Feinabstimmung des DeepSeek R1-Modells zur Ermöglichung präziser medizinischer Fragen und Antworten: Freisetzung des Potenzials von Open-Source-KI

DeepSeek eine Reihe von fortschrittlichen Inferenzmodellen eingeführt, um die Position von OpenAI in der Branche herauszufordern, undVöllig kostenlos, keine NutzungsbeschränkungenDas Programm ist so konzipiert, dass es allen Nutzern zugute kommt.
In diesem Artikel beschreiben wir die Feinabstimmung des DeepSeek-R1-Distill-Llama-8B-Modells anhand des Datensatzes Medical Mind Chain von Hugging Face. Diese Lite-Version des DeepSeek-R1 Modell, das durch eine Feinabstimmung des Llama 3 8B Modells auf die von DeepSeek-R1 generierten Daten erhalten wurde, zeigt eine bessere Inferenz als das ursprüngliche Modell.

DeepSeek R1 Entschlüsselung
DeepSeek-R1 und DeepSeek-R1-Zero übertreffen das o1-Modell von OpenAI bei mathematischen, programmtechnischen und logischen Denkaufgaben.Es ist erwähnenswert, dass sowohl R1 als auch R1-Zero Open-Source-Modelle sind..
DeepSeek-R1-Zero
DeepSeek-R1-Zero ist das erste Open-Source-Modell, das ausschließlich mit groß angelegtem Reinforcement Learning (RL) trainiert wird, im Gegensatz zu herkömmlichen Modellen, die in einem ersten Schritt Supervised Fine-Tuning (SFT) verwenden. Dieser innovative Ansatz ermöglicht es den Modellen, selbstständig CoT (Chain-of-Thought)-Gedankengänge zu erforschen, komplexe Probleme zu lösen und die Ergebnisse iterativ zu optimieren. Allerdings bringt dieser Ansatz auch einige Herausforderungen mit sich, wie z. B. die mögliche Duplizierung von Argumentationsschritten, eine geringere Lesbarkeit und einen uneinheitlichen Sprachstil, was wiederum die Klarheit und Nützlichkeit des Modells beeinträchtigt.
DeepSeek-R1
Die Veröffentlichung von DeepSeek-R1 zielt darauf ab, die Unzulänglichkeiten von DeepSeek-R1-Zero zu überwinden. Durch die Einführung von Cold-Start-Daten vor dem Reinforcement Learning legt DeepSeek-R1 eine stärkere Grundlage für Inferenz- und Nicht-Inferenz-Aufgaben. Diese mehrstufige Trainingsstrategie ermöglicht es DeepSeek-R1, in Mathematik-, Programmier- und Inferenz-Benchmarks eine Spitzenleistung gegenüber OpenAI-o1 zu erzielen und die Lesbarkeit und Kohärenz der Ausgabe deutlich zu verbessern.
DeepSeek-Destillationsmodell
DeepSeek hat auch eine Familie von Destillationsmodellen eingeführt. Diese Modelle sind kleiner und effizienter und bieten gleichzeitig eine hervorragende Inferenzleistung. Obwohl die Parametergrößen von 1,5B bis 70B reichen, verfügen alle diese Modelle über starke Inferenzfähigkeiten. Unter ihnen übertrifft DeepSeek-R1-Distill-Qwen-32B das OpenAI-o1-mini-Modell in mehreren Benchmarks. Die kleineren Modelle übernehmen die Inferenzmuster der größeren Modelle, was die Wirksamkeit der Destillationstechnik voll und ganz unter Beweis stellt.
-1")
DeepSeek R1-Feinabstimmung in Aktion
1. ökologische Konfiguration
Für die Feinabstimmung des Modells wurde Kaggle als Cloud-IDE gewählt, da Kaggle kostenlose GPU-Ressourcen zur Verfügung stellt. Ursprünglich wurden zwei T4-GPUs ausgewählt, aber nur einer wurde verwendet. Wenn Benutzer die Modellfeinabstimmung auf einem lokalen Computer durchführen möchten, müssen sie mindestens überEine RTX 3090-Grafikkarte mit 16 GB Speicher..
Beginnen Sie zunächst ein neues Kaggle-Notizbuch mit dem Umarmungsgesicht des Benutzers Token im Gesang antworten Gewichte & Biases Token wird als Schlüssel hinzugefügt.
Nach der Einrichtung des Schlüssels installieren Sie die unsloth Unsloth ist ein Open-Source-Framework, das die Geschwindigkeit der Feinabstimmung großer Sprachmodelle (LLMs) verdoppelt und die Speichereffizienz erheblich verbessert.
