
Aufgerollt! Langtext-Vektor-Modelle Chunking-Strategien Wettbewerb
Das Langtext-Vektormodell kann zehn Seiten Text in einem einzigen Vektor kodieren. Das klingt mächtig, aber ist es auch wirklich praktisch?
Viele Leute denken... Nicht unbedingt.
Ist es in Ordnung, sie direkt zu verwenden? Sollte es gechunked werden? Wie teilt man am effizientesten auf? In diesem Artikel werden wir die verschiedenen Chunking-Strategien für lange Textvektormodelle eingehend erörtern, die Vor- und Nachteile analysieren und Ihnen helfen, Fallstricke zu vermeiden.
Das Problem der Vektorisierung langer Texte
Zunächst wollen wir sehen, welche Probleme bei der Komprimierung eines ganzen Artikels in einen einzigen Vektor auftreten.
Ein Beispiel für den Aufbau eines Dokumentensuchsystems: Ein einzelner Artikel kann mehrere Themen enthalten. Dieser Blog über den ICML 2024-Teilnehmerbericht enthält beispielsweise eine Einführung in die Konferenz, eine Präsentation der Arbeit von Jina AI (jina-clip-v1) und Zusammenfassungen von anderen Forschungsarbeiten. Wenn der gesamte Artikel in einen einzigen Vektor umgewandelt wird, mischt dieser Vektor Informationen aus drei verschiedenen Themen:
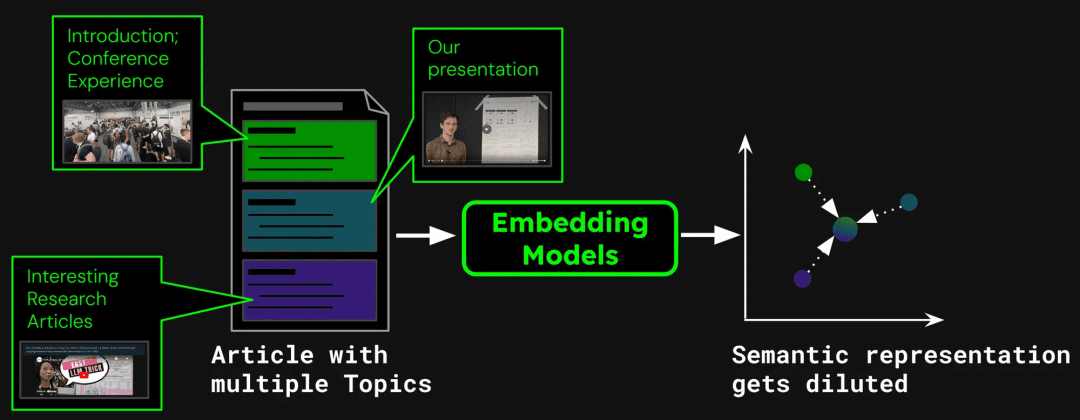
Dies kann zu den folgenden Problemen führen:
1. die Verwässerung der Repräsentation
weist darauf hin, dass die Verdünnung die Präzision der Textvektoren beeinträchtigt. Obwohl der Blogbeitrag mehrere Themen enthält, ist dieAllerdings konzentrieren sich die Suchanfragen der Nutzer in der Regel nur auf eine dieser beiden Möglichkeiten. Die Darstellung des gesamten Artikels durch einen einzigen Vektor ist gleichbedeutend mit der Komprimierung aller Themeninformationen auf einen einzigen Punkt im Vektorraum. Je mehr Text der Eingabe des Modells hinzugefügt wird, desto mehr repräsentiert dieser Vektor das Gesamtthema des Artikels und verwässert die Details bestimmter Passagen oder Themen. Das ist so, als würde man mehrere Pigmente zu einer einzigen Farbe mischen, was es dem Benutzer erschwert, eine bestimmte Farbe aus der Mischung zu erkennen, wenn er sie zu finden versucht.
2. begrenzte Kapazität
Die vom Modell erzeugten Vektordimensionen sind fest, und lange Texte enthalten viele Informationen, was unweigerlich zu einem Informationsverlust während des Transformationsprozesses führt. Es ist, als würde man eine hochauflösende Karte auf eine Briefmarke komprimieren, und viele Details sind nicht sichtbar.
