
Late Chunking x Milvus: Wie man die RAG-Genauigkeit verbessert

01.Kontexte
Bei der Entwicklung von RAG-Anwendungen ist der erste Schritt das Chunking des Dokuments. Ein effizientes Chunking des Dokuments kann die Genauigkeit des nachfolgenden Recall-Inhalts effektiv verbessern. Wie man effizient Chunking ist ein heißes Thema der Diskussion, gibt es wie feste Größe Chunking, zufällige Größe Chunking, Sliding-Window-Resampling, rekursive Chunking, basierend auf dem Inhalt der semantischen Chunking und andere Methoden. Das von Jina AI vorgeschlagene Late Chunking befasst sich mit dem Chunking-Problem aus einer anderen Perspektive, schauen wir es uns an.
02.Was ist Late Chunking?
Bei der Verarbeitung langer Dokumente kann es vorkommen, dass beim herkömmlichen Chunking über weite Entfernungen hinweg kontextuelle Abhängigkeiten in den Dokumenten verloren gehen, was eine große Gefahr für das Abrufen und Verstehen von Informationen darstellt. Das heißt, wenn die Schlüsselinformationen in mehreren Textblöcken verstreut sind, verliert das aus dem Kontext gerissene Textfragment wahrscheinlich seine ursprüngliche Bedeutung, was zu einem schlechteren späteren Abruf führt.
Nehmen wir zum Beispiel die Milvus 2.4.13 Release Note, die wie folgt in zwei Dokumentenblöcke unterteilt ist, und wir wollen dieMilvus 2.4.13有哪些新功能?Der direkt relevante Inhalt befindet sich in Chunk 2, während die Milvus-Versionsinformationen in Chunk 1 sind. An diesem Punkt ist es für das Einbettungsmodell schwierig, diese Referenzen korrekt mit den Entitäten zu verknüpfen, was zu einer schlechten Qualität der Einbettung führt.
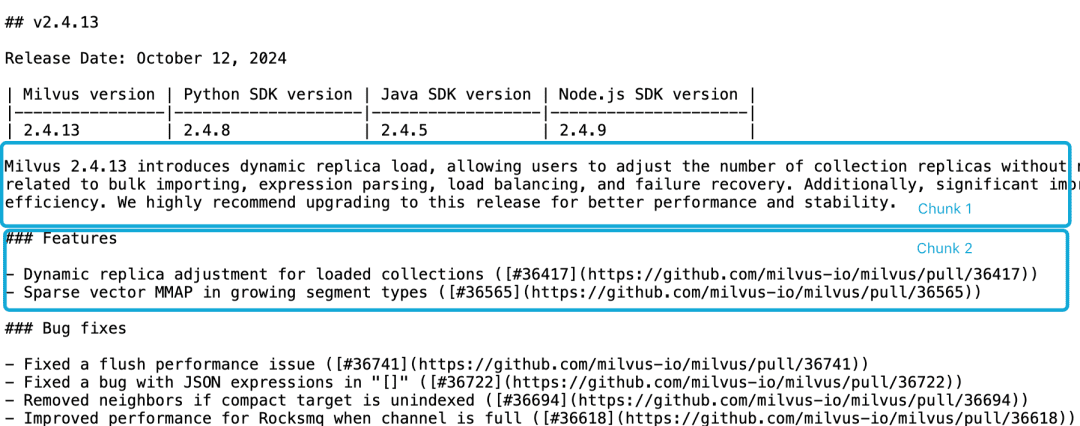
LLM hat Schwierigkeiten, ein solches Korrelationsproblem zu lösen, da sich die Funktionsbeschreibung nicht im selben Chunk wie die Versionsinformationen befindet und ein größeres Kontextdokument fehlt. Es gibt zwar eine Reihe von Heuristiken, die versuchen, dieses Problem zu lösen, wie z. B. die Neuabtastung mit gleitenden Fenstern, sich überschneidende Kontextfensterlängen und das Scannen mehrerer Dokumente, aber wie alle Heuristiken sind auch diese Methoden unzuverlässig; sie können in einigen Fällen funktionieren, aber es gibt keine theoretischen Garantien.
