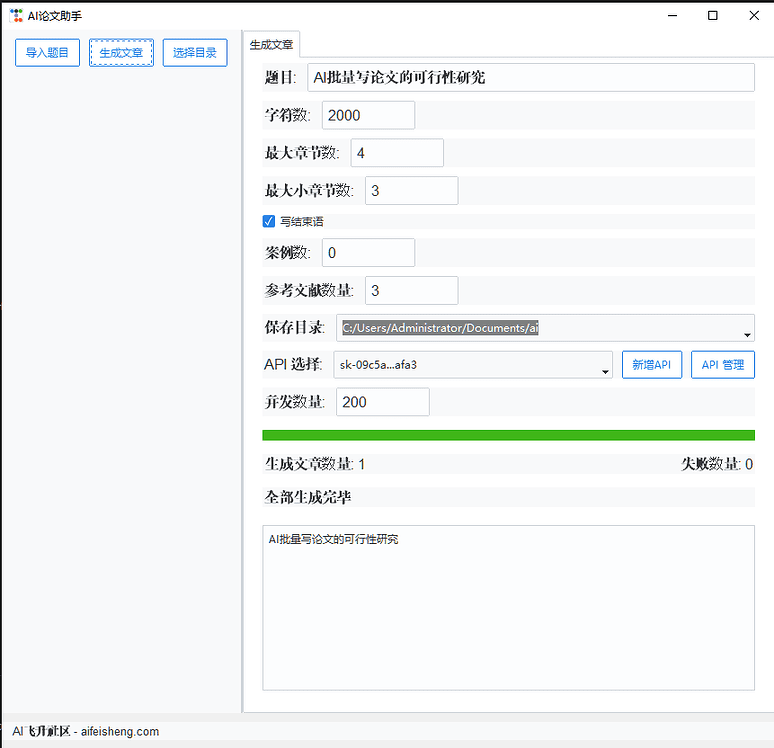
DualPipe: ein bidirektionaler, paralleler Pipeline-Algorithmus zur Verbesserung der Effizienz des Trainings großer KI-Modelle (DeepSeek Open Source Week Day 4)
Allgemeine Einführung
DualPipe ist eine Open-Source-Technologie, die vom DeepSeek-AI-Team mit dem Ziel entwickelt wurde, die Effizienz des Trainings von KI-Modellen in großem Maßstab zu verbessern. Es handelt sich dabei um einen innovativen bidirektionalen, parallelen Pipeline-Algorithmus, der hauptsächlich dazu dient, eine vollständige Überlappung von Berechnung und Kommunikation beim Training von DeepSeek-V3- und R1-Modellen zu erreichen, wodurch "Blasen" (d. h. Wartezeiten) in der Pipeline effektiv reduziert und der Trainingsprozess somit beschleunigt wird. Das von Jiashi Li, Chengqi Deng und Wenfeng Liang entwickelte Projekt wurde auf GitHub veröffentlicht und zieht die Aufmerksamkeit der KI-Gemeinschaft auf sich. Der Hauptvorteil von DualPipe besteht darin, dass das Modelltraining durch optimiertes Scheduling effizient auf Mehrknoten-GPU-Clustern ausgeführt werden kann, wodurch es sich für Billionen-Parameter-Modelltrainingsszenarien eignet und KI-Forschern und -Entwicklern neue Möglichkeiten bietet. DualPipe bietet ein neues paralleles Paradigma für KI-Forscher und -Entwickler.
Funktionsliste
- Bidirektionale Terminplanung in PipelinesUnterstützung der gleichzeitigen Eingabe von Mikrobatches von beiden Enden der Pipeline, was ein hohes Maß an Überlappung zwischen Berechnung und Kommunikation ermöglicht.
- Reduktion von Luftblasen am FließbandReduzierung der Wartezeit während des Trainings durch algorithmische Optimierung.
- Unterstützt umfangreiches ModelltrainingDie neueste Version von DeepSeek-V3 ist die weltweit erste ihrer Art und kann zum Trainieren von Billionen von Parametern für sehr große Modelle wie DeepSeek-V3 verwendet werden.
- Überschneidung von Berechnung und KommunikationParallele Verarbeitung von Berechnungs- und Kommunikationsaufgaben bei Vorwärts- und Rückwärtspropagation zur Verbesserung der GPU-Nutzung.
- Open-Source-UnterstützungEine vollständige Python-Implementierung wird zur Verfügung gestellt, die Entwickler herunterladen, verändern und integrieren können.
Hilfe verwenden
DualPipe ist ein fortschrittliches Tool für Entwickler. Als Open-Source-Projekt auf GitHub verfügt es nicht über eine eigenständige grafische Oberfläche, sondern ist als Codebasis verfügbar. Im Folgenden finden Sie einen detaillierten Leitfaden zur Nutzung, der Entwicklern den schnellen Einstieg und die Integration in ihre KI-Trainingsprojekte erleichtert.
Einbauverfahren
Die Installation von DualPipe erfordert einige grundlegende Python- und Deep-Learning-Umgebungen. Hier sind die Schritte:
- Vorbereitung der Umwelt
- Stellen Sie sicher, dass Python 3.8 oder höher auf Ihrem System installiert ist.
- Installieren Sie Git, um den Code von GitHub herunterzuladen.
