
Advanced RAG: Architektur, Technologie, Anwendungen und Entwicklungsperspektiven
Retrieval-augmented generation (RAG) ist zu einem wichtigen Rahmenwerk im Bereich der Künstlichen Intelligenz geworden, das die Genauigkeit und Relevanz von großen Sprachmodellen (LLMs) bei der Generierung von Antworten unter Verwendung externer Wissensquellen erheblich verbessert. Laut Datenbausteine Die Daten zeigen, dass 60% der LLM-Anwendungen in den Unternehmen Retrieval Augmented Generation (RAG) verwenden, wobei 30% einen mehrstufigen Prozess verwenden.RAG hat viel Aufmerksamkeit erhalten, weil es Antworten erzeugt, die fast so gut sind wie diejenigen, die sich nur auf die Feinabstimmung des Modells verlassen Verbesserte Genauigkeit des 43%Sie zeigt, dass die RAG großes Potenzial zur Verbesserung der Qualität und Zuverlässigkeit von KI-generierten Inhalten.
Herkömmliche RAG-Ansätze stehen jedoch immer noch vor einer Reihe von Herausforderungen, wenn es darum geht, komplexe Anfragen zu beantworten, differenzierte Zusammenhänge zu verstehen und mehrere Datentypen zu verarbeiten. Diese Einschränkungen haben die Entwicklung fortschrittlicher RAGs vorangetrieben, die die Fähigkeiten der KI bei der Informationsbeschaffung und -generierung verbessern sollen. Besonders hervorzuheben.Anzahl der Unternehmen Die RAG wurde in etwa 60%-Produkte integriert, was ihre Bedeutung und Wirksamkeit in der Praxis belegt.
Einer der wichtigsten Durchbrüche in diesem Bereich war die Einführung von multimodalen RAGs und Wissensgraphen. Multimodale RAG erweitern die Fähigkeit von RAGs, nicht nur Text, sondern auch eine breite Palette von Daten wie Bilder, Audio und Video zu verarbeiten. Dies ermöglicht es KI-Systemen, umfassender zu sein und ein besseres kontextuelles Verständnis bei der Interaktion mit Nutzern zu haben. Wissensgraphen hingegen verbessern die Kohärenz und Genauigkeit des Informationsbeschaffungsprozesses und der generierten Inhalte durch eine strukturierte Wissensdarstellung.Microsoft Forschung deutet darauf hin, dass das GraphRAG erforderlich ist Token Die Anzahl wird von 26% auf 97% im Vergleich zu anderen Methoden reduziert, was eine höhere Effizienz und geringere Rechenkosten bedeutet.
Diese Fortschritte in der RAG-Technologie haben zu erheblichen Leistungssteigerungen bei verschiedenen Benchmarks und realen Anwendungen geführt. Zum Beispiel.Wissenslandkarte erreichte im RobustQA-Test eine Genauigkeit von 86,31%, was andere RAG-Methoden weit übertrifft. Darüber hinaus ist dieSequeda und Allemang In einer Folgestudie wurde festgestellt, dass die Kombination von Ontologien die 20%-Fehlerquote verringert. Auch die Unternehmen haben von diesen Fortschritten stark profitiert, dieLinkedIn meldete eine Reduzierung der Lösungszeit für den Kundensupport um 28,61 TP3T durch den Ansatz RAG plus Knowledge Graph.
In diesem Beitrag werden wir uns mit der Entwicklung fortschrittlicher RAGs befassen und die Komplexität von multimodalen RAGs und Wissensgraphen-RAGs sowie ihre Effektivität bei der Verbesserung der KI-gestützten Informationssuche und -generierung untersuchen. Wir werden auch das Potenzial dieser Innovationen für die Anwendung in verschiedenen Branchen und die Herausforderungen bei der Förderung und Anwendung dieser Technologien diskutieren.
- [Was ist Retrieval Augmented Generation (RAG) und warum ist es wichtig für Large Language Modelling (LLM)?
- [Arten der RAG-Architektur]
- [Von der Basis-RAG zur fortgeschrittenen RAG: Überwindung von Einschränkungen und Verbesserung der Fähigkeiten]
- [Fortgeschrittene RAG-Systemkomponenten und Prozesse im Unternehmen]
- [Fortgeschrittene RAG-Technologie]
- [Fortgeschrittene RAG-Anwendungen und Fallstudien]
- [Wie baut man Dialogwerkzeuge mit fortgeschrittenem RAG?]
- [Wie erstelle ich eine fortgeschrittene RAG-Anwendung?]
- [Der Aufstieg der Wissensgraphen in der fortgeschrittenen RAG]
- [Advanced RAG: Verbesserte Generierung von erweiterten Horizonten durch multimodales Retrieval]
- [Wie sich die GenAI-Kollaborationsplattform ZBrain von LeewayHertz von den fortschrittlichen RAG-Systemen abhebt].
Advanced RAG: Architektur, Technologie, Anwendungen und Entwicklungsperspektiven PDF Download:
Advanced RAG: Architektur, Technologie, Anwendungen und Entwicklungsperspektiven
Was ist Retrieval Augmented Generation (RAG) und warum ist es wichtig für Large Language Modelling (LLM)?
Große Sprachmodelle (Large Language Models, LLMs) sind zu einem zentralen Bestandteil von KI-Anwendungen geworden, deren Leistung von virtuellen Assistenten bis hin zu ausgefeilten Datenanalysetools genutzt wird. Doch trotz ihrer Fähigkeiten sind diese Modelle nur begrenzt in der Lage, aktuelle und genaue Informationen zu liefern. An dieser Stelle bietet Retrieval Augmented Generation (RAG) eine leistungsstarke Ergänzung zu LLM.
Was ist Retrieval Augmented Generation (RAG)?
Retrieval Augmented Generation (RAG) ist eine fortschrittliche Technik, die die generativen Fähigkeiten von Large Language Models (LLMs) durch die Integration externer Wissensquellen erweitert.LLMs werden auf großen Datensätzen mit Milliarden von Parametern trainiert und sind in der Lage, eine breite Palette von Aufgaben wie die Beantwortung von Fragen, linguistische Übersetzung und Textvervollständigung durchzuführen.RAGs gehen einen Schritt weiter, indem sie auf maßgebliche und domänenspezifische Wissensdatenbanken verweisen, um die Relevanz, Genauigkeit und Nützlichkeit der generierten Inhalte zu verbessern, ohne dass das Modell neu trainiert werden muss. RAGs gehen einen Schritt weiter, indem sie auf maßgebliche und domänenspezifische Wissensdatenbanken verweisen, um die Relevanz, Genauigkeit und Nützlichkeit der generierten Inhalte zu verbessern, ohne dass das Modell neu trainiert werden muss. Dieser kostengünstige und effiziente Ansatz ist ideal für Unternehmen, die ihre KI-Systeme optimieren wollen.
Wie kann RAG (Retrieval Augmented Generation) Large Language Modelling (LLM) helfen, das Kernproblem zu lösen?
Große Sprachmodelle (Large Language Models, LLMs) spielen eine Schlüsselrolle bei der Steuerung intelligenter Chatbots und anderer NLP-Anwendungen (Natural Language Processing). Durch umfangreiches Training versuchen sie, genaue Antworten in einer Vielzahl von Kontexten zu geben. LLMs selbst haben jedoch einige Schwächen und stehen vor zahlreichen Herausforderungen:
- FehlermeldungUngenaue Antworten können erzeugt werden, wenn die LLM-Kenntnisse unzureichend sind.
- Überholte InformationenDie Trainingsdaten sind statisch, so dass die vom Modell generierten Antworten veraltet sein können.
- nicht-autoritäre QuelleGenerierte Antworten können manchmal aus unzuverlässigen Quellen stammen, was die Glaubwürdigkeit beeinträchtigt.
- terminologische VerwirrungInkonsistente Verwendung der gleichen Terminologie durch verschiedene Datenquellen kann leicht zu Missverständnissen führen.
RAG geht auf diese Probleme ein, indem es dem LLM eine externe maßgebliche Datenquelle zur Verfügung stellt, um die Genauigkeit und den Echtzeitcharakter der Antworten des Modells zu verbessern. Die folgenden Punkte erklären, warum RAG so wichtig für die Entwicklung des LLM ist:
- Verbesserung von Genauigkeit und RelevanzRAG extrahiert die aktuellsten und relevantesten Informationen aus maßgeblichen Quellen, um sicherzustellen, dass die Antworten des Modells genauer und für den aktuellen Kontext relevant sind, da die Trainingsdaten statisch sind.
- Die Grenzen der statischen Daten durchbrechenDie LLM-Ausbildungsdaten sind manchmal veraltet und spiegeln nicht die neuesten Forschungsergebnisse oder Nachrichten wider. Die RAG verschafft LLM Zugang zu den neuesten Daten und hält die Informationen aktuell und relevant.
- Stärkung des Vertrauens der NutzerLLM kann so genannte "Illusionen" erzeugen - selbstbewusste, aber falsche Antworten - und die RAG erhöht die Transparenz und das Vertrauen der Nutzer, indem sie LLM erlaubt, Quellen zu zitieren und überprüfbare Informationen zu liefern.
- KosteneinsparungRAG bietet eine kostengünstigere Alternative zum erneuten Trainieren des LLM mit neuen Daten, was eine kostengünstige Alternative zum erneuten Trainieren des gesamten Modells mit externen Datenquellen darstellt und fortgeschrittene KI-Techniken breiter verfügbar macht.
- Verbesserte Kontrolle und Flexibilität für EntwicklerRAG bietet Entwicklern mehr Freiheit, Wissensquellen flexibel zu spezifizieren, sich schnell an veränderte Anforderungen anzupassen und einen angemessenen Umgang mit sensiblen Informationen zu gewährleisten, um ein breites Spektrum von Anwendungen zu unterstützen und die Effektivität von KI-Systemen zu verbessern.
- Maßgeschneiderte Antworten gebenWährend herkömmliche LLMs dazu neigen, zu allgemeine Antworten zu geben, kombiniert RAG LLMs mit den internen Datenbanken des Unternehmens, Produktinformationen und Benutzerhandbüchern, um spezifischere und relevantere Antworten zu geben und so die Kundenbetreuung und -interaktion erheblich zu verbessern.
RAG (Retrieval Augmented Generation) ermöglicht es LLM, durch die Integration mit externen Wissensdatenbanken genauere, Echtzeit- und kontextualisierte Antworten zu generieren. Dies ist für Organisationen, die sich auf KI verlassen, von Kundenservice bis Datenanalyse, von entscheidender Bedeutung. RAG verbessert nicht nur die Effizienz, sondern erhöht auch das Vertrauen der Nutzer in KI-Systeme.
Arten der RAG-Architektur
Retrieval Augmented Generation (RAG) stellt einen großen Fortschritt in der KI-Technologie dar, indem Sprachmodelle mit externen Wissensabfragesystemen kombiniert werden. Dieser hybride Ansatz verbessert die Fähigkeit der KI-Antwortgenerierung, indem detaillierte und relevante Informationen aus großen externen Datenquellen gewonnen werden. Das Verständnis der verschiedenen Arten von RAG-Architekturen hilft uns, ihre Vorteile entsprechend unseren spezifischen Anforderungen besser zu nutzen. Im Folgenden werden die drei wichtigsten RAG-Architekturen eingehend erläutert:
1. naive RAG
Naive RAG ist die einfachste Methode zur Generierung von Retrieval-Erweiterungen. Das Prinzip ist einfach: Das System extrahiert relevante Informationsbrocken aus der Wissensbasis auf der Grundlage der Anfrage des Benutzers und verwendet diese Informationsbrocken dann als Kontext, um die Antwort durch Sprachmodellierung zu generieren.
Merkmale:
- AbrufmechanismusEine einfache Retrieval-Methode wird verwendet, um relevante Blöcke von Dokumenten aus einem vorher erstellten Index zu extrahieren, normalerweise durch Schlüsselwort-Matching oder grundlegende semantische Ähnlichkeit.
- kontextuelle IntegrationDie abgerufenen Dokumente werden mit der Anfrage des Benutzers zusammengeführt und in das Sprachmodell eingegeben, um eine Antwort zu generieren. Durch diese Fusion erhält das Modell einen umfassenderen Kontext, um relevantere Antworten zu generieren.
- BearbeitungsablaufDas System folgt einem festen Prozess: Abrufen, Zusammenfügen, Generieren. Das Modell verändert die extrahierten Informationen nicht, sondern verwendet sie direkt, um Antworten zu generieren.
2. erweiterte RAG
Advanced RAG basiert auf Naive RAG und verwendet fortschrittlichere Techniken zur Verbesserung der Abrufgenauigkeit und der kontextuellen Relevanz. Es überwindet einige der Einschränkungen von Naive RAG durch die Kombination fortschrittlicher Mechanismen zur besseren Verarbeitung und Nutzung von Kontextinformationen.
Merkmale:
- Verbessertes AbrufenVerbesserung der Qualität und Relevanz der abgerufenen Informationen durch fortgeschrittene Suchstrategien wie die Erweiterung der Suchanfrage (Hinzufügen relevanter Begriffe zur ursprünglichen Anfrage) und die iterative Suche (Optimierung der Dokumente in mehreren Schritten).
- Optimierung des KontextesSelektive Fokussierung auf die relevantesten Teile des Kontextes durch Techniken wie den Aufmerksamkeitsmechanismus hilft dem Sprachmodell, genauere und kontextuell präzisere Antworten zu generieren.
- OptimierungsstrategieOptimierung: Optimierungsstrategien wie Relevanzbewertung und kontextuelle Anreicherung werden eingesetzt, um sicherzustellen, dass das Modell die relevantesten und hochwertigsten Informationen zur Generierung von Antworten erfasst.
3. modulare RAG
Modular RAG ist die flexibelste und am besten anpassbare RAG-Architektur. Sie gliedert den Abruf- und Erzeugungsprozess in einzelne Module auf und ermöglicht so die Optimierung und den Austausch je nach den Bedürfnissen der spezifischen Anwendungen.
Merkmale:
- Modularer AufbauRAG: Zerlegung des RAG-Prozesses in verschiedene Module wie Abfrageerweiterung, Abruf, Neuordnung und Generierung. Jedes Modul kann unabhängig optimiert und bei Bedarf ersetzt werden.
- Flexible AnpassungErmöglicht ein hohes Maß an Anpassung, wobei die Entwickler bei jedem Schritt verschiedene Konfigurationen und Techniken ausprobieren können, um die beste Lösung zu finden. Die Methodik bietet maßgeschneiderte Lösungen für eine Vielzahl von Anwendungsszenarien.
- Integration und AnpassungDie Architektur ist in der Lage, zusätzliche Funktionalitäten wie ein Speichermodul (zur Aufzeichnung vergangener Interaktionen) oder ein Suchmodul (zur Extraktion von Daten aus Suchmaschinen oder Wissensgraphen) zu integrieren. Diese Anpassungsfähigkeit erlaubt es, das RAG-System flexibel an die jeweiligen Bedürfnisse anzupassen.
Die Kenntnis dieser Arten und Merkmale ist entscheidend für die Auswahl und Implementierung der am besten geeigneten RAG-Architektur.
Von der einfachen zur fortgeschrittenen RAG: Überwindung von Grenzen und Erweiterung von Fähigkeiten
Die Retrieval-augmented Generation (RAG) wird in der Natürliche Sprachverarbeitung (NLP) Es hat sich zu einer sehr effektiven Methode für die Kombination von Informationssuche und Texterstellung entwickelt, die eine genauere und kontextbezogene Ausgabe ermöglicht. Im Zuge der technologischen Entwicklung haben die anfänglichen "Basis"-RAG-Systeme jedoch einige Mängel aufgedeckt, die zur Entwicklung fortschrittlicherer Versionen geführt haben. Die Entwicklung von Basis-RAG zu fortgeschrittenem RAG bedeutet, dass wir diese Mängel allmählich überwinden und die Gesamtfähigkeiten des RAG-Systems erheblich verbessern.
