
Crawl4AI meistern: Hochwertige Webdaten für LLM und RAG aufbereiten

Herkömmliche Web-Crawler-Frameworks sind vielseitig, erfordern aber oft zusätzliche Bereinigung und Formatierung bei der Datenverarbeitung, was ihre Integration mit Large Language Models (LLMs) relativ komplex macht. Die Ausgabe vieler Tools (z. B. Rohdaten HTML oder unstrukturiert JSON) enthält viel Rauschen und ist für die direkte Verwendung in Szenarien wie Retrieval Augmented Generation (RAG) nicht geeignet, da es die Qualität der Daten beeinträchtigen würde. LLM Effizienz und Genauigkeit der Verarbeitung.
Crawl4AI bietet eine andere Art von Lösung. Sie konzentriert sich auf die direkte Erzeugung sauberer, strukturierter Markdown Formatierter Inhalt. Bei diesem Format bleibt die semantische Struktur des Originaltextes (z. B. Überschriften, Listen, Codeblöcke) erhalten, während überflüssige Elemente wie Navigation, Werbung, Fußzeilen usw. auf intelligente Weise entfernt werden, so dass es sich ideal zur Verwendung als LLM Inputs oder für den Aufbau hochwertiger RAG Datensatz.Crawl4AI ist ein vollständig quelloffenes Projekt, das keine API Der Schlüssel ist auch nicht auf eine Pay-per-view-Schwelle festgelegt.
Installation und Konfiguration
Empfohlene Verwendung uv Erstellen und aktivieren Sie eine separate Python virtuelle Umgebung zur Verwaltung von Projektabhängigkeiten.uv Es basiert auf einer Rust Entwickelt Aufstrebend Python Paketmanager, mit seinem erheblichen Geschwindigkeitsvorteil (in der Regel gegenüber dem pip (3-5 mal schneller) und effiziente parallele Auflösung von Abhängigkeiten.
# 创建虚拟环境
uv venv crawl4ai-env
# 激活环境
# Windows
# crawl4ai-env\Scripts\activate
# macOS/Linux
source crawl4ai-env/bin/activate
Nachdem die Umgebung aktiviert wurde, verwenden Sie die uv Montage Crawl4AI Kernbibliothek:
uv pip install crawl4ai
Sobald die Installation abgeschlossen ist, führen Sie den Initialisierungsbefehl aus, der für die Installation oder Aktualisierung der Playwright Erforderliche Browser-Treiber (z.B. Chromium) und führen Umweltinspektionen durch.Playwright Es ist eines dieser Dinge, die sich aus Microsoft entwickelte Bibliotheken zur Browser-Automatisierung.Crawl4AI Verwenden Sie es, um echte Benutzerinteraktionen zu simulieren, damit Sie dynamisch geladene Inhalte der JavaScript Umfangreiche Website.
crawl4ai-setup
Wenn Sie Probleme mit dem Browsertreiber haben, können Sie versuchen, ihn manuell zu installieren:
# 手动安装 Playwright 浏览器及依赖
python -m playwright install --with-deps chromium
Je nach Bedarf kann dies geschehen durch uv Installation von Erweiterungspaketen mit zusätzlichen Funktionen:
# 安装文本聚类功能 (依赖 PyTorch)
uv pip install "crawl4ai[torch]"
# 安装 Transformers 支持 (用于本地 AI 模型)
uv pip install "crawl4ai[transformer]"
# 安装所有可选功能
uv pip install "crawl4ai[all]"
Grundlegendes Crawling-Beispiel
dieser Betrag oder weniger Python Das Skript demonstriert die Crawl4AI Die grundlegende Verwendung des Markdown.
import asyncio
from crawl4ai import AsyncWebCrawler
async def main():
# 初始化异步爬虫
async with AsyncWebCrawler() as crawler:
# 执行爬取任务
result = await crawler.arun(
url="https://www.sitepoint.com/react-router-complete-guide/"
)
# 检查爬取是否成功
if result.success:
# 输出结果信息
print(f"标题: {result.title}")
print(f"提取的 Markdown ({len(result.markdown)} 字符):")
# 仅显示前 300 个字符作为预览
print(result.markdown[:300] + "...")
