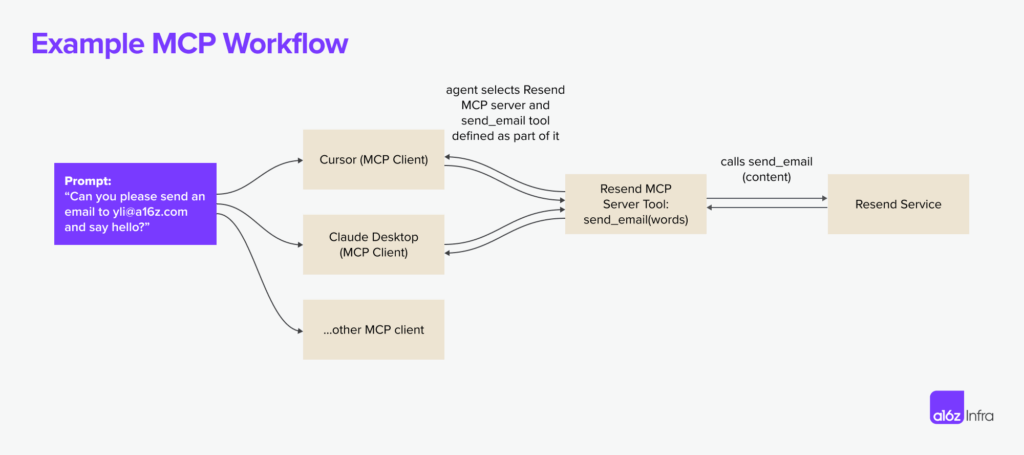
Cloudflare führt AutoRAG ein: Managed RAG Service vereinfacht die Integration von KI-Anwendungen

Cloudflare Kürzlich wurde die Einführung von AutoRAG Open Beta des Dienstes. Dieser vollständig gehostete Retrieval-Augmented Generation (RAG)-Dienst ist der erste seiner Art in der Welt. RAGDie RAG-Technologie verbessert die Genauigkeit der KI-Antworten, indem sie Informationen aus den Daten des Entwicklers abruft und sie in das Large Language Model (LLM) einspeist, um zuverlässigere, faktenbasierte Antworten zu generieren.
Der Aufbau einer RAG-Pipeline bedeutet für viele Entwickler eine mühsame Aufgabe. Sie erfordert die Integration mehrerer Tools und Dienste wie Datenspeicher, Vektordatenbanken, eingebettete Modelle, große Sprachmodelle und benutzerdefinierte Indizierungs-, Abruf- und Generierungslogik. Allein um das Projekt in Gang zu bringen, ist eine Menge "Näharbeit" erforderlich, und die anschließende Wartung ist sogar noch schwieriger. Wenn sich Daten änderten, mussten sie manuell neu indiziert und Einbettungsvektoren generiert werden, damit das System relevant und leistungsfähig blieb. Die erwartete "Frage stellen und eine intelligente Antwort erhalten"-Erfahrung verwandelt sich oft in ein komplexes System mit fragilen Integrationen, klebrigem Code und laufender Wartung.