Beschränkungen der Basis-RAG

Das zugrundeliegende RAG Framework ist ein erster Versuch, Retrieval und Generierung für NLP zu kombinieren. Obwohl dieser Ansatz innovativ ist, stößt er noch an einige Grenzen:
- Einfache SuchmethodenDie meisten grundlegenden RAG-Systeme beruhen auf dem einfachen Abgleich von Schlüsselwörtern, einem Ansatz, der es schwierig macht, die Nuancen und den Kontext der Abfrage zu verstehen und daher nur unzureichend oder teilweise relevante Informationen zu finden.
- Schwierigkeiten, den Kontext zu verstehenEs ist für diese Systeme schwierig, den Kontext einer Benutzeranfrage richtig zu verstehen. So kann das zugrundeliegende RAG-System zwar Dokumente abrufen, die die Schlüsselwörter einer Abfrage enthalten, aber die eigentliche Absicht oder den Kontext des Benutzers nicht erfassen und somit die Bedürfnisse des Benutzers nicht genau erfüllen.
- Begrenzte Fähigkeit, komplexe Abfragen zu bearbeitenEinfache RAG-Systeme schneiden bei komplexen oder mehrstufigen Abfragen schlecht ab. Sie sind nicht in der Lage, den Kontext zu verstehen und genau zu recherchieren, so dass es schwierig ist, komplexe Probleme effektiv zu lösen.
- Statische WissensbasisDas zugrundeliegende RAG-System stützt sich auf eine statische Wissensbasis und verfügt nicht über einen Mechanismus zur dynamischen Aktualisierung; die Informationen können im Laufe der Zeit veraltet sein, was die Genauigkeit und Relevanz der Antwort beeinträchtigt.
- Fehlende iterative OptimierungDie zugrundeliegende RAG verfügt nicht über einen Mechanismus zur Optimierung auf der Grundlage von Rückmeldungen, kann ihre Leistung nicht durch iteratives Lernen verbessern und stagniert mit der Zeit.
Übergang zu Advanced RAG
Im Zuge der technologischen Entwicklung stehen immer ausgefeiltere Lösungen zur Verfügung, um die Unzulänglichkeiten der einfachen RAG-Systeme zu beheben. Fortgeschrittene RAG-Systeme überwinden diese Herausforderungen auf verschiedene Weise:
- Komplexere SuchalgorithmenFortgeschrittene RAG-Systeme verwenden ausgefeilte Techniken wie semantische Suche und kontextbezogenes Verstehen, die über den Abgleich von Schlüsselwörtern hinausgehen, um die tatsächliche Bedeutung hinter einer Anfrage zu verstehen und so die Relevanz der abgerufenen Ergebnisse zu verbessern.
- Verbesserte kontextbezogene IntegrationDiese Systeme integrieren Kontext- und Relevanzgewichte in die Suchergebnisse, um sicherzustellen, dass die Informationen nicht nur korrekt sind, sondern auch in den Kontext passen und besser auf die Anfrage und die Absicht des Benutzers eingehen.
- Iterative Optimierung und Rückkopplungsmechanismen::
Das Advanced RAG-System verwendet einen iterativen Optimierungsprozess, der die Genauigkeit und Relevanz im Laufe der Zeit durch die Einbeziehung von Nutzerfeedback kontinuierlich verbessert. - Dynamische Wissensaktualisierung::
Das fortschrittliche RAG-System ist in der Lage, die Wissensbasis dynamisch zu aktualisieren, kontinuierlich die neuesten Informationen einzubringen und sicherzustellen, dass das System immer die neuesten Trends und Entwicklungen widerspiegelt. - Komplexes kontextuelles Verständnis::
Durch den Einsatz fortgeschrittener NLP-Techniken verfügen fortgeschrittene RAG-Systeme über ein tieferes Verständnis der Anfrage und des Kontexts und sind in der Lage, semantische Nuancen, kontextuelle Hinweise und die Absicht des Nutzers zu analysieren, um kohärentere und relevantere Antworten zu generieren.
Erweiterte RAG-Systemverbesserungen bei Komponenten
Die Entwicklung vom einfachen zum fortgeschrittenen RAG bedeutet, dass das System in jeder der vier Schlüsselkomponenten - Speicherung, Abruf, Anreicherung und Erzeugung - erhebliche Verbesserungen erzielt.
- auf HaldeFortgeschrittene RAG-Systeme machen die Informationssuche effizienter, indem sie Daten durch semantische Indizierung speichern, die nach der Bedeutung der Daten und nicht nach einfachen Schlüsselwörtern organisiert sind.
- abrufen (Daten)Mit der Verbesserung der semantischen Suche und der kontextbezogenen Abfrage findet das System nicht nur relevante Daten, sondern versteht auch die Absicht und den Kontext des Benutzers.
- verstärken.Das Erweiterungsmodul des Advanced RAG-Systems erzeugt durch einen dynamischen Lern- und Anpassungsmechanismus, der auf der Grundlage von Benutzerinteraktionen kontinuierlich optimiert wird, personalisierte und genauere Antworten.
- Erzeugung vonDas Modul Generierung nutzt ein ausgefeiltes kontextbezogenes Verständnis und eine iterative Optimierung, um die Generierung kohärenter und kontextbezogener Antworten zu ermöglichen.
Die Entwicklung von einfachen RAG zu fortgeschrittenen RAG ist ein bedeutender Sprung nach vorn. Durch den Einsatz ausgefeilter Suchtechniken, verbesserter kontextbezogener Integration und dynamischer Lernmechanismen bieten fortgeschrittene RAG-Systeme einen genaueren und kontextbezogenen Ansatz für die Informationsbeschaffung und -generierung. Dieser Fortschritt verbessert die Qualität von KI-Interaktionen und schafft die Grundlage für eine verfeinerte und effizientere Kommunikation.
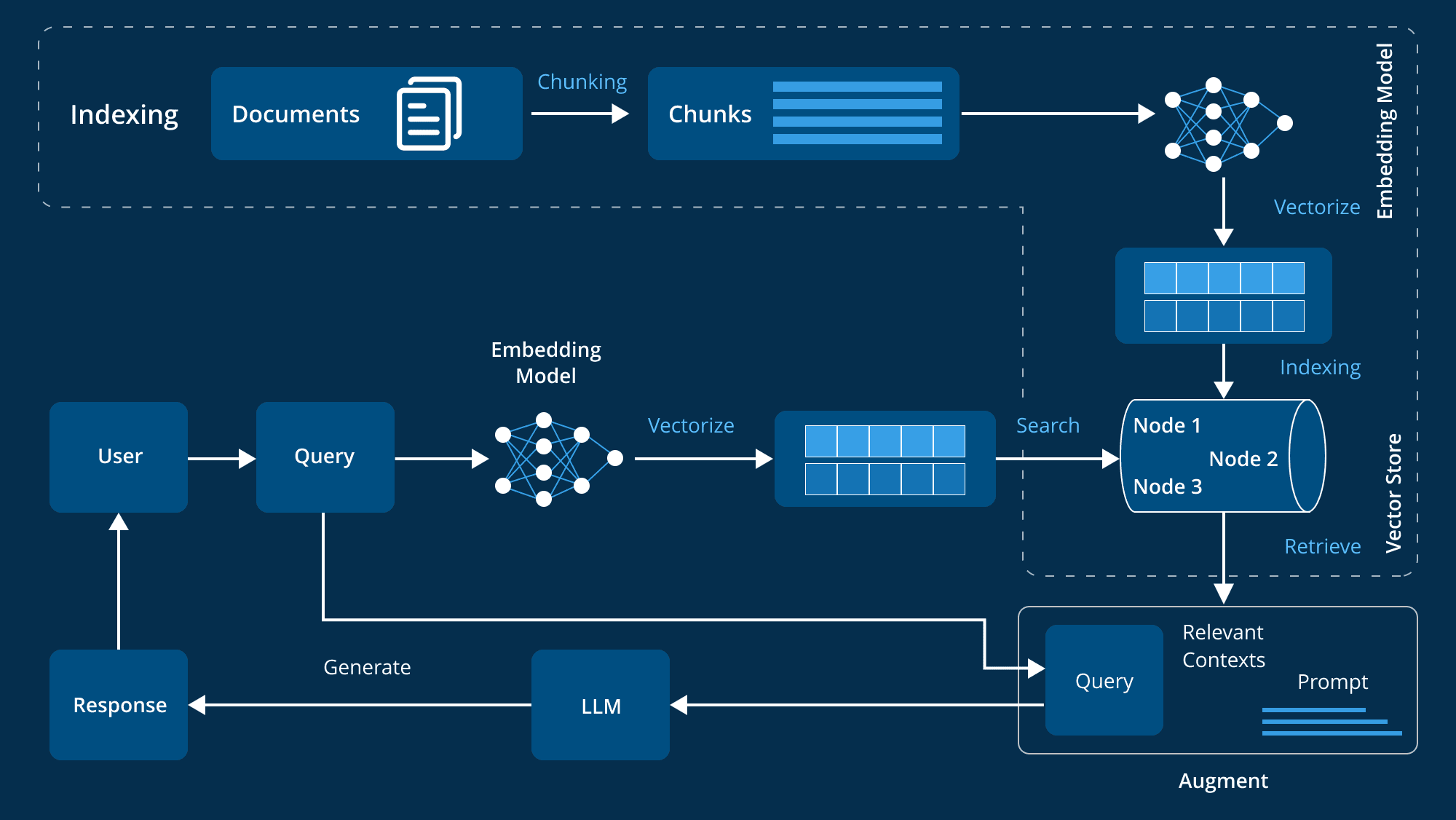
Komponenten und Arbeitsabläufe eines fortgeschrittenen RAG-Systems auf Unternehmensebene
Im Bereich der Unternehmensanwendungen gibt es einen wachsenden Bedarf an Systemen, die auf intelligente Weise relevante Informationen abrufen und generieren können. Retrieval Augmented Generation (RAG)-Systeme haben sich als leistungsstarke Lösungen erwiesen, die die Genauigkeit der Informationsbeschaffung mit der generativen Kraft von Large Language Models (LLMs) kombinieren. Um jedoch ein fortschrittliches RAG-System zu entwickeln, das den komplexen Anforderungen eines Unternehmens gerecht wird, muss seine Architektur sorgfältig konzipiert werden.
Kernkomponenten der Architektur
Ein fortschrittliches Retrieval Augmentation Generation (RAG) System erfordert mehrere Kernkomponenten, die zusammenarbeiten, um die Effizienz und Effektivität des Systems zu gewährleisten. Diese Komponenten umfassen die Datenverwaltung, die Verarbeitung von Benutzereingaben, den Abruf und die Generierung von Informationen sowie die laufende Verbesserung der Systemleistung. Im Folgenden finden Sie eine detaillierte Aufschlüsselung dieser Schlüsselkomponenten:
- Datenaufbereitung und -verwaltung
Die Grundlage eines fortschrittlichen RAG-Systems ist die Aufbereitung und Verwaltung von Daten, die eine Reihe von Schlüsselkomponenten umfasst:
- Datenbündelung und Vektorisierung: Die Daten werden in besser handhabbare Teile zerlegt und in Vektordarstellungen umgewandelt, was für eine effizientere und genauere Suche von entscheidender Bedeutung ist.
- Erstellung von Metadaten und Zusammenfassungen: Die Erstellung von Metadaten und Zusammenfassungen ermöglicht ein schnelles Nachschlagen und verkürzt die Abfragezeit.
- Datenbereinigung: Um sicherzustellen, dass die abgerufenen Informationen korrekt sind, muss gewährleistet sein, dass die Daten sauber, organisiert und frei von Störungen sind.
- Verarbeitet komplexe Datenformate: Die Fähigkeit des Systems, komplexe Datenformate zu verarbeiten, stellt sicher, dass die verschiedenen Datentypen im Unternehmen effektiv genutzt werden.
- Verwaltung der Benutzerkonfiguration: Personalisierung ist in einer Unternehmensumgebung wichtig, und durch die Verwaltung von Benutzerkonfigurationen können die Antworten auf die individuellen Bedürfnisse zugeschnitten werden, wodurch die Benutzererfahrung optimiert wird.
- Verarbeitung von Benutzereingaben
Das Modul zur Verarbeitung von Benutzereingaben spielt eine wichtige Rolle bei der effizienten Bearbeitung von Anfragen durch das System:
- Benutzer-Authentifizierung: Die Sicherheit von Unternehmenssystemen ist sehr wichtig und Authentifizierungsmechanismen stellen sicher, dass nur autorisierte Benutzer das RAG-System nutzen können.
- Abfrage-Optimierer: Die Struktur der Benutzeranfrage ist möglicherweise nicht für die Abfrage geeignet, und der Optimierer optimiert die Anfrage, um die Relevanz und Genauigkeit der Abfrage zu verbessern.
- Eingangsschutzmechanismen: Schutzmechanismen schützen das System vor fremden oder böswilligen Eingaben und gewährleisten die Zuverlässigkeit des Abrufprozesses.
- Nutzung des Chatverlaufs: Durch die Bezugnahme auf frühere Dialoge ist das System besser in der Lage, die aktuelle Anfrage zu verstehen und zu beantworten, was zu genaueren und kontextbezogenen Antworten führt.
- Informationsaufrufsystem
Das Information Retrieval System ist das Herzstück der RAG-Architektur und hat die Aufgabe, die relevantesten Informationen aus einem vorverarbeiteten Datenindex abzurufen:
- Indizierung von Daten: Effiziente Indizierungstechnologien gewährleisten einen schnellen und präzisen Informationsabruf, und fortschrittliche Indizierungsmethoden unterstützen die Verarbeitung großer Mengen von Unternehmensdaten.
- Abstimmung der Hyperparameter: Die Parameter des Abrufmodells werden so eingestellt, dass die Leistung optimiert wird und die relevantesten Ergebnisse abgerufen werden.
- Neuordnung der Ergebnisse: Nach dem Abruf ordnet das System die Ergebnisse neu an, um sicherzustellen, dass die relevantesten Informationen zuerst angezeigt werden, was die Antwortqualität verbessert.
- Optimierung einbetten: Durch die Anpassung der Einbettungsvektoren ist das System in der Lage, die Abfrage besser mit den relevanten Daten abzugleichen und so die Genauigkeit der Abfrage zu verbessern.
- Hypothetische Probleme mit der HyDE-Technologie: Die Generierung von hypothetischen Frage-Antwort-Paaren mit Hilfe der HyDE-Technologie (Hypothetical Document Embedding) kann die Informationsbeschaffung verbessern, wenn Anfrage und Dokument asymmetrisch sind.
- Erzeugung und Verarbeitung von Informationen
Wenn relevante Informationen abgerufen werden, muss das System eine kohärente und kontextabhängige Antwort geben:
- Erzeugung von Antworten: Unter Verwendung fortschrittlicher Large Language Models (LLMs) synthetisiert das Modul die abgerufenen Informationen zu einer umfassenden und genauen Antwort.
- Ausgabeschutz und Auditing: Um sicherzustellen, dass die erzeugten Antworten den Spezifikationen entsprechen, werden sie vom System anhand verschiedener Regeln überprüft.
- Daten-Caching: Häufig aufgerufene Daten oder Antworten werden zwischengespeichert, wodurch sich die Abrufzeit verkürzt und die Effizienz des Systems verbessert.
- Generation Personalisierung: Das System passt die generierten Inhalte an die Bedürfnisse und die Konfiguration des Benutzers an, um die Relevanz und Genauigkeit der Antwort zu gewährleisten.
- Feedback und Systemoptimierung
Fortschrittliche RAG-Systeme sollten in der Lage sein, selbst zu lernen und sich zu verbessern, und Feedback-Mechanismen sind für eine kontinuierliche Optimierung unerlässlich:
- Benutzer-Feedback: Durch das Sammeln und Analysieren von Nutzerfeedback kann das System verbesserungswürdige Bereiche ermitteln und sich weiterentwickeln, um den Bedürfnissen der Nutzer besser gerecht zu werden.
- Optimierung der Daten: Auf der Grundlage von Nutzerrückmeldungen und neuen Erkenntnissen werden die Daten im System kontinuierlich optimiert, um die Qualität und Relevanz der Informationen zu gewährleisten.
- Erstellen Sie Qualitätsbewertungen: Das System bewertet regelmäßig die Qualität der generierten Inhalte und optimiert sie kontinuierlich.
