Conch Stimme inländischen Start, kann die beste chinesische Voice-Synchronisation Produkte werden
Es hat nicht eine inländische Produktion für den Inhalt der Produktion von hervorragenden Voice-over-Produkte, entweder können Sie nur die API oder das Produkt ist in Ordnung Sound-Modell nicht funktioniert.
Zum Beispiel in Übersee ElevenLabs Obwohl die englische ist in Ordnung, aber die chinesische ist wirklich ziehen über, das Hauptproblem der Open-Source-Modell ist, dass das Modell Qualität ist relativ schlecht, insbesondere in der schlechten Tonqualität, gibt es ein klares Gefühl der aktuellen, Multi-Sprache gemischt Szenen und Multi-Sound Multi-Bedeutung Wort Ausdruck ungenau und so weiter.
MiniMax wurde vor einem Monat in Betrieb genommen. Conch AI internationale Version, online zweite Stimme Klonen Funktion, Chinesisch und Englisch vorgelesen sehr gut!Die Funktion zur Stimmerzeugung wurde vor ein paar Tagen auf der nationalen Seite freigeschaltet, und ich war sehr überrascht, als ich sie ausprobierte.Unterstützung von über 17 Sprachen, präzise Steuerung verschiedener emotionaler Ausdrücke und Hunderte von Soundbibliotheken für unterschiedliche Anforderungen..
Das Wichtigste ist, dass die Audioqualität wirklich gut ist, ohne die üblichen Probleme bei der Klangerzeugung und mit einer hochgradig anpassbaren Option, die den Klang verändert, auch wenn derselbe Ton verwendet wird.
Werfen wir einen Blick auf dieses kleine Stück, das ich gemacht habe, und sehen wir uns dann die Auswirkungen der Spracherzeugungsfähigkeiten von Conch an, sowohl in Bezug auf die Funktionalität als auch auf die Effektivität.
Detaillierte Optionen zur Anpassung der Funktionen
Werfen wir einen Blick auf die Funktionen von Conch Voice, es ist wirklich leistungsfähig und detailliert, Conch hat eine riesige Sound-Bibliothek unterstützt mehr als 17 Sprachen.Jede Sprache unterstützt eine breite Palette von Tönen, und Sie können frei zwischen männlichen und weiblichen Stimmen sowie dem Alter wählen..
Sie können filtern, um Töne jeder Identität und jedes Alters zu finden, die Sie benötigen, z. B. benötigt unser Videoskript einen älteren Mann mit Gerechtigkeitssinn, der über diesen Filter schnell gefunden werden kann.
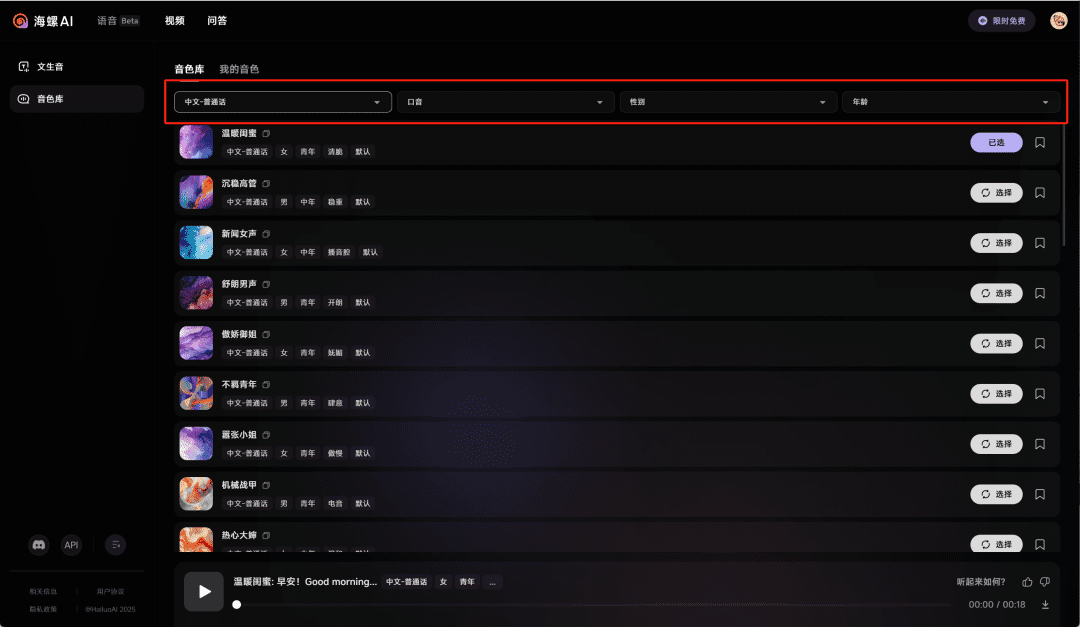
Es ist auch möglich, den Ton nach der Auswahl bis ins kleinste Detail anzupassen.
