
Das quelloffene 1,6B-Minimodell "Little Fox" übertrifft die ähnlichen Modelle Qwen und Gemma


seit (einer Zeit) Chatgpt Seit seiner Einführung scheint die Anzahl der LLM-Parameter (Large Language Models) für jedes Unternehmen ein Wettlauf nach unten zu sein. Die Anzahl der GPT-1-Parameter betrug 117 Millionen (117M), und die vierte Generation, die GPT-4-Parameter, wurde auf 1,8 Billionen (1800B) aufgestockt.
Wie bei anderen LLM-Modellen, z. B. Bloom (176 Milliarden, 176B) und Chinchilla (70 Milliarden, 70B), steigt die Zahl der Parameter ebenfalls stark an. Die Anzahl der Parameter wirkt sich direkt auf die Leistung und Fähigkeit des Modells aus. Mehr Parameter bedeuten, dass das Modell in der Lage ist, komplexere Sprachmuster zu verarbeiten, umfangreichere Kontextinformationen zu verstehen und bei einer Vielzahl von Aufgaben ein höheres Maß an Intelligenz zu zeigen.
Diese enormen Parameter wirken sich jedoch auch direkt auf die Ausbildungskosten und die Entwicklungsumgebung von LLMs aus und schränken die Erforschung von LLMs durch die meisten allgemeinen Forschungsunternehmen ein, was dazu führt, dass große Sprachmodelle allmählich zu einem Wettrüsten zwischen großen Unternehmen werden.
Kürzlich veröffentlichte das aufstrebende KI-Unternehmen TensorOpera dieOpen Source Small Language Models FOXund beweist der Branche, dass Small Language Models (SLMs) auch im Bereich der Intelligenz stark genug sein können.

FOX ist einKleine Sprachmodelle für Cloud- und Edge-Computing. Im Gegensatz zu großen Sprachmodellen mit Dutzenden von Milliarden von Parametern ist FOX Nur 1,6 Milliarden ParameterEs ist eine großartige Möglichkeit, das Beste aus Ihrem Computer herauszuholen, aber es ist auch eine großartige Möglichkeit, eine erstaunliche Leistung über mehrere Aufgaben hinweg zu zeigen.
Titel der Dissertation:
FUCHS-1 TECHNISCHER BERICHT
Link zum Papier:
https://arxiv.org/abs/2411.05281

Wer ist TensorOpera?
TensorOpera ist ein innovatives Unternehmen für künstliche Intelligenz mit Sitz im Silicon Valley, Kalifornien. Zuvor entwickelte es das generative KI-Ökosystem TensorOpera® AI Platform und die föderale Lern- und Analyseplattform TensorOpera® FedML. Der Name des Unternehmens, TensorOpera, ist eine Kombination aus Technologie und Kunst und symbolisiert GenAIs mögliche Entwicklung von multimodalen und multimodalen zusammengesetzten KI-Systemen.

Dr. Jared Kaplan, Mitbegründer und CEO von TensorOpera, sagte: "Das FOX-Modell wurde ursprünglich entwickelt, um den Bedarf an Rechenressourcen deutlich zu reduzieren und gleichzeitig eine hohe Leistung zu gewährleisten. Dies macht die KI-Technologie nicht nur zugänglicher, sondern senkt auch die Hemmschwelle für die Nutzung durch Unternehmen.
Wie funktioniert das Fox-Modell?
