ImBD: Erkennung von KI-generierten Inhalten, Erkennung, ob ein Inhalt von KI generiert wurde oder nicht

Allgemeine Einführung
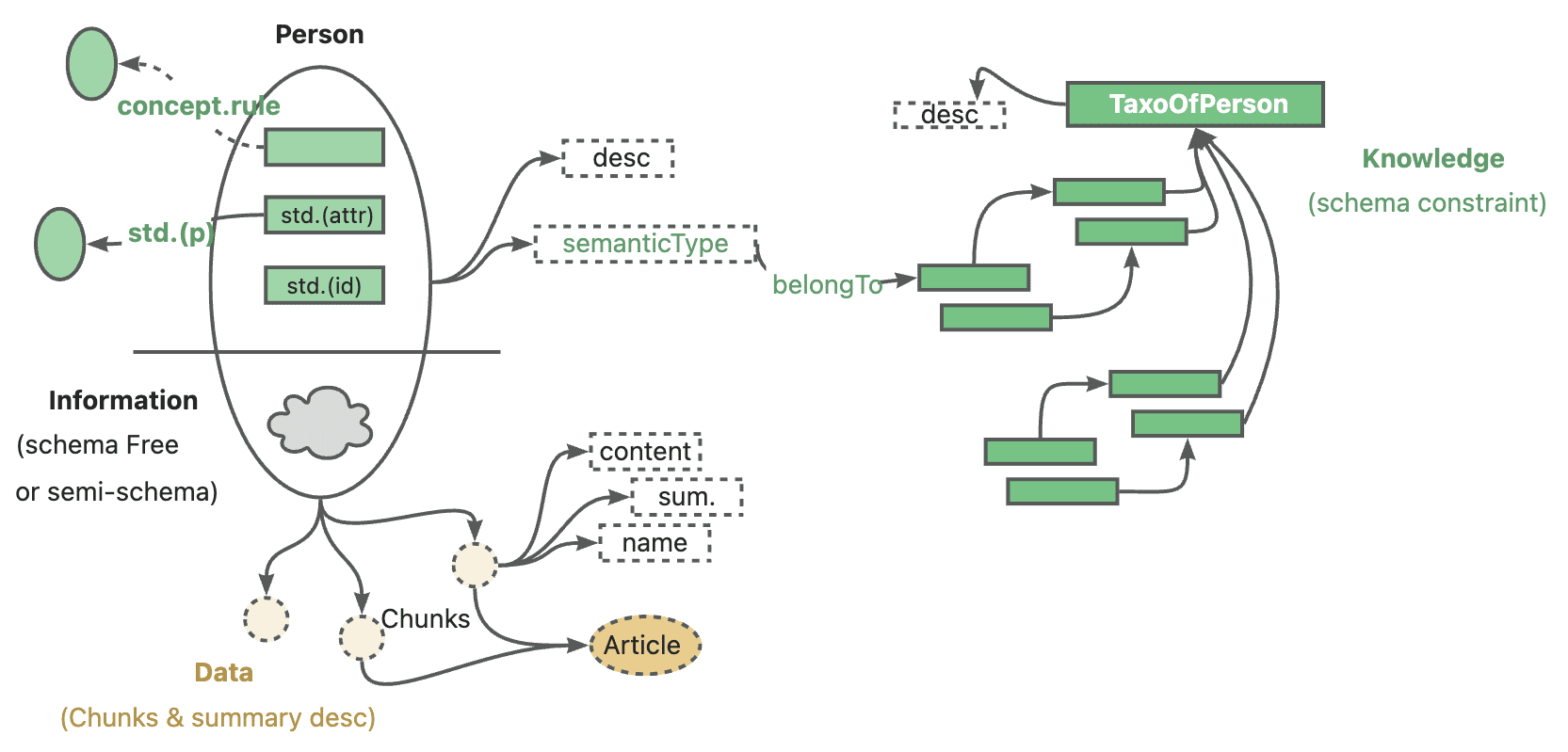
ImBD (Imitate Before Detect) ist ein bahnbrechendes Projekt zur Erkennung maschinell erzeugter Texte, das auf der AAAI 2025 vorgestellt wurde. Mit dem weit verbreiteten Einsatz von Large Language Models (LLMs) wie ChatGPT ist die Erkennung von KI-generierten Textinhalten zunehmend schwieriger geworden. Das ImBD-Projekt schlägt einen neuartigen "Imitate Before Detect"-Ansatz vor, der die Erkennung durch ein tieferes Verständnis der stilistischen Merkmale des Maschinentextes und seiner Nachahmung verbessert. Diese Methode ist die erste, die die stilistische Präferenz von angeglichenem Maschinentext vorschlägt und einen umfassenden Rahmen für die Texterkennung schafft, mit dem maschinell erzeugter Text, der von Menschen verändert wurde, effektiv erkannt werden kann. Das Projekt steht unter der Open-Source-Lizenz Apache 2.0 und bietet eine vollständige Code-Implementierung, vortrainierte Modelle und eine ausführliche Dokumentation, die es Forschern und Entwicklern erleichtert, auf dieser Grundlage weitere Forschung und Anwendungsentwicklung zu betreiben.

