Entwurf und Implementierung von DeepSearch und DeepResearch

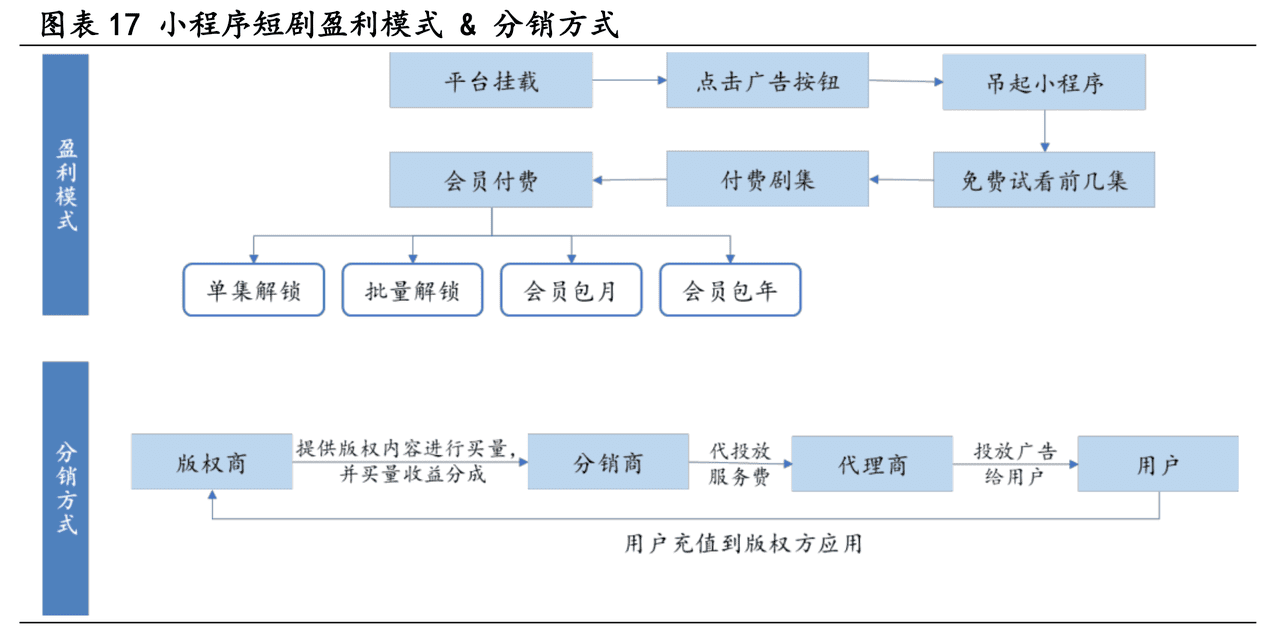
Es ist erst Februar, und Deep Search zeichnet sich bereits als neuer Suchstandard für 2025 ab. Giganten wie Google und OpenAI haben ihre "Deep Research"-Produkte vorgestellt, um der Technologiewelle voraus zu sein. (Wir sind auch stolz darauf, unsere Open-Sourcenode-deepresearch).
Perplexität folgten diesem Beispiel mit ihrem Deep Research, während Musks X AI einen Schritt weiter ging, indem sie Deep-Search-Funktionen direkt in ihre Grok 3-Modell, das im Wesentlichen eine Variante der Tiefenforschung ist.
Ehrlich gesagt ist das Konzept der Tiefensuche keine große Innovation; es ist im Wesentlichen das, was wir letztes Jahr als RAG (Retrieval Augmented Generation) oder Multihop-Quizzing bezeichnet haben. Aber Ende Januar dieses Jahres, mit Tiefensuche-r1 Seit seiner Veröffentlichung hat es eine nie dagewesene Aufmerksamkeit und ein beispielloses Wachstum erfahren.
Erst am vergangenen Wochenende haben sowohl Baidu Search als auch Tencent WeChat Search Deepseek-r1 in ihre Suchmaschinen integriert.KI-Ingenieure haben erkannt, dass dieDurch die Einbeziehung langfristiger Denk- und Schlussfolgerungsprozesse in das Suchsystem ist es möglich, genauere und gründlichere Ergebnisse als je zuvor zu erzielen.
Aber warum findet dieser Wandel gerade jetzt statt? Das ganze Jahr 2024 hindurch scheint "Deep(Re)Search" nicht viel Aufmerksamkeit erregt zu haben. Es sei daran erinnert, dass das Stanford NLP Lab Anfang 2024 die STURM Projekt, webbasierte Erstellung von Langformberichten. Liegt es nur daran, dass "Deep Search" modischer klingt als "mehr QA", "RAG" oder "STORM"? Aber mal ehrlich, manchmal reicht ein erfolgreiches Rebranding aus, damit die Branche plötzlich etwas annimmt, was es schon gibt.
Wir glauben, dass der eigentliche Wendepunkt die Veröffentlichung der OpenAI-Software im September 2024 ist.o1-previewEs führte das Konzept der "Testzeitberechnung" ein und veränderte auf subtile Weise die Wahrnehmung der Branche.Der Begriff "Compute while Reasoning" bedeutet, dass mehr Rechenressourcen in die Reasoning-Phase (d.h. die Phase, in der das große Sprachmodell das Endergebnis generiert) investiert werden, anstatt sich auf die Pre-Training- oder Post-Training-Phasen zu konzentrieren. Zu den klassischen Beispielen gehören das Chain-of-Thought (CoT) Reasoning sowie Ansätze wie"Wait" Techniken wie die Injektion (auch bekannt als Budgetkontrolle), die dem Modell einen größeren Spielraum für interne Überlegungen geben, wie z. B. die Bewertung mehrerer möglicher Antworten, eine eingehendere Planung und eine Selbstreflexion, bevor eine endgültige Antwort gegeben wird.
