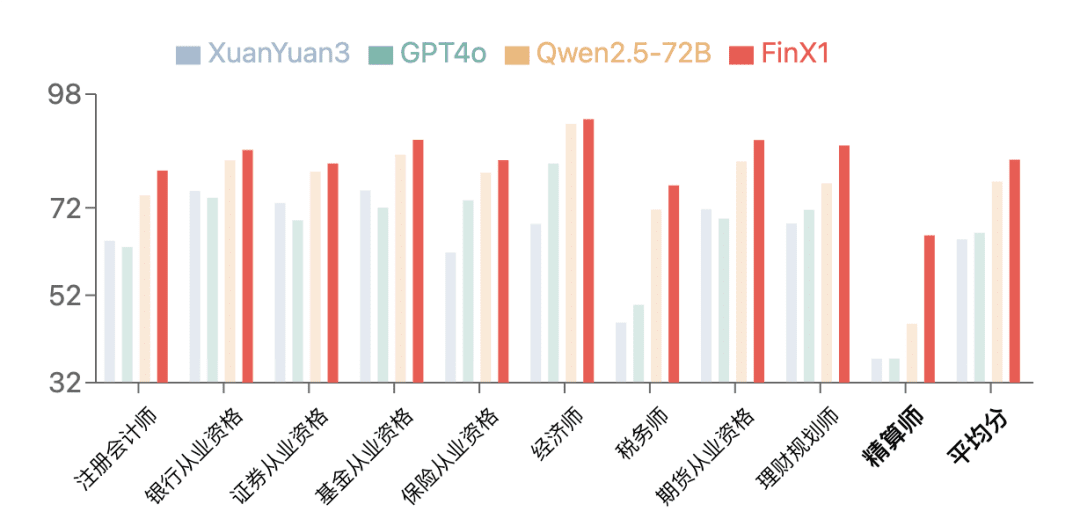
DeepSeek veröffentlicht einheitliche multimodale Verstehens- und generative Modelle: von JanusFlow zu Janus-Pro
JanusFlow Speed Reading
DeepSeek Das Team hat ein weiteres neues Modell veröffentlicht: Janus-Pro, ein innovatives multimodales Framework, wurde in den frühen Morgenstunden des 28. Oktobers vorgestellt. Es handelt sich dabei um ein einheitliches Modell, das in der Lage ist, multimodale Verstehens- und Generierungsaufgaben gleichzeitig zu bewältigen. Das Modell basiert auf der DeepSeek-LLM-1.5b-Basis/DeepSeek-LLM-7b-Basis, unterstützt die Eingabe von 384 x 384 Bildern und verwendet einen speziellen Tokeniser für die Bilderzeugung. Das wichtigste Merkmal ist die Aufteilung der visuellen Kodierung in separate Kanäle unter Beibehaltung eines einzigen Transformator Architektur für die Verarbeitung.
Dieses innovative Design löst nicht nur das Problem der widersprüchlichen Rollen traditioneller Modelle in visuellen Encodern, sondern macht auch das gesamte System flexibler. In der Praxis übertrifft Janus-Pro frühere vereinheitlichte Modelle und konkurriert bei einigen Aufgaben sogar mit speziellen aufgabenbasierten Modellen. Es schlug OpenAIs DALL-E 3 und Stable Diffusion in den Benchmarks GenEval und DPG-Bench.
Die Janus-Modellreihe, die mit dem Modell JanusFlowmit dem Ziel des Aufbaus einerEin einheitlicher Rahmen für multimodales Verstehen und GenerierenDer Kerngedanke ist die Kombination eines autoregressiven Sprachmodells (LLM) mit einem Modell zur Erzeugung eines gleichgerichteten Flusses. Die Kernidee ist die Kombination eines autoregressiven Sprachmodells (LLM) mit einem Modell zur Erzeugung eines gleichgerichteten Flusses, um sowohl ein besseres visuelles Verständnis als auch hochwertige Bilderzeugungsfähigkeiten mit einem einzigen Modell zu erreichen.Janus-Pro Als fortgeschrittene Version von Janus wurde die Leistung des Janus-Modells durch umfassende Optimierungen der Trainingsstrategie, der Datengröße und der Modelldimensionen weiter verbessert und hat in mehreren Benchmark-Tests erhebliche Fortschritte erzielt. In diesem Beitrag wird die Entwicklung des Janus-Modells von JanusFlow zu Janus-Pro systematisch untersucht, wobei der Schwerpunkt auf seinen Merkmalen, Parametern und wichtigsten Verbesserungen liegt.
1) JanusFlow: der Eckpfeiler der einheitlichen Architektur
Papieradresse:: https://arxiv.org/pdf/2411.07975
JanusFlow Die wichtigste Innovation ist dieMinimalistische einheitliche ArchitekturEs integriert das modifizierte Flusserzeugungsmodell nahtlos in den autoregressiven LLM-Rahmen, ohne dass komplexe Änderungen an der LLM-Struktur erforderlich sind. Zu den wichtigsten Merkmalen dieser Architektur gehören:
- Die Erzeugung von Streaming-Bildern wurde korrigiert: JanusFlow verwendet ein modifiziertes Flussmodell für die Bilderzeugung, das von Gaußschem Rauschen ausgeht, iterativ Geschwindigkeitsvektoren vorhersagt, um die latente Raumdarstellung des Bildes zu aktualisieren, und schließlich über einen Decoder hochwertige Bilder erzeugt. Mit diesem Ansatz wird die Einschränkung herkömmlicher Methoden vermieden, bei denen das LLM nur als bedingter Generator fungiert und keine direkte Generierungsfunktion besitzt.
- Entkoppelter visueller Encoder: Um die Leistung des vereinheitlichten Modells zu optimieren, verwendet JanusFlow dieEntkoppelter EncoderStrategie werden separate visuelle Codierer für die Verstehensaufgabe und die Generierungsaufgabe eingesetzt:
- Verstehen von Encodern (fenc): vor-trainiert SigLIP-Groß-Patch/16 Modell, das für die Extraktion semantischer Merkmale von Bildern zuständig ist, um das multimodale Verständnis zu verbessern.
- Erzeugen Sie Encoder (genc) und Decoder (gdec): Kratzertraining ConvNeXt Modul für Bilderzeugungsaufgaben zur Optimierung der Erzeugungsqualität.
- Mechanismen zur Anpassung der Repräsentation: Während des Vereinheitlichungs-Trainingsprozesses führt JanusFlow einZeichenausrichtungMechanismus, der die Zwischendarstellungen der Erzeugungs- und Verstehensmodule aufeinander abstimmt und so die semantische Kohärenz und Konsistenz im Erzeugungsprozess verbessert.
- Eine dreiphasige Ausbildungsstrategie: JanusFlow hat ein fein abgestuftes dreistufiges Schulungsprogramm entwickelt:
- Stufe 1: Zufällige Initialisierung Komponentenanpassung - Die lineare Schicht, der Generator-Encoder und der Decoder werden so trainiert, dass sie mit den vortrainierten LLM- und SigLIP-Encodern als Initialisierungsphase für das weitere Training arbeiten.
