
Wie berechnet man die Anzahl der Parameter für ein großes Modell, und was bedeuten 7B, 13B und 65B?
In letzter Zeit haben viele Personen, die sich mit dem Training und der Inferenz großer Modelle beschäftigen, die Beziehung zwischen der Anzahl der Modellparameter und der Modellgröße diskutiert. Die berühmte Alpaka-Serie der LLaMA-Großmodelle enthält beispielsweise vier Versionen mit unterschiedlichen Parametergrößen: LLaMA-7B, LLaMA-13B, LLaMA-33B und LLaMA-65B.
Das "B" ist hier eine Abkürzung für "Billion", was für Milliarde steht. So enthält das kleinste LLaMA-7B-Modell etwa 7 Milliarden Parameter, während das größte LLaMA-65B-Modell etwa 65 Milliarden Parameter enthält.
Wie werden diese Parameterzahlen also berechnet? Und wie hoch ist die ungefähre Anzahl der Parameter eines großen Modells, die einer 100 GB großen Modelldatei entspricht? Milliarden, Dutzende von Milliarden, Hunderte von Milliarden oder Billionen? In diesem Papier werden diese Fragen eingehend beantwortet.
I. Methoden zur Berechnung großer Modellparametermengen
Wir werden den Transformer, die Infrastruktur des großen Modells, als Beispiel nehmen, um den Prozess der Parameterzählung im Detail zu analysieren.
Eine Norm Transformator Das Modell besteht aus L identischen Schichten, die übereinander gestapelt sind, und jede Schicht enthält zwei Hauptbestandteile: die Selbstbeobachtungsschicht (SAL) und die Feed-Forward-Schicht des neuronalen Netzes (MLP).
1. die Selbstaufmerksamkeit
Der Selbsthaltemechanismus ist das Herzstück des Transformators. Unabhängig davon, ob es sich um Selbsthaltung oder Mehrkopf-Selbsthaltung (MHA) handelt, ist die Berechnung der Kernparametermenge gleich.
In der Selbstbeobachtungsschicht wird die Eingabesequenz zunächst in drei Vektoren abgebildet: einen Abfragevektor (Query, Q), einen Schlüsselvektor (Key, K) und einen Wertvektor (Value, V). In der MHA werden diese drei Vektoren weiter in mehrere Köpfe aufgeteilt, von denen jeder für einen anderen Teil der Eingabesequenz zuständig ist.

- Selbstbeobachtung mit einem Kopf. Q, K, V werden jeweils durch eine Gewichtsmatrix der Form [h, h] linear transformiert, wobei h die Dimension der verborgenen Schicht ist. Somit beträgt die Gesamtzahl der Parameter von Q, K, V 3h². Darüber hinaus gibt es eine lineare Transformationsschicht für die Ausgabe mit der gleichen Gewichtsmatrix der Form [h, h]. Daher ist die Gesamtzahl der Parameter für die einköpfige Selbstbeobachtung 4h² (ignorieren Sie den Begriff der Verzerrung).
- Mehrköpfige Aufmerksamkeit (MHA). Angenommen, es gibt n_Köpfe, jeder mit der Dimension h_Kopf = h / n_Kopf. Jeder Kopf hat eine eigene Q, K, V-Gewichtsmatrix der Form [h, h_Kopf]. Daher ist die parametrische Größe der Q, K, V-Gewichtungsmatrix für jeden Kopf 3 * h * h_head = 3h²/n_head. Die Gesamtzahl der parametrischen Größen für die n_head-Köpfe ist n_head * (3h²/n_head) = 3h². Schließlich ist die Form der linearen Transformations-Gewichtsmatrix für die Ausgangsschicht [h, h]. Die Gesamtzahl der Parameter in der MHA ist also auch 4h² (ignorieren Sie den Begriff der Verzerrung).
Daher kann die Anzahl der Parameter in der Selbstbehauptungsschicht mit 4h² angenähert werden, sowohl für einzelne als auch für mehrere Köpfe.
2. vorwärtsgerichtete neuronale Netzschicht (MLP)
Die MLP-Schicht besteht aus zwei linearen Schichten. Die erste lineare Schicht erweitert die Dimension h der verborgenen Schicht auf 4h, und die zweite lineare Schicht reduziert die Dimension von 4h wieder auf h.

- Die Gewichtsmatrix der ersten linearen Schicht hat die Form [h, 4h] und die Anzahl der Parameter beträgt 4h².
- Die zweite lineare Schicht hat eine Gewichtsmatrix der Form [4h, h] mit der gleichen parametrischen Größe von 4h².
