

KAG: Ein professionelles Wissensdatenbank-Q&A-Framework für hybride Wissensgraphen- und Vektor-Retrieval

Allgemeine Einführung
KAG (Knowledge Augmented Generation) ist ein logisches, formgeleitetes Reasoning- und Retrieval-Framework, das auf der OpenSPG-Engine und Large Language Models (LLMs) basiert. KAG verbessert die LLMs und Wissensgraphen durch die komplementären Stärken von Knowledge Graph und Vector Retrieval auf vier Arten in beide Richtungen: LLM-freundliche Wissensrepräsentationen, Inter-Indexierung zwischen Wissensgraphen und rohen Textfragmenten, hybride Inferenzlöser und hybride Inferenzlöser. Indexierung, hybride Inferenzlöser und Plausibilitätsbewertungsmechanismen. Das Framework ist besonders gut geeignet, um komplexe Wissenslogik-Probleme wie numerische Berechnungen, temporale Beziehungen und Expertenregeln zu behandeln und bietet genauere und zuverlässigere Fragebeantwortungsmöglichkeiten für professionelle Anwendungen.

Funktionsliste
- Fähigkeit, komplexe logische Argumentationsformen zu unterstützen
- Bereitstellung eines hybriden Suchmechanismus aus Wissensgraphen und Vektorabfragen
- Implementierung einer LLM-freundlichen Wissensrepräsentationskonvertierung
- Unterstützt die bidirektionale Indizierung von Wissensstrukturen und Textblöcken
- Integration von LLM-Reasoning, intellektuellem Denken und mathematisch-logischem Denken
- Bereitstellung von Mechanismen zur Bewertung und Validierung der Glaubwürdigkeit
- Unterstützt Multi-Hop-Q&A und komplexe Abfrageverarbeitung
- Bereitstellung maßgeschneiderter Lösungen für die Wissensbasis von Fachgebieten
Hilfe verwenden
1. die Vorbereitung der Umwelt
Als Erstes müssen Sie sicherstellen, dass Ihr System die folgenden Anforderungen erfüllt:
- Python 3.8 oder höher
- OpenSPG-Engine-Umgebung
- Unterstützte API-Schnittstellen für große Sprachmodelle
2. die Installationsschritte
- Klonen des Projektlagers:
git clone https://github.com/OpenSPG/KAG.git
cd KAG
- Installieren Sie die Abhängigkeitspakete:
pip install -r requirements.txt
3. der Prozess der Rahmennutzung
3.1 Vorbereitung der Wissensbasis
- Import von Daten zum Fachwissen des Bereichs
- Konfigurieren des Wissensgraphenmodells
- Einrichtung eines Textindexierungssystems
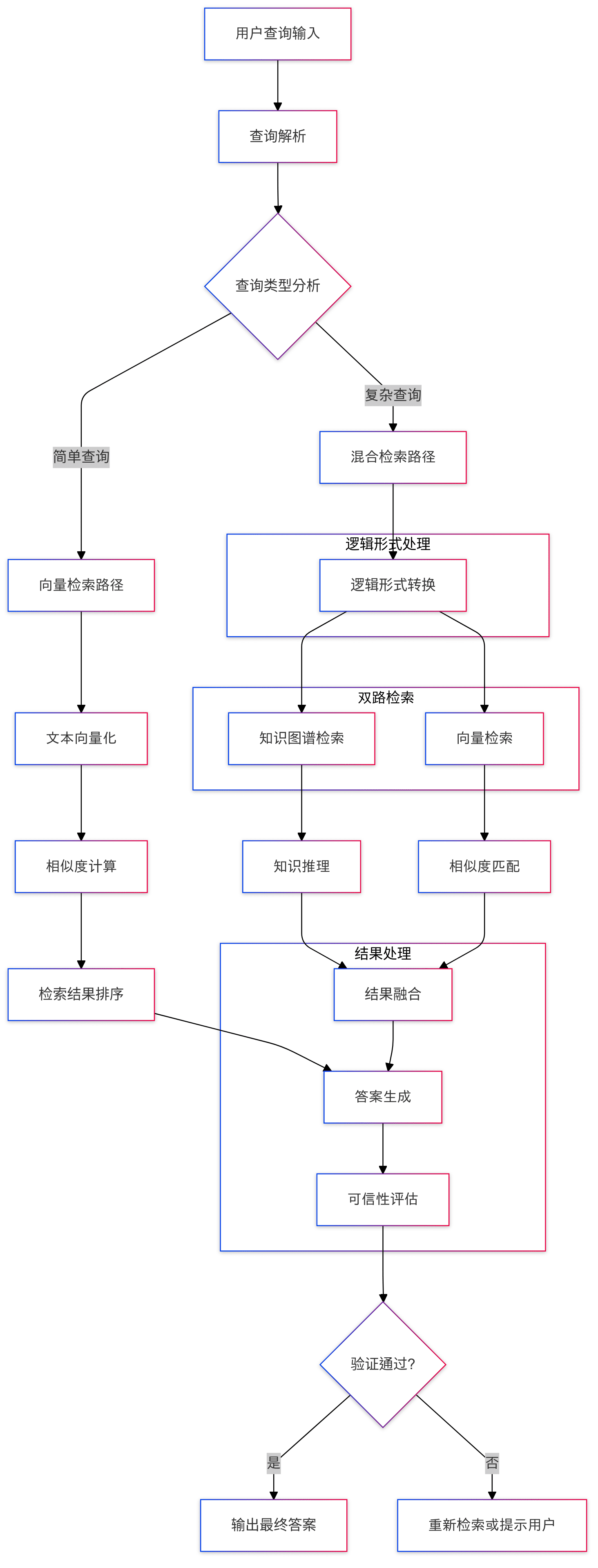
3.2 Abfrageverarbeitung
- Frageneingabe: Das System erhält Fragen in natürlicher Sprache vom Benutzer
- Umwandlung von logischen Formen: Umwandlung von Problemen in standardisierte logische Ausdrücke
- Gemischter Abruf:
- Wissensgraphen-Suchen durchführen
- Durchführen einer Vektorähnlichkeitssuche
- Integration von Suchergebnissen
3.3 Begründungsprozess
- Logisches Schlussfolgern: Mehrstufiges Schlussfolgern mit gemischten Schlussfolgern (Mixed Reasoning Solvers)
- Wissensfusion: Kombination von LLM-Schlussfolgerungen und Wissensgraphen-Schlussfolgerungsergebnissen
- Antwortgenerierung: Bildung der endgültigen Antwort
3.4 Sicherstellung der Glaubwürdigkeit
- Überprüfung der Antwort
- Begründete Pfadverfolgung
- Vertrauensbewertung (math.)
