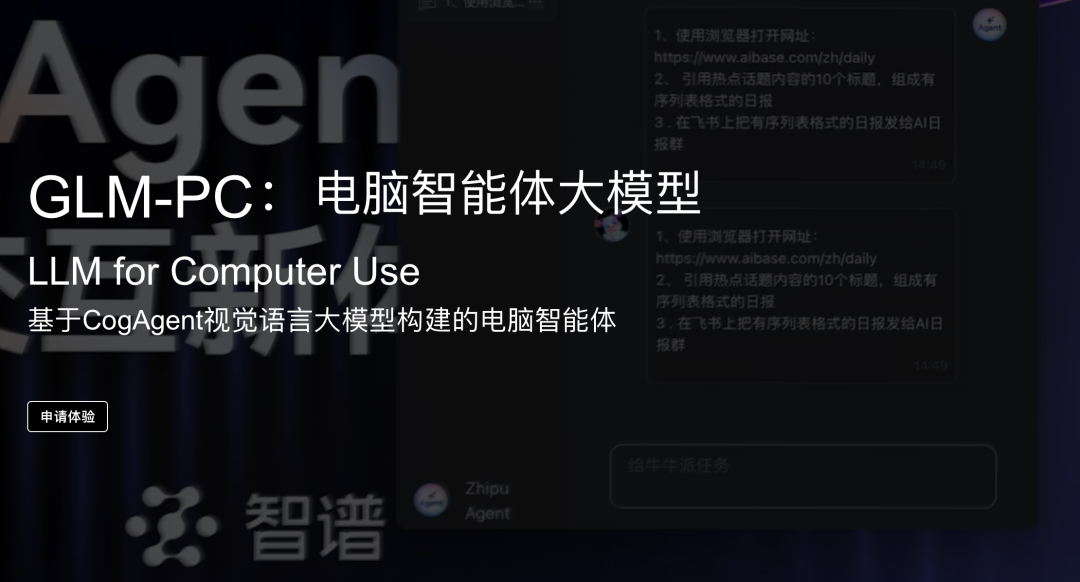
DeepSeek API: Großflächige Anwendung der Festplatten-Caching-Technologie: ein wichtiger Schritt bei der Zivilisierung großer Modelle
-- Eine Diskussion über die tiefere Logik der großen Modell-API-Preiskämpfe, die Optimierung der Nutzererfahrung und die Einbeziehung von Technologien

Bildnachweis: Offizielle DeepSeek-Dokumentation
In einer Zeit, in der der Wettbewerb im Bereich der großen KI-Modelle immer härter wird, hat DeepSeek kürzlich angekündigt, dass sein API-Dienst auf innovative Weise dieFestplatten-Cache-TechnologieDie Preisanpassung von DeepSeek ist schockierend - der Preis des Cache-Hit-Teils wird direkt auf ein Zehntel des vorherigen Preises gesenkt, was die Preise in der Branche unterm Strich noch einmal auffrischt. Als unabhängiger Gutachter, der sich seit langem mit der Big-Model-Technologie und den Branchentrends befasst, bin ich der Meinung, dass der Schritt von DeepSeek nicht nur eine Kostenrevolution ist, die durch technologische Innovation angetrieben wird, sondern auch eine tiefgreifende Optimierung der Big-Model-API-Nutzererfahrung und ein wichtiger Schritt zur Beschleunigung der Verallgemeinerung der Big-Model-Technologie.
Technologische Innovation: Feinheiten des Festplatten-Cache und Leistungssprünge
DeepSeek ist sich der Tatsache bewusst, dass die hohen Kosten und die Latenzprobleme großer Modell-APIs seit langem ein Hindernis für ihre weit verbreitete Nutzung darstellen und dass kontextbezogene Wiederholungen, die bei Benutzeranfragen häufig vorkommen, einen wesentlichen Beitrag zu diesen Problemen leisten. Bei Dialogen mit mehreren Gesprächsrunden muss beispielsweise in jeder Runde der vorherige Dialogverlauf erneut eingegeben werden; bei langen Textverarbeitungsaufgaben enthält die Eingabeaufforderung häufig wiederholte Verweise. Wiederholtes Rechnen Token Dies verschwendet Rechenzeit und erhöht die Latenzzeit.