Dieses Konzept des "Rechnens während des Denkens" sowie Modelle, die sich auf das Denken konzentrieren, führen dazu, dass die Nutzer ein Konzept der "verzögerten Belohnung" akzeptieren:Tauschen Sie längere Wartezeiten gegen hochwertigere und nützlichere Ergebnisse. Wie beim berühmten Stanford-Marshmallow-Experiment haben Kinder, die der Versuchung widerstehen können, sofort einen Marshmallow zu essen, um später zwei Marshmallows zu bekommen, langfristig mehr Erfolg. deepseek-r1 verfestigt diese Benutzererfahrung, die die meisten Benutzer implizit akzeptiert haben, ob es Ihnen gefällt oder nicht.
Dies stellt eine deutliche Abkehr von den traditionellen Suchanforderungen dar. Wenn Ihre Lösung in der Vergangenheit nicht innerhalb von 200 Millisekunden eine Antwort liefern konnte, war das so gut wie gleichbedeutend mit einem Fehlschlag. Doch im Jahr 2025 werden erfahrene Suchentwickler und RAG Ingenieure, stellen Sie Top-1-Präzision und Recall vor die Latenzzeit. Die Nutzer haben sich an längere Bearbeitungszeiten gewöhnt: Solange sie sehen können, wie das System mit der<thinking>.
Im Jahr 2025 ist die Darstellung des Argumentationsprozesses zum Standard geworden, und viele Chat-Schnittstellen werden in speziellen UI-Bereichen dargestellt <think> Der Inhalt.
In diesem Beitrag werden wir die Prinzipien von DeepSearch und DeepResearch anhand unserer Open-Source-Implementierung diskutieren. Wir werden die wichtigsten Design-Entscheidungen vorstellen und auf mögliche Vorbehalte hinweisen.
Was ist Deep Search?
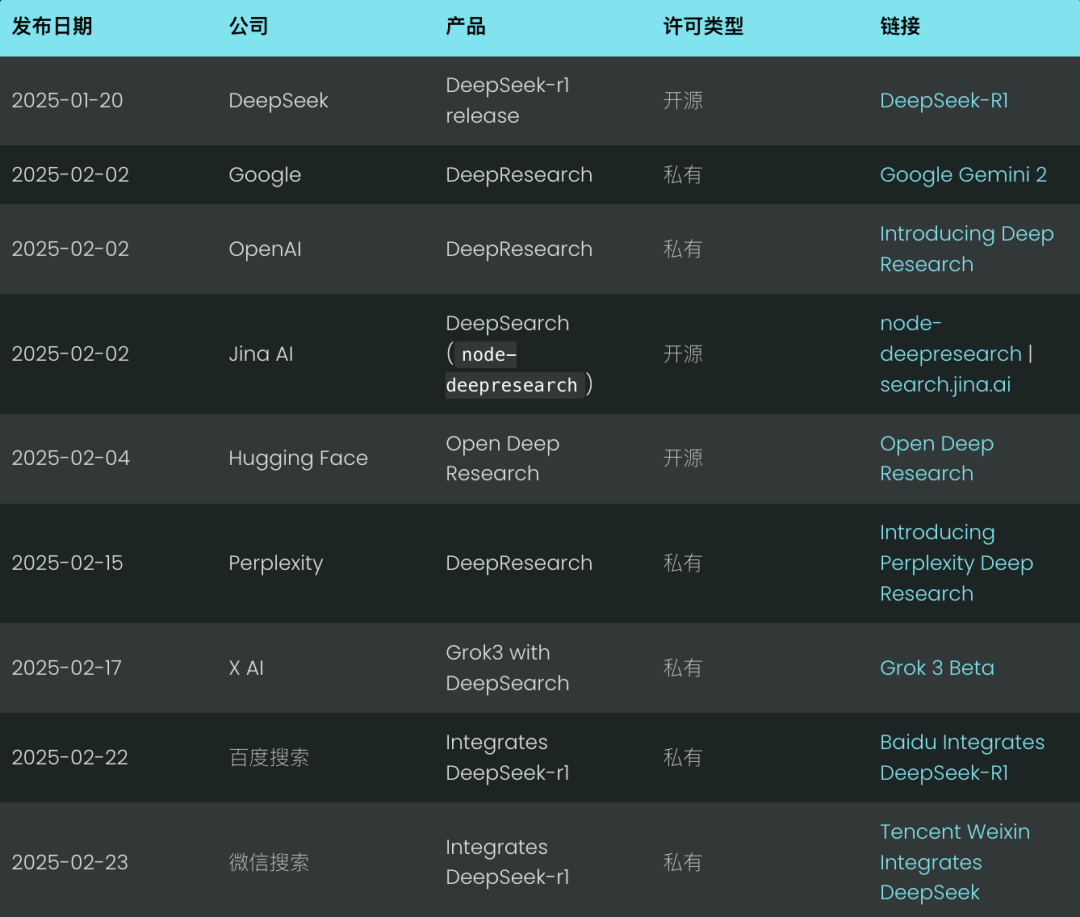
Die Kernidee von DeepSearch besteht darin, die optimale Antwort zu finden, indem die drei Phasen des Suchens, Lesens und Argumentierens durchlaufen werden, bis die optimale Antwort gefunden ist. In der Suchsitzung wird das Internet mit Hilfe einer Suchmaschine erkundet, während sich die Lesesitzung auf die erschöpfende Analyse bestimmter Webseiten konzentriert (z. B. mit Jina Reader). Die Argumentationssitzung hat die Aufgabe, den aktuellen Stand zu bewerten und zu entscheiden, ob das ursprüngliche Problem in kleinere Teilprobleme zerlegt oder alternative Suchstrategien ausprobiert werden sollten.