4. die Nutzung der erweiterten Funktionen
4.1 Maßgeschneiderte Wissensdarstellung
Das Format der Wissensdarstellung kann an die Bedürfnisse Ihres Fachgebiets angepasst werden, wobei die Kompatibilität mit LLM gewährleistet ist:
# 示例代码
knowledge_config = {
"domain": "your_domain",
"schema": your_schema_definition,
"representation": your_custom_representation
}
4.2 Konfiguration der Begründungsregel
Spezialisierte Inferenzregeln können konfiguriert werden, um domänenspezifische Logik zu behandeln:
# 示例代码
reasoning_rules = {
"numerical": numerical_processing_rules,
"temporal": temporal_reasoning_rules,
"domain_specific": your_domain_rules
}
5. bewährte Praktiken
- Sicherstellung der Qualität und Integrität der Daten der Wissensdatenbank
- Optimierung der Suchstrategien zur Verbesserung der Effizienz
- Regelmäßige Aktualisierung und Pflege der Wissensdatenbank
- Überwachung der Systemleistung und -genauigkeit
- Sammeln von Nutzerfeedback zur kontinuierlichen Verbesserung
6. die Lösung gemeinsamer Probleme
- Wenn Sie Probleme mit der Abrufeffizienz haben, können Sie die Indexparameter entsprechend anpassen
- Für komplexe Abfragen kann eine schrittweise Schlussfolgerungsstrategie verwendet werden
- Überprüfung der Wissensdarstellung und der Regelkonfiguration, wenn die Schlussfolgerungsergebnisse ungenau sind
KAG-Projekt-Präsentation
1. einleitung
Vor einigen Tagen hat Ant offiziell ein professionelles Framework für Wissensdienste mit dem Namen Knowledge Augmented Generation (KAG: Knowledge Augmented Generation) veröffentlicht, das darauf abzielt, die Vorteile von Knowledge Graph und Vector Retrieval voll auszuschöpfen, um das Problem der bestehenden RAG Einige Herausforderungen mit dem Tech-Stack.
Von den Ameisen dieses Rahmens Warm-up, habe ich mehr Interesse an einigen der Kernfunktionen der KAG, vor allem logische symbolische Argumentation und Wissen Ausrichtung, in der bestehenden Mainstream-RAG-System, diese beiden Punkte der Diskussion scheint nicht zu viel sein, nutzen Sie diese Open-Source, und eilen, um eine Welle zu studieren.
- Adresse der KAG-Arbeit: https://arxiv.org/pdf/2409.13731
- KAG-Projektadresse: https://github.com/OpenSPG/KAG
2) Überblick über den Rahmen
Bevor wir den Code lesen, sollten wir einen kurzen Blick auf die Ziele und die Positionierung des Frameworks werfen.
2.1 Was und warum?
Wenn ich das KAG-Framework sehe, ist die erste Frage, die vielen Menschen in den Sinn kommt, warum es nicht RAG, sondern KAG heißt. Laut verwandten Artikeln und Papieren wurde das KAG-Framework hauptsächlich entwickelt, um einige der aktuellen Herausforderungen zu lösen, mit denen große Modelle in professionellen Wissensdiensten konfrontiert sind:
- LLM ist nicht in der Lage, kritisch zu denken, und es mangelt ihm an Argumentationsfähigkeit
- Fehler in Bezug auf Fakten, Logik, Präzision, Unfähigkeit, vordefinierte Wissensstrukturen des Fachgebiets zu nutzen, um das Verhalten des Modells einzuschränken
- Generische RAGs haben auch Schwierigkeiten, LLM-Illusionen anzugehen, insbesondere verdeckte irreführende Informationen
- Herausforderungen und Anforderungen an die Fachdienste, Fehlen eines strengen und kontrollierten Entscheidungsprozesses
Daher ist das Ameisen-Team der Ansicht, dass ein professioneller Rahmen für Wissensdienste die folgenden Merkmale aufweisen muss:
- Es ist wichtig, die Genauigkeit des Wissens zu gewährleisten, einschließlich der Integrität der Wissensgrenzen und der Klarheit der Wissensstruktur und -semantik;
- Logische Strenge, zeitliche und numerische Sensibilität sind erforderlich;
- Vollständige Kontextinformationen werden auch benötigt, um den Zugang zu vollständigen unterstützenden Informationen zu erleichtern, wenn wissensbasierte Entscheidungen getroffen werden;
Ant's offizielle Positionierung von KAG ist: Professional Domain Knowledge Augmentation Service Framework, speziell für die aktuelle Kombination von großen Sprachmodellen und Wissensgraphen, um die folgenden fünf Bereiche zu verbessern
- Verbessertes Wissen über LLM-Freundlichkeit
- Indizierungsstruktur zwischen Wissensgraphen und ursprünglichen Textfragmenten
- Logik-Symbol-geführte hybride Reasoning-Engine
- Mechanismus zum Wissensabgleich auf der Grundlage semantischer Schlussfolgerungen
- KAG-Modell
Diese Open-Source-Version umfasst die ersten vier Kernfunktionen in ihrer Gesamtheit.
