistungsstarken Grundlage für die nächste Generation von Sprachmodellierungsagenten.

Hauptmerkmale von MiniMax-M1
- lange KontextverarbeitungEs unterstützt Eingaben von bis zu 1 Million Token und Ausgaben von 80.000 Token und kann lange Dokumente, lange Berichte, akademische Abhandlungen und andere lange Textinhalte effizient verarbeiten, was sich für komplexe Schlussfolgerungsaufgaben eignet.
- Effizientes ReasoningBietet zwei Inferenzbudget-Versionen, 40K und 80K, um die Zuweisung von Rechenressourcen zu optimieren, die Inferenzkosten zu senken und eine hohe Leistung beizubehalten.
- Multidisziplinäre Aufgabenoptimierung: Sie zeichnen sich durch Aufgaben wie mathematisches Denken, Softwareentwicklung, langes kontextuelles Verständnis und die Verwendung von Werkzeugen aus.
- FunktionsaufrufUnterstützt strukturierte Funktionsaufrufe, kann Parameter für externe Funktionsaufrufe identifizieren und ausgeben, kann leicht mit externen Tools interagieren, um die Automatisierung und Arbeitseffizienz zu verbessern.
MiniMax-M1 Leistung
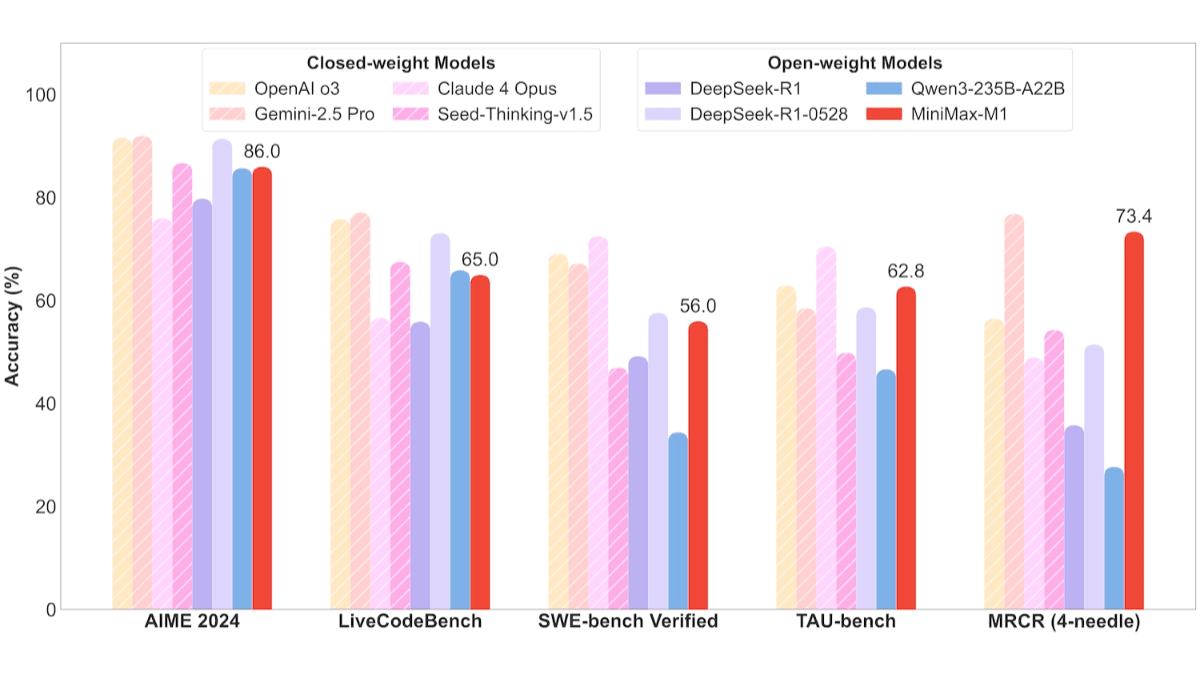
- Aufgaben der SoftwareentwicklungIm SWE-Bench-Benchmark erreichten MiniMax-M1-40k und MiniMax-M1-80k 55,61 TP3T bzw. 56,01 TP3T, was leicht unter den 57,61 TP3T von DeepSeek-R1-0528 liegt und andere Open-Source-Modelle deutlich übertrifft.
- Lange kontextbezogene VerstehensaufgabenMiniMax-M1 stützt sich auf Millionen von Kontextfenstern und übertrifft alle Open-Source-Modelle in allen Bereichen, sogar OpenAI o3 und Claude 4 Opus, und belegt weltweit den zweiten Platz hinter Gemini 2.5 Pro.
- Einsatzszenarien für WerkzeugeIm TAU-Bench-Test führte MiniMax-M1-40k alle Open-Source-Modelle an und schlug Gemini-2.5 Pro.
Die offizielle Website-Adresse von MiniMax-M1
- GitHub-Repository::https://github.com/MiniMax-AI/MiniMax-M1
- HuggingFace-Modellbibliothek::https://huggingface.co/collections/MiniMaxAI/minimax-m1
- Technische Papiere::https://github.com/MiniMax-AI/MiniMax-M1/blob/main/MiniMax_M1_tech_report.pdf
So verwenden Sie MiniMax-M1
- API-Aufrufe::
- Besuchen Sie die offizielle Website: MiniMax besuchen Offizielle Website, registrieren Sie sich und melden Sie sich bei Ihrem Konto an.