- Systemüberwachung: Kontinuierliche Überwachung der Systemleistung, um sicherzustellen, dass das System effizient arbeitet und auf Änderungen in der Nachfrage oder in den Datenmustern reagieren kann.
Integration mit Unternehmenssystemen
Damit ein fortschrittliches RAG-System in einem organisatorischen Umfeld optimal funktioniert, ist eine nahtlose Integration mit bestehenden Systemen unerlässlich:
- Integration von CRM- und ERP-Systemen: Die Verknüpfung fortschrittlicher RAG-Systeme mit Customer Relationship Management (CRM)- und Enterprise Resource Planning (ERP)-Systemen ermöglicht den effizienten Zugriff auf und die Nutzung von wichtigen Geschäftsdaten und verbessert die Fähigkeit, genaue und kontextbezogene Antworten zu generieren.
- APIs und Microservices-Architektur: Durch den Einsatz flexibler APIs und einer Microservices-Architektur lässt sich das RAG-System leicht in bestehende Unternehmenssoftware integrieren und ermöglicht modulare Upgrades und Erweiterungen.
Sicherheit und Compliance
Sicherheit und Compliance sind aufgrund der Sensibilität der Unternehmensdaten besonders wichtig:
- Datensicherheitsprotokoll: Starke Datenverschlüsselung und sichere Datenverarbeitungsmaßnahmen werden eingesetzt, um sensible Informationen zu schützen und die Einhaltung von Datenschutzbestimmungen wie der GDPR zu gewährleisten.
- Zugangskontrolle und Authentifizierung: Implementierung einer sicheren Benutzerauthentifizierung und rollenbasierter Zugriffskontrollmechanismen, um sicherzustellen, dass nur autorisiertes Personal auf das System zugreifen oder es verändern kann.
Skalierbarkeit und Leistungsoptimierung
RAG-Systeme der Unternehmensklasse müssen skalierbar sein und auch unter hoher Last eine gute Leistung erbringen:
- Native Cloud-Architektur: Die Verwendung einer Cloud-Native-Architektur bietet die Flexibilität, Ressourcen nach Bedarf zu skalieren und eine hohe Systemverfügbarkeit und Leistungsoptimierung zu gewährleisten.
- Lastausgleich und Ressourcenmanagement: Effiziente Lastausgleichs- und Ressourcenverwaltungsstrategien helfen dem System, große Mengen an Benutzeranfragen und Daten zu bewältigen und gleichzeitig eine optimale Leistung aufrechtzuerhalten.
Analyse und Berichterstattung
Fortschrittliche RAG-Systeme sollten auch über robuste Analyse- und Berichtsfunktionen verfügen:
- Leistungsüberwachung: Die Echtzeitüberwachung der Systemleistung, der Benutzerinteraktionen und des Systemzustands durch die Integration fortschrittlicher Analysetools ist für die Aufrechterhaltung der Systemeffizienz von entscheidender Bedeutung.
- Integration von Business Intelligence: Die Integration mit Business-Intelligence-Tools kann wertvolle Erkenntnisse für die Entscheidungsfindung liefern und die Unternehmensstrategie vorantreiben.
Fortschrittliche RAG-Systeme auf Unternehmensebene sind eine Kombination aus modernster KI-Technologie, robusten Datenverarbeitungsmechanismen, sicherer und skalierbarer Infrastruktur und nahtlosen Integrationsmöglichkeiten. Durch die Kombination dieser Elemente sind Organisationen in der Lage, RAG-Systeme aufzubauen, die effizient Informationen abrufen und generieren können und gleichzeitig ein zentraler Bestandteil des unternehmensweiten Technologiesystems sind. Diese Systeme bieten nicht nur einen erheblichen geschäftlichen Nutzen, sondern verbessern auch die Entscheidungsprozesse und die allgemeine betriebliche Effizienz.
Fortschrittliche RAG-Technologie
Advanced Retrieval Augmented Generation (RAG) umfasst eine Reihe von technologischen Werkzeugen, die die Effizienz und Genauigkeit in allen Phasen der Verarbeitung verbessern sollen. Diese fortschrittlichen RAG-Systeme sind in der Lage, Daten besser zu verwalten und genauere, kontextbezogene Antworten zu geben, indem sie fortschrittliche Technologien in verschiedenen Phasen des Prozesses einsetzen, von der Indexierung und Umwandlung von Abfragen bis hin zum Abruf und zur Generierung. Im Folgenden werden einige der fortschrittlichen Techniken vorgestellt, die zur Optimierung der einzelnen Phasen des RAG-Prozesses eingesetzt werden:
1. index
Die Indizierung ist ein Schlüsselprozess, der die Genauigkeit und Effizienz von Systemen für große Sprachmodelle (Large Language Models, LLMs) verbessert. Indizierung ist mehr als nur die Speicherung von Daten; sie beinhaltet die systematische Organisation und Optimierung von Daten, um sicherzustellen, dass die Informationen leicht zugänglich und verständlich sind und gleichzeitig wichtige Zusammenhänge erhalten bleiben. Eine wirksame Indexierung hilft, Daten genau und effizient abzurufen, so dass LLMs relevante und genaue Antworten geben können. Zu den Techniken, die bei der Indizierung eingesetzt werden, gehören:
Technik 1: Optimierung von Textblöcken durch Blockoptimierung
Der Zweck der Blockoptimierung besteht darin, die Größe und Struktur von Textblöcken so anzupassen, dass sie nicht zu groß oder zu klein sind und gleichzeitig der Kontext erhalten bleibt, um so die Suche zu verbessern.
Technik 2: Konvertierung von Text in Vektoren mit erweiterten Einbettungsmodellen
Nach der Erstellung von Textblöcken ist der nächste Schritt die Umwandlung dieser Blöcke in Vektordarstellungen. Bei diesem Prozess wird der Text in numerische Vektoren umgewandelt, die seine semantische Bedeutung erfassen. Modelle wie BGE-large oder die E5-Embedding-Familie eignen sich gut zur Darstellung der Nuancen des Textes. Diese Vektordarstellungen sind für das anschließende Retrieval und den semantischen Abgleich entscheidend.
Technik 3: Verbesserung des semantischen Abgleichs durch Einbettung der Feinabstimmung
Das Ziel der Feinabstimmung der Einbettung besteht darin, das semantische Verständnis der indizierten Daten durch das Einbettungsmodell zu verbessern und so die Genauigkeit der Übereinstimmung zwischen den abgerufenen Informationen und der Benutzeranfrage zu erhöhen.
Technik 4: Verbesserung der Sucheffizienz durch Mehrfachdarstellungen
Mehrfachrepräsentationstechniken konvertieren Dokumente in leichtgewichtige Retrievaleinheiten, wie z. B. Zusammenfassungen, um den Retrievalprozess zu beschleunigen und die Genauigkeit bei der Arbeit mit großen Dokumenten zu verbessern.
Technik 5: Hierarchische Indizes zur Organisation von Daten verwenden
Die hierarchische Indexierung verbessert die Suche, indem sie die Daten auf mehreren Ebenen strukturiert, von detailliert bis allgemein, durch Modelle wie RAPTOR, die umfassende und präzise Kontextinformationen liefern.
Technik 6: Verbesserter Datenabruf durch Anhängen von Metadaten
Durch das Anhängen von Metadaten werden jedem Datenblock zusätzliche Informationen hinzugefügt, um die Analyse- und Klassifizierungsmöglichkeiten zu verbessern und die Datenabfrage systematischer und kontextbezogener zu gestalten.
2. die Umwandlung der Abfrage
Die Umwandlung von Suchanfragen zielt darauf ab, die Benutzereingabe zu optimieren und die Qualität des Informationsabrufs zu verbessern. Durch die Verwendung von LLMs ist der Transformationsprozess in der Lage, komplexe oder mehrdeutige Abfragen klarer und spezifischer zu gestalten und so die Sucheffizienz und -genauigkeit insgesamt zu verbessern.
Technik 1: Verwendung von HyDE (Hypothetical Document Embedding) zur Verbesserung der Abfrageklarheit
HyDE verbessert die Relevanz und Genauigkeit des Informationsabrufs durch die Generierung von Hypothesendaten, um die semantische Ähnlichkeit zwischen Fragen und Referenzinhalten zu erhöhen.
Technik 2: Vereinfachung komplexer Abfragen mit mehrstufigen Abfragen
Mehrstufige Abfragen zerlegen komplexe Fragen in einfachere Teilfragen, rufen die Antworten auf jede Teilfrage separat ab und fassen die Ergebnisse zusammen, um eine genauere und umfassendere Antwort zu geben.
Technik 3: Anreicherung des Kontexts mit Backtracking-Hinweisen
Die Backtracking-Hinting-Technik erzeugt aus der komplexen ursprünglichen Anfrage eine umfassendere allgemeine Anfrage, so dass der Kontext als Grundlage für die spezifische Anfrage dient und die endgültige Antwort durch die Kombination der Ergebnisse der ursprünglichen und der umfassenderen Anfrage verbessert wird.
Technik 4: Verbesserung des Abrufs durch Umschreiben der Abfrage
Sowohl LangChain als auch LlamaIndex verwenden diese Technik, wobei LlamaIndex eine besonders leistungsfähige Implementierung bietet, die das Auffinden von Daten drastisch verbessert.
3 Abfrage des Routings
Die Aufgabe des Abfrage-Routings besteht darin, den Abrufprozess zu optimieren, indem die Abfrage auf der Grundlage der Merkmale der Abfrage an die am besten geeignete Datenquelle gesendet wird, um sicherzustellen, dass jede Abfrage von der am besten geeigneten Systemkomponente bearbeitet wird.
Technik 1: Logisches Routing
Das logische Routing optimiert den Abruf, indem es die Struktur der Abfrage analysiert, um die am besten geeignete Datenquelle oder den besten Index auszuwählen. Dieser Ansatz gewährleistet, dass die Abfrage von der Datenquelle verarbeitet wird, die am besten geeignet ist, eine genaue Antwort zu liefern.
Technologie 2: Semantisches Routing
Das semantische Routing leitet die Abfrage an die richtige Datenquelle oder den richtigen Index weiter, indem es die semantische Bedeutung der Abfrage analysiert. Es verbessert die Genauigkeit des Abrufs, indem es den Kontext und die Bedeutung der Abfrage versteht, insbesondere bei komplexen oder differenzierten Fragen.
4. vorbereitende Such- und Datenindizierungsverfahren
Die Optimierung vor dem Abruf verbessert die Qualität und Auffindbarkeit von Informationen in einem Datenindex oder einer Wissensdatenbank. Die spezifischen Optimierungsmethoden hängen von der Art, der Quelle und dem Umfang der Daten ab. So können beispielsweise durch eine Erhöhung der Informationsdichte genauere Antworten mit weniger Token erzeugt werden, was die Benutzerfreundlichkeit verbessert und die Kosten senkt. Optimierungsmethoden, die für ein bestimmtes System funktionieren, sind jedoch für andere Systeme möglicherweise nicht geeignet. Große Sprachmodelle (Large Language Models, LLMs) bieten die Möglichkeit, diese Optimierungen zu testen und abzustimmen, so dass maßgeschneiderte Ansätze zur Verbesserung des Retrievals in verschiedenen Bereichen und Anwendungen möglich sind.
Technik 1: Verwendung von LLMs zur Erhöhung der Informationsdichte
Ein grundlegender Schritt zur Optimierung eines RAG-Systems ist die Verbesserung der Datenqualität vor der Indizierung. Durch den Einsatz von LLMs zur Datenbereinigung, Markierung und Zusammenfassung kann die Informationsdichte erhöht werden, was zu genaueren und effizienteren Datenverarbeitungsergebnissen führt.
Technik 2: Hierarchische Indexsuche
Hierarchische Indexierungssuchen vereinfachen den Suchprozess durch die Erstellung von Dokumentzusammenfassungen als erste Filterebene. Dieser mehrschichtige Ansatz stellt sicher, dass nur die relevantesten Daten in der Suchphase berücksichtigt werden, wodurch die Suche effizienter und genauer wird.
Technik 3: Verbesserung der Suchsymmetrie durch hypothetische Frage-Antwort-Paare
Um die Asymmetrie zwischen Abfragen und Dokumenten zu beheben, verwendet diese Technik LLMs, um hypothetische Q&A-Paare aus Dokumenten zu generieren. Indem diese Frage-Antwort-Paare in die Suche eingebettet werden, kann das System die Benutzeranfrage besser erfüllen, wodurch die semantische Ähnlichkeit verbessert und Suchfehler reduziert werden.
Technik 4: De-Duplizierung mit LLMs
Doppelte Informationen können für ein RAG-System sowohl vorteilhaft als auch nachteilig sein. Die Verwendung von LLMs zur Entduplizierung von Datenblöcken optimiert die Datenindizierung, reduziert das Rauschen und erhöht die Wahrscheinlichkeit, genaue Antworten zu generieren.
Technik 5: Testen und Optimieren von Chunking-Strategien
Eine effektive Chunking-Strategie ist für den Abruf von entscheidender Bedeutung. Durch A/B-Tests mit verschiedenen Chunk-Größen und Überlappungsverhältnissen kann das optimale Gleichgewicht für einen bestimmten Anwendungsfall gefunden werden. Auf diese Weise bleibt ausreichend Kontext erhalten, ohne dass relevante Informationen zu dünn verteilt oder verwässert werden.
Technik 6: Verwendung eines Schiebefenster-Index
Die Sliding-Window-Indizierung stellt sicher, dass wichtige Kontextinformationen zwischen den Segmenten nicht durch Überlappung von Datenblöcken während des Indizierungsprozesses verloren gehen. Dieser Ansatz wahrt die Datenkontinuität und verbessert die Relevanz und Genauigkeit der abgerufenen Informationen.
Technik 7: Erhöhung der Datengranularität
Die Verbesserung der Datengranularität wird in erster Linie durch die Anwendung von Datenbereinigungstechniken erreicht, um irrelevante Informationen zu entfernen und nur die genauesten und aktuellsten Inhalte im Index zu behalten. Dadurch wird die Qualität der Abfrage verbessert und sichergestellt, dass nur relevante Informationen berücksichtigt werden.
Technik 8: Hinzufügen von Metadaten
Das Hinzufügen von Metadaten wie Datum, Zweck oder Abschnitt kann die Genauigkeit der Suche erhöhen, so dass sich das System besser auf die relevantesten Daten konzentrieren und die Suche insgesamt verbessern kann.
Technik 9: Optimierung der Indexstruktur
Die Optimierung der Indizierungsstruktur umfasst die Größenänderung von Chunks und den Einsatz mehrerer Indizierungsstrategien, wie z. B. die Abfrage von Satzfenstern, um die Art und Weise der Datenspeicherung und -abfrage zu verbessern. Durch die Einbettung einzelner Sätze unter Beibehaltung eines Kontextfensters ermöglicht dieser Ansatz eine umfassendere und kontextgenauere Abfrage während der Inferenz.
5. die Abfragetechniken
In der Abrufphase sammelt das System die Informationen, die zur Beantwortung der Benutzeranfrage erforderlich sind. Eine fortschrittliche Suchtechnologie stellt sicher, dass die abgerufenen Inhalte sowohl umfassend als auch kontextuell vollständig sind und eine solide Grundlage für die nachfolgenden Verarbeitungsschritte bilden.
Technik 1: Optimierung von Suchanfragen mit LLMs
LLMs optimieren die Suchanfrage des Nutzers, um sie besser an die Anforderungen des Suchsystems anzupassen, unabhängig davon, ob es sich um eine einfache Suche oder eine komplexe Dialoganfrage handelt. Diese Optimierung sorgt dafür, dass der Suchprozess gezielter und effizienter wird.
Technik 2: Behebung der Asymmetrie zwischen Abfrage und Dokument mit HyDE
Durch die Generierung hypothetischer Antwortdokumente verbessert die HyDE-Technik die semantische Ähnlichkeit beim Retrieval und löst die Asymmetrie zwischen kurzen Abfragen und langen Dokumenten.
TECHNIK 3: Implementierung von Query Routing oder RAG-Entscheidungsmodellierung
Das RAG-Entscheidungsmodell optimiert diesen Prozess weiter, indem es feststellt, wann ein Abruf erforderlich ist, um Ressourcen zu sparen, wenn das große Sprachmodell unabhängig reagieren kann.
