Llasa 1~8B: ein quelloffenes Text-zu-Sprache-Modell für hochwertige Spracherzeugung und Klonen

Allgemeine Einführung
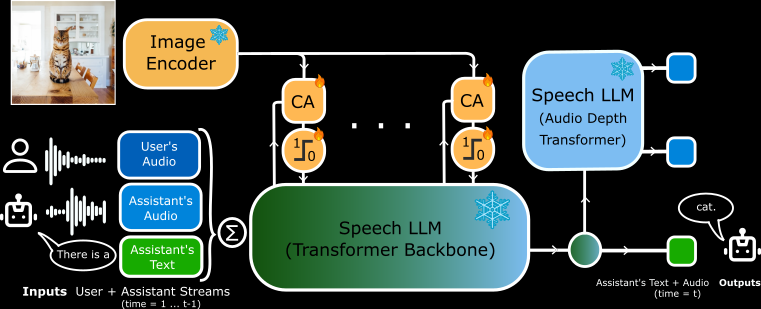
Llasa-3B ist ein quelloffenes Text-to-Speech-Modell (TTS), das vom Audio Lab der Hong Kong University of Science and Technology (HKUST Audio) entwickelt wurde. Das Modell basiert auf der Llama 3.2B-Architektur, die sorgfältig abgestimmt wurde, um eine qualitativ hochwertige Spracherzeugung zu ermöglichen, die nicht nur mehrere Sprachen unterstützt, sondern auch emotionalen Ausdruck und personalisiertes Klonen von Sprache ermöglicht.Llasa-3B hat die Aufmerksamkeit vieler Forscher und Entwickler wegen seiner Ausdruckskraft und Flexibilität bei der natürlichen Sprachsynthese auf sich gezogen.

