
Entlarvung der großen Modell-Illusion: HHEM-Rankings geben Aufschluss über den Stand der faktischen Konsistenz im LLM-Studium

Während sich die Fähigkeiten von Large Language Models (LLMs) ständig weiterentwickeln, war das Phänomen von faktischen Fehlern oder "Illusionen" von Informationen, die nichts mit dem Originaltext zu tun haben, in ihren Ergebnissen immer eine große Herausforderung, die eine breitere Nutzung und tieferes Vertrauen in sie verhindert hat. Um dieses Problem quantitativ bewerten zu können, wurde dieHughes Halluzination Evaluation Model (HHEM) Ranglistenwurde erstellt, um die Häufigkeit von Phantasmen in Mainstream-LLMs bei der Erstellung von Dokumentenzusammenfassungen zu messen.
Der Begriff "Illusion" bezieht sich auf die Tatsache, dass das Modell "Fakten" in die Zusammenfassung einführt, die im Originaldokument nicht enthalten sind oder sogar widersprüchlich sind. Dies ist ein kritischer Qualitätsengpass für Informationsverarbeitungsszenarien, die auf LLM beruhen, insbesondere für solche, die auf Retrieval Augmented Generation (RAG) basieren. Denn wenn das Modell den gegebenen Informationen nicht treu bleibt, wird die Glaubwürdigkeit seines Ergebnisses stark beeinträchtigt.
Wie funktioniert das HHEM?
Das Ranking verwendet das von Vectara entwickelte Halluzinationsbewertungsmodell HHEM-2.1. Es funktioniert so, dass das HHEM-Modell für ein Quelldokument und eine von einem bestimmten LLM erstellte Zusammenfassung eine Halluzinationsbewertung zwischen 0 und 1 ausgibt. Je näher die Punktzahl bei 1 liegt, desto höher ist die sachliche Übereinstimmung der Zusammenfassung mit dem Quelldokument; je näher sie bei 0 liegt, desto stärker sind die Halluzinationen oder sogar vollständig erfundene Inhalte.Vectara bietet auch eine Open-Source-Version, HHEM-2.1-Open, für Forscher und Entwickler an, um die Bewertung lokal durchzuführen, und die Modellkarten werden auf der Plattform Hugging Face veröffentlicht.
Bewertungsmaßstäbe
Für die Evaluierung wurde ein Datensatz von 1006 Dokumenten verwendet, die hauptsächlich aus öffentlich zugänglichen Datensätzen wie dem klassischen CNN/Daily Mail Corpus stammen. Das Projektteam erstellte für jedes Dokument eine Zusammenfassung unter Verwendung der einzelnen LLMs, die an der Evaluierung beteiligt waren, und berechnete dann den HHEM-Score für jedes Paar (Ausgangsdokument, erstellte Zusammenfassung). Um eine Standardisierung der Auswertung zu gewährleisten, wurden alle Modellaufrufe auf temperature Der Parameter ist 0 und dient dazu, die deterministischste Ausgabe des Modells zu erhalten.
Zu den Bewertungsindikatoren gehören u. a:
- Halluzinationsrate. Prozentualer Anteil der Abstracts mit HHEM-Werten unter 0,5. Je niedriger der Wert, desto besser.
- Rate der faktischen Konsistenz. 100% minus der Rate der Halluzinationen, die den Anteil der Zusammenfassungen widerspiegelt, deren Inhalt mit dem Original übereinstimmt.
- Antwortrate. Prozentsatz der Modelle, die erfolgreich nicht leere Zusammenfassungen erstellen. Einige Modelle verweigern möglicherweise die Antwort oder machen Fehler aufgrund von Sicherheitsrichtlinien für Inhalte oder aus anderen Gründen.
- Durchschnittliche Länge der Zusammenfassung. Die durchschnittliche Anzahl der Wörter in den erstellten Zusammenfassungen gibt einen Einblick in den Stil der Ausgabe des Modells.
