
Doubao-1.5-pro veröffentlicht: Ein neues multimodales Basismodell für ultimative Balance

Doubao-1.5-pro
🌟 Musterprofil
Doubao-1.5-pro ist eine sehr spärliche MoE ArchitekturIn den vier Quadranten Prefill/Decode und Attention/FFN unterscheiden sich die Berechnungs- und Zugriffsmerkmale erheblich. Für die vier verschiedenen Quadranten setzen wir heterogene Hardware in Kombination mit verschiedenen Optimierungsstrategien für niedrige Genauigkeit ein, um den Durchsatz deutlich zu erhöhen und gleichzeitig eine niedrige Latenz zu gewährleisten und die Gesamtkosten zu senken, wobei die Optimierungsziele von TTFT und TPOT berücksichtigt werden, um das ultimative Gleichgewicht zwischen Leistung und Inferenz-Effizienz zu erreichen.
- kleiner Aktivierungsparameter: übertrifft die Leistung des sehr großen dichten Modells.
- Szenenübergreifende AnpassungHervorragende Leistungen bei mehreren Prüfungsbenchmarks.
📊 Leistungsbewertung
Doubao-1.5-pro Ergebnisse bei mehreren Benchmarks
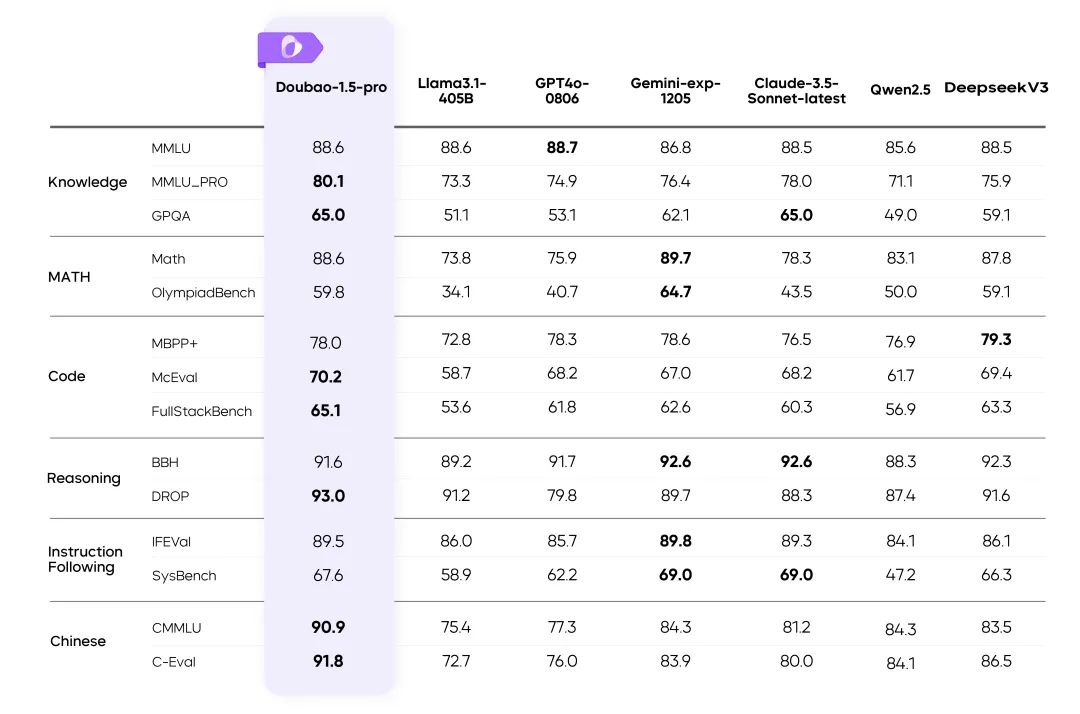
Anweisungen::
- Die Kennzahlen für die übrigen Modelle in der Tabelle stammen aus den offiziellen Ergebnissen, die unveröffentlichten Teile wurden von internen Bewertungsplattformen erstellt.
- GPT4o-0806 Hervorragende Leistung bei öffentlichen Bewertungen von Sprachmodellen, siehe: simple-evals.
⚙️ Gleichgewicht zwischen Leistung und Vernunft
Effiziente MoE-Architektur
- ausnutzen Spärliche MoE-Architektur Zweifache Optimierung der Effizienz der Ausbildung und des Denkens.
