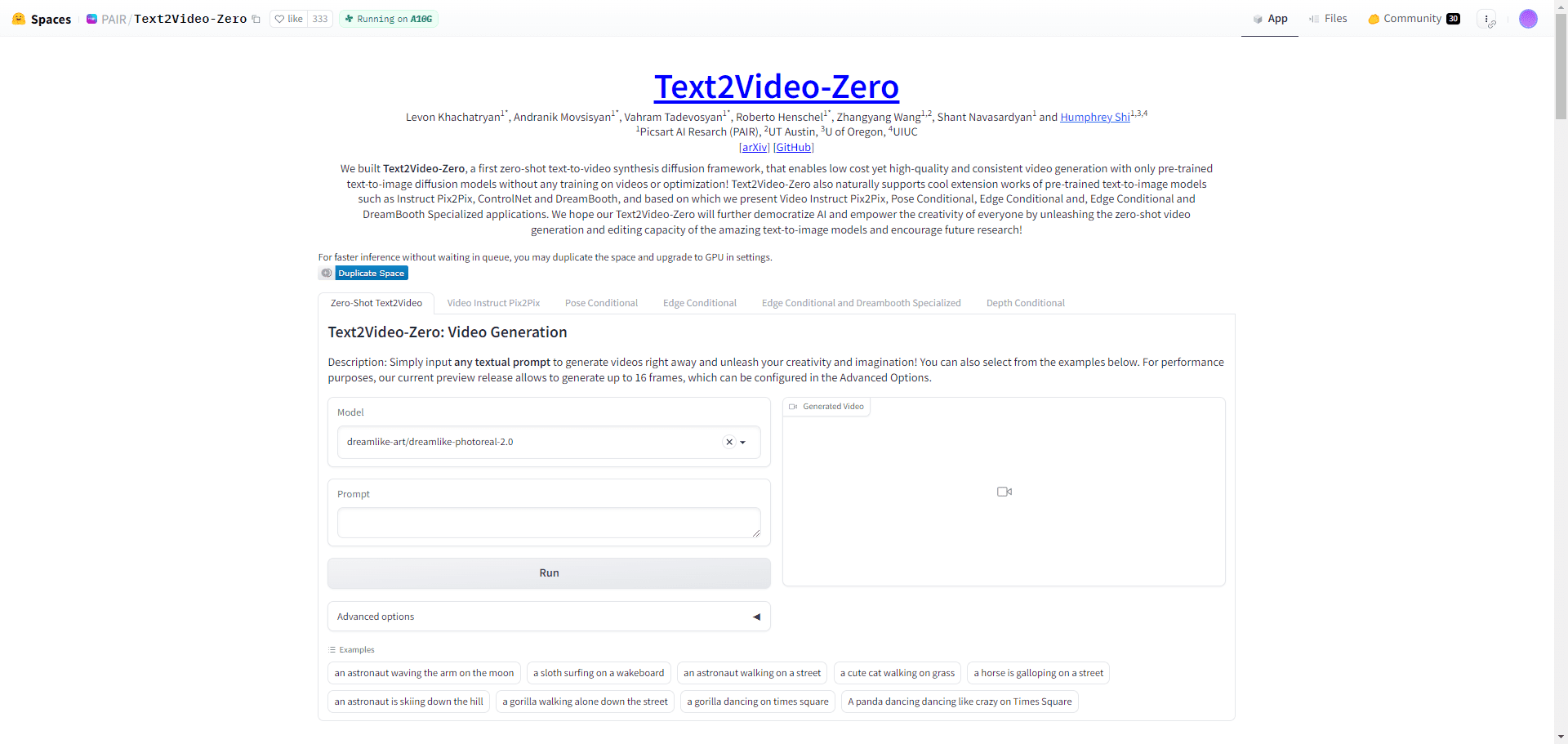
EmotiVoice: Text-to-Speech-Engine mit Multi-Voice- und Emotional Cueing-Steuerung

Allgemeine Einführung
EmotiVoice ist eine von NetEaseYoudao entwickelte Text-to-Speech (TTS) Engine mit mehreren Stimmen und Emotionssteuerung. Diese Open-Source-TTS-Engine unterstützt Englisch und Chinesisch, hat mehr als 2000 verschiedene Stimmen und verfügt über Emotionssynthese-Funktionen, um Stimmen mit mehreren Emotionen wie glücklich, aufgeregt, traurig und wütend zu erstellen. Es bietet eine einfach zu bedienende WEB-Schnittstelle und Batch-Generierung Ergebnisse der Skript-Schnittstelle.
