Deep Research Technology Inventory! Ein Paradigma für LLM-Anwendungen, das weiter fortgeschritten ist als RAGs
Nachdem das Deep-Research-Tool von OpenAI aus dem Nichts auftauchte, brachten alle großen Anbieter ihre eigenen Deep-Research-Tools auf den Markt. Die so genannte Tiefenforschung wird mit einer gewöhnlichen Suche verglichen, bei der eine einfache RAG-Suche in der Regel nur eine Suchrunde erzeugt. Deep Research kann jedoch auf der Grundlage eines Themas suchen, analysieren, abrufen und erneut analysieren, genau wie ein Mensch, bis es das Forschungsziel erreicht. Aus dieser Sicht handelt es sich im Wesentlichen um eine verbesserte Version der RAG-Anwendung, die Verwendung von ReAct/Plan And Solve und anderen Konstruktionsmodi des Pendant Domain Agent, mit der Artikelzerlegung, Planung und Erzeugung, Informationsbeschaffung und Analysefähigkeiten.
Im Prinzip ist es sehr einfach, aber wollen eine private zu erreichen, um ihre eigenen geschäftlichen Anforderungen des fertigen Produkts zu erfüllen, die eigentliche Engineering-Details sowie die Wirkung der Optimierung ist recht komplex, so dass einige Gerüste des Projekts oder fertige Produkt-Entwicklungsplattform ist besonders wichtig, die die gleiche wie die RAG ist, wird es mehr und mehr solcher Entwicklungsrahmen erscheinen.
Heute, bei der Einführung von mehreren Deep Research Open-Source-Implementierung, im Namen der beiden Ideen für die Umsetzung, ist man auf der Grundlage der bestehenden Orchestrierung Framework-Implementierung, wie Langchain Langgraph, der andere ist speziell für die Merkmale der tiefen Forschung Entwicklung. Durch sie können nicht nur schnell bauen tiefe Forschung Anwendungen, sondern auch die Details der Umsetzung dieser Rahmen und spezifische Auswahl, wie z. B. was zu suchen, was zu verwenden Lagerung, was ist die Aufforderung Wort, etc. zu verstehen, die für unsere eigene Umsetzung der Referenzrolle sehr nützlich ist.
1. langchain Open DeepResearch
Es ist eine offizielle Demo-Implementierung von LangChain, die auf dem LangGraph Erstellen Sie den gesamten Verarbeitungsablauf. Durch die Integration mehrerer APIs wie z.B. Tavily , Perplexity, ermöglicht die Suche und das Sammeln von Informationen. Die Benutzer können die Tiefe der Suche für jedes Kapitel festlegen, einschließlich der Anzahl der Iterationen für das Schreiben, Nachdenken, Suchen und Umschreiben, sowie Feedback zum Plan für das Berichtskapitel geben und iterieren, bis sie zufrieden sind.
 Verwendete Aufforderung: https://github.com/langchain-ai/open_deep_research/blob/main/src/open_deep_research/prompts.py
Verwendete Aufforderung: https://github.com/langchain-ai/open_deep_research/blob/main/src/open_deep_research/prompts.py
Projektadresse: https://github.com/langchain-ai/open_deep_research同类型的有Dify等框架编排的Deep Forschungsantrag.