Die Gesamtzahl der Parameter in der MLP-Schicht beträgt also 8h² (ohne Berücksichtigung des Bias-Terms).
3. die Normalisierung der Ebenen
Nach jeder Self-Attention- und MLP-Schicht und nach der letzten Schicht des Transformer-Outputs wird in der Regel eine Schicht-Normalisierung durchgeführt. Jede Schicht der Normalisierung enthält zwei trainierbare Parameter:
- Skalierungsparameter (Gamma): Form ist [h].
- Übersetzungsparameter (Beta): Die Form ist [h].
Da jede Transformatorschicht zwei Schichtnormalisierungen (nach der Selbstbeobachtung bzw. dem MLP) plus eine nach der Ausgabeschicht hat, beträgt die Gesamtzahl der Schichtnormalisierungsparameter für den L-Schicht-Transformator (2L + 1) * 2h.
4. die Einbettung
Der Eingabetext muss zunächst durch die Worteinbettungsschicht in Wortvektoren umgewandelt werden. Angenommen, die Größe der Wortliste ist V und die Dimension des Wortvektors ist h, dann ist die Anzahl der Parameter der Worteinbettungsschicht Vh.
5. die Ausgabeschicht
Die Gewichtsmatrix der Ausgabeschicht wird in der Regel mit der Worteinbettungsschicht geteilt (Weight Tying), um die Anzahl der Parameter zu verringern und die Leistung zu verbessern. Wenn die Gewichtungsmatrix gemeinsam genutzt wird, führt die Ausgabeschicht daher in der Regel keine zusätzliche Anzahl von Parametern ein. Wenn sie nicht geteilt wird, ist die Anzahl der Parameter Vh.
6. positionale Kodierung
Die Positionskodierung wird verwendet, um dem Modell Informationen über die Position der Wörter in der Eingabesequenz zu liefern.
- Codes für trainierbare Positionen. Wenn trainierbare Positionskodierung verwendet wird, ist die Anzahl der Parameter N * h, wobei N die maximale Sequenzlänge ist. Die maximale Sequenzlänge von ChatGPT beträgt zum Beispiel 4k.
- Relativer Positionscode (z. B. RoPE oder ALiBi). Diese Methoden führen keine trainierbaren Parameter ein.
Aufgrund der relativ geringen Anzahl von positionskodierten Parametern sind diese in der Regel bei der Berechnung der Gesamtzahl der Parameter zu vernachlässigen.
7. die Berechnung der Gesamtzahl der Teilnehmer
Zusammenfassend lässt sich sagen, dass die Gesamtzahl der Parameter für ein L-Schicht-Transformatormodell beträgt:
Gesamtzahl der Parameter = L * (Selbstbeobachtungsparameter + MLP-Parameter + LayerNorm-Parameter * 2) + Einbettungsparameter + Ausgangsschichtparameter + LayerNorm-Parameter (nach der Ausgangsschicht)
Gesamtzahl der Parameter ≈ L * (4h² + 8h² + 4h) + Vh + (optional Vh) + 2h
Gesamtzahl der Parameter ≈ L * (12h² + 4h) + Vh + 2h (unter der Annahme, dass die Ausgabeschicht die Gewichte mit der Worteinbettungsschicht teilt)
Wenn die verborgene Dimension h groß ist, sind die primären Terme 4h und 2h vernachlässigbar und die Anzahl der Modellparameter kann weiter angenähert werden als:
Gesamtzahl der Parameter ≈ 12Lh² + Vh
8. geschätzte Anzahl der LLaMA-Teilnehmer
Die folgende Tabelle zeigt einige der Schlüsselparameter der verschiedenen LLaMA-Versionen und die Schätzung ihrer Parameterzahlen:
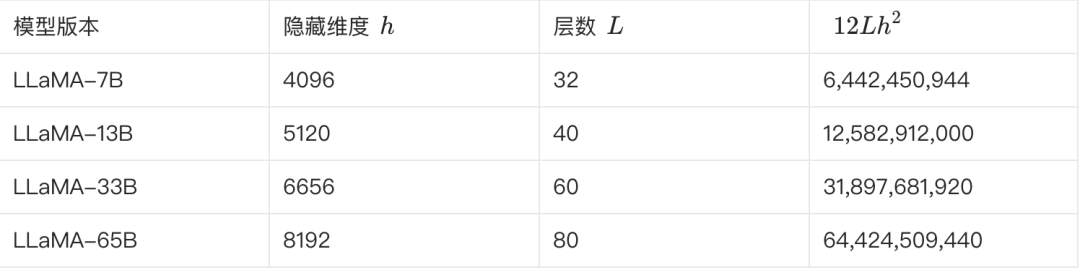
**Wir können dies anhand der obigen Formel überprüfen. Nimmt man LLaMA-7B als Beispiel, so ergibt sich aus der Tabelle: L=32, h=4096, V=32000.**
Geschätzte Anzahl der Parameter ≈ 12 * 32 * 4096² + 32000 * 4096 ≈ 6.55B
Diese Schätzung liegt näher an 6,7 B. Mehrere andere Versionen können auf diese Weise geschätzt und validiert werden.