- Stufe 2: Harmonisierung der Vorschulung - Trainieren Sie das gesamte Modell mit Ausnahme des visuellen Encoders, indem Sie das multimodale Verständnis, die Bilderzeugung und die reinen Textdaten zusammenführen, um zunächst die vereinheitlichenden Fähigkeiten des Modells zu ermitteln.
- Stufe 3: Überwachung der Feinabstimmung - Die Daten zur Feinabstimmung der Befehle werden verwendet, um das Modell weiter zu trainieren, damit es besser auf Benutzerbefehle reagieren kann, und um die Parameter des SigLIP-Encoders in dieser Phase freizugeben.
Merkmale der Parameter:
- Stiftung LLM: Leichte LLM-Architektur mit 1,3B Parametern.
- Visueller Encoder: SigLIP-Large-Patch/16 (Verstehen), ConvNeXt (Erzeugung von Encodern und Decodern).
- Bildauflösung: 384 × 384 Pixel.
Leistung: JanusFlow erreicht sowohl bei der Text-Bild-Generierung als auch bei multimodalen Verstehensaufgaben eine beachtliche Leistung, die viele Spezialmodelle übertrifft und die Effektivität seiner einheitlichen Architektur beweist.
2) Janus-Pro: eine vollständige Aktualisierung von Daten, Modellen und Strategien
Papieradresse:: https://github.com/deepseek-ai/Janus/blob/main/janus_pro_tech_report.pdf
Janus-Pro Als eine verbesserte Version von Janus wurde JanusFlow in drei Hauptbereichen verbessert:
- Optimierte Ausbildungsstrategien: Janus-Pro optimiert die dreistufige Trainingsstrategie von JanusFlow, um Engpässe bei der Trainingseffizienz und -leistung zu beseitigen:
- Stufe 1: Training des erweiterten ImageNet-Datensatzes - Durch die Erhöhung der Anzahl der Trainingsschritte auf dem ImageNet-Datensatz kann das Modell die Pixelabhängigkeiten umfassender erlernen und so die zugrunde liegenden Fähigkeiten der Bilderzeugung verbessern.
- Stufe 2: Fokus auf Text-zu-Bild-Datentraining - In Trainingsstufe 2 werden die ImageNet-Daten entfernt und der reguläre Text-zu-Bild-Datensatz direkt verwendet, so dass das Modell effizienter lernen kann, qualitativ hochwertige Bilder auf der Grundlage von dichten Textbeschreibungen zu erzeugen.
- Stufe 3: Skalierung der Daten - In der überwachten Feinabstimmungsphase wurde das Verhältnis von multimodalen Verständnisdaten, reinen Textdaten und Text-zu-Bild-Daten feinabgestimmt (von 7:3:10 auf 5:1:4), um die multimodale Verständnisleistung weiter zu verbessern und gleichzeitig die visuelle Generierungsfähigkeit sicherzustellen.
- Erweiterte Trainingsdaten: Janus-Pro skaliert die Größe und Vielfalt der Trainingsdaten drastisch, um die Generalisierungsfähigkeit und Generierungsqualität des Modells zu verbessern:
- Multimodales Verständnis von Daten: In der Pre-Trainingsphase der Stufe 2 wurden etwa 90 Millionen neue Samples hinzugefügt, die ein breiteres Spektrum von Bildbeschriftungsdaten (z.B. YFCC) sowie Tabellen-, Diagramm- und Dokumentverständnisdaten (z.B. Docmatix) abdecken. In Stufe 3 der Feinabstimmung werden weitere Stichproben eingeführt. DeepSeek-VL2 Datensatz sowie MEME-Verständnis, chinesische Dialogdaten usw., was die Dialog- und Multitasking-Fähigkeit des Modells erheblich verbessert.
- Visuell erzeugte Daten: Um die ästhetische Qualität und Stabilität der generierten Bilder zu verbessern, führt Janus-Pro etwa 72 Millionen hochwertige synthetische ästhetische Daten ein und stellt das Verhältnis von realen zu synthetischen Daten auf 1:1 ein. Experimente zeigen, dass die Hinzufügung synthetischer Daten die Konvergenz des Modells beschleunigt und die ästhetische Qualität und Stabilität der generierten Bilder deutlich verbessert.
- Erweiterte Modellgröße: Janus-Pro behält nicht nur das 1,5B-Parametermodell von JanusFlow bei, sondern erweitert es auch um die 7B Parameterund bietet Janus-Pro-Serie in den Modellgrößen 1,5B und 7B.Die experimentellen Ergebnisse zeigen, dass die größere LLM die Leistung des Modells erheblich verbessern und die Konvergenzgeschwindigkeit beschleunigen kann. Die experimentellen Ergebnisse zeigen, dass LLMs in größerem Maßstab die Leistung des Modells erheblich verbessern und die Konvergenzgeschwindigkeit beschleunigen können, was die Skalierbarkeit der Janus-Modellarchitektur bestätigt.
Merkmale der Parameter:
- Abmessungen des Modells: Erhältlich in den Modellgrößen 1,5B und 7B.
- Architektur: Folgt der entkoppelten visuellen Codierer-Architektur von JanusFlow.
- Trainingsdaten: Erheblich erweiterte und optimierte Trainingsdaten für multimodales Verstehen und visuelle Generierung.
- Bildauflösung: Die in den Experimenten verwendete Bildauflösung betrug weiterhin 384 × 384 Pixel.
Leistung: Janus-Pro demonstrierte die Effektivität der Daten-, Modell- und Strategie-Upgrades durch signifikante Leistungssteigerungen in allen Benchmarks, insbesondere im multimodalen Verständnis-Benchmark MMBench und den Text-zu-Bild-Generierungs-Benchmarks GenEval und DPG-Bench, die beide JanusFlow und andere fortgeschrittene vereinheitlichte und spezialisierte Modelle übertrafen.
3.Janus reale Anwendungsszenarien
Funktionen des visuellen Verständnisses:
- Bildbeschreibung/Beschriftung.
- Detaillierte Szenenbeschreibung: Kann eine detaillierte Textbeschreibung entsprechend dem Bildinhalt erstellen, einschließlich Szenenelemente, Objekte, Umgebungsatmosphäre usw.. (Beispiel: Beschreibung der Drei Teiche des Westsees, der Küstenlandschaft usw.)
- Grafische Beschreibung: In der Lage sein, Informationen in Grafiken und Diagrammen zu verstehen und zu beschreiben, wie z. B. die Darstellung von Daten und die Trendanalyse von Balkendiagrammen. (Beispiel: Interpretation des Balkendiagramms "Lieblingsfrüchte der Kinder")
- Objekterkennung/Klassifizierung.
- Arten von Objekten in einem Bild identifizieren: In der Lage sein, Kategorien von Objekten, die in einem Bild erscheinen, zu identifizieren und aufzulisten. (Beispiel: Identifizierung der Obstsorte auf einem Bild)
- Zählen von Objekten.
