开源大模型,免费使用GPU资源和API服务(测试期)-1")
glhf.chat: Ausführung fast (aller) quelloffener großer Modelle, freier Zugang zu GPU-Ressourcen und API-Diensten (Betaphase)

Allgemeine Einführung
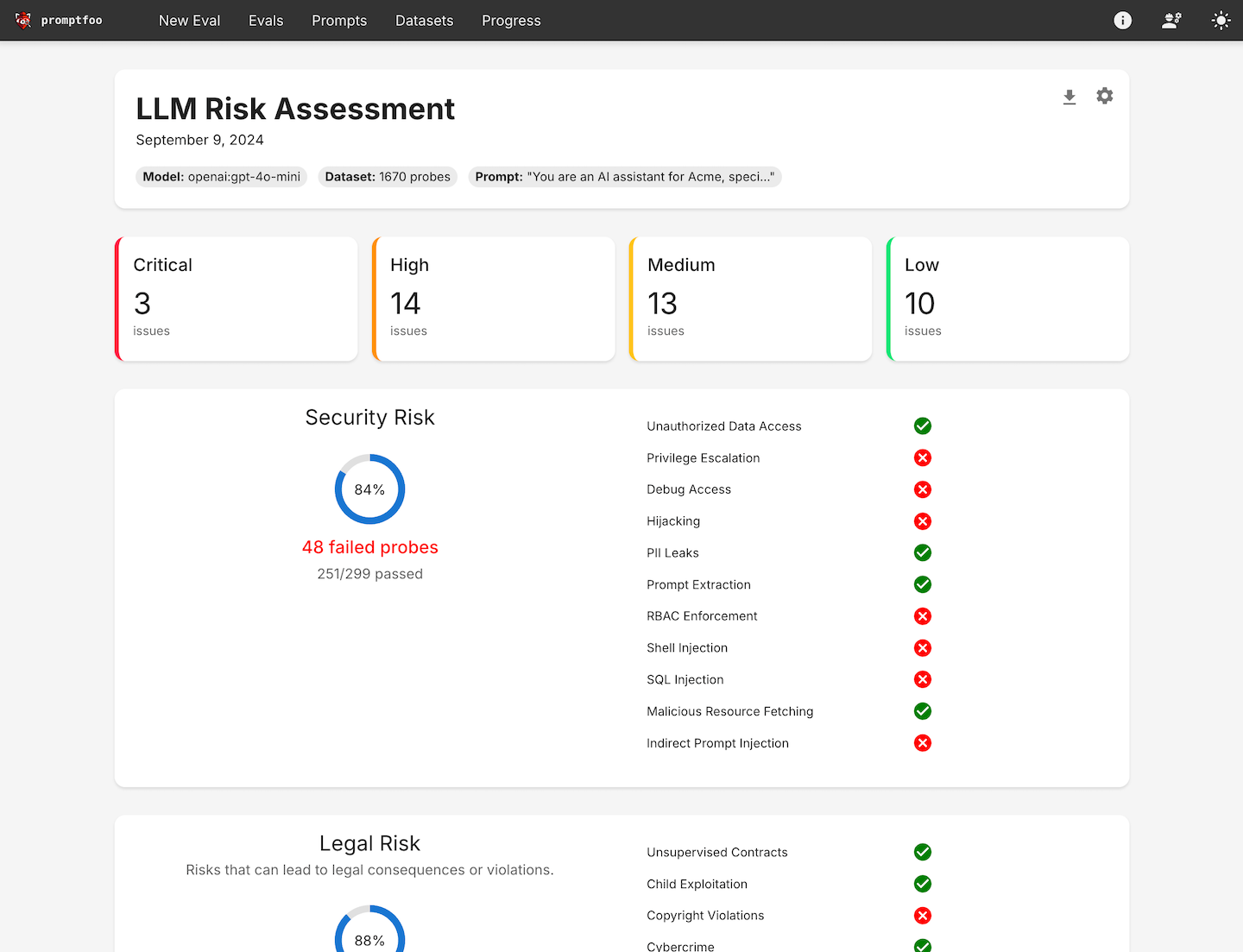
good luck have fun (glhf.chat) ist eine Website, die einen Open-Source-Chatdienst für große Modelle anbietet. Die Plattform ermöglicht es Benutzern, fast jedes Open-Source-Big-Model mit vLLM und einem benutzerdefinierten, automatisch skalierenden GPU-Scheduler auszuführen. Benutzer können einfach einen Link zum Hugging Face Repository einfügen und über die Chat-Schnittstelle oder OpenAI-kompatible APIs interagieren. Die Plattform wird während der Beta-Phase kostenlos angeboten und wird in Zukunft zu einem niedrigeren Preis als die großen Cloud-GPU-Anbieter erhältlich sein.