 DeepSearch - Kontinuierliches Suchen, Lesen von Webseiten und Überlegungen, bis die Antwort gefunden ist (oder darüber hinaus) Token (Haushalt).
DeepSearch - Kontinuierliches Suchen, Lesen von Webseiten und Überlegungen, bis die Antwort gefunden ist (oder darüber hinaus) Token (Haushalt).
Im Gegensatz zum 2024 RAG-System, das in der Regel einen einzigen Suchprozess durchführt, führt DeepSearch mehrere Iterationen durch, die explizite Abbruchbedingungen erfordern. Diese Bedingungen können auf Grenzwerten für die Token-Nutzung oder auf der Anzahl fehlgeschlagener Versuche basieren.
Probieren Sie DeepSearch unter search.jina.ai aus und beobachten Sie die <thinking>um herauszufinden, wo die Schleife auftritt.
Mit anderen Worten.DeepSearch kann als ein LLM-Agent betrachtet werden, der mit verschiedenen Webtools wie Suchmaschinen und Webreadern ausgestattet ist.Der Agent analysiert die aktuellen Beobachtungen und vergangenen Aktionen, um die nächste Vorgehensweise zu bestimmen: ob er direkt eine Antwort geben oder das Netzwerk weiter erkunden soll. Auf diese Weise wird eine Zustandsmaschinenarchitektur aufgebaut, bei der der LLM für die Steuerung der Übergänge zwischen den Zuständen verantwortlich ist.
An jedem Entscheidungspunkt stehen Ihnen zwei Möglichkeiten zur Verfügung: Sie können Hinweise geben, die es dem generativen Standardmodell ermöglichen, spezifische Handlungsanweisungen zu geben, oder Sie können ein spezialisiertes Inferenzmodell wie Deepseek-r1 verwenden, um auf natürliche Weise die nächste zu ergreifende Maßnahme abzuleiten. Aber auch mit r1 müssen Sie den generativen Prozess regelmäßig unterbrechen, um die Ausgabe des Tools (z. B. Suchergebnisse, Webseiteninhalte) in den Kontext einzubringen und es aufzufordern, mit dem Schlussfolgerungsprozess fortzufahren.
Letztlich sind dies nur Details der Implementierung. Ganz gleich, ob Sie Stichworte formulieren oder einfach ein Inferenzmodell verwenden, dieSie alle folgen den zentralen Designprinzipien von DeepSearch: Suchen, Lesen und Ableitendes fortlaufenden Zyklus.
Und was ist DeepResearch?
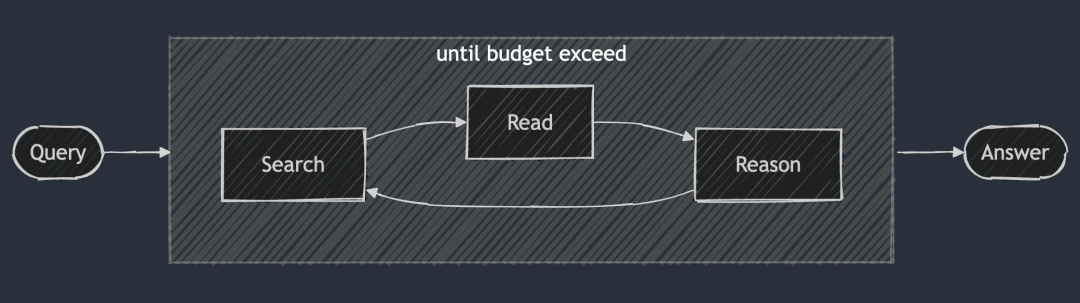
DeepResearch ergänzt DeepSearch um einen strukturierten Rahmen für die Erstellung langer Forschungsberichte. Der Arbeitsablauf beginnt in der Regel mit der Erstellung eines Inhaltsverzeichnisses und wendet DeepSearch dann systematisch auf jeden erforderlichen Abschnitt des Berichts an: von der Einleitung über die verwandte Arbeit und die Methodik bis hin zur Schlussfolgerung. Jeder Abschnitt des Berichts wird durch die Eingabe spezifischer Forschungsfragen in DeepSearch erstellt. Schließlich wurden alle Abschnitte in einen einzigen Hinweis integriert, um die Kohärenz der Gesamterzählung des Berichts zu verbessern.
 DeepSearch dient als Grundbaustein für DeepResearch. Jedes Kapitel wird iterativ durch DeepSearch aufgebaut und dann wird die Gesamtkohärenz verbessert, bevor der endgültige lange Bericht erstellt wird.
DeepSearch dient als Grundbaustein für DeepResearch. Jedes Kapitel wird iterativ durch DeepSearch aufgebaut und dann wird die Gesamtkohärenz verbessert, bevor der endgültige lange Bericht erstellt wird.
Im Jahr 2024 haben wir das Projekt "Forschung" auch intern durchgeführt, und damals haben wir, um die Kohärenz des Berichts zu gewährleisten, einen ziemlich dummen Ansatz gewählt, der darin bestand, bei jeder Iteration alle Kapitel zu berücksichtigen und mehrere Kohärenzverbesserungen vorzunehmen. Aber jetzt scheint es, dass dieser Ansatz ein bisschen zu hart ist, denn die heutigen großen Sprachmodelle haben ein superlanges Kontextfenster, und es ist möglich, kohärente Überarbeitungen in einem Durchgang durchzuführen, was viel effektiver ist.