3. der Verlust von Informationen
Viele Langtextmodelle können nur bis zu 8192 Token verarbeiten. Ein besserer Text muss abgeschnitten werden, in der Regel am Ende, und wenn die Schlüsselinformationen am Ende des Dokuments stehen, kann die Suche fehlschlagen.
4. die Anforderungen an die Segmentierung
Bei einigen Anwendungen müssen nur bestimmte Textsegmente vektorisiert werden, z. B. bei Frage-Antwort-Systemen, bei denen nur die Absätze mit den Antworten für die Vektorisierung extrahiert werden müssen. In diesem Fall ist das Chunking des Textes weiterhin erforderlich.
3 Strategien zur Verarbeitung von Langtexten
Bevor wir mit dem Experiment beginnen, definieren wir zunächst drei Chunked-Strategien, um begriffliche Verwirrung zu vermeiden:
1. kein Chunking:Kodiert den gesamten Text direkt in einen einzigen Vektor.
2. naives Chunking:Der Text wird zunächst in mehrere Textabschnitte unterteilt und separat vektorisiert. Zu den häufig verwendeten Methoden gehört das Chunking mit fester Größe, bei dem der Text in feste Teile aufgeteilt wird. Token Anzahl der Chunks; satzbasiertes Chunking: Chunking in Sätzen; semantikbasiertes Chunking: Chunking auf der Grundlage semantischer Informationen. In diesem Experiment werden Chunks fester Größe verwendet.
3. spätes Chunking:Dabei handelt es sich um eine neue Methode, bei der der gesamte Text vor dem Chunking durchgelesen wird und die aus zwei Hauptschritten besteht:
- Vollständiger Text des KodexKodierung des gesamten Dokuments, um eine Vektordarstellung jedes Tokens zu erhalten, wobei die vollständigen Kontextinformationen erhalten bleiben.