- Genaues Zählen der Anzahl der Objekte in einem Bild: Fähigkeit, die Anzahl bestimmter Objekte in einem Bild genau zu zählen. (Beispiel: Zählen Sie die Anzahl der Pinguine auf dem Bild)
- Meilenstein-Anerkennung.
- Berühmte Wahrzeichen in Bildern identifizieren: In der Lage sein, Wahrzeichen oder Orte zu identifizieren, die in einem Bild erscheinen. (Beispiel: Identifizieren Sie die drei Pools des Westsees)
- Texterkennung/OCR.
- Erkennen von Textinhalten in Bildern: In der Lage sein, Text auf einem Bild zu erkennen und Textinformationen zu extrahieren. (Beispiel: Erkennen von "Serving Soul since Twenty Twelve" auf einer Tafel)
- Visuelle Fragebeantwortung.
- Beantwortung von Fragen auf der Grundlage des Bildinhalts: In der Lage sein, den Inhalt eines Bildes zu verstehen und eine angemessene Antwort auf die Frage des Nutzers zu geben. (Beispiel: Frage "Welche Frucht ist auf dem Bild?" als Antwort auf ein Bild).
- Visual Reasoning/Wissensintegration.
- Die Bedeutungen und Assoziationen hinter Bildern verstehen: In der Lage sein, visuell auf einer tieferen Ebene zu argumentieren und Wissen in einen Kontext zu stellen. (Beispiele: den Humor des Hundebildes der Mona Lisa erklären, den Cartoon-Kontext der Torte verstehen)
- Code-Generierung (Python für Plotting).
- Generieren von Code auf der Grundlage von Benutzerbefehlen: Verstehen Sie die Benutzeranforderungen für die Erstellung von Diagrammen und generieren Sie entsprechend Python-Code. (Beispiel: Generieren von Python-Code zum Zeichnen eines Balkendiagramms)
Funktion zur Erzeugung von Text in Bild:
- Textgestützte Bilderzeugung.
- Generierung von Bildern auf der Grundlage von Textbeschreibungen: Kann semantisch verwandte Bilder auf der Grundlage von Texteingaben des Benutzers generieren.
- Kreative Bilderzeugung: Fähigkeit, abstrakte und phantasievolle Textaufforderungen zu verstehen, um kreative und künstlerische Bilder zu erzeugen. (Beispiele: fliegender Wal, kosmischer Nebel-Corgi usw.)
- Stilisierte Bilderzeugung: Erzeugen Sie Bilder mit einem bestimmten künstlerischen Stil auf der Grundlage der Stilbeschreibung in den Textaufforderungen. (Beispiele: Kirche im Renaissance-Stil, Bergdorf im Stil chinesischer Tuschemalerei usw.)
- Einfache Texterzeugung auf Bildern: Möglichkeit, Bilder mit einfachen Textelementen zu erzeugen. (Beispiel: "Hallo" auf eine Tafel schreiben)
Beispiele für praktische Anwendungsszenarien:
- Intelligenter Assistent: fungiert als multimodaler intelligenter Assistent, der vom Benutzer hochgeladene Bilder versteht und Fragen und Antworten, Beschreibungen, Analysen usw. durchführt.
- Inhaltserstellung: Unterstützen Sie Inhaltsersteller bei der schnellen Erstellung von hochwertigem Bildmaterial, z. B. Grafiken für soziale Medien, Artikelillustrationen und mehr.
- Anwendungen im Bildungsbereich: Für den Unterricht zur Bilderkennung, zur Interpretation von Diagrammen usw., um Schülern das Verständnis visueller Informationen zu erleichtern.
- Information Retrieval: Bietet umfassendere Suchergebnisse durch Bildsuche in Kombination mit Textverständnis und -generierung.
- Künstlerisches Schaffen: Als kreatives Werkzeug hilft es Künstlern, Bilder zu schaffen und neue Formen des visuellen Ausdrucks zu erkunden.
Zu beachtende Parametermerkmale und Einschränkungen:
- Einschränkungen bei der Bildauflösung: Die derzeitige Modellschulung und -prüfung basiert hauptsächlich auf Bildern mit einer Auflösung von 384x384 Pixeln, was bei Szenarien, die eine höhere Auflösung erfordern, zu Einschränkungen führen kann.
- Detailgenauigkeit: Obwohl das Bild semantisch reichhaltig ist, kann die Detailgenauigkeit aufgrund der Auflösungs- und Rekonstruktionsverluste des Vision Tokenizers noch verbessert werden, z. B. sind kleine Gesichtsbereiche möglicherweise nicht fein genug.
4) Zusammenfassung und Ausblick
Die Janus-Modellfamilie, von JanusFlow bis Janus-Pro, zeigt das Potenzial für weitere Durchbrüche im Bereich des einheitlichen multimodalen Verstehens und Erzeugens: Während JanusFlow den Grundstein für eine einheitliche Architektur legte, liefert Janus-Pro einen Quantensprung in der Leistung durch optimierte Trainingsstrategien, Daten-Skalierung und Modellgrößen-Upgrades.Der Erfolg von Janus-Pro Der Erfolg von Janus-Pro bestätigtDatengesteuerte und Modellerweiterungen sind der Schlüssel zur Verbesserung der Leistung von einheitlichen ModellenDie Weiterentwicklung der Janus-Modellfamilie treibt nicht nur den Fortschritt der multimodalen Modelle voran, sondern schafft auch eine solide Grundlage für den Aufbau vielseitiger und intelligenter KI-Systeme.
Vollständiges Papier "Janus-Pro: Ein einheitliches multimodales Verstehens- und Generativmodell, ermöglicht durch Daten- und Modellerweiterungen
AutorXiaokang Chen, Zhiyu Wu, Xingchao Liu, Zizheng Pan, Wen Liu, Zhenda Xie, Xingkai Yu, Chong Ruan
Projektseite: https://github.com/deepseek-ai/Janus
Abstracts
In dieser Arbeit stellen wir Janus-Pro vor, eine verbesserte Version des früheren Janus-Modells. Insbesondere integriert Janus-Pro (1) eine optimierte Trainingsstrategie, (2) erweiterte Trainingsdaten und (3) die Skalierung auf größere Modellgrößen. Mit diesen Verbesserungen macht Janus-Pro signifikante Fortschritte beim multimodalen Verstehen und bei der Befehlsverfolgung von textgenerierten Bildern, während gleichzeitig die Stabilität von textgenerierten Bildern verbessert wird. Wir hoffen, dass diese Arbeit zu weiteren Forschungen in diesem Bereich anregen wird. Der Code und das Modell sind öffentlich zugänglich.
1. einleitung

(a) Durchschnittliche Leistung bei vier multimodalen Verstehensbenchmarks. (b) Leistung der Text-zu-Bild-Instruktion im Anschluss an den Benchmark.
Abbildung 1 | Ergebnisse für multimodales Verstehen und visuelle Generierung für Janus-Pro. Für das multimodale Verstehen haben wir die Genauigkeit von POPE, MME-Perception, GQA und MMMU gemittelt. Die Punktzahl für MME-Perception wurde durch 20 geteilt, um den Bereich [0, 100] zu erreichen. Für die visuelle Generierung haben wir die Leistung der GenEval- und DPG-Bench-Benchmarks für die Befolgung von Befehlen bewertet. Insgesamt übertrifft Janus-Pro sowohl frühere vereinheitlichte multimodale Modelle auf dem Stand der Technik als auch einige aufgabenspezifische Modelle. Die besten Ergebnisse wurden bei der Betrachtung auf dem Bildschirm erzielt.

