Vermeiden Sie die Fallstricke Leitfaden: Taobao DeepSeek R1 Installationspaket bezahlt upsell? Teach you local deployment for free (mit One-Click-Installer)
Kürzlich wurde auf der Plattform Taobao DeepSeek Das Phänomen des Verkaufs von Installationspaketen hat weithin Besorgnis erregt. Es ist überraschend, dass einige Unternehmen von diesem kostenlosen und quelloffenen KI-Modell profitieren. Dies spiegelt auch den Boom wider, den die DeepSeek-Modelle auf lokaler Ebene auslösen.

Wenn Sie auf E-Commerce-Plattformen wie Taobao und Jinduoduo nach "DeepSeek" suchen, können Sie viele Händler finden, die Ressourcen verkaufen, die kostenlos erhältlich sind, darunter Installationspakete, Stichwortpakete, Anleitungen usw. Einige Verkäufer haben sogar DeepSeek-bezogene Anleitungen zum Verkauf angeboten. Einige Verkäufer verkaufen DeepSeek-Tutorials sogar zu einem erhöhten Preis, aber in Wirklichkeit können Benutzer eine große Anzahl kostenloser Download-Links ganz einfach über eine Suchmaschine finden.
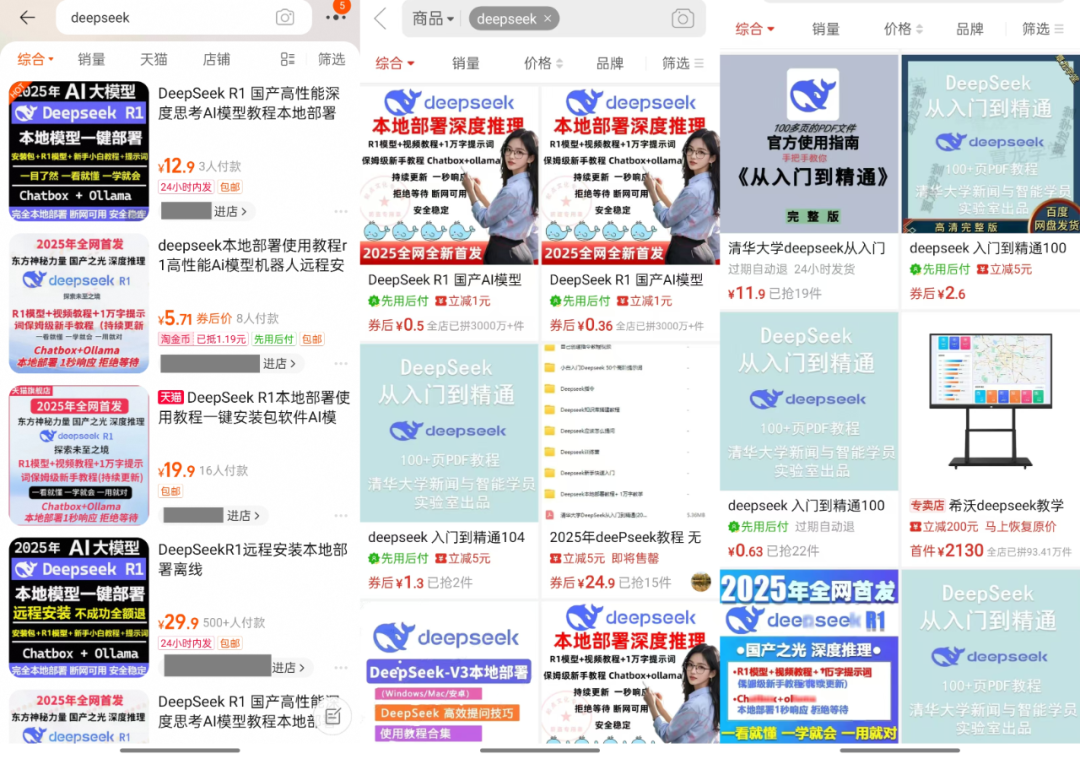
Für wie viel werden diese Ressourcen verkauft? Es wurde beobachtet, dass der Paketpreis von "Installer + Tutorials + Tipps" in der Regel reicht von $ 10 bis $ 30, und die meisten Händler bieten auch ein gewisses Maß an Kundenservice zu unterstützen. Unter ihnen, viele der Waren wurden Hunderte von Kopien, ein paar beliebte Waren und sogar достигают tausend Menschen, um die Skala zu zahlen verkauft worden. Mehr überraschend, ein preislich $ 100 Software-Pakete und Tutorials, sondern auch 22 Menschen wählen, um zu kaufen.

Die Geschäftsmöglichkeiten, die sich durch die Informationslücke ergeben, sind also offensichtlich.
In diesem Artikel zeigen wir dem Leser, wie er DeepSeek-Modelle lokal und kostenlos einsetzen kann. Zuvor werden wir kurz die Notwendigkeit einer lokalen Bereitstellung analysieren.