Um auf die Frage der Namensgebung der KAG zurückzukommen, spekuliere ich persönlich, dass das Konzept der Wissensontologie noch gestärkt werden könnte. Aus der offiziellen Beschreibung und der tatsächlichen Code-Implementierung geht hervor, dass das KAG-Framework, ob in der Konstruktions- oder in der Argumentationsphase, ständig vom Wissen selbst ausgeht, um eine vollständige und strenge logische Verknüpfung aufzubauen, um einige der bekannten Probleme des RAG-Technologie-Stacks so weit wie möglich zu verbessern.
2.2 Was (wie) wird erreicht?
Das KAG-Framework besteht aus drei Teilen: KAG-Builder, KAG-Solver und KAG-Model:
- KAG-Builder wird für die Offline-Indizierung verwendet und beinhaltet die oben genannten Features 1 und 2: Erweiterung der Wissensrepräsentation, gemeinsame Indizierungsstruktur.
- Das Modul KAG-Solver umfasst die Funktionen 3 und 4: Logic-Symbol Hybrid Reasoning Engine, Knowledge Alignment Mechanism.
- Das KAG-Modell hingegen versucht, ein durchgängiges KAG-Modell zu erstellen.
3. die Analyse des Quellcodes
Diese offene Quelle umfasst hauptsächlich die beiden Module KAG-Builder und KAG-Solver, die direkt dem Quellcode der beiden Unterverzeichnisse Builder und Solver entsprechen.
Beim eigentlichen Studium des Codes empfiehlt es sich, mit der examples Beginnen Sie zunächst mit einem Verzeichnis, um den Ablauf des gesamten Frameworks zu verstehen, und gehen Sie dann tiefer in bestimmte Module ein. Die Pfade zu den Einstiegsdateien verschiedener Demos sind ähnlich, z. B. kag/examples/medicine/builder/indexer.py zu kag/examples/medicine/solver/evaForMedicine.pyEs ist klar, dass der Builder verschiedene Module kombiniert, während sich der eigentliche Einstiegspunkt für den Solver in der kag/solver/logic/solver_pipeline.py.
3.1 KAG-Builder
Lassen Sie uns zuerst die vollständige Katalogstruktur veröffentlichen
❯ tree .
.
├── __init__.py
├── component
│ ├── __init__.py
│ ├── aligner
│ │ ├── __init__.py
│ │ ├── kag_post_processor.py
│ │ └── spg_post_processor.py
│ ├── base.py
│ ├── extractor
│ │ ├── __init__.py
│ │ ├── kag_extractor.py
│ │ ├── spg_extractor.py
│ │ └── user_defined_extractor.py
│ ├── mapping
│ │ ├── __init__.py
│ │ ├── relation_mapping.py
│ │ ├── spg_type_mapping.py
│ │ └── spo_mapping.py
│ ├── reader
│ │ ├── __init__.py
│ │ ├── csv_reader.py
│ │ ├── dataset_reader.py
│ │ ├── docx_reader.py
│ │ ├── json_reader.py
│ │ ├── markdown_reader.py
│ │ ├── pdf_reader.py
│ │ ├── txt_reader.py
│ │ └── yuque_reader.py
│ ├── splitter
│ │ ├── __init__.py
│ │ ├── base_table_splitter.py
│ │ ├── length_splitter.py
│ │ ├── outline_splitter.py
│ │ ├── pattern_splitter.py
│ │ └── semantic_splitter.py
│ ├── vectorizer
│ │ ├── __init__.py
│ │ └── batch_vectorizer.py
│ └── writer
│ ├── __init__.py
│ └── kg_writer.py
├── default_chain.py
├── model
│ ├── __init__.py
│ ├── chunk.py
│ ├── spg_record.py
│ └── sub_graph.py
├── operator
│ ├── __init__.py
│ └── base.py
└── prompt
├── __init__.py
├── analyze_table_prompt.py
├── default
│ ├── __init__.py
│ ├── ner.py
│ ├── std.py
│ └── triple.py
├── medical
│ ├── __init__.py
│ ├── ner.py
│ ├── std.py
│ └── triple.py
├── oneke_prompt.py
├── outline_prompt.py
├── semantic_seg_prompt.py
└── spg_prompt.py
Der Bereich "Builder" deckt ein breites Spektrum an Funktionen ab, so dass wir uns hier nur mit einer der wichtigeren Komponenten befassen wollen. KAGExtractor Das grundlegende Flussdiagramm ist unten dargestellt:

Hier geht es in erster Linie um die automatische Erstellung eines Wissensgraphen von unstrukturiertem Text zu strukturiertem Wissen anhand eines großen Modells, wobei einige wichtige Schritte kurz beschrieben werden.