1. ein einfaches Foto einer orangefarbenen Mandarine 2. eine saubere Tafel mit grüner Oberfläche und dem Wort "Hallo", das präzise und deutlich mit weißer Kreide geschrieben ist 3. eine Nahaufnahme einer Sonnenblume, die Wohlstand symbolisiert, mit grünen Stängeln und Blättern, Blütenblättern in voller Blüte und einer Biene, die sich darauf ausruht und deren Flügel im Sonnenlicht glitzern.
Abbildung 2 | Vergleich der textgenerierten Bilder von Janus-Pro und seinem Vorgänger Janus. Janus-Pro bietet eine konsistentere Ausgabe für kurze Prompts, mit höherer visueller Qualität, mehr Details und der Möglichkeit, einfachen Text zu generieren. Die Bildauflösung beträgt 384x384 und ist am besten auf einem Bildschirm zu sehen.
In letzter Zeit wurden erhebliche Fortschritte bei der Vereinheitlichung von multimodalem Verständnis und generativen Modellen erzielt [30, 40, 45, 46, 48, 50, 54, 55]. Es hat sich gezeigt, dass diese Ansätze die Befolgung von Anweisungen bei visuellen Generierungsaufgaben verbessern und gleichzeitig die Modellredundanz reduzieren. Die meisten dieser Ansätze verwenden denselben visuellen Codierer, um die Eingaben sowohl für multimodale Verstehens- als auch für Generierungsaufgaben zu verarbeiten. Dies führt in der Regel zu einer schlechten Leistung beim multimodalen Verstehen, da für die beiden Aufgaben unterschiedliche Darstellungen erforderlich sind. Um dieses Problem zu lösen, schlug Janus [46] eine entkoppelte visuelle Kodierung vor, die den Konflikt zwischen den multimodalen Verstehens- und Generierungsaufgaben entschärft und bei beiden Aufgaben hervorragende Leistungen erzielt.
Als Pioniermodell wurde Janus auf der 1B-Parameter-Skala validiert. Aufgrund der begrenzten Trainingsdaten und der relativ kleinen Modellkapazität weist es jedoch mehrere Nachteile auf, wie z. B. eine schlechte Leistung bei der Erzeugung von Bildern mit kurzen Stichwörtern und eine uneinheitliche Qualität der textgenerierten Bilder. In diesem Beitrag stellen wir Janus-Pro vor, eine verbesserte Version von Janus, die drei Aspekte verbessert: Trainingsstrategie, Daten und Modellgröße. Die Janus-Pro-Familie besteht aus zwei Modellgrößen: 1B und 7B, was die Skalierbarkeit der visuellen Kodierungs-Dekodierungsmethode demonstriert.
Wir haben Janus-Pro in mehreren Benchmarks evaluiert, und die Ergebnisse zeigen ein überragendes multimodales Verständnis und eine deutlich verbesserte Leistung bei der Befolgung von textgenerierten Bildanweisungen. Insbesondere erreicht Janus-Pro-7B eine Punktzahl von 79,2 bei dem multimodalen Verständnis-Benchmark MMBench [29] und übertrifft damit frühere, dem Stand der Technik entsprechende einheitliche multimodale Modelle wie Janus [46] (69,4), TokenFlow [34] (68,9) und MetaMorph [42] (75,2). Darüber hinaus erreicht Janus-Pro-7B eine Punktzahl von 0,80 in der Richtlinie Text-zu-Bildern-Generierung nach dem Leaderboard GenEval [14] und übertrifft damit Janus [46] (0,61), DALL-E 3 (0,67) und Stable Diffusion 3 Medium [11] (0,74).

Abbildung 3 | Architektur von Janus-Pro. Wir entkoppeln visuelle Kodierung für multimodales Verstehen und visuelle Erzeugung. "Und. Encoder" und "Gen. Encoder" sind Abkürzungen für "Understanding Encoder" bzw. "Generation Encoder". "Und. Encoder" und "Gen. Encoder" sind Abkürzungen für "Understanding Encoder" bzw. "Generation Encoder". Am besten auf dem Bildschirm zu sehen.
2. die Methodik
2.1.
Die Architektur von Janus-Pro ist in Abbildung 3 dargestellt und entspricht derjenigen von Janus [46]. Das Kernprinzip der Gesamtarchitektur ist die Entkopplung der visuellen Kodierung für multimodales Verstehen und Generieren. Wir verwenden unabhängige Kodierungsmethoden, um rohe Eingaben in Merkmale umzuwandeln, die dann von einem einheitlichen autoregressiven Transformator verarbeitet werden. Für das multimodale Verstehen verwenden wir den SigLIP [53] Encoder, um hochdimensionale semantische Merkmale aus Bildern zu extrahieren. Diese Merkmale werden von einem 2-D-Netz auf eine 1-D-Sequenz verteilt, und diese Bildmerkmale werden mithilfe eines Verstehensadapters auf den Eingaberaum des LLMs abgebildet. Für die visuelle Generierungsaufgabe verwenden wir den VQ-Tagger aus [38], um Bilder in diskrete IDs umzuwandeln. Nach der Abflachung der ID-Sequenzen auf 1-D verwenden wir einen generativen Adapter, um die Codebook-Einbettungen, die jeder ID entsprechen, auf den Eingaberaum des LLM zu übertragen. Anschließend verketten wir diese Merkmalssequenzen zu einer multimodalen Merkmalssequenz, die anschließend in den LLM zur Verarbeitung eingespeist wird. Zusätzlich zum eingebauten Vorhersagekopf im LLM verwenden wir einen zufällig initialisierten Vorhersagekopf für die Bildvorhersage bei visuellen Generierungsaufgaben. Das gesamte Modell folgt einem autoregressiven Rahmen.
2.2 Optimierte Ausbildungsstrategien
Die vorherige Version von Janus verwendete einen dreistufigen Trainingsprozess. Die erste Stufe konzentriert sich auf das Training von Adaptern und Bildköpfen. Die zweite Phase befasste sich mit dem einheitlichen Pre-Training, bei dem alle Komponenten mit Ausnahme des Verständnis-Encoders und des Generierungs-Encoders ihre Parameter aktualisieren. Die dritte Phase ist die überwachte Feinabstimmung, die auf der zweiten Phase aufbaut, indem die Parameter des Verstehens-Encoders während des Trainingsprozesses weiter freigeschaltet werden. Es gibt einige Probleme mit dieser Trainingsstrategie. In der zweiten Phase teilt Janus das Training der Text-zu-Bild-Fähigkeit in Anlehnung an PixArt [4] in zwei Teile auf. Der erste Teil wurde mit ImageNet [9] Daten trainiert, wobei die Namen der Bildkategorien als Hinweise für textgenerierte Bilder verwendet wurden, mit dem Ziel, Pixelabhängigkeiten zu modellieren. Der zweite Teil wurde mit einfachen textgenerierten Bilddaten trainiert. Bei der Implementierung wurden 66,67% der textgenerierten Bildtrainingsschritte in der zweiten Phase dem ersten Teil zugewiesen. Bei weiteren Experimenten stellte sich jedoch heraus, dass diese Strategie suboptimal ist und zu erheblichen rechnerischen Ineffizienzen führt.
