Komplexes Reasoning mit großen Modellen von OpenAI-o1
Im Jahr 2022 veröffentlichte OpenAI ChatGPT, das als schnellste APP der Welt die Hunderte von Millionen von Nutzern durchbrach, und zu dieser Zeit dachten die Menschen, dass wir einer echten KI näher gekommen waren. Aber die Menschen entdeckten bald, dass ChatGPT zwar Gespräche führen und sogar Gedichte und Artikel schreiben konnte, aber bei einfacher Logik immer noch unbefriedigend war, wie z. B. die berühmte "Erdbeere" mit mehreren "r"-Stämmen darin.
Jetzt, zwei Jahre später, hat OpenAI das o1-Modell veröffentlicht, das eine hitzige Diskussion über die dahinter stehende Methodik mit ihren mächtigen logischen Schlussfolgerungen und OpenAIs mächtige Fähigkeit, Technologie zu verstecken, ausgelöst hat. In diesem Artikel haben wir einige verwandte Artikel durchforstet, um einen Blick auf die Entwicklung der komplexen Schlussfolgerungsfähigkeit großer Modelle zu werfen, wobei wir uns an den Spekulationen über die Technologie des o1-Modells orientieren.
01 Hintergrund
Chain of Thought, kurz CoT, ist ein Konzept aus der kognitiven Psychologie und Pädagogik, das den schrittweisen Prozess beschreibt, durch den sich das Denken von Menschen entwickelt, wenn sie Probleme lösen oder Entscheidungen treffen. Anstatt einfach direkt von der Frage zur Antwort zu springen, umfasst der Prozess mehrere Schritte, von denen jeder das Sammeln, Analysieren, Bewerten und Überarbeiten früherer Schlussfolgerungen beinhalten kann. Auf diese Weise ist der Einzelne in der Lage, mit komplexen Problemen systematischer umzugehen und rationale Lösungen zu entwickeln.
Überwachtes FeintuningÜberwachtes Lernen ist die häufigste Form der Modellschulung im Bereich des maschinellen Lernens. Dabei werden markierte Datensätze verwendet, aus denen das Modell lernt, um Daten genau zu klassifizieren oder Ergebnisse vorherzusagen. Während die Eingabedaten in das Modell einfließen, passt das überwachte Lernen die Gewichte des Modells an, bis das Modell eine angemessene Passung aufweist.
Supervised Fine-Tune, kurz SFT, bezieht sich auf überwachtes Lernen, bei dem wir ein Modell mit einem Datensatz trainieren, der sich auf eine bestimmte Aufgabe konzentriert, und zwar zusätzlich zu einem bestehenden Basismodell, um zu sehen, ob es in der Lage ist, daraus zu lernen, um die spezielle Aufgabe zu lösen.
Reinforcement LearningReinforcement Learning, kurz RL, ist neben dem überwachten und dem unüberwachten Lernen eines der drei grundlegenden Paradigmen des maschinellen Lernens. Beim Reinforcement Learning geht es darum, ein Gleichgewicht zwischen Exploration (dem Unbekannten) und Exploitation (dem Bekannten) zu finden, damit die Modelle die richtigen Verhaltensweisen erlernen können, mit dem Ziel, den langfristigen Ertrag zu maximieren.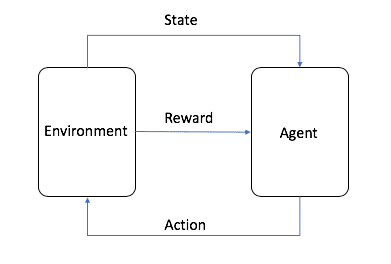
Das Bild stammt von AWS, wie in der Abbildung gezeigt, ist der Agent beim Reinforcement Learning das ultimative Ziel, das wir trainieren müssen, und interagiert mit der eingestellten Umgebung (Environment) und erzeugt Belohnung und Zustandsübertragung, der Agent lernt auf der Grundlage der Belohnung und wählt die nächste Aktion besser aus, so dass der Zyklus der Trainingsprozess ist. Dieser Zyklus ist der Trainingsprozess des Verstärkungslernens.
Im Trainingsprozess von LLM spielt RL eine wichtige Rolle, und es hat sich in der Industrie durchgesetzt, dass die Pre-Trainingsphase mit Hilfe von RLHF ausgerichtet wird. Beim verstärkenden Lernen von LLM benötigen wir in der Regel ein weiteres Modell, das die Umgebung simuliert, um die Ausgabe von LLM zu belohnen, was als Belohnungsmodell oder kurz RM bezeichnet wird.
Wir werden mehrere Modelle haben: das Akteursmodell, das Kritikermodell und das Belohnungsmodell. In Übereinstimmung mit dem obigen Standard-RL-Trainingsrahmen bilden der Akteur und der Kritiker den Agenten und die Belohnung wird im RL-Trainingsprozess als Umgebung trainiert.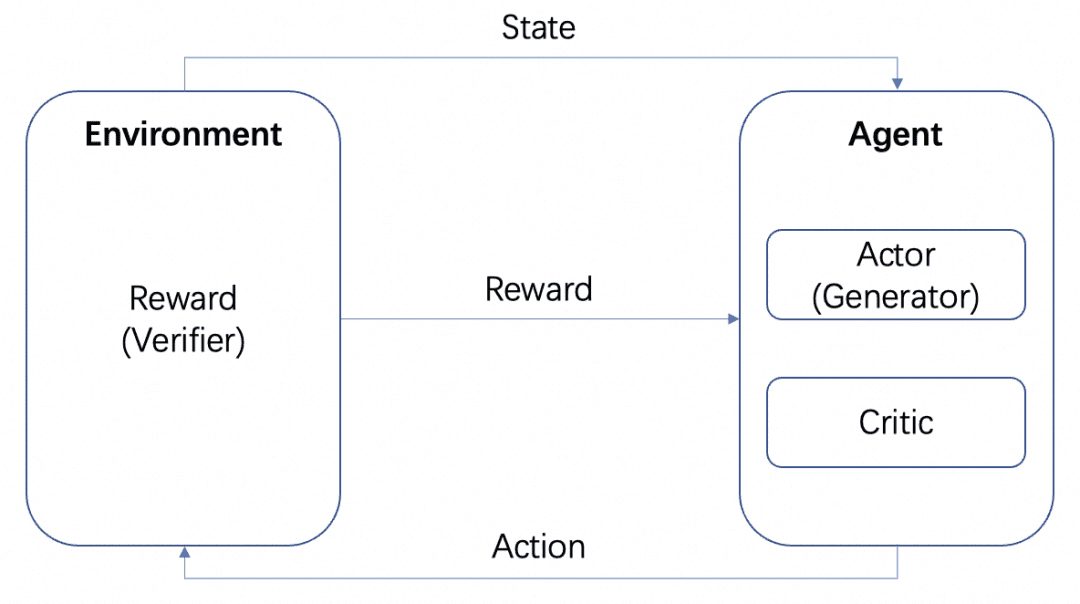
Nach dem Training können wir jedoch Actor- oder Reward-Modelle separat einsetzen, wobei das Actor-Modell unser Generator und das Reward-Modell der Verifier ist, mit dem wir die Qualität der Generierung des Generators messen, also die Generator-Verifier-Struktur, die OpenAI in dem Dokument Let's verify step by step erwähnt. Dies ist die Generator-Verifier-Struktur, die in dem OpenAI-Papier Let's verify step by step erwähnt wird.
Und die Belohnungsmodelle lassen sich danach kategorisieren, wie detailliert ihr Feedback ist:
-Prozessbasiertes Belohnungsmodell PRM: PRM gibt Feedback auf der Grundlage der Zwischenergebnisse von LLM.
-Ergebnisorientiertes Belohnungsmodell ORM: ORM gibt erst nach dem Endergebnis Feedback.
Im Folgenden werden diese beiden Konzepte in spezifischen Szenarien behandelt.
