
Die Modelle der PP-Serie von Flying Paddles sind neu: Die neue 'Biene' für PP-DocBee zum Verstehen von Dokumentenbildern!
Die Technologie zum Verstehen von Dokumentenbildern zielt darauf ab, Computer in die Lage zu versetzen, den Inhalt von Dokumentenbildern genauso gut zu verstehen wie Menschen. Dabei geht es hauptsächlich um die Analyse, Verarbeitung und das Verständnis von Dokumentenbildern (z. B. Papierverträge, Buchseiten, Rechnungen usw.), die durch Scannen oder Fotografieren gewonnen wurden, um die Extraktion wertvoller Informationen wie Text, Tabellen, Diagramme usw. und um die Strukturierung dieser Informationen. Im Zuge des digitalen Wandels wird die Technologie zum Verstehen von Dokumentenbildern in der Wirtschaft, in der Wissenschaft und im täglichen Leben häufig eingesetzt, um die Effizienz und Genauigkeit der Dokumentenverarbeitung zu verbessern.
Zuvor hatte FeiPaddle in Kombination mit dem Wenxin Big Model die PP-ChatOCRv3-Größenmodell-Fusionslösung veröffentlicht, die zunächst die OCR-Technologie nutzt, um den Text im Bild zu extrahieren, und ihn dann in das Wenxin Big Model einspeist, um das Quiz zu analysieren, was letztendlich die Text-Bild-Layout-Analyse und die Informationsextraktionswirkung erheblich verbessert. Das System ist bei Text und Tabellen sehr genau, aber die Fähigkeit, Bilder und Diagramme in Dokumenten zu verstehen, muss weiter verbessert werden. Um die Bedürfnisse der Benutzer bei komplexen und vielfältigen Aufgaben zum Verstehen von Dokumentenbildern besser zu erfüllen, schlagen wir daher ein neues Verfahren vor, PP-DocBee, das auf einem multimodalen großen Modell basiert, um ein durchgängiges Verständnis von Dokumentenbildern zu erreichen. Es kann