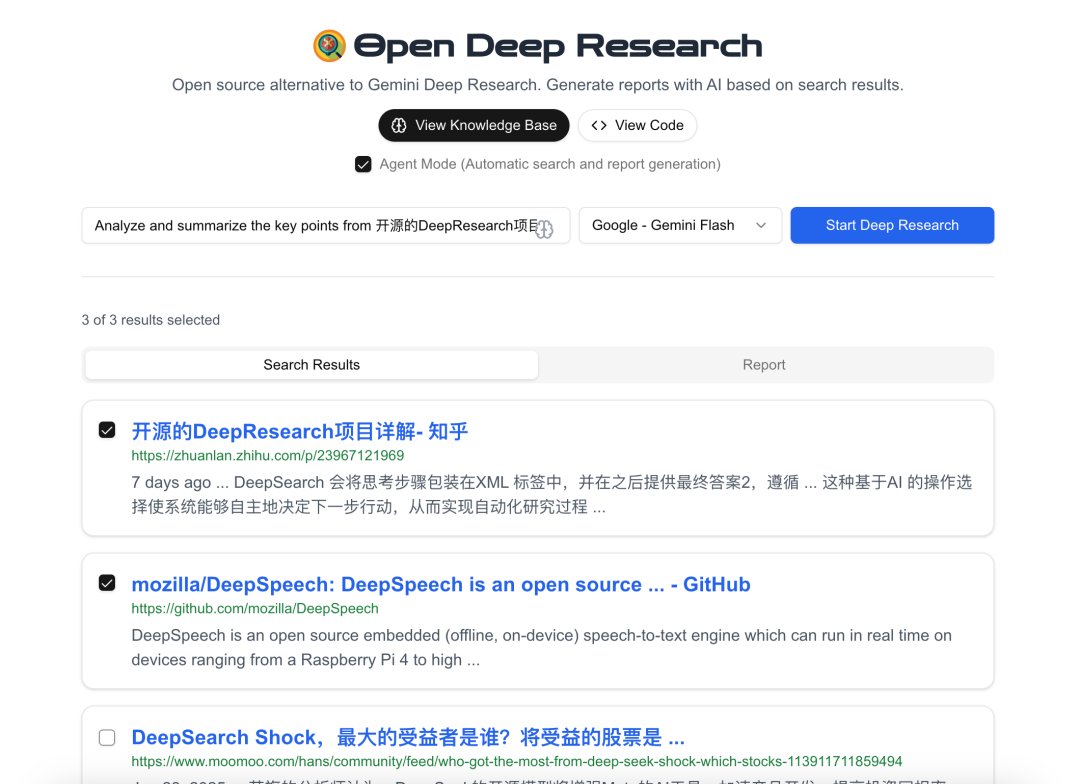
2. offene Tiefenforschung
Open Deep Research ist eine von vielen Klempner-Implementierungen. Sie dekonstruiert den DeepSearch-Prozess und unterstützt automatische und halbautomatische Rechercheprozesse. Durch die Unterstützung einer Vielzahl von API-Schnittstellen ist es nicht nur in der Lage, Informationen aus dem Extranet abzurufen, sondern auch unternehmensinterne Informationen für zusammenfassende Analysen abzurufen. Die Benutzer können je nach Bedarf verschiedene KI-Plattformen wählen, darunter Google, OpenAI, Anthropic, DeepSeek usw., und können sogar auf lokale Modelle zugreifen, um eine personalisierte Recherche durchzuführen.
Er enthält die drei Schritte des Deep ReSearch-Standards:
- Abruf von Suchergebnissen: Erhalten Sie umfassende Suchergebnisse für bestimmte Suchbegriffe über die benutzerdefinierte Google-Suche oder die Bing Search API (konfigurierbar).

- Inhaltsextraktion: JinaAI wird verwendet, um den Inhalt ausgewählter Suchergebnisse zu extrahieren und zu verarbeiten, um die Richtigkeit und Relevanz der Informationen sicherzustellen.
- Erstellung von Berichten: unter Verwendung vom Benutzer ausgewählter AI-Modelle (z. B. Zwillinge (GPT-4, Sonnet usw.) erstellt detaillierte Berichte über die gesammelten Suchergebnisse und die extrahierten Inhalte und bietet detaillierte Analysen und Einblicke in benutzerdefinierte Suchanfragen.
Nachfolgend sehen Sie die Eingabeaufforderung, die zur Erstellung des Berichts verwendet wird:
You are a research assistant tasked with creating a comprehensive report based on multiple sources.
The report should specifically address this request: "${userPrompt}"
Your report should:
1. Have a clear title that reflects the specific analysis requested
2. Begin with a concise executive summary
3. Be organized into relevant sections based on the analysis requested
4. Use markdown formatting for emphasis, lists, and structure
5. Integrate information from sources naturally without explicitly referencing them by number
6. Maintain objectivity while addressing the specific aspects requested in the prompt
7. Compare and contrast the information from each source, noting areas of consensus or points of contention.
8. Showcase key insights, important data, or innovative ideas.
Here are the source articles to analyze:
${articles
.map(
(article) => `
Title: ${article.title}
URL: ${article.url}
Content: ${article.content}
---
`
)
.join('n')}
Format the report as a JSON object with the following structure:
{
"title": "Report title",
"summary": "Executive summary (can include markdown)",
"sections": [
{
"title": "Section title",
"content": "Section content with markdown formatting"
}
]
}
Use markdown formatting in the content to improve readability:
- Use **bold** for emphasis
- Use bullet points and numbered lists where appropriate
- Use headings and subheadings with # syntax
- Include code blocks if relevant
- Use > for quotations
- Use --- for horizontal rules where appropriate
Important: Do not use phrases like "Source 1" or "According to Source 2". Instead, integrate the information naturally into the narrative or reference sources by their titles when necessary.