Monte-Carlo-Baumsuche Die Monte-Carlo-Baumsuche (MCTS) ist ein Baumsuchalgorithmus, dessen Kerngedanke darin besteht, dass bei jedem Schritt mehrere Verhaltensweisen ausprobiert und die möglichen zukünftigen Gewinne der Verhaltensweisen vorhergesagt werden, wobei der Schwerpunkt auf der selektiven Erkundung einiger der lohnenderen Verhaltensweisen liegt.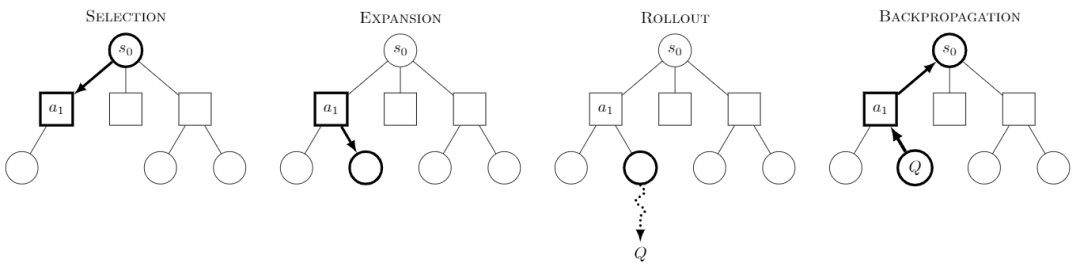
Bild aus Wikipedia. Jede Suche soll in vier Schritte unterteilt sein:
-Auswahl: Auswahl eines Knotens
-Erweiterung: erzeugt einen neuen Knoten aus diesem Knoten, der erforscht werden soll
-Rollout: Durchführung einer Simulation entlang dieses neuen Knotens, um ein Ergebnis zu erhalten
-Backpropagation: Die Ergebnisse der Simulation werden rückwärts propagiert, wobei die Knoten auf den Pfaden aktualisiert werden.
Durch kontinuierliche Erkundung erhalten wir einen Baum und jeder Knoten hat ein mögliches Ergebnis der Erkundung und wir können in diesem Baum suchen, um den besten Pfad oder das beste Ergebnis zu erhalten.
MCTS für RL hat bekannte Modelle wie AlphaZero hervorgebracht, das die Auswahl- und Rollout-Schritte mit trainierbaren Modellen durchführt und so den großen Suchraum und die Simulationskosten von MCTS reduziert, um die optimale Lösung effizient zu erhalten. Der Ansatz von AlphaZero besteht darin, trainierbare Modelle zur Durchführung der Auswahl- und Rollout-Schritte zu verwenden und so den großen Suchraum und die Simulationskosten von MCTS zu reduzieren, um effizient die optimale Lösung zu erhalten, z. B. durch die Verwendung von Policy Network zur effizienten Suche nach dem nächstmöglichen Schritt und die Verwendung von Value Network zur Bestimmung des Wertes jedes Schrittes anstelle der Rollout-Simulation.
o1's Multi-Step Reasoning Ability Wenn es um das o1-Modell geht, müssen wir über seine erstaunliche Multi-Step Reasoning-Fähigkeit sprechen, und die OpenAI-Website gibt mehrere Beispiele, um seine Multi-Step Reasoning-Fähigkeit bei Passwörtern, Codes, Mathematik, Kreuzworträtseln usw. zu zeigen. Das Beispiel zu "Passwörtern" ist "THERE ARE THREE R'S IN STRAWBERRY", das auch ein gutes Beispiel dafür ist, wie es früher entschlüsselt wurde. In dem Beispiel zu "Passwort" lautet das Dekodierungsergebnis "THERE ARE THREE R'S IN STRAWBERRY", was auch das Ergebnis des einst existierenden "Passworts" ist. ChatGPT Begründete Reaktionsfähigkeit.
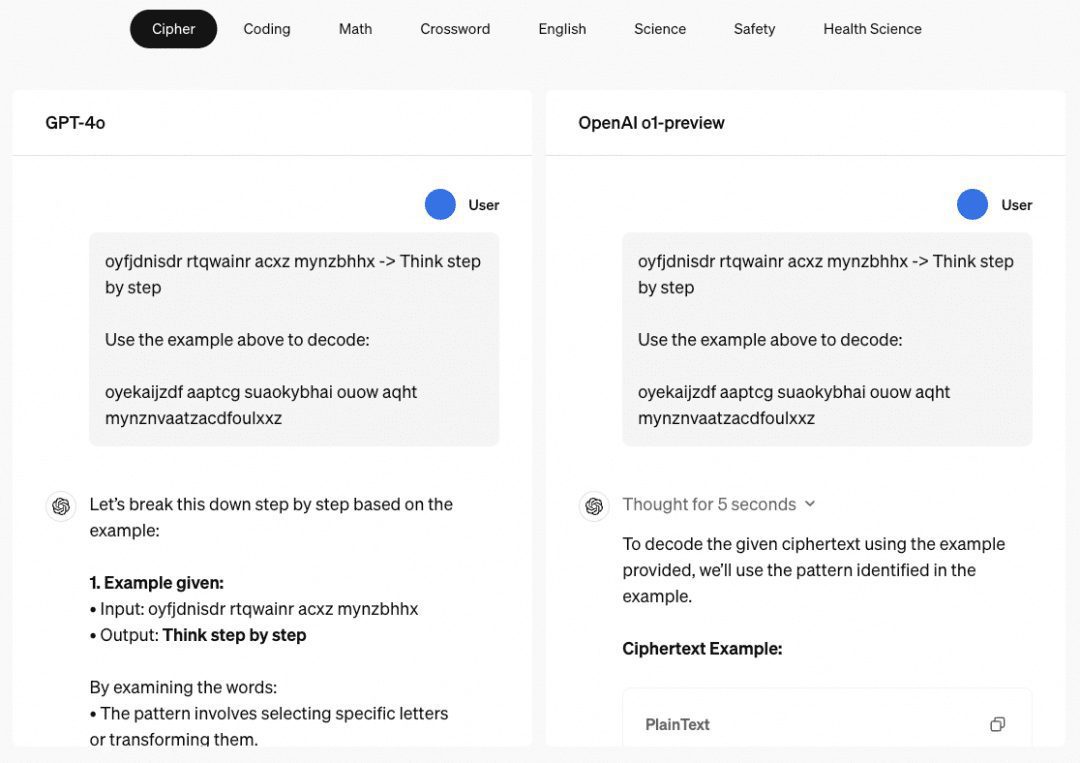
Wir haben daher eine Reihe von Papieren hauptsächlich in dieser Eigenschaft untersucht, die wir wie unten beschrieben zusammengestellt und zusammengefasst haben.
02 Stichwort Technik
Vor der Einführung der Stichworttechnik, die zur Verbesserung der Inferenzfähigkeit des Modells verwendet wird, müssen wir verstehen, was Few-Shot Learning ist. Derzeit erfordert das Training von KI im Allgemeinen eine große Menge an Beispieldaten, während das Lernen mit einer sehr kleinen Menge an Beispieldaten erfolgt.