effizient in allen Arten von Szenarien eingesetzt werden, wie z.B. Dokumentenverständnis, Dokumenten-Fragen und -Antworten, usw. Insbesondere für das Verstehen chinesischer Dokumente, wie z.B. Finanzberichte, Gesetze und Verordnungen, Dissertationen, Handbücher, Verträge, Forschungsberichte, usw., ist die Leistung sehr gut.
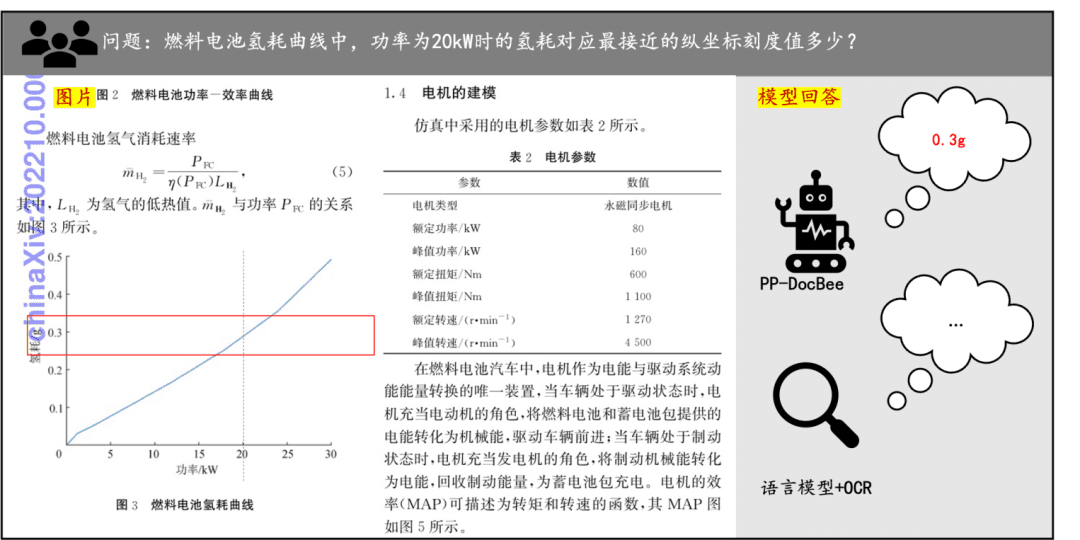
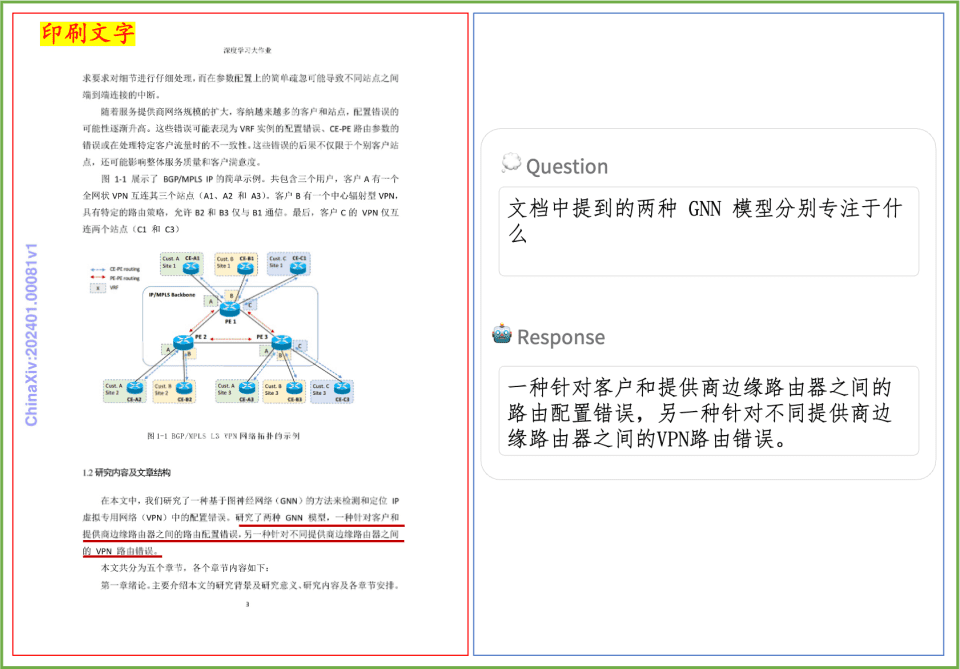
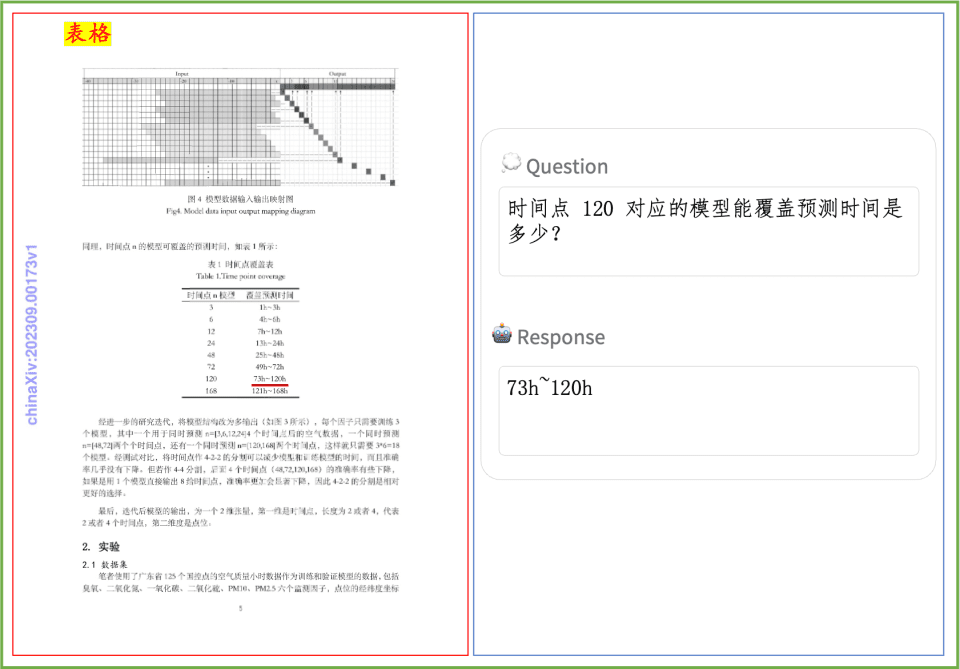
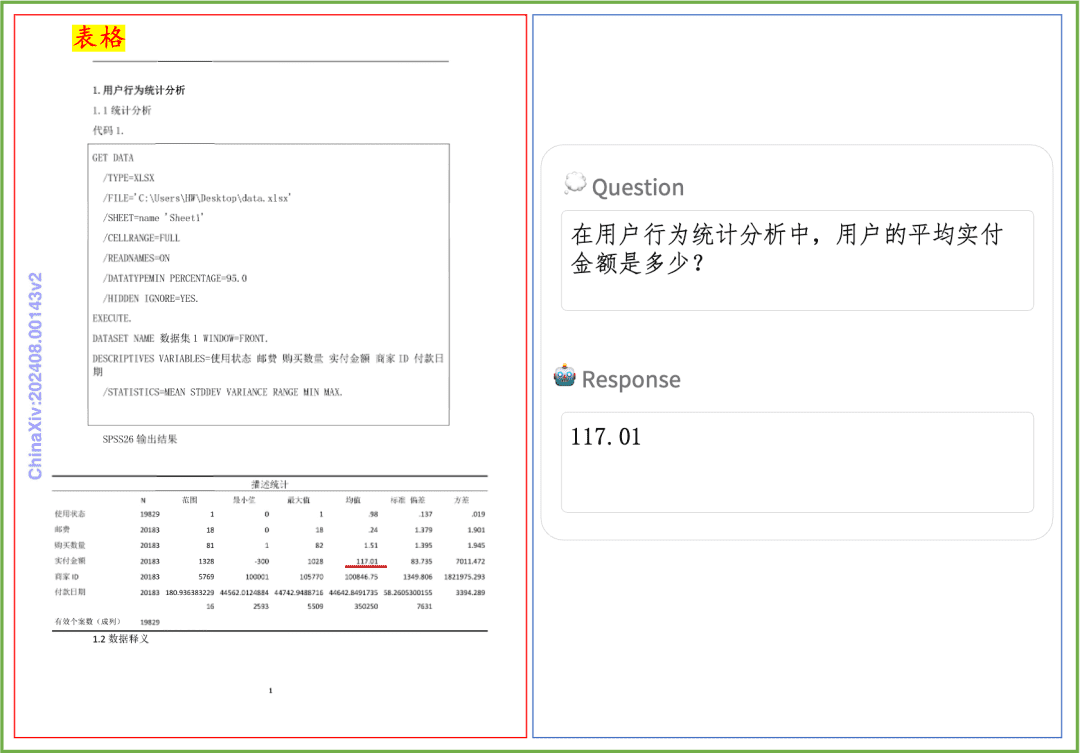
Beispiel für das Verstehen von Dokumenten Ein kurzer Blick auf die Auswirkungen von PP-DocBee auf das Verstehen von gedrucktem Text, Tabellen, Diagrammen und anderen Dokumenten:


PP-DocBee hat grundsätzlich SOTA für Modelle der gleichen Parametervolumenstufe auf mehreren maßgeblichen englischen Dokumentenverständnis-Review-Listen im akademischen Bereich erreicht.