- Abrufen des API-SchlüsselsBeantragen Sie einen API-Schlüssel im Personal Centre oder auf der Entwicklerseite.
- Verwendung der APIAufrufen des Modells auf der Grundlage von HTTP-Anfragen, gemäß der offiziellen API-Dokumentation. Senden Sie zum Beispiel eine Anfrage mit der Python-Request-Bibliothek:
import requests
url = "https://api.minimax.cn/v1/chat/completions"
headers = {
"Authorization": "Bearer YOUR_API_KEY",
"Content-Type": "application/json"
}
data = {
"model": "MiniMax-M1",
"messages": [
{"role": "user", "content": "请生成一段关于人工智能的介绍。"}
]
}
response = requests.post(url, headers=headers, json=data)
print(response.json())- Gesicht umarmen Verwendung::
- Installieren der Hugging Face LibrarySicherstellen, dass Abhängigkeiten wie Transformatoren und Torch installiert sind.
pip install transformers torch- Modelle ladenLaden Sie ein MiniMax-M1-Modell aus dem Hugging Face Hub.
from transformers import AutoModelForCausalLM, AutoTokenizer
model_name = "MiniMaxAI/MiniMax-M1"
tokenizer = AutoTokenizer.from_pretrained(model_name)
model = AutoModelForCausalLM.from_pretrained(model_name)
input_text = "请生成一段关于人工智能的介绍。"
inputs = tokenizer(input_text, return_tensors="pt")
output = model.generate(**inputs, max_length=100)
print(tokenizer.decode(output[0], skip_special_tokens=True))- Verwendung auf MiniMax APP oder Web::
- Zugang zum WebLoggen Sie sich auf der MiniMax-Website ein, geben Sie eine Frage oder Aufgabe auf der Seite ein, und das Modell generiert direkt die Antwort.
- APP HERUNTERLADENLaden Sie die MiniMax APP auf Ihr Mobiltelefon und interagieren Sie mit ihr durch ähnliche Vorgänge.
Produktpreisliste für MiniMax-M1
- Kosten für API-Aufrufe::
- 0-32k Eingangslänge::
- Inputkosten: 0,8 $/Million Token.
- Ausgabekosten8 $/Million Token.
- 32k-128k Eingangslänge::
- Inputkosten: 1,2 $/Million Token.
- Ausgabekosten$16 pro Million Token.
- 128k-1M Eingabe Länge::
- Inputkosten: 2,4 $/Million Token.
- Ausgabekosten$24 pro Million Token.
- 0-32k Eingangslänge::
- APP und Web::
- Kostenlose NutzungMiniMax APP und Web bieten einen unbegrenzten kostenlosen Zugang, der für allgemeine Benutzer und Benutzer mit nichttechnischem Hintergrund geeignet ist.
MiniMax-M1 Kernvorteile
- Fähigkeit zur Verarbeitung langer KontexteEs unterstützt Eingaben von bis zu 1 Million Token und Ausgaben von bis zu 80.000 Token, wodurch es sich für die Verarbeitung langer Dokumente und komplexer Schlussfolgerungen eignet.
- Effiziente InferenzleistungBietet zwei Inferenzbudgetversionen von 40K und 80K, kombiniert mit dem Blitzaufmerksamkeitsmechanismus, um die Rechenressourcen zu optimieren und die Inferenzkosten zu reduzieren.
- Multidisziplinäre Aufgabenoptimierung: Sie zeichnen sich durch Aufgaben wie Software-Engineering, Verständnis für lange Zusammenhänge, mathematisches Denken und den Einsatz von Werkzeugen aus und können sich an unterschiedliche Anwendungsszenarien anpassen.
- Fortschrittliche Technologie-ArchitekturBasierend auf einer hybriden Expertenarchitektur (MoE) und groß angelegtem Reinforcement Learning (RL) Training zur Verbesserung der Recheneffizienz und der Modellleistung.
- hohes Qualitäts-Preis-VerhältnisLeistung: Die Leistung kommt den führenden internationalen Modellen nahe und bietet gleichzeitig flexible Preisstrategien und kostenlosen Zugang zu APP und Web, um die Nutzungsbarriere zu senken.
Personen, für die MiniMax-M1 bestimmt ist
- EntwicklerSoftwareentwickler können effizient Code generieren, die Codestruktur optimieren, Programme debuggen oder automatisch eine Code-Dokumentation erstellen.
- Forscher und AkademikerBearbeitung langer wissenschaftlicher Arbeiten, Durchführung von Literaturübersichten oder komplexen Datenanalysen, Verwendung von Modellen zur schnellen Organisation von Ideen, Erstellung von Berichten und Zusammenfassung von Ergebnissen.
- Ersteller von InhaltenDiejenigen, die lange Inhalte erstellen müssen, verwenden den MiniMax-M1 unter anderem zur Ideenfindung, zum Schreiben von Story-Skizzen, zum Ausbessern von Text oder zur Erstellung von langen Romanen.
- Schülerinnen und Schüler: für die Bereitstellung klarer Lösungen und schriftlicher Unterstützung.
- GeschäftskundeUnternehmen integrieren sie in Automatisierungslösungen, wie z. B. intelligenten Kundenservice, Datenanalysetools oder Geschäftsprozessautomatisierung.
© urheberrechtliche Erklärung
Artikel Copyright AI-Austauschkreis Alle, bitte nicht ohne Erlaubnis vervielfältigen.
Ähnliche Artikel



Keine Kommentare...