Das Papier "Chain of Thought Prompting Elicits Reasoning in Large Language Models" schlägt einen Few-Shot-Ansatz zur Verbesserung der mathematischen Argumentation von Modellen vor:
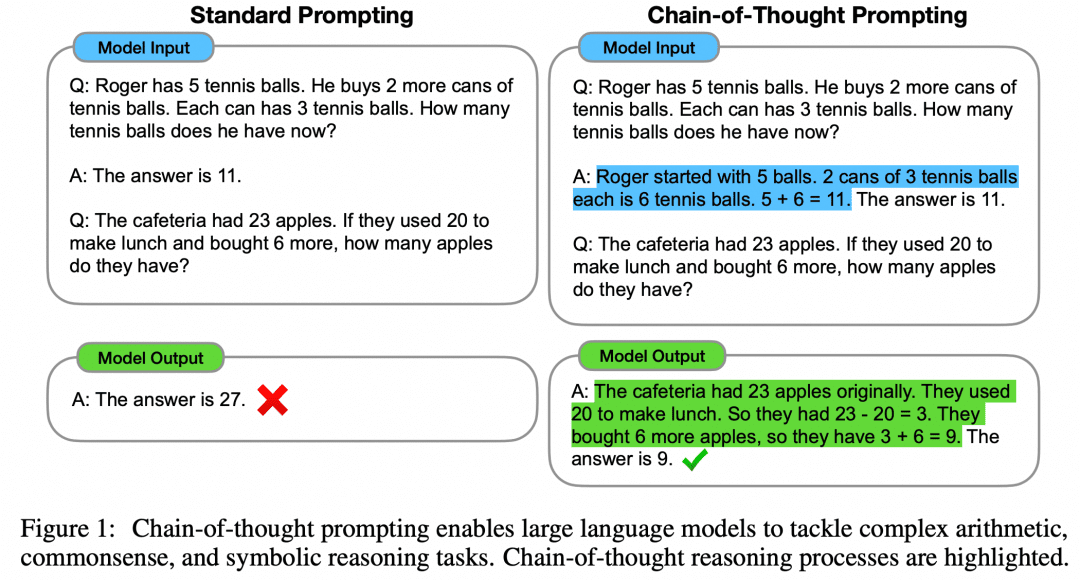
Wie in der Abbildung gezeigt, gibt die linke Seite ein Beispiel für LLM, um in der Eingabeaufforderung LLM zu lernen, was Few-Shot Learning ist, aber seine Wirkung ist immer noch unbefriedigend. In dem Papier wird dieses Few-Shot-Paradigma mit CoT auf der rechten Seite vorgeschlagen. Auf der rechten Seite werden in Few-Shot also nicht nur die Frage und die Antwort eines Beispiels gegeben, sondern auch der Zwischenprozess und das Ergebnis. Die Autoren fanden heraus, dass die auf diese Weise konstruierte Few-Shot-Aufforderung mit CoT die Inferenz des Modells verbessert.
Der Artikel "Large Language Models are Zero-Shot Reasoners" (Große Sprachmodelle sind Zero-Shot-Reasoner) zeigt weiter auf, dass Zero-Shot auch CoT verwenden kann, um die Fähigkeiten des Modells zu verbessern:

Anstatt sich die Mühe zu machen, einen CoT-Zwischenprozess zu konstruieren, oder sogar Beispiele für Few-Shot zu konstruieren, kann ein einfaches "Lasst uns Schritt für Schritt denken" das LLM verbessern. Klingt wie ein Kinderspiel. Diese Aufforderung wurde später von OpenAI aufgegriffen und in "Let's verify step by step" umgewandelt, und dieses Papier ist nun der Kern der wiederholten Lektüre für jeden, der o1 verstehen will.
Natürlich kann der Aufbau von CoT auf Cue-Word-Engineering allein nicht der Grund dafür sein, dass o1 so leistungsfähig ist, aber CoT, ein schrittweiser Ansatz zur Weiterentwicklung der Logik, hat sich zur vorherrschenden Richtung für die Erweiterung des Denkens in großen Modellen entwickelt.
03 CoT + überwachte Feinabstimmung
Natürlich hat es Versuche gegeben, LLMs mit Hilfe von SFT die mehrstufigen Argumentationsfähigkeiten von CoT beizubringen. "STaR: Bootstrapping Reasoning With Reasoning" ist ein früher Versuch. Das Bild unten stammt aus diesem Papier: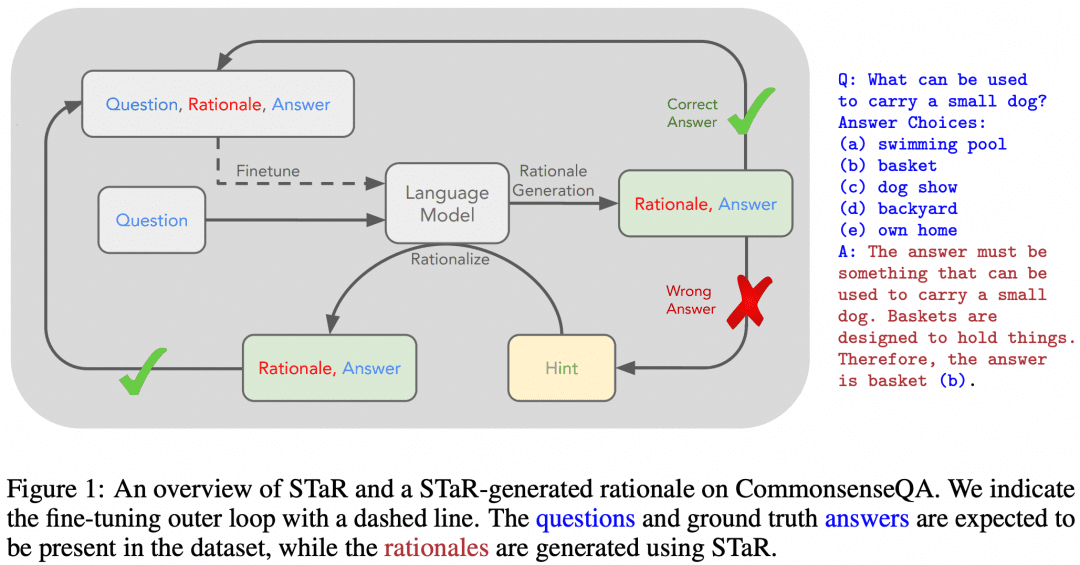
Die Idee des Papiers ist folgende. Zunächst verwenden wir den oben beschriebenen Ansatz des Cue-Word-Engineerings, um das Modell dazu zu bringen, CoT zu versuchen, um über den Datensatz zu schlussfolgern, was zu einer Reihe von Antworten führen wird, die natürlich sowohl richtige als auch falsche Antworten enthalten:
Wenn wir eine korrekte Antwort erhalten, betrachten wir den entsprechenden CoT, der vom Modell generiert wurde, als einen qualitativ hochwertigen CoT, sammeln dann solche qualitativ hochwertigen "Frage-CoT-Antwort"-Proben, um einen neuen Datensatz zu erhalten, und verwenden diesen Datensatz, um unser LLM zu SFT zu machen, und fahren mit der Schleife fort, so dass wir das LLM mit besserer Argumentationsfähigkeit erhalten können. LLM;
Wenn es einige Fragen gibt, die der LLM immer falsch beantwortet, dann lassen wir den LLM direkt die "Frage+Antwort" sehen und lassen ihn einen CoT von der Frage zur Antwort generieren, und wir können denken, dass der vom LLM generierte CoT richtig ist, wenn die Antwort bekannt ist, und dieser Teil der "Frage-CoT-Antwort"-Probe kann auch für das Training verwendet werden. Das Beispiel "Frage-CoT-Antwort" kann auch für das Training verwendet werden.
Da diese Studie schon recht alt ist, ist es leicht, die Lücken darin zu finden, z. B. gibt es bei LLM oft "falsches Verfahren, aber richtiges Ergebnis" oder "richtiges Verfahren, aber falsches Ergebnis", was bedeutet, dass die Stichproben, die wir für das Training oben verwendet haben, nicht wirklich von so hoher Qualität sind. Das bedeutet, dass die Stichproben, die wir für das Training oben verwendet haben, nicht wirklich von hoher Qualität sind. Wie kann man also einen korrekteren Inferenzprozess erhalten?
04 Monte-Carlo-Baumsuche
Wir haben oben gelernt, dass CoT die Logik von der Frage bis zur Antwort in einen Zwischengedankenprozess nach dem anderen zerlegt. Kann MCTS also verwendet werden, um den besten Gedankenschritt für den nächsten Schritt der Argumentation und damit die beste Kette von Argumentationsgedanken zu finden? Natürlich, ja.