Wir haben das Projekt "Forschung" jedoch aus mehreren Gründen nicht freigegeben:
Vor allem die Qualität der Berichte entsprach nicht immer unseren internen Standards. Wir haben es mit zwei bekannten internen Abfragen getestet: "Jina AI's Competitor Analysis" und "Jina AI's Product Strategy". Die Ergebnisse waren enttäuschend, die Berichte waren mittelmäßig und glanzlos und brachten uns keine Aha-Erlebnisse. Zweitens ist die Zuverlässigkeit der Suchergebnisse schlecht, und die Täuschung ist ein ernstes Problem. Und schließlich ist die Lesbarkeit insgesamt schlecht, mit vielen Wiederholungen und Redundanzen zwischen den Abschnitten. Kurz gesagt, er ist wertlos. Und der Bericht ist so lang, dass er sowohl Zeitverschwendung als auch unproduktiv zu lesen ist.
Dieses Projekt hat uns aber auch wertvolle Erfahrungen gebracht und eine Reihe von Teilprodukten hervorgebracht:
Zum Beispiel.Unser tiefes Verständnis für die Verlässlichkeit von Suchergebnissen und die Bedeutung der Faktenüberprüfung auf Absatz- und sogar Satzebene führte direkt zur anschließenden Entwicklung des g.jina.ai-Endpunkts.Wir erkannten auch den Wert der Abfrageerweiterung und begannen, Anstrengungen in das Training von Small Language Models (SLMs) für die Abfrageerweiterung zu investieren. Schließlich gefiel uns der Name ReSearch sehr gut, der sowohl die Idee der Neuerfindung der Suche als auch ein Wortspiel darstellt. Es wäre schade gewesen, ihn nicht zu verwenden, und so haben wir ihn schließlich für das Jahrbuch 2024 verwendet.
Im Sommer 2024 hat unser Projekt "Forschung" einen "schrittweisen" Ansatz gewählt, der sich auf die Erstellung längerer Berichte konzentriert. Es beginnt mit der gleichzeitigen Erstellung des Inhaltsverzeichnisses (TOC) des Berichts, gefolgt von der gleichzeitigen Erstellung des Inhalts aller Kapitel. Schließlich wird jedes Kapitel asynchron schrittweise überarbeitet, wobei jede Überarbeitung den Gesamtinhalt des Berichts berücksichtigt. Im obigen Demo-Video wurde die Abfrage "Competitive Analysis for Jina AI" verwendet.
DeepSearch vs. DeepResearch
Viele Menschen neigen dazu, DeepSearch mit DeepResearch zu verwechseln. Aber unserer Meinung nach lösen sie völlig unterschiedliche Probleme.DeepSearch ist der Baustein von DeepResearch, dem Kernstück, auf dem DeepResearch läuft.
Der Schwerpunkt von DeepResearch liegt auf der Erstellung von qualitativ hochwertigen, gut lesbaren Forschungsberichten.Es geht nicht nur um die Suche nach Informationen, es ist ein systematisches ProjektDas DeepSearch-Projekt wurde als hocheffektives Werkzeug für die Suchfunktion konzipiert, was die Integration effektiver Visualisierungselemente (z. B. Diagramme, Tabellen), eine logische Kapitelstruktur, die einen reibungslosen Fluss zwischen den Unterkapiteln gewährleistet, eine konsistente Terminologie im gesamten Text, die Vermeidung von Informationsredundanz und die Verwendung von fließenden Übergängen zur Verknüpfung der Kontexte erfordert. Diese Elemente stehen nicht in direktem Zusammenhang mit der zugrunde liegenden Suchfunktionalität, weshalb wir uns mehr auf DeepSearch als Unternehmen konzentrieren.
Die Unterschiede zwischen DeepSearch und DeepResearch sind in der nachstehenden Tabelle zusammengefasst. Es ist erwähnenswert, dassSowohl DeepSearch als auch DeepResearch sind untrennbar mit langen Kontext- und Inferenzmodellen verbunden, allerdings aus leicht unterschiedlichen Gründen.
DeepResearch benötigt einen langen Kontext, um lange Berichte zu erstellen, was verständlich ist. Und obwohl DeepSearch als Suchwerkzeug erscheint, muss es sich auch an frühere Suchversuche und Webseiteninhalte erinnern, um nachfolgende Operationen zu planen, weshalb lange Kontexte ebenso wichtig sind.

Verstehen der DeepSearch-Implementierung
Open Source Link: https://github.com/jina-ai/node-DeepResearch
Das Herzstück von DeepResearch ist der Mechanismus des Zirkelschlusses. Anders als die meisten RAG-Systeme, die versuchen, Fragen in einem Schritt zu beantworten, verwenden wir eine iterative Schleife. Es wird so lange nach Informationen gesucht, relevante Quellen gelesen und Schlussfolgerungen gezogen, bis es eine Antwort findet oder das Token-Budget erschöpft ist. Hier ist ein komprimiertes Skelett dieser großen while-Schleife:
// 主推理循环
while (tokenUsage < tokenBudget && badAttempts <= maxBadAttempts) {
// 追踪进度
step++; totalStep++;// Holen Sie die aktuelle Ausgabe aus der Lücken-Warteschlange, oder verwenden Sie die ursprüngliche Ausgabe, wenn diese nicht verfügbar ist
const currentQuestion = gaps.length > 0 ? gaps.shift() : question;/
/ Generierung von Prompts basierend auf dem aktuellen Kontext und den erlaubten Aktionen
system = getPrompt(diaryContext, allQuestions, allKeywords.
allowReflect, allowAnswer, allowRead, allowSearch, allowCoding.
badContext, allKnowledge, unvisitedURLs);/
/ LLM soll entscheiden, wie es weitergeht
const result = await LLM.generateStructuredResponse(system, messages, schema);
thisStep = result.object;/
/ Ausgewählte Aktionen ausführen (antworten, nachdenken, suchen, besuchen, codieren)
if (thisStep.action === 'answer') {
// Antwortaktionen verarbeiten...