Um dieses Problem zu lösen, führt DeepSeek die kontextbezogene Festplatten-Caching-Technologie ein. Das Kernprinzip ist die intelligente Zwischenspeicherung kontextbezogener Inhalte, die voraussichtlich in Zukunft wiederverwendet werden, wie z. B. Dialogverlauf, Systemvoreinstellungen, Few-Shot-Beispiele usw., in einem verteilten Festplatten-Array. Wenn ein Benutzer eine neue API-Anfrage startet, erkennt das System automatisch, ob der Präfix-Teil der Eingabe mit dem zwischengespeicherten Inhalt übereinstimmt (Hinweis: Der Präfix muss identisch sein, um den Cache zu treffen). Ist dies der Fall, liest das System das Duplikat direkt aus dem Hochgeschwindigkeits-Festplattencache, ohne eine Neuberechnung vorzunehmen, wodurch sowohl die Latenzzeit als auch die Kosten optimiert werden.
Um ein besseres Verständnis für die Funktionsweise des Caching zu bekommen, sehen wir uns einige Beispiele an DeepSeek Offizielles Beispiel geliefert:
Beispiel 1: Dialogszenario mit mehreren Runden
Hauptmerkmal: Nachfolgende Dialogrunden greifen automatisch auf den Kontext-Cache der vorangegangenen Runde zu.
In Dialogen mit mehreren Gesprächsrunden, in denen Benutzer typischerweise aufeinanderfolgende Fragen zu einem einzigen Thema stellen, kann das Festplatten-Caching von DeepSeek den Dialogkontext effizient wiederverwenden. Zum Beispiel im folgenden Dialogszenario:
Erste Anfrage:
messages: [
{"role": "system", "content": "你是一位乐于助人的助手"},
{"role": "user", "content": "中国的首都是哪里?"}
]
Zweiter Antrag:
messages: [
{"role": "system", "content": "你是一位乐于助人的助手"},
{"role": "user", "content": "中国的首都是哪里?"},
{"role": "assistant", "content": "中国的首都是北京。"},
{"role": "user", "content": "美国的首都是哪里?"}
]

Bildnachweis: Offizielle DeepSeek-Dokumentation
Beispiel für einen Cache-Treffer in einem Mehrrunden-Dialogszenario: Nachfolgende Dialogrunden treffen automatisch auf den Kontext-Cache der vorherigen Runde.
Da bei der zweiten Anfrage der Präfix-Teil (Systemnachricht + erste Nutzernachricht) genau derselbe ist wie bei der ersten Anfrage, wird dieser Teil vom Cache erfasst, ohne dass die Berechnung wiederholt werden muss, wodurch sich die Latenzzeit und die Kosten verringern.
Den offiziellen Daten von DeepSeek zufolge sank die gemessene Latenzzeit des ersten Tokens in extremen Szenarien mit 128K Eingaben und den meisten Wiederholungen von 13 Sekunden auf 500 Millisekunden, was eine erstaunliche Leistungsverbesserung darstellt. Selbst in nicht extremen Szenarien kann die Latenzzeit effektiv reduziert und die Benutzerfreundlichkeit verbessert werden.
Darüber hinaus ist der Festplatten-Caching-Service von DeepSeek vollständig automatisiert und benutzerunabhängig. Sie können die Leistungs- und Preisvorteile des Caching nutzen, ohne Code oder API-Schnittstelle ändern zu müssen. Die neue Funktion prompt_cache_hit_tokens (Cache-Treffer) im von der API zurückgegebenen Nutzungsfeld ermöglicht es Benutzern, die Anzahl der erhaltenen Cache-Treffer zu sehen. Token (Anzahl der Token) und prompt_cache_miss_tokens (Anzahl der verpassten Token), um die Cache-Treffer in Echtzeit zu überwachen und die Cache-Leistung besser zu bewerten und zu optimieren.
DeepSeek ist in der Lage, die Führung bei der Anwendung der Festplatten-Caching-Technologie in großem Maßstab zu übernehmen, was untrennbar mit seiner fortschrittlichen Modellarchitektur verbunden ist. Die von DeepSeek V2 vorgeschlagene MLA-Struktur (Multi-head Latent Attention) komprimiert die Größe des Kontext-KV-Cache erheblich und garantiert gleichzeitig die Leistung des Modells, wodurch es möglich wird, den KV-Cache auf einer kostengünstigen Festplatte zu speichern, wodurch die Grundlage für die Festplatten-Caching-Technologie gelegt wird, die sich auf dem Markt etablieren soll. Dadurch wird es möglich, den KV-Cache auf einer kostengünstigen Festplatte zu speichern, wodurch die Grundlage für die Festplatten-Caching-Technologie geschaffen wird.
