
OCR-Aufforderung zum Extrahieren von Bildtext mithilfe visueller Modelle

Bei komplexen Textstrukturen oder gemischtem Textinhalt ist es sinnvoll, den Inhalt mit Hilfe der OCR-Funktion des visuellen Modells zu extrahieren.
Multimodale Makromodelle oder spezialisierte visuelle Modelle können den Inhalt des Bildes verstehen und Anweisungen erhalten, um die Erkennungsaufgabe zu erfüllen, und wir werden diese Fähigkeit nutzen, um die Ausgabe an unsere Anforderungen anzupassen.
Es wird empfohlen, OCR Prompt mit dem folgenden Tool zu testen: ChatGPT , Kimi und Qwen2-VL(Derzeit die genaueste)
Testbild:
Die Komplexität dieses Bildes liegt in dem verdeckten json-Teil, der von verschiedenen großen Modellen auf unterschiedliche Weise verstanden wird
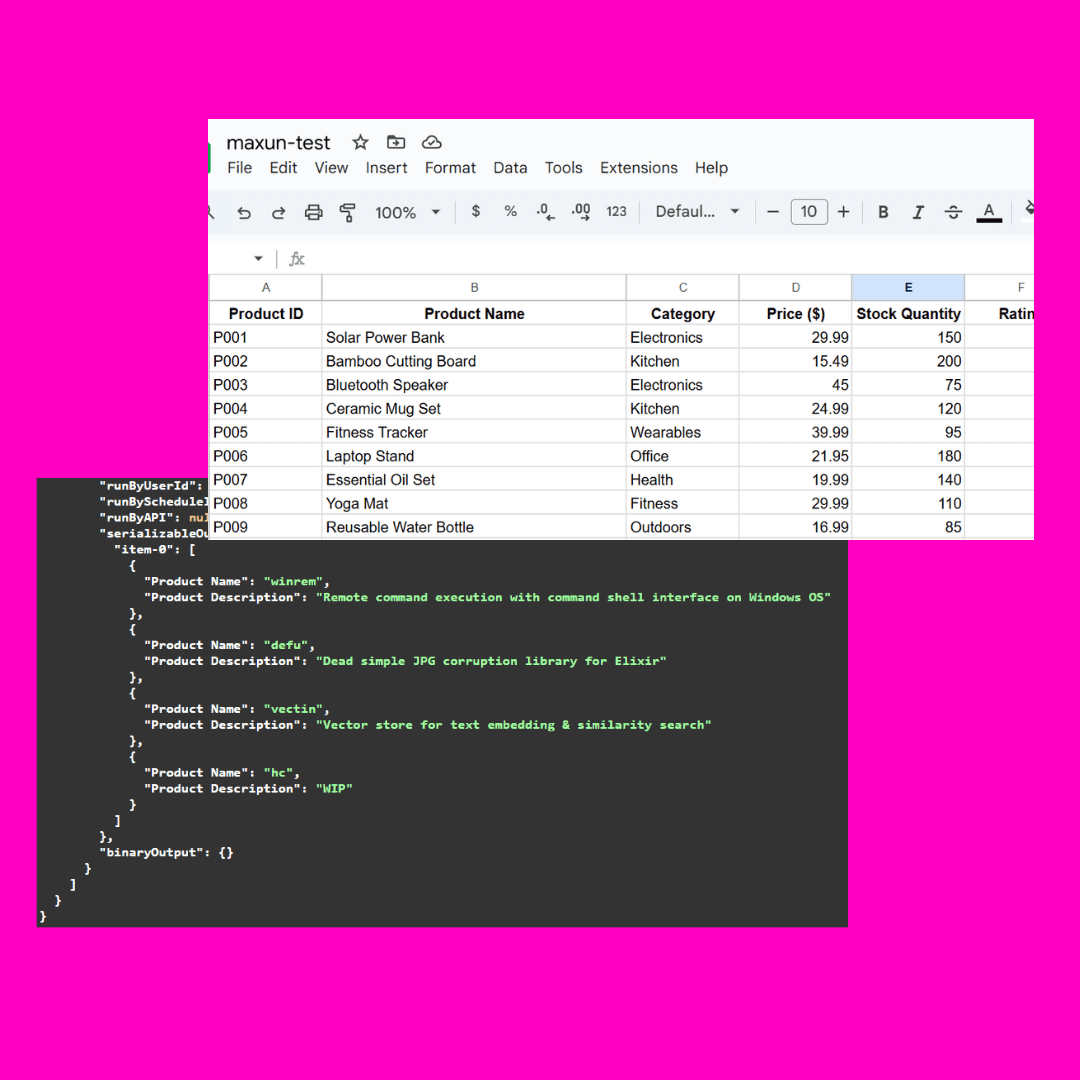
Einfache Befehle sind in der Regel ausreichend:
按照原文格式提取
Es wird nur ein Teil des Inhalts extrahiert:
仅提取图片中的表格部分
Extrahiert und in ein festes Textformat umgeschrieben:
识别图片后整理为MARKDOWN格式表格,请保持表格原始顺序、格式和语言
Strukturierte Extraktion:
您的任务是将文件内容转录并格式化为 markdown。您的目标是创建一个结构良好、可读性强的 markdown 文档,该文档准确表示原始内容,同时添加适当的格式和标签。 请按照以下说明完成任务: 1. 仔细阅读整个文件内容。 2. 将内容转录为 markdown 格式,密切关注现有的格式和结构。 3. 如果您在原始内容中发现任何不清楚的格式,请自行判断添加适当的 markdown 格式以提高可读性和结构。 4. 对于表格、标题和目录,请添加以下标签: - 表格:将整个表格括在 [TABLE] 和 [/TABLE] 标签中。如果表格内容在下一页继续,请合并表格内容。 - 标题(在每页开头重复的完整字符串):括在 markdown 文件内的 [HEADER] 和 [/HEADER] 标签中。 - 目录:用 [TOC] 和 [/TOC] 标签括起来 5. 转录表格时: - 如果表格跨越多页,请将内容合并为一个连贯的表格。 - 使用适当的 markdown 表格格式,表格结构使用竖线 (|) 和连字符 (-)。 6. 不要在转录中包含分页符。 7. 保持文档的逻辑流程和结构,确保使用 markdown 标题正确格式化章节和小节(# 表示主标题,## 表示副标题等)。 8. 根据需要对其他格式元素(如粗体、斜体、列表和代码块)使用适当的 markdown 语法。 10. 仅返回 markdown 格式的解析内容,包括表格、标题和目录的指定标签。
Extrahieren und übersetzen:
Der Übersetzungsbefehl, den ich am häufigsten verwende, kommt hier zum Einsatz. Er eignet sich auch hervorragend für OCR, um komplex strukturierten Text zu extrahieren:Übersetzung der "englischen Anleitungsvorlage" in "chinesische Anweisungen" unter Beibehaltung der ursprünglichen Formatierung
© urheberrechtliche Erklärung
Artikel Copyright AI-Austauschkreis Alle, bitte nicht ohne Erlaubnis vervielfältigen.
Ähnliche Artikel




Keine Kommentare...