Um dieses Problem zu lösen, wurden zwei Änderungen vorgenommen.
- Längere Ausbildung in der ersten PhaseWir haben eine erste Trainingsstufe hinzugefügt, die ein vollständiges Training auf dem ImageNet-Datensatz ermöglicht. Unsere Ergebnisse zeigen, dass das Modell selbst mit festen LLM-Parametern Pixelabhängigkeiten effektiv modellieren und sinnvolle Bilder auf der Grundlage von Kategorienamen erzeugen kann.
- Phase II: gezielte AusbildungIn der zweiten Phase haben wir die ImageNet-Daten aufgegeben und direkt einfache textgenerierte Bilddaten verwendet, um das Modell für die Generierung von Bildern auf der Grundlage von dichten Beschreibungen zu trainieren. Dieser neu gestaltete Ansatz ermöglicht es der zweiten Phase, textgenerierte Bilddaten effektiver zu nutzen und so die Trainingseffizienz und die Gesamtleistung zu verbessern.
In der dritten Stufe des überwachten Feinabstimmungsprozesses passten wir auch die Datenverhältnisse der verschiedenen Arten von Datensätzen an, indem wir das Verhältnis von multimodalen Daten, reinen Textdaten und textgenerierten Bilddaten von 7:3:10 auf 5:1:4 änderten. Durch die leichte Verringerung des Verhältnisses von textgenerierten Bilddaten konnten wir feststellen, dass diese Anpassung eine verbesserte multimodale Verständnisleistung bei gleichzeitiger Beibehaltung starker visueller Generierungsfähigkeiten ermöglichte.
2.3 Datenerweiterungen
Wir erweitern die Trainingsdaten, die Janus für das multimodale Verstehen und die Erzeugung von Visionen verwendet.
- multimodales VerständnisFür die zweite Stufe der Pre-Trainingsdaten beziehen wir uns auf DeepSeekVL2 [49] und fügen etwa 90 Millionen Proben hinzu. Dazu gehören Bildbeschriftungsdatensätze (z. B. YFCC [31]) sowie Daten für das Verstehen von Tabellen, Diagrammen und Dokumenten (z. B. Docmatix [20]). Für die dritte Stufe der überwachten Feinabstimmung haben wir zusätzliche Datensätze aus DeepSeek-VL2 hinzugefügt, wie z. B. MEME-Verständnis, chinesische Dialogdaten und Datensätze, die das Dialogerlebnis verbessern sollen. Diese Ergänzungen erweitern die Fähigkeiten des Modells beträchtlich und bereichern seine Fähigkeit, eine Vielzahl von Aufgaben zu bewältigen und gleichzeitig das allgemeine Dialogerlebnis zu verbessern.
- visuelle ProduktionWir haben festgestellt, dass die realen Daten, die in der vorherigen Version von Janus verwendet wurden, von mangelhafter Qualität waren und erhebliches Rauschen enthielten, was typischerweise zu instabilen textgenerierten Bildern führte, die eine ästhetisch schlechte Ausgabe zur Folge hatten. In Janus-Pro haben wir ca. 72 Millionen synthetische, ästhetische Datenproben eingefügt, um das Verhältnis von realen zu synthetischen Daten in der einheitlichen Pre-Trainingsphase auf 1:1 zu bringen.Hinweise für diese synthetischen Datenproben sind öffentlich verfügbar, wie z.B. in [43]. Experimente haben gezeigt, dass das Modell beim Training auf synthetischen Daten schneller konvergiert und nicht nur eine stabilere textgenerierte Bildausgabe, sondern auch eine deutlich bessere ästhetische Qualität erzeugt.
2.4 Erweiterungen des Modells
Eine frühere Version von Janus überprüfte die Effektivität der Verwendung des 1.5B LLM für die visuelle Kodierungsentkopplung. In Janus-Pro haben wir das Modell auf 7B erweitert, und die Hyperparameter der 1.5B und 7B LLMs sind in Tabelle 1 detailliert aufgeführt. Wir beobachteten eine signifikante Erhöhung der Konvergenzgeschwindigkeit des multimodalen Verstehens und des visuellen Generierungsverlustes bei Verwendung größerer LLMs im Vergleich zu kleineren Modellen. Dieses Ergebnis bestätigt die robuste Skalierbarkeit dieses Ansatzes.
Tabelle 1 | Konfiguration der Architektur von Janus-Pro. Wir listen die Hyperparameter der Architektur auf.
| Janus-Pro-1B | Janus-Pro-7B | |
| Umfang des Wortschatzes | 100K | 100K |
| Größe einbetten | 2048 | 4096 |
| Kontextfenster | 4096 | 4096 |
| Aufmerksamkeitsspanne | 16 | 32 |
| Stockwerk | 24 | 30 |
Tabelle 2 Detaillierte Hyperparameter für das Janus-Pro-Training. Das Datenverhältnis bezieht sich auf das Verhältnis von multimodalen Verstehensdaten, reinen Textdaten und visuell generierten Daten.

3 Experimente
3.1 Einzelheiten der Durchführung
In unseren Experimenten verwenden wir DeepSeek-LLM (1.5B und 7B) [3] als Basissprachmodell mit einer maximal unterstützten Sequenzlänge von 4096. Für den visuellen Kodierer, der in der Verstehensaufgabe verwendet wird, haben wir SigLIP-Large-Patch16-384 [53] gewählt. Der Generierungskodierer hat ein Codebuch der Größe 16.384 und tastet das Bild 16 Mal ab. Sowohl der Verstehensadapter als auch der Generierungsadapter sind zweischichtige MLPs. Die detaillierten Hyperparameter für jede Stufe sind in Tabelle 2 angegeben. Alle Bilder wurden auf 384x384 Pixel verkleinert. Bei multimodalen Verständnisdaten wird die lange Seite des Bildes auf 384 verkleinert und die kurze Seite mit der Hintergrundfarbe (RGB: 127, 127, 127) gefüllt, um 384 zu erreichen. Bei visuellen Generierungsdaten wird die kurze Seite auf 384 verkleinert und die lange Seite auf 384 beschnitten. um die Trainingseffizienz zu verbessern, verwenden wir während des Trainings Sequence Packing. Wir mischen alle Datentypen nach bestimmten Verhältnissen in einem einzigen Trainingsschritt. Unser Janus wird mit HAI-LLM [15] trainiert und evaluiert, einem leichtgewichtigen und effizienten verteilten Trainingssystem, das auf PyTorch aufbaut. Der gesamte Trainingsprozess dauerte etwa 7/14 Tage auf einem 16/32-Knoten-Cluster, der mit 8 Nvidia A100 (40GB) GPUs für 1,5B/7B Modelle ausgestattet war.
