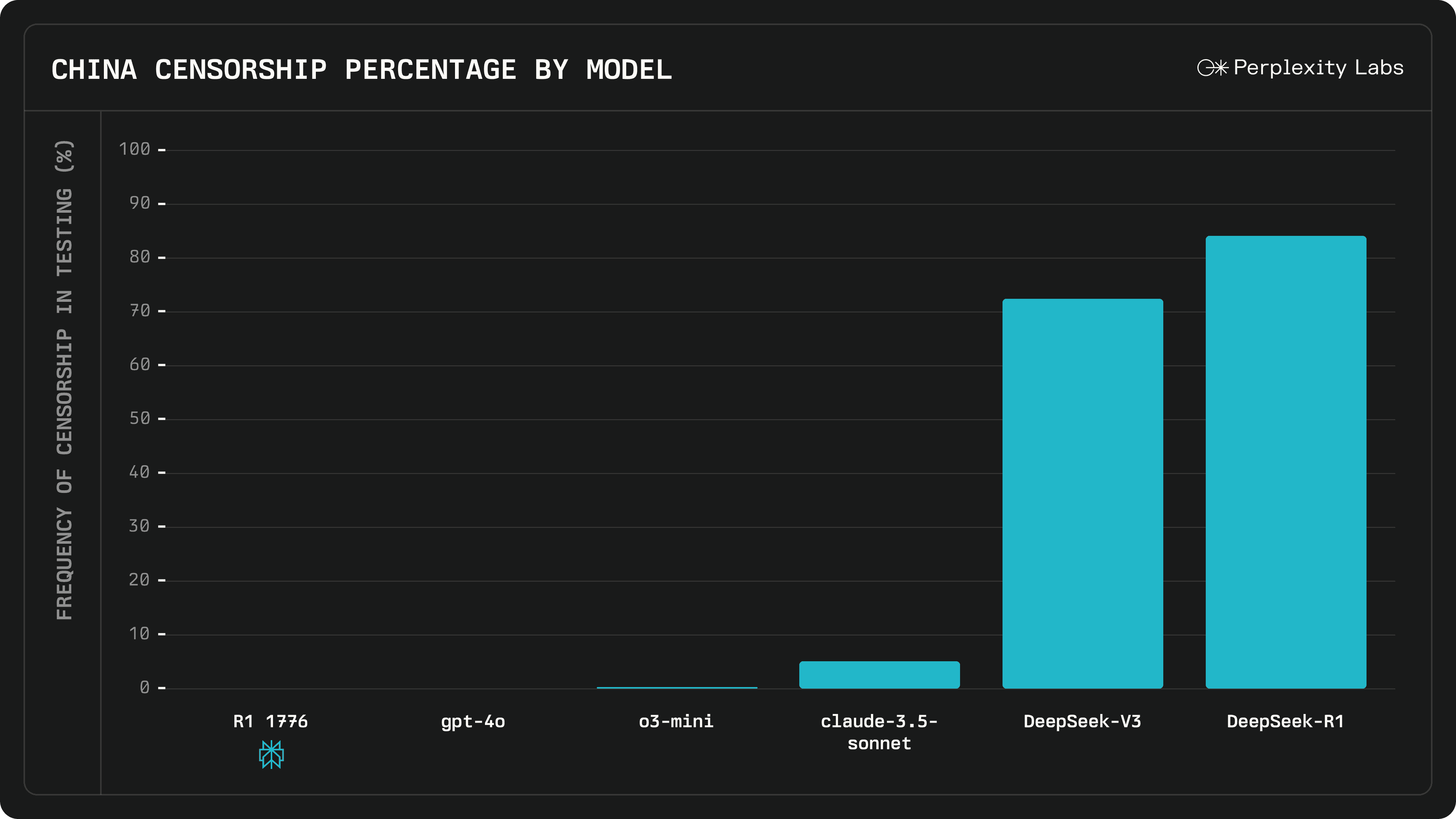
Jina AI stellt Reader-LM vor, ein revolutionäres kleines Sprachmodell zur effizienten Extraktion des Hauptinhalts von HTML-Webseiten
Jina AI hat Reader-LM-0.5B und Reader-LM-1.5B veröffentlicht, zwei kleine Sprachmodelle, die entwickelt wurden, um rohes, verrauschtes HTML aus dem offenen Web in das saubere Markdown-Format zu konvertieren. Sie unterstützen Kontextlängen von bis zu 256K Token und zeigen bei Konvertierungsaufgaben eine vergleichbare oder bessere Leistung als große Sprachmodelle. Leistung bei der Konvertierungsaufgabe.
Vorwort
Im April 2024 veröffentlichte Jina AI Jina Reader, eine einfache API, die jede URL in LLM-freundliches Markdown konvertiert. Die API nutzt den Headless Chrome Browser, um den Quellcode einer Webseite zu holen, extrahiert den Hauptinhalt mit Mozillas Readability-Paket und konvertiert das bereinigte HTML in Markdown, indem sie Regex und die Turndown-Bibliotheken, um das bereinigte HTML in Markdown zu konvertieren.
Nach der Veröffentlichung wies das Feedback der Nutzer auf Probleme mit der Qualität der Inhalte hin, die Jina AI durch Patches in der bestehenden Pipeline behoben hat.
Seitdem stellen wir uns die Frage: Können wir dieses Problem mit einem Sprachmodell durchgängig lösen, anstatt an weiteren Heuristiken und regulären Ausdrücken herumzubasteln (die immer schwieriger zu pflegen und der Mehrsprachigkeit nicht förderlich sind)?

