MiDashengLM - Xiaomis Open-Source-Modell zum Verstehen von Geräuschen

Was ist MiDashengLM
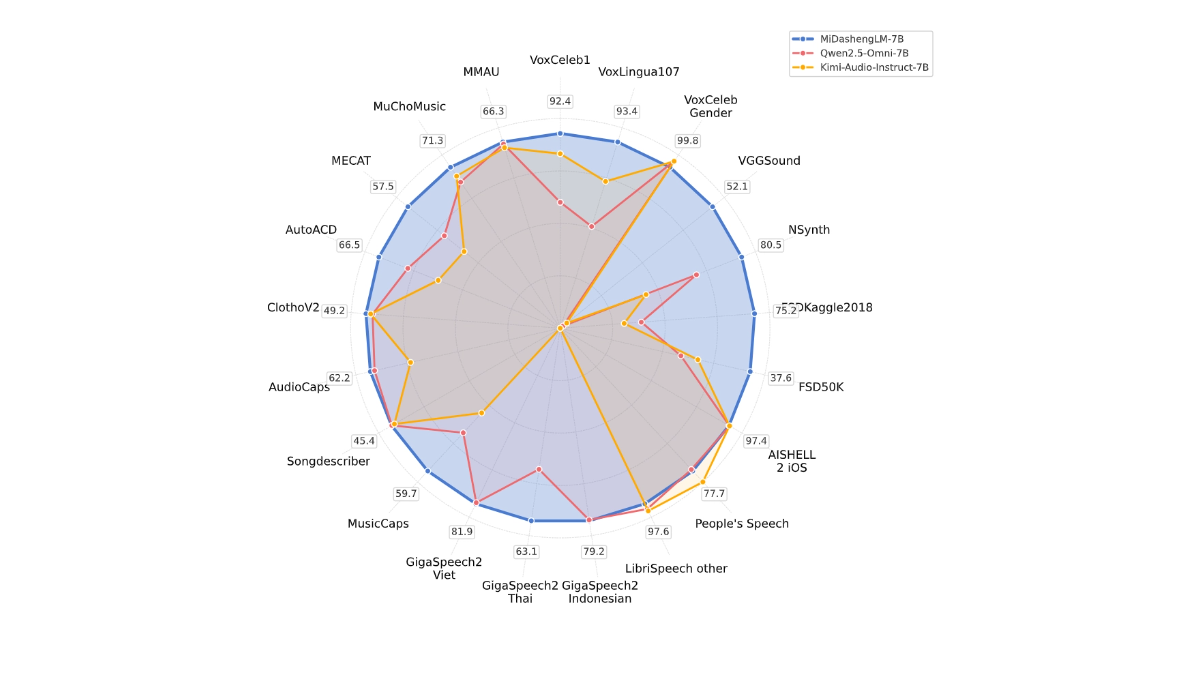
MiDashengLM ist Xiaomis großes Open-Source-Modell für effizientes Klangverständnis, mit der spezifischen Parameterversion MiDashengLM-7B, die sich auf Audioverarbeitung und -verständnis konzentriert. Das Modell basiert auf dem Xiaomi Dasheng Audio-Encoder und dem Qwen2.5-Omni-7B Thinker Decoder, der Sprach-, Umgebungsgeräusch- und Musikverständnis in sich vereint. Das Modell hat eine ausgezeichnete Inferenz-Effizienz, mit der ersten Token Die Trainingsdaten von MiDashengLM sind vollständig quelloffen und unterstützen sowohl die akademische als auch die kommerzielle Nutzung und bieten eine leistungsstarke Unterstützung zur Verbesserung der multimodalen Interaktionserfahrung.
Hauptmerkmale von MiDashengLM
- Audioinhalte in Text umwandelnDas Modell übersetzt verschiedene Arten von Audiodaten, wie z. B. gesprochene Stimmen, Naturgeräusche oder Musik, in Textbeschreibungen, die den Menschen helfen, schnell zu verstehen, was in den Audiodaten wirklich vor sich geht.
- Identifizieren von AudiokategorienDas Modell kann erkennen, ob es sich bei einem Audiomaterial um Sprache, Umgebungsgeräusche, Musik usw. handelt, ebenso wie es die Audiodaten kennzeichnen kann, um ihre Verwendung in verschiedenen Szenarien zu erleichtern.
- SpracherkennungKonvertiert das, was eine Person sagt, in Text, unterstützt mehrere Sprachen und eignet sich besonders für den Einsatz in Sprachassistenten oder intelligenten Geräten.
