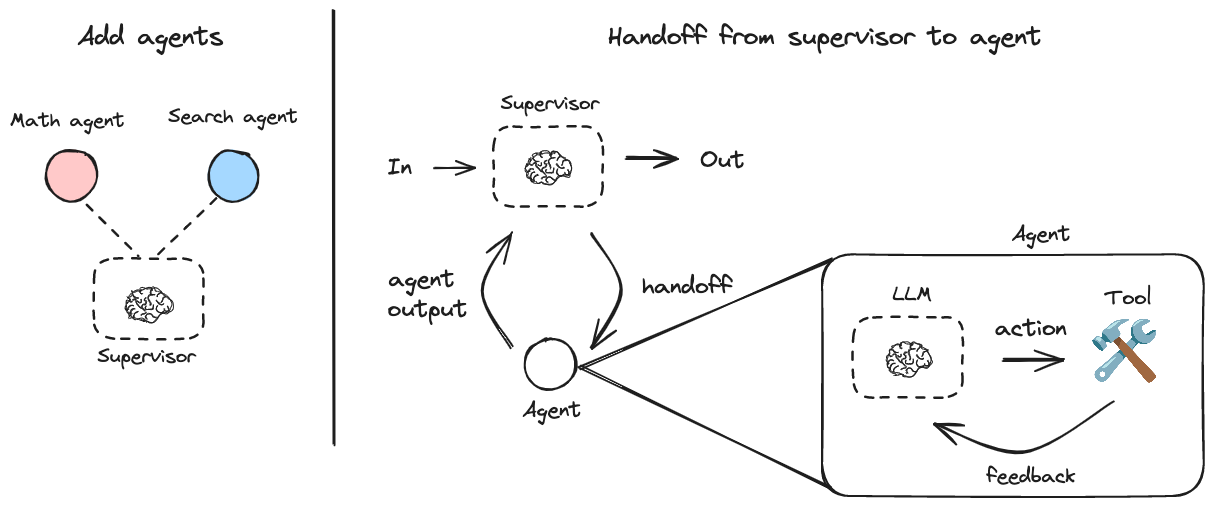
LocalAI: quelloffene Lösungen für den Einsatz von lokaler KI, Unterstützung für mehrere Modellarchitekturen, einheitliche WebUI-Verwaltung von Modellen und APIs

Allgemeine Einführung
LocalAI ist eine quelloffene lokale KI-Alternative, die darauf abzielt, API-Schnittstellen bereitzustellen, die mit OpenAI, Claude und anderen kompatibel sind. LocalAI wurde von Ettore Di Giacinto entwickelt und wird von ihm gepflegt. Es unterstützt eine Vielzahl von Modellarchitekturen, darunter gguf, Transformatoren, Diffusoren und mehr für lokale oder lokale Implementierungen.

Funktionsliste
- Texterstellung: Unterstützt die GPT-Modellreihe, die in der Lage ist, hochwertige Textinhalte zu erzeugen.
- Audiogenerierung: Erzeugen Sie eine natürliche und weiche Stimme durch die Text-zu-Audio-Funktion.
- Bilderzeugung: Mit Hilfe eines stabilen Diffusionsmodells werden qualitativ hochwertige Bilder erzeugt.
- Sprachklonen: Erzeugen von Sprache, die der Originalstimme ähnlich ist, durch die Technologie des Sprachklonens.
- Verteiltes Reasoning: unterstützt P2P-Reasoning, um die Effizienz der Modellbildung zu verbessern.
- Modell-Download: Laden Sie Modelle direkt von Plattformen wie Huggingface herunter und führen Sie sie aus.
- Integrierte WebUI: Bietet eine integrierte Web-Benutzeroberfläche für eine benutzerfreundliche Bedienung.
- Erzeugung von Vektordatenbankeinbettungen: Unterstützung der Erzeugung von Vektordatenbankeinbettungen.
- Constrained Syntax: Unterstützung für die Generierung von Textinhalten mit eingeschränkter Syntax.
- Vision API: Bietet Funktionen zur Bildverarbeitung und -analyse.
- Reordering API: unterstützt die Neuordnung und Optimierung von Textinhalten.
Einbauverfahren
- Verwendung von Installationsskripten::
- Führen Sie den folgenden Befehl aus, um LocalAI herunterzuladen und zu installieren:
curl -s https://localai.io/install.sh | sh
- Führen Sie den folgenden Befehl aus, um LocalAI herunterzuladen und zu installieren:
- Docker verwenden::
- Wenn keine GPU vorhanden ist, führen Sie den folgenden Befehl aus, um LocalAI zu starten:
docker run -ti --name local-ai -p 8080:8080 localai/localai:latest-aio-cpu - Wenn Sie einen Nvidia-Grafikprozessor haben, führen Sie den folgenden Befehl aus:
docker run -ti --name local-ai -p 8080:8080 --gpus all localai/localai:latest-aio-gpu-nvidia-cuda-12
- Wenn keine GPU vorhanden ist, führen Sie den folgenden Befehl aus, um LocalAI zu starten:
Verwendungsprozess
- LocalAI starten::
- Nachdem Sie LocalAI durch den oben beschriebenen Installationsprozess gestartet haben, rufen Sie die
http://localhost:8080Rufen Sie die WebUI auf.
- Nachdem Sie LocalAI durch den oben beschriebenen Installationsprozess gestartet haben, rufen Sie die
- Modelle laden::
- Navigieren Sie in der WebUI zur Registerkarte Modelle, wählen Sie das gewünschte Modell aus und laden Sie es.
- Alternativ können Sie das Modell auch über die Befehlszeile laden, zum Beispiel:
local-ai run llama-3.2-1b-instruct:q4_k_m
- Inhalte generieren::
- Wählen Sie in der WebUI den entsprechenden Funktionsbaustein (z.B. Textgenerierung, Bildgenerierung, etc.), geben Sie die gewünschten Parameter ein und klicken Sie auf die Schaltfläche Generieren.
- Um zum Beispiel einen Text zu erstellen, geben Sie die Eingabeaufforderung ein, wählen das Modell aus und klicken auf die Schaltfläche "Text erstellen".
- verteilte Schlussfolgerung::
- Konfigurieren Sie mehrere LocalAI-Instanzen, um eine verteilte P2P-Inferenz zu erreichen und die Effizienz der Inferenz zu verbessern.
- Siehe den Distributed Inference Configuration Guide in der offiziellen Dokumentation.
Erweiterte Funktionen
- Kundenspezifische Modelle::
- Benutzer können benutzerdefinierte Modelle von Huggingface oder dem OCI-Register herunterladen und laden, um spezifische Anforderungen zu erfüllen.
- API-Einbindung::
- LocalAI bietet eine REST-API, die mit der OpenAI-API kompatibel ist, damit Entwickler sie einfach in bestehende Anwendungen integrieren können.
- Detaillierte Informationen zur Verwendung der API finden Sie in der offiziellen API-Dokumentation.
© urheberrechtliche Erklärung
Artikel Copyright AI-Austauschkreis Alle, bitte nicht ohne Erlaubnis vervielfältigen.
Ähnliche Artikel



Keine Kommentare...