3.2 Bewertung der Einstellungen
Multimodales Verstehen: Um das multimodale Verstehen zu evaluieren, haben wir unser Modell mit weithin anerkannten bildbasierten visuell-verbalen Benchmarks wie GQA [17], POPE [23], MME [12], SEED [21], MMB [29], MM-Vet [51] und MMMU [52] getestet.
Tabelle 3 | Vergleich mit dem Stand der Technik beim Benchmarking des multimodalen Verstehens. "Und." und "Gen." stehen für "Verstehen" bzw. "Generieren". Modelle, die externe vortrainierte Diffusionsmodelle verwenden, sind mit † gekennzeichnet.

Visuelle Erzeugung: Um die Fähigkeiten der visuellen Generierung zu bewerten, haben wir GenEval [14] und DPG-Bench [16] verwendet.GenEval ist ein anspruchsvoller Bild-zu-Text-Generierungs-Benchmark, der entwickelt wurde, um die vollen generativen Fähigkeiten eines visuellen Generierungsmodells durch eine detaillierte Analyse seiner kombinatorischen Fähigkeiten auf Instanzebene widerzuspiegeln.DPG-Bench (Dense Prompted Graph Benchmark) ist ein umfassender Datensatz mit 1065 lange, dichte Cues in einem umfassenden Datensatz, der dazu dient, die komplexen semantischen Ausrichtungsfähigkeiten von Text-Bild-Modellen zu bewerten.
3.3 Vergleich mit dem Stand der Technik
Multimodale Verstehensleistung: In Tabelle 3 vergleichen wir den vorgeschlagenen Ansatz mit den modernsten vereinheitlichten und reinen Verstehensmodellen.Janus-Pro erzielt insgesamt die besten Ergebnisse. Dies kann auf die Entkopplung von multimodalem Verstehen und generierter visueller Kodierung zurückgeführt werden, die den Konflikt zwischen diesen beiden Aufgaben entschärft. Janus-Pro bleibt auch im Vergleich zu wesentlich größeren Modellen sehr konkurrenzfähig. Zum Beispiel übertrifft Janus-Pro-7B TokenFlow-XL (13B) in allen Benchmarks außer GQA.
Tabelle 4 Bewertung der Text-zu-Bild-Generierung im GenEval-Benchmark. "Und." und "Gen." stehen für "Verstehen" bzw. "Generieren". Modelle, die externe vortrainierte Diffusionsmodelle verwenden, sind mit † gekennzeichnet.

Tabelle 5 Leistung auf DPG-Bench. Mit Ausnahme von Janus und Janus-Pro sind alle Methoden in dieser Tabelle spezifisch für das Modell, das zur Erstellung der Aufgabe verwendet wurde.

Visuelle Generierungsleistung: Wir berichten über die visuelle Generierungsleistung auf GenEval und DPG-Bench. Wie in Tabelle 4 zu sehen ist, erreicht unser Janus-Pro-7B in GenEval eine Gesamtgenauigkeit von 80% und übertrifft damit alle anderen vereinheitlichten oder nur für die Generierung unterstützten Methoden, z. B. Transfusion [55] (63%), SD3-Medium (74%) und DALL-E 3 (67%). Dies zeigt, dass unsere Methode die Anweisungen besser befolgen kann. Wie aus Tabelle 5 hervorgeht, erreicht Janus-Pro im DPG-Bench eine Punktzahl von 84,19 und übertrifft damit alle anderen Methoden. Dies zeigt, dass Janus-Pro gut darin ist, dichten Anweisungen für die Text-Bild-Generierung zu folgen.
3.4 Qualitative Ergebnisse
Wir zeigen die Ergebnisse des multimodalen Verstehens in Abb. 4. Janus-Pro zeigt ein beeindruckendes Verstehen bei der Verarbeitung von Eingaben aus verschiedenen Kontexten und demonstriert damit seine Leistungsfähigkeit. Im unteren Teil von Abb. 4 sind auch einige Ergebnisse der Bilderzeugung durch Text zu sehen. Die von Janus-Pro-7B erzeugten Bilder sind sehr realistisch und enthalten viele Details, obwohl die Auflösung nur $384\mal384$ beträgt. Bei phantasievollen und kreativen Szenarien erfasst Janus-Pro-7B die semantischen Informationen in den Prompts genau und erzeugt sinnvolle und kohärente Bilder.

Abbildung 4 | Qualitative Ergebnisse des multimodalen Verständnisses und der visuellen Generierungsfähigkeiten. Das Modell ist Janus-Pro-7B, und die visuell erzeugte Bildausgabe hat eine Auflösung von $384\times384$. am besten auf einem Bildschirm zu sehen.
4. schlussfolgerung
In diesem Papier werden Verbesserungen an Janus in Bezug auf die Trainingsstrategie, die Daten und die Modellgröße vorgenommen. Diese Verbesserungen führen zu signifikanten Verbesserungen beim multimodalen Verstehen und bei der Texterzeugung nach Bildbefehlen. Janus-Pro hat jedoch immer noch einige Einschränkungen. Beim multimodalen Verstehen ist die Eingabeauflösung auf $384\mal384$ begrenzt, was die Leistung bei feinkörnigen Aufgaben wie OCR beeinträchtigt. Bei textgenerierten Bildern führt die geringe Auflösung in Verbindung mit dem Rekonstruktionsverlust durch den visuellen Tagger zu Bildern, die zwar semantisch reichhaltig sind, denen es aber dennoch an Details fehlt. So können beispielsweise kleine Gesichtsregionen, die nur einen begrenzten Bildbereich einnehmen, nicht ausreichend detailliert erscheinen. Eine Erhöhung der Bildauflösung kann diese Probleme lindern.
bibliographie
[1] J. Bai, S. Bai, S. Yang, S. Wang, S. Tan, P. Wang, J. Lin, C. Zhou, and J. Zhou. qwen-vl: a cutting-edge large-scale visual language model with versatility. arXiv preprint arXiv:2308.12966, 2023.[2] J. Betker, G. Goh, L. Jing, T. Brooks, J. Wang, L. Li, L. Ouyang, J. Zhuang, J. Lee, Y. Guo, et al. Verbesserung der Bilderzeugung durch bessere Beschriftung. Computer Science. https://cdn.openai.com/papers/dall-e-3.pdf, 2(3):8, 2023.
[3] X. Bi, D. Chen, G. Chen, S. Chen, D. Dai, C. Deng, H. Ding, K. Dong, Q. Du, Z. Fu, et al. DeepSeek LLM: Extending open source language models using long-termism. arXiv preprint arXiv:2401.02954, 2024.
[4] J. Chen, J. Yu, C. Ge, L. Yao, E. Xie, Y. Wu, Z. Wang, J. Kwok, P. Luo, H. Lu, et al. PixArtℎ: fast training diffusion transformer for photo-realistic text generation image synthesis. arXiv preprint arXiv:2310.00426, 2023.
