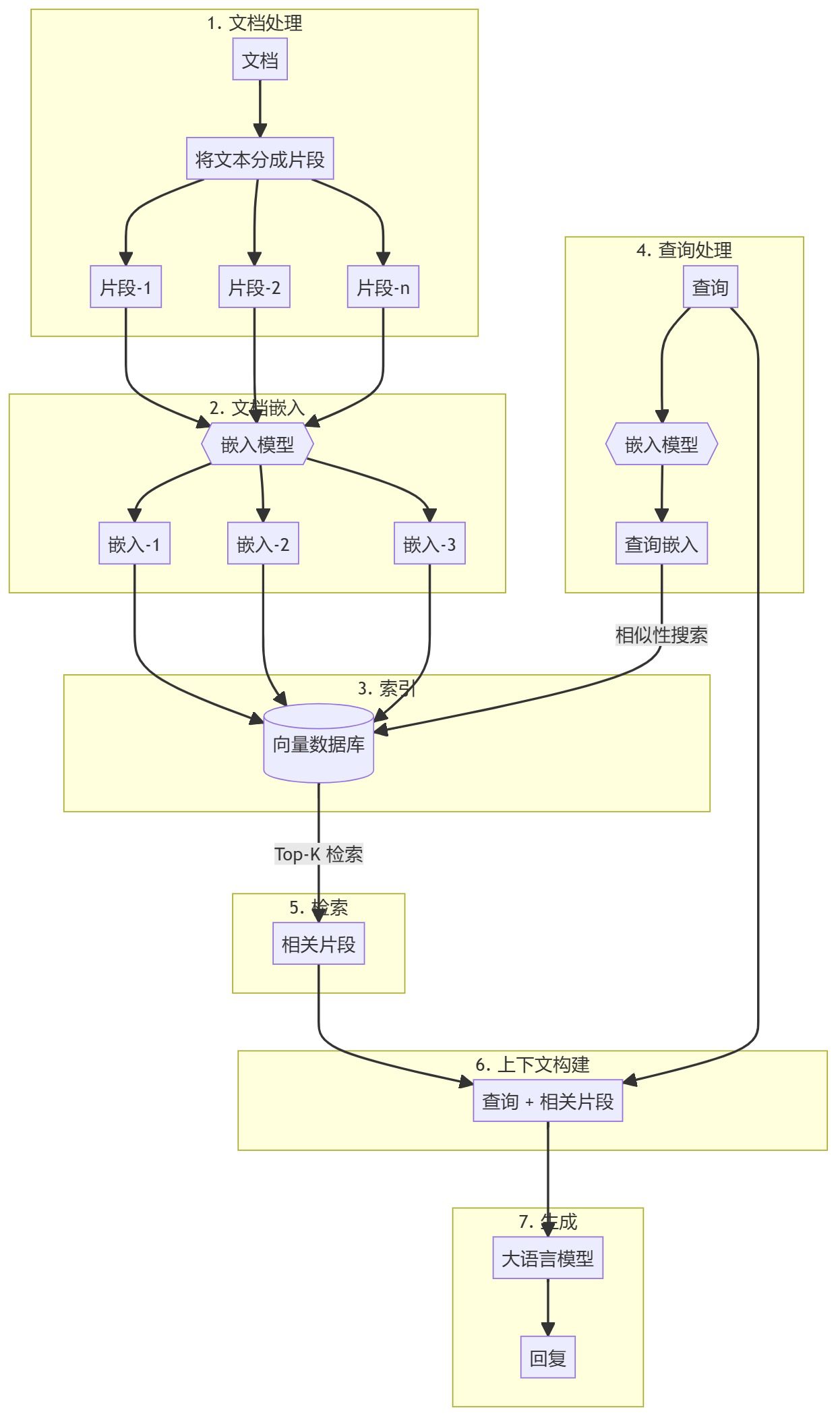
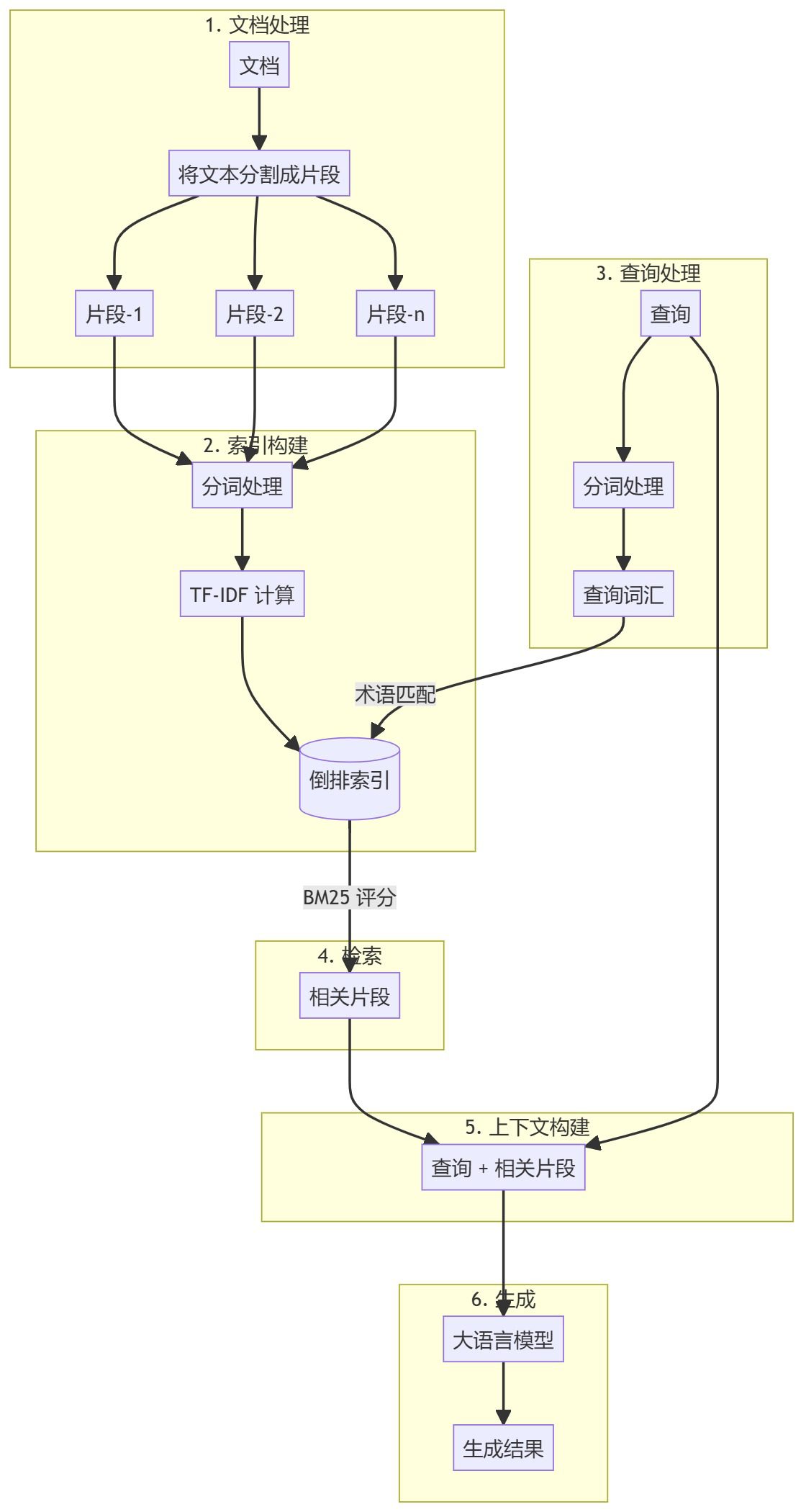