%%capture
!pip install unsloth
!pip install --force-reinstall --no-cache-dir --no-deps git+https://github.com/unslothai/unsloth.git
Dieser Schritt ist entscheidend für das anschließende Herunterladen des Datensatzes und das Hochladen des fein abgestimmten Modells.
from huggingface_hub import login
from kaggle_secrets import UserSecretsClient
user_secrets = UserSecretsClient()
hf_token = user_secrets.get_secret("HUGGINGFACE_TOKEN")
login(hf_token)
Melden Sie sich dann bei Weights & Biases (wandb) an und erstellen Sie ein neues Projekt, um den Verlauf des Experiments zu verfolgen und den Fortschritt zu optimieren.
import wandb
wb_token = user_secrets.get_secret("wandb")
wandb.login(key=wb_token)
run = wandb.init(
project='Fine-tune-DeepSeek-R1-Distill-Llama-8B on Medical COT Dataset',
job_type="training",
anonymous="allow"
)
2. modelle und tokeniser laden
In der Praxis dieser Arbeit wurde die Unsloth-Version des Modells DeepSeek-R1-Distill-Llama-8B geladen.
https://huggingface.co/unsloth/DeepSeek-R1-Distill-Llama-8B
Um die Speichernutzung zu optimieren und die Leistung zu verbessern, wurde das Modell in einer 4-Bit-quantisierten Weise geladen.
from unsloth import FastLanguageModel
max_seq_length = 2048
dtype = None
load_in_4bit = True
model, tokenizer = FastLanguageModel.from_pretrained(
model_name="unsloth/DeepSeek-R1-Distill-Llama-8B",
max_seq_length=max_seq_length,
dtype=dtype,
load_in_4bit=load_in_4bit,
token=hf_token,
)
3. vor der Feinabstimmung des Modells - Grundierung der Argumentationsfähigkeit
Um eine Prompt-Vorlage für das Modell zu erstellen, wurde ein Systemprompt mit Platzhaltern für die Frage- und Antwortgenerierung definiert. Dieser Prompt soll das Modell durch einen schrittweisen Denkprozess leiten und schließlich logisch strenge und genaue Antworten erzeugen.
prompt_style = """Below is an instruction that describes a task, paired with an input that provides further context.
Write a response that appropriately completes the request.
Before answering, think carefully about the question and create a step-by-step chain of thoughts to ensure a logical and accurate response.
### Instruction:
You are a medical expert with advanced knowledge in clinical reasoning, diagnostics, and treatment planning.
Please answer the following medical question.
### Question:
{}
### Response:
<think>{}"""
In diesem Beispiel wird eine Nachricht an die prompt_style ein medizinisches Problem und wandelte es in Token um, die dann Token an das Modell übergeben, um die Antwort zu generieren.
question = "A 61-year-old woman with a long history of involuntary urine loss during activities like coughing or sneezing but no leakage at night undergoes a gynecological exam and Q-tip test. Based on these findings, what would cystometry most likely reveal about her residual volume and detrusor contractions?"
FastLanguageModel.for_inference(model)
inputs = tokenizer([prompt_style.format(question, "")], return_tensors="pt").to("cuda")
outputs = model.generate(
input_ids=inputs.input_ids,
attention_mask=inputs.attention_mask,
max_new_tokens=1200,
use_cache=True,
)
response = tokenizer.batch_decode(outputs)
print(response[0].split("### Response:")[1])
Der Kern der obigen medizinischen Frage ist:
Eine 61-jährige Frau mit einer langen Vorgeschichte von unwillkürlichem Urinverlust bei Aktivitäten wie Husten oder Niesen, aber ohne nächtlichen Urinverlust. Sie unterzog sich einer gynäkologischen Untersuchung und einem Q-Tip-Test. Welche Informationen würde eine Zystometrie auf der Grundlage dieser Befunde am ehesten über ihr Restharnvolumen und den Status der Detrusorkontraktion liefern?
Auch ohne Feinabstimmung erzeugt das Modell erfolgreich Gedankenketten und führt strenge Überlegungen durch, bevor es die endgültige Antwort gibt, wobei der gesamte Überlegungsprozess in der <think></think> Tagged within.
Warum ist also noch eine Feinabstimmung erforderlich? Obwohl das Modell einen detaillierten Argumentationsprozess aufweist, ist seine Darstellung etwas langatmig und nicht prägnant genug. Außerdem werden die endgültigen Antworten in Form von Aufzählungslisten dargestellt, was von der Struktur und dem Stil des Datensatzes abweicht, der feinabgestimmt werden soll.