[5] J. Chen, C. Ge, E. Xie, Y. Wu, L. Yao, X. Ren, Z. Wang, P. Luo, H. Lu, and Z. Li. PixArt-Sigma: weak-to-strong diffusion transformer training for 4K text generation image generation. arXiv preprint arXiv:2403.04692, 2024.
[6] X. Chu, L. Qiao, X. Lin, S. Xu, Y. Yang, Y. Hu, F. Wei, X. Zhang, B. Zhang, X. Wei, et al. Mobilevlm: ein schneller, reproduzierbarer und leistungsstarker visueller Sprachassistent für mobile Geräte. arXiv preprint arXiv:2312.16886, 2023.
[7] X. Chu, L. Qiao, X. Zhang, S. Xu, F. Wei, Y. Yang, X. Sun, Y. Hu, X. Lin, B. Zhang, et al. Mobilevlm v2: Eine schnellere und leistungsfähigere Basis für die visuelle Sprachmodellierung. arXiv preprint arXiv:2402.03766, 2024.
[8] W. Dai, J. Li, D. Li, A. M. H. Tiong, J. Zhao, W. Wang, B. Li, P. Fung, and S. Hoi. Instructblip: towards a generalised visual language model with command fine-tuning, 2023.
[9] J. Deng, W. Dong, R. Socher, L.-J. Li, K. Li, and L. Fei-Fei. Imagenet: a large-scale hierarchical image database. In Proceedings of the 2009 IEEE Conference on Computer Vision and Pattern Recognition, Seiten 248-255, Institute of Electrical and Electronics Engineers, 2009.
[10] R. Dong, C. Han, Y. Peng, Z. Qi, Z. Ge, J. Yang, L. Zhao, J. Sun, H. Zhou, H. Wei, et al. Dreamllm: multimodales kollaboratives Verstehen und Erstellen. arXiv preprint arXiv:2309.11499, 2023.
[11] P. Esser, S. Kulal, A. Blattmann, R. Entezari, J. Mller, H. Saini, Y. Levi, D. Lorenz, A. Sauer, F. Boesel, D. Podell, T. Dockhorn, Z. English, K. Lacey A. Goodwin, Y. Marek, and R. Rombach. scaling-corrected stream transformer for high-resolution image synthesis, 2024. URL https://arxiv.org/abs/2403.03206.
[12] C. Fu, P. Chen, Y. Shen, Y. Qin, M. Zhang, X. Lin, J. Yang, X. Zheng, K. Li, X. Sun, et al. MME: ein umfassender Bewertungsmaßstab für multimodale große Sprachmodelle. arXiv preprint arXiv:2306.13394, 2023.
[13] Y. Ge, S. Zhao, J. Zhu, Y. Ge, K. Yi, L. Song, C. Li, X. Ding, and Y. Shan. SEED-X: a multimodal model with unified multi-granularity understanding and generation. arXiv preprint arXiv:2404.14396, 2024.
[14] D. Ghosh, H. Hajishirzi, and L. Schmidt. GenEval: an object-oriented framework for evaluating text-generated image alignment. Advances in Neural Information Processing Systems, 36, 2024.
[15] High-flyer, HAI-LLM: An Efficient and Lightweight Large Model Training Tool, 2023, URL https://www.high-flyer.cn/en/blog/hai-llm.
[16] X. Hu, R. Wang, Y. Fang, B. Fu, P. Cheng, and G. Yu. ELLA: Equipping diffusion models for enhanced semantic alignment. arXiv preprint arXiv:2403.05135, 2024.
[17] D. A. Hudson und C. D. Manning. gqa: a new dataset for real-world visual reasoning and combinatorial quizzing. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 6700-6709, 2019.
[18] Y. Jin, K. Xu, L. Chen, C. Liao, J. Tan, B. Chen, C. Lei, A. Liu, C. Song, X. Lei, et al. Dynamische diskrete visuelle Tokenisierung für visuelles Vortraining in einheitlicher Sprache. arXiv preprint arXiv:2309.04669, 2023.
[19] H. Laurenon, D. van Strien, S. Bekman, L. Tronchon, L. Saulnier, T. Wang, S. Karamcheti, A. Singh, G. Pistilli, Y. Jernite, and et al. Einführung in IDEFICS: ein offenes Modell zur Reproduktion von visuellen Sprachmodellen auf dem neuesten Stand der Technik, 2023. URL https://huggingface.co/blog/id efics.
[20] H. Laurenon, A. Marafioti, V. Sanh, und L. Tronchon. Building and better understanding visual language models: insights and future directions, 2024.
[21] B. Li, R. Wang, G. Wang, Y. Ge, Y. Ge, and Y. Shan. SEED-Bench: benchmarking multimodal LLMs using generative understanding. arXiv preprint arXiv:2307.16125, 2023.
[22] D. Li, A. Kamko, E. Akhgari, A. Sabet, L. Xu, und S. Doshi. Spielplatz v2.5: Drei-Punkt-Einsichten zur Verbesserung der ästhetischen Qualität textgenerierter Bilderzeugung. arXiv preprint arXiv:2402.17245, 2024.
[23] Y. Li, Y. Du, K. Zhou, J. Wang, W. X. Zhao, and J.-R. Wen. Evaluating object illusions in large-scale visual language models. arXiv preprint arXiv:2305.10355, 2023.
[24] Z. Li, H. Li, Y. Shi, A. B. Farimani, Y. Kluger, L. Yang, and P. Wang. double diffusion for unified image generation and understanding. arXiv preprint arXiv:2501.00289, 2024.
[25] Z. Li, J. Zhang, Q. Lin, J. Xiong, Y. Long, X. Deng, Y. Zhang, X. Liu, M. Huang, Z. Xiao, et al. Hunyuan-DiT: ein leistungsfähiger Multiauflösungs-Diffusionstransformator mit feinem chinesischen Verständnis. arXiv preprint arXiv:2405.08748, 2024.
[26] H. Liu, C. Li, Y. Li, and Y. J. Lee. Improved fine-tuning baselines for visual commands. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seiten 26296-26306, 2024.
[27] H. Liu, C. Li, Q. Wu, and Y. J. Lee. visual command fine-tuning. Advances in Neural Information Processing Systems, 36, 2024.
[28] H. Liu, W. Yan, M. Zaharia, and P. Abbeel. world model on million-length videos and languages using ring attention. arXiv preprint arXiv:2402.08268, 2024.
[29] Y. Liu, H. Duan, Y. Zhang, B. Li, S. Zhang, W. Zhao, Y. Yuan, J. Wang, C. He, Z. Liu, et al. MMBench: ist Ihr multimodales Modell ein Alleskönner? arXiv preprint arXiv:2307.06281, 2023.
[30] Y. Ma, X. Liu, X. Chen, W. Liu, C. Wu, Z. Wu, Z. Pan, Z. Xie, H. Zhang, X. yu, L. Zhao, Y. Wang, J. Liu, and C. Ruan. Janusflow: reconciling autoregressive and corrective flows for unified multimodal understanding and generation, 2024.
[31] mehdidc. yfcc-huggingface. https://huggingface.co/datasets/mehdidc/yfcc15 m, 2024.