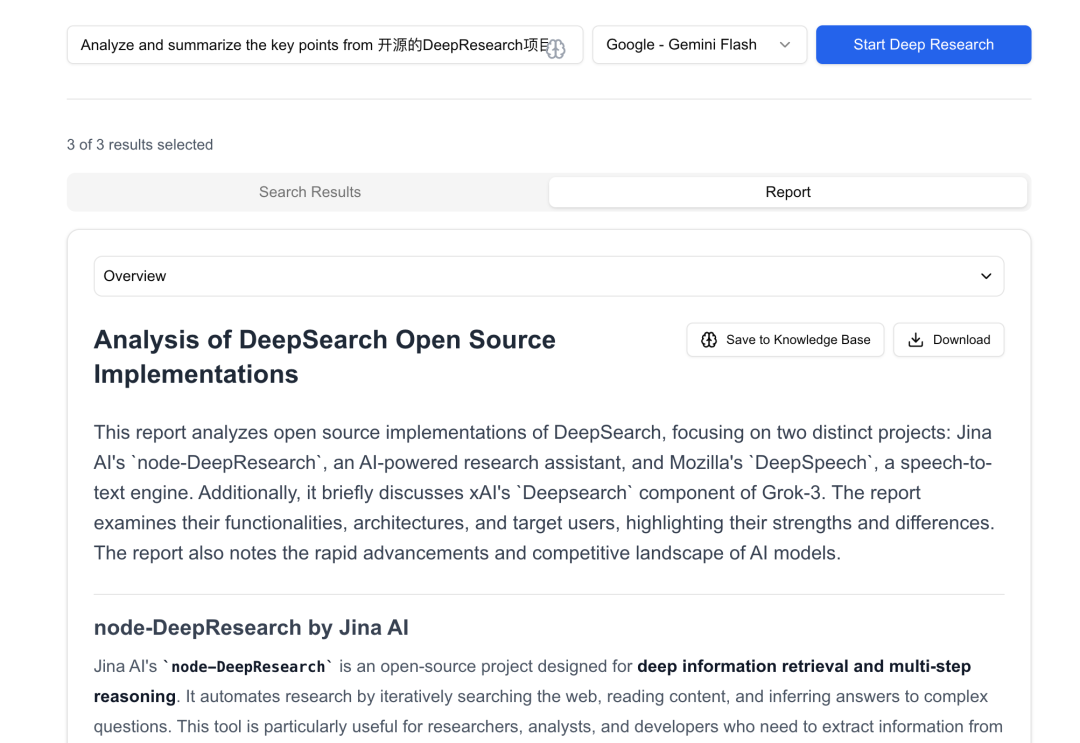
Der erstellte Bericht kann heruntergeladen oder in der Wissensdatenbank gespeichert werden, aber er verfügt nicht über ausreichend hochwertige Suchquellen und es fehlt an Forschungsvalidierung und iterativen Prozessen, so dass es noch Raum für Qualitätsverbesserungen gibt, aber der Gesamtprozess ist klar und gut geeignet, um auf dieser Grundlage der kontinuierlichen Verbesserung und Verfeinerung aufzubauen.
Projektadresse: https://github.com/btahir/open-deep-research
Der gleiche Typ ist auch erhältlich:
https://github.com/nickscamara/open-deep-research (4.3k)
https://github.com/mshumer/OpenDeepResearcher (2.2k)
https://github.com/assafelovic/gpt-researcher (19k)
https://github.com/zaidmukaddam/scira (6.4k)
https://github.com/jina-ai/node-DeepResearch (2.6k)
Unter ihnen, node-DeepResearch für jina's Open-Source-Implementierung tiefe Forschung, können Sie direkt seine api, und andere Modell-Schnittstellen sind so einfach zu bedienen, können Sie schnell in ihre eigenen Anwendungen zu integrieren.
kurz
Wie zu Beginn des Artikels erwähnt, ist Deep Research das Ergebnis der Entwicklung der Nachfrage des Nutzers nach einem qualitativ hochwertigen Zugang zu Inhalten, der den Informationskokon der passiven Empfehlung durchbricht und die traditionelle Suche und Zusammenfassung aufgibt, um dann den ineffizienten Prozess zu suchen und zusammenzufassen, auch durch Automatisierung. Entsprechend dieser Entwicklungsrichtung wird die Art und Weise des Erwerbs von Inhalten neue Veränderungen erfahren, was eine große Herausforderung für die traditionelle Suchempfehlung darstellt.
© urheberrechtliche Erklärung
Artikel Copyright AI-Austauschkreis Alle, bitte nicht ohne Erlaubnis vervielfältigen.
Ähnliche Artikel



Keine Kommentare...