- Bündelung von StückenGenerierung von Vektoren für jeden Textblock durch Durchschnittsbildung der Token-Vektoren desselben Textblocks entsprechend der Chunk-Grenze. Da der Vektor jedes Tokens im Kontext des gesamten Textes erzeugt wird, kann die späte Partitionierung die Kontextinformationen zwischen den Blöcken erhalten.
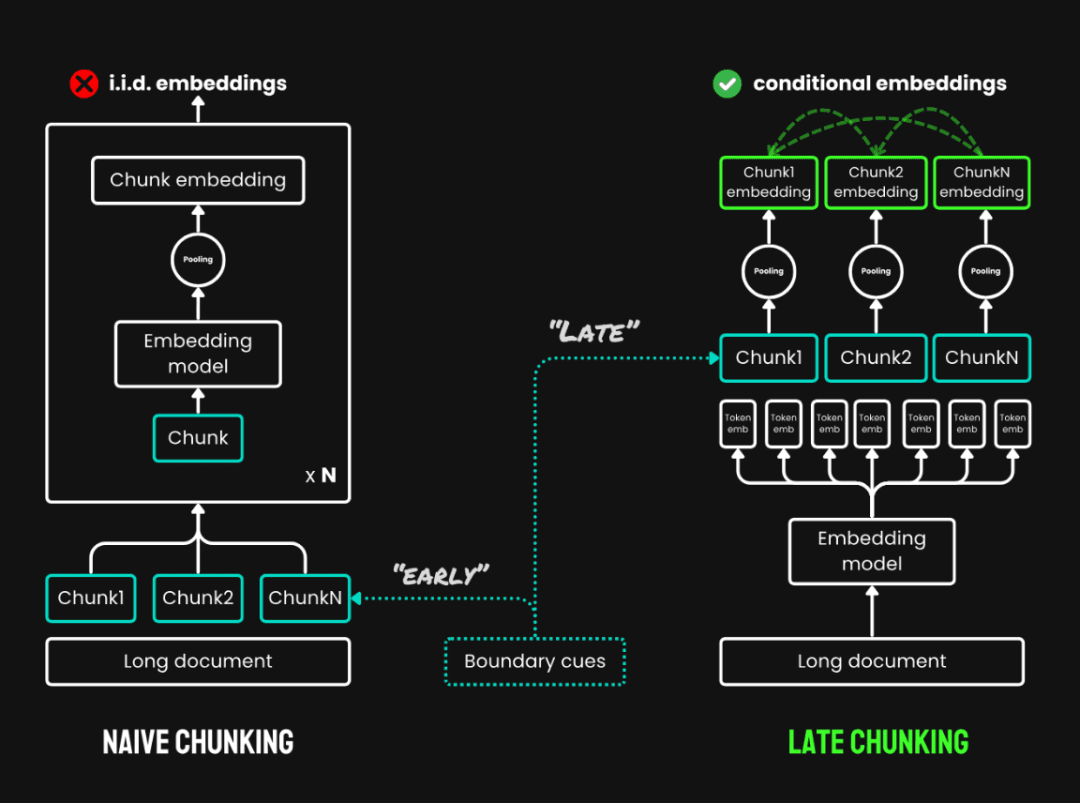
Spätes Splitting vs. einfaches Chunking
Bei Modellen, die die maximale Eingabelänge überschreiten (z.B. 8192 Token), verwenden wir die Langes spätes ChunkingIn diesem Fall wird dem Late-Splitting ein Vorsegmentierungsschritt hinzugefügt, bei dem das Dokument zunächst in mehrere überlappende Makroblöcke aufgeteilt wird, die jeweils eine Länge innerhalb des verarbeitbaren Bereichs des Modells haben. Dann wird innerhalb jedes Makroblocks eine Standard-Spätaufteilungsstrategie (Kodierung und Pooling) angewendet. Die Überlappung zwischen den Makroblöcken wird genutzt, um die Kontinuität der Kontextinformationen zu gewährleisten.
Late Score Specific Implementation Code: https://github.com/jina-ai/late-chunking在 Notebook Experience: https://colab.research.google.com/drive/1iz3ACFs5aLV2O_ uZEjiR1aHGlXqj0HY7?usp=sharing
Welches ist also die beste Methode?
Zu Vergleichszwecken haben wir den Datensatz auf 5 Datensätzen verwendet, wobei die jina-embeddings-v3 In den Experimenten wurden alle Langtexte auf die maximale Eingabelänge des Modells (8192 Token) gekürzt und in Textblöcke von jeweils 64 Token unterteilt.

Die 5 Testdatensätze entsprechen auch 5 verschiedenen Retrievalaufgaben
Die nachstehende Abbildung zeigt den Leistungsunterschied zwischen den drei Methoden bei verschiedenen Aufgaben, wobei keine Methode in allen Fällen die beste ist und die Wahl von der jeweiligen Aufgabe abhängt.
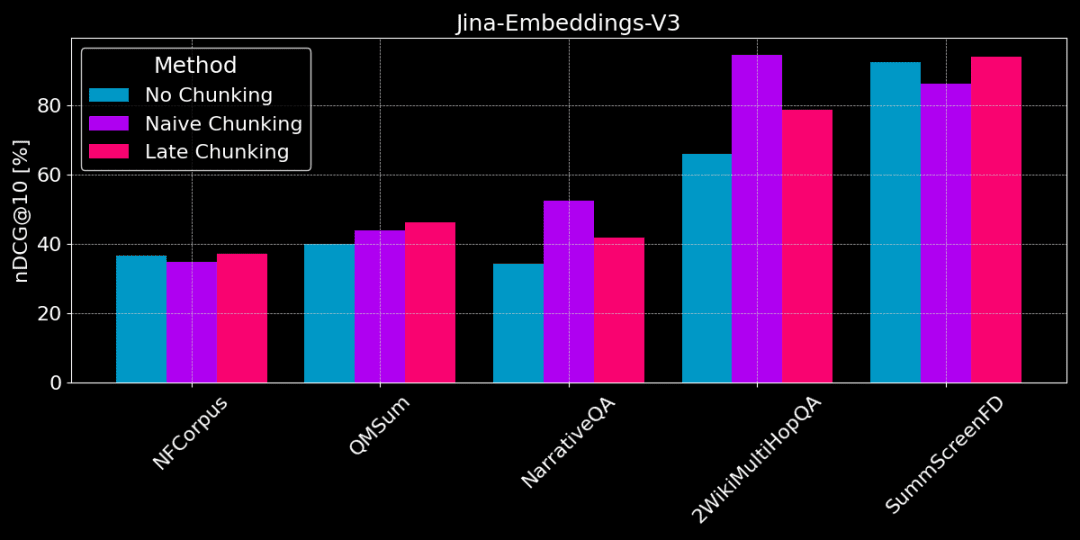
Kein Chunking vs. einfaches Chunking vs. spätes Chunking
👩🏫 Finden Sie konkrete Fakten, einfaches Chunking ist gut.