Warum sollten Sie DeepSeek-R1 lokal einsetzen?
DeepSeek-R1 Modelle sind zwar nicht die leistungsstärksten Inferenzmodelle, die heute verfügbar sind, aber sie sind sicherlich eine sehr gefragte Option auf dem Markt. Bei der direkten Nutzung der Dienste offizieller Hosting-Plattformen oder von Drittanbietern kommt es jedoch häufig zu Serverüberlastungen.
Ein lokales Bereitstellungsmodell kann dieses Problem wirksam umgehen. Kurz gesagt, bedeutet die lokale Bereitstellung, dass KI-Modelle auf den eigenen Geräten der Nutzer installiert werden, anstatt sich auf Cloud-APIs oder Online-Dienste zu verlassen. Zu den gängigen lokalen Bereitstellungsmethoden gehören die folgenden:
- Leichtes lokales ReasoningLäuft auf einem PC oder einem mobilen Gerät, z. B. Llama.cpp, Whisper, Modelle im GGUF-Format.
- Bereitstellung von Servern/WorkstationsAusführen großer Modelle mit Hochleistungs-GPUs oder TPUs, wie der NVIDIA RTX 4090, A100, usw.
- Private Cloud/Intranet-ServerEinsatz auf lokalen Servern, z.B. mit Werkzeugen wie TensorRT, ONNX Runtime, vLLM.
- Einsatz von Edge-GerätenKI-Modelle auf eingebetteten Systemen oder IoT-Geräten wie dem Jetson Nano, Raspberry Pi usw. ausführen.
Verschiedene Bereitstellungsmethoden eignen sich für unterschiedliche Anwendungsszenarien. Lokal eingesetzte Technologien haben ihren einzigartigen Wert in einer Reihe von Bereichen unter Beweis gestellt, zum Beispiel:
- Vor Ort installierte KI-AnwendungenErstellen von privaten Chatbots, Dokumentenanalysesystemen usw.
- wissenschaftliche BerechnungenAnwendungen in der Datenanalyse und Modellbildung in der Biomedizin, der Physiksimulation und anderen Bereichen.
- Offline AI-FunktionenBietet Spracherkennung, OCR und Bildverarbeitungsfunktionen in einer netzunabhängigen Umgebung.
- Sicherheitsaudit und ÜberwachungUnterstützung bei Compliance-Analysen in der Rechts-, Finanz- und anderen Branchen.
In diesem Artikel werden wir uns auf die leichtgewichtige lokale Inferenz konzentrieren, die für eine Vielzahl von Einzelanwendern die wichtigste Einsatzoption darstellt.
Vorteile des lokalen Einsatzes
Neben der Beseitigung der Ursache für das Problem des "ausgelasteten Servers" bietet die lokale Bereitstellung eine Reihe von Vorteilen:
- Datenschutz und DatensicherheitEinsatz von KI-Modellen auf lokaler Ebene macht das Hochladen sensibler Daten in die Cloud überflüssig, wodurch das Risiko von Datenlecks wirksam verhindert wird. Dies ist für Branchen wie das Finanz-, Gesundheits- und Rechtswesen, die ein hohes Maß an Datensicherheit erfordern, von entscheidender Bedeutung. Darüber hinaus hilft die lokale Bereitstellung Unternehmen oder Organisationen bei der Einhaltung von Datenschutzbestimmungen, wie dem chinesischen Datenschutzgesetz und der EU-Grundverordnung.
- Geringe Latenzzeit und EchtzeitleistungDa alle Berechnungen lokal und ohne Netzwerkanfragen durchgeführt werden, hängt die Geschwindigkeit der Schlussfolgerungen ausschließlich von der Rechenleistung des lokalen Geräts ab. Solange die Leistung des Geräts ausreicht, können die Nutzer daher hervorragende Echtzeitreaktionen erzielen, was den lokalen Einsatz ideal für anspruchsvolle Echtzeitanwendungsszenarien wie Spracherkennung, automatisiertes Fahren und industrielle Inspektion macht.
- Langfristige KostenwirksamkeitNative Bereitstellung: Durch die native Bereitstellung entfallen die API-Abonnementgebühren, was eine einmalige und langfristige Nutzung ermöglicht. Bei Anwendungen mit geringen Leistungsanforderungen können die Hardwarekosten auch durch den Einsatz von leichtgewichtigen Modellen wie den quantisierten INT 8- oder 4-Bit-Modellen gesenkt werden.
- Offline-VerfügbarkeitKI-Modelle können auch ohne Netzwerkverbindung genutzt werden, was sich für Edge Computing, Offline-Büros, entfernte Umgebungen und andere Szenarien eignet. Die Fähigkeit, offline zu arbeiten, gewährleistet auch die Kontinuität kritischer Dienste und vermeidet Geschäftsunterbrechungen aufgrund von Netzwerkunterbrechungen.