Beim traditionellen Chunking wird eine Pre-Chunking-Strategie angewandt, d. h. der Text wird zuerst gechunked und durchläuft dann das Embedding-Modell. Der Text wird zunächst anhand von Parametern wie Satz-, Absatz- oder voreingestellter Maximallänge geschnitten. Das Embedding-Modell verarbeitet diese Chunks dann einen nach dem anderen mit Hilfe von Methoden wie dem Durchschnitts-Pooling, dem Token Beim Late Chunking wird zuerst das Embedding-Modell durchlaufen und dann gechunked (das ist die Bedeutung von late). Late Chunking hingegen bedeutet, das Embedding-Modell vor dem Chunking zu durchlaufen (hier kommt die Bedeutung von late ins Spiel, erst Vektorisierung und dann Chunking), wir nehmen zuerst die Transformator Die Schicht wird auf den gesamten Text angewandt und erzeugt für jedes Token eine Sequenz von Vektordarstellungen, die umfangreiche Kontextinformationen enthalten. Anschließend werden diese Token-Vektorsequenzen gleichmäßig gepoolt, um die endgültige Blockeinbettung zu erhalten, die den gesamten Textkontext berücksichtigt.
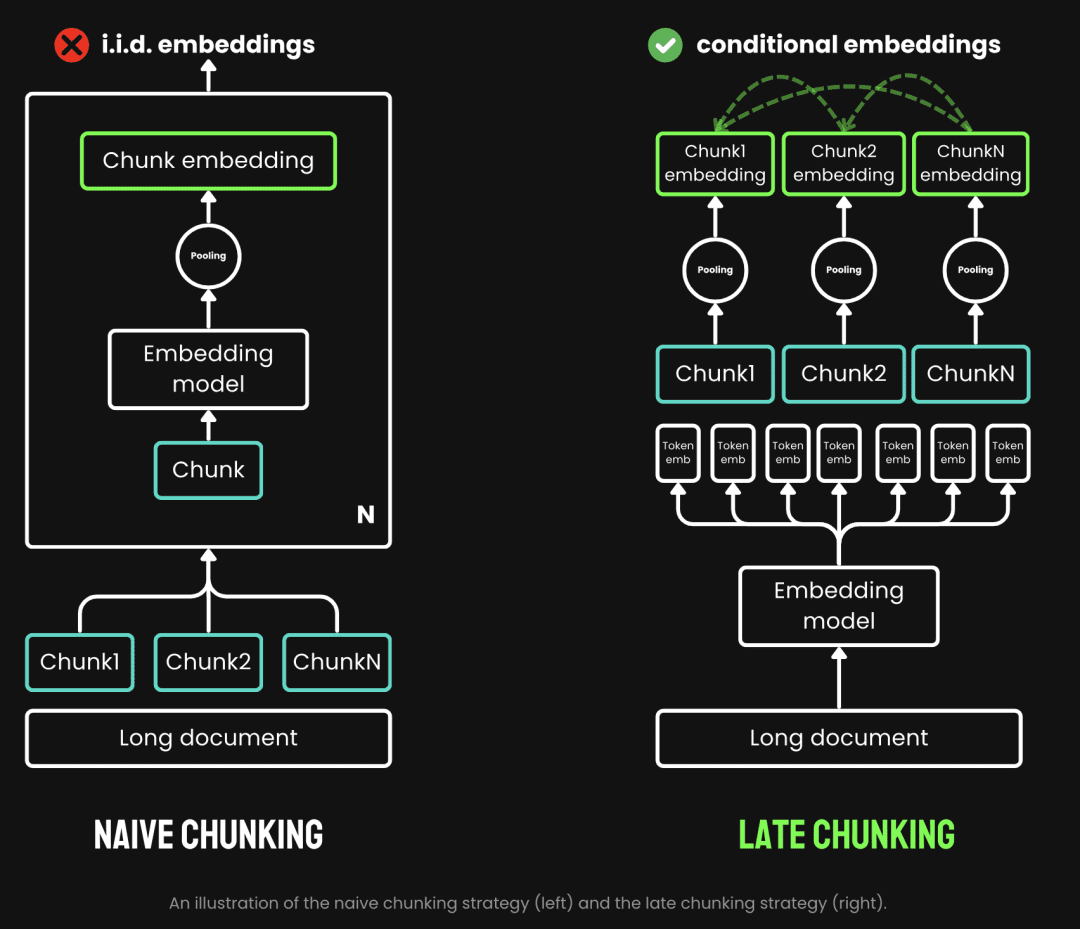
(Bildquelle: https://jina.ai/news/late-chunking-in-long-context-embedding-models/)
Late Chunking erzeugt eine Blockeinbettung, bei der jeder Block mehr Kontextinformationen kodiert und so die Qualität und Genauigkeit der Kodierung verbessert. Wir können lange Kontext-Embedding-Modelle unterstützen, indem wir lange Kontexte unterstützen, wie z. B. jina-embeddings-v2-base-enEs kann bis zu 8192 Token Text verarbeiten (das entspricht 10 DIN-A4-Seiten), was im Grunde die kontextuellen Anforderungen der meisten langen Texte erfüllt.
