
Intern-S1 - Quelloffene wissenschaftliche multimodale Makromodelle vom Shanghai AI Lab

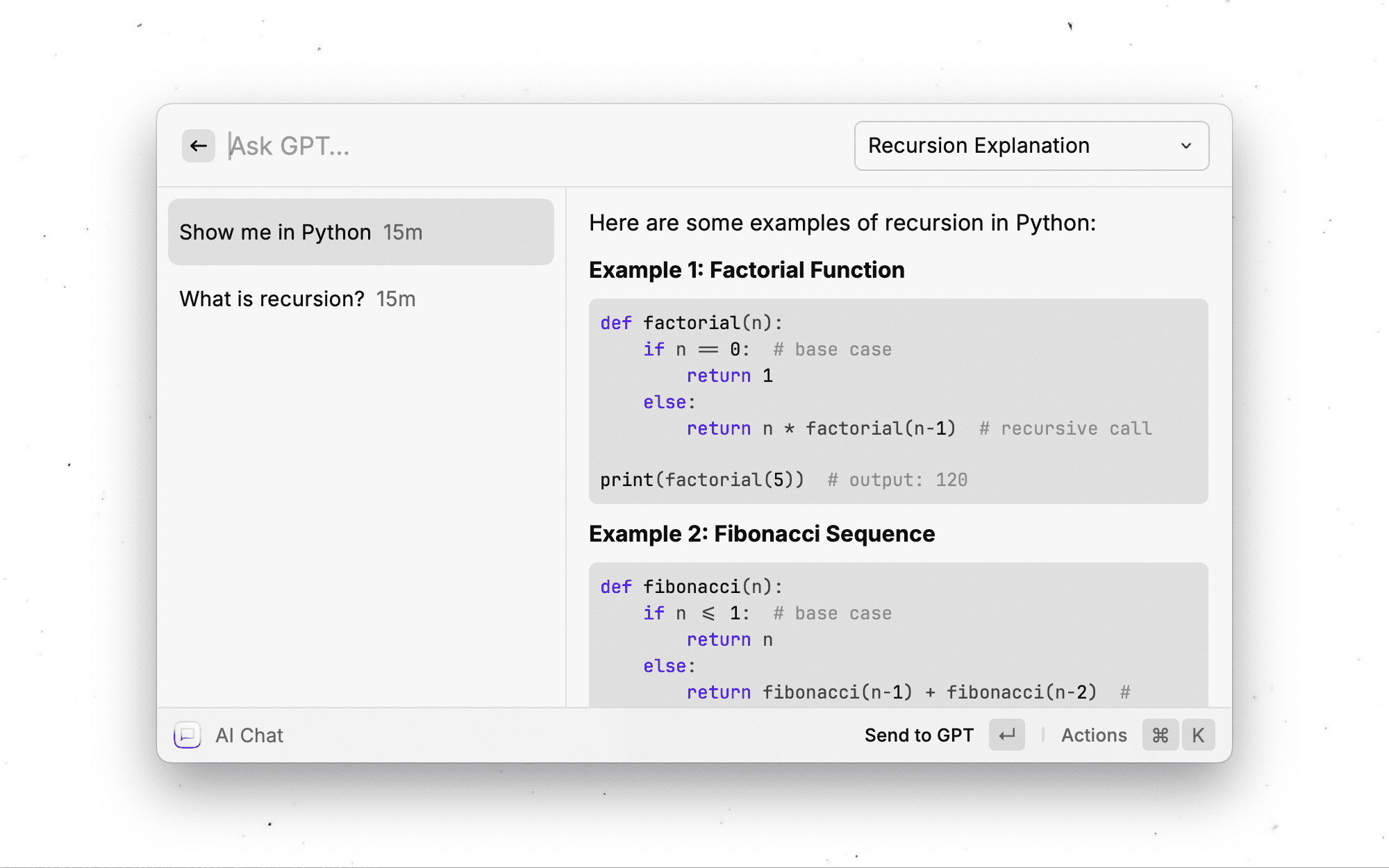
Was ist Intern-S1?