Technik 4: Tiefe Erkundung mit rekursiven Suchern
Ein rekursiver Sucher führt weitere Abfragen auf der Grundlage des vorherigen Ergebnisses durch und eignet sich für die vertiefte Suche nach relevanten Daten, um detaillierte oder umfassende Informationen zu erhalten.
Technik 5: Optimierung der Datenquellenauswahl mit Route Retriever
Der Routing Retriever verwendet LLM, um dynamisch die am besten geeignete Datenquelle oder das am besten geeignete Abfragetool auszuwählen, um die Effektivität des Abfrageprozesses basierend auf dem Kontext der Abfrage zu verbessern.
Technik 6: Automatisierte Abfrageerstellung mit Auto-Retrievern
Der Auto-Retriever nutzt den LLM, um automatisch Metadatenfilter oder Abfrageanweisungen zu generieren und so den Datenbankabfrageprozess zu vereinfachen und den Informationsabruf zu optimieren.
Technik 7: Kombinieren von Ergebnissen mit einem Fusionssucher
Der Fusion Retriever kombiniert Ergebnisse aus mehreren Abfragen und Indizes, um eine umfassende und nicht-duplizierende Sicht auf die Informationen zu erhalten und eine umfassende Suche zu gewährleisten.
Technik 8: Aggregieren von Datenkontexten mit Auto Merge Searchers
Der Auto Merge Retriever kombiniert mehrere Datensegmente zu einem einzigen, einheitlichen Kontext und verbessert die Relevanz und Vollständigkeit der Informationen durch die Integration kleinerer Kontexte.
Technik 9: Feinabstimmung des Einbettungsmodells
Die Feinabstimmung des Einbettungsmodells, um es domänenspezifischer zu machen, verbessert die Fähigkeit, Fachterminologie zu verarbeiten. Dieser Ansatz verbessert die Relevanz und Genauigkeit der abgerufenen Informationen, indem er die domänenspezifischen Inhalte besser aufeinander abstimmt.
Technik 10: Implementierung der dynamischen Einbettung
Dynamische Einbettungen gehen über statische Darstellungen hinaus, indem sie Wortvektoren an den Kontext anpassen und so ein nuancierteres Verständnis der Sprache ermöglichen. Dieser Ansatz, wie z. B. das Modell embeddings-ada-02 von OpenAI, erfasst kontextbezogene Bedeutungen genauer und liefert somit genauere Suchergebnisse.
Technik 11: Nutzung der hybriden Suche
Bei der hybriden Suche wird die Vektorsuche mit dem herkömmlichen Schlüsselwortabgleich kombiniert, so dass sowohl semantische Ähnlichkeit als auch eine präzise Begriffserkennung möglich sind. Dieser Ansatz ist besonders effektiv in Szenarien, in denen eine präzise Begriffserkennung erforderlich ist, um eine umfassende und genaue Suche zu gewährleisten.
6. post-retrieval Techniken
Sobald die relevanten Inhalte erfasst wurden, konzentriert sich die Post-Retrieval-Phase darauf, wie diese Inhalte effektiv zusammengesetzt werden können. Dieser Schritt beinhaltet die Bereitstellung präziser und prägnanter Kontextinformationen für das Large Language Model (LLM), um sicherzustellen, dass das System über alle Details verfügt, die für die Generierung kohärenter und genauer Antworten erforderlich sind. Die Qualität dieser Integration bestimmt unmittelbar die Relevanz und Klarheit der endgültigen Ausgabe.
Technik 1: Optimierung der Suchergebnisse durch Neuordnung
Nach dem Abruf ordnet das Neuordnungsmodell die Suchergebnisse neu an, um die relevantesten Dokumente näher an der Anfrage zu platzieren und so die Qualität der dem LLM zur Verfügung gestellten Informationen und folglich die Erstellung der endgültigen Antwort zu verbessern. Die Neuordnung reduziert nicht nur die Anzahl der Dokumente, die dem LLM zur Verfügung gestellt werden müssen, sondern wirkt auch als Filter zur Verbesserung der Genauigkeit der Sprachverarbeitung.
Technik 2: Optimierung der Suchergebnisse durch Komprimierung mit kontextbezogenen Hinweisen
Der LLM kann die abgerufenen Informationen filtern und komprimieren, bevor er die endgültige Eingabeaufforderung erstellt. Die Komprimierung hilft dem LLM, sich mehr auf kritische Informationen zu konzentrieren, indem redundante Hintergrundinformationen reduziert und Fremdgeräusche entfernt werden. Durch diese Optimierung wird die Qualität der Antwort verbessert, da sie sich auf die wichtigen Details konzentriert. Frameworks wie LLMLingua verbessern diesen Prozess weiter, indem sie überflüssige Token entfernen und die Prompts prägnanter und effektiver machen.
Technik 3: Scoring und Filterung der abgerufenen Dokumente durch Korrektur der RAGs
Bevor Inhalte in den LLM eingegeben werden, müssen die Dokumente ausgewählt und gefiltert werden, um irrelevante oder weniger genaue Dokumente zu entfernen. Diese Technik stellt sicher, dass nur hochwertige, relevante Informationen verwendet werden, wodurch die Genauigkeit und Zuverlässigkeit der Antwort verbessert wird. Corrective RAG nutzt ein Modell wie T5-Large, um die Relevanz der abgerufenen Dokumente zu bewerten, und filtert diejenigen heraus, die unter einem vorgegebenen Schwellenwert liegen. So wird sichergestellt, dass nur wertvolle Informationen in die endgültige Antwort einfließen.
7. generative Technologien
In der Generierungsphase werden die abgerufenen Informationen bewertet und neu sortiert, um die wichtigsten Inhalte zu ermitteln. Die fortschrittliche Technologie in dieser Phase umfasst die Auswahl der wichtigsten Details, die die Relevanz und Zuverlässigkeit der Antwort erhöhen. Dieser Prozess stellt sicher, dass der generierte Inhalt nicht nur die Anfrage beantwortet, sondern auch durch die abgerufenen Daten sinnvoll ergänzt wird.
Technik 1: Rauschunterdrückung mit Tipps zur Gedankenkette
Gedankenkettenaufforderungen helfen LLM, mit verrauschten oder irrelevanten Hintergrundinformationen umzugehen, und erhöhen die Wahrscheinlichkeit, eine korrekte Antwort zu geben, selbst wenn es Störungen in den Daten gibt.
TECHNIK 2: Selbstreflexion des Systems durch Selbst-RAG
Bei Self-RAG wird das Modell darauf trainiert, während der Generierung reflektierende Token zu verwenden, so dass es seine eigene Ausgabe in Echtzeit bewerten und verbessern kann, indem es die beste Antwort auf der Grundlage von Faktizität und Qualität auswählt.
Technik 3: Vernachlässigung störender Hintergründe durch Feinabstimmung
Das RAG-System wurde speziell abgestimmt, um die Fähigkeit des LLM zu verbessern, fremde Hintergründe zu ignorieren und sicherzustellen, dass nur relevante Informationen die endgültige Antwort beeinflussen.
Technik 4: Verbesserung der LLM-Robustheit gegenüber irrelevanten Hintergründen mit Natural Language Reasoning
Die Integration von NLI-Modellen (Natural Language Inference) hilft dabei, irrelevante Kontextinformationen herauszufiltern, indem sie den abgerufenen Kontext mit der generierten Antwort vergleicht und so sicherstellt, dass nur relevante Informationen die endgültige Ausgabe beeinflussen.
Technik 5: Steuerung des Datenabrufs mit FLARE
FLARE (Flexible Language Modelling Adaptation for Retrieval Enhancement) ist ein auf Cue-Engineering basierender Ansatz, der sicherstellt, dass LLM Daten nur bei Bedarf abruft. Er passt die Abfrage kontinuierlich an und prüft auf Schlüsselwörter mit geringer Wahrscheinlichkeit, die den Abruf relevanter Dokumente auslösen, um die Genauigkeit der Antwort zu verbessern.
Technik 6: Verbesserung der Antwortqualität mit ITER-RETGEN
ITER-RETGEN (Iterative Retrieval-Generation) verbessert die Antwortqualität durch iterative Ausführung des Generierungsprozesses. Bei jeder Iteration wird das vorherige Ergebnis als Kontext verwendet, um weitere relevante Informationen abzurufen, wodurch die Qualität und Relevanz der endgültigen Antwort kontinuierlich verbessert wird.
Technik 7: Klärung von Fragen mit Hilfe von ToC (Tree of Clarification)
ToC generiert rekursiv spezifische Fragen, um Mehrdeutigkeiten in der ursprünglichen Anfrage zu klären. Dieser Ansatz verfeinert den Frage-und-Antwort-Prozess, indem er die ursprüngliche Frage kontinuierlich auswertet und verfeinert, was zu einer detaillierteren und genaueren endgültigen Antwort führt.
8. die Bewertung
Bei fortgeschrittenen Retrieval Augmented Generation (RAG)-Technologien ist der Evaluierungsprozess von entscheidender Bedeutung, um sicherzustellen, dass die abgerufenen und synthetisierten Informationen sowohl genau als auch relevant für die Anfrage des Benutzers sind. Der Bewertungsprozess besteht aus zwei Schlüsselkomponenten: Qualitätsbewertungen und erforderliche Fähigkeiten.
Die Qualitätsbewertung konzentriert sich auf die Messung der Genauigkeit und Relevanz des Inhalts:
- Hintergrund Relevanz. Bewertung der Anwendbarkeit der abgerufenen oder generierten Informationen im spezifischen Kontext der Abfrage. Sicherstellen, dass die Antwort korrekt und auf die Bedürfnisse des Nutzers zugeschnitten ist.
- Antwort Treue. Prüfen Sie, ob die erzeugten Antworten die abgerufenen Daten korrekt wiedergeben und keine Fehler oder irreführenden Informationen enthalten. Dies ist wichtig, um die Zuverlässigkeit der Ergebnisse des Systems zu gewährleisten.
- Relevanz der Antwort. Evaluieren Sie, ob die generierte Antwort die Anfrage des Benutzers direkt und effektiv beantwortet, und stellen Sie sicher, dass die Antwort sowohl nützlich ist als auch mit dem Kern der Frage übereinstimmt.
Die erforderlichen Fähigkeiten sind diejenigen, über die das System verfügen muss, um qualitativ hochwertige Ergebnisse zu liefern:
- Robustheit gegenüber Lärm. Messen Sie die Fähigkeit des Systems, fremde oder verrauschte Daten zu filtern, um sicherzustellen, dass diese Störungen die Qualität der endgültigen Antwort nicht beeinträchtigen.
- Negative Ablehnung. Testen Sie die Effektivität des Systems bei der Erkennung und dem Ausschluss von fehlerhaften oder irrelevanten Informationen, die den generierten Output verunreinigen.
- Integration von Informationen. Bewerten Sie die Fähigkeit des Systems, mehrere relevante Informationen in eine kohärente, umfassende Antwort zu integrieren, die dem Benutzer eine vollständige Antwort liefert.
- Kontrafaktische Robustheit. Überprüfen Sie die Leistung des Systems bei der Bearbeitung hypothetischer oder kontrafaktischer Szenarien, um sicherzustellen, dass die Antworten auch bei spekulativen Fragen korrekt und zuverlässig sind.
Gemeinsam sorgen diese Bewertungskomponenten dafür, dass das Advanced RAG-System eine Antwort liefert, die sowohl genau und relevant, als auch robust und zuverlässig ist und auf die spezifischen Bedürfnisse des Nutzers zugeschnitten ist.
Zusätzliche Technologien
Chat Engine: Verbesserung des Dialogs im RAG-System
Die Integration einer Chat-Engine in ein fortschrittliches Retrieval Augmented Generation (RAG)-System verbessert die Fähigkeit des Systems, Folgefragen zu bearbeiten und den Kontext des Dialogs beizubehalten, ähnlich wie bei der traditionellen Chatbot-Technologie. Verschiedene Implementierungen bieten unterschiedliche Komplexitätsgrade:
- Kontext-Chat-Engine: Dieser zugrundeliegende Ansatz steuert die Antwort des Large Language Model (LLM), indem er den für die Anfrage des Nutzers relevanten Kontext abruft, einschließlich früherer Chats. Dadurch wird sichergestellt, dass der Dialog kohärent und kontextuell angemessen ist.
- Konzentration plus kontextbezogene Modi: Hierbei handelt es sich um einen fortschrittlicheren Ansatz, bei dem die Chatprotokolle und die letzten Nachrichten jeder Interaktion zu einer optimierten Abfrage zusammengefasst werden. Diese verfeinerte Abfrage nimmt den relevanten Kontext und kombiniert ihn mit der ursprünglichen Nutzernachricht, um dem LLM eine genauere und kontextbezogene Antwort zu geben.
Diese Implementierungen tragen dazu bei, die Kohärenz und Relevanz des Dialogs im RAG-System zu verbessern und bieten je nach Bedarf unterschiedliche Komplexitätsgrade.
Referenzzitate: Sicherstellen, dass die Quellen korrekt sind
Es ist wichtig, die Genauigkeit der Referenzen zu gewährleisten, insbesondere wenn mehrere Quellen zu den generierten Antworten beitragen. Dies kann auf verschiedene Weise erreicht werden:
- Direkte Kennzeichnung der Quelle: Das Einrichten einer Aufgabe in einer Sprachmodell-Eingabeaufforderung (LLM) erfordert, dass die Quelle in der generierten Antwort direkt gekennzeichnet wird. Dieser Ansatz ermöglicht es, die Originalquelle eindeutig zu kennzeichnen.
- Fuzzy-Matching-Technik: Fuzzy-Matching-Techniken, wie sie von LlamaIndex verwendet werden, werden eingesetzt, um Teile des generierten Inhalts mit Textblöcken im Quellindex abzugleichen. Der unscharfe Abgleich verbessert die Genauigkeit des Inhalts und stellt sicher, dass er die Informationen der Quelle wiedergibt.
Durch die Anwendung dieser Strategien kann die Genauigkeit und Zuverlässigkeit von Referenzzitaten erheblich verbessert werden, wodurch sichergestellt wird, dass die erstellten Antworten sowohl glaubwürdig als auch gut belegt sind.
Agenten der Retrieval Augmented Generation (RAG)
Agenten spielen eine wichtige Rolle bei der Verbesserung der Leistung von Retrieval Augmented Generation (RAG)-Systemen, indem sie dem Large Language Model (LLM) zusätzliche Werkzeuge und Funktionen zur Verfügung stellen, um seine Reichweite zu erweitern. Ursprünglich über die LLM-API eingeführt, ermöglichen diese Agenten den LLMs, externe Codefunktionen, APIs und sogar andere LLMs zu nutzen, um ihre Funktionalität zu erweitern.
Eine wichtige Anwendung von Agenten ist die Suche nach mehreren Dokumenten. Die jüngsten OpenAI-Assistenten zeigen beispielsweise Fortschritte in diesem Konzept. Diese Assistenten ergänzen herkömmliche LLMs durch die Integration von Funktionen wie Chat-Protokolle, Wissensspeicher, Schnittstellen zum Hochladen von Dokumenten und Funktionsaufruf-APIs, die natürliche Sprache in umsetzbare Befehle umwandeln.
Der Einsatz von Agenten erstreckt sich auch auf die Verwaltung mehrerer Dokumente, wobei jedes Dokument von einem eigenen Agenten bearbeitet wird, z. B. Zusammenfassungen und Quiz. Ein zentraler, übergeordneter Agent überwacht diese dokumentenspezifischen Agenten, leitet Abfragen weiter und konsolidiert Antworten. Dieser Aufbau unterstützt komplexe Vergleiche und Analysen über mehrere Dokumente hinweg und demonstriert fortgeschrittene RAG-Techniken.
Antwort auf Synthesizer: Ausarbeitung der endgültigen Antwort
Der letzte Schritt des RAG-Prozesses besteht darin, den abgerufenen Kontext und die ursprüngliche Benutzeranfrage zu einer Antwort zusammenzufassen. Neben der direkten Kombination des Kontexts mit der Abfrage und der Verarbeitung durch den LLM gibt es noch weitere verfeinerte Ansätze:
- Iterative Optimierung: Durch die Aufteilung des abgerufenen Kontexts in kleinere Teile wird die Antwort durch mehrfache Interaktionen mit dem LLM optimiert.