Wenn spezifische, lokalisierte Sachinformationen aus Text extrahiert werden müssen (z. B. "Wer hat etwas gestohlen?") ), Datensätze wie QMSum, NarrativeQA und 2WikiMultiHopQA, schneidet das einfache Chunking besser ab als die Vektorisierung des gesamten Dokuments. Da Antworten in der Regel in einem bestimmten Teil des Textes zu finden sind, kann Plain Chunking den Textabschnitt, der die Antwort enthält, genauer lokalisieren, ohne durch andere Fremdinformationen abgelenkt zu werden.
Allerdings wird beim Chunking auch der Kontext abgeschnitten, und es gehen möglicherweise globale Informationen verloren, die für die korrekte Analyse von Verweisbeziehungen und Referenzen im Text erforderlich sind.
👩🏫 Der Artikel ist thematisch kohärent, und späte Bewertungen sind besser.
Die späte Markierung ist effektiver, wenn das Thema klar und die Struktur des Textes kohärent ist. Da die späte Einteilung den Kontext berücksichtigt, ermöglicht sie ein besseres Verständnis der Bedeutung und Relevanz der einzelnen Teile, einschließlich der Verweisbeziehungen innerhalb langer Texte.
Wenn der Artikel jedoch viele irrelevante Inhalte enthält, wird bei der späten Bewertung das "Rauschen" berücksichtigt, was zu einem Leistungsrückgang und einer Verschlechterung der Genauigkeit führt. NarrativeQA und 2WikiMultiHopQA schneiden zum Beispiel nicht so gut ab wie einfaches Chunking, weil diese Artikel zu viele irrelevante Informationen enthalten.
Hat die Größe der Chunks einen Einfluss?
Die folgende Abbildung zeigt die Leistung der einfachen Chunking- und der späten Chunking-Methode auf verschiedenen Datensätzen mit unterschiedlichen Chunk-Größen:
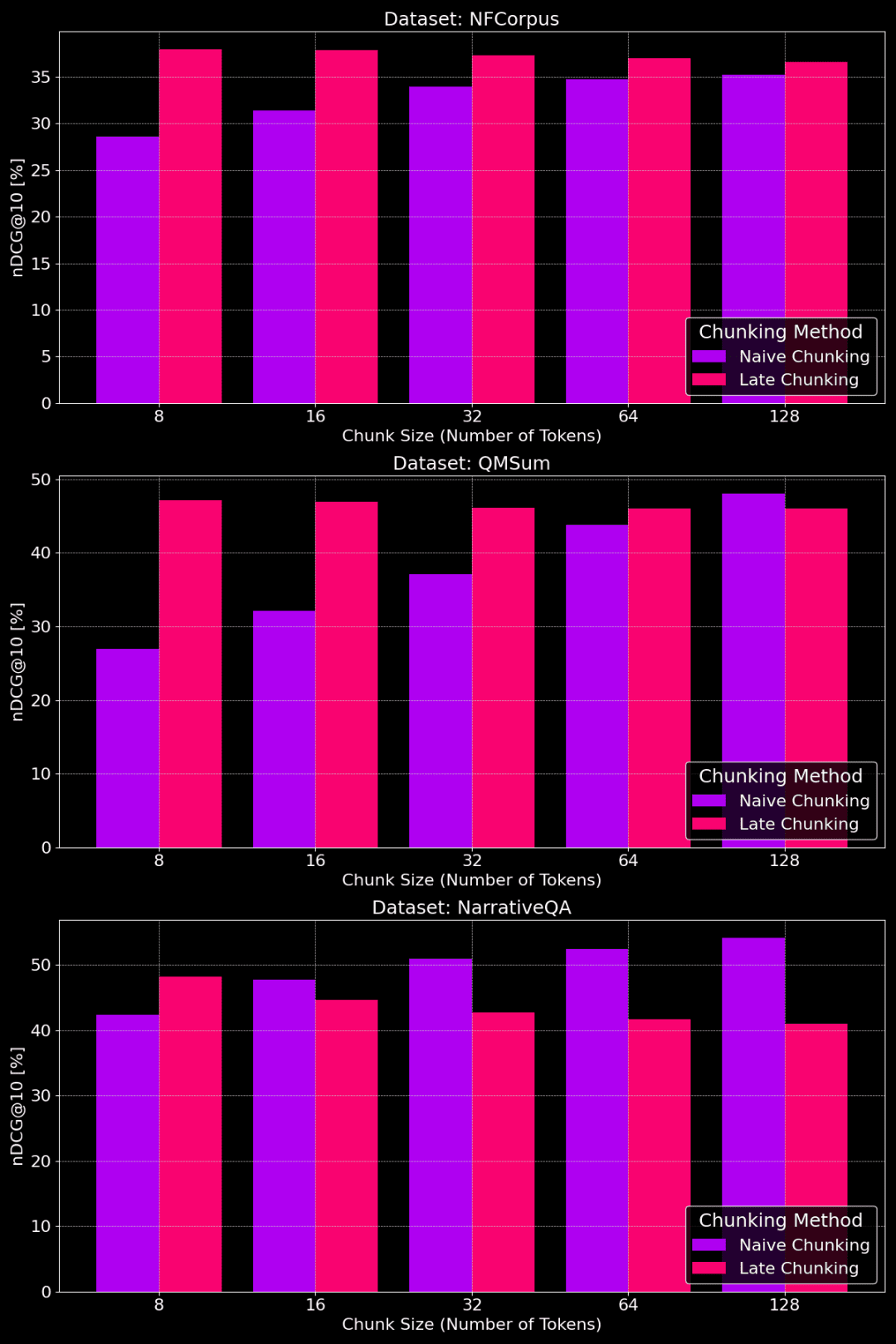
Leistungsvergleich zwischen einfachem Chunking und spätem Chunking für verschiedene Chunk-Größen
Wie aus der Abbildung ersichtlich ist, hängt die optimale Chunk-Größe davon ab, wie der jeweilige Datensatz aussieht.
Bei der Late-Splitting-Methode erfassen kleinere Chunks die Kontextinformationen besser und funktionieren daher besser. Insbesondere wenn der Datensatz viele Inhalte enthält, die nichts mit dem Thema zu tun haben (wie im Fall des NarrativeQA-Datensatzes), kann zu viel Kontext zu Rauschen führen und die Leistung beeinträchtigen.
Beim einfachen Chunking funktionieren größere Chunks manchmal besser, weil die enthaltenen Informationen umfassender und weniger verlustbehaftet sind. Manchmal sind die Chunks jedoch zu groß und die Informationen sind zu unübersichtlich, was wiederum die Abrufgenauigkeit verringert. Die optimale Chunk-Größe muss also an den jeweiligen Datensatz und die Aufgabe angepasst werden, und es gibt keine pauschale Antwort.
Wenn wir die Vor- und Nachteile der verschiedenen Chunking-Strategien kennen, wie wählen wir dann die richtige aus?
1. wo ist eine Volltextvektorisierung (ohne Chunking) sinnvoll?
- Das Thema ist einzigartig, wobei die wichtigsten Informationen am Anfang stehen:Bei strukturierten Nachrichten beispielsweise befinden sich die wichtigsten Informationen oft in den Überschriften und den ersten Absätzen. In diesem Fall liefert die direkte Verwendung der Volltextvektorisierung in der Regel gute Ergebnisse, da das Modell die wichtigsten Informationen erfasst.