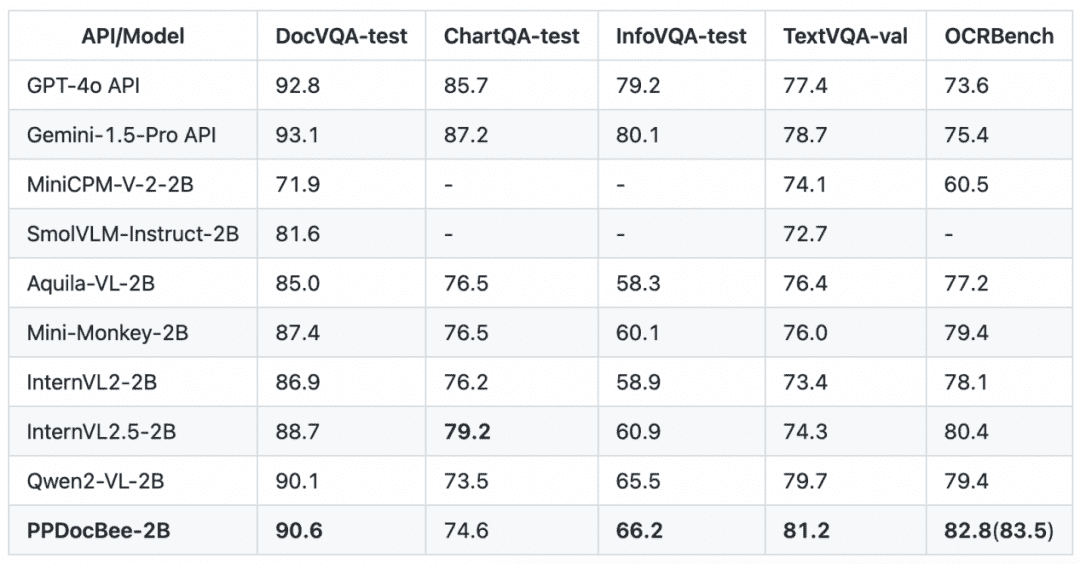
English Document Comprehension Review List Mitbewerbervergleich
Hinweis: Die OCRBench-Kennzahlen sind auf eine 100-Punkte-Skala normiert, und die OCRBench-Kennzahlen von PPDocBee-2B haben eine Punktzahl von 82,8 für die End-to-End-Evaluierung und 83,5 für die OCR-Post-Processing-unterstützte Evaluierung. PP-DocBee liegt auch in der Kategorie der Metriken für interne Geschäftsszenarien in China über den derzeit gängigen Open- und Closed-Source-Modellen.
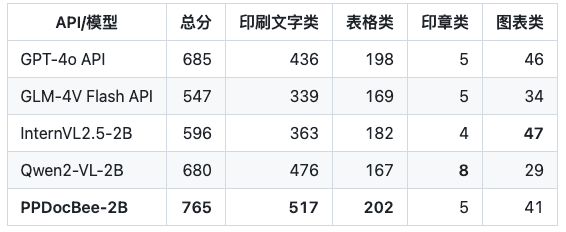
Business Chinese Scenario Vergleich von Wettbewerbern
Hinweis: Die Bewertungsgruppe chinesischer Szenarien für den internen Geschäftsverkehr umfasst Szenarien für Finanzberichte, Gesetze und Vorschriften, wissenschaftliche und technische Arbeiten, Handbücher, geisteswissenschaftliche Arbeiten, Verträge, Forschungsarbeiten usw., die in vier Hauptkategorien unterteilt sind: gedruckter Text, Formulare, Siegel und Diagramme.
Um die Inferenzleistung von PP-DocBee weiter zu verbessern, erreichen wir durch die Optimierung der Operator-Fusion eine Reduzierung der Inferenzzeit um 51,51 TP3T und eine Reduzierung der gesamten End-to-End-Zeit um 41,91 TP3T, wie in der folgenden Tabelle dargestellt.
| PP-DocBee | Durchschnittliche Ende-zu-Ende-Zeit(en) | Durchschnittliche Vorverarbeitungszeit (s) | Durchschnittliche Zeit, die für das Argumentieren aufgewendet wird (s) |
| Standardversion | 1.60 | 0.29 | 1.30 |
| High Performance Edition | 0.93 | 0.29 | 0.63 |
Hinweis: Die Hochleistungsversion hat im Grunde die gleiche Anzahl an Ausgabe-Token wie die Standardversion mit der gleichen Anzahl an Eingabe-Token. Dank der Hochleistungsoptimierung mit dem Flying Paddle reagiert PP-DocBee schneller, ohne die Qualität der Antworten zu beeinträchtigen. Einzelheiten zu dieser leistungsstarken Version finden Sie unter: https://github.com/PaddlePaddle/PaddleMIX/tree/develop/deploy/ppdocbee
Wir bieten auch eine Online-Erfahrungsumgebung für die Flying Paddle Star River Community, in der Sie die Funktionen von PP-DocBee über das Flying Paddle Star River Community Application Centre (https://aistudio.baidu.com/application/detail/60135) schnell kennenlernen können.