- Zusammenfassung des Kontextes: Die Komprimierung einer großen Menge an Kontext auf die LLM-Aufforderungen gewährleistet, dass die Antworten konzentriert und relevant bleiben.
- Generierung von Mehrfachantworten: Generieren Sie mehrere Antworten aus verschiedenen Segmenten des Kontextes und integrieren Sie diese Antworten dann in eine einheitliche Antwort.
Diese Techniken verbessern die Qualität und Genauigkeit der Antworten des RAG-Systems und zeigen das Potenzial fortschrittlicher Methoden für die Antwortsynthese.
Der Einsatz dieser fortschrittlichen RAG-Technologien kann die Systemleistung und -zuverlässigkeit erheblich verbessern. Durch die Optimierung des Prozesses in jeder Phase, von der Datenvorverarbeitung bis zur Generierung von Antworten, können Unternehmen genauere, effizientere und leistungsfähigere KI-Anwendungen erstellen.
Fortgeschrittene RAG-Anwendungen und -Fälle
Fortgeschrittene Retrieval Augmented Generation (RAG)-Systeme werden in einer Vielzahl von Bereichen eingesetzt, um die Datenanalyse, die Entscheidungsfindung und die Benutzerinteraktion durch ihre leistungsstarken Datenverarbeitungs- und Generierungsfunktionen zu verbessern. Von der Marktforschung über die Kundenbetreuung bis hin zur Erstellung von Inhalten haben fortgeschrittene RAG-Systeme in einer Reihe von Bereichen erhebliche Vorteile gezeigt. Spezifische Anwendungen dieser Systeme in verschiedenen Bereichen werden im Folgenden beschrieben:
1. Marktforschung und Wettbewerbsanalyse
- DatenintegrationDas RAG-System ist in der Lage, Daten aus einer Vielzahl von Quellen wie sozialen Medien, Nachrichtenartikeln und Branchenberichten zu integrieren und zu analysieren.
- Identifizierung von TrendsDurch die Verarbeitung großer Datenmengen ist das RAG-System in der Lage, sich abzeichnende Markttrends und Veränderungen im Verbraucherverhalten zu erkennen.
- Einblick in die WettbewerberDas System bietet detaillierte Wettbewerbsstrategien und Leistungsanalysen, um Unternehmen bei der Selbstbewertung und beim Benchmarking zu unterstützen.
- verwertbare ErkenntnisseUnternehmen können diese Berichte für die strategische Planung und Entscheidungsfindung nutzen.
2. Kundenbetreuung und Interaktion
- Kontextabhängige AntwortenDas RAG-System ruft relevante Informationen aus der Wissensdatenbank ab, um den Kunden genaue und kontextbezogene Antworten zu geben.
- Verringerung der ArbeitsbelastungAutomatisierung der Bearbeitung gängiger Probleme nimmt den Druck von den manuellen Support-Teams, so dass diese sich mit komplexeren Problemen befassen können.
- Persönlicher ServiceDas System passt die Antworten und Interaktionen an die individuellen Bedürfnisse an, indem es die Kundenhistorie und -präferenzen analysiert.
- Verbessern des interaktiven ErlebnissesQualitativ hochwertige Unterstützungsdienste erhöhen die Kundenzufriedenheit und stärken die Kundenbeziehungen.
3. Einhaltung von Vorschriften und Risikomanagement
- Regulatorische AnalyseDas RAG-System scannt und interpretiert Rechtsdokumente und regulatorische Leitlinien, um die Einhaltung der Vorschriften zu gewährleisten.
- RisikoermittlungDas System identifiziert schnell potenzielle Compliance-Risiken, indem es interne Richtlinien mit externen Vorschriften vergleicht.
- Compliance-EmpfehlungenPraktische Ratschläge, die Unternehmen helfen, Lücken in der Einhaltung von Vorschriften zu schließen und rechtliche Risiken zu verringern.
- Effiziente BerichterstattungGenerieren Sie Berichte und Zusammenfassungen zur Einhaltung der Vorschriften, die leicht zu prüfen und zu kontrollieren sind.
4. Produktentwicklung und Innovation
- Analyse des KundenfeedbacksRAG: Das RAG-System analysiert das Kundenfeedback, um gemeinsame Probleme und Schmerzpunkte zu identifizieren.
- Einblicke in den MarktVerfolgen Sie aufkommende Trends und Kundenbedürfnisse, um die Produktentwicklung zu steuern.
- Innovative VorschlägeBereitstellung von potenziellen Produktmerkmalen und Empfehlungen für Verbesserungen auf der Grundlage von Datenanalysen.
- WettbewerbspositionierungUnterstützung von Unternehmen bei der Entwicklung von Produkten, die den Bedürfnissen des Marktes entsprechen und sich von denen der Konkurrenz abheben.
5. Finanzanalyse und -prognose
- DatenintegrationDas RAG-System integriert Finanzdaten, Marktbedingungen und Wirtschaftsindikatoren für eine umfassende Analyse.
- TrendanalyseErkennen von Mustern und Trends auf den Finanzmärkten zur Unterstützung von Prognosen und Investitionsentscheidungen.
- AnlageberatungPraktische Beratung über Anlagemöglichkeiten und Risikofaktoren.
- strategische PlanungUnterstützung strategischer Finanzentscheidungen durch genaue Prognosen und datengestützte Empfehlungen.
6. Semantische Suche und effizientes Informationsretrieval
- kontextuelles VerständnisDas RAG-System führt eine semantische Suche durch, indem es den Kontext und die Bedeutung der Benutzeranfragen versteht.
- Relevante Ergebnisse:: Verbesserung der Sucheffizienz durch Auffinden der relevantesten und genauesten Informationen aus großen Datenmengen.
- Zeit sparen:: Optimierung des Datenabrufs und Verringerung des Zeitaufwands für die Suche nach Informationen.
- Verbessern Sie die GenauigkeitBietet genauere Suchergebnisse als herkömmliche Suchmethoden für Schlüsselwörter.
7. Verbessern der Erstellung von Inhalten
- Integration von TrendsDas RAG-System nutzt die neuesten Daten, um sicherzustellen, dass die generierten Inhalte den aktuellen Markttrends und Publikumsinteressen entsprechen.
- Automatische Generierung von Inhalten:: Automatische Generierung von Inhaltsideen und Entwürfen auf der Grundlage von Themen und Zielgruppen.
- Verbesserung der BeteiligungGenerieren Sie ansprechendere und relevantere Inhalte, um die Interaktion mit den Nutzern zu verbessern.
- rechtzeitige Aktualisierung:: Sicherstellen, dass die Inhalte die neuesten Ereignisse und Marktentwicklungen widerspiegeln und aktuell bleiben.
8. Textzusammenfassung
- HöhepunkteDas RAG-System kann lange Dokumente effektiv zusammenfassen und die wichtigsten Punkte und Erkenntnisse herausarbeiten.
- Zeit sparenSparen Sie Zeit beim Lesen mit prägnanten Berichtszusammenfassungen für vielbeschäftigte Führungskräfte und Manager.
- Fokus aufHervorhebung der Schlüsselbotschaften, damit die Entscheidungsträger die wichtigsten Punkte schnell erfassen können.
- Höhere Effizienz bei der Entscheidungsfindung:: Bereitstellung relevanter Informationen in leicht verständlicher Form, um die Effizienz der Entscheidungsfindung zu verbessern.
9. Fortgeschrittenes Frage- und Antwortsystem
- Präzise AntwortenDas RAG-System extrahiert Daten aus einer Vielzahl von Informationsquellen, um präzise Antworten auf komplexe Fragen zu geben.
- Zugangserweiterung:: Verbessern Sie den Zugang zu Informationen in verschiedenen Bereichen, z. B. im Gesundheits- oder Finanzwesen.
- kontextabhängig:: Gezielte Antworten auf die spezifischen Bedürfnisse und Fragen des Nutzers geben.
- Komplexe Themen:: Bewältigung komplexer Probleme durch Integration verschiedener Informationsquellen.
10. Gesprächsagenten und Chatbots
- KontextinformationenDas RAG-System verbessert die Interaktion zwischen Chatbots und virtuellen Assistenten, indem es relevante kontextbezogene Informationen liefert.
- Verbessern Sie die Genauigkeit:: Stellen Sie sicher, dass die Antworten der Dialogagenten korrekt und informativ sind.
- Benutzerunterstützung:: Verbesserung der Benutzerunterstützung durch Bereitstellung einer intelligenten und reaktionsschnellen Dialogschnittstelle.
- Interaktive Natur:: Abruf relevanter Daten in Echtzeit, um Interaktionen natürlicher und ansprechender zu gestalten.
11. Informationsabfrage
- Erweiterte SucheVerbessern Sie die Genauigkeit von Suchmaschinen durch die Abfrage- und Generierungsfunktionen von RAG.
- Generierung von InformationsfragmentenGenerierung effektiver Informationsschnipsel zur Verbesserung der Benutzerfreundlichkeit.
- Verbesserte Suchergebnisse:: Anreicherung der Suchergebnisse mit Antworten, die vom RAG-System generiert wurden, um die Auflösung von Anfragen zu verbessern.
- Wissensmaschine:: Nutzung von Unternehmensdaten zur Beantwortung interner Fragen, z. B. zur Personalpolitik oder zu Fragen der Einhaltung von Vorschriften, um den Zugang zu Informationen zu erleichtern.
12. Personalisierte Empfehlungen
- Analyse von KundendatenGenerieren Sie personalisierte Produktempfehlungen, indem Sie frühere Einkäufe und Bewertungen analysieren.
- Verbessern des Einkaufserlebnisses:: Verbessern Sie das Einkaufserlebnis des Nutzers, indem Sie ihm Produkte auf der Grundlage seiner persönlichen Vorlieben empfehlen.
- Einnahmen erhöhenEmpfehlen Sie relevante Produkte auf der Grundlage des Kundenverhaltens, um den Umsatz zu steigern.
- Marktplatzabgleich:: Anpassung der empfohlenen Inhalte an aktuelle Markttrends, um den sich ändernden Kundenbedürfnissen gerecht zu werden.
13. Text-Abschluss
- kontextuelle Ergänzung:: Das RAG-System vervollständigt Teile des Textes auf eine kontextuell angemessene Weise.
- Effizienzsteigerung:: Präzise Vervollständigungen, um Aufgaben wie das Schreiben von E-Mails oder Code zu vereinfachen.
- Produktivitätsverbesserung:: Reduzieren Sie den Zeitaufwand für Schreib- und Kodierungsaufgaben und steigern Sie die Produktivität.
- Wahrung der Kohärenz:: Achten Sie darauf, dass die textlichen Ergänzungen mit dem bestehenden Inhalt und Tonfall übereinstimmen.
14. die Datenanalyse
- Vollständige Datenintegration:: Das RAG-System integriert Daten aus internen Datenbanken, Marktberichten und externen Quellen, um einen umfassenden Überblick und eingehende Analysen zu ermöglichen.
- genaue Vorhersage:: Verbesserung der Genauigkeit der Prognosen durch Analyse der neuesten Daten, Trends und historischen Informationen.
- Einblick in die EntdeckungAnalyse umfassender Datensätze, um neue Chancen zu erkennen und zu bewerten und wertvolle Erkenntnisse für Wachstum und Verbesserungen zu gewinnen.
- Datengestützte Empfehlungen:: Bereitstellung datengestützter Empfehlungen durch Analyse umfassender Datensätze zur Unterstützung der strategischen Entscheidungsfindung und zur Verbesserung der allgemeinen Qualität der Entscheidungsfindung.
15. Übersetzungsaufgabe
- Suche nach einer Übersetzung:: Abrufen relevanter Übersetzungen aus Datenbanken zur Unterstützung bei Übersetzungsaufgaben.
- Generierung von Kontexten:: Generieren Sie konsistente Übersetzungen auf der Grundlage des Kontexts und unter Bezugnahme auf den abgerufenen Korpus.
- Verbessern Sie die Genauigkeit:: Verwendung von Daten aus verschiedenen Quellen zur Verbesserung der Genauigkeit von Übersetzungen.
- EffizienzsteigerungRationalisierung des Übersetzungsprozesses durch Automatisierung und kontextabhängige Generierung.
16. Analyse des Kundenfeedbacks
- umfassende AnalyseAnalyse von Feedback aus verschiedenen Quellen, um ein umfassendes Verständnis der Kundenstimmung und der Probleme zu erhalten.
- EinblickDetaillierte Einblicke, die wiederkehrende Themen und Schmerzpunkte der Kunden aufzeigen.
- DatenintegrationIntegration von Feedback aus internen Datenbanken, sozialen Medien und Bewertungen für eine umfassende Analyse.
- Informative EntscheidungsfindungSchnellere und intelligentere Entscheidungen auf der Grundlage von Kundenfeedback zur Verbesserung von Produkten und Dienstleistungen.
Diese Anwendungen veranschaulichen die vielfältigen Möglichkeiten moderner RAG-Systeme und zeigen, dass sie die Effizienz, die Genauigkeit und den Einblick verbessern können. Ob es um die Verbesserung des Kundensupports, die Verbesserung der Marktforschung oder die Rationalisierung der Datenanalyse geht, fortschrittliche RAG-Systeme bieten unschätzbare Lösungen, die die strategische Entscheidungsfindung und operative Exzellenz fördern.
Aufbau von Dialogwerkzeugen mit fortgeschrittener RAG
KI-Tools für Dialoge spielen eine entscheidende Rolle bei modernen Benutzerinteraktionen, da sie lebendiges und schnelles Feedback über eine Vielzahl von Plattformen liefern. Wir können die Fähigkeiten dieser Tools auf eine ganz neue Ebene heben, indem wir ein fortschrittliches Retrieval Augmented Generation (RAG)-System integrieren, das eine leistungsstarke Informationsabfrage mit fortschrittlichen Generierungstechniken kombiniert, um sicherzustellen, dass Dialoge sowohl informativ sind als auch einen natürlichen Kommunikationsfluss aufrechterhalten. Wenn das RAG-System in ein KI-Tool für Dialoge integriert wird, liefert es den Benutzern genaue und kontextbezogene Antworten, während gleichzeitig ein natürlicher Dialogfluss aufrechterhalten wird. In diesem Abschnitt wird untersucht, wie RAG zum Aufbau fortgeschrittener Dialogwerkzeuge verwendet werden kann. Dabei werden die Schlüsselelemente hervorgehoben, auf die man sich beim Aufbau dieser Systeme konzentrieren muss, und wie man sie in realen Anwendungen effektiv und praktisch einsetzen kann.
Gestaltung des Dialogprozesses
Das Herzstück eines jeden Dialogwerkzeugs ist sein Dialogablauf - d.h. die Schritte, in denen das System Benutzereingaben verarbeitet und Antworten generiert. Bei fortgeschrittenen RAG-basierten Werkzeugen muss der Entwurf des Dialogablaufs sorgfältig geplant werden, um die Retrieval-Fähigkeiten des RAG-Systems und die Generierung von Sprachmodellen voll auszunutzen. Dieser Ablauf besteht typischerweise aus mehreren Schlüsselphasen:
Problembewertung und Neuausrichtung::
- Das System bewertet zunächst die vom Benutzer gestellte Frage und stellt fest, ob sie neu formatiert werden muss, um den für eine genaue Antwort erforderlichen Kontext zu liefern. Wenn die Frage zu vage ist oder wichtige Details fehlen, kann das System sie in eine eigenständige Abfrage umformatieren, um sicherzustellen, dass alle erforderlichen Informationen enthalten sind.
Relevanzprüfung und Weiterleitung::
- Sobald die Frage richtig formatiert ist, sucht das System nach relevanten Daten im Vektorspeicher (einer Datenbank mit indizierten Informationen). Wenn relevante Informationen gefunden werden, wird die Frage an die RAG-Anwendung weitergeleitet, die die erforderlichen Informationen abruft, um eine Antwort zu generieren.