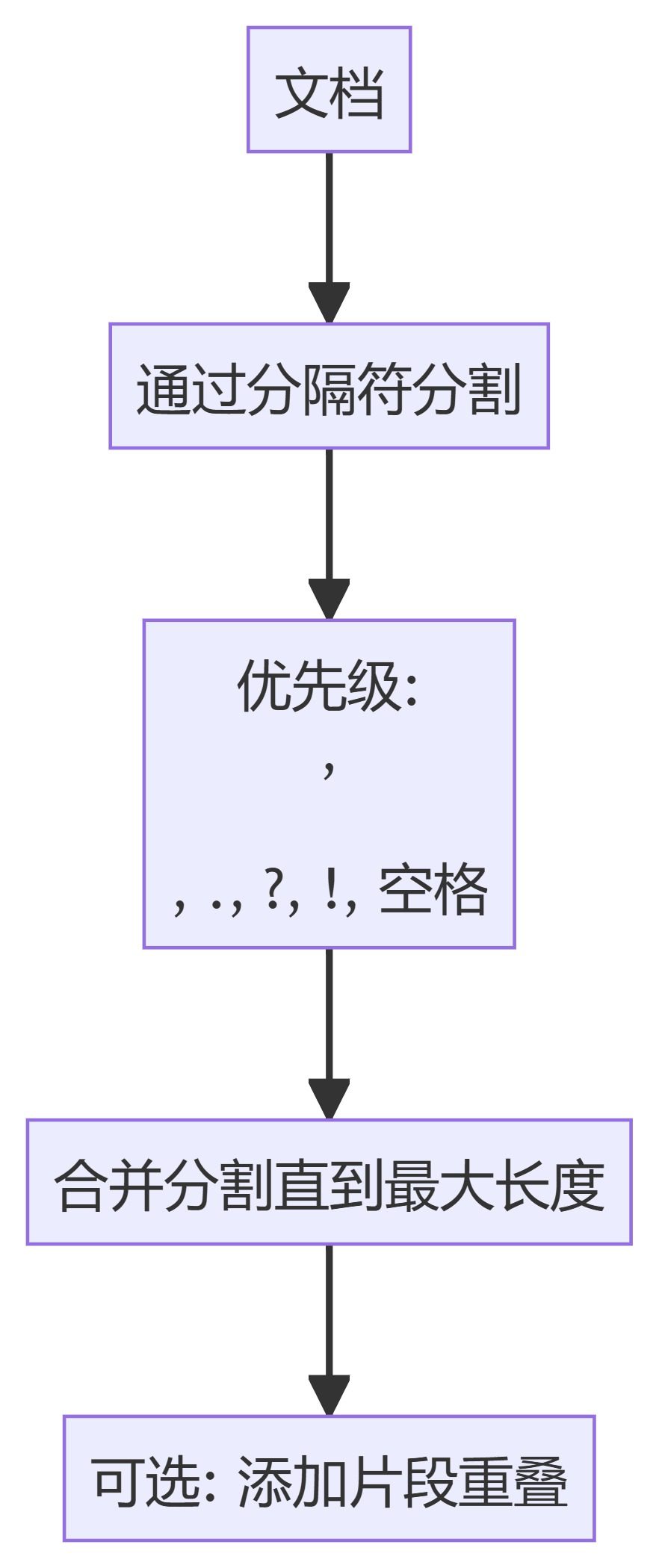
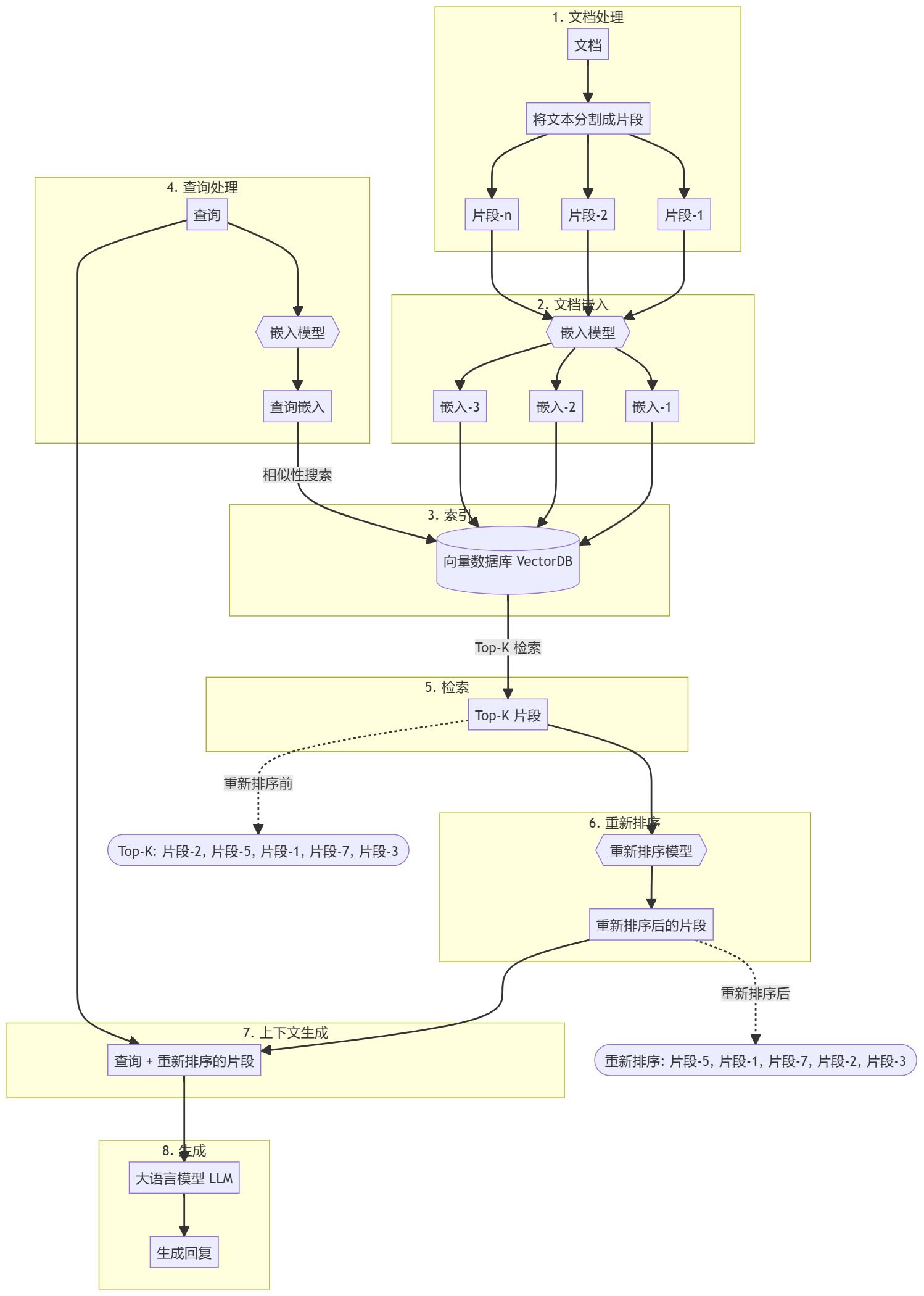
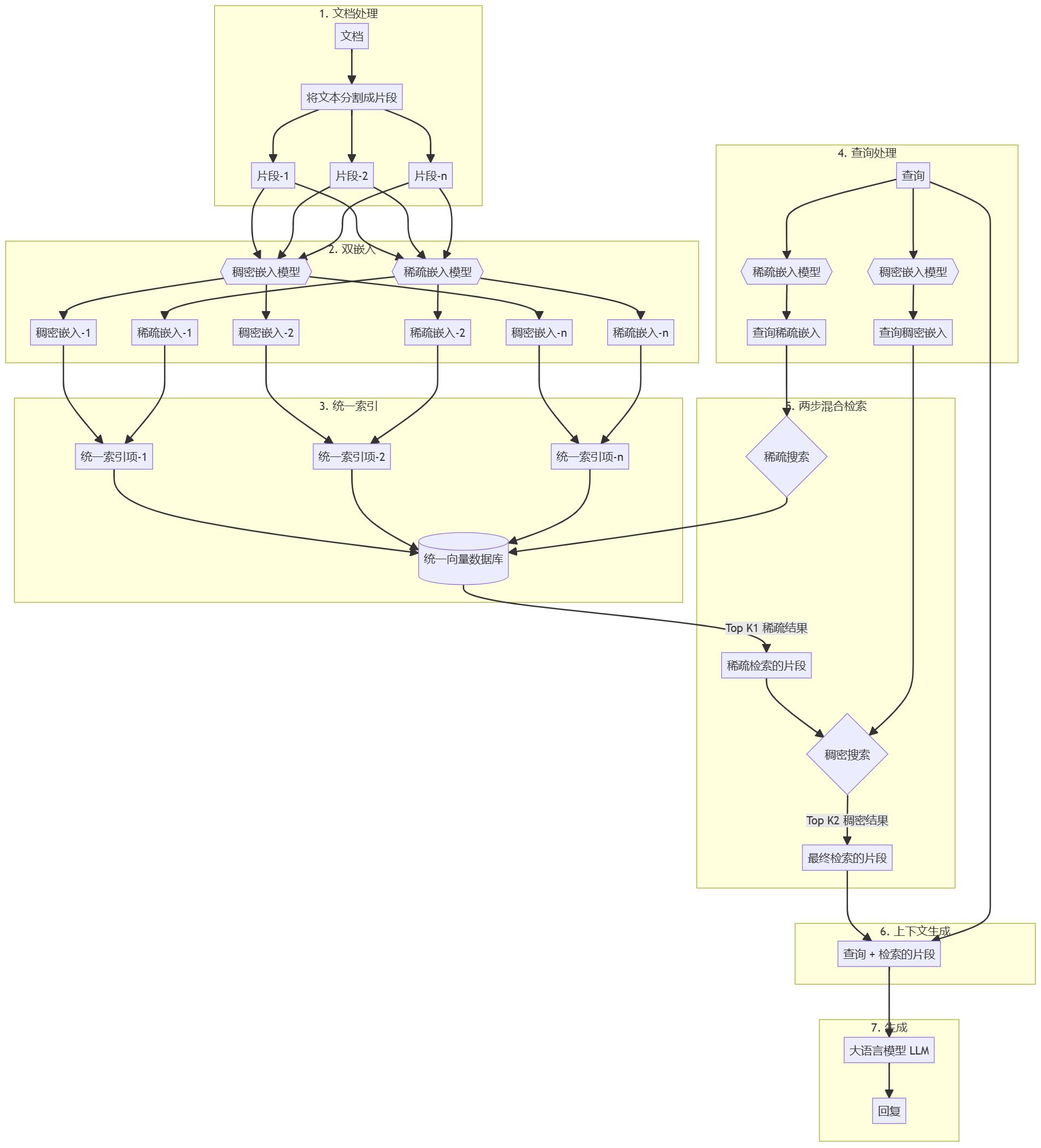