Mutual Reasoning Makes Smaller LLMs Stronger Problem-Solvers hat einen solchen MCTS-Algorithmus entwickelt, der rStar genannt wird, und das Projekt auf GitHub veröffentlicht.
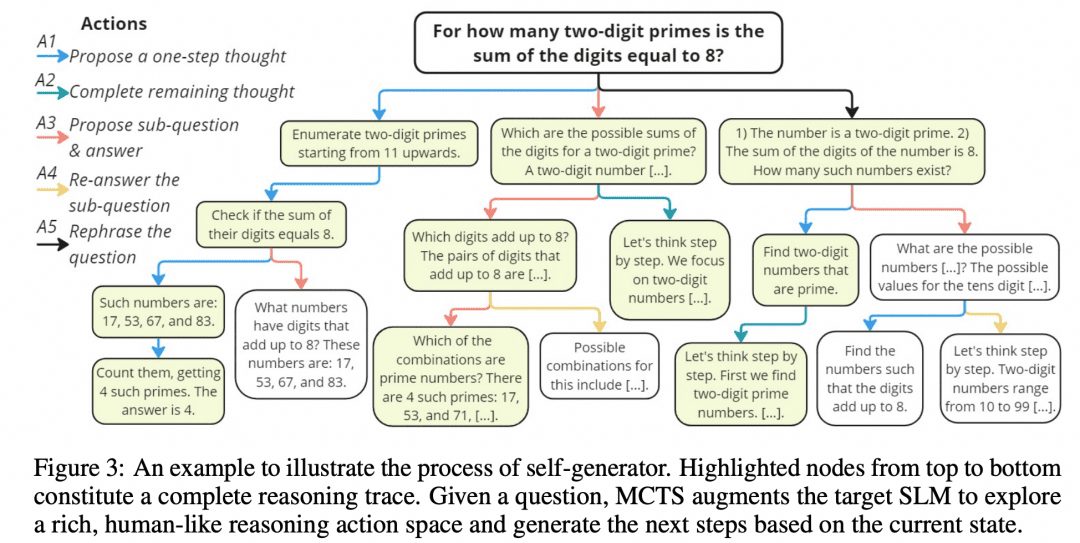
Wie in der Abbildung oben dargestellt, haben die Forscher die Zwischenschritte des CoT in 5 Arten von Knotenpunkten unterteilt:
1. die nächsten Schritte in der Argumentation generieren
2. alle nachfolgenden Überlegungen generieren
3. eine Unterfrage und eine Antwort generieren
4. erneute Beantwortung der Unterfragen
5 Fragen der Rekonfiguration
Das MCTS wird dann verwendet, um den nächsten Gedankenschrittknoten zu bestimmen. Der Pfad, der durch einen Gedankenknoten nach dem anderen verbunden ist, ist der CoT. Wir nehmen einfach alle Endergebnisse, die wir erhalten, und stimmen über sie ab.
Natürlich haben die Autoren noch mehr untersucht, denn wie bereits erwähnt, ist es notwendig, die Korrektheit der Knoten und die Korrektheit der Argumentation bei jedem Schritt zu messen:
Diskriminator-Filterung: nach dem ursprünglichen Inferenzpfad erhalten, zufällig Maske einen Teil davon, und verwenden Sie dann ein anderes Modell für die Ausgabe, wenn wir das gleiche Ergebnis wie das Original-Generator zu erhalten, dann ist die ursprüngliche Inferenzpfad zuverlässig.
-Korrektheit der Antworten: Alle endgültigen Antworten werden gesammelt, und der Anteil einer bestimmten Antwort an allen Antworten ist die Antwortbewertung.
-Prozesskorrektheit: Für jeden Argumentationsknoten im Pfad wird eine Anzahl von Knoten vom Typ 2 parallel generiert, um eine Anzahl von Ein-Schritt-Endergebnissen zu erzeugen, und der Anteil dieser Ergebnisse, die das Endergebnis des aktuellen Pfades sind, wird als Prozessbewertung dieses Argumentationsknotens betrachtet. Die dreiteilige Maßnahme führt zu einem optimalen Pfad, und das Endergebnis des optimalen Pfades wird als das Ergebnis des MCTS betrachtet.
05 Generator + Prüfer
Neben dem oben erwähnten MCTS, das es ermöglicht, Denkprozesse in Bäumen zu organisieren und zu erforschen, gibt es noch andere Möglichkeiten, dies zu tun. Verstärkungslernen zum Beispiel, und auch hier sehen wir uns die Einführung in das Verstärkungslernen an: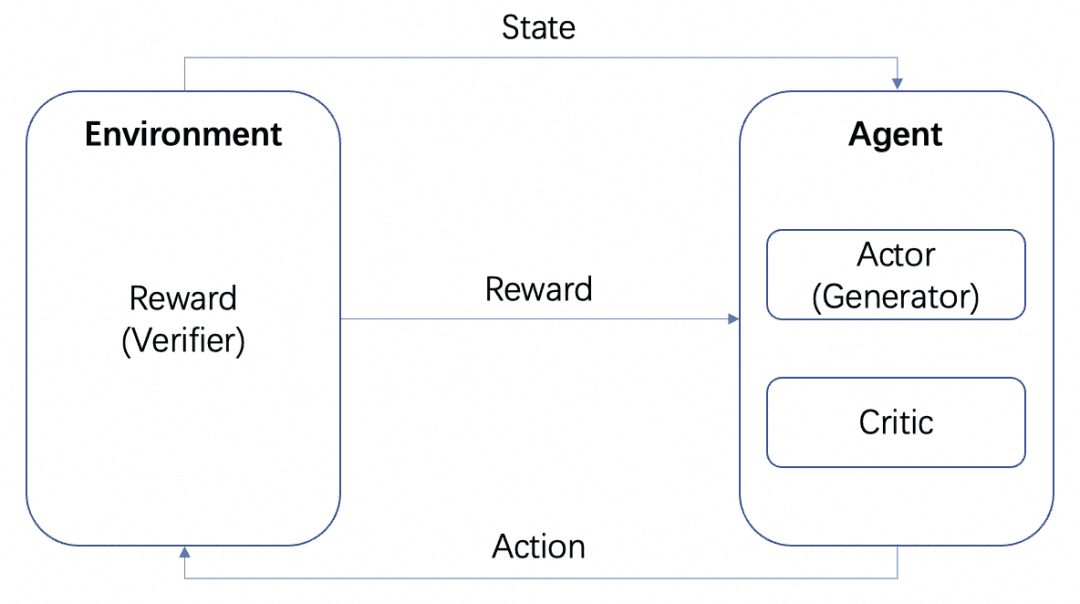
Nehmen wir den LLM als Akteur, ein anderes RM, das auf das Problem trainiert wurde, als Umgebung und einen impliziten Kritiker, so würde eine Verstärkungslernschleife wie folgt aussehen: Der Akteur produziert ein Ergebnis für das Problem, das RM überprüft die Korrektheit des Ergebnisses und gibt es an den Agenten weiter, und der Akteur und der Kritiker trainieren entsprechend der Belohnung. Der Actor und der Critic werden auf der Grundlage des Reward trainiert. Wir bezeichnen den Agenten als Generator, da seine Aufgabe darin besteht, Ergebnisse zu generieren, und den RM als Verifier, da seine Aufgabe darin besteht, die Ergebnisse zu verifizieren.
Wenn man darüber nachdenkt, ist die Beziehung zwischen Actor und Critic innerhalb eines Agenten nicht sehr ähnlich zu dem von AlphaZero verwendeten Policy- und Value-Netzwerk? Es stimmt auch, dass Policy- und Value-Netzwerke in den Actor- und Critic-Rahmen passen.