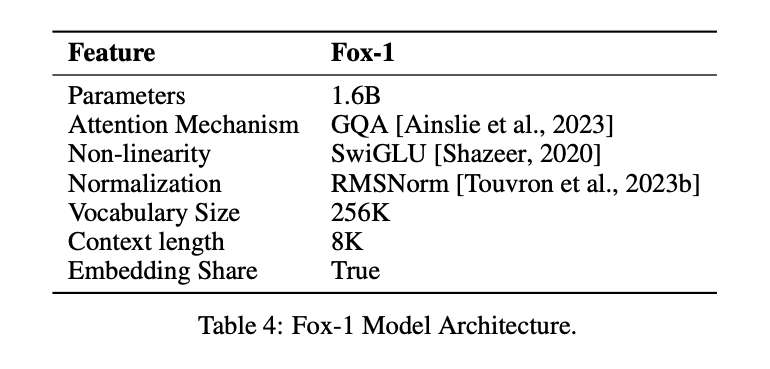
Um die gleiche Wirkung wie das LLM mit einer geringeren Anzahl von Parametern zu erzielen, wurde das Fox-1-ModellNur DecoderArchitektur und führt verschiedene Verbesserungen und Umgestaltungen für mehr Leistung ein. Dazu gehören
① NetzwerkschichtBei der Entwicklung von Modellarchitekturen haben breitere und flachere neuronale Netze bessere Speicherkapazitäten, während tiefere und schlankere Netze stärkere Inferenzfähigkeiten aufweisen. Diesem Prinzip folgend, verwendet Fox-1 eine tiefere Architektur als die meisten modernen SLMs. Fox-1 besteht aus 32 selbst-aufmerksamen Schichten, was 781 TP3T tiefer ist als Gemma-2B (18 Schichten) und 331 TP3T tiefer als StableLM-2-1.6B (24 Schichten) und Qwen1.5-1.8B (24 Schichten).
② Gemeinsame EinbettungFox-1 verwendet 2.048 versteckte Dimensionen, um insgesamt 256.000 Vokabulare mit etwa 500 Millionen Parametern zu erstellen. Größere Modelle verwenden in der Regel separate Einbettungsschichten für die Eingabeschicht (Vokabular zu eingebetteten Ausdrücken) und die Ausgabeschicht (eingebettete Ausdrücke zu Vokabular). Bei Fox-1 benötigt allein die Einbettungsschicht 1 Milliarde Parameter. Um die Gesamtzahl der Parameter zu reduzieren, maximiert die gemeinsame Nutzung der Einbettungsschichten für Eingabe und Ausgabe die Ausnutzung der Gewichte.
(iii) Vor-NormierungFox-1 verwendet RMSNorm, um die Eingaben der einzelnen Transformationsschichten zu normalisieren; RMSNorm ist die bevorzugte Wahl für die Vornormalisierung in modernen, groß angelegten Sprachmodellen und weist eine bessere Effizienz als LayerNorm auf.
④ Drehpositionskodierung (RoPE)Fox-1 akzeptiert standardmäßig Eingabe-Token mit einer Länge von bis zu 8K. Um die Leistung in längeren Kontextfenstern zu verbessern, verwendet Fox-1 eine gedrehte Positionskodierung, bei der θ für die Kodierung auf 10.000 gesetzt wird. Token Relative Positionsabhängigkeit zwischen
⑤ Aufmerksamkeit bei Gruppenabfragen (GQA)Fox-1 ist mit 4 Key-Value-Heads und 16 Attention-Heads ausgestattet, um die Trainings- und Inferenzgeschwindigkeit zu erhöhen und den Speicherverbrauch zu reduzieren.
Neben der Modellierung struktureller Verbesserungen.FOX-1 verbessert auch die Tokenisierung und die Ausbildung..
die Wortart (in der chinesischen Grammatik)Fox-1 verwendet den SentencePiece-basierten Gemma-Klassifikator, der eine Vokabulargröße von 256K bietet. Die Vergrößerung des Vokabulars hat mindestens zwei Hauptvorteile. Erstens wird die Länge der verborgenen Informationen im Kontext vergrößert, da jedes Token eine dichtere Information kodiert. Ein Vokabular der Größe 26 kann beispielsweise nur ein Zeichen in [a-z] kodieren, ein Vokabular der Größe 262 kann jedoch zwei Buchstaben gleichzeitig kodieren, wodurch es möglich wird, längere Zeichenfolgen in einem Token fester Länge darzustellen. Zweitens verringert ein größeres Vokabular die Wahrscheinlichkeit unbekannter Wörter oder Phrasen, was in der Praxis zu einer besseren Leistung bei nachgelagerten Aufgaben führt: Das große Vokabular von Fox-1 erzeugt weniger Token für einen gegebenen Textkorpus, was zu einer besseren Inferenzleistung führt.