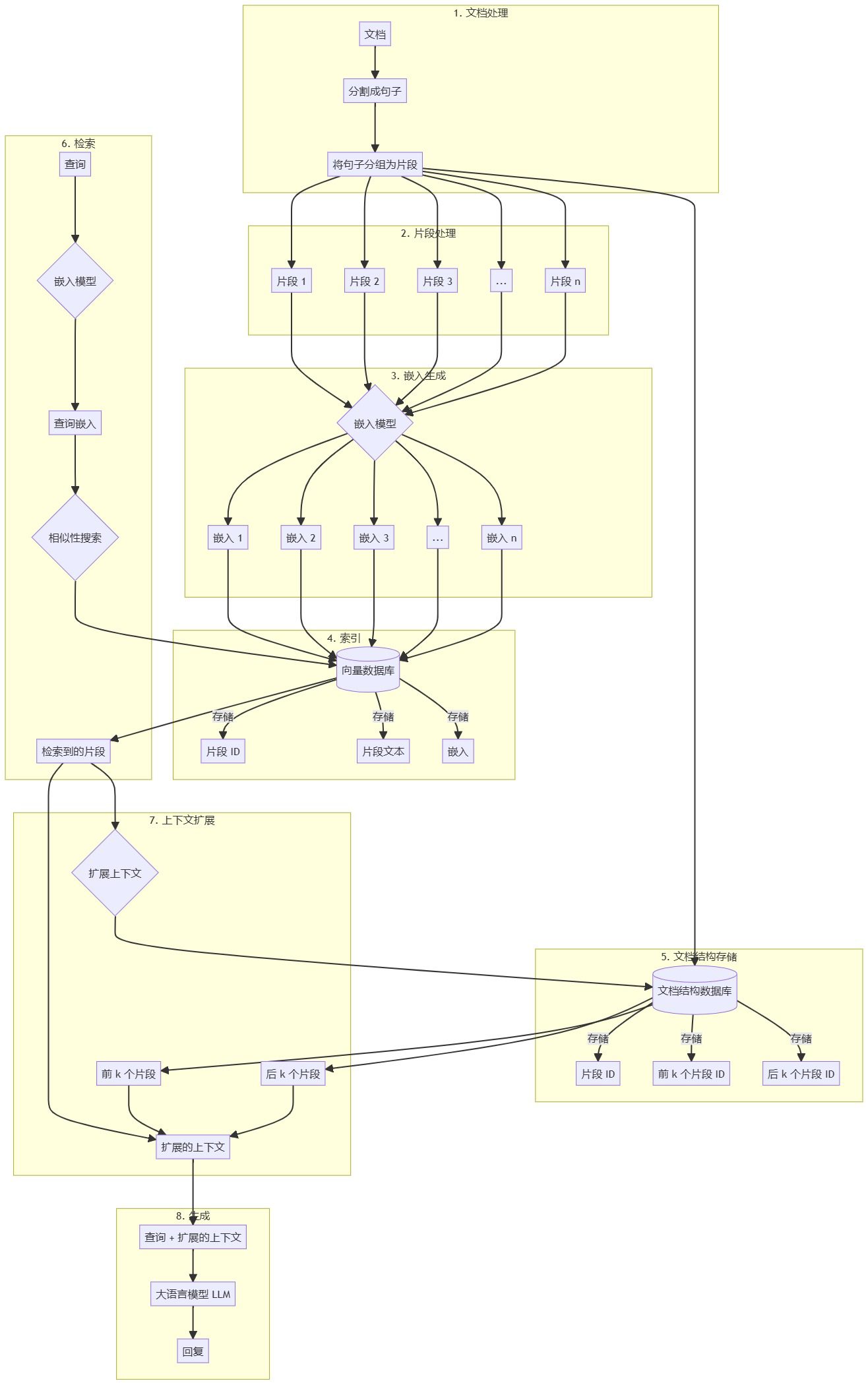
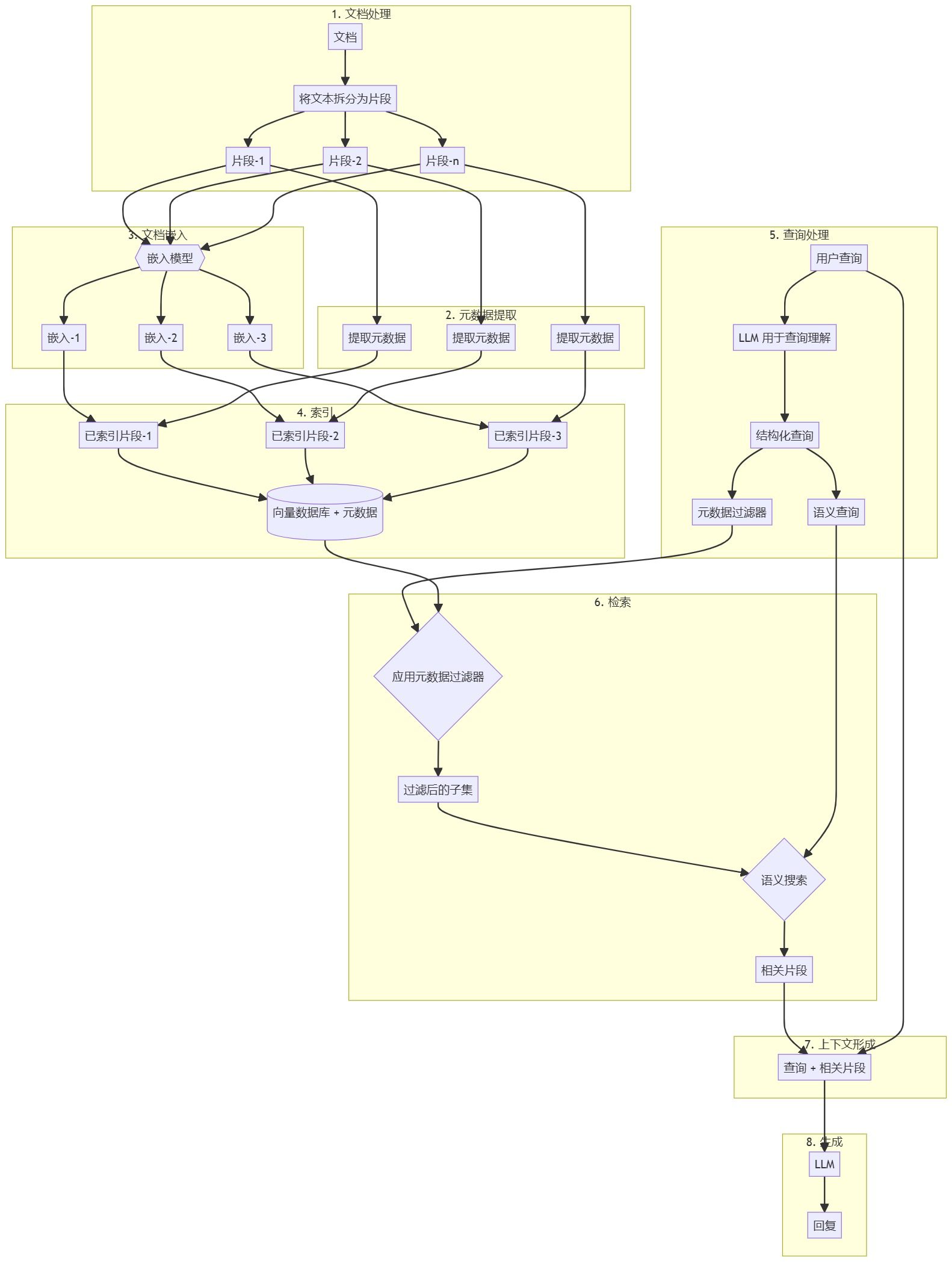
Wie konvertiere ich die von Dify bereitgestellte API in ein Format, das mit der OpenAI-Schnittstelle kompatibel ist?
Jeder, der mit Dify gearbeitet hat, sollte wissen, dass Dify zwar eine großartige KI-App ist, aber die API, die sie bietet, nicht mit Open AI kompatibel ist, was es für einige Apps unmöglich macht, an Dify anzudocken. Was ist die Lösung für dieses Problem?