Wir fassen nun zusammen, dass ein Verstärkungslernprozess drei Netze umfasst: Actor, Critic und RM. Im Einsatz werden je nach Situation verschiedene Frameworks verwendet: Bei Schachspielen ist der Gewinner erst am Ende des Spiels bekannt und das RM gibt zu wenig Belohnung, also entscheiden wir uns dafür, das Actor-Critic-Framework im Einsatz beizubehalten und führen dann MCTS durch, um eine bessere Lösung zu erhalten; im LLM-Einsatz kann unser trainiertes RM zeitnahes Feedback geben, also können wir natürlich Actor und RM zu einem Generator-Verifier-Framework im Einsatz kombinieren. Bei der LLM-Bereitstellung kann unser trainiertes RM zeitnahes Feedback liefern, so dass wir Actor und RM zum Zeitpunkt der Bereitstellung auf natürliche Weise zu einem Generator-Verifier-Framework kombinieren können.
OpenAI hat seit den Tagen von GPT3 in dieser Richtung gearbeitet (ChatGPT basiert auf dem GPT-3.5-Modell). Die Lösung wurde in dem Papier Training Verifiers to Solve Math Word Problems vorgestellt. Das Bild unten ist aus diesem Papier:
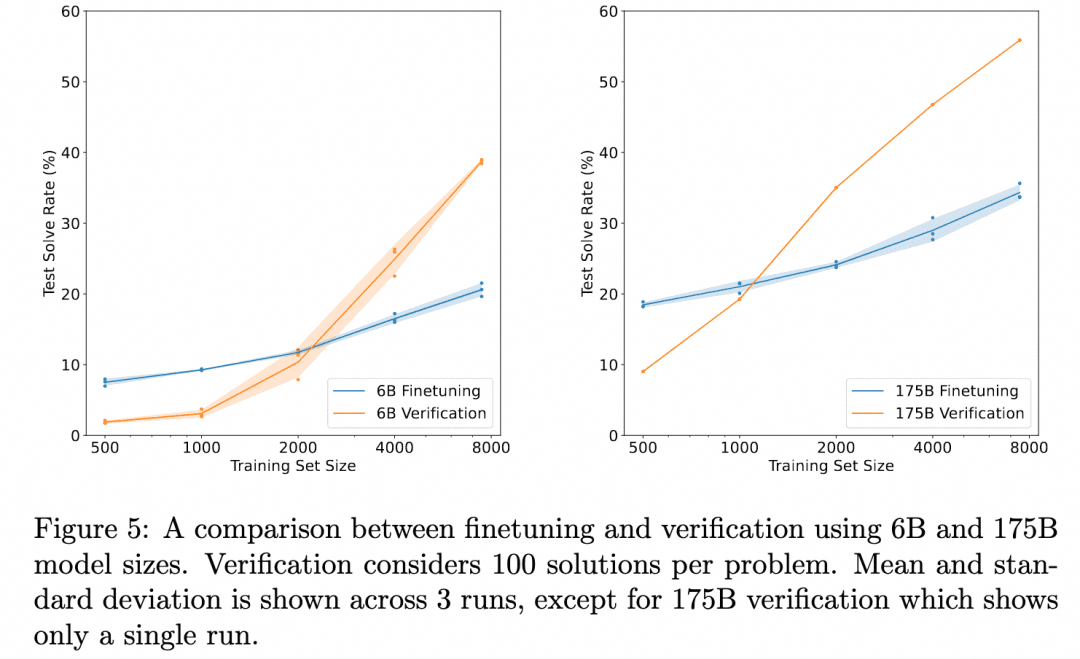
Das obige Diagramm vergleicht die "Korrektheit der Ergebnisse, die durch eine bloße Feinabstimmung des Generators erzielt wurden" mit der "Korrektheit der Ergebnisse, die durch eine Feinabstimmung eines Überprüfers, die Auswertung mehrerer vom Generator erzeugter Ergebnisse und die Auswahl des am besten bewerteten Ergebnisses erzielt wurden". Dies zeigt die Wirksamkeit des Verifiers.
Der Grund dafür ist, dass die Aufgabe hier darin besteht, über das Problem nachzudenken, um das Ergebnis zu erhalten. Der verwendete Generator erzeugt also keinen zwischengeschalteten Denkprozess, sondern produziert direkt das Ergebnis, und der Verifier ist ebenfalls das ORM (Outcome Based Reward Model), das wir im Abschnitt über Reinforcement Learning erwähnt haben und das dazu dient, auf der Grundlage des Ergebnisses des Generators eine Punktzahl zu ermitteln. Es handelt sich hier also nicht um einen mehrstufigen Inferenzprozess, den wir erforschen wollen, sondern lediglich um die Entdeckung, dass die ORM-Validierung zu besseren Endergebnissen führt als eine einfache Feinabstimmung.
Daher ging das OpenAI-Team einen Schritt weiter: Einerseits wurde der Generator dazu gebracht, nicht mehr direkt Ergebnisse auszugeben, sondern schrittweise zu argumentieren; andererseits wurde ein PRM (Process-based Reward Model) trainiert, das als Verifier fungiert und dessen Aufgabe es ist, für jeden Schritt im Argumentationsprozess des Generators eine Punktzahl zu vergeben. Wir glauben, dass die Ergebnisse, die durch das Streben nach Korrektheit im Argumentationsprozess des Generators auf diese Weise erzielt werden, am wahrscheinlichsten korrekt sind.
Dies ist das oben erwähnte Let's Verify Schritt für Schritt. In dieser Arbeit verglich das Team die Inferenzergebnisse, die bei der Suche nach demselben Generator mit PRM und ORM als Verifizierer erzielt wurden (zu diesem Zeitpunkt war ihr Generator bereits GPT-4), und bewies, dass PRM als Verifizierer genauere Ergebnisse erzielte. Die folgende Abbildung stammt aus dem Papier:
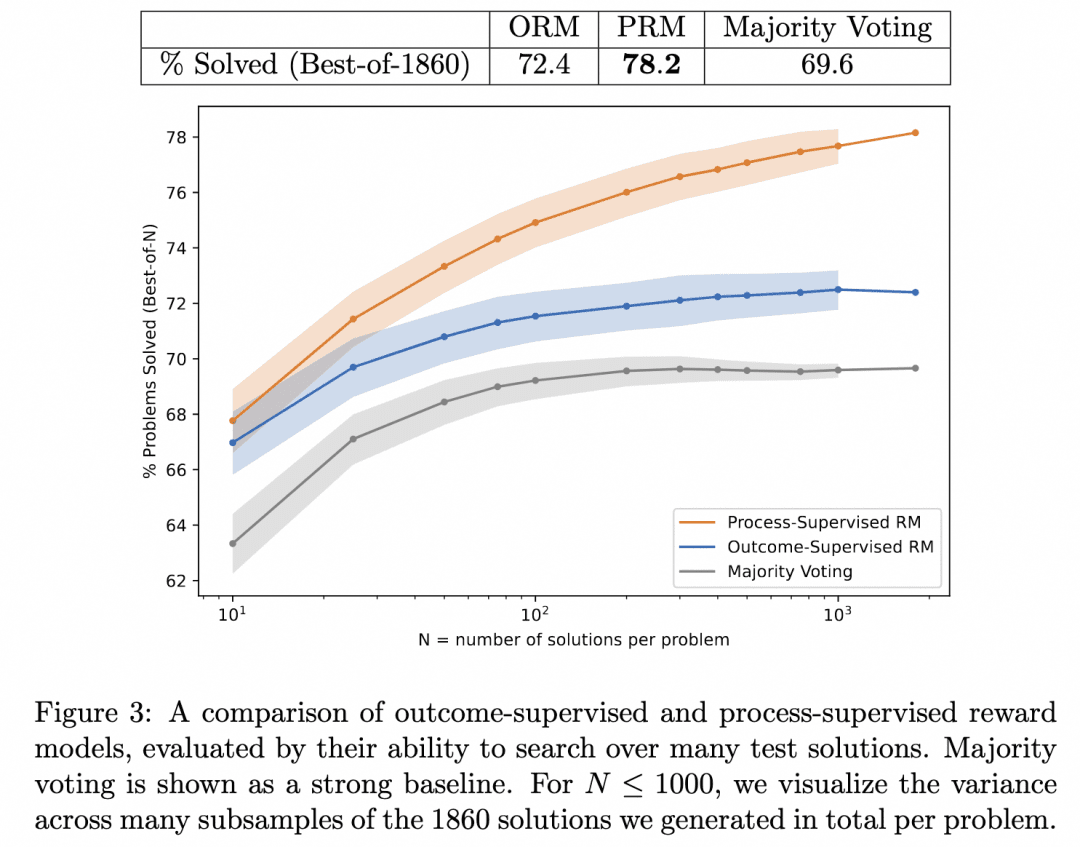
Die obige Abbildung veranschaulicht, dass derselbe schrittweise Inferenzgenerator zu Ergebnissen führt, bei denen es für uns gültig ist, den ORM als Verifizierer zu verwenden, um die beste Antwort für das Ergebnis auszuwählen, aber wir haben eine höhere Wahrscheinlichkeit, richtig zu liegen, wenn wir den PRM als Verifizierer verwenden, um die beste Antwort für den Prozess auszuwählen!