AutoRAG Das Ziel ist es, diese Komplexität zu beseitigen. Mit ein paar Klicks erhalten Entwickler eine vollständig verwaltete RAG-Pipeline. Der Service deckt alles ab, vom Datenzugriff über automatisiertes Chunking und Embedding bis hin zur Speicherung von Vektoren in der Cloudflare (in Form eines Nominalausdrucks) Vectorize in der Datenbank, dann die Durchführung semantischer Suchen und die Nutzung der Workers AI Der gesamte Prozess der Erstellung einer qualitativ hochwertigen Antwort.AutoRAG Die Datenquellen werden kontinuierlich überwacht und im Hintergrund auf Aktualisierungen hin indexiert, sodass KI-Anwendungen automatisch und ohne menschliches Zutun auf dem neuesten Stand gehalten werden können. Diese Abstraktion ermöglicht es den Entwicklern, sich mehr auf die Entwicklung der Cloudflare um intelligentere und schnellere Anwendungen auf der Entwicklungsplattform des
Der Wert der RAG-Anträge
Große Sprachmodelle (wie die von Meta Llama 3.3) sind leistungsstark, aber ihr Wissen ist auf Trainingsdaten beschränkt. Wenn sie nach neuen, geschützten oder bereichsspezifischen Informationen gefragt werden, haben sie oft Schwierigkeiten, genaue Antworten zu geben. Dies kann durch die Bereitstellung relevanter Informationen durch Systemaufforderungen unterstützt werden, aber dies erhöht den Umfang der Eingabe und ist durch die Länge des Kontextfensters begrenzt. Ein anderer Ansatz ist die Feinabstimmung des Modells, aber das ist kostspielig und erfordert ständiges Neutraining, um mit der Aktualisierung der Informationen Schritt zu halten.
Die RAG ruft zum Zeitpunkt der Abfrage relevante Informationen aus einer bestimmten Datenquelle ab, kombiniert sie mit der Eingabeabfrage des Benutzers und stellt dann beides dem LLM zur Verfügung, um eine Antwort zu erzeugen. Dieser Ansatz ermöglicht es dem LLM, seine Antwort auf die vom Entwickler bereitgestellten Daten zu stützen und so sicherzustellen, dass die Informationen korrekt und aktuell sind. Daher eignet sich RAG gut für den Aufbau von KI-gesteuerten Kundendienstrobotern, internen Wissensdatenbankassistenten, semantischer Dokumentensuche und anderen Anwendungsszenarien, die ständig aktualisierte Informationsquellen erfordern. Im Vergleich zur Feinabstimmung ist RAG kostengünstiger und flexibler im Umgang mit dynamisch aktualisierten Daten.

Erläuterung der Funktionsweise von AutoRAG
AutoRAG nutzen. Cloudflare Vorhandene Komponenten der Entwicklerplattform konfigurieren automatisch die RAG-Pipeline für den Benutzer. Die Entwickler müssen keinen eigenen Code schreiben, um die Workers AIundVectorize im Gesang antworten AI Gateway und andere Dienste, erstellen Sie einfach eine AutoRAG Instanz und verweist sie auf eine Datenquelle (z. B. die R2 Storage Bucket) ist ausreichend.
AutoRAG Im Kern geht es dabei um zwei Prozesse:Indizierung im Gesang antworten Abfrage von.
- Indizierung ist ein asynchroner Prozess, der im Hintergrund läuft. Er läuft in der
AutoRAGDie Instanzen werden sofort nach der Erstellung gestartet und laufen automatisch nach dem Round-Robin-Prinzip, d. h. sie verarbeiten neue oder aktualisierte Dateien nach Abschluss jedes Auftrags. Während des Indizierungsprozesses werden die Inhalte in für die semantische Suche optimierte Vektoren umgewandelt. - (ein Dokument usw.) einsehen ist ein synchronisierter Prozess, der durch das Senden einer Suchanfrage durch den Benutzer ausgelöst wird.
AutoRAGBei Erhalt einer Anfrage wird der relevanteste Inhalt aus der Vektordatenbank abgerufen und eine kontextbezogene Antwort unter Verwendung dieses Inhalts und des LLM erzeugt.
Indizierungsprozess erklärt
Wenn die Datenquelle verbunden ist, wird dieAutoRAG Die folgenden Schritte werden automatisch durchgeführt, um die Daten zu extrahieren, zu transformieren und als Vektoren zu speichern, die für die semantische Suche bei späteren Abfragen optimiert sind:
- Extrahieren von Dateien aus Datenquellen:
AutoRAGLesen von Dateien direkt aus konfigurierten Datenquellen. Unterstützt derzeit die Verwendung derCloudflare R2Integration zur Bearbeitung von Dokumenten in PDF, Bild, Text, HTML, CSV und vielen anderen Formaten. - Markdown-Konvertierung: ausnutzen
Workers AIDie Markdown-Konvertierungsfunktion wandelt alle Dateien in ein strukturiertes Markdown-Format um und gewährleistet so die Konsistenz zwischen verschiedenen Dateitypen. Bei Bilddateien wird dieWorkers AIDas Objekt wird erkannt, und sein Inhalt wird durch die Umwandlung von visuellen in verbale Informationen als Markdown-Text beschrieben. - Chunking: Der extrahierte Text wird in kleinere Abschnitte aufgeteilt, um die Granularität der Suche zu verbessern.