- Erstens gibt es das Modul zur Erkennung von Entitäten, bei dem zunächst eine spezifische Erkennung von Entitäten für vordefinierte Wissensgraphentypen und anschließend eine allgemeine Erkennung von benannten Entitäten durchgeführt wird. Dieser zweistufige Erkennungsmechanismus soll sicherstellen, dass sowohl domänenspezifische Entitäten erfasst werden als auch allgemeine Entitäten nicht übersehen werden.
- Der Prozess der Kartierungserstellung wird von der
assemble_sub_graph_with_spg_recordsDie Besonderheit dieser Methode besteht darin, dass das System Attribute von nicht-basischen Typen in Knoten und Kanten im Graphen umwandelt, anstatt sie als ursprüngliche Attribute der Entität beizubehalten. Diese kleine Änderung wird ehrlich gesagt nicht sehr gut verstanden, und bis zu einem gewissen Grad soll sie die Komplexität der Entitäten vereinfachen, aber in der Praxis ist es nicht ganz klar, wie viel Nutzen diese Strategie bringt, und die Komplexität des Builds wird definitiv erhöht. - Standardisierung von Entitäten durch
named_entity_standardizationim Gesang antwortenappend_official_nameDie beiden Methoden werden gemeinsam angewandt. Zunächst werden die Entitätsnamen normalisiert und dann werden diese normalisierten Namen mit den ursprünglichen Entitätsinformationen verknüpft. Dieser Prozess ähnelt der Entity Resolution.
Insgesamt ist die Funktionalität des Builder-Moduls ziemlich nah an der derzeit üblichen Technologie für die Erstellung von Graphen, und die entsprechenden Artikel und der Code sind nicht allzu schwer zu verstehen, so dass ich sie hier nicht wiederholen werde.
3.2 KAG-Auflöser
Solver Teil des Rahmens beinhaltet eine Menge von Kernfunktionen Punkte, vor allem die Logik des symbolischen Denkens im Zusammenhang mit Inhalt, zunächst einen Blick auf die allgemeine Struktur:
❯ tree .
.
├── __init__.py
├── common
│ ├── __init__.py
│ └── base.py
├── implementation
│ ├── __init__.py
│ ├── default_generator.py
│ ├── default_kg_retrieval.py
│ ├── default_lf_planner.py
│ ├── default_memory.py
│ ├── default_reasoner.py
│ ├── default_reflector.py
│ └── lf_chunk_retriever.py
├── logic
│ ├── __init__.py
│ ├── core_modules
│ │ ├── __init__.py
│ │ ├── common
│ │ │ ├── __init__.py
│ │ │ ├── base_model.py
│ │ │ ├── one_hop_graph.py
│ │ │ ├── schema_utils.py
│ │ │ ├── text_sim_by_vector.py
│ │ │ └── utils.py
│ │ ├── config.py
│ │ ├── lf_executor.py
│ │ ├── lf_generator.py
│ │ ├── lf_solver.py
│ │ ├── op_executor
│ │ │ ├── __init__.py
│ │ │ ├── op_deduce
│ │ │ │ ├── __init__.py
│ │ │ │ ├── deduce_executor.py
│ │ │ │ └── module
│ │ │ │ ├── __init__.py
│ │ │ │ ├── choice.py
│ │ │ │ ├── entailment.py
│ │ │ │ ├── judgement.py
│ │ │ │ └── multi_choice.py
│ │ │ ├── op_executor.py
│ │ │ ├── op_math
│ │ │ │ ├── __init__.py
│ │ │ │ └── math_executor.py
│ │ │ ├── op_output
│ │ │ │ ├── __init__.py
│ │ │ │ ├── module
│ │ │ │ │ ├── __init__.py
│ │ │ │ │ └── get_executor.py
│ │ │ │ └── output_executor.py
│ │ │ ├── op_retrieval
│ │ │ │ ├── __init__.py
│ │ │ │ ├── module
│ │ │ │ │ ├── __init__.py
│ │ │ │ │ ├── get_spo_executor.py
│ │ │ │ │ └── search_s.py
│ │ │ │ └── retrieval_executor.py
│ │ │ └── op_sort
│ │ │ ├── __init__.py
│ │ │ └── sort_executor.py
│ │ ├── parser
│ │ │ ├── __init__.py
│ │ │ └── logic_node_parser.py
│ │ ├── retriver
│ │ │ ├── __init__.py
│ │ │ ├── entity_linker.py
│ │ │ ├── graph_retriver
│ │ │ │ ├── __init__.py
│ │ │ │ ├── dsl_executor.py
│ │ │ │ └── dsl_model.py
│ │ │ ├── retrieval_spo.py
│ │ │ └── schema_std.py
│ │ └── rule_runner
│ │ ├── __init__.py
│ │ └── rule_runner.py
│ └── solver_pipeline.py
├── main_solver.py
├── prompt
│ ├── __init__.py
│ ├── default
│ │ ├── __init__.py
│ │ ├── deduce_choice.py
│ │ ├── deduce_entail.py
│ │ ├── deduce_judge.py
│ │ ├── deduce_multi_choice.py
│ │ ├── logic_form_plan.py
│ │ ├── question_ner.py
│ │ ├── resp_extractor.py
│ │ ├── resp_generator.py
│ │ ├── resp_judge.py
│ │ ├── resp_reflector.py
│ │ ├── resp_verifier.py
│ │ ├── solve_question.py
│ │ ├── solve_question_without_docs.py
│ │ ├── solve_question_without_spo.py
│ │ └── spo_retrieval.py
│ ├── lawbench
│ │ ├── __init__.py
│ │ └── logic_form_plan.py
│ └── medical
│ ├── __init__.py
│ └── question_ner.py
└── tools
├── __init__.py
└── info_processor.py
Ich habe die Solver-Eingabedatei bereits erwähnt, daher werde ich den entsprechenden Code hier veröffentlichen:
class SolverPipeline:
def __init__(self, max_run=3, reflector: KagReflectorABC = None, reasoner: KagReasonerABC = None,
generator: KAGGeneratorABC = None, **kwargs):
"""
Initializes the think-and-act loop class.