} else if (thisStep.action === 'reflect') {
// Verarbeitung reflektierender Aktionen...
} // ... Und so weiter für die anderen Aktionen
Um die Stabilität und Struktur des Outputs zu gewährleisten, wurde eine wichtige Maßnahme getroffen:Selektives Deaktivieren bestimmter Vorgänge bei jedem Schritt.
So deaktivieren wir beispielsweise die Operation "visit", wenn keine URL im Speicher vorhanden ist, und wir verhindern, dass der Agent die Operation "answer" sofort wiederholt, wenn die letzte Antwort abgelehnt wurde. Dieser Mechanismus lenkt den Agenten in die richtige Richtung und verhindert, dass er sich immer wieder an der gleichen Stelle befindet.
System-Hinweis
Für die Gestaltung der Systemansagen verwenden wir XML-Tags, um die verschiedenen Teile zu definieren, was es uns ermöglicht, robustere Systemansagen und generierte Inhalte zu erstellen. Gleichzeitig haben wir festgestellt, dass direkt in den JSON-Schema's description Felder mit Feldbeschränkungen für bessere Ergebnisse. Es stimmt, dass Inferenzmodelle wie DeepSeek-R1 theoretisch die meisten Stichwörter automatisch generieren können. In Anbetracht der Beschränkungen der Kontextlänge und unseres Bedarfs an feinkörniger Kontrolle des Agentenverhaltens ist diese Art der expliziten Eingabe von Stichwörtern in der Praxis jedoch zuverlässiger.
function getPrompt(params...) {
const sections = [];// Hinzufügen einer Kopfzeile mit Systembefehlen
sections.push("Sie sind ein leitender KI-Forschungsassistent mit Spezialisierung auf mehrstufiges Denken...") ;
// Hinzufügen von akkumulierten Wissensfragmenten (falls sie existieren)
if (Wissen?.Länge) {
sections.push("[Wissenseintrag]");;
}// Hinzufügen von Kontextinformationen für vorherige Aktionen
if (context?.length) {
sections.push("[Action History]");;
}
// Fehlversuche und erlernte Strategien hinzufügen
if (badContext?.length) {
sections.push("[Fehlversuche]");;
sections.push("[verbesserte Strategie]");;
}
// Definition der verfügbaren Aktionsoptionen auf der Grundlage des aktuellen Zustands
sections.push("[verfügbare Aktionsdefinitionen]");;
// Anweisungen zur Formatierung der Antwort hinzufügen
sections.push("Bitte antworten Sie in einem gültigen JSON-Format, das dem JSON-Schema genau entspricht.");;
return abschnitte.join("nn");
}
Überwindung des Problems der Wissenslücke
In DeepSearch wird dieEine "Wissenslückenfrage" bezieht sich auf eine Wissenslücke, die der Agent schließen muss, bevor er die Kernfrage beantworten kann.Anstatt zu versuchen, die ursprüngliche Frage direkt zu beantworten, identifiziert und löst der Agent Teilfragen, die die notwendige Wissensbasis bilden.
Das ist eine sehr elegante Art, damit umzugehen.
// 在“反思行动”中识别出知识空白问题后
if (newGapQuestions.length > 0) {
// 将新问题添加到队列的头部
gaps.push(...newGapQuestions);// Fügen Sie die ursprüngliche Frage immer an das Ende der Warteschlange an.
gaps.push(originalQuestion);
}
Er erstellt eine FIFO-Warteschlange (First In First Out) mit einem Rotationsmechanismus, der den folgenden Regeln folgt:
- Neue Fragen mit Wissenslücken werden nach Priorität geordnet und an den Anfang der Warteschlange gestellt.
- Die ursprüngliche Frage steht immer am Ende der Warteschlange.
- Das System extrahiert bei jedem Schritt Ausgaben aus dem Queue-Kopf zur Bearbeitung.
Der Clou dieses Konzepts ist, dass es einen gemeinsamen Kontext für alle Probleme aufrechterhält. Das heißt, wenn ein Problem mit einer Wissenslücke gelöst wird, kann das gewonnene Wissen sofort auf alle nachfolgenden Probleme angewendet werden und wird uns schließlich helfen, auch das ursprüngliche Problem zu lösen.
FIFO-Warteschlange vs. Rekursion
Zusätzlich zu den FIFO-Warteschlangen können wir auch Rekursion verwenden, was einer Deep-First-Suchstrategie entspricht. Bei der Rekursion wird für jedes "Wissenslückenproblem" ein völlig neuer Aufrufstapel mit einem eigenen Kontext erstellt. Das System muss jedes Wissenslückenproblem (und alle seine potenziellen Unterprobleme) vollständig lösen, bevor es zum übergeordneten Problem zurückkehrt.
Ein einfaches Beispiel für eine 3-stufige Rekursion von Problemen mit tiefen Wissenslücken, wobei die Zahlen in den Kreisen die Reihenfolge angeben, in der die Probleme gelöst werden.
Im rekursiven Modus muss das System Q1 (und seine möglichen abgeleiteten Teilprobleme) vollständig lösen, bevor es zu anderen Problemen übergehen kann! Dies steht im Gegensatz zum Warteschlangen-Ansatz, der nach der Bearbeitung von 3 Wissenslückenproblemen zu Q1 zurückkehren würde.