- Es wird empfohlen, eine virtuelle Umgebung zu verwenden, um Abhängigkeitskonflikte mit dem folgenden Befehl zu vermeiden:
python -m venv dualpipe_env source dualpipe_env/bin/activate # Linux/Mac dualpipe_env\Scripts\activate # Windows
- Code-Repository klonen
Laden Sie das DualPipe-Repository lokal herunter, indem Sie den folgenden Befehl in das Terminal eingeben:git clone https://github.com/deepseek-ai/DualPipe.git cd DualPipe
- Installation von Abhängigkeiten
DualPipe stützt sich auf gängige Deep-Learning-Bibliotheken. Die spezifischen Abhängigkeiten sind im Repository nicht explizit aufgeführt, aber aufgrund der Funktionalität wird davon ausgegangen, dass es eine Umgebung wie PyTorch benötigt. Sie können mit dem folgenden Befehl versuchen, die Basisabhängigkeiten zu installieren:pip install torch torchvisionWenn Sie eine Fehlermeldung über fehlende Bibliotheken erhalten, folgen Sie den Aufforderungen zur weiteren Installation.
- Überprüfen der Installation
Da es sich bei DualPipe um algorithmischen Code und nicht um eine eigenständige Anwendung handelt, ist es nicht möglich, die Überprüfung direkt durchzuführen. Sie kann jedoch anhand der Codedateien überprüft werden (z. B.dualpipe.py), um zu bestätigen, dass der Download abgeschlossen ist.
Verwendung
Das Herzstück von DualPipe ist ein Scheduling-Algorithmus, den Entwickler in bestehende Modell-Trainings-Frameworks (wie PyTorch oder DeepSpeed) integrieren müssen. So funktioniert er:
1. die Struktur des Codes zu verstehen
- zeigen (eine Eintrittskarte)
DualPipeOrdner, der Hauptcode kann sich im Ordnerdualpipe.pyoder in einem ähnlichen Dokument. - Lesen Sie die Codekommentare und den technischen Bericht zu DeepSeek-V3 (Link in der Beschreibung des GitHub-Repository), um die Algorithmuslogik zu verstehen. Im Bericht werden Beispiele für die DualPipe-Planung erwähnt (z. B. 8 Pipeline-Ebenen und 20 Mikrobatches).
2. die Integration in den Ausbildungsrahmen
- Aufbereitung von Modellen und DatenAngenommen, Sie haben bereits ein PyTorch-basiertes Modell und einen Datensatz.
- Modifizierung des AusbildungszyklusEinbettung der DualPipe-Planungslogik in den Trainingscode. Hier ist ein vereinfachtes Beispiel:
# 伪代码示例 from dualpipe import DualPipeScheduler # 假设模块名 import torch # 初始化模型和数据 model = MyModel().cuda() optimizer = torch.optim.Adam(model.parameters()) data_loader = MyDataLoader() # 初始化 DualPipe 调度器 scheduler = DualPipeScheduler(num_ranks=8, num_micro_batches=20) # 训练循环 for epoch in range(num_epochs): scheduler.schedule(model, data_loader, optimizer) # 调用 DualPipe 调度 - Die Implementierung muss an den tatsächlichen Code angepasst werden, und es wird empfohlen, sich auf die Beispiele im GitHub-Repository zu beziehen (falls vorhanden).
3. die Konfiguration der Hardwareumgebung
- DualPipe ist für Multi-Node-GPU-Cluster konzipiert und wird für die Verwendung mit mindestens 8 GPUs (z. B. NVIDIA H800) empfohlen.
- Stellen Sie sicher, dass der Cluster InfiniBand oder NVLink unterstützt, um die Vorteile der Kommunikationsoptimierung voll auszuschöpfen.
4. die Bedienung und Inbetriebnahme
- Führen Sie das Trainingsskript im Terminal aus:
python train_with_dualpipe.py - Beobachten Sie die Protokollausgabe und prüfen Sie, ob sich die Berechnung und die Kommunikation erfolgreich überschneiden. Wenn es einen Leistungsengpass gibt, passen Sie die Anzahl der Mikrobatches oder die Pipeline-Ebene an.
Featured Function Bedienung
Bidirektionale Terminplanung in Pipelines
- Einstellung in der Konfigurationsdatei oder im Code
num_ranks(Anzahl der Pipeline-Ebenen) undnum_micro_batches(Anzahl der Mikrochargen). - Beispielkonfiguration: 8 Stufen, 20 Mikrochargen, siehe das Planungsdiagramm im technischen Bericht.
Überschneidungen bei der rechnerischen Kommunikation
- Ohne manuelles Eingreifen übernimmt DualPipe automatisch die positiven Berechnungen (z. B.
F) mit der umgekehrten Berechnung (z.B.B) von sich überschneidenden Kommunikationsaufgaben. - Überprüfen Sie die Zeitstempel in den Protokollen, um sicherzustellen, dass die Kommunikationszeit in den Berechnungen nicht enthalten ist.
Reduktion von Luftblasen am Fließband
- Die optimale Konfiguration wurde durch Anpassung der Mikrochargengröße (z. B. von 20 auf 16) und Beobachtung der Veränderung der Trainingszeit gefunden.
caveat
- Hardware-VoraussetzungDualPipe-Vorteile können mit einer einzigen Karte nicht voll genutzt werden, daher wird eine Multi-GPU-Umgebung empfohlen.
- Unterstützung der DokumentationDie GitHub-Seite ist derzeit sehr informationsarm, daher wird empfohlen, sie in Verbindung mit dem technischen Bericht DeepSeek-V3 (arXiv: 2412.19437) eingehend zu studieren.
- Unterstützung der GemeinschaftStellen Sie Fragen auf der GitHub Issues-Seite oder lesen Sie die entsprechenden Diskussionen auf der X-Plattform (z. B. die Beiträge von @deepseek_ai).
Durch die Befolgung dieser Schritte können Entwickler DualPipe in ihre Projekte integrieren und die Effizienz des Modelltrainings in großem Maßstab erheblich verbessern.
© urheberrechtliche Erklärung
Artikel Copyright AI-Austauschkreis Alle, bitte nicht ohne Erlaubnis vervielfältigen.
Ähnliche Artikel


Keine Kommentare...