Zunächst einmal können Sie die Emotionen des Tons, einschließlich glücklich, traurig, wütend und andere fünf oder sechs Arten von Emotionen, zum Beispiel die folgenden Audio-ich zeige die verschiedenen emotionalen Leistung des Tons von warmen Freundinnen, können Sie deutlich hören, sehr natürlich.
Dann ist die Geschwindigkeit der Rede, das ist sehr gut zu verstehen, je höher der Wert der schneller er spricht, die Lautstärke ist auch sehr gut zu verstehen, je höher der Wert der Stimme der höheren Stimme, der Ton dieser Ich habe versucht, grob kann als der Wert der größeren die Stimme der spitzeren, desto kleiner der Wert der Stimme der weicheren verstanden werden.
Durch die Kontrolle dieser vier Anpassungsoptionen können wirEs kann so gestimmt werden, dass es sehr unterschiedlich klingt, auch wenn man denselben Ton wählt. Es macht wirklich Spaß, das auszuprobieren!.
Ein weiterer Tipp ist es, '' an der Stelle hinzuzufügen, an der Sie eine Pause benötigen, diese Art von Markierungen können das Modell dazu bringen, eine Tonpause für eine bestimmte Zeit zu erzeugen, wenn Sie diese Art von Bedarf haben, können Sie es versuchen.
Leistungsstarke Generierungseffekte
Zusätzlich zu den reichen Timbre zusätzlich zu den Muscheln Modell Ontologie ist auch sehr mächtig, haben wir einige Open-Source-TTS wissen, dass viele Modelle der häufigsten Probleme der Klangqualität Probleme ist, gibt es ein Gefühl der aktuellen, einige Verzerrungen einige sind absichtlich hinzugefügt einige sind Ausbildung Probleme.
Hier habe ich einen relativ langen Absatz gefunden, den ich vor einiger Zeit für ihn geschrieben habe, um ein kleines Diktat zu erstellen, dasDie Tonqualität ist sehr gut, die Pausen sind natürlich, und er betont, wenn es nötig ist..
Ein weiteres häufiges Problem bei der Sprachmodellierung ist die Erstellung sehr langer Inhalte.Viele Modelle unterstützen sehr kurze Textlängen, Conch unterstützt bis zu 10.000 Zeichen.Das ist im Grunde die Länge von längeren Manuskripten und Romanen mit einem Kapitel, und das ist völlig ausreichend.
Das folgende ist ein Zeitraum von Zeit vor fand ich ein Wu Enda zweitausend Worte des Manuskripts, das er sehr gut und kein Problem zu lesen, die Erzeugung von Geschwindigkeit ist auch sehr schnell, kann er während der Vorschau zu generieren, sehr zeitsparend!
Das letzte knifflige Problem ist die mehrsprachige gemischte Szene und polyphone Szene, einige relativ gute Sprachmodelle haben auch oft Probleme, speziell lassen Sie die KI einen Testtext erzeugt, ein Absatz enthält fünf verschiedene Sprachen, die Muschel liest perfekt, das ist wirklich zu stark.
Guten Morgen! Je suis très heureux de vous rencontrer. Ich liebe Musik und Kunst. Das macht mich sehr glücklich. ¡Buenos días amigos! Lasst uns zu Mittag essen.
Es handelt sich um eine mehrstimmige Szene, in der er die Aussprache von "walk" (háng), "first" (xíng), "bank" (háng) und "trip" (xíng) in ihren verschiedenen Positionen genau bestimmt und sehr komplexe mehrstimmige Äußerungen sehr gut beherrscht.
Ich werde heute einen Schritt vorausgehen und anhalten, wenn ich eine Linie fahre. Ich muss morgen zur Bank, wenn ich also im Stau stehe, könnte mein Zeitplan beeinträchtigt werden.
Das ist alles für die Einführung. Sie können damit weiter herumspielen und es an den folgenden Stellen verwenden:
Muschelstimme: https://hailuoai.com/audioHailuo
国内API服务:https://platform.minimaxi.com/document/T2A%20V2
Letztes Jahr habe ich mit meinen Freunden immer darüber gesprochen, wann es in China ein so leistungsfähiges Voice-Over-Produkt wie ElevenLabs geben würde, und jetzt haben wir sogar noch bessere Ergebnisse als ElevenLabs, und in 24 Jahren haben wir Modelle entwickelt, die vom Bild über das Video bis hin zum Audio mit den Klassenbesten konkurrieren können, so dass ich hoffe, dass die einheimischen KI-Anbieter uns dieses Jahr mehr Überraschungen bieten können.
© urheberrechtliche Erklärung
Artikel Copyright AI-Austauschkreis Alle, bitte nicht ohne Erlaubnis vervielfältigen.
Ähnliche Artikel

Keine Kommentare...