- Wenn keine relevanten Informationen im Vektorspeicher vorhanden sind, muss das System entscheiden, ob es mit der vom Sprachmodell allein generierten Antwort fortfährt oder das RAG-System auffordert, mitzuteilen, dass keine zufriedenstellende Antwort gegeben werden kann.
Generierung einer Antwort::
- Je nach den im vorherigen Schritt getroffenen Entscheidungen verwendet das System entweder die abgerufenen Daten, um detaillierte Antworten zu generieren, oder es stützt sich auf das Wissen des Sprachmodells und die Dialoghistorie, um dem Benutzer zu antworten. Mit diesem Ansatz wird sichergestellt, dass das Tool in der Lage ist, mit realen Problemen umzugehen, aber auch zwanglose Dialoge mit offenem Ende zu ermöglichen.
Optimierung der Dialogprozesse durch Entscheidungsmechanismen
Ein wichtiger Aspekt bei der Entwicklung fortgeschrittener RAG-Dialogwerkzeuge ist die Implementierung von Entscheidungsmechanismen, die den Ablauf des Dialogs steuern. Diese Mechanismen helfen dem System, auf intelligente Weise zu entscheiden, wann es Informationen abruft, wann es sich auf generative Fähigkeiten verlässt und wann es den Benutzer darüber informiert, dass keine relevanten Daten verfügbar sind. Durch diese Entscheidungen kann das Werkzeug flexibler werden und sich an verschiedene Dialogszenarien anpassen.
- Entscheidungspunkt 1: Neu erfinden oder weitermachen?
Das System entscheidet zunächst, ob die Frage des Benutzers so behandelt werden kann, wie sie ist, oder ob sie umgestaltet werden muss. Dieser Schritt stellt sicher, dass das System die Absicht des Benutzers versteht und über den notwendigen Kontext verfügt, um eine effektive Suche oder Generierung zu ermöglichen, bevor es eine Antwort erzeugt. - Entscheidungspunkt 2: Abrufen oder Erzeugen?
Falls eine Umformung erforderlich ist, stellt das System fest, ob relevante Informationen im Vektorspeicher vorhanden sind. Wenn relevante Daten gefunden werden, verwendet das System die RAG für das Retrieval und die Generierung der Antwort. Ist dies nicht der Fall, muss das System entscheiden, ob es sich zur Generierung der Antwort allein auf das Sprachmodell stützt. - Entscheidungspunkt 3: Informieren oder interagieren?
Wenn weder der Vektorspeicher noch das Sprachmodell eine zufriedenstellende Antwort liefern können, teilt das System dem Benutzer mit, dass keine relevanten Informationen verfügbar sind, wodurch die Transparenz und Glaubwürdigkeit des Dialogs erhalten bleibt.
Wie man effektive Prompts für dialogische RAGs entwirft
Prompts spielen eine Schlüsselrolle bei der Steuerung des Gesprächsverhaltens von Sprachmodellen. Die Gestaltung effektiver Prompts erfordert ein klares Verständnis der Kontextinformationen, der Ziele der Interaktion sowie des gewünschten Stils und Tons. Beispiel:
- HintergrundinformationenBereitstellung relevanter Kontextinformationen, um sicherzustellen, dass das Sprachmodell bei der Erstellung oder Anpassung von Fragen den erforderlichen Kontext erfasst.
- Zielgerichtete TippsKlären Sie den Zweck jeder Aufforderung, z. B. um die Frage anzupassen, einen Abrufprozess zu bestimmen oder eine Antwort zu generieren.
- Stil und TonSprachmodell: Legen Sie den gewünschten Stil (z.B. formell, leger) und Tonfall (z.B. informativ, einfühlsam) fest, um sicherzustellen, dass die Ausgabe des Sprachmodells den Erwartungen der Benutzer entspricht.
Die Entwicklung von Dialogwerkzeugen unter Verwendung fortgeschrittener RAG-Techniken erfordert eine integrierte Strategie, die die Stärken von Retrieval und Generierung kombiniert. Durch die sorgfältige Gestaltung von Dialogabläufen, die Implementierung intelligenter Entscheidungsmechanismen und die Entwicklung effektiver Prompts können Entwickler KI-Werkzeuge erstellen, die sowohl genaue und kontextreiche Antworten als auch natürliche, sinnvolle Interaktionen mit den Nutzern liefern.
Wie erstellt man fortgeschrittene RAG-Anwendungen?
Es ist großartig, mit dem Aufbau einer grundlegenden Retrieval Augmented Generation (RAG)-Anwendung zu beginnen, aber um das volle Potenzial von RAG in komplexeren Szenarien auszuschöpfen, müssen Sie über die Grundlagen hinausgehen. In diesem Abschnitt wird beschrieben, wie man eine fortgeschrittene RAG-Anwendung erstellt, die den Abrufprozess erweitert, die Antwortgenauigkeit verbessert und fortgeschrittene Techniken wie das Umschreiben von Abfragen und den mehrstufigen Abruf implementiert.
Bevor wir uns mit den fortgeschrittenen Techniken befassen, wollen wir kurz die grundlegende Funktionalität einer RAG-Anwendung erläutern, die die Fähigkeiten eines Sprachmodells (LLM) mit einer externen Wissensbasis zur Beantwortung von Benutzeranfragen kombiniert. Dieser Prozess besteht typischerweise aus zwei Phasen:
- abrufen (Daten)Die Anwendung sucht in Vektordatenbanken oder anderen Wissensdatenbanken nach Textausschnitten, die für die Anfrage des Benutzers relevant sind.
- lesenDer abgerufene Text wird an den LLM weitergeleitet, um eine Antwort auf der Grundlage dieser Kontexte zu erzeugen.
Dieser Ansatz des "Suchens und Lesens" liefert LLM die Hintergrundinformationen, die erforderlich sind, um genauere Antworten auf Fragen zu geben, die Fachwissen erfordern.
Die Schritte zur Erstellung einer fortgeschrittenen RAG-Anwendung sind wie folgt:
Schritt 1: Verwendung fortgeschrittener Techniken zur Verbesserung des Abrufs
Die Abrufphase ist entscheidend für die Qualität der endgültigen Antwort. In einer einfachen RAG-Anwendung ist der Abrufprozess relativ einfach, aber in einer fortgeschrittenen RAG-Anwendung können Sie die folgenden Erweiterungen verwenden:
1. mehrstufige Suche
Die mehrstufige Suche hilft dabei, die relevantesten Kontexte zu finden, indem die Suche in mehreren Schritten verfeinert wird. Sie umfasst in der Regel Folgendes:
- Erste breite Suche: Beginnen Sie mit einer breit angelegten Suche nach einer Reihe von potenziell relevanten Dokumenten.
- Verfeinern Sie Ihre SucheEine präzisere Suche auf der Grundlage vorläufiger Ergebnisse, die auf die wichtigsten Segmente eingegrenzt sind.
Diese Methode verbessert die Genauigkeit der abgerufenen Informationen, was wiederum zu genaueren Antworten führt.
2. das Umschreiben von Abfragen
Beim Query Rewriting wird die Anfrage eines Nutzers in ein Format umgewandelt, das mit größerer Wahrscheinlichkeit relevante Suchergebnisse liefert. Dies kann auf verschiedene Weise erreicht werden:
- stichprobenfreie UmschreibungRewrite queries without concrete examples, relying on the linguistic understanding of the model.
- Muster ohne UmschreibenBeispiele: Es werden Beispiele bereitgestellt, die den Modellen helfen, ähnliche Abfragen umzuschreiben, um die Genauigkeit zu verbessern.
- Maßgeschneiderte UmschreibmaschinenFeinabstimmung des Modells für das Umschreiben von Abfragen, um domänenspezifische Abfragen besser bearbeiten zu können.
Diese umgeschriebenen Abfragen stimmen besser mit der Sprache und Struktur der Dokumente in der Wissensbasis überein und verbessern so die Abfragegenauigkeit.
3. die Zerlegung der Unterabfrage
Bei komplexen Abfragen, die mehrere Fragen oder Aspekte umfassen, kann die Zerlegung der Abfrage in mehrere Unterabfragen die Abfrage verbessern. Jede Unterabfrage konzentriert sich auf einen bestimmten Aspekt der ursprünglichen Frage, so dass das System den relevanten Kontext für jeden Teil abrufen und die Antworten integrieren kann.
Schritt 2: Verbesserung der Antwortgenerierung
Nachdem Sie den Abrufprozess verbessert haben, besteht der nächste Schritt darin, die Art und Weise zu optimieren, wie das Big Language Model Antworten erzeugt:
1 Tipps zum Backtracking
Bei komplexen oder vielschichtigen Fragen kann es hilfreich sein, zusätzliche, umfassendere Abfragen zu erstellen. Diese "Fallback"-Hinweise können dazu beitragen, ein breiteres Spektrum an Kontextinformationen abzurufen, so dass das Big Language Model umfassendere Antworten generieren kann.
2. hypothetische Dokumenteneinbettung (HyDE)
HyDE ist eine hochmoderne Technik, die die Absicht einer Abfrage erfasst, indem sie hypothetische Dokumente auf der Grundlage der Abfrage des Benutzers erzeugt und diese Dokumente dann verwendet, um passende reale Dokumente in einer Wissensdatenbank zu finden. Dieser Ansatz ist besonders geeignet, wenn die Anfrage semantisch nicht mit dem relevanten Kontext übereinstimmt.
Schritt 3: Integration von Feedback-Schleifen
Um die Leistung von RAG-Anwendungen kontinuierlich zu verbessern, ist es wichtig, Feedback-Schleifen in das System zu integrieren:
1. das Feedback der Nutzer
Integration eines Mechanismus, der es den Benutzern ermöglicht, die Relevanz und Genauigkeit der Antworten zu bewerten. Dieses Feedback kann zur Anpassung des Abruf- und Generierungsprozesses genutzt werden.
2. verbessertes Lernen
Mithilfe von Reinforcement-Learning-Techniken werden Modelle auf der Grundlage von Nutzerfeedback und anderen Leistungskennzahlen trainiert. So kann das System aus seinen Fehlern lernen und die Genauigkeit und Relevanz mit der Zeit verbessern.
Schritt 4: Erweiterung und Optimierung
Mit der Weiterentwicklung der RAG-Anwendungen wird die Leistungsskalierung und -optimierung immer wichtiger:
1. verteilte Suche
Um große Wissensdatenbanken zu bewältigen, werden verteilte Retrievalsysteme implementiert, die Retrievalaufgaben parallel über mehrere Knoten verarbeiten können, wodurch die Latenzzeit verringert und die Verarbeitungsgeschwindigkeit erhöht wird.
2) Caching-Strategie
Durch die Implementierung einer Caching-Strategie zur Speicherung häufig aufgerufener Kontextblöcke wird die Notwendigkeit des wiederholten Abrufs verringert und die Antwortzeiten verkürzt.
3. die Optimierung des Modells
Optimierung großer Sprachmodelle und anderer in der Anwendung verwendeter Modelle, um den Rechenaufwand zu verringern und gleichzeitig die Genauigkeit zu erhalten. Techniken wie Modelldestillation und Quantisierung sind hier sehr nützlich.
Der Aufbau einer fortgeschrittenen RAG-Anwendung erfordert ein tiefgreifendes Verständnis der Abrufmechanismen und Generierungsmodelle sowie die Fähigkeit, komplexe Technologien zu implementieren und zu optimieren. Wenn Sie die oben beschriebenen Schritte befolgen, können Sie ein fortschrittliches RAG-System erstellen, das die Erwartungen der Benutzer übertrifft und hochwertige, kontextgenaue Antworten für eine Vielzahl von Anwendungsszenarien liefert.
Das Aufkommen von Wissensgraphen in fortgeschrittenen RAGs
Die Rolle von Wissensgraphen in fortgeschrittenen Retrieval Augmentation Generation (RAG)-Systemen ist besonders wichtig geworden, da Unternehmen bei komplexen datengesteuerten Aufgaben zunehmend auf KI setzen.Nach Angaben von Gartner. Der Knowledge Graph ist eine der Spitzentechnologien, die in der Zukunft mehrere Märkte umwälzen wird, so Gartner.Neue Technologien für das Radar stellte fest, dass Wissensgraphen zentrale Hilfsmittel für fortgeschrittene KI-Anwendungen sind und die Grundlage für die Datenverwaltung, die Argumentationsfähigkeit und die Zuverlässigkeit der KI-Ergebnisse bilden. Dies hat zu einer weit verbreiteten Nutzung von Wissensgraphen in verschiedenen Branchen wie dem Gesundheitswesen, dem Finanzwesen und dem Einzelhandel geführt.
Was ist der Knowledge Graph?
Ein Wissensgraph ist eine strukturierte Darstellung von Informationen, in der Entitäten (Knoten) und die Beziehungen zwischen ihnen (Kanten) explizit definiert sind. Bei diesen Entitäten kann es sich um konkrete Objekte (wie Personen und Orte) oder abstrakte Konzepte handeln. Die Beziehungen zwischen den Entitäten tragen zum Aufbau eines Wissensnetzes bei, das das Abrufen von Daten, das Ziehen von Schlussfolgerungen und das Ziehen von Schlüssen für den Menschen verständlicher macht. Der Knowledge Graph ist mehr als nur eine Datenspeicherung, er erfasst die reichhaltigen und nuancierten Beziehungen innerhalb einer Domäne, was ihn zu einem leistungsstarken Werkzeug für KI-Anwendungen macht.
Abfrageerweiterung und Planung mit Wissensgraphen
Die Anreicherung von Anfragen ist eine Lösung für das Problem unklarer Fragestellungen im RAG-System. Ziel ist es, einer Abfrage den notwendigen Kontext hinzuzufügen, um sicherzustellen, dass auch vage Fragen richtig interpretiert werden können. Im Finanzbereich können zum Beispiel Fragen wie "Was sind die aktuellen Herausforderungen bei der Umsetzung der Finanzregulierung?" Fragen wie "Was sind die aktuellen Herausforderungen bei der Umsetzung von Finanzvorschriften?" können so erweitert werden, dass sie spezifische Einheiten wie "AML-Compliance" oder "KYC-Prozess" enthalten, um den Suchprozess auf die relevantesten Informationen zu konzentrieren.
Im juristischen Bereich können Fragen wie "Welche Risiken sind mit Verträgen verbunden?" können durch Hinzufügen spezifischer Vertragstypen wie "Arbeitsvertrag" oder "Dienstleistungsvertrag" auf der Grundlage des vom Wissensgraphen bereitgestellten Kontexts erweitert werden.
Die Abfrageplanung hingegen zerlegt komplexe Abfragen in überschaubare Teile, indem sie Unterabfragen generiert. Dadurch wird sichergestellt, dass das RAG-System die relevantesten Informationen abrufen und integrieren kann, um eine umfassende Antwort zu geben. Um beispielsweise die Frage zu beantworten: "Welche Auswirkungen haben die neuen Rechnungslegungsstandards auf das Unternehmen? könnte das System zunächst Daten über die einzelnen Rechnungslegungsstandards, den Zeitplan für die Umsetzung und die historischen Auswirkungen auf verschiedene Bereiche abrufen.
Im medizinischen Bereich kann eine Frage wie "Was sind die neuesten Fortschritte bei medizinischen Geräten? in Unterfragen aufgeschlüsselt werden, die sich mit Fortschritten in bestimmten Bereichen befassen, z. B. "implantierbare Geräte", "Diagnosegeräte" oder "chirurgische Instrumente", um sicherzustellen, dass das System detaillierte und relevante Informationen aus jeder Unterkategorie erhält. Detaillierte und relevante Informationen aus jeder Unterkategorie.
Durch die Verbesserung und Planung von Abfragen hilft der Knowledge Graph bei der Optimierung und Strukturierung von Abfragen, um die Genauigkeit und Relevanz der Informationsbeschaffung zu verbessern und letztendlich genauere und nützlichere Antworten in komplexen Bereichen wie Finanzen, Recht und Gesundheitswesen zu liefern.