4. das Laden und die Vorverarbeitung von Datensätzen
Die Eingabeaufforderungsvorlage wurde durch Hinzufügen eines dritten Platzhalters für die Spalte "Komplexe Gedankenkette" in der Eingabeaufforderungsvorlage feinabgestimmt, um den Verarbeitungsanforderungen des Datensatzes gerecht zu werden.
train_prompt_style = """Below is an instruction that describes a task, paired with an input that provides further context.
Write a response that appropriately completes the request.
Before answering, think carefully about the question and create a step-by-step chain of thoughts to ensure a logical and accurate response.
### Instruction:
You are a medical expert with advanced knowledge in clinical reasoning, diagnostics, and treatment planning.
Please answer the following medical question.
### Question:
{}
### Response:
<think>
{}
</think>
{}"""
Eine Python-Funktion wurde geschrieben, um eine "Text"-Spalte im Datensatz zu erstellen. Der Inhalt der Spalte besteht aus einer Vorlage für Trainingsfragen mit Platzhaltern, die mit Fragen, Gedankenketten bzw. Antworten gefüllt sind.
EOS_TOKEN = tokenizer.eos_token # Must add EOS_TOKEN
def formatting_prompts_func(examples):
inputs = examples["Question"]
cots = examples["Complex_CoT"]
outputs = examples["Response"]
texts = []
for input, cot, output in zip(inputs, cots, outputs):
text = train_prompt_style.format(input, cot, output) + EOS_TOKEN
texts.append(text)
return {
"text": texts,
}
Die ersten 500 Beispiele aus dem FreedomIntelligence/medical-o1-reasoning-SFT-Datensatz wurden vom Hugging Face Hub geladen.
https://huggingface.co/datasets/FreedomIntelligence/medical-o1-reasoning-SFT?row=46
Anschließend wird über die formatting_prompts_func bildet die Spalte "Text" des Datensatzes ab.
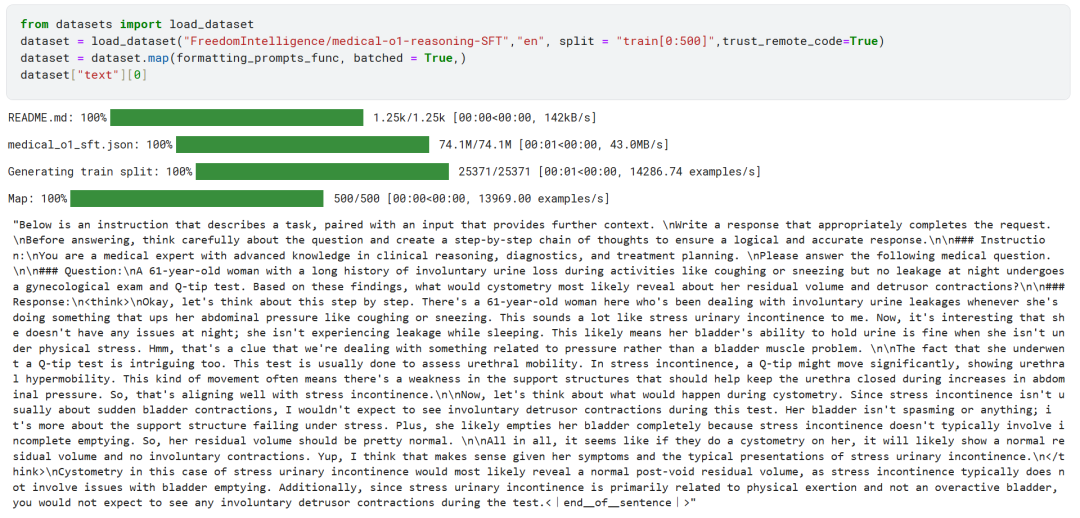
Wie Sie oben sehen können, hat die Spalte "Text" erfolgreich die Systemhinweise, Anweisungen, Gedankenketten und endgültigen Antworten integriert.