Verständnisse DeepSeek-R1 API Cache Hit vs. Preis:Häufig gestellte Fragen zur Verwendung der DeepSeek-R1-API
Anwendungsszenarien: von langen Text-Fragen bis hin zur Code-Analyse, die Grenzen sind unendlich erweiterbar!
Es gibt eine Vielzahl von Szenarien, in denen die Festplatten-Caching-Technologie eingesetzt werden kann, und fast jede Anwendung mit großen Modellen, die kontextbezogene Eingaben beinhaltet, kann davon profitieren. Der ursprüngliche Artikel listet die folgenden typischen Szenarien auf und enthält weitere spezifische Beispiele:
- Ein Quiz-Assistent mit langen voreingestellten Aufforderungswörtern:
- Hauptmerkmal: Feste Systemprompts können zwischengespeichert werden, was die Kosten pro Anfrage reduziert.
- Beispiel:
Beispiel 2: Langer Text Q&A-Szenario
Hauptmerkmal: Mehrere Analysen desselben Dokuments können im Cache gespeichert werden.
Die Nutzer müssen denselben Ergebnisbericht analysieren und unterschiedliche Fragen stellen:
Erste Anfrage:
messages: [
{"role": "system", "content": "你是一位资深的财报分析师..."},
{"role": "user", "content": "<财报内容>\n\n请总结一下这份财报的关键信息。"}
]
Zweiter Antrag:
messages: [
{"role": "system", "content": "你是一位资深的财报分析师..."},
{"role": "user", "content": "<财报内容>\n\n请分析一下这份财报的盈利情况。"}
]
Da bei der zweiten Anfrage der Teil der Systemnachricht und der Benutzernachricht das gleiche Präfix wie bei der ersten Anfrage hat, kann dieser Teil vom Cache erfasst werden, um Rechenressourcen zu sparen.
- Rollenspiel-Apps mit mehreren Dialogrunden:
- Hauptmerkmale: hohe Wiederverwendung des Dialogverlaufs und umfangreiche Zwischenspeicherung.
- (Beispiel 1 wurde im Detail dargestellt)
- Datenanalyse für feste Textsammlungen:
- Hauptmerkmale: mehrere Analysen und Quizfragen zum selben Dokument mit hoher Wiederholung des Präfixes.
- Zum Beispiel mehrere Analysen und Fragerunden zu ein und demselben Finanzbericht oder Rechtsdokument. (Beispiel 2 wurde im Detail dargestellt)
- Werkzeuge zur Codeanalyse und Fehlerbehebung auf der Ebene des Code-Repository:
- Hauptmerkmal: Code-Analyseaufgaben erfordern oft eine große Menge an Kontext, und das Zwischenspeichern kann zur Kostensenkung beitragen.
- Lernen mit wenigen Schüssen:
- Hauptmerkmal: Few-Shot-Beispiele mit dem Präfix Prompt können zwischengespeichert werden, wodurch die Kosten für mehrere Few-Shot-Aufrufe reduziert werden.
- Beispiel:
Beispiel 3: Lernszenario mit wenigen Schüssen
Hauptmerkmal: dasselbe Few-shot-Beispiel kann als Präfix zwischengespeichert werden.
Die Benutzer verwenden Few-Shot-Learning, um die Effektivität des Modells bei der Abfrage von historischem Wissen zu verbessern:
Erste Anfrage:
messages: [
{"role": "system", "content": "你是一位历史学专家,用户将提供一系列问题,你的回答应当简明扼要,并以`Answer:`开头"},
{"role": "user", "content": "请问秦始皇统一六国是在哪一年?"},
{"role": "assistant", "content": "Answer:公元前221年"},
{"role": "user", "content": "请问汉朝的建立者是谁?"},
{"role": "assistant", "content": "Answer:刘邦"},
{"role": "user", "content": "请问唐朝最后一任皇帝是谁"},
{"role": "assistant", "content": "Answer:李柷"},
{"role": "user", "content": "请问明朝的开国皇帝是谁?"},
{"role": "assistant", "content": "Answer:朱元璋"},
{"role": "user", "content": "请问清朝的开国皇帝是谁?"}
]
Zweiter Antrag:
messages: [
{"role": "system", "content": "你是一位历史学专家,用户将提供一系列问题,你的回答应当简明扼要,并以`Answer:`开头"},
{"role": "user", "content": "请问秦始皇统一六国是在哪一年?"},
{"role": "assistant", "content": "Answer:公元前221年"},
{"role": "user", "content": "请问汉朝的建立者是谁?"},
{"role": "assistant", "content": "Answer:刘邦"},
{"role": "user", "content": "请问唐朝最后一任皇帝是谁"},
{"role": "assistant", "content": "Answer:李柷"},
{"role": "user", "content": "请问明朝的开国皇帝是谁?"},
{"role": "assistant", "content": "Answer:朱元璋"},
{"role": "user", "content": "请问商朝是什么时候灭亡的"},
]
Da bei der zweiten Anfrage dasselbe 4-Schuss-Beispiel als Präfix verwendet wird, kann dieser Teil aus dem Cache abgerufen werden, und es muss nur die letzte Frage neu berechnet werden, wodurch die Kosten für das Few-Shot-Lernen erheblich gesenkt werden.