Intern-S1 ist ein wissenschaftliches multimodales Großmodell, das vom Shanghai Artificial Intelligence Laboratory entwickelt wurde. Das Modell integriert linguistische und multimodale Fähigkeiten und verfügt über leistungsstarke Funktionen wie cross-modales wissenschaftliches Parsing, linguistische und visuelle Fusion, wissenschaftliche Datenverarbeitung, Beantwortung wissenschaftlicher Fragen, Versuchsplanung und -optimierung usw. Intern-S1 ist die erste "cross-modale wissenschaftliche Parsing-Engine", die komplexe wissenschaftliche modale Daten wie chemische Molekularformeln, Proteinsequenzen, seismische Signale usw. genau interpretieren kann und die besten Closed-Source-Modelle bei multidisziplinären professionellen Aufgaben übertrifft. Intern-S1 basiert auf dem Dynamic Tokenizer und dem Time-Series Signal Encoder, um eine tiefgreifende Fusion mehrerer wissenschaftlicher Modalitäten zu erreichen, mit leistungsstarken allgemeinen Argumentationsfähigkeiten und erstklassigen professionellen Fähigkeiten durch die Verwendung von allgemeiner und spezialisierter Fusion wissenschaftlicher Datensynthese, die weithin bei der Integration wissenschaftlicher Forschungswerkzeuge, Bild- und Textfusion und komplexer wissenschaftlicher modaler Datenverarbeitung und anderen Szenarien eingesetzt wird.

Hauptfunktionen von Intern-S1
- Modalübergreifende wissenschaftliche AnalyseIm Folgenden finden Sie einige Beispiele dafür, wie wir komplexe wissenschaftliche Modaldaten genau interpretieren können, z. B. bei der Vorhersage von Synthesewegen für Verbindungen und der Bestimmung der Durchführbarkeit chemischer Reaktionen in der Chemie, bei der Analyse von Proteinsequenzen und der Entdeckung von Zielstrukturen für Medikamente in der Biomedizin sowie bei der Identifizierung seismischer Signale und der Analyse seismischer Ereignisse im Bereich der Geowissenschaften.
- Verbale und visuelle IntegrationKombination von verbalen und visuellen Informationen für komplexe multimodale Aufgaben.
- Wissenschaftliche DatenverarbeitungUnterstützung einer Vielzahl komplexer wissenschaftlicher modaler Dateneingaben, wie z. B. Lichtveränderungskurven in der Materialwissenschaft und Gravitationswellensignale in der Astronomie usw., um eine tiefgreifende Fusion und effiziente Verarbeitung von Daten zu erreichen.
- Antworten auf wissenschaftliche FragenBenutzer erhalten genaue Antworten auf wissenschaftliche Fragen auf der Grundlage einer leistungsstarken Wissensbasis und von Schlussfolgerungsmöglichkeiten.
- Versuchsplanung und OptimierungUnterstützung der Forscher bei der Erstellung von Versuchsprotokollen, der Optimierung von Versuchsabläufen und der Verbesserung der Forschungseffizienz.
- Multi-Intelligenz-TeamarbeitUnterstützt multi-intelligente Körpersysteme, die mit anderen Intelligenzen zusammenarbeiten, um komplexe wissenschaftliche Aufgaben zu bewältigen.
- Autonomes Lernen und EvolutionEs hat die Fähigkeit, selbständig zu lernen und seine Leistung auf der Grundlage seiner Interaktion mit der Umwelt zu optimieren.
- Datenverarbeitung und -analyseBereitstellung von Datenverarbeitungs- und Analysetools, die Forschern helfen, wissenschaftliche Daten schnell zu verarbeiten und zu analysieren.
- Einsatz und Anwendung von ModellenUnterstützt die lokale Bereitstellung und Cloud-Dienste für den einfachen Einsatz in verschiedenen Szenarien.
Intern-S1 offizielle Website-Adresse
- Projekt-Website:: https://intern-ai.org.cn/
- Github-Repositorien:: https://github.com/InternLM/Intern-S1
- HuggingFace-Modellbibliothek:: https://huggingface.co/internlm/Intern-S1-FP8
So verwenden Sie Intern-S1
- Plattform für Online-Erlebnisse
- ZugangsplattformenÖffnen Sie Ihren Browser und besuchen Sie die offizielle Website des Projekts, um das Intern-S1-Modell kennenzulernen.
- Aufnahme eines Dialogs: Geben Sie eine Frage oder Anfrage in das Eingabefeld ein und senden Sie es ab, um eine Antwort von Intern-S1 zu erhalten.
- Nutzung von SonderfunktionenBefolgen Sie die Anweisungen auf der Plattform entsprechend der Funktion, die Sie interessiert, z. B. organische Chemie.
- GitHub-Repository
- Klon-LagerKlonen Sie das Repository, indem Sie den folgenden Befehl in die Kommandozeile eingeben:
git clone https://github.com/InternLM/Intern-S1.git- Installation von Abhängigkeiten: Wechseln Sie in das Repository-Verzeichnis und installieren Sie die Python-Abhängigkeiten:
cd Intern-S1
pip install -r requirements.txt- BetriebsmodellAusführen des Modells anhand der README-Datei im Repository oder des Beispielcodes. Normalerweise können Sie Python-Skripte verwenden:
python script_name.pySpezifische Skriptnamen und Parameter müssen entsprechend den Anweisungen im Repository angepasst werden.