Gehostet unter der Replicate-Demo-Adresse
:多声音与情感提示控制的文本转语音引擎-1")
Funktionsliste
Bereitstellung einer WEB-Schnittstelle und einer Skript-Batch-Verarbeitungsschnittstelle
Unterstützung der Emotionssynthese
Mehrere Soundoptionen
Unterstützt chinesische und englische Synthese
Hilfe verwenden
Schauen Sie sich das GitHub-Repository für die Installation und Gebrauchsanweisungen an
Ausführen eines Docker-Images zum Testen von EmotiVoice
Auf der Wiki-Seite können Sie zusätzliche Informationen herunterladen, z. B. bereits trainierte Modelle.
Treten Sie der WeChat-Gruppe bei, um Feedback auszutauschen
Als Reaktion auf die Nachfrage der Community freuen wir uns, dieFunktion zum Klonen von Tönenund bietet zwei Beispiel-Tutorials!
Anmerkungen.
- Diese Funktion erfordert mindestens eine Nvidia-GPU-Grafik .
- ZieltonDaten sind entscheidend! Detaillierte Anforderungen werden im nächsten Abschnitt beschrieben.
- Derzeit wird diese Funktion nur in Chinesisch und Englisch unterstützt, d. h. Sie können entweder mit chinesischen oder englischen Daten trainieren, umHolen Sie sich ein Timbre-Modell, das zwei Sprachen sprechen kann.
- Obwohl EmotiVoice die emotionale Steuerung unterstützt, müssen die Trainingsdaten ebenfalls emotional sein, wenn Sie möchten, dass Ihre Stimme Emotionen vermittelt.
- Nach dem Training, bei dem nur Ihre Daten verwendet werden, kann das EmotiVoice aus demDer Originalton wird verändert. Dies bedeutet, dass das neue Modell vollständig an Ihre Daten angepasst wird. Wenn Sie die mehr als 2000 Originalstimmen von EmotiVoice verwenden möchten, wird empfohlen, das vortrainierte Originalmodell zu verwenden.
Detaillierte Anforderungen an die Trainingsdaten
- Die Audiodaten sollten von hoher Qualität sein und müssen für die Stimme einer einzelnen Person klar und verzerrungsfrei sein. Die Dauer oder die Anzahl der Sätze ist vorerst nicht vorgeschrieben, ein paar Sätze sind in Ordnung, aber mehr als 100 Sätze werden empfohlen.
- Der Text, der zu jedem Audio gehört, sollte genau mit dem Inhalt der Sprache übereinstimmen. Vor dem Training wird der Rohtext mit G2P in Phoneme umgewandelt. Dabei muss auf Pausen geachtet werden (sp*) und die Ergebnisse der polyphonen Umwandlung haben einen erheblichen Einfluss auf die Qualität der Ausbildung.
- Wenn Sie möchten, dass Ihre Stimme Emotionen vermittelt, müssen die Trainingsdaten ebenfalls emotional sein. Darüber hinaus sollte der Inhalt des **Tags "Prompt "** für jedes Audio geändert werden. Der Inhalt des Prompts kann eine beliebige Form der textlichen Beschreibung der Emotion, der Sprechgeschwindigkeit und des Sprechstils umfassen.
- Dann erhalten Sie eine Datei namens
data directoryVerzeichnis, das zwei Unterverzeichnisse enthält, dastrainim Gesang antwortenvalid. Jedes Unterverzeichnis hat einedatalist.jsonlDatei und jede Zeile ist formatiert:{"key": "LJ002-0020", "wav_path": "data/LJspeech/wavs/LJ002-0020.wav", "speaker": "LJ", "text": ["<sos/eos>", "[IH0]", "[N]", "engsp1", "[EY0]", "[T]", "[IY1]", "[N]", "engsp1", "[TH]", "[ER1]", "[T]", "[IY1]", "[N]", ".", "<sos/eos>"], "original_text": "In 1813", "prompt": "common"}.