- Hochgradig anpassbar und kontrollierbarLokaler Einsatz: Durch den lokalen Einsatz können die Benutzer das Modell feinabstimmen und optimieren, um es besser an die spezifischen Geschäftsanforderungen anzupassen. So hat das DeepSeek-R1-Modell zahlreiche fein abgestimmte und destillierte Versionen hervorgebracht, darunter die uneingeschränkte Version deepseek-r1-abliterated. Darüber hinaus unterliegen lokale Bereitstellungen nicht den Richtlinienänderungen Dritter, was eine bessere Kontrolle ermöglicht und potenzielle Risiken wie API-Preisanpassungen oder Zugangsbeschränkungen vermeidet.
Beschränkungen der lokalen Bereitstellung
Die Vorteile des lokalen Einsatzes sind beträchtlich, aber die Einschränkungen sind nicht zu vernachlässigen, nicht zuletzt die Rechenleistung, die für groß angelegte Modelle erforderlich ist.
- Eingaben für HardwarekostenEinzelne Benutzer haben oft Schwierigkeiten, Modelle mit großen Parametern auf ihren lokalen Geräten auszuführen, während Modelle mit kleineren Parametern eine geringere Leistung aufweisen können. Daher müssen die Nutzer einen Kompromiss zwischen Hardwarekosten und Modellleistung eingehen. Das Streben nach Hochleistungsmodellen erfordert zwangsläufig zusätzliche Hardware-Investitionen.
- Fähigkeit zur Verarbeitung umfangreicher AufgabenBei Aufgaben, die eine umfangreiche Datenverarbeitung erfordern, ist häufig Hardwareunterstützung auf Serverebene erforderlich, um sie effektiv zu erledigen. Persönliche Geräte haben einen natürlichen Engpass bei der Verarbeitungsleistung.
- technologische SchwelleVerglichen mit dem Komfort von Cloud-Diensten, die einfach durch den Besuch einer Webseite oder die Konfiguration einer API genutzt werden können, gibt es eine technische Barriere für die lokale Bereitstellung. Wenn die Nutzer ihre Modelle noch feiner abstimmen müssen, wird die Bereitstellung noch schwieriger. Glücklicherweise werden die technischen Hürden für die lokale Bereitstellung nach und nach abgebaut.
- WartungskostenAktualisierungen und Iterationen des Modells und der zugehörigen Werkzeuge können Probleme mit der Konfiguration der Umgebung verursachen, so dass der Benutzer Zeit und Mühe in die Wartung und Problemlösung investieren muss.
Daher muss die Entscheidung für eine lokale Bereitstellung oder ein Online-Modell je nach der tatsächlichen Situation des Nutzers getroffen werden. Nachfolgend finden Sie eine kurze Zusammenfassung der Szenarien, in denen eine lokale Bereitstellung sinnvoll ist und in denen sie nicht sinnvoll ist:
- Für den lokalen Einsatz geeignete SzenarienHohe Anforderungen an den Datenschutz, geringe Latenzzeiten, langfristige Nutzung (z. B. KI-Assistenten für Unternehmen, juristische Analysesysteme usw.).
- Szenarien, die sich nicht für den lokalen Einsatz eignenKurzfristige Testvalidierung, hohe arithmetische Anforderungen, Abhängigkeit von sehr großen Modellen (z. B. 70B+ Parameterebene).
Die private Bereitstellung auf kostenlosen Servern in der Cloud ist ebenfalls ein guter Weg, der schon vor langer Zeit empfohlen wurde, aber eine gewisse technische Basis erfordert:Online-Einsatz des Open-Source-Modells DeepSeek-R1 mit kostenloser GPU-Leistung
Lokale DeepSeek-R1-Bereitstellung in Aktion
Es gibt viele Möglichkeiten, DeepSeek-R1 lokal einzusetzen, aber in diesem Artikel werden wir zwei einfache Optionen vorstellen: basierend auf dem Ollama Bereitstellungsmethoden und Null-Code-Bereitstellungsszenarien mit LM Studio.
Option 1: Ollama-basierter Einsatz von DeepSeek-R1
Ollama ist das vorherrschende Framework für den Einsatz und die Ausführung nativer Sprachmodelle. Es ist leichtgewichtig und hoch skalierbar und hat seit der Veröffentlichung der Llama-Modellfamilie von Meta an Bedeutung gewonnen. Trotz seines Namens ist das Ollama-Projekt von der Gemeinschaft getragen und steht nicht in direktem Zusammenhang mit der Entwicklung von Meta und der Llama-Modellfamilie.

Das Ollama-Projekt wächst schnell, und die Vielfalt der Modelle und Ökosysteme, die es unterstützt, nimmt rapide zu.