LLM-Illusion-Rankings erklärt
Nachfolgend finden Sie die LLM-Halluzinationsrankings auf der Grundlage der HHEM-2.1-Modellbewertung (Stand: 25. März 2025, bitte beachten Sie die aktuelle Aktualisierung):
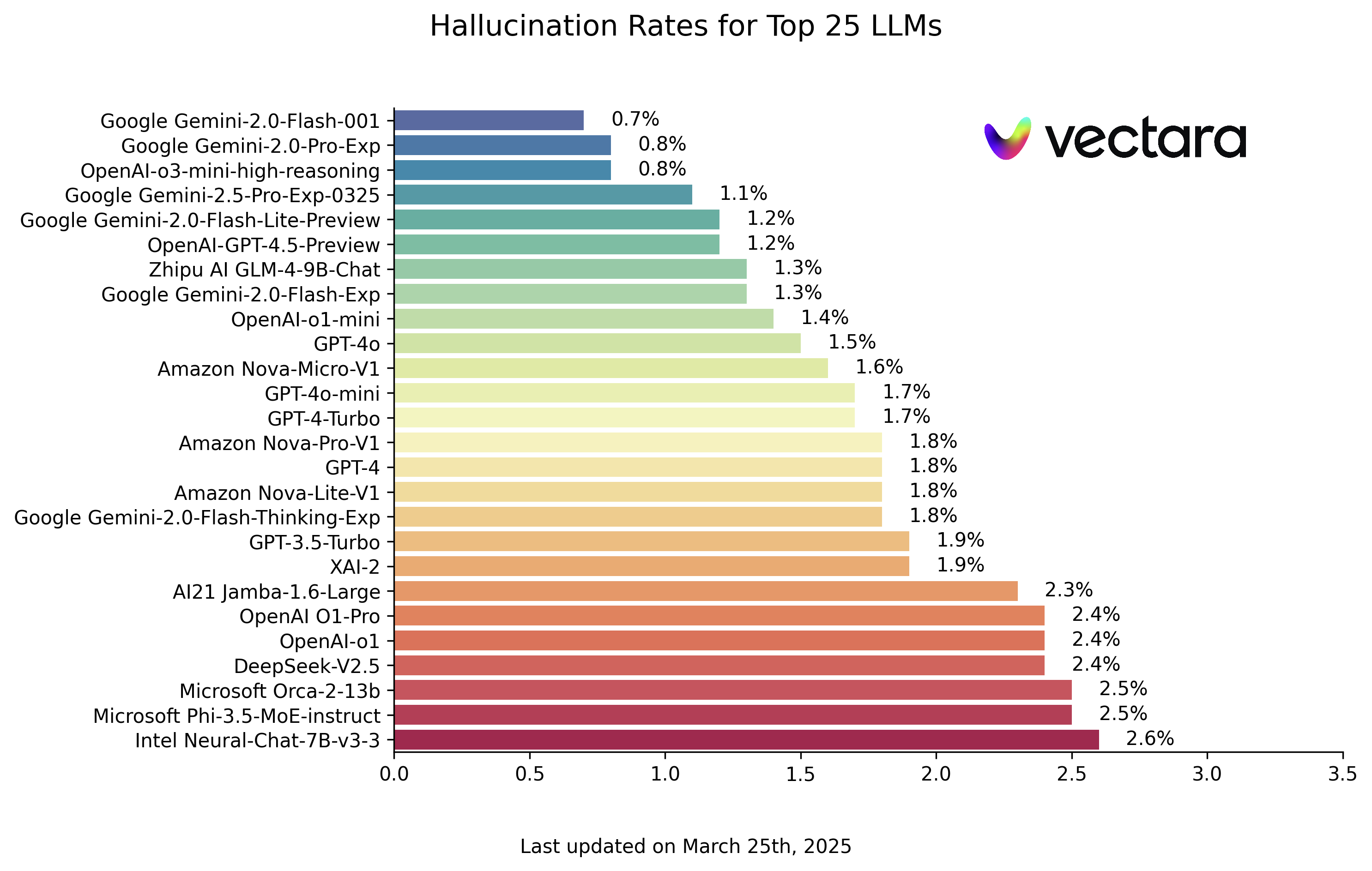
| Modell | Halluzinationsrate | Rate der faktischen Konsistenz | Antwortrate | Durchschnittliche Länge der Zusammenfassung (Wörter) |
|---|---|---|---|---|
| Google Gemini-2.0-Flash-001 | 0.7 % | 99.3 % | 100.0 % | 65.2 |
| Google Gemini-2.0-Pro-Exp | 0.8 % | 99.2 % | 99.7 % | 61.5 |
| OpenAI-o3-mini-high-reasoning | 0.8 % | 99.2 % | 100.0 % | 79.5 |
| Google Gemini-2.5-Pro-Exp-0325 | 1.1 % | 98.9 % | 95.1 % | 72.9 |
| Google Gemini-2.0-Flash-Lite-Vorschau | 1.2 % | 98.8 % | 99.5 % | 60.9 |
| OpenAI-GPT-4.5-Vorschau | 1.2 % | 98.8 % | 100.0 % | 77.0 |
| Zhipu AI GLM-4-9B-Chat | 1.3 % | 98.7 % | 100.0 % | 58.1 |
| Google Gemini-2.0-Flash-Exp | 1.3 % | 98.7 % | 99.9 % | 60.0 |
| OpenAI-o1-mini | 1.4 % | 98.6 % | 100.0 % | 78.3 |
| GPT-4o | 1.5 % | 98.5 % | 100.0 % | 77.8 |
| Amazonas Nova-Micro-V1 | 1.6 % | 98.4 % | 100.0 % | 90.0 |
| GPT-4o-mini | 1.7 % | 98.3 % | 100.0 % | 76.3 |
| GPT-4-Turbo | 1.7 % | 98.3 % | 100.0 % | 86.2 |
| Google Gemini-2.0-Blitz-Denk-Exp | 1.8 % | 98.2 % | 99.3 % | 73.2 |
| Amazonas Nova-Lite-V1 | 1.8 % | 98.2 % | 99.9 % | 80.7 |
| GPT-4 | 1.8 % | 98.2 % | 100.0 % | 81.1 |
| Amazon Nova-Pro-V1 | 1.8 % | 98.2 % | 100.0 % | 85.5 |
| GPT-3.5-Turbo | 1.9 % | 98.1 % | 99.6 % | 84.1 |
| XAI-2 | 1.9 % | 98.1 | 100.0 % | 86.5 |
| AI21 Jamba-1.6-Groß | 2.3 % | 97.7 % | 99.9 % | 85.6 |
| OpenAI O1-Pro | 2.4 % | 97.6 % | 100.0 % | 81.0 |
| OpenAI-o1 | 2.4 % | 97.6 % | 99.9 % | 73.0 |
| DeepSeek-V2.5 | 2.4 % | 97.6 % | 100.0 % | 83.2 |
| Microsoft Orca-2-13b | 2.5 % | 97.5 % | 100.0 % | 66.2 |
| Microsoft Phi-3.5-MoE-Anleitung | 2.5 % | 97.5 % | 96.3 % | 69.7 |
| Intel Neural-Chat-7B-v3-3 | 2.6 % | 97.4 % | 100.0 % | 60.7 |
| Google Gemma-3-12B-Instruct | 2.8 % | 97.2 % | 100.0 % | 69.6 |