- Audio-Fragen und AntwortenBeantwortet Fragen auf der Grundlage von Audioinhalten, z. B. "Was war das für ein Geräusch?" im Auto, und das Modell kann antworten.
- multimodale InteraktionDie Fähigkeit, Audio- und andere Informationen (z. B. Text, Bilder) in Verbindung miteinander zu verstehen, was eine intelligentere und natürlichere Interaktion mit dem Gerät ermöglicht.
Offizielle Adresse der Website von MiDashengLM
- GitHub-Repository:: https://github.com/xiaomi-research/dasheng-lm
- HuggingFace-Modellbibliothek:: https://huggingface.co/mispeech/midashenglm-7b
- Technische Papiere:: https://github.com/xiaomi-research/dasheng-lm/blob/main/technical_report/MiDashengLM_techreport.pdf
- Online-Erlebnis-Demo:: https://huggingface.co/spaces/mispeech/MiDashengLM-7B
Wie man MiDashengLM verwendet
- Online-ErfahrungBesuchen Sie die Online-Demo von MiDashengLM.
- Hochladen von AudiodateienHochladen einer Audiodatei (unterstützte Formate: WAV, MP3, usw.).
- Warten auf die BearbeitungNach dem Hochladen der Audiodaten verarbeitet das Modell die Audiodaten automatisch und generiert die Ergebnisse.
- Ergebnisse anzeigenNach Abschluss der Verarbeitung können Sie die vom Modell generierten Beschreibungs- oder Klassifizierungsergebnisse anzeigen.
Die Stärken von MiDashengLM
- Effiziente InferenzleistungDie Inferenz-Effizienz von MiDashengLM ist extrem hoch, die Latenzzeit für das erste Token ist sehr niedrig und der Durchsatz ist stark verbessert, was für Echtzeit-Interaktionsszenarien geeignet ist.
- Leistungsstarkes Hörverstehen: ermöglicht ein einheitliches Verständnis eines breiten Spektrums von Audiodaten, einschließlich Sprache, Umgebungsgeräuschen und Musik, und vermeidet die Einschränkungen herkömmlicher Methoden.
- Daten und Modelle Open SourceDie Trainingsdaten und -modelle sind vollständig quelloffen, was die Forschung und Sekundärentwicklung durch Entwickler erleichtert und sowohl die akademische als auch die kommerzielle Nutzung unterstützt.
- Breite Palette von AnwendungsszenarienAnwendung in einer Vielzahl von Bereichen wie Smart Cockpit, Smart Home, Sprachassistent, Erstellung von Audioinhalten sowie Bildung und Lernen.
- Optimierung der TechnologieMiDashengLM basiert auf einem optimierten Audio-Encoder- und Decoder-Design und zeichnet sich durch die Bewältigung komplexer Audioaufgaben bei gleichzeitiger Reduzierung der Rechenlast aus.
- AusbildungsstrategienEine Trainingsstrategie, die auf einem generischen Audio-Beschreibungsabgleich und einer Multi-Experten-Analyse basiert, stellt sicher, dass das Modell die tiefen semantischen Assoziationen von Audio lernt und die Generalisierung verbessert.
Personen, für die MiDashengLM bestimmt ist
- Forscher im Bereich der künstlichen IntelligenzDas Modell stellt Forschern Open-Source-Modelle für das Hörverstehen und Trainingsdaten zur Verfügung, um Forschung und Innovation in verwandten Bereichen zu erleichtern.
- Entwickler von intelligenten GerätenFür Teams, die Produkte wie intelligente Cockpits, intelligente Häuser, Sprachassistenten usw. entwickeln, wird das Modell schnell in das Produkt integriert, um das Interaktionserlebnis zu verbessern.
- Ersteller von Audio-InhaltenAudioproduzenten verwenden Modelle zur automatischen Erstellung von Audiobeschreibungen und -etiketten, um die Effizienz der Inhaltserstellung zu verbessern.
- Lehrende und Lernende: im Bereich des Sprachenlernens und des Musikunterrichts, indem sie den Lernenden mit Aussprache-Feedback und theoretischer Anleitung hilft, sich Wissen anzueignen.
- GeschäftskundeEine effiziente Lösung für Unternehmen, die Audioverstehensfunktionen für die kommerzielle Nutzung benötigen, die für die Produktentwicklung und Serviceoptimierung genutzt werden können.
© urheberrechtliche Erklärung
Artikel Copyright AI-Austauschkreis Alle, bitte nicht ohne Erlaubnis vervielfältigen.
Ähnliche Artikel

Keine Kommentare...