- Highlights der ForschungBestimmung des optimalen Verhältnisses zwischen Leistung und Effizienz durch das Sparsity Scaling Law.
Ausbildung Verlust vs.

Leistungsvergleich der Modelle
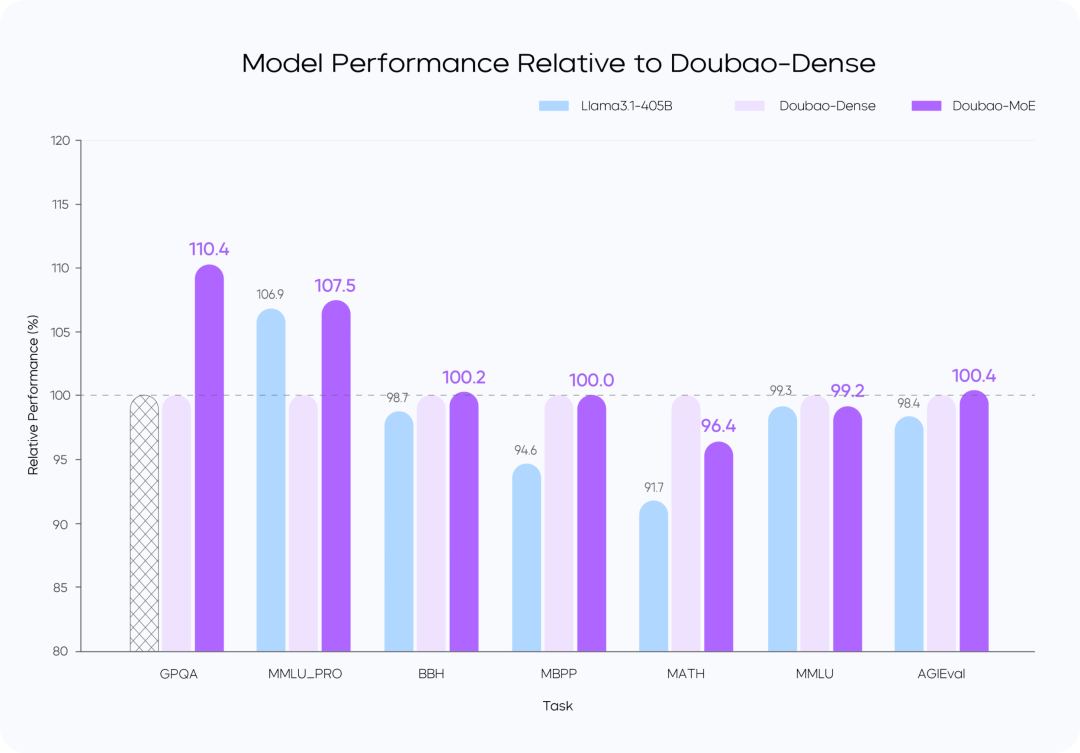
Anweisungen::
- Das Doubao-MoE-Modell übertrifft ein dichtes Modell mit der siebenfachen Anzahl aktivierter Parameter (Doubao-Dense).
- Doubao Dense Model Training ist effizienter als Llama 3.1-405Bsind Datenqualität und Optimierung der Hyperreferenzen entscheidend.
