

为了串联项目执行流程并翻译提示词指令,我们需要根据prompts.py文件中的内容来详细描述每一步的执行流程及其对应的提示词指令。
项目执行流程及对应提示词指令
1. 生成搜索查询以帮助计划报告
- Prompt:
report_planner_query_writer_instructions = """ 你是一名专家技术写手,正在帮助计划一份报告。 <报告主题> {topic} </报告主题> <报告组织> {report_organization} </报告组织> <任务> 你的目标是生成 {number_of_queries} 个搜索查询,以帮助收集全面的信息来规划报告部分。 这些查询应当: 1. 与报告主题相关 2. 帮助满足报告组织中规定的要求 使查询足够具体,以找到高质量、相关的资源,同时覆盖报告结构所需的广度。 </任务> """
2. 生成报告计划
- Prompt:
report_planner_instructions = """ 我需要一个报告计划。 <任务> 生成一个报告部分的列表。 每个部分应当包含以下字段: - 名称 - 报告部分的名称。 - 描述 - 本部分涵盖的主要主题的简要概述。 - 研究 - 是否需要为本部分报告进行网络研究。 - 内容 - 本部分的内容,现在可以留空。 例如,介绍和结论将不需要研究,因为它们将从报告的其他部分提炼信息。 </任务> <主题> 报告的主题是: {topic} </主题> <报告组织> 报告应遵循此组织: {report_organization} </报告组织> <上下文> 以下是用于规划报告部分的上下文: {context} </上下文> <反馈> 以下是对报告结构的审查反馈(如果有): {feedback} </反馈> """
3. 编写搜索查询
- Prompt:
query_writer_instructions = """ 你是一名专家技术写手,正在编写有针对性的网络搜索查询,以收集撰写技术报告部分的全面信息。 <部分主题> {section_topic} </部分主题> <任务> 你的目标是生成 {number_of_queries} 个搜索查询,以帮助收集有关本部分主题的全面信息。 这些查询应当: 1. 与主题相关 2. 检查该主题的不同方面 使查询足够具体,以找到高质量、相关的资源。 </任务> """
4. 撰写报告部分
- Prompt:
section_writer_instructions = """ 你是一名专家技术写手,正在撰写技术报告的一个部分。 <部分主题> {section_topic} </部分主题> <现有部分内容(如果已填写)> {section_content} </现有部分内容> <源材料> {context} </源材料> <撰写指南> 1. 如果现有部分内容未填写,则从头撰写新的部分。 2. 如果现有部分内容已填写,请撰写一个新的部分,将现有内容与新信息综合起来。 <长度和风格> - 严格限制在150-200字 - 不使用营销语言 - 技术重点 - 使用简单、清晰的语言 - 用**加粗**的最重要的见解开头 - 使用简短的段落(每段最多2-3句话) - 使用 ## 作为部分标题(Markdown格式) - 仅在有助于澄清观点时使用一个结构元素: * 要么是比较2-3个关键项目的集中表格(使用Markdown表格语法) * 要么是使用正确的Markdown列表语法的简短列表(3-5项): - 使用 `*` 或 `-` 表示无序列表 - 使用 `1.` 表示有序列表 - 确保正确的缩进和间距 - 以参考以下源材料的###来源结束: * 列出每个来源的标题、日期和URL * 格式:`- 标题 : URL` </长度和风格> <质量检查> - 恰好150-200字(不包括标题和来源) - 仔细使用一个结构元素(表格或列表),仅在有助于澄清观点时 - 一个具体的例子/案例研究 - 以加粗见解开头 - 在创建部分内容之前不作任何序言 - 在结尾引用来源 </质量检查> """