Ist dies die Technologie hinter dem o1, nach der wir suchen? Wir können zum jetzigen Zeitpunkt nur vermuten, dass es sich um eine der Kerntechnologien dahinter handelt. Die Gründe dafür sind die folgenden:
1, ist dieses Papier relativ weit von der Veröffentlichung von o1 entfernt, und ein Jahr ist genug Zeit für OpenAI-Forscher, um sich tiefer in diese Richtung zu vertiefen. Aufgrund der Gültigkeit des PRM ist ein Jahr zwar auch genug Zeit, um sich auf andere Richtungen einzustellen, aber wir denken immer noch, dass sie sich eher vertiefen als umkehren.
Das Papier zeigt die Effektivität des PRM als Verifier, und es ist klar, dass der nächste Schritt darin bestehen könnte, den Generator mit einem leistungsfähigen Verifier zu verbessern, um bessere Ergebnisse zu erzielen. Aber das Papier geht nicht darauf ein, so dass wir Grund zu der Annahme haben, dass OpenAI es versucht haben muss, und es ist nicht klar, ob das Ergebnis o1 war.
Nachdem diese Vermutung aus dem Weg geräumt ist, wollen wir uns nun anderen Möglichkeiten zuwenden, Verifier für die Suche zu nutzen. Der Artikel "Scaling LLM Test-Time Compute Optimally can be More Effective than Scaling Model Parameters" von Google DeepMind vom vergangenen August enthält weitere Forschungsergebnisse. Dieser Artikel wird von vielen als eine ähnliche technische Linie wie die Prinzipien hinter o1 angesehen. Das Bild unten stammt aus diesem Papier:
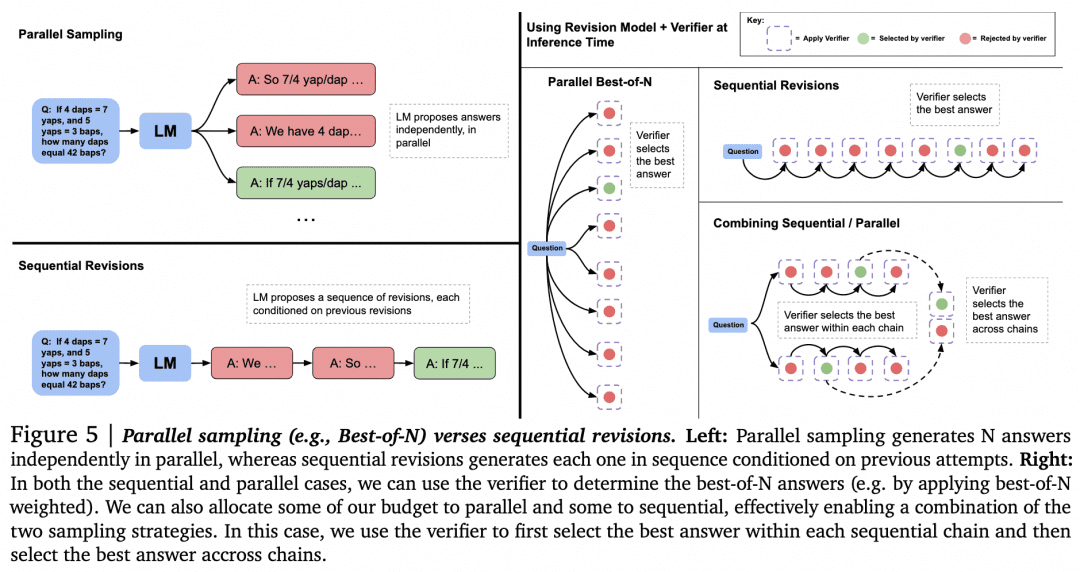
Nun, da wir einen Generator und einen Verifier haben, wie können wir sie dazu bringen, miteinander zu arbeiten, um die besten Ergebnisse zu erzielen? Wie bereits erwähnt, besteht eine Möglichkeit darin, dass der Generator parallel Proben nimmt, um mehrere Ergebnisse zu erhalten, und der Verifier diese auswertet und das beste Ergebnis auswählt. Dies ist der Ansatz Paralleles Sampling + Best-of-N links in der Abbildung oben. Aber es gibt natürlich auch andere Ansätze:
-Bei der Generierung mehrerer Ergebnisse ist es möglich, dass der Generator nicht nur mehrere Ergebnisse parallel abfragt, sondern auch ein Ergebnis generiert und dann das Ergebnis selbst überprüft und korrigiert, um eine Folge von Antworten zu erhalten, die nicht mehr parallel zueinander sind.
-Bei der Auswahl durch den Überprüfer kann es Alternativen zu Best-of-N geben. Wie in der folgenden Abbildung aus dem Papier dargestellt:
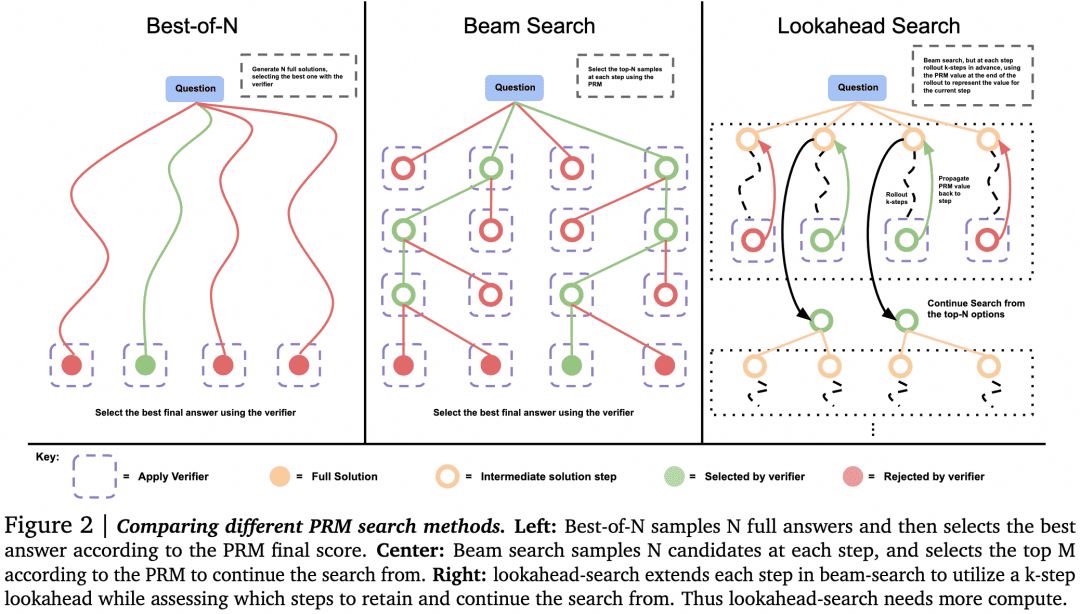
In dem Papier wird festgestellt, dass wir bei einfachen Problemen den Generator mit Hilfe von Verifier zur Selbstkontrolle und Korrektur anregen sollten, anstatt blindlings parallel zu suchen. Bei komplexen Problemen ist es für den Generator besser, verschiedene Lösungen parallel zu versuchen.