开源大模型,免费使用GPU资源和API服务(测试期)-1")
Funktionsliste
- Unterstützt eine Vielzahl von Open-Source-Makromodellen, darunter Meta Llama, Qwen, Mixtral usw.
- Ermöglicht den Zugriff auf bis zu acht Nvidia A100 80Gb GPUs
- Reasoning Services für automatisierte Agentenpopulationsmodelle
- Bedarfsgesteuertes Starten und Herunterfahren von Clustern zur Optimierung der Ressourcennutzung
- Bietet OpenAI-kompatible APIs für eine einfache Integration
Hilfe verwenden
Installation und Nutzung
- Registrieren & Anmelden: Zugangglhf.chatund registrieren Sie sich für ein Konto und melden Sie sich anschließend an.
- Modell auswählenWählen Sie das gewünschte Makromodell auf der Homepage der Plattform aus, darunter Meta Llama, Qwen, Mixtral und andere.
- Den Link einfügenEinfügen: Fügen Sie den Link zum Hugging Face Repository an der angegebenen Stelle ein, und die Plattform wird das Modell automatisch laden.
- Verwendung der Chat-SchnittstelleInteraktion mit dem Modell über die Chatschnittstelle auf der Website: Geben Sie Fragen oder Befehle ein, und das Modell wird in Echtzeit Antworten geben.
- API-EinbindungIntegrieren Sie die Funktionen der Plattform in Ihre eigenen Anwendungen mit Hilfe von OpenAI-kompatiblen APIs, wie in der API-Dokumentation im Help Centre der Website beschrieben.
Detaillierte Funktionsabläufe
- Modellauswahl und Laden::
- Nach dem Einloggen gelangen Sie zur Modellauswahlseite.
- Blättern Sie durch die Liste der unterstützten Modelle und klicken Sie auf das gewünschte Modell.
- Fügen Sie den Link zum Hugging Face Repository in das Pop-up-Dialogfeld ein und klicken Sie auf die Schaltfläche "Modell laden".
- Warten Sie, bis das Modell vollständig geladen ist. Die Ladezeit hängt von der Größe des Modells und den Netzbedingungen ab.
- Verwendung der Chat-Schnittstelle::
- Sobald das Modell geladen ist, rufen Sie den Chat-Bildschirm auf.
- Geben Sie eine Frage oder Anweisung in das Eingabefeld ein und klicken Sie auf Senden.
- Das Modell generiert eine Antwort auf der Grundlage der Eingaben und die Antwort wird im Chatfenster angezeigt.
- Es können mehrere Fragen oder Befehle nacheinander eingegeben werden, die das Modell nacheinander verarbeitet und beantwortet.
- API-Verwendung::
- Besuchen Sie die API-Dokumentationsseite für API-Schlüssel und Anweisungen.
- Integrieren Sie die API in Ihre Anwendung und folgen Sie dem in der Dokumentation enthaltenen Beispielcode, um Aufrufe zu tätigen.
- Senden Sie eine Anfrage über die API, um eine vom Modell generierte Antwort zu erhalten.
- Die API unterstützt eine Vielzahl von Programmiersprachen, siehe die Dokumentation für spezifischen Beispielcode.
Ressourcenmanagement und -optimierung
- Auto-ErweiterungDie Plattform verwendet einen benutzerdefinierten GPU-Scheduler, der die GPU-Ressourcen je nach Benutzerbedarf automatisch auf- und abbaut, um eine effiziente Nutzung zu gewährleisten.
- Aktivierung auf AbrufFür Modelle, die nicht häufig verwendet werden, startet die Plattform Cluster bei Bedarf und schaltet sie automatisch ab, wenn sie verwendet werden, um Ressourcen zu sparen.
- Kostenloser TestWährend des Betatests haben die Nutzer kostenlosen Zugang zu allen Funktionen der Plattform, und am Ende des Tests wird ein vergünstigter Tarif verfügbar sein.
© urheberrechtliche Erklärung
Artikel Copyright AI-Austauschkreis Alle, bitte nicht ohne Erlaubnis vervielfältigen.
Ähnliche Artikel

Keine Kommentare...