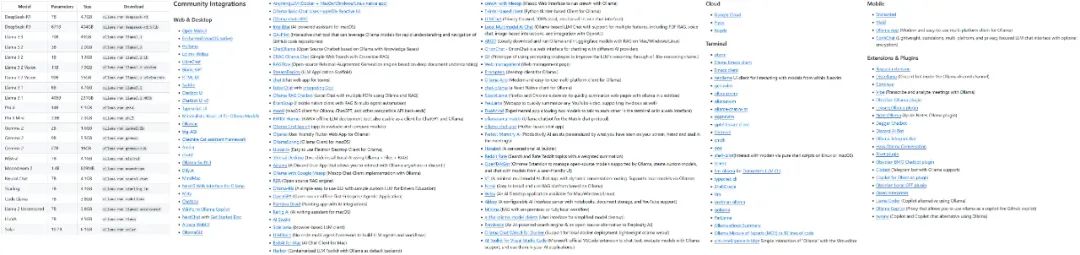
Einige der von Ollama unterstützten Modelle und Ökologien
Der erste Schritt zur Verwendung von Ollama besteht darin, die Ollama-Software herunterzuladen und zu installieren. Besuchen Sie die offizielle Ollama-Download-Seite und wählen Sie die Version aus, die Ihrem Betriebssystem entspricht.
Herunterladen: https://ollama.com/download
Nach der Installation von Ollama müssen Sie das KI-Modell für das Gerät konfigurieren. Nehmen wir DeepSeek-R1 als Beispiel. Besuchen Sie die Modellbibliothek auf der Ollama-Website, um die unterstützten Modelle und Versionen zu durchsuchen:
https://ollama.com/search
DeepSeek-R1 ist in 29 verschiedenen Versionen der Ollama-Modellbibliothek in Maßstäben von 1,5B bis 67B erhältlich, darunter auch auf der Grundlage der Open-Source-Modelle Llama und Qwen feinabgestimmte, destillierte oder quantifizierte Versionen.
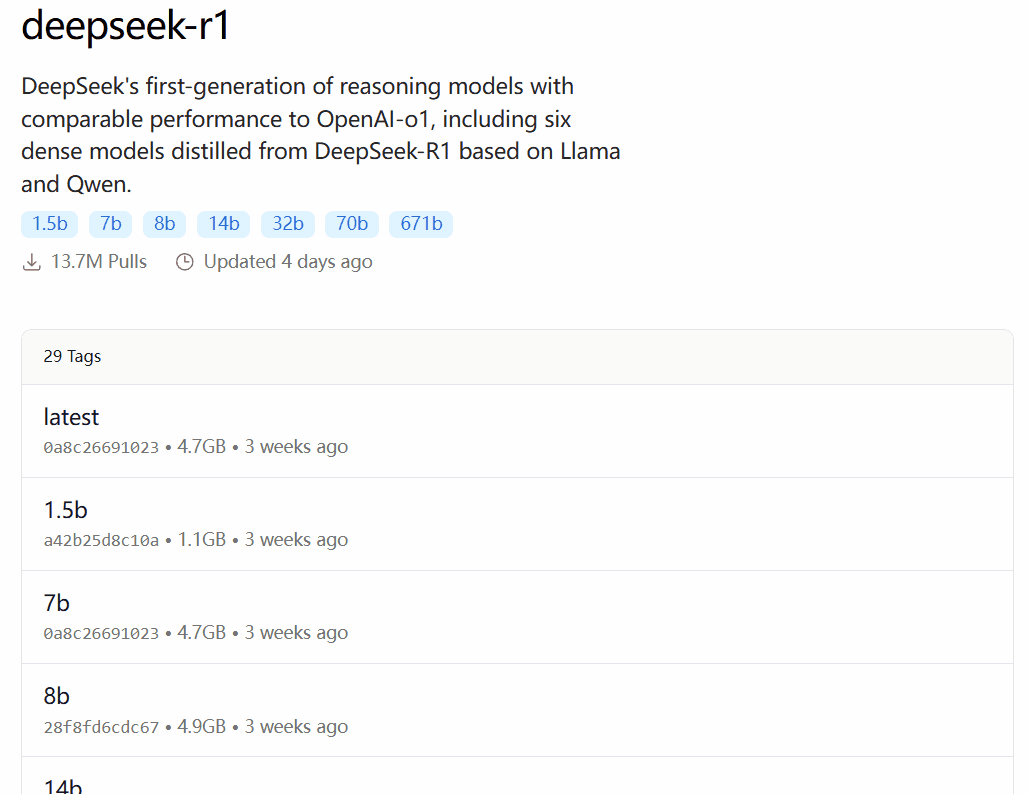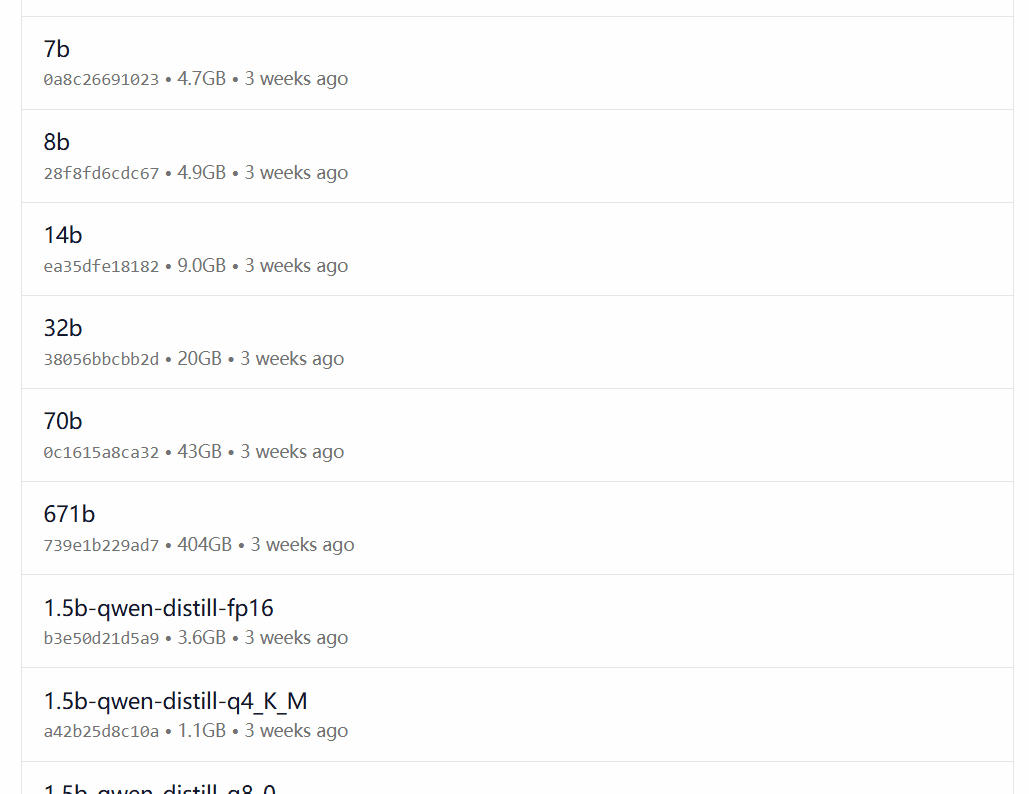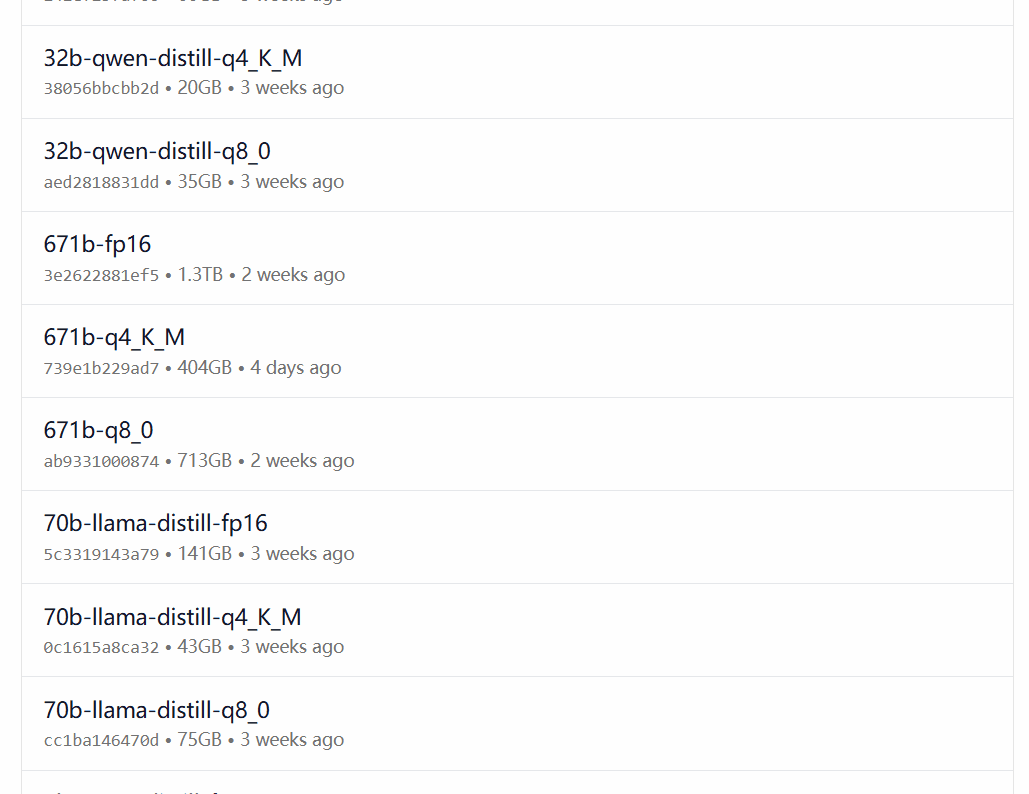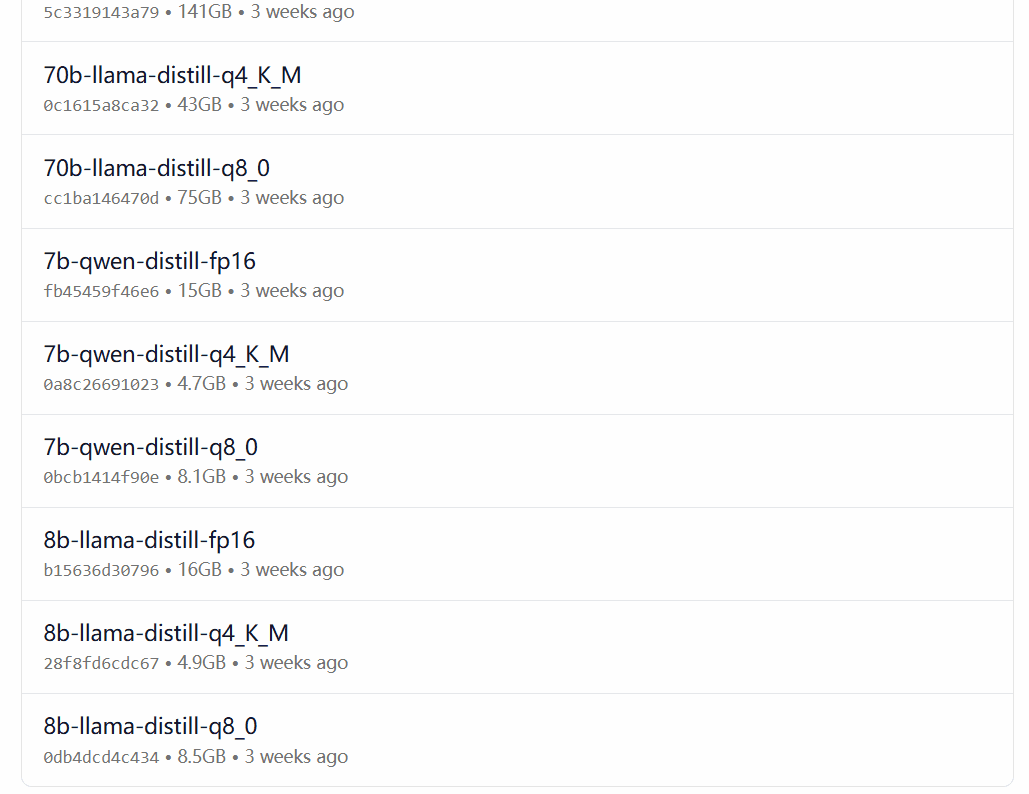