In der Praxis haben wir festgestellt, dass es bei rekursiven Methoden schwierig ist, das Budget zu kontrollieren. Da Unterprobleme immer wieder neue Unterprobleme hervorbringen können, ist es schwierig zu bestimmen, wie viel Token-Budget ihnen ohne klare Richtlinien zugewiesen werden sollte. Der Vorteil der Rekursion in Bezug auf eine klare kontextuelle Isolierung verblasst im Vergleich zur Komplexität der Budgetkontrolle und dem Potenzial für verzögerte Rückgaben. Im Gegensatz dazu sorgt das Design von FIFO-Warteschlangen für ein ausgewogenes Verhältnis zwischen Tiefe und Breite und stellt sicher, dass das System weiterhin Wissen aufbaut, sich schrittweise verbessert und schließlich zum ursprünglichen Problem zurückkehrt, anstatt tiefer in einen potenziell unendlichen Rekursionssumpf zu versinken.
Abfrage umschreiben
Eine interessante Herausforderung war die Frage, wie die Suchanfrage des Nutzers effektiv umgeschrieben werden kann:
// 在搜索行为处理器中
if (thisStep.action === 'search') {
// 搜索请求去重
const uniqueRequests = await dedupQueries(thisStep.searchRequests, existingQueries);// Umformung von Abfragen in natürlicher Sprache in effizientere Suchausdrücke
const optimisedQueries = await rewriteQuery(uniqueRequests);
// Sicherstellen, dass frühere Suchvorgänge nicht doppelt durchgeführt werden
const newQueries = await dedupQueries(optimisedQueries, allKeywords);
// Eine Suche durchführen und die Ergebnisse speichern
for (const query of newQueries) {
const results = await searchEngine(query);
if (results.length > 0) {
storeResults(Ergebnisse);
allKeywords.push(query);
}
}
}
Wir haben festgestellt, dassDas Umschreiben von Suchanfragen ist viel wichtiger als erwartet und ist wohl einer der wichtigsten Faktoren bei der Bestimmung der Qualität von Suchergebnissen.Ein guter Abfrage-Rewriter wandelt nicht nur die natürliche Sprache des Benutzers in eine Sprache um, die besser für die BM25 Die Algorithmen verarbeiten Schlüsselwortformulare, die auch die Abfrage erweitern, um mehr mögliche Antworten in verschiedenen Sprachen, Tönen und Inhaltsformaten abzudecken.
Was die Entdopplung von Abfragen betrifft, so haben wir zunächst ein LLM-basiertes Verfahren ausprobiert, mussten aber feststellen, dass es schwierig war, den Ähnlichkeitsschwellenwert genau zu steuern, und die Ergebnisse nicht zufriedenstellend waren. Schließlich entschieden wir uns für das jina-embeddings-v3. Dank seiner hervorragenden Leistung bei der semantischen Textähnlichkeitsaufgabe konnten wir problemlos eine sprachübergreifende Deduplizierung erreichen, ohne uns Sorgen machen zu müssen, dass nicht-englische Abfragen durch falsch-positive Ergebnisse gefiltert werden. Zufälligerweise war es das Einbettungsmodell, das letztendlich eine Schlüsselrolle spielte. Wir hatten zunächst nicht vor, es für das In-Memory-Retrieval zu verwenden, aber wir waren überrascht, dass es bei der Deduplizierungsaufgabe sehr effizient arbeitete.
Crawling von Webinhalten
Das Crawlen von Webseiten und die Verarbeitung von Inhalten ist ebenfalls ein wichtiger Teil des Prozesses, bei dem wir die Jina Leser Zusätzlich zum vollständigen Inhalt der Webseite sammeln wir zusammenfassende Ausschnitte, die von der Suchmaschine zurückgegeben werden, als unterstützende Informationen für nachfolgende Überlegungen. Diese Schnipsel können als kurze Zusammenfassung des Webseiteninhalts betrachtet werden.
// 访问行为处理器
async function handleVisitAction(URLs) {
// 规范化并过滤已访问过的 URL
const uniqueURLs = normalizeAndFilterURLs(URLs);// Parallele Verarbeitung jeder URL
const results = await Promise.all(uniqueURLs.map(async url => {
versuchen {
// Abrufen und Extrahieren des Inhalts
const content = await readUrl(url);
// Als Wissen gespeichert
addToKnowledge(`Was ist in ${url}? `, Inhalt, [url], 'url');
return {url, success: true};
} catch (Fehler) {
return {url, success: false};
} finally {
visitedURLs.push(url);
}
}));
// Protokolle auf der Grundlage der Ergebnisse aktualisieren
updateDiaryWithVisitResults(results).
}
Um die Nachverfolgung zu erleichtern, normalisieren wir die URLs und begrenzen die Anzahl der URLs, auf die pro Schritt zugegriffen wird, um den Speicherbedarf des Agenten zu kontrollieren.
Speicherverwaltung
Eine zentrale Herausforderung bei mehrstufigen Schlussfolgerungen ist die effiziente Verwaltung des Speichers der Agenten. Das von uns entwickelte Speichersystem unterscheidet zwischen dem, was als "Speicher" und was als "Wissen" zählt. Aber in jedem Fall sind sie alle Teil des Kontexts des LLM-Hinweises, getrennt durch verschiedene XML-Tags:
// 添加知识条目
function addToKnowledge(question, answer, references, type) {
allKnowledge.push({
question: question,
answer: answer,
references: references,
type: type, // 'qa', 'url', 'coding', 'side-info'
updated: new Date().toISOString()
});
}// Schritte in das Protokoll aufnehmen
function addToDiary(step, action, question, result, evaluation) {
diaryContext.push(`
In Schritt ${Schritt} haben Sie **${Aktion}** auf die Frage: "${Frage}" durchgeführt.