Zusammenfassend können wir die Vorteile von Late Chunking in RAG-Anwendungen sehen:
- Verbesserte Genauigkeit: Durch die Erhaltung von Kontextinformationen liefert Late Chunking relevantere Inhalte für Abfragen als einfaches Chunking.
- Effiziente LLM-Aufrufe: Late Chunking reduziert die an den LLM übergebene Textmenge, da es weniger und relevantere Chunks zurückgibt.
03.Testen von Late Chunking
3.1 Implementierung der Late Chunking Base
Funktion sentence_chunker für das Originaldokument zum Absatz-Chunking, Rückgabe des Inhalts der Chunks und der Chunk-Markierungsinformation span_annotations (d.h. der Anfang und das Ende der Chunk-Markierung)
def sentence_chunker(document, batch_size=10000):
nlp = spacy.blank("en")
nlp.add_pipe("sentencizer", config={"punct_chars": None})
doc = nlp(document)
docs = []
for i in range(0, len(document), batch_size):
batch = document[i : i + batch_size]
docs.append(nlp(batch))
doc = Doc.from_docs(docs)
span_annotations = []
chunks = []
for i, sent in enumerate(doc.sents):
span_annotations.append((sent.start, sent.end))
chunks.append(sent.text)
return chunks, span_annotations
Die Funktion document_to_token_embeddings übergibt das Modell jinaai/jina-embeddings-v2-base-en Modell sowie den Tokeniser, der die Einbettung des gesamten Dokuments zurückgibt.
def document_to_token_embeddings(model, tokenizer, document, batch_size=4096): tokenized_document = tokenizer(document, return_tensors="pt") tokens = tokenized_document.tokens() outputs = [] for i in range(0, len(tokens), batch_size): start = i end = min(i + batch_size, len(tokens)) batch_inputs = {k: v[:, start:end] for k, v in tokenized_document.items()} with torch.no_grad(): model_output = model(**batch_inputs) outputs.append(model_output.last_hidden_state) model_output = torch.cat(outputs, dim=1) return model_output
Die Funktion late_chunking chunked das Embedding des gesamten Dokuments sowie die Markup-Informationen span_annotations der ursprünglichen Chunks.
def late_chunking(token_embeddings, span_annotation, max_length=None): outputs = [] for embeddings, annotations in zip(token_embeddings, span_annotation): if ( max_length is not None ): annotations = [ (start, min(end, max_length - 1)) for (start, end) in annotations if start < (max_length - 1) ] pooled_embeddings = [] for start, end in annotations: if (end - start) >= 1: pooled_embeddings.append( embeddings[start:end].sum(dim=0) / (end - start) ) pooled_embeddings = [ embedding.detach().cpu().numpy() for embedding in pooled_embeddings ] outputs.append(pooled_embeddings) return outputs
Wenn ein Modell verwendet wirdjinaai/jina-embeddings-v2-base-enLate Chunking durchführen
tokenizer = AutoTokenizer.from_pretrained('jinaai/jina-embeddings-v2-base-en', trust_remote_code=True)
model = AutoModel.from_pretrained('jinaai/jina-embeddings-v2-base-en', trust_remote_code=True)