Eine ähnliche Arbeit ist A Comparative Study on Reasoning Patterns of OpenAI's o1 Model. Das Paper-Team hat Open-o1, eine Replik von o1, auf GitHub veröffentlicht, und dieser Artikel ist das Ergebnis einiger ihrer Forschungen nach der Veröffentlichung von o1. Das Bild unten ist aus dem Papier:
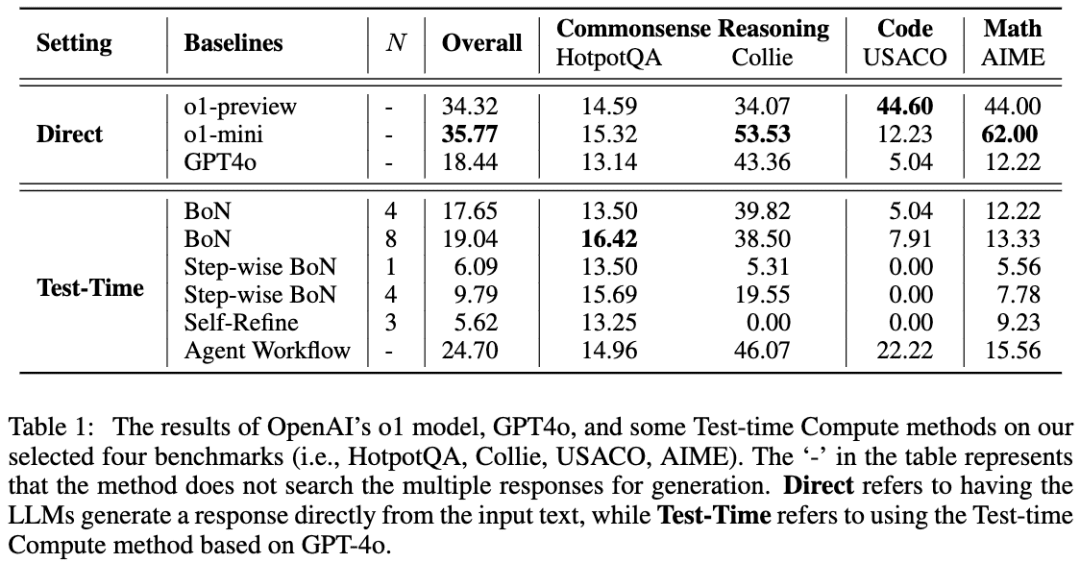
Das Team verwendete GPT-4o als Skelettmodell und verglich dann seine Ergebnisse mit vier gängigen Ansätzen, um LLMs dazu zu bringen, erst zu denken und dann zu argumentieren. Das Team fand heraus, dass bei der HotpotQA-Aufgabe sowohl der Best-of-N-Ansatz als auch der schrittweise BoN-Ansatz in der Lage waren, die Argumentation der LLMs erheblich zu verbessern, wobei BoN sogar dazu führte, dass GPT-4o das o1-Modell übertraf.
06 OpenR
Von den aktuellen Open-Source-Projekten, die versuchen, o1 zu replizieren, ist OpenR eines der relativ gut gemachten Projekte.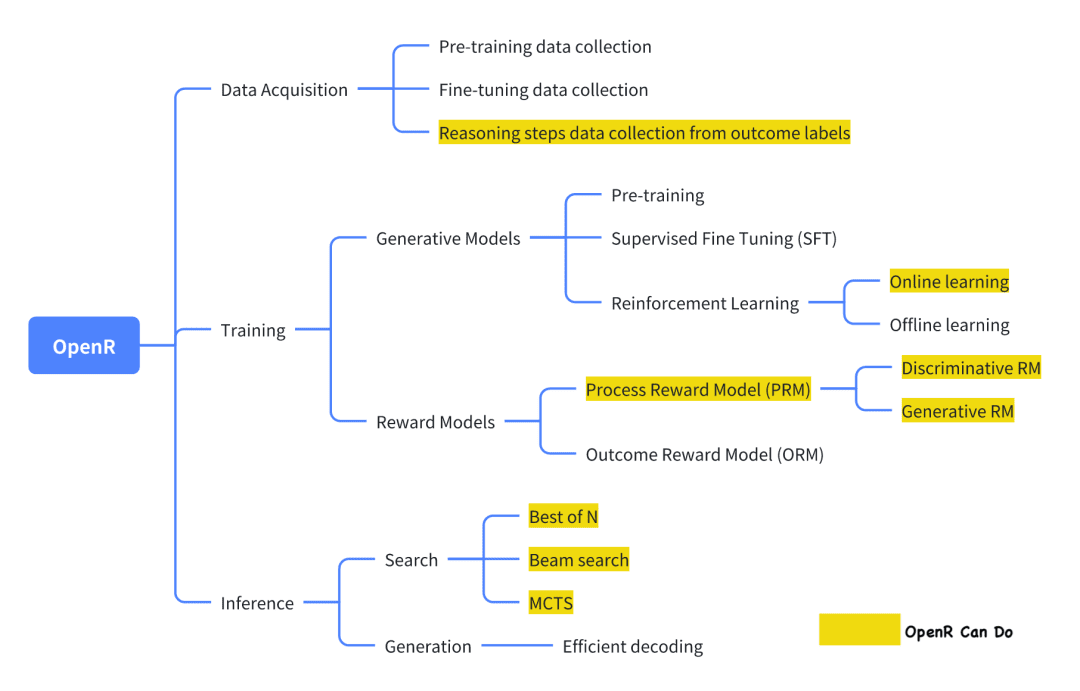
Das Bild stammt aus der offiziellen Dokumentation, die in ihrer jetzigen Form die Datenerfassung sowie die Schulung und den Einsatz im Einklang mit dem Generator-Verifier-Rahmen implementiert.
Datenerhebung Laut der offiziellen Einführung stammt die Methode der Datenerhebung aus dem Papier: "Improve Mathematical Reasoning in Language Models by Automated Process Supervision". Kurz gesagt geht es um die Verwendung von MCTS zur Erweiterung des ursprünglichen problem-final_answer-Datensatzes, um CoT-Inferenzschritte zu erzeugen. Schließlich erhält man einen MATH-APS-Datensatz.
Einschlägige Datensätze wurden auf ModelScope gehostet:
PRM800K-Datensatz (schrittweise):
https://modelscope.cn/datasets/AI-ModelScope/openai-prm800k-stepwise-critic/
MATH-APS-Datensatz:
https://modelscope.cn/datasets/AI-ModelScope/MATH-APS/
Math-Shepherd-Datensatz:
https://modelscope.cn/datasets/AI-ModelScope/Math-Shepherd
Das Generator-Trainingsteam verwendet eine Variante des PPO-Algorithmus aus dem Reinforcement Learning, um den Generator zu trainieren. Kurz gesagt verwendet der PPO-Algorithmus die vom Belohnungsmodell bereitgestellten Belohnungsinformationen, um den Generator zu trainieren, und schränkt gleichzeitig den Actor ein, damit er während des Lernprozesses nicht zu weit vom ursprünglichen Actor abweicht, um den Verlust des vorhandenen Wissens zu vermeiden. Derzeit unterstützt OpenR drei Varianten: APPO, GRPO und TPPO.