🚀 Leistungsstarke Argumentation
Optimierung der Rechen- und Zugriffsfunktionen
Doubao-1.5-pro schneidet in vier Rechenquadranten gut ab: Prefill, Decode, Attention und FFN.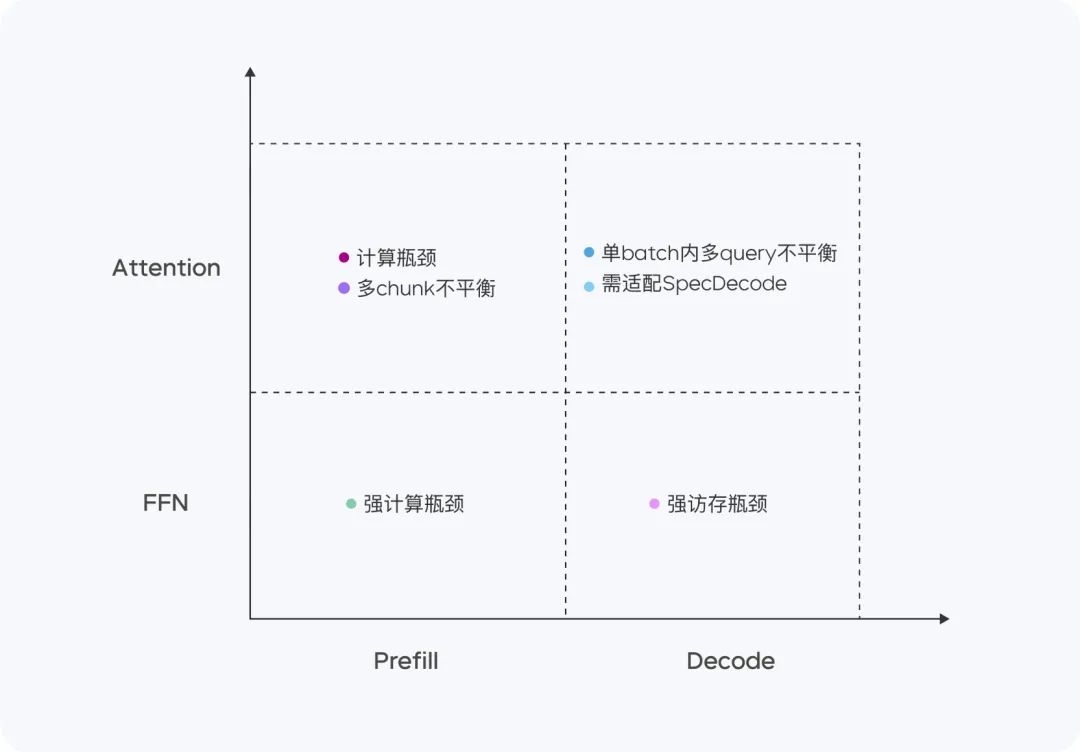
In der Prefill-Phase ist der Kommunikations- und Zugriffsengpass nicht offensichtlich, aber der Berechnungsengpass ist leicht zu erreichen. In Anbetracht der Eigenschaften der einseitigen LLM-Aufmerksamkeit führen wir Chunk-PP Prefill Serving auf mehreren Geräten mit hohen Rechenzugriffsraten durch, so dass die Auslastungsrate des Tensor Core im Online-System nahe bei 60% liegt.
- Prefill Attention: Erweitert die quelloffene 8-Bit-Implementierung von FlashAttention um Anweisungen wie MMA/WGMMA, kombiniert mit Per N Token Die Quantisierungsstrategie pro Sequenz stellt sicher, dass diese Phase verlustfrei auf GPUs unterschiedlicher Architekturen ablaufen kann. Durch die Modellierung des Aufmerksamkeitsverbrauchs von Slices unterschiedlicher Länge und die Kombination mit der dynamischen Cross-Query-Batching-Strategie wird während des Chunk-PP-Servings ein Ausgleich zwischen den Karten erreicht, wodurch die durch ein Lastungleichgewicht verursachten Leerläufe effektiv beseitigt werden;
- Prefill FFN: Die W4A8-Quantisierung reduziert effektiv den Zugriffs-Overhead von spärlichen MoE-Experten und liefert durch die Cross-Query-Batching-Strategie mehr Inputs für die FFN-Phase, wodurch der MFU auf 0,8 verbessert wird.
In der Dekodierungsphase ist der rechnerische Engpass nicht offensichtlich, aber die Kommunikations- und Speicheranforderungen sind relativ hoch. Wir verwenden Serving, ein Gerät mit geringerem Rechen- und Speicherbedarf, um einen höheren ROI zu erzielen. Gleichzeitig verwenden wir eine sehr kostengünstige Abtastung und eine spekulative Decodierungsstrategie, um die TPOT-Metriken zu reduzieren.
- Decode Attention: TP wird eingesetzt, um das häufige Szenario großer Unterschiede in den KV-Längen verschiedener Abfragen innerhalb eines einzigen Stapels durch heuristische Suche und eine aggressive Strategie zur Aufteilung langer Sätze zu optimieren; in Bezug auf die Genauigkeit wird weiterhin die Quantisierung "Pro N Token pro Sequenz" verwendet; außerdem wird die Attention-Berechnung während des Stichprobenverfahrens optimiert, um sicherzustellen, dass nur einmal auf den KV-Cache zugegriffen wird. Zusätzlich wird die Aufmerksamkeitsberechnung während des Zufallsstichprobenverfahrens optimiert, um sicherzustellen, dass nur einmal auf den KV-Cache zugegriffen wird.