Die Rolle von Wissensgraphen in der RAG
In RAG-Systemen (Retrieval-enhanced Generation) verbessern Wissensgraphen den Retrieval- und Generierungsprozess durch die Bereitstellung strukturierter und kontextreicher Daten. Herkömmliche RAG-Systeme stützen sich auf unstrukturierten Text und Vektordatenbanken, was zu einer ungenauen oder unvollständigen Informationsbeschaffung führen kann. Durch die Integration von Wissensgraphen sind RAG-Systeme in der Lage,:
- Verbessertes Abfrageverständnis: Wissensgraphen helfen dem System, den Kontext und die Beziehungen einer Abfrage besser zu verstehen und so relevante Daten genauer abzurufen.
- Verbesserte Generierung von Antworten: Die strukturierten Daten, die der Knowledge Graph bereitstellt, können kohärentere, kontextbezogene Antworten generieren und so das Risiko von KI-Fehlern verringern.
- Implementierung komplexer Argumentation: Wissensgraphen unterstützen Multi-Hop-Schlussfolgerungen, bei denen das System neues Wissen ableiten oder disparate Informationen durch das Durchlaufen mehrerer Beziehungen verbinden kann.
Schlüsselkomponenten des Wissensgraphen
Der Wissensgraph besteht aus den folgenden Hauptkomponenten:
- Knotenpunkte: Stellt verschiedene Entitäten oder Konzepte im Bereich des Wissens dar, z. B. Personen, Orte oder Dinge.
- Seite: Beschreiben Sie die Beziehungen zwischen den Knoten und zeigen Sie, wie diese Einheiten miteinander verbunden sind.
- Attribute: Zusätzliche Informationen oder Metadaten, die mit Knoten und Kanten verbunden sind und mehr Kontext oder Details liefern.
- Dreiklang: Die Grundbausteine eines Wissensgraphen, die ein Thema, ein Prädikat und ein Objekt enthalten (z. B. "Einstein" [Thema] "Entdeckung" [Prädikat] "Relativität" [Objekt ]), bilden diese Tripel das Grundgerüst für die Beschreibung von Beziehungen zwischen Entitäten.
Wissensgraphen-RAG-Methodik
Die KG-RAG-Methodik besteht aus drei Hauptschritten:
- KG Konstruktion: In diesem Schritt werden unstrukturierte Textdaten in einen strukturierten Wissensgraphen umgewandelt, um sicherzustellen, dass die Daten organisiert und relevant sind.
- Zurückgeholt: Mit Hilfe eines neuartigen Suchalgorithmus, der Chain of Exploration (CoE) genannt wird, führt das System eine Datenrecherche durch den Wissensgraphen durch.
- Erzeugung von Antworten: Schließlich werden die abgerufenen Informationen verwendet, um kohärente und kontextualisierte Antworten zu generieren, indem die strukturierten Daten des Knowledge Graph mit den Fähigkeiten eines großen Sprachmodells kombiniert werden.
Diese Methodik unterstreicht die wichtige Rolle von strukturiertem Wissen bei der Verbesserung des Abruf- und Generierungsprozesses von RAG-Systemen.
Vorteile von Wissensgraphen in RAG
Die Integration des Wissensgraphen in das RAG-System bringt mehrere wesentliche Vorteile mit sich:
- Strukturierte Wissensrepräsentation: Wissensgraphen organisieren Informationen in einer Weise, die die komplexen Beziehungen zwischen Entitäten widerspiegelt und die Datenabfrage und -nutzung effizienter macht.
- Kontextuelles Verstehen: Wissensgraphen liefern umfangreichere Kontextinformationen, indem sie Beziehungen zwischen Entitäten erfassen, so dass das RAG-System relevantere und kohärentere Antworten generieren kann.
- Logische Fähigkeiten: Die Wissenszuordnung hilft dem System, durch die Analyse von Beziehungen zwischen Entitäten neues Wissen abzuleiten, um umfassendere und genauere Antworten zu erhalten.
- Integration von Wissen: Wissensgraphen können Informationen aus verschiedenen Quellen integrieren, um einen umfassenderen Überblick über Daten zu erhalten und bessere Entscheidungen zu treffen.
- Interpretierbarkeit und Transparenz: Die strukturierte Natur des Wissensgraphen macht den Argumentationspfad klar und verständlich, erleichtert die Erklärung des Schlussfolgerungsbildungsprozesses und verbessert die Glaubwürdigkeit des Systems.
Integration von KG mit LLM-RAG
Die Verwendung von Wissensgraphen in Verbindung mit Large Language Modelling (LLM) in RAG-Systemen verbessert die gesamte Wissensdarstellung und die Schlussfolgerungsmöglichkeiten. Diese Kombination ermöglicht eine dynamische Wissensfusion, die sicherstellt, dass die Informationen zum Zeitpunkt der Schlussfolgerung aktuell und relevant bleiben und somit genauere und aufschlussreichere Antworten generieren.LLMs können sowohl strukturierte als auch unstrukturierte Daten nutzen, um qualitativ bessere Ergebnisse zu liefern.
Verwendung von Wissensgraphen in Gedankenketten-Quizzes
Knowledge Mapping gewinnt im Bereich des Thought-Chain-Quizings zunehmend an Bedeutung, insbesondere in Verbindung mit Large Language Modelling (LLM). Bei diesem Ansatz werden komplexe Fragen in Teilfragen zerlegt, relevante Informationen abgerufen und zu einer endgültigen Antwort zusammengefügt. Wissensgraphen liefern in diesem Prozess strukturierte Informationen, die die Argumentationsfähigkeit des LLM verbessern.
Ein LLM-Agent könnte zum Beispiel zunächst den Wissensgraphen nutzen, um relevante Entitäten in einer Anfrage zu identifizieren, dann weitere Informationen aus verschiedenen Quellen einholen und schließlich eine umfassende Antwort generieren, die das vernetzte Wissen im Graphen widerspiegelt.
Praktische Anwendungen von Wissensgraphen
In der Vergangenheit wurden Wissensgraphen hauptsächlich in datenintensiven Bereichen wie Big-Data-Analysen und Unternehmenssuchsystemen verwendet, wo ihre Aufgabe darin bestand, die Konsistenz und Einheitlichkeit zwischen verschiedenen Datensilos zu wahren. Mit der Entwicklung von RAG-Systemen, die auf großen Sprachmodellen basieren, haben Wissensgraphen jedoch neue Anwendungsszenarien gefunden. Sie dienen nun als strukturierte Ergänzung zu probabilistischen großen Sprachmodellen und helfen dabei, falsche Informationen zu reduzieren, mehr Kontext zu liefern und als Gedächtnis- und Personalisierungsmechanismus in KI-Systemen zu fungieren.
Einführung in GraphRAG
GraphRAG ist eine moderne Retrieval-Methode, die Wissensgraphen und Vektordatenbanken in einer RAG-Architektur (Retrieval Augmented Generation) kombiniert. Dieses hybride Modell nutzt die Stärken beider Systeme, um KI-Lösungen zu liefern, die genauer, kontextbezogen und leicht verständlich sind.Gartner hat erklärt Die wachsende Bedeutung von Wissensgraphen für die Verbesserung der Produktstrategie und die Schaffung neuer KI-Anwendungsszenarien.
GraphRAG bietet folgende Funktionen:
- Höhere Genauigkeit: Durch die Kombination strukturierter und unstrukturierter Daten ist GraphRAG in der Lage, genauere und umfassendere Antworten zu geben.
- Skalierbarkeit: Dieser Ansatz vereinfacht die Entwicklung und Wartung von RAG-Anwendungen und ermöglicht eine bessere Skalierbarkeit.
- Interpretierbarkeit: GraphRAG bietet klare Inferenzpfade, die die Transparenz des Systems erhöhen, so dass die Ergebnisse der KI leichter zu verstehen sind und man ihnen vertrauen kann.
Vorteile von GraphRAG
GraphRAG hat gegenüber den herkömmlichen RAG-Methoden mehrere wesentliche Vorteile:
- Höhere Qualität der Antworten: Die Integration des Knowledge Graph hat die Genauigkeit und Relevanz von KI-generierten Antworten verbessert, wobei aktuelle Benchmarks eine dreifache Verbesserung der Genauigkeit zeigen.
- Kostenwirksamkeit: GraphRAG ist kostengünstiger, benötigt weniger Rechenressourcen und Trainingsdaten und ist eine attraktive Option für Unternehmen, die ihre KI-Investitionen optimieren wollen.
- Bessere Skalierbarkeit: Dieser Ansatz unterstützt groß angelegte KI-Anwendungen und ermöglicht es Unternehmen, komplexere Abfragen und größere Datensätze zu verarbeiten.
- Verbesserte Interpretierbarkeit: Der strukturierte Ansatz von GraphRAG bietet klarere Inferenzpfade, die den KI-Entscheidungsprozess transparenter und einfacher zu debuggen machen.
- Verborgene Zusammenhänge aufdecken: Wissensgraphen können Zusammenhänge aufzeigen, die in großen Datensätzen unbemerkt bleiben, und so tiefere Einblicke ermöglichen und die Qualität des Entscheidungsprozesses verbessern.
Gemeinsame GraphRAG-Architekturen
Es gibt mehrere GraphRAG-Architekturen, mit denen sich Wissensgraphen effektiv in RAG-Systeme integrieren lassen:
- Wissensgraphen mit semantischem Clustering: Diese Architektur verbessert die Relevanz und Genauigkeit der Datenabfrage, indem relevante Informationen vor der Generierung von Antworten in Gruppen zusammengefasst werden.
- Integration von Wissensgraphen mit Vektordatenbanken: Diese Architektur kombiniert die beiden Systeme, um einen umfassenderen Kontext für das größere Sprachmodell zu schaffen, was zur Generierung umfassenderer und kontextgerechterer Antworten führt.
- Wissensgraphen-gestütztes Frage- und Antwortsystem: In dieser Architektur fügt der Wissensgraph den Antworten, die vom großen Sprachmodell nach dem Vektor-Retrieval generiert werden, faktische Informationen hinzu, um die Genauigkeit und Vollständigkeit der Antworten zu gewährleisten.
- Graphengestütztes hybrides Retrieval: Dieser Ansatz kombiniert die Vektorsuche, die Suche nach Schlüsselwörtern und graphen-spezifische Abfragen, um ein leistungsfähiges und flexibles Retrievalsystem zu schaffen, das die Fähigkeit großer Sprachmodelle zur Generierung relevanter Antworten verbessert.
Aufkommende Modelle für GraphRAG
Im Zuge der Weiterentwicklung von GraphRAG zeichnen sich allmählich mehrere Muster ab:
- Enquiry Enhancement: Optimieren und erweitern Sie Abfragen mithilfe von Wissensgraphen, um sicherzustellen, dass die relevantesten Informationen abgerufen werden.
- Antwortverbesserung: Verbessern Sie die Genauigkeit und Vollständigkeit der vom Big Language Model generierten Antworten, indem Sie relevante Fakten hinzufügen.
- Antwortkontrolle: Verwenden Sie Wissensgraphen, um die Genauigkeit von KI-generierten Inhalten zu überprüfen und das Risiko falscher oder inkorrekter Informationen zu verringern.
Diese Muster zeigen, wie GraphRAG die Art und Weise verändert, wie KI-Systeme komplexe Abfragen verarbeiten und Antworten generieren.
Anwendungen von GraphRAG
- Juristische Recherche: Die Fähigkeit von GraphRAG, durch ein komplexes Netz von Gesetzen, Rechtsprechung und Fallstudien zu navigieren, gibt Juristen ein leistungsfähiges Werkzeug an die Hand, um relevante juristische Informationen und potenzielle Zusammenhänge zu entdecken.
- Gesundheitswesen: Im Gesundheitswesen hilft GraphRAG, die komplexen Beziehungen zwischen medizinischem Wissen, Patientengeschichte und Behandlungsoptionen zu verstehen, um die Diagnosegenauigkeit und die personalisierte Behandlungsplanung zu verbessern.
- Finanzielle Analyse: GraphRAG hilft bei der Analyse komplexer Finanznetzwerke und -abhängigkeiten und bietet Einblicke in Markttrends, Risikomanagement und Anlagestrategien unter Verwendung miteinander verbundener Daten aus dem Wissensgraphen.
- Analyse sozialer Netzwerke: GraphRAG ermöglicht die Erforschung komplexer sozialer Strukturen und Interaktionen und hilft Forschern und Analysten, Beziehungs- und Einflussmuster in sozialen Netzwerken zu verstehen.
- Wissensmanagement: GraphRAG verbessert die Wissensbasis des Unternehmens, indem es Beziehungen und Hierarchien innerhalb von Organisationen erfasst und nutzt, Entscheidungsprozesse verbessert und Innovationen im Unternehmen fördert.
Mit den Fortschritten der KI wird es immer wichtiger, Wissensgraphen in Systeme zur Generierung von Retrieval-Erweiterungen einzubeziehen. Wissensgraphen bieten einen leistungsfähigen Rahmen für die Organisation und Verknüpfung von Daten, was zu präziseren, kontextbezogenen und leicht interpretierbaren KI-Lösungen führt. Die Entstehung von GraphRAG zeigt die Vorteile der Kombination von Wissensgraphen mit traditionellen Vektormethoden, die einen umfassenderen und effizienteren Ansatz für die Informationsbeschaffung und die Generierung von Antworten bieten.
Advanced RAG: Horizonterweiterung durch erweiterte Generierung mit multimodalem Retrieval
Die Fortschritte in der künstlichen Intelligenz wurden von Durchbrüchen begleitet, die die Grenzen des maschinellen Verstehens und der Generierung weiter ausdehnen. Während sich traditionelle Retrieval Augmented Generation (RAG)-Systeme in erster Linie auf Textdaten konzentriert haben, stellt das Aufkommen der multimodalen RAG einen wichtigen technologischen Sprung dar. Diese innovative Technologie ermöglicht es der künstlichen Intelligenz, verschiedene Formen von Daten - wie Text, Bilder, Audio und Video - zu verarbeiten und zu integrieren, um inhaltsreiche und kontextualisierte Ergebnisse zu erzeugen. Durch die Nutzung multimodaler Daten werden diese fortschrittlichen KI-Systeme flexibler und kontextsensitiver und sind in der Lage, tiefere Einblicke und genauere Antworten zu geben. In diesem Abschnitt werden die Kernkonzepte, Betriebsmechanismen und potenziellen Anwendungen multimodaler RAG untersucht, um ihre Bedeutung für die nächste Generation von KI-Interaktionen zu verdeutlichen.
Multimodale RAG verstehen
Multimodales RAG ist eine fortschrittliche Erweiterung des klassischen RAG-Rahmens, die Abrufmechanismen mit generativer KI für mehrere Datentypen kombiniert. Während traditionelle RAG-Systeme Informationen durch die Abfrage von Textdatenbanken erhalten, erweitert multimodales RAG diese Fähigkeit durch die Integration von Text, Bildern, Audio und Video in den Abfrage- und Generierungsprozess. Diese Erweiterung ermöglicht es den KI-Modellen, eine größere Bandbreite an Eingaben zu nutzen, um umfassendere und differenziertere Ergebnisse zu erzielen.
Wie funktioniert die multimodale RAG?
Der Arbeitsablauf einer multimodalen RAG besteht darin, verschiedene Arten von Daten in ein strukturiertes Format, in der Regel Vektoren, zu kodieren, damit das KI-Modell sie verarbeiten kann. Diese Vektoren werden in einem gemeinsamen Einbettungsraum gespeichert, der Daten aus verschiedenen Modalitäten enthält. Bei einer Abfrage ruft das Modell relevante Informationen aus diesen Modalitäten ab und stellt so sicher, dass eine umfassendere und genauere Antwort gegeben wird. Beispielsweise kann das System bei einer Anfrage zu einem historischen Ereignis Textbeschreibungen, relevante Bilder, Audioclips von Expertenkommentaren und Videomaterial abrufen, die zusammen eine detailliertere und informativere Antwort ergeben.