Fuchs-1Daten vor dem TrainingDie Daten stammen aus den Datensätzen Redpajama, SlimPajama, Dolma, Pile und Falcon, die insgesamt 3 Billionen Textdaten umfassen. Um die Ineffizienz des Pre-Trainings für lange Sequenzen aufgrund seines Aufmerksamkeitsmechanismus zu mildern, führt Fox-1 in der Pre-Trainingsphase eineEine dreistufige Lehrplan-LernstrategieFox-1 ist eine dreistufige Pipeline für das Pre-Training von Kursen, bei der die Chunk-Länge der Trainingsmuster schrittweise von 2K auf 8K erhöht wird, um lange kontextuelle Fähigkeiten bei geringen Kosten zu gewährleisten. Um mit der dreiphasigen Kursvorbereitungspipeline konsistent zu sein, reorganisiert Fox-1 die Rohdaten in drei verschiedene Sätze, einschließlich unüberwachter und instruktionsgesteuerter Datensätze sowie Daten aus verschiedenen Bereichen wie Code, Webinhalte, mathematische und wissenschaftliche Dokumente.
Die Fox-1-Ausbildung kann in drei Phasen unterteilt werden.
- Die erste Phase besteht aus insgesamt 39% Datenproben während des gesamten Pre-Trainings, wobei der Datensatz von 1,05 Billionen Token in Stichproben der Länge 2.000 partitioniert wird, mit einer Stapelgröße von 2 M. In dieser Phase wird eine lineare Aufwärmphase von 2.000epoch verwendet.
- Die zweite Phase umfasst etwa 59%-Proben mit 1,58 Billionen Token und erhöht die Chunk-Länge von 2K auf 4K und 8K. Die tatsächliche Chunk-Länge variiert je nach Datenquelle. In Anbetracht der Tatsache, dass die zweite Phase am längsten dauert und verschiedene Quellen aus unterschiedlichen Datensätzen umfasst, wird die Stapelgröße ebenfalls auf 4M erhöht, um die Trainingseffizienz zu verbessern.
- In der dritten Phase schließlich wird das Fox-Modell anhand von 6,2 Milliarden Token (etwa 0,02% der Gesamtmenge) qualitativ hochwertiger Daten trainiert, wodurch die Grundlage für verschiedene nachgelagerte Aufgaben wie Befehlsfolge, Smalltalk, domänenspezifische Fragen und Antworten usw. geschaffen wird.
Wie hat Fox-1 abgeschnitten?