5. die Modellkonfiguration
Das Modell wird mit der Low-Rank-Adapter-Technik konfiguriert, indem das Zielmodul eingestellt wird.
model = FastLanguageModel.get_peft_model(
model,
r=16,
target_modules=[
"q_proj",
"k_proj",
"v_proj",
"o_proj",
"gate_proj",
"up_proj",
"down_proj",
],
lora_alpha=16,
lora_dropout=0,
bias="none",
use_gradient_checkpointing="unsloth", # True or "unsloth" for very long context
random_state=3407,
use_rslora=False,
loftq_config=None,
)
Anschließend wurden die Trainingsparameter und der Trainer (Trainer) konfiguriert. Das Modell, der Tokenizer, der Datensatz und andere wichtige Trainingsparameter wurden dem Trainer zur Verfügung gestellt, um den Feinabstimmungsprozess des Modells zu optimieren.
from trl import SFTTrainer
from transformers import TrainingArguments
from unsloth import is_bfloat16_supported
trainer = SFTTrainer(
model=model,
tokenizer=tokenizer,
train_dataset=dataset,
dataset_text_field="text",
max_seq_length=max_seq_length,
dataset_num_proc=2,
args=TrainingArguments(
per_device_train_batch_size=2,
gradient_accumulation_steps=4,
# Use num_train_epochs = 1, warmup_ratio for full training runs!
warmup_steps=5,
max_steps=60,
learning_rate=2e-4,
fp16=not is_bfloat16_supported(),
bf16=is_bfloat16_supported(),
logging_steps=10,
optim="adamw_8bit",
weight_decay=0.01,
lr_scheduler_type="linear",
seed=3407,
output_dir="outputs",
),
)
6. modellhafte Ausbildung
trainer_stats = trainer.train()
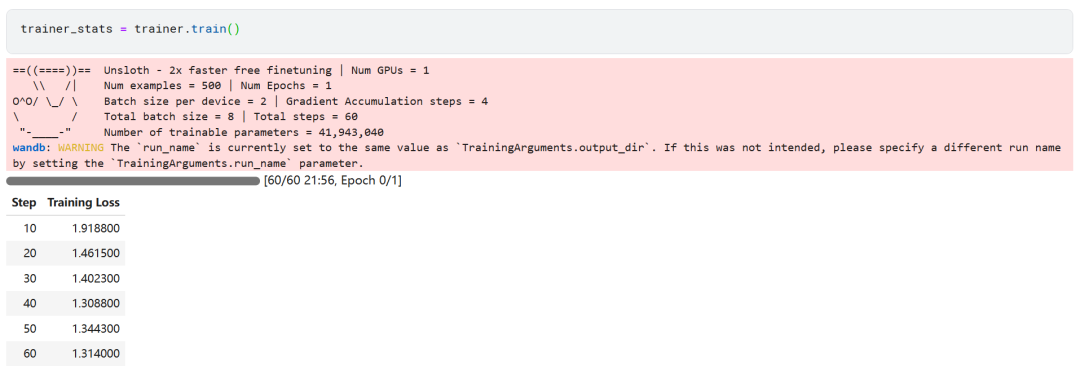
Das Modelltraining dauerte 22 Minuten. Der Trainingsverlust (Verlust) nimmt allmählich ab, was ein positives Zeichen dafür ist, dass sich die Leistung des Modells verbessert hat.
Der vollständige Bericht über die Modellbewertung kann auf der Website von Weights & Biases eingesehen werden.
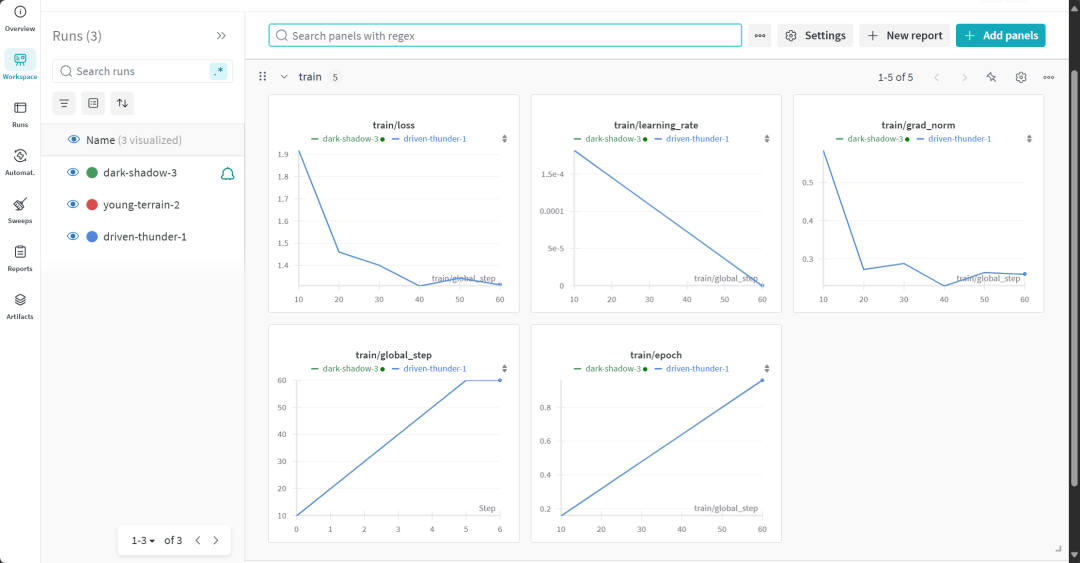
7. die Bewertung der Argumentationsfähigkeit des fein abgestimmten Modells
Zur vergleichenden Analyse wurden dem feinabgestimmten Modell erneut dieselben Fragen gestellt wie vor der Feinabstimmung, um die Veränderung der Modellleistung zu beobachten.