:param max_run: Maximum number of runs to limit the thinking and acting loop, defaults to 3.
:param reflector: Reflector instance for reflect tasks.
:param reasoner: Reasoner instance for reasoning about tasks.
:param generator: Generator instance for generating actions.
"""
self.max_run = max_run
self.memory = DefaultMemory(**kwargs)
self.reflector = reflector or DefaultReflector(**kwargs)
self.reasoner = reasoner or DefaultReasoner(**kwargs)
self.generator = generator or DefaultGenerator(**kwargs)
self.trace_log = []
def run(self, question):
"""
Executes the core logic of the problem-solving system.
Parameters:
- question (str): The question to be answered.
Returns:
- tuple: answer, trace log
"""
instruction = question
if_finished = False
logger.debug('input instruction:{}'.format(instruction))
present_instruction = instruction
run_cnt = 0
while not if_finished and run_cnt < self.max_run:
run_cnt += 1
logger.debug('present_instruction is:{}'.format(present_instruction))
# Attempt to solve the current instruction and get the answer, supporting facts, and history log
solved_answer, supporting_fact, history_log = self.reasoner.reason(present_instruction)
# Extract evidence from supporting facts
self.memory.save_memory(solved_answer, supporting_fact, instruction)
history_log['present_instruction'] = present_instruction
history_log['present_memory'] = self.memory.serialize_memory()
self.trace_log.append(history_log)
# Reflect the current instruction based on the current memory and instruction
if_finished, present_instruction = self.reflector.reflect_query(self.memory, present_instruction)
response = self.generator.generate(instruction, self.memory)
return response, self.trace_log
insgesamt SolverPipeline.run() Die Methodik umfasst 3 Hauptmodule:Reasoner, Reflector im Gesang antworten GeneratorDie allgemeine Logik ist immer noch sehr klar: Zuerst versucht man, die Frage zu beantworten, dann denkt man darüber nach, ob das Problem gelöst wurde, und wenn nicht, denkt man so lange weiter, bis man eine zufriedenstellende Antwort erhält oder die maximale Anzahl von Versuchen erreicht. Im Grunde genommen ahmt es die allgemeine Denkweise des Menschen beim Lösen komplexer Probleme nach.
Im folgenden Abschnitt werden die drei oben genannten Module näher analysiert.
3.3 Begründer
Das Inferenzmodul ist wahrscheinlich der komplexeste Teil des gesamten Systems, und sein Hauptcode lautet wie folgt:
class DefaultReasoner(KagReasonerABC):
def __init__(self, lf_planner: LFPlannerABC = None, lf_solver: LFSolver = None, **kwargs):
def reason(self, question: str):
"""
Processes a given question by planning and executing logical forms to derive an answer.
Parameters:
- question (str): The input question to be processed.
Returns:
- solved_answer: The final answer derived from solving the logical forms.
- supporting_fact: Supporting facts gathered during the reasoning process.
- history_log: A dictionary containing the history of QA pairs and re-ranked documents.
"""
# logic form planing
lf_nodes: List[LFPlanResult] = self.lf_planner.lf_planing(question)
# logic form execution
solved_answer, sub_qa_pair, recall_docs, history_qa_log = self.lf_solver.solve(question, lf_nodes)
# Generate supporting facts for sub question-answer pair
supporting_fact = '\n'.join(sub_qa_pair)
# Retrieve and rank documents
sub_querys = [lf.query for lf in lf_nodes]
if self.lf_solver.chunk_retriever:
docs = self.lf_solver.chunk_retriever.rerank_docs([question] + sub_querys, recall_docs)
else:
logger.info("DefaultReasoner not enable chunk retriever")
docs = []
history_log = {
'history': history_qa_log,
'rerank_docs': docs
}
if len(docs) > 0:
# Append supporting facts for retrieved chunks
supporting_fact += f"\nPassages:{str(docs)}"
return solved_answer, supporting_fact, history_log
Daraus ergibt sich ein allgemeines Flussdiagramm für das Argumentationsmodul: (Logik wie Fehlerbehandlung wurde weggelassen)

Es ist leicht zu erkennen, dassDefaultReasoner.reason() Die Methodik gliedert sich im Wesentlichen in drei Schritte:
- Logic Form Planning (LFP): umfasst hauptsächlich
LFPlanner.lf_planing - Logic Form Execution (LFE): umfasst hauptsächlich
LFSolver.solve - Document Reranking: umfasst hauptsächlich
LFSolver.chunk_retriever.rerank_docs
Jeder der drei Schritte wird im Folgenden im Detail analysiert.