# 将完整的 Markdown 内容保存到文件
with open("example_content.md", "w", encoding="utf-8") as f:
f.write(result.markdown)
print(f"内容已保存到 example_content.md")
else:
# 输出错误信息
print(f"爬取失败: {result.url}")
print(f"状态码: {result.status_code}")
print(f"错误信息: {result.error_message}")
if __name__ == "__main__":
asyncio.run(main())
Nach dem Ausführen dieses Skripts wird dieCrawl4AI wird aktiviert Playwright Kontrollierter Browser-Zugriff auf festgelegte URLAusführende Seite JavaScriptidentifiziert und extrahiert dann auf intelligente Weise die wichtigsten Inhaltsbereiche, filtert ablenkende Elemente heraus und erzeugt schließlich saubere Markdown Dokumentation.
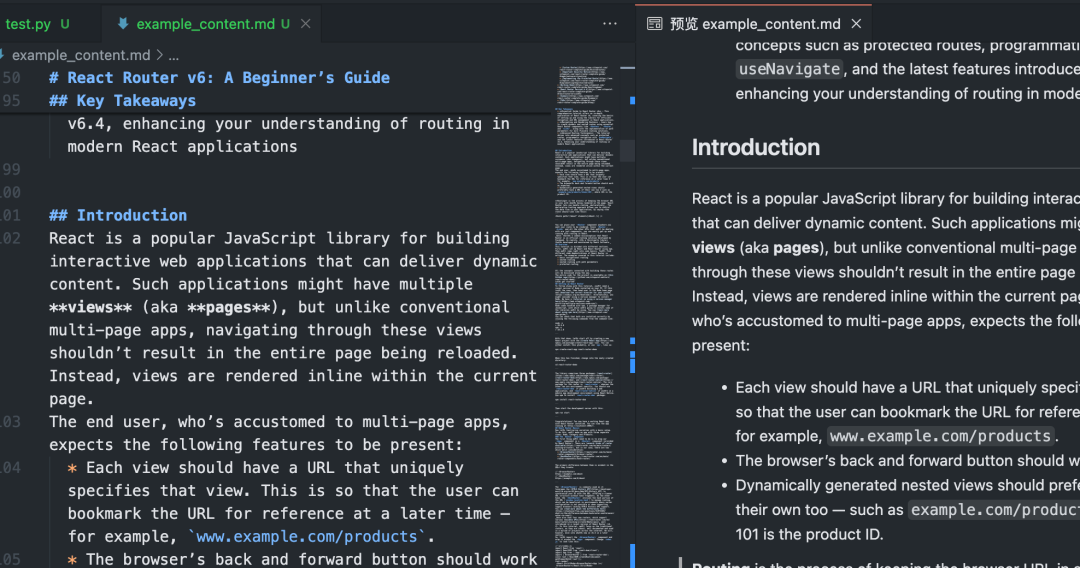
Batch und paralleles Crawling
mehrere verarbeiten URL wennCrawl4AI der Parallelverarbeitung kann die Effizienz drastisch erhöhen. Durch die Konfiguration der CrawlerRunConfig den Nagel auf den Kopf treffen concurrency der die Anzahl der gleichzeitig verarbeiteten Seiten steuert.
import asyncio
from crawl4ai import AsyncWebCrawler, BrowserConfig, CrawlerRunConfig, CacheMode
async def main():
urls = [
"https://example.com/page1",
"https://example.com/page2",
"https://example.com/page3",
# 添加更多 URL...
]
# 浏览器配置:无头模式,增加超时
browser_config = BrowserConfig(
headless=True,
timeout=45000, # 45秒超时
)
# 爬取运行配置:设置并发数,禁用缓存以获取最新内容
run_config = CrawlerRunConfig(
concurrency=5, # 同时处理 5 个页面
cache_mode=CacheMode.BYPASS # 禁用缓存
)
results = []
async with AsyncWebCrawler(browser_config=browser_config) as crawler:
# 使用 arun_many 进行批量并行爬取
# 注意:arun_many 需要将 run_config 列表传递给 configs 参数
# 如果所有 URL 使用相同配置,可以创建一个配置列表
configs = [run_config.clone(url=url) for url in urls] # 为每个URL克隆配置并设置URL
# arun_many 返回一个异步生成器
async for result in crawler.arun_many(configs=configs):
if result.success:
results.append(result)
print(f"已完成: {result.url}, 获取了 {len(result.markdown)} 字符")
else:
print(f"失败: {result.url}, 错误: {result.error_message}")
# 将所有成功的结果合并到一个文件
with open("combined_results.md", "w", encoding="utf-8") as f:
for i, result in enumerate(results):
f.write(f"## {result.title}\n\n")
f.write(result.markdown)
f.write("\n\n---\n\n")
print(f"所有成功内容已合并保存到 combined_results.md")
if __name__ == "__main__":
asyncio.run(main())
zur Kenntnis nehmen: Der obige Code verwendet die arun_many Methode, die der empfohlene Weg ist, um große Listen von URLs zu verarbeiten, anstatt eine Schleife durch einen Aufruf der arun Mehr Effizienz.arun_many Es ist eine Liste von Konfigurationen erforderlich, die jeweils einer URL. Wenn alle URL Mit der gleichen Grundkonfiguration kann die clone() Methode erstellt eine Kopie und setzt eine bestimmte URL.