Welche Version zu wählen ist, hängt von der Hardwarekonfiguration des Benutzers ab. Avnish von der dev.to-Entwickler-Community hat einen Artikel geschrieben, der die Hardware-Anforderungen für die unterschiedlich großen Versionen von DeepSeek-R1 zusammenfasst:
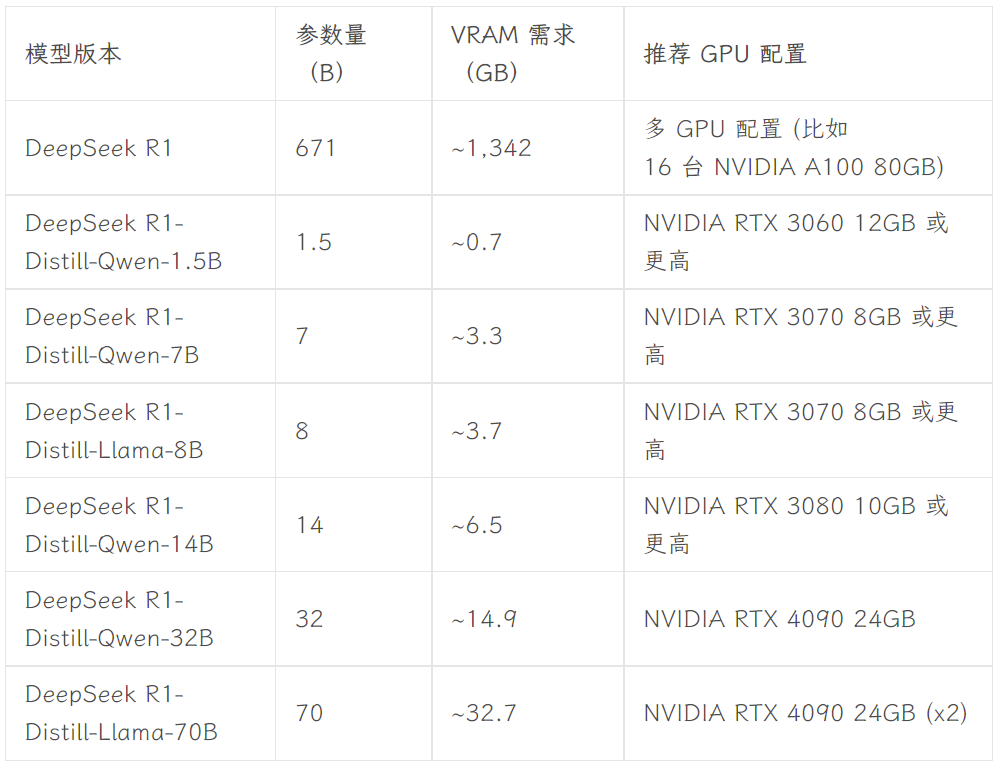
Bildquelle: https://dev.to/askyt/deepseek-r1-architecture-training-local-deployment-and-hardware-requirements-3mf8
In diesem Artikel wird die Version 8B als Beispiel für die Demonstration verwendet. Öffnen Sie das Geräteterminal und führen Sie den folgenden Befehl aus:
ollama run deepseek-r1:8b
Dann warten Sie einfach, bis das Modell fertig heruntergeladen ist. (Ollama unterstützt auch das Herunterladen von Modellen direkt von Hugging Face, mit dem Befehl ollama run hf.co/{Benutzername}/{Bibliothek}:{quantifizierte Version}, z.B. ollama run hf.co/bartowski/Llama-3.2-3B-Instruct-GGUF:Q8_0.)

Sobald das Modell heruntergeladen wurde, können Sie mit der 8B-Version von DeepSeek-R1 im Terminal sprechen.

Diese Art von Terminaldialog ist jedoch für den durchschnittlichen Benutzer nicht intuitiv und bequem. Daher ist ein benutzerfreundliches grafisches Front-End erforderlich. Es gibt eine große Auswahl