[Einzelheiten und Ergebnisse] [Bewertung (falls zutreffend)] `); und
}
In Anbetracht des Trends zu sehr langen Kontexten im LLM 2025 haben wir uns entschieden, auf Vektordatenbanken zu verzichten und stattdessen einen kontextuellen Gedächtnisansatz zu verwenden: Das Gedächtnis des Agenten besteht aus drei Teilen innerhalb eines Kontextfensters: erworbenes Wissen, besuchte Websites und Protokolle fehlgeschlagener Versuche. Dieser Ansatz ermöglicht es dem Agenten, während des Denkprozesses ohne zusätzliche Abrufschritte direkt auf die komplette Historie und den Wissensstand zuzugreifen.
Bewertung der Antworten
Wir fanden auch heraus, dass die Generierung und Bewertung von Antworten besser gelang, wenn sie in verschiedenen Stichwörtern untergebracht wurden.Wenn wir eine neue Frage erhalten, ermitteln wir zunächst die Bewertungskriterien und bewerten sie dann von Fall zu Fall. Der Bewerter zieht eine kleine Anzahl von Beispielen zur Konsistenzbewertung heran, was zuverlässiger ist als eine Selbsteinschätzung.
// 独立评估阶段
async function evaluateAnswer(question, answer, metrics, context) {
// 根据问题类型确定评估标准
const evaluationCriteria = await determineEvaluationCriteria(question);// Bewerten Sie jedes Kriterium einzeln
const results = [];
for (const criterion of evaluationCriteria) {
const result = await evaluateSingleCriterion(criterion, question, answer, context);
results.push(result);
}
// Feststellen, ob die Antwort die Gesamtbewertung besteht
zurück {
pass: results.every(r => r.pass),
think: results.map(r => r.reasoning).join('n')
};
}
Haushaltskontrolle
Bei der Haushaltskontrolle geht es nicht nur um Kosteneinsparungen, sondern auch darum, sicherzustellen, dass das System Probleme angemessen angeht, bevor das Budget aufgebraucht ist, und zu vermeiden, dass vorschnell Antworten gegeben werden.Seit der Veröffentlichung von DeepSeek-R1 hat sich unser Denken über die Budgetkontrolle von der einfachen Einsparung von Budgets hin zur Förderung eines tieferen Denkens und dem Streben nach qualitativ hochwertigen Antworten verschoben.
In unserer Implementierung fordern wir das System ausdrücklich auf, Wissenslücken zu erkennen, bevor es versucht, eine Antwort zu geben.
if (thisStep.action === 'reflect' && thisStep.questionsToAnswer) {
// 强制深入推理,添加子问题
gaps.push(...newGapQuestions);
gaps.push(question); // 别忘了原始问题
}
Indem wir die Flexibilität haben, bestimmte Aktionen zu aktivieren und zu deaktivieren, können wir das System anweisen, Werkzeuge zu verwenden, die das Denken vertiefen.
// 在回答失败后
allowAnswer = false; // 强制代理进行搜索或反思
Um zu vermeiden, dass Token für ungültige Wege verschwendet werden, begrenzen wir die Anzahl der Fehlversuche. Wenn wir uns der Budgetgrenze nähern, aktivieren wir den "Beast Mode", um sicherzustellen, dass wir trotzdem eine Antwort geben und nicht mit leeren Händen nach Hause gehen.
// 启动野兽模式
if (!thisStep.isFinal && badAttempts >= maxBadAttempts) {
console.log('Enter Beast mode!!!');// Konfigurieren Sie Eingabeaufforderungen, um entscheidende Antworten zu erhalten.
system = getPrompt(
diaryContext, allQuestions, allKeywords.
false, false, false, false, false, false, // andere Vorgänge deaktivieren
badContext, allKnowledge, unvisitedURLs.
true // Beast-Modus aktivieren
);
// Erzwingen Sie die Erstellung von Antworten
const result = await LLM.generateStructuredResponse(system, messages, answerOnlySchema);
thisStep = result.object;
thisStep.isFinal = true;
}
Die Beast-Mode-Eingabeaufforderung ist absichtlich überspitzt formuliert und weist den LLM ausdrücklich darauf hin, dass jetzt eine entscheidende Entscheidung getroffen werden muss, um eine Antwort auf der Grundlage der verfügbaren Informationen zu geben!
<action-answer>
🔥 启动最高战力! 绝对优先! 🔥Oberste Direktive:
- Beseitigen Sie jedes Zögern! Es ist besser, eine Antwort zu geben, als zu schweigen!
- Es kann eine lokalisierte Strategie verfolgt werden - unter Verwendung aller bekannten Informationen!
- Lassen Sie die Wiederverwendung früherer Fehlversuche zu!
- Wenn Sie sich nicht entscheiden können: Schlagen Sie auf der Grundlage der verfügbaren Informationen entschlossen zu!
Scheitern ist keine Option! Seien Sie sicher, dass Sie Ihre Ziele erreichen! ⚡️
</action-answer>
Damit ist sichergestellt, dass wir auch bei schwierigen oder vagen Fragen eine brauchbare Antwort geben können und nicht nichts.
zu einem Urteil gelangen
DeepSearch kann als ein wichtiger Durchbruch in der Suchtechnologie bei der Bearbeitung komplexer Anfragen bezeichnet werden. Es unterteilt den gesamten Prozess in unabhängige Such-, Lese- und Schlussfolgerungsschritte und überwindet damit viele der Einschränkungen herkömmlicher RAG- oder Multi-Hop-Q&A-Systeme mit nur einer Runde.