Strukturierte Datenextraktion (Selektor-basiert)
abgesehen von Markdown(math.) GattungCrawl4AI Auch verfügbar CSS Selektor oder XPath Extrahiert strukturierte Daten, ideal für Websites mit regelmäßigen Datenformaten.
import asyncio
import json
from crawl4ai import AsyncWebCrawler, ExtractorConfig
async def main():
# 定义提取规则 (CSS 选择器)
extractor_config = ExtractorConfig(
strategy="css", # 明确指定策略为 CSS
rules={
"products": {
"selector": "div.product-card", # 主选择器
"type": "list",
"properties": {
"name": {"selector": "h2.product-title", "type": "text"},
"price": {"selector": ".price span", "type": "text"},
"link": {"selector": "a.product-link", "type": "attribute", "attribute": "href"}
}
}
}
)
async with AsyncWebCrawler() as crawler:
result = await crawler.arun(
url="https://example-shop.com/products",
extractor_config=extractor_config
)
if result.success and result.extracted_data:
extracted_data = result.extracted_data
with open("products.json", "w", encoding="utf-8") as f:
json.dump(extracted_data, f, ensure_ascii=False, indent=2)
print(f"已提取 {len(extracted_data.get('products', []))} 个产品信息")
print("数据已保存到 products.json")
elif not result.success:
print(f"爬取失败: {result.error_message}")
else:
print("未提取到数据或提取规则匹配失败")
if __name__ == "__main__":
asyncio.run(main())
Dieser Ansatz erfordert nicht LLM Die kostengünstige und schnelle Intervention eignet sich für Szenarien, bei denen das Zielelement eindeutig ist.
KI-unterstützte Datenextraktion
Für Seiten mit komplexen Strukturen oder ohne festes Muster können Sie die LLM Intelligente Extraktion durchführen.
import asyncio
import json
from crawl4ai import AsyncWebCrawler, BrowserConfig, AIExtractorConfig
async def main():
# 配置 AI 提取器
ai_config = AIExtractorConfig(
provider="openai", # 或 "local", "anthropic" 等
model="gpt-4o-mini", # 使用 OpenAI 的模型
# api_key="YOUR_OPENAI_API_KEY", # 如果环境变量未设置,在此提供
schema={
"type": "object",
"properties": {
"article_summary": {"type": "string", "description": "A brief summary of the article."},
"key_topics": {"type": "array", "items": {"type": "string"}, "description": "List of main topics discussed."},
"sentiment": {"type": "string", "enum": ["positive", "negative", "neutral"], "description": "Overall sentiment of the article."}
},
"required": ["article_summary", "key_topics"]
},
instruction="Extract the summary, key topics, and sentiment from the provided article text."
)
browser_config = BrowserConfig(timeout=60000) # AI 处理可能需要更长时间
async with AsyncWebCrawler(browser_config=browser_config) as crawler:
result = await crawler.arun(
url="https://example-news.com/article/complex-analysis",
ai_extractor_config=ai_config
)
if result.success and result.ai_extracted:
ai_extracted = result.ai_extracted
print("AI 提取的数据:")
print(json.dumps(ai_extracted, indent=2, ensure_ascii=False))
# 也可以选择保存到文件
# with open("ai_extracted_data.json", "w", encoding="utf-8") as f:
# json.dump(ai_extracted, f, ensure_ascii=False, indent=2)
elif not result.success:
print(f"爬取失败: {result.error_message}")
else:
print("AI 未能提取所需数据。")
if __name__ == "__main__":
asyncio.run(main())
Die KI-Extraktion bietet große Flexibilität, um Inhalte zu verstehen und bei Bedarf strukturierte Ausgaben zu generieren, verursacht aber zusätzliche Kosten. API Gesprächskosten (bei Nutzung von Cloud-Diensten) LLM) und Bearbeitungszeit. Wählen Sie das lokale Modell (z.B. Mistral, Llama) können die Kosten senken und die Privatsphäre schützen, haben aber lokale Hardwareanforderungen.