3.3.1 Logische Form der Planung
DefaultLFPlanner.lf_planing() Methode wird in erster Linie verwendet, um eine Abfrage in eine Reihe unabhängiger logischer Formen zu zerlegen (lf_nodes: List[LFPlanResult]).
lf_nodes: List[LFPlanResult] = self.lf_planner.lf_planing(question)
Die Umsetzungslogik ist zu finden in kag/solver/implementation/default_lf_planner.pyDer Schwerpunkt liegt dabei auf llm_output Führen Sie ein regularisiertes Parsing durch oder rufen Sie LLM auf, um eine neue logische Form zu erzeugen, falls diese nicht vorhanden ist.
Hier ist etwas, das Sie im Auge behalten sollten kag/solver/prompt/default/logic_form_plan.py relevante Angelegenheiten LogicFormPlanPrompt Bei der detaillierten Ausgestaltung des Projekts geht es darum, wie ein komplexes Problem in mehrere Unterabfragen und ihre entsprechenden logischen Formen zerlegt werden kann.
3.3.2 Logik Form Ausführung
LFSolver.solve() Es werden Methoden verwendet, um bestimmte logische Probleme zu lösen, die Antworten, Paare von Teilproblemantworten, zugehörige Rückrufdokumente und Historie usw. zurückgeben.
solved_answer, sub_qa_pair, recall_docs, history_qa_log = self.lf_solver.solve(question, lf_nodes)
Vertiefungkag/solver/logic/core_modules/lf_solver.pyDer Abschnitt mit dem Quellcode, der zu finden ist LFSolver Die Klasse (Logical Form Solver) ist die Kernklasse des gesamten Argumentationsprozesses und ist für die Ausführung der logischen Form (LF) und die Generierung der Antwort verantwortlich:
- Die wichtigsten Methoden sind
solvedie eine Anfrage und eine Reihe von logischen Formularknoten (List[LFPlanResult]). - ausnutzen
LogicExecutorum logische Formen auszuführen, die Antworten, Wissensgraphenpfade und Historien erzeugen. - Verarbeitet Unterabfragen und Antwortpaare, sowie die dazugehörige Dokumentation.
- Fehlerbehandlung und Fallback-Strategie: Wenn keine Antwort oder relevante Dokumentation gefunden wird, wird versucht, die
chunk_retrieverRückruf der entsprechenden Dokumente.
Die wichtigsten Prozesse sind die folgenden:

darunter auch LogicExecutor ist eine der kritischeren Klassen, daher hier der Kerncode:
executor = LogicExecutor(
query, self.project_id, self.schema,
kg_retriever=self.kg_retriever,
chunk_retriever=self.chunk_retriever,
std_schema=self.std_schema,
el=self.el,
text_similarity=self.text_similarity,
dsl_runner=DslRunnerOnGraphStore(...),
generator=self.generator,
report_tool=self.report_tool,
req_id=generate_random_string(10)
)
kg_qa_result, kg_graph, history = executor.execute(lf_nodes, query)
- Umsetzungslogik
LogicExecutorDer entsprechende Code für die Klasse befindet sich in der Dateikag/solver/logic/core_modules/lf_executor.py. seineexecuteDer Hauptausführungsablauf der Methode ist nachstehend dargestellt.
Dieser Ausführungsablauf demonstriert eine doppelte Suchstrategie: Vorrangige Verwendung von strukturierten Graphdaten für die Suche und Inferenz und Rückgriff auf unstrukturierte Textinformationen, wenn der Graph nicht beantwortbar ist.
Das System versucht zunächst, die Frage durch den Wissensgraphen zu beantworten, und zwar für jeden Knoten des logischen Ausdrucks mit Hilfe verschiedener Aktoren (unter Einbeziehung derdeduceundmathundsortundretrievalundoutputWenn der Graph keine zufriedenstellende Antwort liefert (und "Ich weiß nicht" zurückgibt), greift das System auf die Textblockabfrage zurück: Es verwendet die zuvor erhaltenen NER-Ergebnisse (named entity) als Abfrageankerpunkt und kombiniert sie mit den historischen Q&A-Datensätzen, um eine kontextverbesserte Abfrage zu erstellen, die dann durch das System geleitet wird.chunk_retrieverGenerieren Sie die Antwort auf der Grundlage des abgerufenen Dokuments neu.