Während des Entwicklungsprozesses haben wir ständig darüber nachgedacht, wie die künftige Suchtechnologiebasis im Jahr 2025 angesichts der drastischen Veränderungen in der gesamten Suchbranche nach der Veröffentlichung von DeepSeek-R1 aussehen sollte. Welche neuen Bedürfnisse tauchen auf? Welche Bedürfnisse sind obsolet? Welche Bedürfnisse sind eigentlich Pseudo-Bedürfnisse?
Rückblickend auf die DeepSearch-Implementierung haben wir sorgfältig ermittelt, was erwartet wurde und wesentlich war, was wir für selbstverständlich hielten und nicht wirklich brauchten und was wir überhaupt nicht erwartet hatten, sich aber als entscheidend herausstellte.
Erstens.Ein LLM mit langem Kontext, der Ausgaben in einem kanonischen Format (z. B. JSON-Schema) erzeugt, ist unerlässlich!. Möglicherweise ist auch ein Inferenzmodell erforderlich, um die Schlussfolgerungen aus Aktionen und die Erweiterung von Abfragen zu verbessern.
Auch Abfrageerweiterungen sind unbedingt erforderlichob mit SLM, LLM oder speziellen Inferenzmodellen implementiert, ist ein unausweichlicher Teil des Prozesses. Nach der Durchführung dieses Projekts wurde uns jedoch klar, dass SLM für diese Aufgabe möglicherweise nicht gut geeignet ist, da die Abfrageerweiterung von Natur aus mehrsprachig sein muss und sich nicht auf die einfache Ersetzung von Synonymen oder die Extraktion von Schlüsselwörtern beschränken kann. Sie muss umfassend genug sein, um eine Token-Basis zu haben, die mehrere Sprachen abdeckt (so dass die Skalierung leicht 300 Millionen Parameter erreichen kann), und sie muss intelligent genug sein, um über den Tellerrand zu schauen. Die Skalierung von Abfragen durch SLM allein kann also nicht funktionieren.
Web-Such- und Web-Lesefähigkeiten haben zweifellos oberste Priorität!Glücklicherweise hat sich unser [Reader (r.jina.ai)] sehr gut bewährt und ist nicht nur leistungsstark, sondern auch gut erweiterbar, was mich dazu inspiriert hat, darüber nachzudenken, wie wir unseren Such-Endpunkt verbessern können (s.jina.ai) gibt es viele Anregungen, die bei der nächsten Iteration optimiert werden können.
Vektormodelle sind nützlich, werden aber an völlig unerwarteten Stellen eingesetzt. Ursprünglich dachten wir, es würde für die Abfrage im Speicher oder in Verbindung mit einer Vektordatenbank zur Komprimierung des Kontexts verwendet werden, aber beides erwies sich als nicht notwendig. Letztendlich fanden wir heraus, dass es am besten funktioniert, das Vektormodell für die Deduplizierung zu verwenden, im Wesentlichen eine STS-Aufgabe (Semantic Text Similarity). Da die Anzahl der Abfragen und Wissenslücken in der Regel im Bereich von Hunderten liegt, ist es vollkommen ausreichend, die Kosinusähnlichkeit direkt im Speicher zu berechnen, ohne eine Vektordatenbank zu verwenden.
Wir haben das Reranker-Modell nicht verwendetDas Embeddings- und Rerankermodell kann theoretisch als Hilfsmittel verwendet werden, um zu bestimmen, welche URLs auf der Grundlage der Anfrage, des URL-Titels und des Zusammenfassungs-Snippets für den Zugriff priorisiert werden sollten. Für die Modelle Embeddings und Reranker ist die Mehrsprachigkeit eine Grundvoraussetzung, da Anfragen und Fragen mehrsprachig sind. Eine lange Kontextverarbeitung ist für die Modelle Embeddings und Reranker hilfreich, aber nicht entscheidend. Bei der Verwendung von Vektoren sind wir auf keine Probleme gestoßen, was wahrscheinlich darauf zurückzuführen ist, dass die jina-embeddings-v3 (eine hervorragende Kontextlänge von 8192 Token). Zusammenfassend lässt sich sagen, dass diejina-embeddings-v3 im Gesang antworten jina-reranker-v2-base-multilingual Sie sind immer noch meine erste Wahl, da sie mehrsprachige Unterstützung, SOTA-Leistung und eine gute Handhabung von langem Kontext bieten.
Der Agent-Rahmen hat sich letztendlich als unnötig erwiesen. Das Vercel AI SDK bietet viel Komfort bei der Anpassung an verschiedene LLM-Anbieter, was den Entwicklungsaufwand erheblich reduziert, da nur eine Zeile Code geändert werden muss, um ein neues LLM in der Software zu erstellen. Zwillinge Umschalten zwischen Studio, OpenAI und Google Vertex AI. Die Proxy-Speicherverwaltung ist sinnvoll, aber die Einführung eines speziellen Frameworks dafür ist fragwürdig. Ich persönlich bin der Meinung, dass eine übermäßige Abhängigkeit von Frameworks eine Barriere zwischen LLM und dem Entwickler aufbauen kann, und der syntaktische Zucker, den sie bieten, kann zu einer Belastung für den Entwickler werden. Viele LLM/RAG-Frameworks haben dies bereits bewiesen. Es ist klüger, sich die nativen Fähigkeiten des LLM zu eigen zu machen und sich nicht von Frameworks einschränken zu lassen.
Dieser Beitrag ist von WeChat: Jina AI
© urheberrechtliche Erklärung
Artikel Copyright AI-Austauschkreis Alle, bitte nicht ohne Erlaubnis vervielfältigen.
Ähnliche Artikel


Keine Kommentare...