Das Virifier-Schulungsteam verwendete SFT-überwachtes Lernen, um einen PRM mit dem oben genannten MATH-APS-Datensatz sowie zwei Open-Source-Datensätzen, PRM800K und Math-Shepherd, zu trainieren. Bei diesen drei Step-Level-Datensätzen kennzeichnete das Team jeden Schritt mit einem "+" oder "-" und bat dann das PRM zu lernen, die Kennzeichnung jedes Schritts vorherzusagen und festzustellen, ob sie richtig oder falsch war.
Das Modell verwendet "schrittweise" Daten für das PPO-Training, und die resultierenden Modellgewichte wurden in ModelScope gehostet, das derzeit Kontrollpunkte für SFT-, PRM- und RL-Modelle sowie einige GGUF-Formate bereitstellt:
Das Modell mistral-7b-sft:
https://modelscope.cn/models/AI-ModelScope/mistral-7b-sft
RL-Modell (GGUF-Version):
https://modelscope.cn/models/QuantFactory/math-shepherd-mistral-7b-rl-GGUF
PRM-Modellierung:
-GGUF-Version: https://modelscope.cn/models/QuantFactory/math-shepherd-mistral-7b-prm-GGUF
-PRM-Modell: https://modelscope.cn/models/AI-ModelScope/math-shepherd-mistral-7b-prm
Reasoning Deployment Zum Zeitpunkt der Bereitstellung verwendet OpenR Suchalgorithmen durch den angegebenen Generator und Verifier, um den Reasoning-Prozess und die endgültige Antwort zu erhalten. Derzeit werden MCTS, Beam Search und best_of_n unterstützt.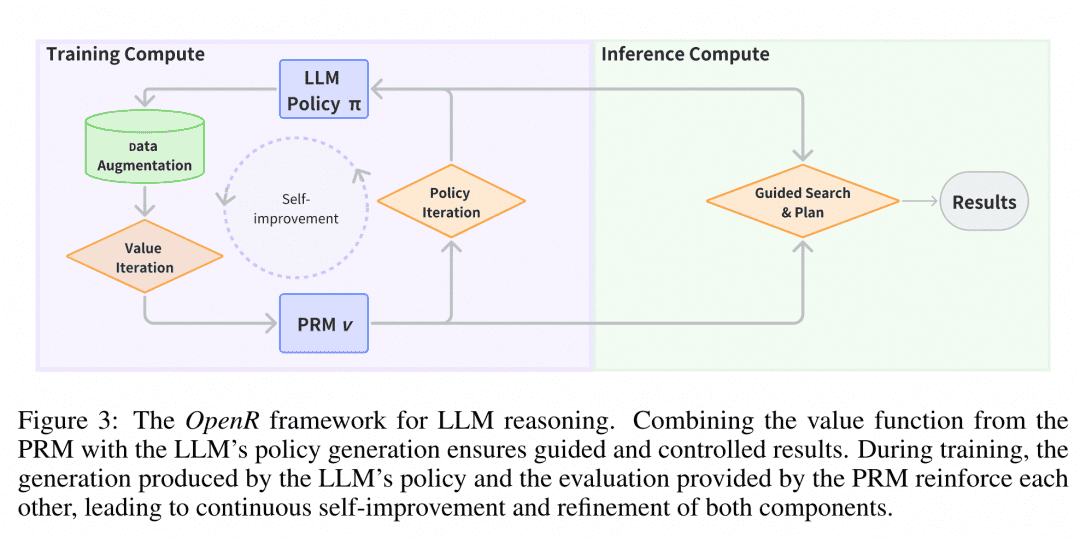
Das Bild stammt aus dem Papier "OpenR: An Open Source Framework for Advanced Reasoning with Large Language Models" (OpenR: Ein Open-Source-Framework für fortgeschrittenes Reasoning mit großen Sprachmodellen). Die Struktur von OpenR ist in der Abbildung dargestellt, und bisher implementiert OpenR eine Nachbildung der Kette von O1, von der Sammlung von Trainingsdaten über das Training einer PRM bis hin zur Verwendung der PRM zur Verstärkung des Lernens und schließlich zum Einsatz des Modells. OpenR implementiert derzeit eine Kette, die O1 nachbildet, von der Sammlung von Trainingsdaten über das Training eines PRM, die Verwendung des PRM zur Verstärkung des Lernens bis hin zur Bereitstellung des Modells für die Suche, und das Team hat all diese Arbeit quelloffen gemacht, damit die Community davon lernen und es ausprobieren kann, so dass wir einen Einblick bekommen.
Creative Space ExperienceWir haben den Inferenzdienst von OpenR im Magic Hitch Community Creative Space implementiert, und Entwickler können die Auswirkungen von OpenR online unter folgendem Link erleben: https://www.modelscope.cn/studios/modelscope/OpenR_Inference
07 Schlussfolgerung
Die oben genannten Arbeiten zum mehrstufigen Schlussfolgern, die wir untersucht haben, zeigen, dass das schrittweise Schlussfolgern des LLM anstelle des Überspringens von Zwischenprozessen seine Genauigkeit bei logikbezogenen Problemen erheblich verbessern kann. Um den LLM schrittweise schlussfolgern zu lassen, können wir ihn mit Hilfe einiger Datensätze mit Zwischenprozessen feinabstimmen, zusätzlich zur Anleitung mit einfacher Stichworttechnik. Noch effizienter ist es, einen Verifier zu trainieren, der die Genauigkeit des Generators schrittweise verifizieren kann, um die vom Generator erzeugten Ergebnisse zu durchsuchen.
Aus den bisherigen Spekulationen und Veröffentlichungen geht hervor, dass die wahrscheinliche Technologie für o1 genau auf der Zusammenarbeit zwischen dem leistungsstarken LLM-Generator und dem LLM-Verifizierer basiert. Diese Art von Links-auf-Rechts-Fuß, sich selbst wiederholend gegen sich selbst, ist nicht das erste Mal im Deep Learning, aber OpenAI ist das erste, das ein solches Modell in den LLM-Bereich einführt, was sehr teuer ist, nur um den Generator zu trainieren, was wirklich eine große Sache ist.
Daher sind wir der Meinung, dass wir, wenn wir o1 replizieren wollen, als Erstes einen Verifier benötigen, der den Generator unterstützen und anleiten kann. Um die Daten zu generieren, die für das Training des Verifiers benötigt werden, können wir uns auf die obigen Kapitel CoT + Supervised Fine-Tune und Monte Carlo Tree Search beziehen, um qualitativ hochwertigere Daten zu geringeren Kosten zu erhalten. Um die für das Training des Verifiers benötigten Daten zu generieren, kann man sich auf die obigen Kapitel CoT + Supervised Fine-Tune und Monte Carlo Tree Search beziehen, um kostengünstig an qualitativ hochwertigere Daten zu gelangen. Aus diesem Grund haben wir auch diese Aufgaben vorgestellt.
Schließlich präsentierten wir ein hochgradig fertiges Open-Source-Projekt, und auf der Grundlage ihrer Arbeit konnten wir unsere Gedanken und Ideen ordnen.
08 Hinweis
Gedankenketten als Aufforderung zum Nachdenken in großen Sprachmodellen
Große Sprachmodelle sind Zero-Shot Reasoners
STaR: Bootstrapping Reasoning With Reasoning
Gegenseitiges Reasoning macht kleinere LLMs zu stärkeren Problemlösern
Schulung von Prüfern zur Lösung von mathematischen Textaufgaben
Prüfen wir Schritt für Schritt
Optimale Skalierung der LLM-Testzeitberechnung kann effektiver sein als die Skalierung der Modellparameter
Eine vergleichende Studie zu den Argumentationsmustern von OpenAIs o1-Modell
OpenR: Ein Open-Source-Framework für fortgeschrittenes Reasoning mit großen Sprachmodellen
© urheberrechtliche Erklärung
Artikel Copyright AI-Austauschkreis Alle, bitte nicht ohne Erlaubnis vervielfältigen.
Ähnliche Artikel



Keine Kommentare...