- Einbetten: Jeder Textblock verwendet die
Workers AIDas Einbettungsmodell wird verarbeitet, um den Inhalt in eine Vektordarstellung umzuwandeln. - Vektorielle Speicherung: Die erzeugten Vektoren werden zusammen mit Metadaten wie Quellort, Dateiname usw. in der automatisch erstellten
Cloudflare VectorizeIn der Datenbank.

Anfrage Prozessdetails
Wenn ein Endnutzer eine Anfrage initiiert, wird dieAutoRAG Koordiniert die folgenden Maßnahmen:
- Empfang von Abfrageanfragen: Der Abfrage-Workflow beginnt mit
AutoRAGAI Search oder Search API Endpunkt, um eine Anfrage zu senden. - Query Rewrite (optional):
AutoRAGBietet die Möglichkeit zur Verwendung vonWorkers AIDas LLM schreibt die ursprüngliche Eingabeabfrage um und wandelt sie in eine effizientere Suchabfrage um, um die Qualität des Abrufs zu verbessern. - Abfrage-Einbettung: Die umgeschriebene (oder ursprüngliche) Abfrage wird mit demselben Modell wie bei der Dateneinbettung in einen Vektor umgewandelt, um Ähnlichkeitsvergleiche mit den gespeicherten Vektordaten zu ermöglichen.
- Vektorisieren Vektorsuche: Die Abfragevektoren stimmen mit den
AutoRAGzugehörigVectorizeDie Datenbank wird durchsucht, um die wichtigsten Vektoren zu finden. - Metadaten und Content Retrieval:
VectorizeGibt die wichtigsten Textblöcke und ihre Metadaten zurück. Gleichzeitig wird der Text aus demR2Der entsprechende Rohinhalt wird aus dem Speicherbereich abgerufen. Diese Informationen werden an das Textgenerierungsmodell weitergegeben. - Erzeugung von Antworten:
Workers AIDas Textgenerierungsmodell in verwendet den abgerufenen Inhalt und die ursprüngliche Anfrage des Benutzers, um die endgültige Antwort zu generieren.
Das Ergebnis ist eine KI-gesteuerte Antwort, die genau und aktuell ist und auf privaten Nutzerdaten basiert.

Praktische Übungen: Schnelle Erstellung von RAG-Anwendungen mit der Browser-Rendering-API
In der Regel wird das Startup AutoRAG Zeigen Sie einfach auf eine bestehende R2 Speicher-Bucket. Was aber, wenn die Inhaltsquelle eine dynamische Webseite ist, die erst gerendert werden muss, bevor sie abgerufen werden kann?Cloudflare angeboten Browser-Rendering-API (jetzt offiziell verfügbar) löst dieses Problem. Die API ermöglicht Entwicklern die programmatische Steuerung von Headless-Browser-Instanzen, um gängige Aktionen wie das Crawlen von HTML-Inhalten, das Erstellen von Screenshots, das Generieren von PDFs und mehr durchzuführen.
Die folgenden Schritte beschreiben, wie Sie die Browser Rendering API Crawling von Website-Inhalten, Hinterlegung von R2und verbinden Sie es mit dem AutoRAG um eine auf dem Inhalt der Website basierende Frage- und Antwortfunktion zu ermöglichen.