5. 评估报告部分
- Prompt:
section_grader_instructions = """ 审核相对于指定主题的报告部分: <部分主题> {section_topic} </部分主题> <部分内容> {section} </部分内容> <任务> 评估该部分是否通过检查技术准确性和深度,充分涵盖了主题。 如果该部分未满足任何标准,请生成具体的后续搜索查询以收集缺失的信息。 </任务> <格式> grade: Literal["pass","fail"] = Field( description="评估结果,指示响应是否符合要求('通过')或需要修订('失败')。" ) follow_up_queries: List[SearchQuery] = Field( description="后续搜索查询列表。", ) </格式> """
6. 撰写最终的报告部分
- Prompt:
final_section_writer_instructions = """ 你是一名专家技术写手,正在撰写综合报告其他部分信息的部分。 <部分主题> {section_topic} </部分主题> <可用报告内容> {context} </可用报告内容> <任务> 1. 部分特定方法: 对于介绍: - 使用 # 作为报告标题(Markdown格式) - 50-100字限制 - 使用简单和清晰的语言 - 重点介绍报告的核心动机,1-2段 - 使用清晰的叙述弧线介绍报告 - 不使用任何结构元素(无列表或表格) - 不需要来源部分 对于结论/总结: - 使用 ## 作为部分标题(Markdown格式) - 100-150字限制 - 对于比较报告: * 必须包含使用Markdown表格语法的集中比较表 * 表格应提炼报告中的见解 * 保持表格条目清晰简洁 - 对于非比较报告: * 仅在有助于提炼报告中的要点时使用一个结构元素: * 要么是比较报告中项目的集中表格(使用Markdown表格语法) * 要么是使用正确的Markdown列表语法的简短列表: - 使用 `*` 或 `-` 表示无序列表 - 使用 `1.` 表示有序列表 - 确保正确的缩进和间距 - 以具体的下一步或影响结束 - 不需要来源部分 3. 撰写方法: - 使用具体细节而非一般陈述 - 每个字都要有意义 - 重点突出最重要的一点 </任务> <质量检查> - 对于介绍:50-100字限制,# 作为报告标题,无结构元素,无来源部分 - 对于结论:100-150字限制,## 作为部分标题,仅使用一个结构元素,无来源部分 - Markdown格式 - 不在响应中包含字数或任何序言 </质量检查> """
串联执行流程
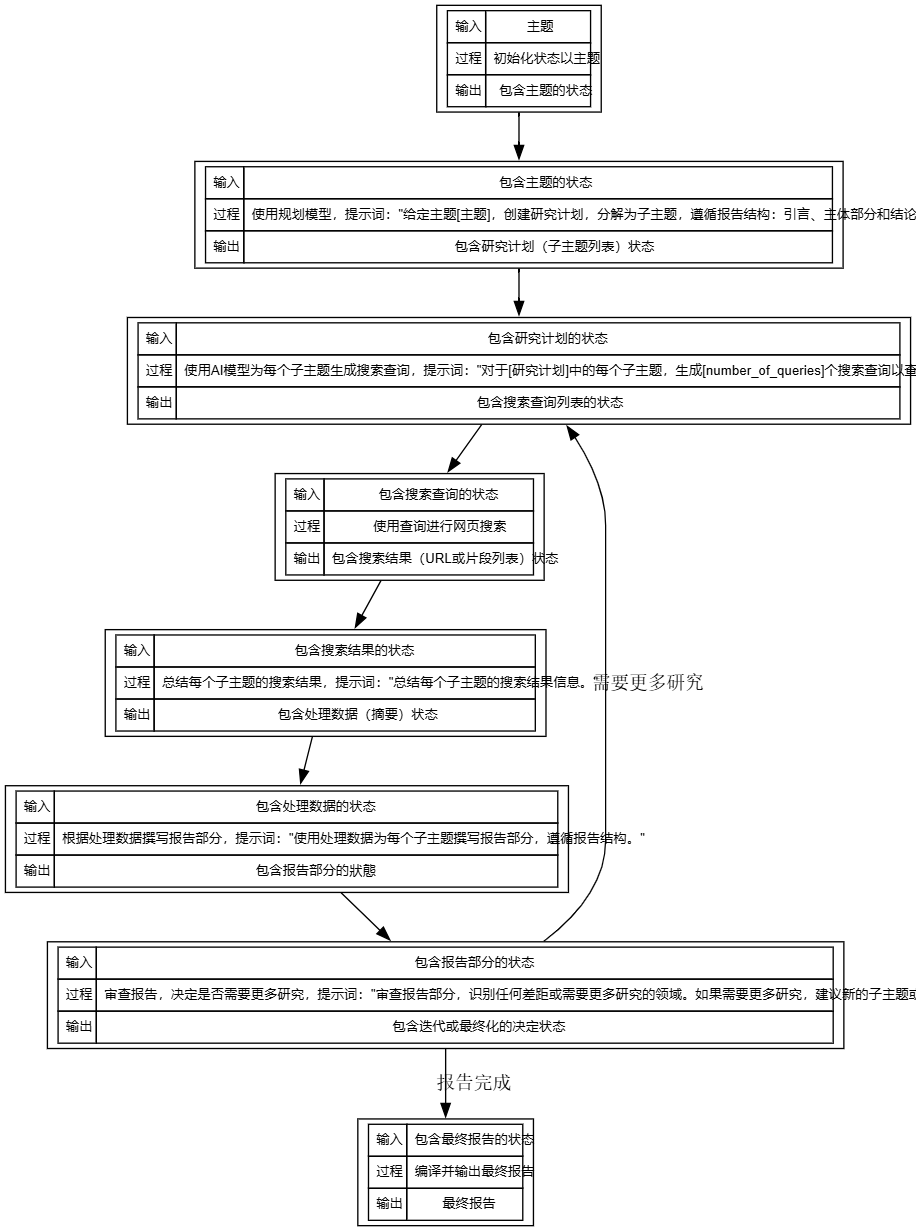
1. 初始化(Start)
- 输入 :用户提供的主题,例如“AI推理市场的概述,重点是Fireworks、Together.ai、Groq”。
- 过程 :系统初始化状态,将主题存储为状态的一部分,无需AI模型调用。
- 输出 :包含主题的状态,供后续步骤使用。
2. 规划(Planning)
- 输入 :包含主题的状态。