Verteilung der Ausbildungsschritte.
Für Chinesisch, siehe DataBaker-RezeptBitte beachten Sie die englische Fassung:LJSpeech-Rezept. Im Folgenden finden Sie eine Zusammenfassung:
- Bereiten Sie die Schulungsumgebung vor - sie muss nur einmal konfiguriert werden.
# create conda enviroment conda create -n EmotiVoice python=3.8 -y conda activate EmotiVoice # then run: pip install EmotiVoice[train] # or git clone https://github.com/netease-youdao/EmotiVoice pip install -e .[train]
- Beratung Detaillierte Anforderungen an die Trainingsdaten Datenaufbereitung durchführen, empfohlene ReferenzbeispieleDataBaker-Rezept im Gesang antworten LJSpeech-RezeptMethoden und Skripte in der
- Führen Sie anschließend den folgenden Befehl aus, um ein Verzeichnis für die Schulung zu erstellen:
python prepare_for_training.py --data_dir <data directory> --exp_dir <experiment directory>. Ersatz<data directory>für den tatsächlichen Pfad des vorbereiteten Datenverzeichnisses.<experiment directory>ist der gewünschte Pfad zum experimentellen Verzeichnis. - Kann je nach Serverkonfiguration und Daten geändert werden
<experiment directory>/config/config.py. Nachdem Sie die Änderungen vorgenommen haben, starten Sie den Trainingsprozess, indem Sie den folgenden Befehl ausführentorchrun --nproc_per_node=1 --master_port 8018 train_am_vocoder_joint.py --config_folder <experiment directory>/config --load_pretrained_model True. (Dieser Befehl startet den Trainingsprozess unter Verwendung des angegebenen Konfigurationsordners und lädt alle angegebenen vortrainierten Modelle). Diese Methode ist derzeit für Linux verfügbar, unter Windows können Probleme auftreten! - Wählen Sie nach Abschluss einiger Trainingsschritte einen Kontrollpunkt und führen Sie den folgenden Befehl aus, um zu bestätigen, dass die Ergebnisse den Erwartungen entsprechen:
python inference_am_vocoder_exp.py --config_folder exp/DataBaker/config --checkpoint g_00010000 --test_file data/inference/text. Vergessen Sie nicht zu änderndata/inference/textDer Inhalt des Lautsprecherfeldes in der Wenn Sie mit dem Ergebnis zufrieden sind, können Sie es gerne verwenden! Eine modifizierte Version der Demoseite wird bereitgestellt: diedemo_page_databaker.pyKommen Sie und erleben Sie die Wirkung des Tons nach dem Klonen mit DataBaker. - Wenn die Ergebnisse nicht zufriedenstellend sind, können Sie das Training fortsetzen oder Ihre Daten und Umgebung überprüfen. Natürlich können Sie auch in der Community darüber diskutieren oder ein Problem einreichen!
Laufzeit-Referenzinformationen.
Wir stellen Ihnen die folgenden Informationen zur Laufzeit und zur Hardwarekonfiguration als Referenz zur Verfügung:
- Pip-Paketversionen: Python 3.8.18, torch 1.13.1, cuda 11.7
- GPU-Kartenmodell: NVIDIA GeForce RTX 3090, NVIDIA A40
- Zeitaufwändiges Training: Es dauert etwa 1-2 Stunden, um 10.000 Schritte zu trainieren.
Es kann sogar ohne eine GPU-Grafikkarte trainiert werden, da nur die CPU verwendet wird. Bitte warten Sie auf die guten Nachrichten!
Adresse für den Download des Installationspakets mit einem Klick
Windows Thunderbolt Cloud-Laufwerk
Ein-Klick-Installationsprogramm für Mac
Das Passwort zum Entpacken lautet jian27 oder jian27.com
© urheberrechtliche Erklärung
Artikel Copyright AI-Austauschkreis Alle, bitte nicht ohne Erlaubnis vervielfältigen.
Ähnliche Artikel

Keine Kommentare...