- FFN dekodieren: W4A8 quantifiziert halten und mit EP einsetzen.
Insgesamt haben wir die folgenden Optimierungen am PD-getrennten Serving-System vorgenommen:
- Maßgeschneidertes RPC-Backend für die Tensor-Übertragung und optimierte Tensor-Übertragungseffizienz über TCP/RDMA-Netzwerke durch Zero-Copy, Multi-Stream-Parallelität usw., was wiederum die KV-Cache-Übertragungseffizienz unter PD-Trennung verbessert.
- Es unterstützt die flexible Zuweisung und dynamische Erweiterung und Schrumpfung von Prefill- und Decode-Clustern und führt für jede Rolle unabhängig voneinander eine elastische HPA-Erweiterung durch, um sicherzustellen, dass sowohl Prefill als auch Decode keine redundante Arithmetik aufweisen und die arithmetische Zuweisung der beiden Seiten mit dem tatsächlichen Online-Verkehrsmuster übereinstimmt.
- Im Rahmen der GPU-Computing und CPU Pre-und Post-Processing asynchron, so dass die GPU Argumentation Schritt N, wenn die CPU frühen Start der N + 1 Schritt Kernel, um die GPU ist immer voll, den gesamten Rahmen Verarbeitung Aktion der GPU Argumentation Null Overhead. Darüber hinaus mit unseren selbst entwickelten Server-Cluster-Lösung und flexible Unterstützung für Low-Cost-Chips, ist die Hardware-Kosten deutlich niedriger als die Industrie-Lösung. Wir haben auch die Effizienz der Paketkommunikation durch maßgeschneiderte Netzwerkkarten