[32] D. Podell, Z. English, K. Lacey, A. Blattmann, T. Dockhorn, J. Mller, J. Penna, and R. Rombach. sdxl: improving potential diffusion models for high-resolution image synthesis. arXiv preprint arXiv:2307.01952,. 2023.
[33] D. Podell, Z. English, K. Lacey, A. Blattmann, T. Dockhorn, J. Mller, J. Penna, and R. Rombach. sdxl: improving potential diffusion models for high resolution image synthesis. 2024.
[34] L. Qu, H. Zhang, Y. Liu, X. Wang, Y. Jiang, Y. Gao, H. Ye, D. K. Du, Z. Yuan, and X. Wu. Tokenflow: a unified image tagger for multimodal understanding and generation. arXiv preprint arXiv:2412.03069, 2024.
[35] A. Ramesh, P. Dhariwal, A. Nichol, C. Chu, and M. Chen. hierarchical text-conditional image generation using CLIP latent values. arXiv preprint arXiv:2204.06125, 1(2):3, 2022.
[36] R. Rombach, A. Blattmann, D. Lorenz, P. Esser, and B. Ommer. High-resolution image synthesis using a latent diffusion model. 2022.
[37] R. Rombach, A. Blattmann, D. Lorenz, P. Esser, and B. Ommer: High-resolution image synthesis using latent diffusion models. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 10684-10695, 2022.
[38] P. Sun, Y. Jiang, S. Chen, S. Zhang, B. Peng, P. Luo, and Z. Yuan. Autoregressive Modelle schlagen Diffusion: das LLama für skalierbare Bilderzeugung. arXiv preprint arXiv:2406.06525, 2024.
[39] Q. Sun, Q. Yu, Y. Cui, F. Zhang, X. Zhang, Y. Wang, H. Gao, J. Liu, T. Huang, and X. Wang. multimodal generative pretraining. arXiv preprint arXiv:2307.05222, 2023.
[40] C. Team. Chameleon: A basic model for early fusion of mixed modes. arXiv preprint arXiv:2405.09818, 2024.
[41] G. Team, R. Anil, S. Borgeaud, Y. Wu, J.-B. Alayrac, J. Yu, R. Soricut, J. Schalkwyk, A. M. Dai, A. Hauth, et al. Zwillinge: eine Familie von fähigen multimodalen Modellen. arXiv preprint arXiv:2312.11805, 2023.
[42] S. Tong, D. Fan, J. Zhu, Y. Xiong, X. Chen, K. Sinha, M. Rabbat, Y. LeCun, S. Xie, and Z. Liu. Metamorph: multimodal understanding and generation through instruction fine-tuning. arXiv preprint arXiv:2412.14164,. 2024.
[43] Vivym. Midjourney Aufforderungsdatensatz. https://huggingface.co/datasets/vivym/midjourney-prompts, 2023. Datum des Besuchs: [Datum des Besuchs einfügen, z. B. 2023-10-15].
[44] C. Wang, G. Lu, J. Yang, R. Huang, J. Han, L. Hou, W. Zhang, and H. Xu. Illume: illuminating your LLMs to see, draw, and self-enhance. arXiv preprint arXiv:2412.06673, 2024.
[45] X. Wang, X. Zhang, Z. Luo, Q. Sun, Y. Cui, J. Wang, F. Zhang, Y. Wang, Z. Li, Q. Yu, et al. Emu3: die nächste Tag-Vorhersage ist alles, was Sie brauchen. arXiv preprint arXiv:2409.18869, 2024.
[46] C. Wu, X. Chen, Z. Wu, Y. Ma, X. Liu, Z. Pan, W. Liu, Z. Xie, X. Yu, C. Ruan, et al. Janus: Entkopplung visueller Kodierung für einheitliches multimodales Verstehen und Generieren. arXiv preprint arXiv:2410.13848, 2024.
[47] S. Wu, H. Fei, L. Qu, W. Ji, und T.-S. Chua. next-gpt: any-to-any multimodal LLM. arXiv preprint arXiv:2309.05519, 2023.
[48] Y. Wu, Z. Zhang, J. Chen, H. Tang, D. Li, Y. Fang, L. Zhu, E. Xie, H. Yin, L. Yi, et al. VILA-U: ein grundlegendes Modell für die Integration von visuellem Verstehen und Generieren. arXiv preprint arXiv:2409.04429, 2024.
[49] Z. Wu, X. Chen, Z. Pan, X. Liu, W. Liu, D. Dai, H. Gao, Y. Ma, C. Wu, B. Wang, et al. DeepSeek-VL2: hybrides visuelles Experten-Sprachmodell für fortgeschrittenes multimodales Verstehen. arXiv preprint arXiv:2412.10302, 2024.
[50] J. Xie, W. Mao, Z. Bai, D. J. Zhang, W. Wang, K. Q. Lin, Y. Gu, Z. Chen, Z. Yang, and M. Z. Shou. show-o: a single converter for unified multimodal understanding and generation. arXiv preprint arXiv:2408.12528,. 2024.
[51] W. Yu, Z. Yang, L. Li, J. Wang, K. Lin, Z. Liu, X. Wang, and L. Wang. MM-Vet: assessing the integrative power of large multimodal models. arXiv preprint arXiv:2308.02490, 2023.
[52] X. Yue, Y. Ni, K. Zhang, T. Zheng, R. Liu, G. Zhang, S. Stevens, D. Jiang, W. Ren, Y. Sun, et al. MMMU: A large-scale multidisciplinary multimodal understanding and inference benchmark for expert AGI. in Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 9556-9567, 2024.
[53] X. Zhai, B. Mustafa, A. Kolesnikov, and L. Beyer. sigmoid loss for language image pretraining. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Seiten 11975-11986, 2023.
[54] C. Zhao, Y. Song, W. Wang, H. Feng, E. Ding, Y. Sun, X. Xiao, and J. Wang. Monoformer: a single converter for diffusion and autoregression. arXiv preprint arXiv:2409.16280, 2024.
[55] C. Zhou, L. Yu, A. Babu, K. Tirumala, M. Yasunaga, L. Shamis, J. Kahn, X. Ma, L. Zettlemoyer, and O. Levy. Transfusion: predicting the next labelled and diffused image using a multimodal model. arXiv Preprint. arXiv:2408.11039, 2024.
[56] Y. Zhu, M. Zhu, N. Liu, Z. Ou, X. Mou, and J. Tang. lLAVA-Phi: Efficient multimodal assistant with small language models. arXiv preprint arXiv:2401.02330, 2024.[57] L. Zhuo, R. Du, H. Xiao, Y. Li, D. Liu, R. Huang, W. Liu, L. Zhao, F.-Y. Wang, Z. Ma, et al. Lumina-Next: Lumina-T2X leistungsfähiger und schneller machen mit Next-DiT. arXiv preprint arXiv:2406.18583, 2024.
© urheberrechtliche Erklärung
Artikel Copyright AI-Austauschkreis Alle, bitte nicht ohne Erlaubnis vervielfältigen.
Ähnliche Artikel


Keine Kommentare...