an Frontends, z. B. das WebUI öffnen Sie erhalten etwas wie ChatGPT Sie können auch wählen Chatbox und andere Desktop-Anwendungen. Weitere Frontend-Optionen finden Sie in der offiziellen Ollama-Dokumentation:
https://github.com/ollama/ollama
- WebUI öffnen
Wenn Sie Open WebUI wählen, führen Sie einfach die folgenden zwei Codezeilen im Terminal aus:
Installieren Sie Open WebUI:
pip install open-webui
Führen Sie den Dienst Open WebUI aus:
open-webui serve
Rufen Sie anschließend http://localhost:8080 in Ihrem Browser auf, um die ChatGPT-ähnliche Weboberfläche zu nutzen. In der Modellliste von Open WebUI sehen Sie mehrere Modelle, die von lokalen Ollama konfiguriert wurden, darunter die Versionen DeepSeek-R1 7B und 8B sowie andere Modelle wie Llama 3.1 8B, Llama 3.2 3B, Phi 4, Qwen 2.5 Coder und so weiter. Für die Tests wurde das Modell DeepSeek-R1 8B ausgewählt:

- Chatbox
Wenn Sie es vorziehen, eine eigenständige Desktop-Anwendung zu verwenden, können Sie Tools wie Chatbox in Betracht ziehen. Die Konfigurationsschritte sind ebenso einfach und beginnen mit dem Herunterladen und Installieren der Chatbox-Anwendung:
https://chatboxai.app/zh
Nach dem Start von Chatbox öffnen Sie die Schnittstelle "Einstellungen", wählen Sie unter "Modellanbieter" die OLLAMA-API und dann in der Spalte "Modell" das gewünschte Modell aus. Wählen Sie dann das gewünschte Modell im Feld "Modell" aus und stellen Sie die Parameter wie die maximale Anzahl von Kontextnachrichten und die Temperatur nach Ihren Bedürfnissen ein (Sie können auch die Standardeinstellungen beibehalten).

Nach der Konfiguration können Sie eine reibungslose Unterhaltung mit dem lokal eingesetzten DeepSeek-R1-Modell in Chatbox führen. Die Testergebnisse zeigen jedoch, dass das DeepSeek-R1 7B-Modell bei der Verarbeitung komplexer Befehle leicht unterdurchschnittlich ist. Dies bestätigt den vorangegangenen Punkt, dass einzelne Nutzer in der Regel nur Modelle mit relativ begrenzter Leistung auf lokalen Geräten ausführen können. Es ist jedoch absehbar, dass mit der Weiterentwicklung der Hardwaretechnologie die Hürden für den lokalen Einsatz von Modellen mit großen Parametern für Einzelanwender in Zukunft weiter sinken werden - und dieser Tag ist vielleicht nicht mehr allzu fern.