| Qwen2.5-7B-Instruct | 2.8 % | 97.2 % | 100.0 % | 71.0 |
| AI21 Jamba-1.5-Mini | 2.9 % | 97.1 % | 95.6 % | 74.5 |
| XAI-2-Vision | 2.9 % | 97.1 | 100.0 % | 79.8 |
| Qwen2.5-Max | 2.9 % | 97.1 % | 88.8 % | 90.4 |
| Google Gemma-3-27B-Instruct | 3.0 % | 97.0 % | 100.0 % | 62.5 |
| Schneeflocken-Arktis-Instruct | 3.0 % | 97.0 % | 100.0 % | 68.7 |
| Qwen2.5-32B-Instruct | 3.0 % | 97.0 % | 100.0 % | 67.9 |
| Microsoft Phi-3-mini-128k-Instruktion | 3.1 % | 96.9 % | 100.0 % | 60.1 |
| Mistral Klein3 | 3.1 % | 96.9 % | 100.0 % | 74.9 |
| OpenAI-o1-Vorschau | 3.3 % | 96.7 % | 100.0 % | 119.3 |
| Google Gemini-1.5-Flash-002 | 3.4 % | 96.6 % | 99.9 % | 59.4 |
| Microsoft Phi-4-Mini-Anleitung | 3.4 % | 96.6 % | 100.0 % | 69.7 |
| Google Gemma-3-4B-Instruct | 3.7 % | 96.3 % | 100.0 % | 63.7 |
| 01-AI Yi-1.5-34B-Chat | 3.7 % | 96.3 % | 100.0 % | 83.7 |
| Llama-3.1-405B-Instruct | 3.9 % | 96.1 % | 99.6 % | 85.7 |
| DeepSeek-V3 | 3.9 % | 96.1 % | 100.0 % | 88.2 |
| Microsoft Phi-3-mini-4k-Instruktion | 4.0 % | 96.0 % | 100.0 % | 86.8 |
| Llama-3.3-70B-Instruct | 4.0 % | 96.0 % | 100.0 % | 85.3 |
| PraktikantLM3-8B-Instruct | 4.0 % | 96.0 % | 100.0 % | 97.5 |
| Microsoft Phi-3.5-Mini-Anleitung | 4.1 % | 95.9 % | 100.0 % | 75.0 |
| Mistral-Groß2 | 4.1 % | 95.9 % | 100.0 % | 77.4 |
| Llama-3-70B-Chat-hf | 4.1 % | 95.9 % | 99.2 % | 68.5 |
| Qwen2-VL-7B-Anleitung | 4.2 % | 95.8 % | 100.0 % | 73.9 |
| Qwen2.5-14B-Instruct | 4.2 % | 95.8 % | 100.0 % | 74.8 |
| Qwen2.5-72B-Instruct | 4.3 % | 95.7 % | 100.0 % | 80.0 |
| Llama-3.2-90B-Vision-Instruct | 4.3 % | 95.7 % | 100.0 % | 79.8 |
| Claude-3.7-Sonett | 4.4 % | 95.6 % | 100.0 % | 97.8 |
| Claude-3.7-Sonnet-Think | 4.5 % | 95.5 % | 99.8 % | 99.9 |
| Cohere Befehl-A | 4.5 % | 95.5 % | 100.0 % | 77.3 |
| AI21 Jamba-1.6-Mini | 4.6 % | 95.4 % | 100.0 % | 82.3 |
| XAI Grok | 4.6 % | 95.4 % | 100.0 % | 91.0 |
| Anthropisch Claude-3-5-Sonett | 4.6 % | 95.4 % | 100.0 % | 95.9 |
| Qwen2-72B-Instruct | 4.7 % | 95.3 % | 100.0 % | 100.1 |