Schritt 1: Erstellen Sie einen Worker zur Erfassung von Webseiten und laden Sie sie auf R2 hoch
Erstellen Sie zunächst eine Cloudflare WorkerVerwenden Sie Puppeteer greift auf die angegebene URL zu, rendert die Seite und speichert den vollständigen HTML-Inhalt in der R2 Lagereimer. Wenn es bereits einen R2 Eimer, kann dieser Schritt übersprungen werden.
- Initialisieren Sie ein neues Arbeitsprojekt (z. B.
browser-r2-worker):npm create cloudflare@latest browser-r2-workerOption
Hello World Starter(math.) GattungWorker onlyFriedenTypeScript. - Montage
@cloudflare/puppeteer::npm i @cloudflare/puppeteer - Erstellen Sie eine Datei mit dem Namen
html-bucketdes R2-Storage-Buckets:npx wrangler r2 bucket create html-bucket - existieren
wrangler.toml(oderwrangler.json) Konfigurationsdatei zum Hinzufügen von Browser-Rendering und R2-Bucket-Bindungen:# wrangler.toml compatibility_flags = ["nodejs_compat"] [browser] binding = "MY_BROWSER" [[r2_buckets]] binding = "HTML_BUCKET" bucket_name = "html-bucket" - Ersetzen Sie es durch das folgende Skript
src/index.tsDieses Skript nimmt die URL aus der POST-Anforderung, verwendet Puppeteer, um den HTML-Code der Seite zu holen und speichert ihn in R2:import puppeteer from "@cloudflare/puppeteer"; interface Env { MY_BROWSER: puppeteer.BrowserWorker; // Correct typing if available, otherwise 'any' HTML_BUCKET: R2Bucket; } interface RequestBody { url: string; } export default { async fetch(request: Request, env: Env): Promise<Response> { if (request.method !== 'POST') { return new Response('Please send a POST request with a target URL', { status: 405 }); } try { const body = await request.json() as RequestBody; // Basic validation, consider adding more robust checks if (!body.url) { return new Response('Missing "url" in request body', { status: 400 }); } const targetUrl = new URL(body.url); // Use URL constructor for parsing and validation const browser = await puppeteer.launch(env.MY_BROWSER); const page = await browser.newPage(); await page.goto(targetUrl.href, { waitUntil: 'networkidle0' }); // Wait for network activity to cease const htmlPage = await page.content(); // Generate a unique key for the R2 object const key = `${targetUrl.hostname}_${Date.now()}.html`; await env.HTML_BUCKET.put(key, htmlPage, { httpMetadata: { contentType: 'text/html' } // Set content type }); await browser.close(); return new Response(JSON.stringify({ success: true, message: 'Page rendered and stored successfully', key: key }), { headers: { 'Content-Type': 'application/json' } }); } catch (error) { console.error("Error processing request:", error); // Return a generic error message to the client return new Response(JSON.stringify({ success: false, message: 'Failed to process request' }), { status: 500, headers: { 'Content-Type': 'application/json' } }); } } } satisfies ExportedHandler<Env>; - Worker einsetzen:
npx wrangler deploy - Test Worker, z.B. Erfassung
Cloudflaredieses Blogbeitrags:curl -X POST https://browser-r2-worker.<YOUR_SUBDOMAIN>.workers.dev \ -H "Content-Type: application/json" \ -d '{"url": "https://blog.cloudflare.com/introducing-autorag-on-cloudflare"}'Oberbefehlshaber (Militär)
<YOUR_SUBDOMAIN>Ersetzen Sie IhrCloudflare WorkersSubdomains.
Schritt 2: AutoRAG-Instanz erstellen und Indizes überwachen
Füllen Sie den Inhalt der Datei R2 Nachdem der Eimer erstellt wurde, wird der AutoRAG Beispiel:
- existieren
CloudflareNavigieren Sie in der Systemsteuerung zu AI > AutoRAG. - Wählen Sie "AutoRAG erstellen" und schließen Sie die Einrichtung ab:
- Wählen Sie die Wissensbasis, die die
R2Lagerkübel (in diesem Fallhtml-bucket). - Wählen Sie das Einbettungsmodell (Standard empfohlen).