- Umarmendes Gesicht Modellbibliothek
- Modelle laden: Verwenden Sie den folgenden Code in der Python-Umgebung, um das Modell und den Disambiguator zu laden:
from transformers import AutoModelForCausalLM, AutoTokenizer
model_name = "internlm/Intern-S1-FP8"
tokenizer = AutoTokenizer.from_pretrained(model_name)
model = AutoModelForCausalLM.from_pretrained(model_name)- Text generierenVerwenden Sie das Modell, um Text zu erstellen oder andere Aufgaben auszuführen:
inputs = tokenizer("Tell me about an interesting physical phenomenon.", return_tensors="pt")
output = model.generate(**inputs, max_length=100)
print(tokenizer.decode(output[0], skip_special_tokens=True))- Verwendung der Modell-APIWenn Hugging Face einen API-Dienst anbietet, rufen Sie das Modell direkt über die API auf:
import requests
url = "https://api-inference.huggingface.co/models/internlm/Intern-S1-FP8"
headers = {"Authorization": "Bearer YOUR_HUGGINGFACE_API_TOKEN"}
data = {"inputs": "Tell me about an interesting physical phenomenon."}
response = requests.post(url, headers=headers, json=data)
print(response.json()["generated_text"])Die wichtigsten Vorteile von Intern-S1
- multimodale FähigkeitEs kombiniert leistungsstarke Sprachverstehens- und visuelle Verarbeitungsfunktionen und ist in der Lage, Texte, Bilder und viele andere Datentypen zu verarbeiten und zu verstehen.
- Optimierung wissenschaftlicher MissionenModelle eignen sich hervorragend für naturwissenschaftliche Aufgaben wie die Entschlüsselung chemischer Strukturen, das Verständnis von Proteinsequenzen und die Planung von Synthesewegen für Verbindungen.
- Groß angelegte VorschulungAufbauend auf einem 235-Milliarden-Parameter-MoE-Sprachmodell (Mixture of Experts) und einem visuellen Codierer mit 6-Milliarden-Parametern, die mit 5 Billionen Token multimodaler Daten trainiert wurden, von denen mehr als 2,5 Billionen Token aus dem wissenschaftlichen Bereich stammen.
- Dynamischer TokenizerDas Modell basiert auf einem dynamischen Tokenizer, der das native Verständnis spezialisierter Daten wie Molekularformeln, Proteinsequenzen und seismischer Signale unterstützt.
- Modalübergreifende wissenschaftliche Parsing-MaschineDie bahnbrechende, modalübergreifende wissenschaftliche Parsing-Engine des Intern-S1 ist in der Lage, ein breites Spektrum komplexer wissenschaftlicher Modaldaten genau zu interpretieren, was ein hervorragendes wissenschaftliches Denken und Verständnis beweist.
- Allgemeines logisches Denken und berufliche KompetenzAuf der Grundlage der wissenschaftlichen Datensynthesemethode der Allzweckfusion verfügt Praktikant-S1 über eine starke allgemeine Denkfähigkeit und eine Reihe von erstklassigen beruflichen Fähigkeiten.
- Autonomes Lernen und EvolutionDas Modell ist in der Lage, selbständig zu lernen und seine Leistung durch Interaktion mit der Umwelt zu optimieren.
- Multi-Intelligenz-TeamarbeitUnterstützt multi-intelligente Körpersysteme, die mit anderen Intelligenzen zusammenarbeiten können, um komplexe wissenschaftliche Aufgaben zu bewältigen.
- Datenverarbeitung und -analyseBereitstellung von Datenverarbeitungs- und Analysetools, die Forschern helfen, wissenschaftliche Daten schnell zu verarbeiten und zu analysieren.
Personen, für die Intern-S1 bestimmt ist
- (wissenschaftlicher) ForscherForscher, die komplexe Datenanalysen und Versuchspläne in den Bereichen Chemie, Biologie, Physik und Geowissenschaften durchführen.
- DatenanalystFachleute, die aus großen Mengen wissenschaftlicher Daten wertvolle Informationen für die Entscheidungsfindung gewinnen.
- SoftwareentwicklerSoftwareentwickler, die fortgeschrittene multimodale Analysefunktionen in ihre Anwendungen integrieren.
- Lehrkräfte und StudentenLehrkräfte und Studierende, die Modelle zur Unterstützung des Unterrichts oder zur Durchführung wissenschaftlicher Forschung in einem akademischen Umfeld verwenden.
- Entscheidungsträger in UnternehmenUnternehmensleiter, die wichtige Geschäftsentscheidungen auf der Grundlage von Datenanalysen treffen.
© urheberrechtliche Erklärung
Artikel Copyright AI-Austauschkreis Alle, bitte nicht ohne Erlaubnis vervielfältigen.
Ähnliche Artikel


Keine Kommentare...