Illustration von reader-lm, das die Pipeline aus Lesbarkeit+Turndown+Regex-Heuristik durch ein kleines Sprachmodell ersetzt.
Über Reader-LM
11. September 2024 -- Jina AI treibt die Innovation im Bereich der künstlichen Intelligenz für die Verarbeitung von Inhalten und die Textkonvertierung weiter voran und kündigte heute die Einführung seiner neuesten technologischen Errungenschaften Reader-LM-0.5B und Reader-LM-1.5B an, zwei kleine Sprachmodelle. Diese Modelle läuten eine neue Ära der Verarbeitung von Roh-HTML-Inhalten im offenen Web ein, indem sie komplexes HTML effizient in das strukturierte Markdown-Format konvertieren und so eine leistungsstarke Unterstützung für Content-Management- und Machine-Learning-Anwendungen im Zeitalter von Big Data bieten.
Bahnbrechende Leistung und Effizienz
Die Modelle Reader-LM-0.5B und Reader-LM-1.5B erreichen eine vergleichbare oder sogar bessere Leistung als größere Sprachmodelle und behalten dabei eine kompakte Parametergröße bei. Diese Modelle unterstützen Kontextlängen von bis zu 256K Token und verarbeiten die verrauschten Elemente von modernem HTML wie Inline-CSS, Skripte usw. und erzeugen saubere, gut strukturierte Markdown-Dateien. Dies ist eine große Erleichterung für Benutzer, die Text aus rohen Webinhalten extrahieren und konvertieren müssen.

Benutzerfreundliche, praktische Erfahrung
Jina AI bietet eine Lösung für dieses Problem im Google Colab (0.5Bim Gesang antworten1.5BDas Reader-LM-Modell wurde entwickelt, um den Nutzern die Möglichkeit zu geben, die Leistungsfähigkeit des Reader-LM-Modells durch die Verwendung von Reader-LM-Notizen einfach zu erleben. Egal, ob es darum geht, verschiedene Versionen des Modells zu laden, die URL einer verarbeiteten Website zu ändern oder die Ausgabe zu untersuchen, die Benutzer können dies in einer kostenlosen, cloudbasierten Umgebung tun. Darüber hinaus wird Reader-LM in Kürze auf den Azure- und AWS-Marktplätzen verfügbar sein und damit mehr Integrations- und Bereitstellungsoptionen für Unternehmensanwender bieten.
Leistung jenseits traditioneller Modelle
Durch Vergleichstests mit großen Sprachmodellen wie GPT-4o, Gemini-1.5-Flash, Gemini-1.5-Pro, LLaMA-3.1-70B und Qwen2-7B-Instruct zeigt Reader-LM gute Ergebnisse bei ROUGE-L, Word Error Rate (WER) und Token Fehlerrate (TER), neben anderen wichtigen Metriken. Diese Bewertungen zeigen, dass Reader-LM führend ist bei der Genauigkeit, der Wiederauffindbarkeit und der Fähigkeit, sauberes Markdown zu erzeugen.

Qualitative Forschung bestätigt seine Vorteile
Zusätzlich zur quantitativen Bewertung hat Jina AI die überragende Leistung von Reader-LM bei der Extraktion von Überschriften, dem Hauptinhalt, der Beibehaltung der Struktur und der Verwendung der Markdown-Syntax durch qualitative Studien der visuell inspizierten Markdown-Ausgabe bestätigt. Diese Ergebnisse unterstreichen die Effizienz und Zuverlässigkeit von Reader-LM in realen Anwendungen.
Ein innovativer Ansatz für eine zweistufige Ausbildung
Jina AI erläuterte die Einzelheiten ihres Trainingsverfahrens für Reader-LM, einschließlich der Datenvorbereitung, des zweistufigen Trainings und der Überwindung von Modelldegradation und Zyklusproblemen. Sie betonten die Bedeutung der Qualität der Trainingsdaten und stellten die Stabilität des Modells und die Qualität der Generierung durch technische Mittel wie vergleichende Suche und wiederholte Abbruchkriterien sicher.
ultimativ
Jina AI's Reader-LM ist nicht nur ein wichtiger Durchbruch im Bereich der Kleinsprachenmodellierung, sondern auch eine bedeutende Erweiterung der Möglichkeiten zur Verarbeitung von offenen Webinhalten. Mit der Veröffentlichung dieser beiden Modelle steht Entwicklern und Datenwissenschaftlern nicht nur ein effizientes, einfach zu bedienendes Werkzeug zur Verfügung, sondern es eröffnen sich auch neue Möglichkeiten für KI-Anwendungen zur Extraktion, Bereinigung und Transformation von Inhalten.
© urheberrechtliche Erklärung
Artikel Copyright AI-Austauschkreis Alle, bitte nicht ohne Erlaubnis vervielfältigen.
Verwandte Beiträge



Keine Kommentare...