Methoden zur Umsetzung multimodaler RAGs
Es gibt eine Reihe von Ansätzen zur Realisierung einer multimodalen RAG, die jeweils ihre eigenen Vorteile und Herausforderungen mit sich bringen:
- Ein einziges multimodales Modell:
Bei diesem Ansatz wird ein einheitliches Modell verwendet, das darauf trainiert ist, verschiedene Datentypen - z. B. Text, Bilder, Audio - in einem gemeinsamen Vektorraum zu kodieren. Das Modell kann dann nahtlos über diese Datentypen hinweg abrufen und generieren. Dieser Ansatz vereinfacht zwar den Prozess durch die Verwendung eines einzigen Modells, erfordert aber ein komplexes Training, um eine genaue Kodierung und Abfrage multimodaler Daten zu gewährleisten. - Textbasiertes Basis-Modal:
Bei diesem Ansatz werden nicht-textuelle Daten vor der Kodierung und Speicherung in textuelle Beschreibungen umgewandelt. Dieser Ansatz nutzt die Vorteile der derzeit modernsten Textmodelle. Allerdings kann es bei der Umwandlung zu Informationsverlusten kommen, da Nuancen im Bild oder Ton möglicherweise nicht vollständig im Text wiedergegeben werden. - Mehrere Encoder:
Bei diesem Ansatz werden verschiedene Modelle zur Kodierung unterschiedlicher Datentypen verwendet, die jeweils von einem eigenen spezialisierten Modell verarbeitet werden. Der Abrufprozess integriert diese Ergebnisse. Dieser Ansatz ermöglicht zwar eine spezialisiertere Kodierung und einen genaueren Datenabruf, erhöht aber die Komplexität des Systems und erfordert eine sorgfältige Verwaltung mehrerer Modelle und ihrer Interaktionen.
Architektur eines multimodalen RAG
Die Architektur des multimodalen RAG baut auf den Grundlagen traditioneller RAGs auf und berücksichtigt gleichzeitig die Komplexität des Umgangs mit mehreren Datentypen. Die Kernarchitektur umfasst die folgenden Schlüsselkomponenten:
- Modalspezifische Geber:
Jede Datenmodalität, z. B. Text, Bild oder Audio, wird von einem speziellen Kodierer verarbeitet. Diese Kodierer wandeln die Rohdaten in einen einheitlichen Einbettungsraum um, so dass alle Modalitäten auf standardisierte Weise verglichen und abgerufen werden können. - Gemeinsamer eingebetteter Raum:
Eine Schlüsselkomponente des multimodalen RAG ist der gemeinsame Einbettungsraum, in dem kodierte Vektoren aus verschiedenen Modalitäten gespeichert werden. Dieser Raum ermöglicht modalitätsübergreifende Vergleiche und Abfragen, so dass das Modell relevante Informationen in verschiedenen Datentypen erkennen kann. - Retriever:
Die Retriever-Komponente ist für die Abfrage des gemeinsamen Einbettungsraums zuständig, um die relevantesten Datenpunkte in allen Modalitäten zu finden. Sie kann Informationen auf der Grundlage verschiedener Kriterien wie Relevanz für die Eingabeabfrage oder Ähnlichkeit mit anderen Datenpunkten im Raum abrufen. - Generator:
Sobald relevante Informationen abgerufen wurden, integriert die Generator-Komponente diese Daten in die Antwort des KI-Modells. Bei dem Generator handelt es sich in der Regel um ein komplexes Sprachmodell, das Erkenntnisse aus verschiedenen Modalitäten in eine kohärente und kontextgenaue Ausgabe verweben kann. - Integrationsmechanismen:
Der Fusionsmechanismus ist für die Kombination der abgerufenen multimodalen Daten zu einer einheitlichen Darstellung für die Verwendung durch den Generator verantwortlich. Dieser Prozess kann die Auswahl der relevantesten Modalitäten oder die Synthese von Informationen aus verschiedenen Quellen beinhalten, um eine umfassende Antwort zu erstellen.
Es gibt mehrere Schlüsselstrategien, die angewandt werden müssen, um die Informationen der verschiedenen Modalitäten in einem RAG-System zu verwalten:
- Gleichmäßig in den Raum eingebettet:
Die Kodierung aller Datentypen in einem gemeinsamen Einbettungsraum ermöglicht es dem System, multimodale Suchvorgänge effizient durchzuführen. Gleichzeitig bietet dieser Einbettungsraum eine Grundlage für die Integration und den Abgleich von Daten aus verschiedenen Quellen. - Modalübergreifende Aufmerksamkeitsmechanismen:
Durch den Einsatz eines modalübergreifenden Aufmerksamkeitsmechanismus wird sichergestellt, dass das Modell in der Lage ist, sich auf die wichtigsten Informationen in den abgerufenen Daten zu konzentrieren, unabhängig davon, aus welcher Modalität sie stammen. Dies trägt dazu bei, die Bedeutung der einzelnen Datentypen in der endgültigen Antwort auszugleichen. - Modalitätsspezifische Nachbearbeitung:
Nach Abschluss des Abrufs kann eine spezifische Nachbearbeitung der Daten für jede Modalität erforderlich sein, z. B. die Größenanpassung von Bildern oder die Normalisierung von Audiodaten, um sicherzustellen, dass die Daten für die Integration und Erstellung optimiert sind.
Multimodale RAG in Chatbots
Multimodale RAGs erweitern die Fähigkeiten von Chatbots erheblich und ermöglichen ihnen, reichhaltigere und kontextbezogenere interaktive Erfahrungen zu bieten. Herkömmliche Chatbots sind in erster Linie auf Text angewiesen, was ihre Fähigkeit einschränkt, auf Informationen zu reagieren, die Sehen oder Hören beinhalten. Multimodale RAG ermöglichen es Chatbots, Informationen aus Bildern, Video- und Audioclips zu erfassen und zu integrieren, um ein umfassenderes und interessanteres Nutzererlebnis zu bieten.
Zum Beispiel durch die Verwendung der multimodalen RAG's Kundenbetreuung Chatbot Anleitungsvideos, Produktbilder oder Audioanleitungen können als Antwort auf die Anfrage eines Benutzers angezeigt werden und ermöglichen so eine interaktivere und praktischere Hilfe. Dies ist besonders wichtig in Bereichen wie dem Einzelhandel, dem Gesundheitswesen und dem Bildungswesen, wo die Kommunikation oft durch mehrere Formen von Informationen unterstützt werden muss.
Ausbau der multimodalen RAG-Anwendungen
Die Einführung multimodaler Funktionen eröffnet neue Möglichkeiten in einer Vielzahl von Branchen:
- Gesundheitswesen:
Multimodale RAGs können textuelle medizinische Aufzeichnungen, radiologische Bilder, Laborergebnisse und Audiobeschreibungen von Patienten kombinieren, um die Genauigkeit und Vollständigkeit von Diagnosesystemen zu verbessern. - Finanzen:
Im Bereich der Finanzdienstleistungen kann das multimodale RAG komplexe Dokumente mit Tabellen, Diagrammen und erklärenden Texten verarbeiten und analysieren, um den Entscheidungsprozess zu verbessern. - Bildung:
Bildungsplattformen können multimodale RAGs verwenden, um Text, Videovorlesungen, Illustrationen und interaktive Simulationen zu einer vollständigen Lehrgeschichte zu verschmelzen und so eine reichere Lernerfahrung zu bieten.
Multimodale RAG ist ein wichtiger technologischer Fortschritt, der das Potenzial hat, die Art und Weise zu verändern, wie KI-Systeme mit Nutzern interagieren und auf sie reagieren. Durch die Einbeziehung mehrerer Datentypen in den Abfrage- und Generierungsprozess können multimodale RAG-Systeme reichhaltigere, genauere und kontextualisierte Ergebnisse liefern, die neue Möglichkeiten in einer Reihe von Branchen eröffnen. Es ist zu erwarten, dass mit der Weiterentwicklung der Technologie die Anwendungsmöglichkeiten erweitert werden, um die Fähigkeit der KI zur Verarbeitung komplexer multimodaler Informationen weiter zu verbessern.
Wie sich die GenAI-Koordinationsplattform ZBrain von LeewayHertz von fortschrittlichen RAG-Systemen abhebt.
Sind Sie neugierig auf erweiterte RAG, multimodale RAG und Wissensgraphen? Stellen Sie sich vor, diese leistungsstarken Funktionen in einer einzigen Plattform zu kombinieren, mit der Sie einfach fortschrittliche KI-Anwendungen erstellen können. Das ist ZBrain.
ZBrainZBrain wurde von LeewayHertz entwickelt und ist eine umfassende Orchestrierungsplattform zur Vereinfachung und Beschleunigung der Entwicklung und Skalierung von KI-Lösungen der Unternehmensklasse. Mit seiner benutzerfreundlichen Low-Code-Umgebung ermöglicht ZBrain Unternehmen die schnelle Erstellung, Bereitstellung und Skalierung kundenspezifischer generativer KI-Anwendungen (GenAI) bei reduziertem Programmieraufwand. Die Plattform revolutioniert den KI-Entwicklungsprozess in Unternehmen, indem sie es ihnen ermöglicht, ihre eigenen Daten zu nutzen, um hochgradig individualisierte und präzise KI-Anwendungen zu entwickeln. Als zentrales Kontrollzentrum lässt sich ZBrain nahtlos in bestehende Technologie-Stacks integrieren, um die Effizienz der Entwicklung von GenAI-Anwendungen zu verbessern. Auf ZBrain aufbauende Anwendungen zeichnen sich durch die Verarbeitung natürlicher Sprache (NLP) aus, z. B. bei der Erstellung von Berichten, der Übersetzung, der Datenanalyse, der Klassifizierung und der Zusammenfassung von Texten. Durch die Nutzung privater und kontextbezogener Daten stellt ZBrain sicher, dass die Antworten hochgradig relevant und personalisiert sind, um spezifische Geschäftsanforderungen zu erfüllen.
Schnittstelle zu fortgeschrittenen Retrieval Augmentation Generation (RAG)-Systemen
- Integration von verschiedenen Datenquellen: ZBrain integriert eine Vielzahl von Datenquellen, darunter private, öffentliche und Echtzeit-Datenströme in allen Datenformaten (strukturiert, halbstrukturiert und unstrukturiert), um die Genauigkeit und Relevanz von KI-Antworten zu verbessern.
- Optimierung auf Blockebene: Die Plattform stellt sicher, dass genaue und maßgeschneiderte Ergebnisse erzeugt werden, indem die Informationen in handhabbare Teile zerlegt und die effektivsten Suchstrategien angewandt werden.
- Automatische Entdeckung von Abrufstrategien: Hochentwickelte Algorithmen in ZBrain identifizieren automatisch optimale Suchstrategien und wenden diese an. Dadurch werden manuelle Eingriffe auf der Grundlage von Daten und Kontext reduziert und die Genauigkeit der Datenabfrage verbessert.
- Schutzmaßnahmen und Kontrolle von Halluzinationen: ZBrain ist mit Sicherheitsvorkehrungen und Phantomkontrollen ausgestattet, um die Generierung ungenauer oder irreführender Informationen zu verhindern und eine hohe Genauigkeit und Zuverlässigkeit zu gewährleisten.
multimodale Fähigkeit
- Verarbeitet mehrere Datenformate. ZBrain zeichnet sich durch die Verarbeitung mehrerer Datenformate wie Text, Bilder, Video und Audio aus und liefert eine umfassende und detaillierte Antwort.
- Integration und Analyse über verschiedene Datentypen hinweg. Die Plattform ist in der Lage, verschiedene Arten von Daten zu integrieren und zu analysieren, um umfassendere Erkenntnisse und relevante Antworten zu liefern.
- Verbesserte Abfrageverarbeitung. ZBrain verwaltet und ruft Informationen aus verschiedenen Datenmodalitäten effizient ab und verbessert so die Genauigkeit und den Einblick in komplexe Probleme.
Wissenslandkarte
- Rahmenwerk für strukturierte Daten. ZBrain organisiert Daten in einem strukturierten Netzwerk, das die Abfragegenauigkeit verbessert und tiefere Einblicke durch die Verbindung verwandter Konzepte ermöglicht.
- Tiefere Dateneinblicke. Die vernetzte Natur des Knowledge Graph ermöglicht es ZBrain, nuancierte, kontextbezogene Antworten zu liefern, die zu umfassenderen und aussagekräftigeren Erkenntnissen führen.
- Erweiterte Datenkapazitäten. ZBrain unterstützt die Erweiterung von Daten auf Block- oder Dateiebene, die Aktualisierung von Metainformationen und die Erstellung von Ontologien zur Verbesserung der Datendarstellung, -organisation und -abfrage.
Vorteile des Einsatzes von ZBrain bei der Entwicklung von KI-Lösungen für Unternehmen
ZBrain bietet viele Vorteile für die Entwicklung von KI-Lösungen für Unternehmen, darunter:
- Skalierbarkeit
ZBrain macht es einfach, KI-Lösungen zu skalieren, um wachsende Datenmengen und Nutzungsszenarien ohne Leistungseinbußen zu bewältigen. - Effiziente Integration
Die Plattform lässt sich problemlos in bestehende Technologiepakete integrieren, was die Implementierungszeit und -kosten reduziert und die Einführung von KI beschleunigt. - Personalisierung
ZBrain unterstützt die Entwicklung von hochgradig maßgeschneiderten KI-Anwendungen, die spezifische Geschäftsanforderungen erfüllen und mit den Unternehmenszielen übereinstimmen. - Ressourceneffizienz
Der geringe Code-Anteil reduziert den Bedarf an einer großen Anzahl von Entwicklern und eignet sich für Organisationen mit kleineren technischen Teams. - Umfassende Lösungen
Von der Entwicklung bis zur Bereitstellung deckt ZBrain den gesamten Lebenszyklus einer KI-Anwendung ab und ist damit eine umfassende Lösung. - Neutrale Cloud-Bereitstellung
ZBrain ist Cloud-neutral, so dass Anwendungen auf einer Vielzahl von Cloud-Plattformen eingesetzt werden können, was eine flexible Anpassung an unterschiedliche organisatorische Anforderungen und Infrastrukturpräferenzen ermöglicht.
Das fortschrittliche RAG-System, die multimodale Unterstützung und die robuste Knowledge-Graph-Integration machen ZBrain zu einer leistungsstarken Plattform, die in einer Vielzahl von Anwendungen für mehr Genauigkeit, Effizienz und Einblicke sorgt.
Fußnote
Die Fortschritte bei der Retrieval-Augmented Generation (RAG) haben ihre Fähigkeiten drastisch erhöht, so dass frühere Beschränkungen überwunden und neue Möglichkeiten für die KI-gestützte Informationsbeschaffung und -generierung eröffnet werden konnten. Durch den Einsatz ausgeklügelter Retrieval-Mechanismen kann fortschrittliches RAG auf große Datenmengen zugreifen, um sicherzustellen, dass die generierten Antworten sowohl genau als auch kontextbezogen relevant sind. Dieser Fortschritt ebnet den Weg für dynamischere und interaktive KI-Anwendungen und macht RAG zu einem wichtigen Werkzeug in Bereichen wie Kundenservice, Forschung, Wissensmanagement und Inhaltserstellung. Die Anwendung dieser fortschrittlichen RAG-Technologien bietet Organisationen die Möglichkeit, die Benutzererfahrung zu verbessern, Prozesse zu rationalisieren und komplexe Probleme mit größerer Genauigkeit und Effizienz zu lösen.
Mit der Einführung von Multimodal RAG und Knowledge Graph RAG werden die Fähigkeiten dieses Rahmens weiter verbessert, was eine weit verbreitete Anwendung in allen Branchen fördert. Multimodal RAG kombiniert textuelle, visuelle und andere Formen von Daten und ermöglicht es dem Large Language Model (LLM), umfassendere und kontextbezogene Antworten zu generieren, die das Nutzererlebnis verbessern und reichhaltigere und differenziertere Informationen liefern. Und Knowledge Graph RAG nutzt vernetzte Datenstrukturen, um semantisch reichhaltige Inhalte abzurufen und zu generieren, was die Genauigkeit und Tiefe der Informationen erheblich verbessert. Diese Fortschritte in der RAG-Technologie läuten eine neue Welle der KI-Innovation ein und bieten intelligentere und flexiblere Lösungen für komplexe Herausforderungen bei der Informationsbeschaffung.
© urheberrechtliche Erklärung
Artikel Copyright AI-Austauschkreis Alle, bitte nicht ohne Erlaubnis vervielfältigen.
Ähnliche Artikel



Keine Kommentare...