und selbst entwickelte Netzwerkprotokolle erheblich optimiert. Auf der arithmetischen Ebene erreichen wir eine effiziente Überlappung (Overlap) zwischen Berechnung und Kommunikation und gewährleisten so die Stabilität und Effizienz des verteilten Rechnens auf mehreren Computern.
🎯 Datenkennzeichnung: keine Abkürzungen
- Aufbau eines effizienten Datenproduktionssystems, das Folgendes kombiniert Team Etikettierung im Gesang antworten Modellierung von SelbsthebevorgängenDie Qualität der Daten wurde erheblich verbessert.
🖼️ Multimodale Fähigkeiten
Visuelle Multimodalität: Komplexe Szenarien leicht gemacht
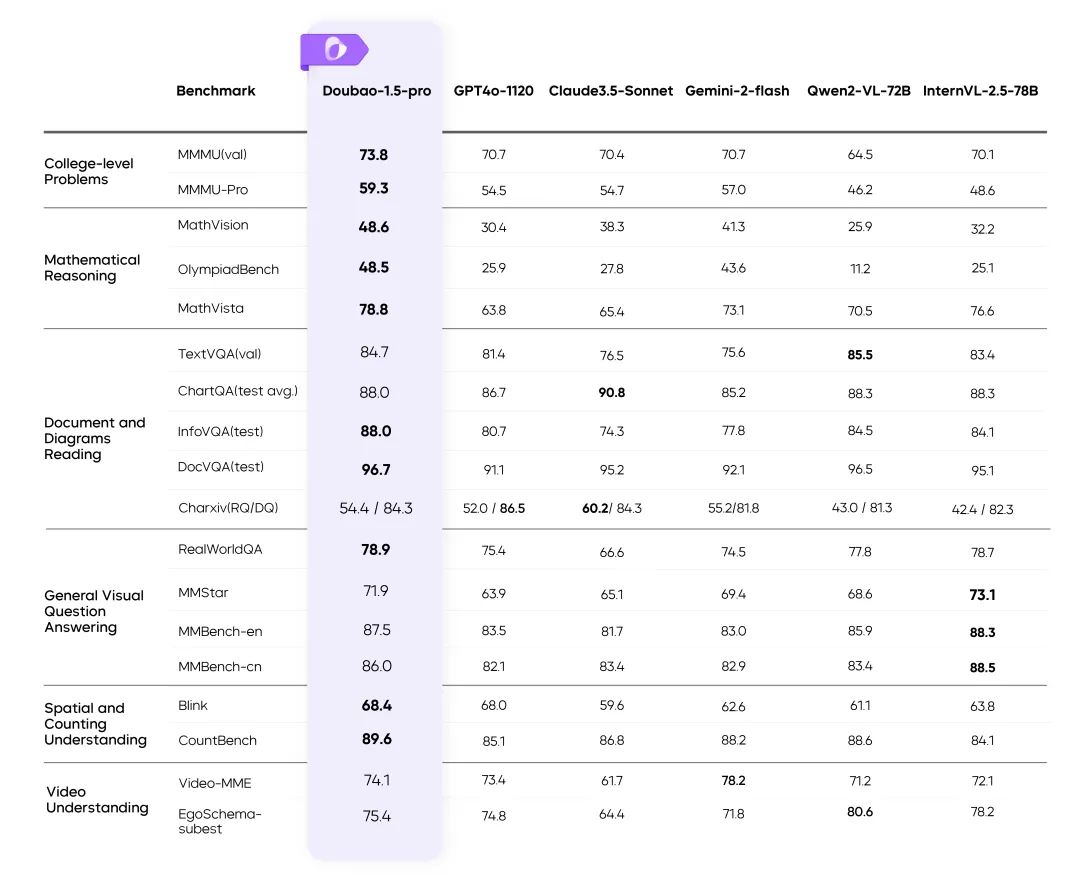
Dynamisches Auflösungstraining: Durchsatzverbesserung 60%
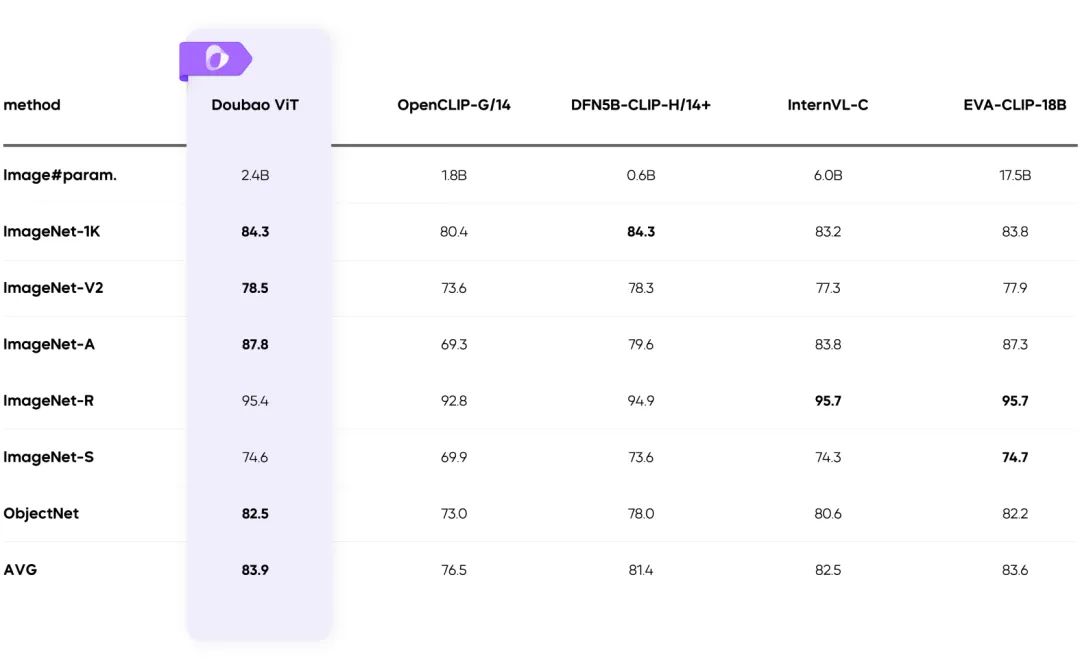
- Lösen Sie das Problem der ungleichmäßigen Belastung des visuellen Encoders und verbessern Sie die Effizienz erheblich.
✅ Zusammenfassung
Doubao-1.5-pro findet ein optimales Gleichgewicht zwischen hoher Leistung und niedrigen Inferenzkosten und erzielt einen Durchbruch in multimodalen Szenarien:
- Innovativer Entwurf einer spärlichen Architektur.
- Hochwertige Trainingsdaten und Optimierungssysteme.
- Neue Maßstäbe in der multimodalen Technologie setzen.
© urheberrechtliche Erklärung
Artikel Copyright AI-Austauschkreis Alle, bitte nicht ohne Erlaubnis vervielfältigen.
Ähnliche Artikel



Keine Kommentare...