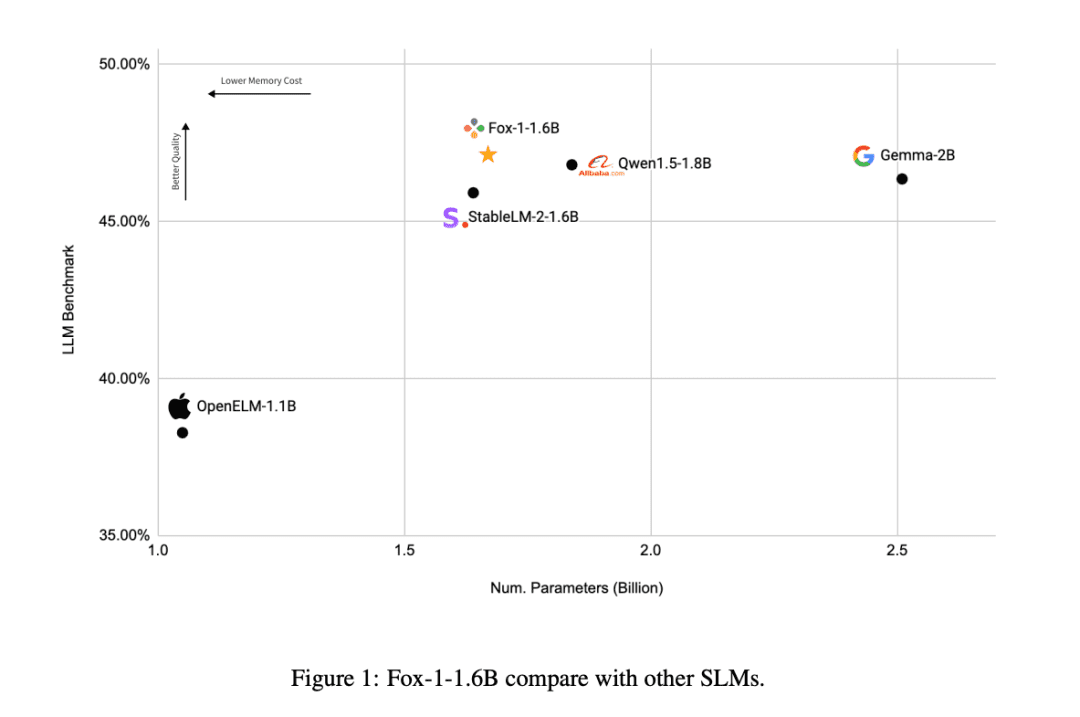
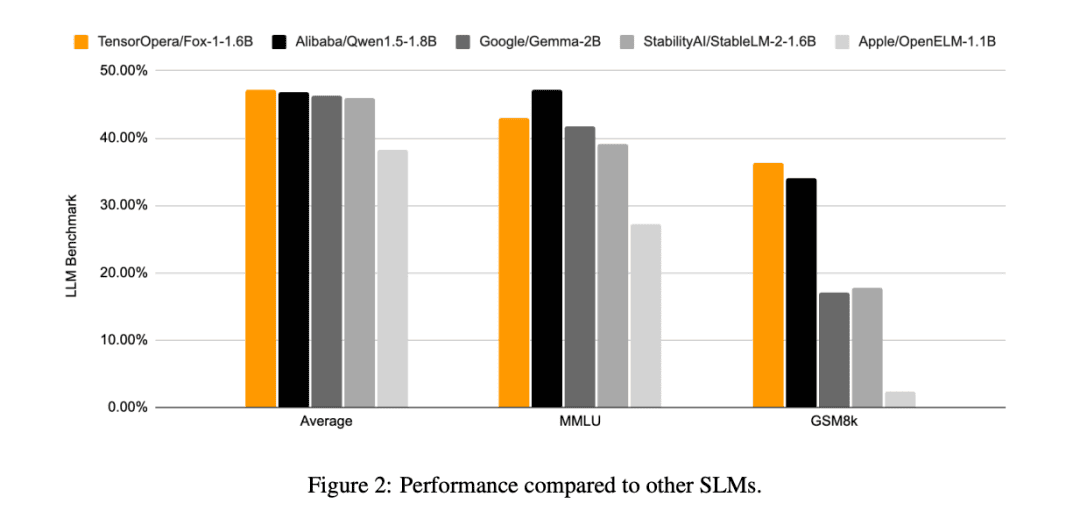
Im Vergleich zu den anderen SLM-Modellen (Gemma-2B, Qwen1.5-1.8B, StableLM-2-1.6B und OpenELM1.1B) ist FOX-1 erfolgreicher in ARC Challenge (25-Schuss), HellaSwag (10-Schuss), TruthfulQA (0-Schuss), MMLU (5-Schuss), Winogrande (5-Schuss), GSM8k (5-Schuss), GSM8k (5-Schuss) MMLU (5-Schuss), Winogrande (5-Schuss), GSM8k (5-Schuss)Die Durchschnittswerte des Benchmarks für die sechs Aufgaben waren am höchsten und waren auf dem GSM8k deutlich besser.