Darüber hinaus bieten wir auch lokale gradio-Bereitstellung, OpenAI-Service-Bereitstellung, sowie detaillierte Anweisungen, Benutzer und Enthusiasten sind herzlich eingeladen, das Projekt Homepage besuchen: https://github.com/PaddlePaddle/PaddleMIX/tree/develop/paddlemix/ Beispiele/ppdocbee
Einführung in das Programm PP-DocBee
Die Modellstruktur von PP-DocBee ist in der folgenden Abbildung dargestellt, wobei die Architektur von ViT+MLP+LLM verwendet wird. Die Optimierungsideen für Szenarien zum Verstehen von Dokumenten umfassenStrategien zur Datensynthese, Datenvorverarbeitung, Trainingsmethoden und Unterstützung bei der OCR-NachbearbeitungSchließlich ist das Modell in der Lage, sowohl ein allgemeines Dokumentenverständnis als auch ein starkes Parsing von Dokumenten in chinesischen Szenarien durchzuführen.

Aufbau des PP-DocBee-Modells
PP-DocBee enthält insbesondere die folgenden wichtigen Verbesserungen:
1) Strategie der Datensynthese
Um das Problem der unzureichenden chinesischen Sprachkenntnisse und des Mangels an Szenedaten zu lösen, haben wir eine intelligente Lösung für die Produktion von Dokumententypen entwickelt, verschiedene Links zur Datengenerierung für jeden der drei Haupttypen von Datensätzen, wie z. B. Doc, Table, Chart usw., entworfen und zahlreiche Strategien angewandt: Kombination von kleinem OCR-Modell und großem LLM-Modell, Produktion von Bilddaten auf der Grundlage der Rendering-Engine und maßgeschneiderte Datenproduktion für jeden Dokumententyp Abfragevorlagen usw., was zu einer höheren Q&A-Qualität und kontrollierbaren Erstellungskosten führt. Die Einzelheiten sind in der nachstehenden Abbildung dargestellt:
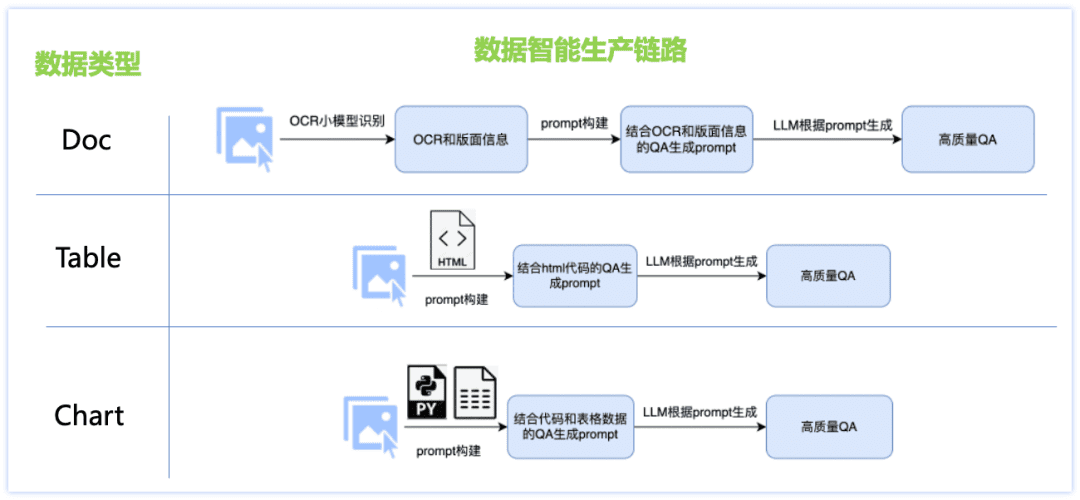
Daten der Dokumentenklasse:
Picture: Sammeln und Organisieren von Papieren, Finanzberichten, Forschungsberichten und anderen PDF-Dateien, kombiniert mit PDF-Analysetools zur Erstellung umfangreicher Bilddaten für einseitige Dokumente;
F&A: Das kleine Modell von ocr extrahiert detaillierte Bild-Layout-Informationen und gleicht so die Unzulänglichkeiten der visuellen Wahrnehmung des großen Modells aus. Gleichzeitig wird die leistungsstarke Textverständnis-Fähigkeit des großen Sprachmodells genutzt, um die Ungenauigkeit der individuellen Zeichenerkennung des kleinen Modells von ocr zu korrigieren, so dass die Kombination der beiden Modelle eine qualitativ hochwertigere und typgesteuerte F&A erzeugen kann.