- Im Allgemeinen hat es keine Auswirkungen auf die Suchergebnisse, wenn so viel Textinhalt wie möglich in das Modell aufgenommen wird. Allerdings neigen Modelle für lange Texte dazu, dem Anfangsteil (Titel, Einleitung usw.) mehr Aufmerksamkeit zu schenken, und die Informationen im Mittel- und Endteil werden möglicherweise ignoriert. Wenn sich also die wichtigsten Informationen in der Mitte oder am Ende des Artikels befinden, ist diese Methode weit weniger effektiv.
- Detaillierte Versuchsergebnisse finden Sie in:https://jina.ai/news/still-need-chunking-when-long-context-models-can-do-it-all
2. wo ist Naive Chunking angebracht?
- Vielfalt der Themen, Notwendigkeit, spezifische Informationen abzurufenWenn Ihr Text mehr als ein Thema enthält oder wenn eine Benutzerabfrage auf einen bestimmten Sachverhalt im Text abzielt, ist einfaches Chunking eine gute Wahl. Es kann die Verwässerung von Informationen wirksam vermeiden und die Genauigkeit beim Abrufen bestimmter Informationen verbessern.
- Notwendigkeit, lokalisierte Textausschnitte anzuzeigenÄhnlich wie bei einer Suchmaschine ist eine Chunking-Strategie erforderlich, um Textausschnitte, die sich auf die Suchanfrage beziehen, in den Ergebnissen anzuzeigen.
- Außerdem wirkt sich das Chunking auf den Speicherplatz und die Verarbeitungszeit aus, da mehr Textblöcke vektorisiert werden müssen.
3. wie passt Late Chunking dazu?
- Thematische Kohärenz, Bedarf an kontextuellen InformationenBei langen Texten mit zusammenhängenden Themen, wie z. B. Aufsätzen, langen Berichten usw., kann die Methode der späten Partitionierung die Kontextinformationen effektiv beibehalten, um die Gesamtsemantik des Textes besser zu verstehen. Sie eignet sich besonders für Aufgaben, bei denen es darauf ankommt, die Beziehung zwischen verschiedenen Teilen eines Textes zu verstehen, z. B. beim Leseverstehen und beim semantischen Abgleich langer Texte.
- Notwendigkeit, lokale Details mit globaler Semantik in Einklang zu bringenDie Methode der späten Aufteilung kann lokale Details und globale Semantik in kleineren Chunk-Größen effektiv ausgleichen und in vielen Fällen bessere Ergebnisse erzielen als die beiden anderen Methoden. Es ist jedoch zu beachten, dass die späte Partitionierung die Wirkung beeinträchtigt, wenn der Artikel viele irrelevante Inhalte enthält, da solche irrelevanten Informationen berücksichtigt werden.
zu einem Urteil gelangen
Die Auswahl einer Vektorisierungsstrategie für Langtexte ist ein komplexes Thema, für das es keine einheitliche Lösung gibt. Sie erfordert die Berücksichtigung von Datenmerkmalen und Abrufzielen, einschließlich der bereits erwähnten Textlänge, der Anzahl der Themen und der Lage der Schlüsselinformationen.
In diesem Beitrag hoffen wir, einen vergleichenden Analyserahmen für verschiedene Chunking-Strategien zu schaffen und einige Referenzen durch experimentelle Ergebnisse zu liefern. In der praktischen Anwendung können Sie weitere Experimente vergleichen und die am besten geeignete Strategie für Ihr Szenario wählen.
Wenn Sie an der Vektorisierung von Langtext interessiert sindjina-embeddings-v3Mit seinen fortschrittlichen Funktionen zur Verarbeitung langer Texte, der Unterstützung mehrerer Sprachen und der späten Auswertung ist es einen Versuch wert.
© urheberrechtliche Erklärung
Artikel Copyright AI-Austauschkreis Alle, bitte nicht ohne Erlaubnis vervielfältigen.
Verwandte Beiträge



Keine Kommentare...