- 过程 :使用规划模型(如默认OpenAI o3-mini或Groq的deepseek-r1-distill-llama-70b)生成研究计划。提示词为:“给定主题[主题],创建研究计划,分解为子主题,遵循报告结构:引言、主体部分和结论。”
- 输出 :状态更新为包含研究计划(子主题列表),例如“1. AI推理市场的定义;2. Fireworks的角色;3. Together.ai的案例分析”等。
- 提示词来源 :从configuration.py的DEFAULT_REPORT_STRUCTURE推测,结构包括引言、主体部分和结论,主体部分需涵盖关键概念、定义和实例。
3. 查询生成(Query Generation)
- 输入 :包含研究计划的状态。
- 过程 :使用AI模型为每个子主题生成搜索查询,提示词为:“对于[研究计划]中的每个子主题,生成[number_of_queries]个搜索查询以查找相关信息。”默认number_of_queries为2。
- 输出 :状态更新为包含搜索查询列表,例如“AI推理市场定义 2023”、“Fireworks AI服务案例”等。
- 提示词来源 :从项目文档中提到可配置查询数量,假设提示词为生成查询的通用形式。
4. 网页搜索(Web Search)
- 输入 :包含搜索查询的状态。
- 过程 :使用搜索API(如默认Tavily)执行每个查询,获取网页搜索结果。无AI模型调用,直接通过工具执行。
- 输出 :状态更新为包含搜索结果(URL或片段列表),例如Tavily返回的网页摘要。
- 技术细节 :依赖tavily-python>=0.5.0,需配置TAVILY_API_KEY。
5. 数据处理(Data Processing)
- 输入 :包含搜索结果的状态。
- 过程 :使用AI模型总结每个子主题的搜索结果,提示词为:“总结每个子主题的搜索结果信息。”
- 输出 :状态更新为包含处理数据(摘要),例如“AI推理市场定义:指使用AI模型进行实时预测的行业,2023年增长迅速。”
- 提示词来源 :假设为总结任务的通用提示,基于项目目标为生成报告。
6. 报告撰写(Report Writing)
- 输入 :包含处理数据的状态。
- 过程 :使用撰写模型(如默认Anthropic Claude 3.5 Sonnet)根据处理数据撰写报告部分,提示词为:“使用处理数据为每个子主题撰写报告部分,遵循报告结构。”
- 输出 :状态更新为包含报告部分,例如“引言:AI推理市场是AI应用的重要领域;主体部分1:Fireworks提供高效推理服务,案例包括云端部署。”
- 提示词来源 :结合DEFAULT_REPORT_STRUCTURE,报告需包括概述、关键概念和实例。
7. 反思(Reflection)
- 输入 :包含报告部分的状态。
- 过程 :使用AI模型审查报告,决定是否需要更多研究,提示词为:“审查报告部分,识别任何差距或需要更多研究的领域。如果需要更多研究,建议新的子主题或查询。”
- 输出 :状态更新为包含迭代决定(例如需要更多研究)或最终报告。如果需要迭代,输出新的子主题或查询建议。
- 提示词来源 :从项目文档提到支持反射和迭代,假设提示词为审查和建议的通用形式。
8. 输出(Output)
- 输入 :包含最终报告的状态(当Reflection决定报告完成)。
- 过程 :编译所有报告部分,生成Markdown格式的最终报告,无AI模型调用。
- 输出 :最终报告,例如完整的Markdown文档,供用户下载或查看。
© 版权声明
文章版权归 AI分享圈 所有,未经允许请勿转载。
相关文章


暂无评论...