# First chunk the text as normal, to obtain the beginning and end points of the chunks.
chunks, span_annotations = sentence_chunker(document)
# Then embed the full document.
token_embeddings = document_to_token_embeddings(model, tokenizer, document)
# Then perform the late chunking
chunk_embeddings = late_chunking(token_embeddings, [span_annotations])[0]
3.2 Vergleich mit traditionellen Einbettungsmethoden
Nehmen wir die milvus 2.4.13 Release Note als Beispiel.
Milvus 2.4.13 führt die dynamische Replikabeladung ein, die es den Benutzern ermöglicht, die Anzahl der Replikate der Sammlung anzupassen, ohne die Sammlung freigeben und neu laden zu müssen. Sammlung.
Diese Version behebt außerdem mehrere kritische Fehler im Zusammenhang mit dem Massenimport, dem Parsen von Ausdrücken, dem Lastausgleich und der Fehlerbehebung.
Außerdem wurden die MMAP-Ressourcennutzung und die Importleistung erheblich verbessert, was die Effizienz des Systems insgesamt erhöht.
Wir empfehlen dringend ein Upgrade auf diese Version, um die Leistung und Stabilität zu verbessern.
Es werden das traditionelle Embedding, d.h. Chunking gefolgt von Embedding, und das Late Chunking approach Embedding, d.h. Embedding gefolgt von Chunking, durchgeführt. Dann wird die milvus 2.4.13 Vergleichen Sie die Ergebnisse mit denen der beiden Embedding-Ansätze.
cos_sim = lambda x, y: np.dot(x, y) / (np.linalg.norm(x) * np.linalg.norm(y))
milvus_embedding = model.encode('milvus 2.4.13')
for chunk, late_chunking_embedding, traditional_embedding in zip(chunks, chunk_embeddings, embeddings_traditional_chunking):
print(f'similarity_late_chunking("milvus 2.4.13", "{chunk}")')
print('late_chunking: ', cos_sim(milvus_embedding, late_chunking_embedding))
print(f'similarity_traditional("milvus 2.4.13", "{chunk}")')
print('traditional_chunking: ', cos_sim(milvus_embedding, traditional_embeddings))
Aus den Ergebnissen: Wörter milvus 2.4.13 Die Ähnlichkeit der Late Chunking-Ergebnisse mit gechunkten Dokumenten ist höher als die der traditionellen Einbettung, weil Late Chunking zunächst eine Einbettung für die gesamte Textpassage durchführt, was dazu führt, dass die gesamte Textpassage milvus 2.4.13 Informationen, was wiederum die Ähnlichkeit bei nachfolgenden Textvergleichen erheblich verbessert.
similarity_late_chunking("milvus 2.4.13", "Milvus 2.4.13 introduces dynamic replica load, allowing users to adjust the number of collection replicas without needing to release and reload the collection.")
late_chunking: 0.8785206
similarity_traditional("milvus 2.4.13", "Milvus 2.4.13 introduces dynamic replica load, allowing users to adjust the number of collection replicas without needing to release and reload the collection.")
traditional_chunking: 0.8354263
similarity_late_chunking("milvus 2.4.13", "This version also addresses several critical bugs related to bulk importing, expression parsing, load balancing, and failure recovery.")
late_chunking: 0.84828955
similarity_traditional("milvus 2.4.13", "This version also addresses several critical bugs related to bulk importing, expression parsing, load balancing, and failure recovery.")
traditional_chunking: 0.7222632
similarity_late_chunking("milvus 2.4.13", "Additionally, significant improvements have been made to MMAP resource usage and import performance, enhancing overall system efficiency.")
late_chunking: 0.84942204
similarity_traditional("milvus 2.4.13", "Additionally, significant improvements have been made to MMAP resource usage and import performance, enhancing overall system efficiency.")