Erweiterte Konfigurationen und Tipps
Crawl4AI Bietet eine Fülle von Konfigurationsoptionen zur Bewältigung komplexer Szenarien.
Browser-Konfiguration (BrowserConfig)
BrowserConfig Steuert das Starten und Verhalten des Browsers selbst.
from crawl4ai import BrowserConfig
config = BrowserConfig(
browser_type="firefox", # 使用 Firefox 浏览器
headless=False, # 显示浏览器界面,方便调试
user_agent="MyCustomCrawler/1.0", # 设置自定义 User-Agent
proxy_config={ # 配置代理服务器
"server": "http://proxy.example.com:8080",
"username": "proxy_user",
"password": "proxy_password"
},
ignore_https_errors=True, # 忽略 HTTPS 证书错误 (开发环境常用)
use_persistent_context=True, # 启用持久化上下文
user_data_dir="./my_browser_profile", # 指定用户数据目录,用于保存 cookies, local storage 等
timeout=60000, # 全局浏览器操作超时 (毫秒)
verbose=True # 打印更详细的日志
)
# 在初始化 AsyncWebCrawler 时传入
# async with AsyncWebCrawler(browser_config=config) as crawler:
# ...
Crawlen Sie die Laufzeitkonfiguration (CrawlerRunConfig)
CrawlerRunConfig Kontrolle Einzel arun() vielleicht arun_many() Das spezifische Verhalten des Anrufs.
from crawl4ai import CrawlerRunConfig, CacheMode
run_config = CrawlerRunConfig(
cache_mode=CacheMode.READ_ONLY, # 只读缓存,不写入新缓存
check_robots_txt=True, # 检查并遵守 robots.txt 规则
wait_until="networkidle", # 等待网络空闲再提取,适合JS动态加载内容
wait_for="css:div#final-content", # 等待特定 CSS 选择器元素出现
js_code="window.scrollTo(0, document.body.scrollHeight);", # 页面加载后执行 JS 代码 (例如滚动到底部触发加载)
scan_full_page=True, # 尝试自动滚动页面以加载所有内容 (用于无限滚动)
screenshot=True, # 截取页面截图 (结果在 result.screenshot,Base64编码)
pdf=True, # 生成页面 PDF (结果在 result.pdf,Base64编码)
word_count_threshold=50, # 过滤掉少于 50 个单词的文本块
excluded_tags=["header", "nav", "footer", "aside"], # 从 Markdown 中排除特定 HTML 标签
exclude_external_links=True # 不提取外部链接
)
# 在调用 arun() 或创建配置列表给 arun_many() 时传入
# result = await crawler.arun(url="...", config=run_config)
Umgang mit JavaScript und dynamischen Inhalten
dank Playwright(math.) GattungCrawl4AI Gute Handhabung von Abhängigkeiten JavaScript Gerenderte Website. Schlüssel Konfiguration:
wait_until: Eingestellt auf"networkidle"vielleicht"load"Sie ist in der Regel etwas effizienter als der Standard"domcontentloaded"Besser geeignet für dynamische Seiten.wait_for: auf ein bestimmtes Element warten oderJavaScriptDie Bedingungen sind erfüllt.js_codeAnpassung nach dem Laden der Seite ausführenJavaScriptwie das Anklicken von Schaltflächen und das Durchblättern von Seiten.scan_full_page:: Automatischer Umgang mit unendlich scrollenden Seiten.delay_before_return_html: Fügen Sie eine kurze Verzögerung vor der Extraktion hinzu, um sicherzustellen, dass alle Skripte ausgeführt werden.
Fehlerbehandlung und Fehlersuche
- Sonde
result.success: Überprüfen Sie diese Eigenschaft nach jedem Crawlen. - auschecken
result.status_codeim Gesang antwortenresult.error_message:: Ermitteln Sie den Grund für den Fehler. - aufstellen
headless=False: InBrowserConfigSie können den Browserbetrieb beobachten und das Problem visuell diagnostizieren. - .
verbose=True: InBrowserConfigin den Einstellungen, um ein ausführlicheres Laufzeitprotokoll zu erhalten. - ausnutzen
try...exceptPäckchenarun()vielleichtarun_many()Aufruf, der eine möglichePythonEine Ausnahme.
import asyncio
from crawl4ai import AsyncWebCrawler, BrowserConfig
async def debug_crawl():
# 启用调试模式:显示浏览器,打印详细日志
debug_browser_config = BrowserConfig(headless=False, verbose=True)
async with AsyncWebCrawler(browser_config=debug_browser_config) as crawler:
try:
result = await crawler.arun(url="https://problematic-site.com")
if not result.success:
print(f"Crawl failed: {result.error_message} (Status: {result.status_code})")
else:
print("Crawl successful.")