Bildnachweis: Offizielle DeepSeek-Dokumentation
Beispiel für einen Cache-Treffer in einem Datenanalyse-Szenario: Anfragen mit demselben Präfix können den Cache treffen (Hinweis: Das Bild hier folgt dem ursprünglichen Datenanalyse-Beispiel und konzentriert sich mehr auf den Begriff der Präfix-Duplikation; das Few-shot-Beispielszenario kann auf dieselbe Weise interpretiert werden).
Diese Szenarien sind nur die Spitze des Eisbergs. Die Anwendung der Festplatten-Caching-Technologie eröffnet wirklich neue Möglichkeiten für die Anwendung von APIs für große Modelle mit langem Kontext. So können wir beispielsweise leistungsfähigere Tools für die Erstellung von Langtexten entwickeln, komplexere wissensintensive Aufgaben bewältigen und tiefgründigere und einprägsamere KI-Anwendungen für Konversationen entwickeln.
Referenz: Inspiriert von Claude
Kostenvorteil: Die Preise sinken um Größenordnungen und kommen der großen Modellökologie zugute
Die Preisanpassung für die DeepSeek-API ist "episch", wobei der Cache-Treffer-Teil der API mit 0,10 $/Millionen Token und der Treffer-Teil mit 1 $/Million Token bepreist wird. Der Preis für einen Cache-Treffer beträgt nur 0,1 $ pro Million Token, und der Preis für einen Miss beträgt nur 1 $ pro Million Token, was eine Größenordnung niedriger ist als der vorherige Preis für einen Cache-Treffer.
Nach den offiziellen Angaben von DeepSeek können damit bis zu 90% eingespart werden, und selbst ohne jegliche Optimierung können die Nutzer insgesamt mehr als 50% einsparen. Dieser Kostenvorteil ist von großer Bedeutung, um die Schwelle für die Anwendung großer Modelle zu senken und die Popularität großer Modelle zu steigern.
Noch interessanter ist die Preisstrategie von DeepSeek. Die Preise für Cache-Hits und -Misses sind gestaffelt, um die Benutzer zu ermutigen, den Cache so weit wie möglich zu nutzen, das Prompt-Design zu optimieren und die Cache-Trefferquote zu erhöhen, wodurch die Kosten weiter gesenkt werden. Gleichzeitig fallen weder für den Cache-Dienst selbst noch für den Cache-Speicherplatz zusätzliche Gebühren an, was wirklich benutzerfreundlich ist.
Bildnachweis: Offizielle DeepSeek-Dokumentation
Der Preis für die DeepSeek-API wurde erheblich gesenkt, so dass Cache-Treffer nur noch 0,1 $/Million Token kosten.
Die erhebliche Preissenkung von DeepSeek API wird zweifellos die Entwicklung des Preiskampfes bei den großen Modellen beschleunigen. Im Gegensatz zum früheren einfachen Preiswettbewerb ist die Preissenkung von DeepSeek jedoch eine rationale Preissenkung auf der Grundlage von technologischer Innovation und Kostenoptimierung, die nachhaltiger und branchenorientierter ist. Dieser gesunde Preiswettbewerb wird letztlich dem gesamten Big-Model-Ökosystem zugute kommen, so dass mehr Entwickler und Unternehmen in den Genuss fortschrittlicher Big-Model-Technologie zu niedrigeren Kosten kommen.