| Microsoft Phi-4 | 4.7 % | 95.3 % | 100.0 % | 100.3 |
| Mixtral-8x22B-Instruct-v0.1 | 4.7 % | 95.3 % | 99.9 % | 92.0 |
| Anthropischer Claude-3-5-Haiku | 4.9 % | 95.1 % | 100.0 % | 92.9 |
| 01-AI Yi-1.5-9B-Chat | 4.9 % | 95.1 % | 100.0 % | 85.7 |
| Cohere Befehl-R | 4.9 % | 95.1 % | 100.0 % | 68.7 |
| Llama-3.1-70B-Instruct | 5.0 % | 95.0 % | 100.0 % | 79.6 |
| Google Gemma-3-1B-Instruct | 5.3 % | 94.7 % | 99.9 % | 57.9 |
| Llama-3.1-8B-Instruct | 5.4 % | 94.6 % | 100.0 % | 71.0 |
| Cohere Befehl-R-Plus | 5.4 % | 94.6 % | 100.0 % | 68.4 |
| Mistral-Klein-3.1-24B-Instruct | 5.6 % | 94.4 % | 100.0 % | 73.1 |
| Llama-3.2-11B-Vision-Instruct | 5.5 % | 94.5 % | 100.0 % | 67.3 |
| Llama-2-70B-Chat-hf | 5.9 % | 94.1 % | 99.9 % | 84.9 |
| IBM Granit-3.0-8B-Instruct | 6.5 % | 93.5 % | 100.0 % | 74.2 |
| Google Gemini-1.5-Pro-002 | 6.6 % | 93.7 % | 99.9 % | 62.0 |
| Google Gemini-1.5-Blitz | 6.6 % | 93.4 % | 99.9 % | 63.3 |
| Mistral-Pixtral | 6.6 % | 93.4 % | 100.0 % | 76.4 |
| Microsoft phi-2 | 6.7 % | 93.3 % | 91.5 % | 80.8 |
| Google Gemma-2-2B-it | 7.0 % | 93.0 % | 100.0 % | 62.2 |
| Qwen2.5-3B-Instruct | 7.0 % | 93.0 % | 100.0 % | 70.4 |
| Llama-3-8B-Chat-hf | 7.4 % | 92.6 % | 99.8 % | 79.7 |
| Mistral-Ministral-8B | 7.5 % | 92.5 % | 100.0 % | 62.7 |
| Google Gemini-Pro | 7.7 % | 92.3 % | 98.4 % | 89.5 |
| 01-AI Yi-1.5-6B-Chat | 7.9 % | 92.1 % | 100.0 % | 98.9 |
| Llama-3.2-3B-Instruct | 7.9 % | 92.1 % | 100.0 % | 72.2 |
| DeepSeek-V3-0324 | 8.0 % | 92.0 % | 100.0 % | 78.9 |
| Mistral-Ministral-3B | 8.3 % | 91.7 % | 100.0 % | 73.2 |
| Datenbausteine dbrx-Instruktion | 8.3 % | 91.7 % | 100.0 % | 85.9 |
| Qwen2-VL-2B-Anleitung | 8.3 % | 91.7 % | 100.0 % | 81.8 |
| Cohere Aya Weite 32B | 8.5 % | 91.5 % | 99.9 % | 81.9 |
| IBM Granit-3.1-8B-Instruct | 8.6 % | 91.4 % | 100.0 % | 107.4 |
| Mistral-klein2 | 8.6 % | 91.4 % | 100.0 % | 74.2 |
| IBM Granit-3.2-8B-Instruct | 8.7 % | 91.3 % | 100.0 % | 120.1 |
| IBM Granite-3.0-2B-Instruct | 8.8 % | 91.2 % | 100.0 % | 81.6 |
