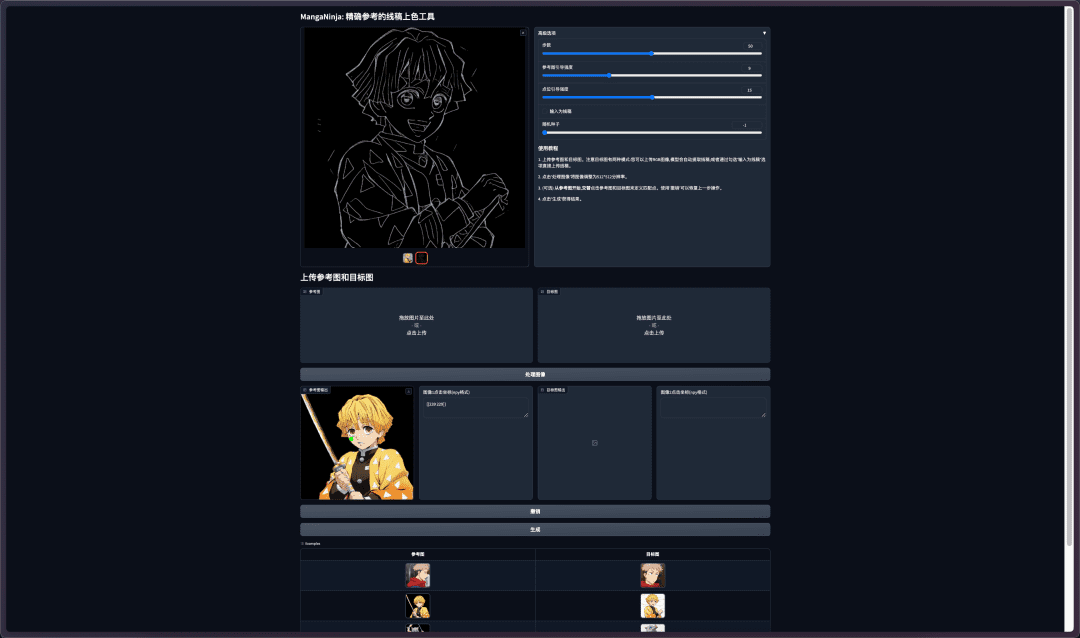
Ming-lite-omni - Vereinheitlichte multimodale Makromodelle - Open Source vom Ant 100 Team
Was ist Ming-lite-omni?
Ming-Lite-Omni ist ein quelloffenes, vereinheitlichtes multimodales Big Model des Bailing Big Model-Teams der Ant Group, das auf der hocheffizienten Mixture of Experts (MoE)-Architektur aufbaut. Ming-Lite-Omni unterstützt die Verarbeitung multimodaler Daten wie Text, Bild, Audio und Video und verfügt über leistungsstarke Verstehens- und Generierungsfunktionen. Ming-Lite-Omni ist auf Recheneffizienz optimiert, unterstützt die Verarbeitung großer Datenmengen und Echtzeit-Interaktion und ist hoch skalierbar. Ming-Lite-Omni ist hochgradig skalierbar und verfügt über eine breite Palette von Anwendungsszenarien, die den Benutzern eine integrierte intelligente Lösung mit einem breiten Anwendungsspektrum bieten.

Hauptmerkmale von Ming-lite-omni
- multimodale InteraktionUnterstützt mehrere Eingaben und Ausgaben wie Text, Bild, Audio, Video usw. für ein natürliches und reibungsloses Interaktionserlebnis. Unterstützt Mehrrunden-Dialoge für eine kohärente Interaktion.
- Verstehen und ErzeugenLeistungsstarke Verstehensfunktionen zum genauen Erkennen und Verstehen von Daten in verschiedenen Modalitäten. Effiziente Generierungsfunktionen, die die Generierung von hochwertigen Text-, Bild-, Audio- und Videoinhalten unterstützen.
- Effiziente VerarbeitungBasierend auf der MoE-Architektur optimiert es die Rechenleistung und unterstützt die Verarbeitung großer Datenmengen und die Interaktion in Echtzeit.
Offizielle Website-Adresse von Ming-lite-omni
- HuggingFace-Modellbibliothek::https://huggingface.co/inclusionAI/Ming-Lite-Omni
Wie man Ming-lite-omni verwendet
- Vorbereitung der Umwelt::
- Installation von PythonPython: Python 3.8 oder höher wird empfohlen. Downloaden und installieren Sie es von der Python-Website.