- Wählen Sie das LLM aus, das für die Erstellung der Antwort verwendet wird (empfohlener Standard).
- Wählen oder erstellen Sie eine
AI Gatewayum die Verwendung des Modells zu überwachen. - wegen
AutoRAGInstanzbenennung (z.B.my-rag). - Wählen oder erstellen Sie ein Dienst-API-Token, das die Autorisierung der
AutoRAGErstellen Sie Ressourcen in Ihrem Konto und greifen Sie darauf zu.
- Wählen Sie die Wissensbasis, die die
- Wählen Sie "Erstellen", um die
AutoRAGBeispiel.
Nach der Erstellung wird dieAutoRAG wird automatisch eine Vectorize Datenbank und beginnen mit der Indizierung der Daten. Es ist möglich, eine Datenbank in der AutoRAG s Übersichtsseite, um den Indizierungsfortschritt zu sehen. Die Indizierungszeit hängt von der Anzahl und dem Typ der Dateien in der Datenquelle ab.

Schritt 3: Testen und Integrieren in die Anwendung
Sobald die Indizierung abgeschlossen ist, kann die Abfrage beginnen. Die Indizierung kann in der AutoRAG Instanz Spielplatz Stellen Sie auf den Registerkarten Fragen, die sich auf den Upload beziehen, z. B. "Was ist AutoRAG?".
Sobald der Test zufriedenstellend ist, wird die AutoRAG direkt in die Anwendung integriert. Wenn Sie die Cloudflare Workers Erstellung von Anwendungen, die direkt über die KI-Bindung aufgerufen werden können AutoRAG::
existieren wrangler.toml Fügen Sie die Bindung ein:
# wrangler.toml
[ai]
binding = "AI"
Rufen Sie dann im Arbeitscode aiSearch() Methode (um die von der KI generierte Antwort zu erhalten) oder die Search() Methode (um nur eine Liste von Suchergebnissen zu erhalten):
// Example in a Worker using the AI binding
export default {
async fetch(request: Request, env: Env, ctx: ExecutionContext): Promise<Response> {
// Assuming 'env' includes the AI binding: interface Env { AI: Ai }
if (!env.AI) {
return new Response("AI binding not configured.", { status: 500 });
}
try {
const answer = await env.AI.run('@cf/meta/llama-3.1-8b-instruct', { // Example model, replace if needed
prompt: 'What is AutoRAG?', // Simple prompt example
rag: { // Use the RAG configuration via the binding
autorag_id: 'my-rag' // Specify your AutoRAG instance name
}
});
// Or using the specific AutoRAG methods if available via the binding
// const searchResults = await env.AI.autorag('my-rag').Search({ query: 'What is AutoRAG?' });
// const aiAnswer = await env.AI.autorag('my-rag').aiSearch({ query: 'What is AutoRAG?' });
return new Response(JSON.stringify(answer), { headers: { 'Content-Type': 'application/json' }});
} catch (error) {
console.error("Error querying AutoRAG:", error);
return new Response("Failed to query AutoRAG", { status: 500 });
}
}
}
Hinweis: Das obige Beispiel für Worker-Code basiert auf allgemeinen AI-Bindungen und der Integration von RAG-Funktionen, insbesondere AutoRAG Für den Aufruf der Bindung lesen Sie bitte die Cloudflare Offizielle Dokumentation für die neueste und genaueste Verwendung.
Weitere Einzelheiten zur Integration finden Sie unter AutoRAG Verwenden Sie den Abschnitt "AutoRAG" des Beispiels oder schlagen Sie in der Entwicklerdokumentation nach.
Strategische Bedeutung und Wert für Entwickler
AutoRAG Der Start markiert die Cloudflare Die Integration von KI-Funktionen in die Entwicklerplattform wird weiter vertieft. Durch die Integration von Schlüsselkomponenten der RAG-Pipeline (R2, Vectorize, Workers AI, AI Gateway), die als gehosteter Dienst gekapselt sind.Cloudflare Erheblich niedrigere Hürden für Entwickler bei der Entwicklung intelligenter Anwendungen mit ihren eigenen Daten.