| Mistral-7B-Anleitung-v0.3 | 9.5 % | 90.5 % | 100.0 % | 98.4 |
| Google Gemini-1.5-Pro | 9.1 % | 90.9 % | 99.8 % | 61.6 |
| Anthropischer Claude-3-opus | 10.1 % | 89.9 % | 95.5 % | 92.1 |
| Google Gemma-2-9B-it | 10.1 % | 89.9 % | 100.0 % | 70.2 |
| Llama-2-13B-Chat-hf | 10.5 % | 89.5 % | 99.8 % | 82.1 |
| AllenAI-OLMo-2-13B-Instruct | 10.8 % | 89.2 % | 100.0 % | 82.0 |
| AllenAI-OLMo-2-7B-Instruct | 11.1 % | 88.9 % | 100.0 % | 112.6 |
| Mistral-Nemo-Instruct | 11.2 % | 88.8 % | 100.0 % | 69.9 |
| Llama-2-7B-Chat-hf | 11.3 % | 88.7 % | 99.6 % | 119.9 |
| Microsoft AssistentLM-2-8x22B | 11.7 % | 88.3 % | 99.9 % | 140.8 |
| Cohere Aya Ausdehnung 8B | 12.2 % | 87.8 % | 99.9 % | 83.9 |
| Amazon Titan-Express | 13.5 % | 86.5 % | 99.5 % | 98.4 |
| Google PaLM-2 | 14.1 % | 85.9 % | 99.8 % | 86.6 |
| DeepSeek-R1 | 14.3 % | 85.7 % | 100.0% | 77.1 |
| Google Gemma-7B-it | 14.8 % | 85.2 % | 100.0 % | 113.0 |
| IBM Granit-3.1-2B-Instruct | 15.7 % | 84.3 % | 100.0 % | 107.7 |
| Qwen2.5-1.5B-Instruct | 15.8 % | 84.2 % | 100.0 % | 70.7 |
| Qwen-QwQ-32B-Vorschau | 16.1 % | 83.9 % | 100.0 % | 201.5 |
| Anthropisches Claude-3-Sonett | 16.3 % | 83.7 % | 100.0 % | 108.5 |
| IBM Granite-3.2-2B-Instruct | 16.5 % | 83.5 % | 100.0 % | 117.7 |
| Google Gemma-1.1-7B-it | 17.0 % | 83.0 % | 100.0 % | 64.3 |
| Anthropischer Akt-2 | 17.4 % | 82.6 % | 99.3 % | 87.5 |
| Google Flan-T5-groß | 18.3 % | 81.7 % | 99.3 % | 20.9 |
| Mixtral-8x7B-Anleitung-v0.1 | 20.1 % | 79.9 % | 99.9 % | 90.7 |
| Llama-3.2-1B-Instruct | 20.7 % | 79.3 % | 100.0 % | 71.5 |
| Apple OpenELM-3B-Instruct | 24.8 % | 75.2 % | 99.3 % | 47.2 |
| Qwen2.5-0.5B-Instruct | 25.2 % | 74.8 % | 100.0 % | 72.6 |
| Google Gemma-1.1-2B-it | 27.8 % | 72.2 % | 100.0 % | 66.8 |
| TII Falke-7B-Anleitung | 29.9 % | 70.1 % | 90.0 % | 75.5 |
Hinweis: Die Modelle sind in absteigender Reihenfolge nach der Phantomrate geordnet. Die vollständige Liste und die Details zum Modellzugang können im ursprünglichen HHEM Leaderboard GitHub-Repository eingesehen werden.