Durch die Kombination von strukturierten Wissensgraphen mit unstrukturierten Textdaten ist dieses hybride Retrieval in der Lage, möglichst vollständige und kontextuell kohärente Antworten zu liefern und gleichzeitig die Genauigkeit zu erhalten. - Kernkomponente
Zusätzlich zu der oben beschriebenen spezifischen Implementierungslogik ist zu beachten, dass dieLogicExecutorDie Initialisierung erfordert die Übergabe mehrerer Komponenten. Aus Platzgründen hier nur eine kurze Beschreibung der Kernfunktion jeder Komponente, die spezifische Implementierung kann im Quellcode nachgelesen werden.- kg_retriever: Wissensgraphen-Retriever
Beratungkag/solver/implementation/default_kg_retrieval.pyMitteKGRetrieverByLlm(KGRetrieverABC)das die Suche nach Entitäten und Beziehungen implementiert, wobei mehrere Abgleichsmethoden wie exakt/fuzzy, One-Hop-Subgraphen usw. zum Einsatz kommen. - chunk_retriever: Textchunk-Retriever
Beratungkag/common/retriever/kag_retriever.pyMitteDefaultRetriever(ChunkRetrieverABC)Der Code hier ist es wert, untersucht zu werden. Erstens ist er in Bezug auf die Entity-Verarbeitung standardisiert, und außerdem bezieht sich das Retrieval hier auf HippoRAG, wobei eine hybride Retrieval-Strategie angewandt wird, die DPR (Dense Passage Retrieval) und PPR (Personalized PageRank) kombiniert, und dann weiter auf der Fusion von DPR- und PPR-Score basiert. Außerdem wird hier eine hybride Suchstrategie angewandt, die DPR (Dense Passage Retrieval) und PPR (Personalized PageRank) kombiniert, und durch die anschließende Fusion von DPR- und PPR-basierten Scores wird die dynamische Gewichtung der beiden Suchmethoden weiter verbessert. - entity_linker (el): Entitätslinker
Beratungkag/solver/logic/core_modules/retriver/entity_linker.pyMitteDefaultEntityLinker(EntityLinkerBase)Die Idee der Konstruktion von Merkmalen vor der Parallelisierung der Verarbeitung von Entity-Links wird hier verwendet. - dsl_runner: Graph-Datenbank-Abfrage
Beratungkag/solver/logic/core_modules/retriver/graph_retriver/dsl_executor.pyMitteDslRunnerOnGraphStore(DslRunner)verantwortlich für die strukturierte Abfrage Informationen in einem bestimmten Graphen-Datenbank Abfrageanweisung, wird dieses Stück die zugrunde liegenden spezifischen Graphen-Datenbank, sind die Details relativ komplex, aber nicht zu viel beteiligt.
- kg_retriever: Wissensgraphen-Retriever
Aus dem obigen Code und Flussdiagramm geht hervor, dass die gesamte Logic Form Execution (LFE)-Schleife eine hierarchische Verarbeitungsarchitektur aufweist:
- das Dach eines Gebäudes
LFSolverVerantwortlich für den Gesamtprozess - Mesosphäre
LogicExecutorVerantwortlich für die Implementierung bestimmter logischer Formulare (LF) - Boden (eines Stapels)
DSL RunnerVerantwortlich für die Interaktion mit der Graphdatenbank
3.3.3 Dokument Reranking
Wenn Sie die Option chunk_retrieverwerden auch die zurückgerufenen Dokumente neu geordnet.
if self.lf_solver.chunk_retriever:
docs = self.lf_solver.chunk_retriever.rerank_docs(
[question] + sub_querys, recall_docs
)
3.4 Reflektor
Reflector Klasse implementiert in erster Linie die _can_answer zusammen mit _refine_query Zwei Methoden, die erste, um festzustellen, ob eine Frage beantwortet werden kann, und die zweite, um die Zwischenergebnisse einer Multi-Hop-Anfrage zu optimieren, damit die endgültige Antwort generiert werden kann.
Verwandte Referenzen zur Implementierung kag/solver/prompt/default/resp_judge.py zusammen mit kag/solver/prompt/default/resp_reflector.py Diese beiden Prompt-Dateien sind einfacher zu verstehen.
3.5 Generator
Heftklammer LFGenerator wählt auf der Grundlage verschiedener Szenarien (mit oder ohne Wissensgraphen, mit oder ohne Dokumente usw.) dynamisch Wortvorlagen aus und generiert Antworten auf die entsprechenden Fragen.
Die entsprechenden Implementierungen befinden sich in der kag/solver/logic/core_modules/lf_generator.pyDer Code ist relativ intuitiv und wird nicht wiederholt.
4. einige Überlegungen
Ant dieser Open-Source-KAG-Framework, das sich auf professionelle Domain Knowledge Enhancement Services, die symbolische Argumentation, Wissen Ausrichtung und eine Reihe von innovativen Punkten, umfassende Studie, fühle ich mich, dass der Rahmen ist besonders geeignet für die Notwendigkeit für strenge Beschränkungen für das Schema des professionellen Wissens der Szene, sowohl in der Indizierung und Abfrage der Bühne, der gesamte Workflow wird immer wieder verstärkt einen Standpunkt: Sie müssen von der eingeschränkten Wissensbasis, um den Bau Graphen zu erstellen oder logische Schlussfolgerungen zu ziehen. Diese Denkweise soll bis zu einem gewissen Grad das Problem des fehlenden Fachwissens sowie die Illusion großer Modelle lindern.
Obwohl es einige Unterschiede zwischen dem technischen Weg und GraphRAG gibt, kann KAG bis zu einem gewissen Grad als eine Praxis in der Richtung von Wissensverbesserungsdiensten im professionellen Bereich von GraphRAG angesehen werden, insbesondere um die Unzulänglichkeiten beim Wissensabgleich und bei der Argumentation zu kompensieren. Obwohl es einige Unterschiede zwischen KAG und GraphRAG in Bezug auf die Technologie gibt, kann KAG als eine Praxis von GraphRAG in der Richtung von Wissensverbesserungsdiensten im professionellen Bereich angesehen werden, insbesondere um die Defizite beim Wissensabgleich und der Argumentation zu kompensieren. Unter diesem Gesichtspunkt ziehe ich es vor, es Knowledge constrained GraphRAG zu nennen.