Unbegrenztes Streaming und Gleichzeitigkeit, sichere und zuverlässige Caching-Dienste
Neben den Leistungs- und Preisvorteilen sind auch die Stabilität und Sicherheit der DeepSeek API vertrauenswürdig. Der DeepSeek API-Dienst ist auf eine Kapazität von 1 Billion Token pro Tag ausgelegt, mit unbegrenztem Streaming und Gleichzeitigkeit für alle Nutzer, was die Qualität des Dienstes unter hohen Lastbedingungen gewährleistet.
DeepSeek hat auch der Datensicherheit volle Aufmerksamkeit geschenkt. Der Cache jedes Nutzers ist getrennt und logisch voneinander isoliert, um die Sicherheit und den Schutz der Nutzerdaten zu gewährleisten. Caches, die über einen längeren Zeitraum nicht genutzt wurden, werden automatisch geleert (in der Regel nach ein paar Stunden bis ein paar Tagen) und nicht lange aufbewahrt oder für andere Zwecke verwendet, was mögliche Sicherheitsrisiken weiter reduziert.
Es ist zu beachten, dass das Cache-System 64 Token als Speichereinheit verwendet und dass alles, was weniger als 64 Token enthält, nicht in den Cache aufgenommen wird. Außerdem ist das Cache-System "best effort" und garantiert keine 100% Cache-Treffer. Darüber hinaus dauert der Aufbau des Caches einige Sekunden, was aber für lange Kontext-Szenarien durchaus akzeptabel ist.
Modell-Upgrade und Zukunftsaussichten
Es ist erwähnenswert, dass DeepSeek zusammen mit der Einführung der Festplatten-Caching-Technologie auch bekannt gab, dass das DeepSeek-Chat-Modell zu DeepSeek-V3 aufgerüstet wurde und das DeepSeek-Rasoner-Modell das neue Modell DeepSeek-R1 ist. Die neuen Modelle bieten verbesserte Leistung und Fähigkeiten zu einem deutlich niedrigeren Preis, was die die Wettbewerbsfähigkeit der DeepSeek API.
Laut der offiziellen Preisinformation genießt DeepSeek-V3 API (deepseek-chat) bis zum 8. Februar 2025 um 24:00 Uhr einen ermäßigten Preis, mit einem Preis von nur $0,1/Millionen Token für zwischengespeicherte Treffer, $1/Million Token für verpasste Eingaben und $2/Millionen Token für Ausgaben. DeepSeek-R1 API (deepseek-reasoner) wird als Inferenzmodell mit einer 32K Gedankenkettenlänge und 8K maximaler Ausgabelänge positioniert, mit einem Eingabepreis (zwischengespeicherte Treffer) von $1/Million Token. DeepSeek-R1 API (deepseek-reasoner) wird als Inferenzmodell mit 32K Gedankenkettenlängen und 8K maximalen Ausgabelängen positioniert, mit einem Eingabepreis von $1/Million Token für zwischengespeicherte Treffer, $4/Million Token für verpasste Eingaben und $16/Million Token für Ausgaben (alle Token für die Gedankenkette und die endgültige Antwort). und alle Token der endgültigen Antwort).
Die Reihe innovativer Initiativen von DeepSeek zeigt, dass das Unternehmen kontinuierlich in Technologien investiert und seine Philosophie der Benutzerorientierung verfolgt. Wir haben allen Grund zu der Annahme, dass die Big-Model-Technologie mit DeepSeek und weiteren innovativen Kräften ihre Reife beschleunigen, umfassender werden und weitreichendere Veränderungen in allen Branchen bewirken wird.
Schlussbemerkungen
Die innovative Nutzung der Festplatten-Caching-Technologie und die erhebliche Preissenkung der DeepSeek-API sind ein bahnbrechender Durchbruch. Sie löst nicht nur die langjährigen Kosten- und Latenzprobleme von Big-Model-APIs, sondern bringt den Nutzern auch bessere Qualität und umfassendere Big-Model-Dienste durch technologische Innovation. Der Schritt von DeepSeek kann das Wettbewerbsmuster von Big-Model-APIs neu definieren, die Popularität und Anwendung von KI-Technologie beschleunigen und letztendlich ein wohlhabenderes, offenes und inklusives Big-Model-Ökosystem aufbauen.
© urheberrechtliche Erklärung
Artikel Copyright AI-Austauschkreis Alle, bitte nicht ohne Erlaubnis vervielfältigen.
Ähnliche Artikel



Keine Kommentare...