Ein Blick auf die Rangliste zeigt, dass Googles Gemini Familie von Modellen und einige der neueren Modelle von OpenAI (z. B. das o3-mini-high-reasoning) haben beeindruckende Ergebnisse erzielt, wobei die Rate der Halluzinationen auf einem sehr niedrigen Niveau gehalten wurde. Dies zeigt die Fortschritte, die die Hersteller von Kopfhörern bei der Verbesserung der Faktorisierung ihrer Modelle gemacht haben. Gleichzeitig sind erhebliche Unterschiede zwischen den Modellen verschiedener Größen und Architekturen festzustellen. Einige kleinere Modelle, wie das von Microsoft Phi Serie oder Googles Gemma Reihe, erzielten ebenfalls gute Ergebnisse, was darauf hindeutet, dass die Anzahl der Modellparameter nicht die einzige Determinante für die faktische Konsistenz ist. Einige frühe oder speziell optimierte Modelle weisen jedoch relativ hohe Täuschungsquoten auf.
Diskrepanz zwischen starken Inferenzmodellen und Wissensbasen: der Fall DeepSeek-R1
die Charts (der Bestseller) DeepSeek-R1 Die relativ hohe Rate an Halluzinationen (14,31 TP3T) wirft eine Frage auf, die es wert ist, untersucht zu werden: Warum neigen einige Modelle, die bei logischen Aufgaben gut abschneiden, bei faktenbasierten Zusammenfassungsaufgaben zu Halluzinationen?
DeepSeek-R1 Solche Modelle sind oft so konzipiert, dass sie komplexes logisches Denken, das Befolgen von Befehlen und das Denken in mehreren Schritten beherrschen. Ihre Hauptstärke liegt in der "Deduktion" und "Ableitung" und nicht einfach in der "Wiederholung" oder "Paraphrasierung". Allerdings können Wissensdatenbanken (insbesondere RAG (Wissensbasis in Szenarien) ist die Kernanforderung genau die letztgenannte: Das Modell muss Antworten oder Zusammenfassungen ausschließlich auf der Grundlage der bereitgestellten Textinformationen geben, wobei die Einführung von externem Wissen oder eine Überextraktion auf ein Minimum beschränkt werden.
Wenn ein starkes Reasoning-Modell nur auf die Zusammenfassung mit einem bestimmten Dokument beschränkt ist, kann sein "Reasoning"-Instinkt ein zweischneidiges Schwert sein. Es kann:
- Überinterpretation. Unnötige Extrapolation von Informationen aus dem Originaltext und Ziehen von Schlussfolgerungen, die im Originaltext nicht ausdrücklich erwähnt werden.
- Informationen zum Nähen. Es wird versucht, die fragmentierten Informationen im Originaltext durch eine "vernünftige" logische Kette zu verknüpfen, die möglicherweise nicht durch den Originaltext gestützt wird.
- Externes Standardwissen. Selbst wenn sie aufgefordert werden, sich nur auf den Originaltext zu verlassen, kann das in ihrer Ausbildung erworbene umfangreiche Wissen über die Welt unbewusst einfließen und zu Abweichungen von den Fakten des Originaltextes führen.
Einfach ausgedrückt, können solche Modelle "zu viel denken", und in Szenarien, die eine genaue und getreue Wiedergabe von Informationen erfordern, neigen sie dazu, "zu schlau für ihr eigenes Wohl" zu sein und Inhalte zu schaffen, die vernünftig zu sein scheinen, aber in Wirklichkeit eine Illusion sind. Dies zeigt, dass die Argumentationsfähigkeit von Modellen und die faktische Konsistenz (insbesondere bei eingeschränkten Informationsquellen) zwei unterschiedliche Fähigkeitsdimensionen sind. Für Szenarien wie Wissensdatenbanken und RAGs kann es wichtiger sein, Modelle mit einer niedrigen Halluzinationsrate auszuwählen, die die eingegebenen Informationen getreu wiedergeben, als einfach nur eine Argumentationsbewertung zu verfolgen.