Daten der Tabellenklasse:
Bild: Basierend auf dem Tabellenbild, das HTML-Textinformationen enthält, ändern Sie den Wert, das Thema und andere Informationen im Text durch das große Sprachmodell und erhalten das inhaltsreiche, qualitativ hochwertige Tabellenbild durch das Tabellenrendering-Tool.
Q&A: der Text im html-Format, der dem Tabellenbild entspricht, wird als GT-Hilfsinformation verwendet, um die Genauigkeit der Antworten zu gewährleisten, und der Entwurf von fein abgestimmten Aufforderungen, um qualitativ hochwertige Q&A durch ein großes Sprachmodell zu produzieren.
Daten der Diagrammklasse:
Bild: Basierend auf den von der Menge getesteten, qualitativ hochwertigen Diagramm-Quelldaten (Bild-Code-Tabelle-Daten), ändern Sie zufällig den numerischen Wert des Diagramms, die Achsen, die Legende, das Thema und andere feinkörnige Informationen im Code durch das große Sprachmodell, und erhalten Sie den Quellcode mit verschiedenen Inhalten, die durch das Diagramm-Rendering-Tool (Matplotlib, Seaborn, Vega-Liteusw.), um qualitativ hochwertige Kartenbilddaten zu erhalten;
Q&A: Der Code, der dem Diagrammbild und den Tabellendaten entspricht, wird als GT-Hilfsinformation verwendet, um die Genauigkeit der Antwort zu gewährleisten, und die entsprechenden Fragetypen werden für verschiedene Arten von Diagrammen entworfen, und die fein abgestimmte Eingabeaufforderung wird entworfen, um hochwertige Q&A durch das große Sprachmodell zu produzieren. Durch das oben beschriebene intelligente Produktionsschema von Dokumentendaten erhalten wir eine riesige Menge an synthetischen Daten und filtern einige von ihnen als Trainingsdaten für PP-DocBee (die Datenverteilung ist in der Abbildung unten dargestellt), wodurch die Modellfähigkeit effektiv verbessert wird.
