Kurzanleitung für Produktmanager zu häufig verwendeten Stichwörtern
Einleitung Willkommen beim Handbuch für Produktmanager Cue Words Quick Reference. Dieses Handbuch ist eine Sammlung von Tipps und Tricks, die Produktmanager bei ihrer täglichen Arbeit anwenden können. Der Inhalt reicht von der Verbesserung grundlegender Fähigkeiten, Fallstudien und der Anwendung von Management-Frameworks bis hin zur Auswahl von Werkzeugen, Produktfreigabe, Verarbeitung von Benutzerfeedback und Datenanalyse...




























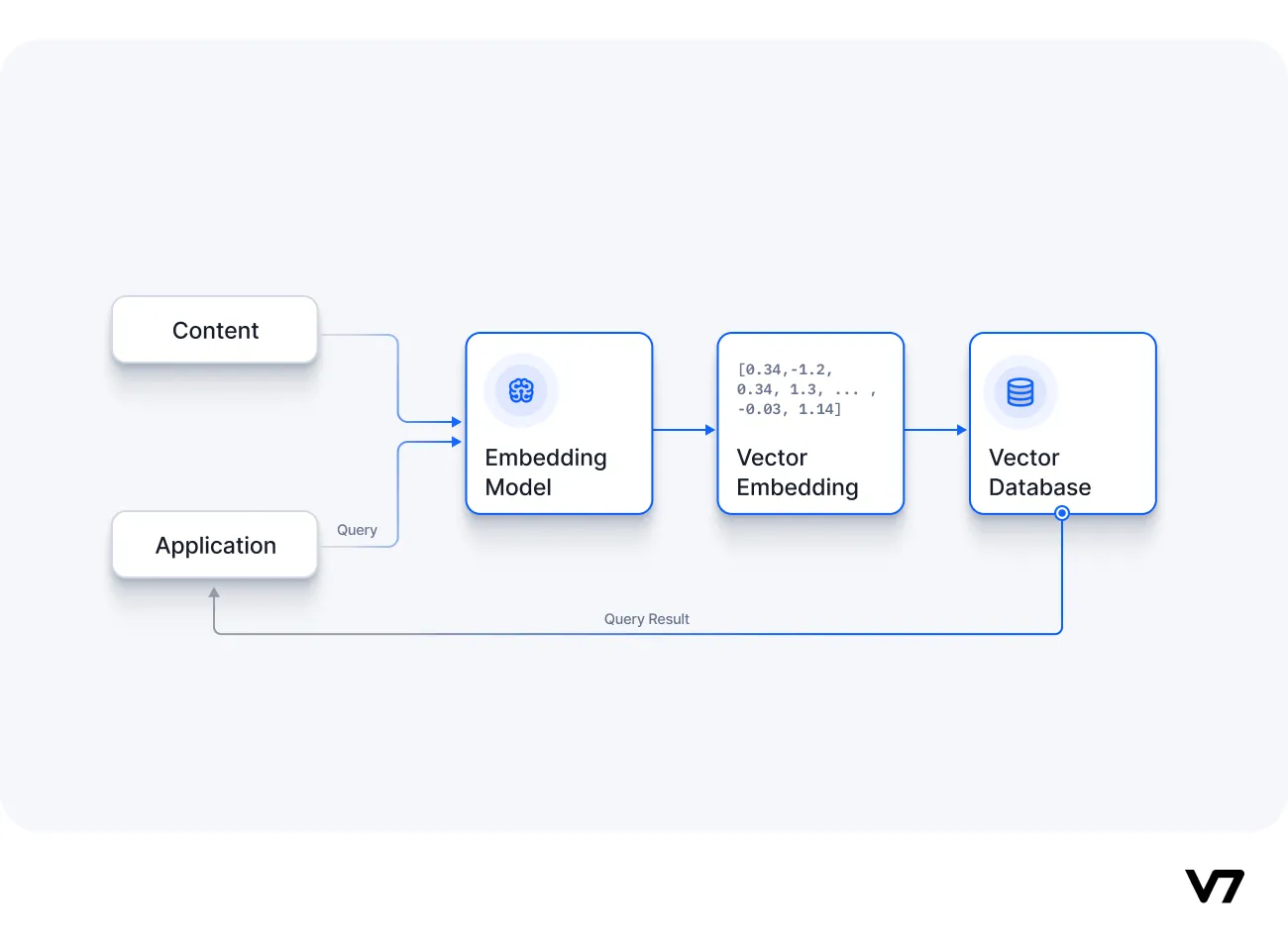
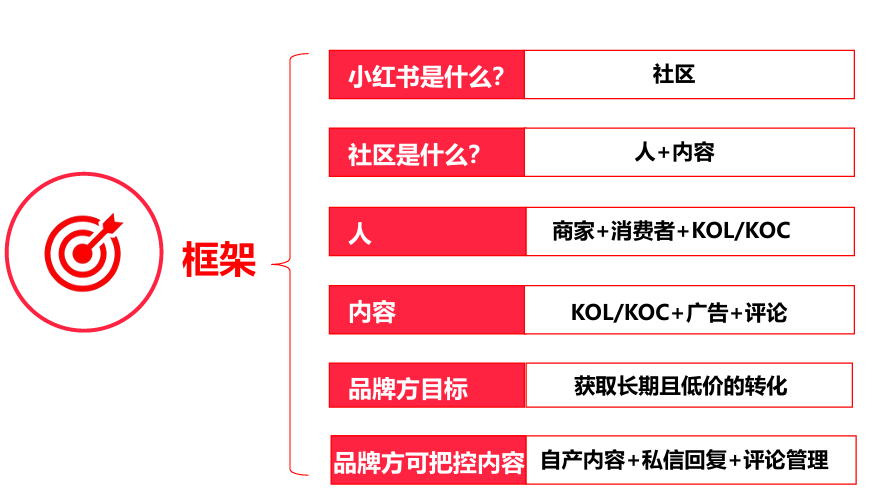
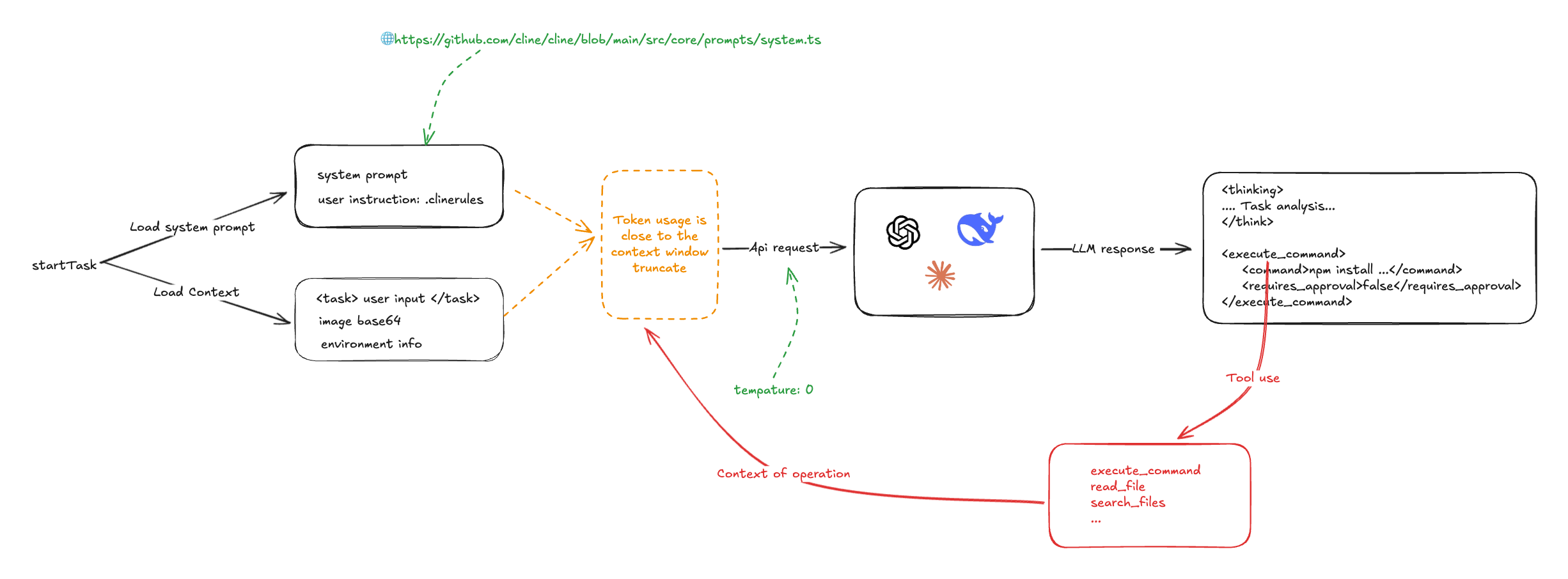

![[转]从零拆解一款火爆的浏览器自动化智能体,4步学会设计自主决策Agent](https://aisharenet.com/wp-content/uploads/2025/01/e0a98a1365d61a3.png)