Native GraphRAG, mit hierarchischer Zusammenfassung auf der Grundlage verschiedener Gemeinschaften, kann relativ abstrakte Fragen auf hoher Ebene beantworten, aber auch wegen der übermäßigen Konzentration auf abfrageorientierte Zusammenfassung (QFS) kann das Framework bei feinkörnigen Sachfragen nicht gut abschneiden, und in Anbetracht der Kostenfrage hat das native GraphRAG hat eine Menge Herausforderungen im Pendant-Bereich, während das KAG-Framework mehr Optimierungen in der Graphen-Konstruktionsphase vorgenommen hat, wie z.B. Entity-Alignment und Standardisierungsoperationen auf der Basis spezifischer Schemata, und in der Abfragephase auch Knowledge Graph Reasoning auf der Basis symbolischer Logik einführt, obwohl symbolisches Reasoning im Graphenbereich schon eine ganze Weile erforscht wird, obwohl es noch nicht wirklich auf RAG-Szenarien angewendet wurde. Die Stärkung der RAG-Reasoning-Fähigkeit ist eine Forschungsrichtung, der der Autor optimistischer gegenübersteht, und vor einiger Zeit hat Microsoft die vier Schichten der Reasoning-Fähigkeit des RAG-Technologie-Stacks zusammengefasst:
- Level-1 Explizite Fakten, Explizite Fakten
- Ebene-2 Implizite Fakten, verborgene Fakten
- Stufe-3 Interpretierbare Begründungen, Interpretierbare (Pendant) Begründungen
- Level-4 Hidden Rationales, unsichtbare (hängende Domäne) Rationales
Gegenwärtig sind die Schlussfolgerungsfähigkeiten der meisten RAG-Rahmenwerke noch auf die Ebene 1 beschränkt, und die darüber liegenden Ebenen 3 und 4 betonen die Bedeutung des vertikalen Schlussfolgerns. Die Schwierigkeit liegt in der mangelnden Kenntnis großer Modelle im vertikalen Bereich, und die Einführung des symbolischen Schlussfolgerns in der Abfragestufe des KAG-Rahmenwerks kann bis zu einem gewissen Grad als eine Erkundung dieser Richtung angesehen werden, und es ist abzusehen, dass in den folgenden Jahren eine Welle neuer Forschungen im Bereich des RAG-Schlussfolgerns durchgeführt werden wird. Es ist vorhersehbar, dass das RAG-Reasoning eine neue Forschungswelle auslösen wird, wie z.B. die weitere Fusion der modelleigenen Reasoning-Fähigkeiten, wie RL oder CoT, usw. Zum jetzigen Zeitpunkt wurden einige Versuche in der Szene unternommen, wobei es noch mehr oder weniger Einschränkungen gibt.
Zusätzlich zur Argumentationssitzung verweist die KAG in Retrieval HippoRAG Die Anwendung einer hybriden DPR- und PPR-Retrievalstrategie und die effiziente Nutzung von PageRank zeigen die Vorteile von Wissensgraphen gegenüber dem traditionellen Vektorretrieval, und es ist davon auszugehen, dass in Zukunft weitere Graphretrieval-Algorithmen in die RAG-Technologie integriert werden.
Natürlich ist davon auszugehen, dass sich der KAG-Rahmen noch in einem frühen und schnellen Iterationsstadium befindet, und es sollte noch Raum für Diskussionen über die konkrete Umsetzung der Funktionen geben, wie z. B. die Frage, ob die bestehende Logic Form Planning und Logic Form Execution eine vollständige theoretische Unterstützung auf der Entwurfsebene haben und ob es angesichts komplexer Probleme zu einer unzureichenden Dekomposition und einem Ausführungsversagen kommen wird. Ob es unzureichende Zerlegung, Ausführung Scheitern, aber diese Grenze Definition und Robustheit Fragen sind in der Regel sehr schwierig zu behandeln, sondern erfordert auch eine Menge von Versuch und Irrtum Kosten, wenn die gesamte Argumentation Kette zu komplex ist, kann die ultimative Ausfallrate höher sein, nachdem alle, eine Vielzahl von Abbau zurück zu der Strategie ist nur ein gewisses Maß an Linderung des Problems. Darüber hinaus ist mir aufgefallen, dass der GraphStore am unteren Ende des Frameworks tatsächlich eine Schnittstelle für inkrementelle Aktualisierungen reserviert hat, aber die Anwendung auf der oberen Schicht zeigte nicht die entsprechenden Fähigkeiten, was auch eine Funktion ist, die nach meinem persönlichen Verständnis von der GraphRAG-Gemeinschaft stärker gefordert wird.
Im Großen und Ganzen gilt das KAG-Framework als ein sehr hartes Stück Arbeit in der jüngeren Vergangenheit, das eine Menge innovativer Punkte enthält, und der Code hat wirklich eine Menge Detailpolitur erfahren, was als wichtiger Impuls für den Landeprozess des RAG-Technologiestacks angesehen wird.
© urheberrechtliche Erklärung
Artikel Copyright AI-Austauschkreis Alle, bitte nicht ohne Erlaubnis vervielfältigen.
Ähnliche Artikel

Keine Kommentare...