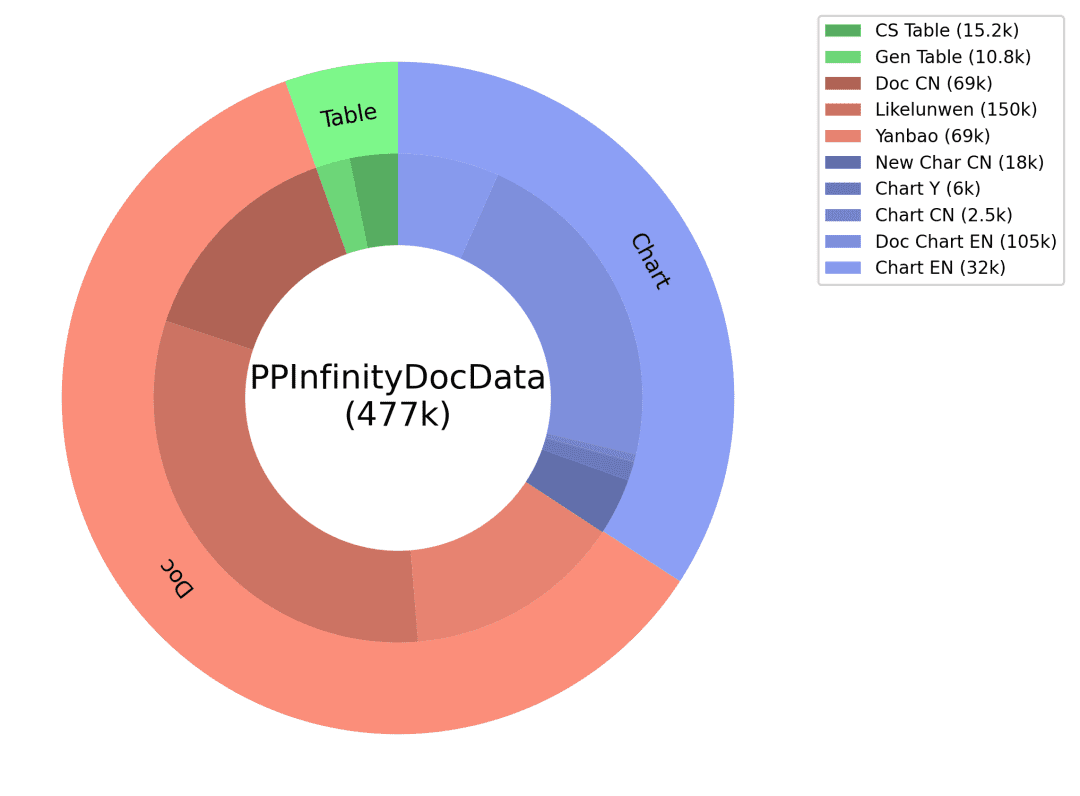
Synthetische Datenverteilung
2. die Vorverarbeitung der Daten
Es werden zwei Strategien verfolgt: Zum einen wird während des Trainings ein größerer Schwellenwert für die Größenänderung festgelegt, um die allgemeine Auflösungsverteilung des Datensatzes zu erhöhen, und zum anderen wird für die meisten regulären Bilder während der Inferenz eine gleichmäßige Vergrößerung um das 1,1- bis 1,3-fache festgelegt, während die ursprüngliche Datenvorverarbeitungsstrategie für Bilder mit geringer Auflösung unverändert bleibt. Diese beiden Strategien führten zu angemesseneren und umfassenderen visuellen Merkmalen, die das endgültige Verständnis verbesserten.
3. die Ausbildungsmethoden
Es handelt sich hauptsächlich um eine Mischung aus verschiedenen Klassen von Daten zum Dokumentenverständnis, und es wurde ein Mechanismus zum Datenabgleich eingerichtet. Zu den verschiedenen Datensätzen gehören die allgemeine VQA-Klasse, die OCR-Klasse, die Diagrammklasse, die Klasse der textreichen Dokumente, die Klasse der mathematischen und komplexen Argumente, die Klasse der synthetischen Daten, die reinen Textdaten usw. Der Datenabgleichsmechanismus besteht darin, Stichprobenverhältnisse für Daten aus verschiedenen Quellen in verschiedenen Klassen und zwischen verschiedenen Klassen festzulegen, um die Stichprobengewichte von Daten mit größeren Gewinnen in mehreren Klassen zu erhöhen und die quantitativen Unterschiede zwischen den verschiedenen Arten von Datensätzen auszugleichen.
4. die Unterstützung bei der OCR-Nachbearbeitung
Vor allem durch die OCR-Tool oder Modell im Voraus zu OCR-Erkennung von Text-Ergebnisse zu erhalten, und dann als Hilfsmittel a priori Informationen in das Bild Quiz-Fragen zur Verfügung gestellt, und dann geben PP-DocBee Modell Argumentation, kann in den Text ist nicht viel und klares Bild hat einige Auswirkungen auf die Verbesserung.
© urheberrechtliche Erklärung
Artikel Copyright AI-Austauschkreis Alle, bitte nicht ohne Erlaubnis vervielfältigen.
Ähnliche Artikel



Keine Kommentare...