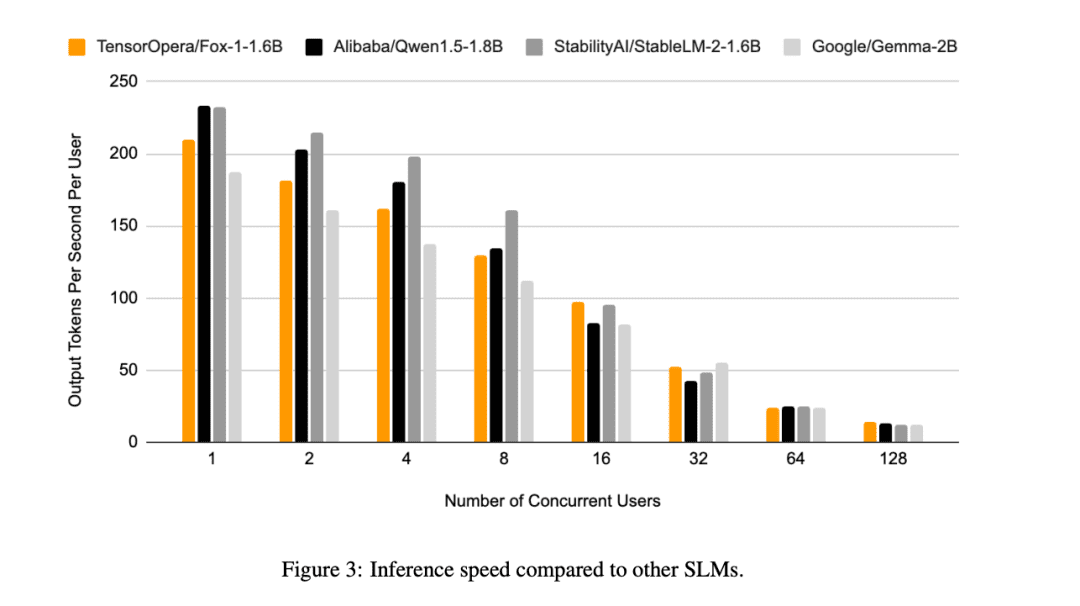
Darüber hinaus bewertete TensorOpera Fox-1, Qwen1.5-1.8B und Gemma-2B unter Verwendung der vLLM End-to-End Inferenz-Effizienz mit der TensorOpera Service Platform auf einem einzigen NVIDIA H100.
Fox-1 erreicht einen Durchsatz von über 200 Token pro Sekunde und übertrifft damit Gemma-2B und entspricht Qwen1.5-1.8B in derselben Einsatzumgebung. Bei BF16-Präzision benötigt Fox-1 nur 3703MiB GPU-Speicher, während Qwen1.5-1.8B, StableLM-2-1.6B und Gemma-2B jeweils 4739MiB, 3852MiB und 5379MiB benötigen.
Kleine Parameter, aber dennoch wettbewerbsfähig
Während alle KI-Firmen jetzt bei großen Sprachmodellen konkurrieren, hat TensorOpera einen anderen Ansatz gewählt, indem es im SLM-Bereich den Durchbruch schaffte, ähnliche Ergebnisse wie LLM mit nur 1,6B erzielte und in verschiedenen Benchmarks gut abschnitt.
Selbst mit begrenzten Datenressourcen kann TensorOpera Sprachmodelle mit konkurrenzfähiger Leistung vortrainieren und damit anderen KI-Unternehmen eine neue Denkweise vermitteln.
© urheberrechtliche Erklärung
Artikel Copyright AI-Austauschkreis Alle, bitte nicht ohne Erlaubnis vervielfältigen.
Ähnliche Artikel



Keine Kommentare...