# ... process result ...
except Exception as e:
print(f"An unexpected error occurred: {e}")
if __name__ == "__main__":
asyncio.run(debug_crawl())
Beobachtung robots.txt
Beachten Sie bei der Durchführung eines Web-Crawls die Vorgaben der Website robots.txt Die Dokumentation ist eine grundlegende Netiquette und verhindert IP-Sperren.Crawl4AI Sie kann automatisch verarbeitet werden.
existieren CrawlerRunConfig aufstellen check_robots_txt=True::
respectful_config = CrawlerRunConfig(
check_robots_txt=True
)
# result = await crawler.arun(url="https://example.com", config=respectful_config)
# if not result.success and result.status_code == 403:
# print("Access denied by robots.txt")
Crawl4AI Automatisch heruntergeladen, zwischengespeichert und geparst robots.txt Datei, wenn die Regel den Zugriff auf das Ziel verbietet URL(math.) Gattungarun() scheitern wird.result.success wegen False(math.) Gattungstatus_code Dies ist in der Regel 403 mit der entsprechenden Fehlermeldung.
Sitzungsmanagement (Session Management)
Für mehrstufige Vorgänge, die eine Anmeldung oder die Beibehaltung des Status erfordern (z. B. Formularübermittlung, Seitennavigation), kann die Sitzungsverwaltung verwendet werden. Dies kann durch Hinzufügen eines neuen Sitzungsmanagers zu der CrawlerRunConfig Geben Sie dasselbe in der session_idDas System kann in mehr als einem arun() Die gleiche Browser-Seiteninstanz wird zwischen den Aufrufen wiederverwendet, wobei die cookies im Gesang antworten JavaScript Status.
import asyncio
from crawl4ai import AsyncWebCrawler, CrawlerRunConfig, CacheMode
async def session_example():
async with AsyncWebCrawler() as crawler:
session_id = "my_unique_session"
# Step 1: Load login page (hypothetical)
login_config = CrawlerRunConfig(session_id=session_id, cache_mode=CacheMode.BYPASS)
await crawler.arun(url="https://example.com/login", config=login_config)
print("Login page loaded.")
# Step 2: Execute JS to fill and submit login form (hypothetical)
login_js = """
document.getElementById('username').value = 'user';
document.getElementById('password').value = 'pass';
document.getElementById('loginButton').click();
"""
submit_config = CrawlerRunConfig(
session_id=session_id,
js_code=login_js,
js_only=True, # 只执行 JS,不重新加载页面
wait_until="networkidle" # 等待登录后跳转完成
)
await crawler.arun(config=submit_config) # 无需 URL,在当前页面执行 JS
print("Login submitted.")
# Step 3: Crawl a protected page within the same session
protected_config = CrawlerRunConfig(session_id=session_id, cache_mode=CacheMode.BYPASS)
result = await crawler.arun(url="https://example.com/dashboard", config=protected_config)
if result.success:
print("Successfully crawled protected page:")
print(result.markdown[:200] + "...")
else:
print(f"Failed to crawl protected page: {result.error_message}")
# 清理会话 (可选,但推荐)
# await crawler.crawler_strategy.kill_session(session_id)
if __name__ == "__main__":
asyncio.run(session_example())
Die erweiterte Sitzungsverwaltung umfasst das Exportieren und Importieren des Speicherstatus des Browsers (cookies, localStorage), so dass die Anmeldung zwischen den Skriptläufen beibehalten werden kann.
Crawl4AI Bietet einen leistungsstarken und flexiblen Funktionssatz, der bei richtiger Konfiguration effizient und zuverlässig die erforderlichen Informationen aus einer Vielzahl von Websites extrahieren und hochwertige Daten für nachgeschaltete KI-Anwendungen aufbereiten kann.
© urheberrechtliche Erklärung
Artikel Copyright AI-Austauschkreis Alle, bitte nicht ohne Erlaubnis vervielfältigen.
Ähnliche Artikel

Keine Kommentare...