traditional_chunking: 0.6907381
similarity_late_chunking("milvus 2.4.13", "We highly recommend upgrading to this release for better performance and stability.")
late_chunking: 0.85431844
similarity_traditional("milvus 2.4.13", "We highly recommend upgrading to this release for better performance and stability.")
traditional_chunking: 0.71859795
3.3 Testen von Late Chunking in Milvus
Importieren von Late Chunking-Daten in Milvus
batch_data=[]
for i in range(len(chunks)):
data = {
"content": chunks[i],
"embedding": chunk_embeddings[i].tolist(),
}
batch_data.append(data)
res = client.insert(
collection_name=collection,
data=batch_data,
)
Abfrageprüfung
Wir definieren die Cosinus-Ähnlichkeits-Abfragemethode sowie die Verwendung der nativen Milvus-Abfragemethode für Late Chunking.
def late_chunking_query_by_milvus(query, top_k = 3):
query_vector = model(**tokenizer(query, return_tensors="pt")).last_hidden_state.mean(1).detach().cpu().numpy().flatten()
res = client.search(
collection_name=collection,
data=[query_vector.tolist()],
limit=top_k,
output_fields=["id", "content"],
)
return [item.get("entity").get("content") for items in res for item in items]
def late_chunking_query_by_cosine_sim(query, k = 3):
cos_sim = lambda x, y: np.dot(x, y) / (np.linalg.norm(x) * np.linalg.norm(y))
query_vector = model(**tokenizer(query, return_tensors="pt")).last_hidden_state.mean(1).detach().cpu().numpy().flatten()
results = np.empty(len(chunk_embeddings))
for i, (chunk, embedding) in enumerate(zip(chunks, chunk_embeddings)):
results[i] = cos_sim(query_vector, embedding)
results_order = results.argsort()[::-1]
return np.array(chunks)[results_order].tolist()[:k]
Die Ergebnisse zeigen, dass die beiden Methoden den gleichen Inhalt liefern, was darauf hindeutet, dass die Ergebnisse der Abfrage nach Late Chunking in Milvus korrekt sind.
> late_chunking_query_by_milvus("What are new features in milvus 2.4.13", 3)
['nn### Featuresnn- Dynamic replica adjustment for loaded collections ([#36417](https://github.com/milvus-io/milvus/pull/36417))n- Sparse vector MMAP in growing segment types ([#36565](https://github.com/milvus-io/milvus/pull/36565))...
> late_chunking_query_by_cosine_sim("What are new features in milvus 2.4.13", 3)
['nn### Featuresnn- Dynamic replica adjustment for loaded collections ([#36417](https://github.com/milvus-io/milvus/pull/36417))n- Sparse vector MMAP in growing segment types ([#36565](https://github.com/milvus-io/milvus/pull/36565))...
04.Zusammenfassungen
Wir stellen den Hintergrund, die grundlegenden Konzepte und die zugrundeliegende Implementierung von Late Chunking vor, wie es entstanden ist, und stellen dann fest, dass Late Chunking gut funktioniert, indem wir es in Mivlus testen. Insgesamt macht die Kombination aus Genauigkeit, Effizienz und Einfachheit der Implementierung Late Chunking zu einem effektiven Ansatz für RAG-Anwendungen.
Referenz.
- https://stackoverflow.blog/2024/06/06/breaking-up-is-hard-to-do-chunking-in-rag-applications
- https://jina.ai/news/late-chunking-in-long-context-embedding-models/
- https://jina.ai/news/what-late-chunking-really-is-and-what-its-not-part-ii/
Beispiel-Code:
Link: https://pan.baidu.com/s/1cYNfZTTXd7RwjnjPFylReg?pwd=1234 Code extrahieren: 1234 Code läuft auf aws g4dn.xlarge Maschine
© urheberrechtliche Erklärung
Artikel Copyright AI-Austauschkreis Alle, bitte nicht ohne Erlaubnis vervielfältigen.
Ähnliche Artikel




Keine Kommentare...