question = "A 61-year-old woman with a long history of involuntary urine loss during activities like coughing or sneezing but no leakage at night undergoes a gynecological exam and Q-tip test. Based on these findings, what would cystometry most likely reveal about her residual volume and detrusor contractions?"
FastLanguageModel.for_inference(model) # Unsloth has 2x faster inference!
inputs = tokenizer([prompt_style.format(question, "")], return_tensors="pt").to("cuda")
outputs = model.generate(
input_ids=inputs.input_ids,
attention_mask=inputs.attention_mask,
max_new_tokens=1200,
use_cache=True,
)
response = tokenizer.batch_decode(outputs)
print(response[0].split("### Response:")[1])
Die Versuchsergebnisse zeigen, dass die Qualität des Outputs des feinabgestimmten Modells deutlich verbessert wurde und die Antworten genauer sind. Die Gedankenkette wurde prägnanter dargestellt und die endgültige Antwort war direkter und klarer in nur einem Absatz beantwortet, was auf den Erfolg dieser Modellfeinabstimmung hinweist.

8. lokale Speicherung von Modellen
Speichern Sie nun den Adapter, das vollständige Modell und den Tokeniser lokal für die Verwendung in anderen Projekten.
new_model_local = "DeepSeek-R1-Medical-COT"
model.save_pretrained(new_model_local)
tokenizer.save_pretrained(new_model_local)
model.save_pretrained_merged(new_model_local, tokenizer, save_method="merged_16bit")
9. hochgeladenes Modell bei Hugging Face Hub
Adapter, Tokenisers und vollständige Modelle wurden ebenfalls in den Hugging Face Hub eingefügt, damit die KI-Gemeinschaft dieses fein abgestimmte Modell in vollem Umfang nutzen und problemlos in ihre Systeme integrieren kann.
new_model_online = "realyinchen/DeepSeek-R1-Medical-COT"
model.push_to_hub(new_model_online)
tokenizer.push_to_hub(new_model_online)
model.push_to_hub_merged(new_model_online, tokenizer, save_method="merged_16bit")
Zusammenfassungen
Der Bereich der künstlichen Intelligenz (KI) befindet sich in einem raschen Wandel. Der Aufstieg der Open-Source-Community stellt eine große Herausforderung für die KI-Landschaft dar, die in den letzten drei Jahren von proprietären Modellen dominiert wurde. Open Source Large Language Models (LLMs) werden immer schneller und effizienter, so dass es einfacher denn je ist, sie mit geringeren Rechen- und Speicherressourcen fein abzustimmen.
Dieses Papier gibt einen detaillierten Einblick in die DeepSeek R1 Inferenzmodells und beschreibt, wie dessen Lite-Version für die Anwendung in medizinischen Frage-Antwort-Szenarien feinabgestimmt werden kann. Das fein abgestimmte Inferenzmodell bietet nicht nur erhebliche Leistungsverbesserungen, sondern macht es auch praktisch für den Einsatz in Schlüsselbereichen wie Medizin, Notfalldienste und Gesundheitswesen.
Als Reaktion auf die Veröffentlichung von DeepSeek R1 hat OpenAI auch schnell zwei wichtige Tools eingeführt: ein fortschrittlicheres Inferenzmodell, o3, und das Betreiber KI-Agent. Letzterer stützt sich auf den neuen Computer Usage Agent (CUA, den Computer Use Agent)-Modell, das die Fähigkeit demonstriert, selbstständig auf Websites zu navigieren und komplexe Aufgaben auszuführen.
Quellcode:
https://www.kaggle.com/code/realyinchen/deepseek-r1-medical-cot
© urheberrechtliche Erklärung
Artikel Copyright AI-Austauschkreis Alle, bitte nicht ohne Erlaubnis vervielfältigen.
Ähnliche Artikel



Keine Kommentare...