- Installation von abhängigen BibliothekenInstallieren Sie die erforderlichen Abhängigkeits-Bibliotheken, indem Sie die folgenden Befehle in einem Terminal oder auf der Kommandozeile ausführen.
pip install -r requirements.txt
pip install data/matcha_tts-0.0.5.1-cp38-cp38-linux_x86_64.whl
pip install diffusers==0.33.0
pip install nvidia-cublas-cu12==12.4.5.8 # 如果使用NVIDIA GPU- Modelle herunterladenLaden Sie das Modell Ming-Lite-Omni von Hugging Face herunter.
git clone https://huggingface.co/inclusionAI/Ming-Lite-Omni
cd Ming-Lite-Omni- Modelle laden: Verwenden Sie den folgenden Code, um das Modell und den Prozessor zu laden:
import os
import torch
from transformers import AutoProcessor, GenerationConfig
from modeling_bailingmm import BailingMMNativeForConditionalGeneration
# 设置模型路径
model_path = "Ming-Lite-Omni-Preview"
# 加载模型
model = BailingMMNativeForConditionalGeneration.from_pretrained(
model_path,
torch_dtype=torch.bfloat16,
low_cpu_mem_usage=True
).to("cuda")
# 加载处理器
processor = AutoProcessor.from_pretrained(model_path, trust_remote_code=True)- Vorbereiten der DateneingabeMing-Lite-Omni unterstützt eine Vielzahl von modalen Eingaben, z.B. Text- und Bildeingaben.
- Texteingabe::
messages = [
{
"role": "HUMAN",
"content": [
{"type": "text", "text": "请详细介绍鹦鹉的生活习性。"}
],
},
]- Bildeingabe::
messages = [
{
"role": "HUMAN",
"content": [
{"type": "image", "image": os.path.join("assets", "flowers.jpg")},
{"type": "text", "text": "What kind of flower is this?"}
],
},
]- Vorverarbeitung der DatenVorverarbeitung der Eingangsdaten mit Hilfe eines Prozessors:
text = processor.apply_chat_template(messages, add_generation_prompt=True)
image_inputs, video_inputs, audio_inputs = processor.process_vision_info(messages)
inputs = processor(
text=[text],
images=image_inputs,
videos=video_inputs,
audios=audio_inputs,
return_tensors="pt",
)
inputs = inputs.to(model.device)
for k in inputs.keys():
if k == "pixel_values" or k == "pixel_values_videos" or k == "audio_feats":
inputs[k] = inputs[k].to(dtype=torch.bfloat16)- modellhafte ArgumentationAufruf des Modells, um Schlussfolgerungen zu ziehen und die Ausgabe zu generieren:
generation_config = GenerationConfig.from_dict({'no_repeat_ngram_size': 10})
generated_ids = model.generate(
**inputs,
max_new_tokens=512,
use_cache=True,
eos_token_id=processor.gen_terminator,
generation_config=generation_config,
)
generated_ids_trimmed = [
out_ids[len(in_ids):] for in_ids, out_ids in zip(inputs.input_ids, generated_ids)
]
output_text = processor.batch_decode(
generated_ids_trimmed, skip_special_tokens=True, clean_up_tokenization_spaces=False
)[0]
print(output_text)- AusgabeergebnisDas Modell erzeugt die entsprechenden Ausgaben, um die Ergebnisse je nach Bedarf weiter zu verarbeiten oder zu präsentieren.
Die wichtigsten Vorteile von Ming-Lite-Omni
- multimodale VerschmelzungUnterstützt multimodale Eingabe und Ausgabe von Text, Bildern, Audio und Video für eine vollständige multimodale Interaktion.
- Effiziente ArchitekturAuf der Grundlage der Mixture of Experts (MoE)-Architektur optimiert das dynamische Routing die Recheneffizienz und reduziert die Ressourcenverschwendung.
- Harmonisierung des Verständnisses und der ErzeugungDie Encoder-Decoder-Architektur unterstützt integriertes Verstehen und Generieren und bietet so eine kohärente interaktive Erfahrung.
- Optimierte ArgumentationDer hybride lineare Aufmerksamkeitsmechanismus reduziert die Rechenkomplexität, unterstützt die Interaktion in Echtzeit und ist für schnelle Reaktionsszenarien geeignet.
- weit verbreitetAnwendbar in einer Vielzahl von Bereichen wie intelligenter Kundenservice, Inhaltserstellung, Bildung, Gesundheitswesen und Smart Office.
- Open Source und Unterstützung durch die GemeinschaftOpen-Source-Modell mit einer Community, die Entwicklern eine Fülle von Ressourcen zur Verfügung stellt, um schnell einsatzbereit zu sein und Innovationen zu entwickeln.
Personen, für die Ming-Lite-Omni geeignet ist
- GeschäftskundeTechnologieunternehmen und Unternehmen, die Inhalte erstellen und effiziente multimodale Lösungen benötigen.
- Lehrkräfte und StudentenLehrer und Studenten, die KI zur Unterstützung ihres Lehrens und Lernens nutzen wollen.
- GesundheitspraktikerMitarbeiter des Gesundheitswesens, die Unterstützung bei der Analyse von Krankenakten und der Interpretation medizinischer Bilder benötigen.
- Intelligente BürobenutzerMitarbeiter und Management von Organisationen, die Dokumente verarbeiten und die Effizienz im Büro verbessern müssen.
- DurchschnittsverbraucherEinzelne Nutzer, die intelligente Geräte verwenden und kreative Inhalte erstellen müssen.
© urheberrechtliche Erklärung
Artikel Copyright AI-Austauschkreis Alle, bitte nicht ohne Erlaubnis vervielfältigen.
Ähnliche Artikel



Keine Kommentare...