II. die Umrechnung großer parametrischer Modellgrößen in Modellgrößen
Nachdem wir verstanden haben, wie die Anzahl der Parameter berechnet wird, sehen wir uns an, wie die Anzahl der Parameter und die Modellgröße umgerechnet werden.
Wir verwenden weiterhin LLaMA-7B als Beispiel, das etwa 7 Milliarden Teilnehmer hat.
- Theoretische Berechnungen. Wenn jeder Parameter im FP32-Format (32-Bit-Gleitkommazahl, die 4 Byte belegt) gespeichert wird, beträgt die theoretische Größe von LLaMA-7B: 7B * 4 Byte = 28 GB.
- Physische Speicherung. Um Speicherplatz zu sparen und die Berechnungseffizienz zu verbessern, werden die Modellgewichte normalerweise in einem Format mit geringerer Genauigkeit gespeichert, wie z. B. FP16 (16-Bit-Gleitkommazahl, die 2 Byte belegt) oder BF16. Bei Verwendung von FP16-Speicher beträgt die Größe von LLaMA-7B theoretisch: 7B * 2 Byte = 14 GB.
- Andere Faktoren. Zusätzlich zu den Gewichtsparametern kann die Modelldatei auch Informationen über den Zustand des Optimierers (z. B. Impuls und Varianz des Adam-Optimierers), die Wortliste, die Modellkonfiguration usw. enthalten, die zusätzlichen Speicherplatz beanspruchen. Darüber hinaus können einige Parameter (z. B. Gamma und Beta für die Schichtnormalisierung) im FP32-Format gespeichert werden.
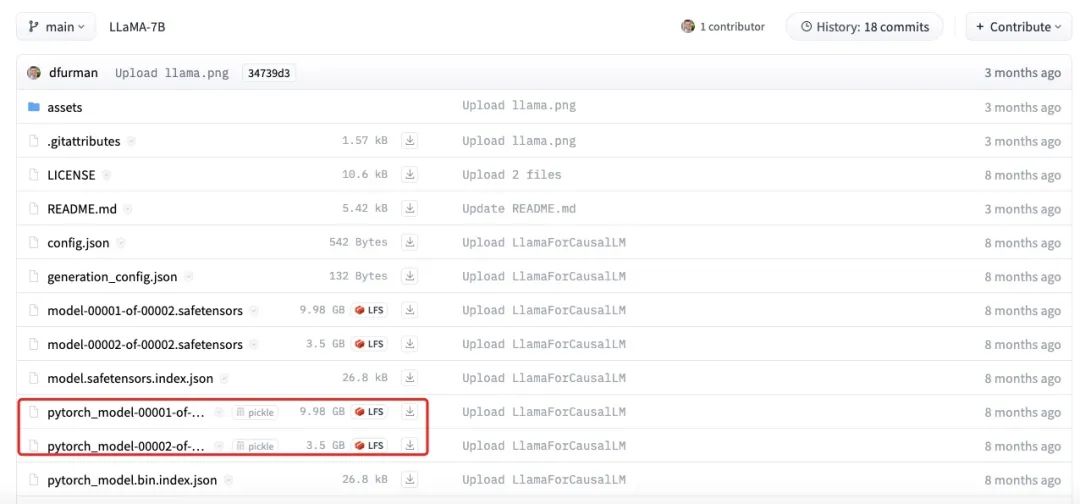
Die obige Abbildung zeigt die tatsächliche Größe der LLaMA-7B-Modelldatei. Es ist zu erkennen, dass die Gesamtgröße der einzelnen Teile etwa 13,5 GB beträgt, was näher an unserer Schätzung von 14 GB liegt. Die geringen Differenzen können durch Rundungsfehler, Bias-Parameter oder die Tatsache, dass einige Parameter immer noch in FP32 gespeichert sind, verursacht werden.
© urheberrechtliche Erklärung
Artikel Copyright AI-Austauschkreis Alle, bitte nicht ohne Erlaubnis vervielfältigen.
Ähnliche Artikel



Keine Kommentare...