Methodik und Hintergrund
Das HHEM-Ranking ist nicht aus dem Nichts entstanden und baut auf einer Reihe früherer Bemühungen im Bereich der Erforschung der faktischen Konsistenz auf, wie z. B. den folgenden SUMMAC, TRUE, TrueTeacher Die Methodik, die in den Arbeiten von et al. Die zentrale Idee besteht darin, ein Modell speziell für die Erkennung von Halluzinationen zu trainieren, das ein hohes Maß an Korrelation mit menschlichen Bewertern bei der Beurteilung der Übereinstimmung der Zusammenfassung mit dem Originaltext erreicht.
Die Zusammenfassungsaufgabe wurde im Rahmen des Evaluierungsprozesses als Proxy für die Faktizität des LLM ausgewählt. Dies liegt nicht nur daran, dass die Zusammenfassungsaufgabe selbst ein hohes Maß an faktischer Konsistenz erfordert, sondern auch daran, dass sie dem Arbeitsmodell des RAG-Systems sehr ähnlich ist - in RAG ist es das LLM, das die Rolle der Integration und Zusammenfassung der abgerufenen Informationen spielt. Die Ergebnisse dieses Rankings sind daher aufschlussreich für die Beurteilung der Zuverlässigkeit des Modells in RAG-Anwendungen.
Es sei darauf hingewiesen, dass das Bewertungsteam Dokumente ausschloss, bei denen die Modelle die Antwort verweigerten oder sehr kurze, ungültige Antworten gaben, und schließlich die 831 Dokumente (von ursprünglich 1006), für die alle Modelle erfolgreich Zusammenfassungen erstellen konnten, für die endgültige Berechnung der Rangfolge verwendete, um Fairness zu gewährleisten. Die Metriken für die Antwortrate und die durchschnittliche Länge der Zusammenfassungen spiegeln auch die Verhaltensmuster der Modelle bei der Bearbeitung dieser Anfragen wider.
Die für die Bewertung verwendete Prompt-Vorlage lautet wie folgt:
You are a chat bot answering questions using data. You must stick to the answers provided solely by the text in the passage provided. You are asked the question 'Provide a concise summary of the following passage, covering the core pieces of information described.' <PASSAGE>'
Zum Zeitpunkt des eigentlichen Anrufs wird die<PASSAGE> wird durch den spezifischen Inhalt des Quelldokuments ersetzt.
vorausschauend
Das HHEM-Ranking-Programm hat angekündigt, dass es plant, den Umfang der Bewertung in Zukunft zu erweitern:
- Genauigkeit der Zitate. Fügen Sie eine Bewertung der Genauigkeit der LLM-Quellennachweise in den RAG-Szenarien hinzu.
- Andere RAG-Aufgaben. Abdeckung weiterer RAG-bezogener Aufgaben, wie z.B. die Zusammenfassung von mehreren Dokumenten.
- Mehrsprachige Unterstützung. Ausweitung der Bewertung auf andere Sprachen als Englisch.
Das HHEM-Ranking bietet ein wertvolles Fenster für die Beobachtung und den Vergleich der Fähigkeit verschiedener LLMs, Täuschungen zu kontrollieren und die faktische Konsistenz zu erhalten. Es ist zwar nicht das einzige Maß für die Qualität eines Modells und deckt auch nicht alle Arten von Täuschungen ab, aber es hat sicherlich die Aufmerksamkeit der Branche auf das Thema der LLM-Zuverlässigkeit gelenkt und bietet einen wichtigen Bezugspunkt für Entwickler, um Modelle auszuwählen und zu optimieren. In dem Maße, wie die Modelle und Bewertungsmethoden weiter verbessert werden, können wir noch mehr Fortschritte bei der Bereitstellung von genauen und vertrauenswürdigen Informationen aus LLMs erwarten.
© urheberrechtliche Erklärung
Artikel Copyright AI-Austauschkreis Alle, bitte nicht ohne Erlaubnis vervielfältigen.
Ähnliche Artikel


Keine Kommentare...