Für EntwicklerAutoRAG Der wichtigste Wert derBequemlichkeitEs beseitigt die Last der manuellen Konfiguration und Wartung einer komplexen RAG-Infrastruktur. Es beseitigt den Aufwand für die manuelle Konfiguration und Wartung einer komplexen RAG-Infrastruktur und eignet sich besonders für Teams, die schnell Prototypen erstellen müssen oder nicht über dedizierte MLOps-Ressourcen verfügen. Verglichen mit dem Aufbau einer eigenen RAG-Infrastruktur ist es ein Kompromiss: Sie opfern einen Teil der zugrundeliegenden Kontrolle und Anpassungsflexibilität für eine schnellere Entwicklung und einen geringeren Verwaltungsaufwand.
Gleichzeitig spiegelt dies die Cloudflare Eine Erweiterung der Plattformstrategie: Bereitstellung von immer umfassenderen Rechen-, Speicher- und KI-Diensten am Rande des globalen Netzwerks, die ein eng integriertes Ökosystem bilden. Entwickler nutzen AutoRAG Bedeutet tiefere Integration Cloudflare Technologie-Stack, der einen gewissen Nutzen bringen kannBindung an den LieferantenÜberlegungen, sondern auch dank der optimierten Integration zwischen den Diensten innerhalb der Ökologie.
Während der öffentlichen Testphase werden dieAutoRAG freier Startaber Rechenoperationen wie Indizierung, Abruf und Anreicherung verbrauchen Workers AI im Gesang antworten Vectorize Die Nutzung der zugrundeliegenden Dienste, wie z. B. der Entwickler, muss mit diesen Kosten verbunden sein. Derzeit ist jedes Konto auf die Erstellung von 10 AutoRAG Instanzen, von denen jede bis zu 100.000 DokumenteDiese Einschränkungen können in Zukunft angepasst werden.
Fahrplan für die künftige Entwicklung
Cloudflare anzeigen. AutoRAG wird weiter ausgebaut und soll beispielsweise im Jahr 2025 um weitere Funktionen ergänzt werden:
- Mehr Integration von Datenquellen: abgesehen von
R2Der Plan unterstützt das direkte Parsen von Website-URLs (unter Verwendung von Browser-Rendering-Techniken) und den Zugriff aufCloudflare D1und andere strukturierte Datenquellen. - Verbesserung der Qualität der Antworten: Erkunden Sie integrierte Techniken wie Reranking und rekursives Chunking, um die Relevanz und Qualität der generierten Antworten zu verbessern.
AutoRAG Die Entwicklungsrichtung wird entsprechend dem Feedback der Nutzer und den Anwendungsszenarien kontinuierlich angepasst.
Sofortige Erfahrung
rechts AutoRAG Interessierte Entwickler können Folgendes besuchen Cloudflare Der Abschnitt AI > AutoRAG des Bedienfelds ermöglicht Ihnen, mit der Erstellung und Erprobung zu beginnen. Egal, ob Sie eine KI-Suchfunktion, einen internen Wissensassistenten oder einfach nur eine LLM-Anwendung ausprobieren möchten.AutoRAG Beide bieten die Möglichkeit, etwas in der Welt zu bewirken. Cloudflare Ein Weg, um schnell ein RAG-Projekt in einem globalen Netzwerk zu starten. Ausführlichere Informationen finden Sie in der Dokumentation für Entwickler. In der Zwischenzeit ist das nun offiziell verfügbare Browser-Rendering-API Ebenfalls von Interesse.
© urheberrechtliche Erklärung
Artikel Copyright AI-Austauschkreis Alle, bitte nicht ohne Erlaubnis vervielfältigen.
Ähnliche Artikel

Keine Kommentare...