CAG: Eine cache-gestützte Generierungsmethode, die 40 Mal schneller ist als RAG
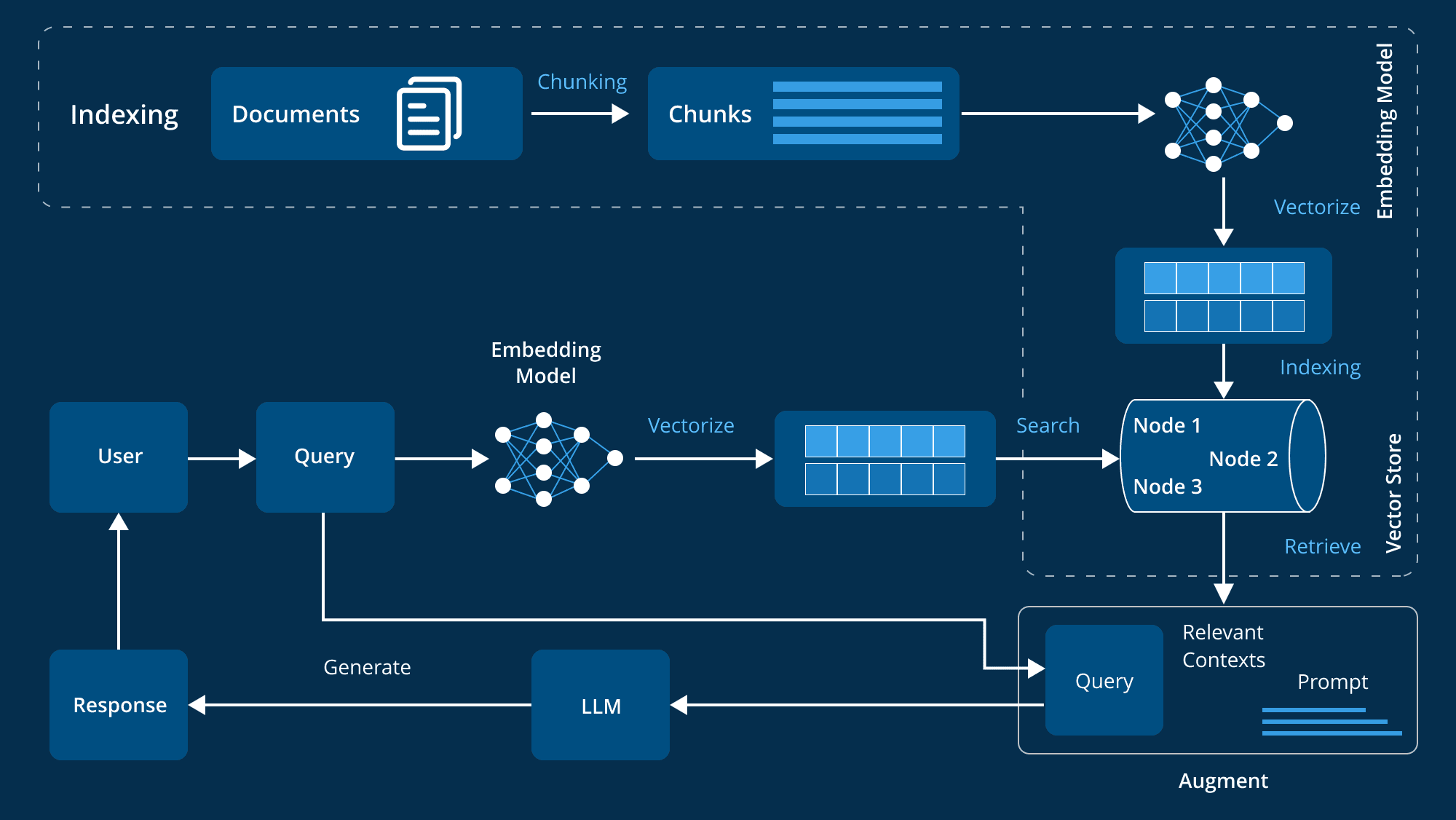
CAG (Cache Augmented Generation), das 40 Mal schneller ist als RAG (Retrieval Augmented Generation), revolutioniert den Wissenserwerb: Anstatt externe Daten in Echtzeit abzurufen, wird das gesamte Wissen in den Modellkontext vorgeladen. Es ist, als würde man eine riesige Bibliothek in ein mobiles Toolkit kondensieren, das man bei Bedarf durchblättern kann, und die CAG-Implementierung ist elegant:
- Das Dokument wird zunächst vorverarbeitet, um sicherzustellen, dass es in das LLM-Kontextfenster passt
- Der verarbeitete Inhalt wird dann in den Key-Value-Cache kodiert
- Schließlich wird dieser Cache im Arbeitsspeicher oder auf der Festplatte gespeichert und kann jederzeit abgerufen werden.
Die Ergebnisse sind überzeugend: Bei Benchmark-Datensätzen wie HotPotQA und SQuAD ist CAG nicht nur 40 Mal schneller, sondern auch wesentlich genauer und kohärenter. Dies ist auf seine Fähigkeit zurückzuführen, den Kontext global zu erfassen, ohne Probleme mit Abfragefehlern oder unvollständigen Daten.
Was die praktischen Anwendungen betrifft, so ist diese Technologie in Bereichen wie der medizinischen Diagnose, der Finanzanalyse und dem Kundendienst vielversprechend. Sie ermöglicht es KI-Systemen, eine hohe Leistung beizubehalten und gleichzeitig den Wartungsaufwand für komplexe Architekturen zu vermeiden.
Letztendlich besteht die Innovation von CAG darin, dass es aus "take-it-as-you-go" ein "carry-it-around" macht, was nicht nur die Effizienz verbessert, sondern auch neue Möglichkeiten für den KI-Einsatz eröffnet. Dies könnte der Standard für die nächste Generation von KI-Architekturen sein.

Referenzen:
[1] https://github.com/hhhuang/CAG
[2] https://arxiv.org/abs/2412.15605
[3] LLMs mit langem Kontext haben mit langem kontextunabhängigem Lernen zu kämpfen: https://arxiv.org/pdf/2404.02060v2
© urheberrechtliche Erklärung
Artikel Copyright AI-Austauschkreis Alle, bitte nicht ohne Erlaubnis vervielfältigen.
Ähnliche Artikel


Keine Kommentare...