**Sowohl Open WebUI als auch Chatbox unterstützen den Zugriff auf DeepSeeks Modelle, ChatGPT und Claude über APIs, Zwillinge und andere Geschäftsmodelle. Die Benutzer können sie als Front-End-Schnittstelle für die tägliche Nutzung von KI-Tools verwenden. Darüber hinaus können die in Ollama konfigurierten Modelle in andere Tools integriert werden, z. B. in Anwendungen zur Erstellung von Notizen wie Obsidian und Civic Notes.
Option 2: Bereitstellung von DeepSeek-R1 ohne Code mit LM Studio
Für Benutzer, die nicht mit der Befehlszeile oder Code vertraut sind, können Sie LM Studio verwenden, um DeepSeek-R1 ohne Code einzusetzen. Besuchen Sie zunächst die offizielle Download-Seite von LM Studio, um das für Ihr Betriebssystem geeignete Programm herunterzuladen:
https://lmstudio.ai
Starten Sie LM Studio nach Abschluss der Installation und legen Sie auf der Registerkarte "Meine Modelle" den lokalen Speicherordner für die Modelle fest:

Als Nächstes laden Sie die benötigten Sprachmodelldateien von Hugging Face herunter und platzieren sie in dem oben genannten Ordner entsprechend der angegebenen Verzeichnisstruktur (LM Studio verfügt über eine eingebaute Modellsuchfunktion, die in der Praxis jedoch nicht gut funktioniert). Beachten Sie, dass Sie die Modelldateien im .gguf-Format herunterladen müssen. Zum Beispiel Untuch Eine von der Organisation bereitgestellte Sammlung von DeepSeek-R1-Modellen:
https://huggingface.co/collections/unsloth/deepseek-r1-all-versions-678e1c48f5d2fce87892ace5
In Anbetracht der Hardwarekonfiguration wählen wir in dieser Arbeit die DeepSeek-R1-Distillate-Version (14B-Parameternummer), die auf der Feinabstimmung des Qwen-Modells basiert, und die quantisierte 4-Bit-Version: DeepSeek-R1-Distill-Qwen-14B-Q4_K_M.gguf.
Nachdem der Download abgeschlossen ist, legen Sie die Modelldateien in dem zuvor festgelegten Ordner gemäß der folgenden Verzeichnisstruktur ab:
Modellordner /unsloth/DeepSeek-R1-Distill-Qwen-14B-GGUF/DeepSeek-R1-Distill-Qwen-14B-Q4_K_M.gguf
Öffnen Sie schließlich LM Studio und wählen Sie das Modell, das Sie laden möchten, oben auf der Anwendungsoberfläche aus, um mit dem lokalen Modell zu kommunizieren.

Der größte Vorteil von LM Studio ist, dass es komplett ohne Code auskommt. Sie müssen weder ein Terminal benutzen noch Code schreiben - Sie müssen nur die Software installieren und die Ordner konfigurieren, was es sehr benutzerfreundlich macht.
Zusammenfassungen
Die Anleitungen in diesem Artikel bieten nur eine grundlegende Ebene für den lokalen Einsatz von DeepSeek-R1. Für eine tiefere Integration dieses beliebten Modells in lokale Arbeitsabläufe ist eine detailliertere Konfiguration erforderlich, z. B. die Einrichtung von Systemaufforderungen und eine erweiterte Modellfeinabstimmung, RAG Integration, Suchfunktion, multimodale Fähigkeiten und Funktionen zum Aufrufen von Tools. Gleichzeitig glaube ich, dass mit der Weiterentwicklung von KI-spezifischer Hardware und Technologien für kleine Modelle die Hürden für den lokalen Einsatz großer Modelle in Zukunft weiter sinken werden. Sind Sie nach der Lektüre dieses Artikels bereit, das DeepSeek-R1-Modell selbst einzusetzen?
Beigefügtes DeepSeek R1+OpenwebUI Ein-Klick-Installationspaket
Das von Sword27 bereitgestellte Ein-Klick-Installationspaket integriert speziell für DeepSeek die WebUI öffnen
DeepSeek lokale Bereitstellung von One-Click-Run, entpackt zu verwenden Unterstützung 1.5b 7b 8b 14b 32b, mindestens Unterstützung für 2G Grafikkarte
Einbauverfahren
1.AI-Umgebung herunterladen: https://pan.quark.cn/s/1b1ad88c7244
2. das Installationspaket herunterladen: https://pan.quark.cn/s/7ec8d85b2f95
Holen Sie sich Hilfe im Originalartikel: https://www.jian27.com/html/1396.html
© urheberrechtliche Erklärung
Artikel Copyright AI-Austauschkreis Alle, bitte nicht ohne Erlaubnis vervielfältigen.
Ähnliche Artikel



Keine Kommentare...