Erfahrung: https://huggingface.co/spaces/srinivasbilla/llasa-3b-tts
Funktionsliste
- Text-to-SpeechKonvertiert Text in natürlichen, weichen Klang.
- SprachklonenNur 15 Sekunden Audiomaterial werden benötigt, um eine bestimmte menschliche Stimme zu klonen, einschließlich Timbre und Emotion.
- Unterstützung mehrerer SprachenChinesisch und Englisch werden unterstützt, wobei eine Ausweitung auf weitere Sprachen angestrebt wird.
- affektiver AusdruckDie Fähigkeit, Emotionen in die generierte Sprache einzubringen, erhöht die Authentizität der Sprache.
- Unterstützung mehrerer Modelle1B- und 3B-Modelle im parametrischen Maßstab verfügbar, 8B-Modelle sollen in Zukunft eingeführt werden
- offene GewichtungAlle Modelle sind mit offenen Gewichten versehen, die direkt verwendet oder von den Entwicklern zweimal feinabgestimmt werden können, und unterstützen Transformers und vLLM Rahmen.
Hilfe verwenden
Installation und Vorbereitung der Umgebung
Um das Modell Llasa-3B zu verwenden, müssen Sie zunächst die folgende Umgebung vorbereiten:
Python-UmgebungPython 3.9 oder höher wird empfohlen.
Verwandte Bibliotheken: Erfordert die Installation vontorch, transformers, xcodec2usw. Bibliothek.
conda create -n xcodec2 python=3.9
conda activate xcodec2
pip install transformers torch xcodec2==0.1.3
Herunterladen und Laden von Modellen
Besuchen Sie Hugging Face aufLlasa-3B-SeiteSie können die Modell-Download-Funktion von Hugging Face direkt nutzen:
from transformers import AutoTokenizer, AutoModelForCausalLM
import torch
import soundfile as sf
llasa_3b = 'HKUST-Audio/Llasa-3B'
tokenizer = AutoTokenizer.from_pretrained(llasa_3b)
model = AutoModelForCausalLM.from_pretrained(llasa_3b)
model.eval()
model.to('cuda') # 如果有GPU
Text-to-Speech-Verfahren
- Vorbereiteter Text::
- Geben Sie den Text ein, den Sie in Sprache umwandeln möchten.
- Vorverarbeitung von Text::
- Verwenden Sie z. B. einen bestimmten formatierten Text, um das Modell für die Spracherzeugung anzuleiten:
input_text = "这是一个测试文本,请转成语音。" formatted_text = f"<|TEXT_UNDERSTANDING_START|>{input_text}<|TEXT_UNDERSTANDING_END|>"
- Verwenden Sie z. B. einen bestimmten formatierten Text, um das Modell für die Spracherzeugung anzuleiten:
- Sprache generieren::
- Wandeln Sie den Text in ein Token um, das das Modell verstehen kann:
chat = [ {"role": "user", "content": "Convert the text to speech:" + formatted_text}, {"role": "assistant", "content": "<|SPEECH_GENERATION_START|>"} ] input_ids = tokenizer.apply_chat_template(chat, tokenize=True, return_tensors='pt', continue_final_message=True) input_ids = input_ids.to('cuda') - Erzeugen Sie ein Sprach-Token:
speech_end_id = tokenizer.convert_tokens_to_ids('<|SPEECH_GENERATION_END|>') outputs = model.generate(input_ids, max_length=2048, eos_token_id=speech_end_id, do_sample=True, top_p=1, temperature=0.8)
- Wandeln Sie den Text in ein Token um, das das Modell verstehen kann:
- Sprachdecodierung::
- Konvertiert das generierte Token zurück in Audio:
from xcodec2.modeling_xcodec2 import XCodec2Model model_path = "HKUST-Audio/xcodec2" Codec_model = XCodec2Model.from_pretrained(model_path).eval().cuda() generated_ids = outputs[0][input_ids.shape[1]:-1] speech_tokens = tokenizer.batch_decode(generated_ids, skip_special_tokens=True) speech_ids = [int(token[4:-2]) for token in speech_tokens if token.startswith('<|s_') and token.endswith('|>')] speech_tokens_tensor = torch.tensor(speech_ids).cuda().unsqueeze(0).unsqueeze(0) gen_wav = Codec_model.decode_code(speech_tokens_tensor) sf.write("output.wav", gen_wav[0, 0, :].cpu().numpy(), 16000)
- Konvertiert das generierte Token zurück in Audio:
Sprachklonen
- Nehmen Sie etwa 15 Sekunden der Originaltonspur auf oder bereiten Sie sie vor.::
- Verwenden Sie ein Aufnahmegerät oder stellen Sie eine vorhandene Audiodatei zur Verfügung.
- phonetischer Klonierungsprozess::
- Kodierung der ursprünglichen Tonfrequenzen in ein Codebuch, das das Modell verwenden kann:
prompt_wav = sf.read("your_source_audio.wav")[0] # 必须是16kHz采样率 vq_code_prompt = Codec_model.encode_code(torch.from_numpy(prompt_wav).unsqueeze(0).unsqueeze(0).cuda()) - Ergänzen Sie den Textgenerierungsprozess um Audiohinweise:
speech_ids_prefix = [f"<|s_{id}|>"foridin vq_code_prompt[0, 0, :].tolist()] chat = [ {"role": "user", "content": "Convert the text to speech:" + formatted_text}, {"role": "assistant", "content": "<|SPEECH_GENERATION_START|>" + ''.join(speech_ids_prefix)} ] # 后续步骤与文本转语音相同
- Kodierung der ursprünglichen Tonfrequenzen in ein Codebuch, das das Modell verwenden kann:
caveat
- Vergewissern Sie sich, dass das Audio-Eingangsformat korrekt ist. Der Llasa-3B unterstützt nur 16kHz-Audio.
- Die Leistung des Modells hängt direkt von der Qualität des eingegebenen Textes und Tons ab, wodurch die Qualität der Eingabe gewährleistet wird.
© urheberrechtliche Erklärung
Artikel Copyright AI-Austauschkreis Alle, bitte nicht ohne Erlaubnis vervielfältigen.
Ähnliche Artikel


Keine Kommentare...