Demo-Adresse: https://ai-detector.fenz.ai/ai-detector
Funktionsliste
- Unterstützt die hochpräzise Erkennung von maschinell erstelltem Text
- Bereitstellung von vortrainierten Modellen für den direkten Einsatz und die Verwendung
- Neuartiger Algorithmus zum Abgleich von Textmerkmalen implementiert
- Enthält detaillierte experimentelle Datensätze und Bewertungsbenchmarks
- Bereitstellung eines vollständigen Schulungs- und Inferenzcodes
- Unterstützt benutzerdefinierte Trainingsdaten für die Feinabstimmung des Modells
- Enthält eine ausführliche API-Dokumentation und Anwendungsbeispiele.
- Bereitstellung von Befehlszeilen-Tools für schnelle Tests und Bewertungen
- Unterstützt die Stapelverarbeitung von Text
- Enthält Visualisierungstools zur Anzeige von Testergebnissen
Hilfe verwenden
1. ökologische Konfiguration
Zunächst müssen Sie Ihre Python-Umgebung konfigurieren und die erforderlichen Abhängigkeiten installieren:
git clone https://github.com/Jiaqi-Chen-00/ImBD
cd ImBD
pip install -r requirements.txt
2. die Datenaufbereitung
Bevor Sie mit der Anwendung von ImBD beginnen, müssen Trainings- und Testdaten vorbereitet werden. Die Daten sollten die folgenden zwei Kategorien enthalten:
- Manuell erstellter Originaltext
- Maschinell erzeugter oder maschinell bearbeiteter Text
Anforderungen an das Datenformat:
- Textdateien müssen UTF-8 kodiert sein
- Jede Probe nimmt eine Zeile ein
- Es wird vorgeschlagen, den Datensatz in eine Trainingsmenge, eine Validierungsmenge und eine Testmenge im Verhältnis 8:1:1 aufzuteilen.
3. die Modellausbildung
Führen Sie den folgenden Befehl aus, um das Training zu starten:
python train.py \
--train_data path/to/train.txt \
--val_data path/to/val.txt \
--model_output_dir path/to/save/model \
--batch_size 32 \
--learning_rate 2e-5 \
--num_epochs 5
4. die Modellbewertung
Bewerten Sie die Leistung des Modells anhand von Testsätzen:
python evaluate.py \
--model_path path/to/saved/model \
--test_data path/to/test.txt \
--output_file evaluation_results.txt
5. die Texterkennung
Erkennung von einzelnen Texten:
python detect.py \
--model_path path/to/saved/model \
--input_text "要检测的文本内容" \
--output_format json
Stapelweise Erkennung von Text:
python batch_detect.py \
--model_path path/to/saved/model \
--input_file input.txt \
--output_file results.json
6. erweiterte Funktionen
6.1 Feinabstimmung des Modells
Das Modell kann mit Ihrem eigenen Datensatz feinabgestimmt werden, wenn Sie eine Optimierung für domänenspezifischen Text benötigen:
python finetune.py \
--pretrained_model_path path/to/pretrained/model \
--train_data path/to/domain/data \
--output_dir path/to/finetuned/model
6.2 Analyse der Visualisierung
Analysieren Sie die Testergebnisse mit dem integrierten Visualisierungstool:
python visualize.py \
--results_file path/to/results.json \
--output_dir path/to/visualizations
6.3 Bereitstellung von API-Diensten
Stellen Sie das Modell als REST-API-Dienst bereit:
python serve.py \
--model_path path/to/saved/model \
--host 0.0.0.0 \
--port 8000
7 Vorbehalte
- GPUs werden für die Modellschulung empfohlen, um die Effizienz zu verbessern
- Die Qualität der Trainingsdaten hat einen erheblichen Einfluss auf die Modellleistung
- Regelmäßige Aktualisierung des Modells, um neue KI-generierte Textmerkmale zu berücksichtigen
- Beachtung der Modellversionierung bei der Bereitstellung in Produktionsumgebungen
- Es wird empfohlen, die Testergebnisse für eine spätere Analyse und Modelloptimierung zu speichern.
8. häufig gestellte Fragen
F: Welche Sprachen unterstützt das Modell?
A: Derzeit unterstützen wir hauptsächlich Englisch, andere Sprachen müssen mit entsprechenden Datensätzen trainiert werden.
F: Wie kann ich die Genauigkeit meiner Tests verbessern?
A: Die Leistung kann durch das Hinzufügen von Trainingsdaten, das Abstimmen von Modellparametern und die Feinabstimmung mit domänenspezifischen Daten verbessert werden.
F: Wie kann die Erkennungsgeschwindigkeit optimiert werden?
A: Die Erkennungsgeschwindigkeit kann durch Stapelverarbeitung, Modellquantisierung und GPU-Beschleunigung verbessert werden.
© urheberrechtliche Erklärung
Artikel Copyright AI-Austauschkreis Alle, bitte nicht ohne Erlaubnis vervielfältigen.
Ähnliche Artikel


Keine Kommentare...