
Meeseeks - Meeseeks - Open-Source-Bewertung der Fähigkeit, Modellanweisungen in einem Prüfungssatz zu befolgen
Meeseeks ist ein Open-Source-Bewertungsset für große Modelle, das vom M17-Team bei Meituan verwendet wird, um die Fähigkeit eines Modells zu bewerten, Anweisungen zu befolgen.Meeseeks verwendet einen dreistufigen Bewertungsrahmen, um umfassend zu messen, ob ein Modell in der Lage ist, Antworten in strikter Übereinstimmung mit den Anweisungen des Benutzers von der Makro- bis zur Mikroebene zu generieren, und bewertet nicht das Wissen über den Inhalt der Antwort als positiv...

gpt-realtime - das neueste KI-Sprachmodell von OpenAI
gpt-realtime ist ein fortschrittliches Sprachmodell von OpenAI, das direkte Audioverarbeitung unterstützt, um natürliche und flüssige Sprache zu erzeugen. Das Modell unterstützt mehrere Sprachen und Stile, versteht nonverbale Hinweise wie Lachen und kann zwischen Sprachen wechseln.
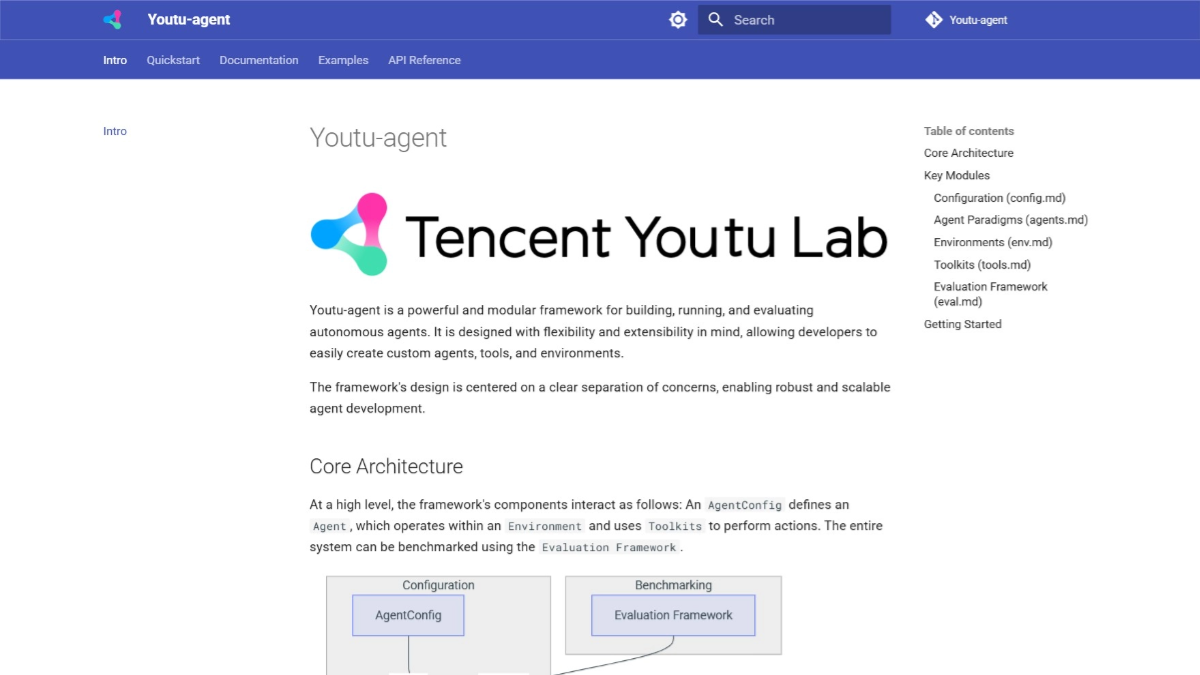
Youtu-agent - Tencent Open-Source-Framework für effiziente intelligente Körper
Youtu-agent ist ein Open-Source-Framework zum Aufbau und Betrieb autonomer Intelligenzen von Tencent Youtu Labs. Das Framework schneidet in den WebWalkerQA- und GAIA-Benchmarks mit einer Genauigkeit von 71,47% bzw. 72,8% gut ab...

HunyuanVideo-Foley - Tencents Open-Source-Modell zur Erzeugung von Videotönen
HunyuanVideo-Foley ist ein Open-Source-Video-Sound-Generierungsmodell von Tencents Mixed-Yuan-Team, das das Hinzufügen von genau abgestimmten Soundeffekten zu stummen Videos unterstützt. Das Modell basiert auf einem groß angelegten Datensatz Ausbildung , mit einem multimodalen Diffusionskonverter Architektur , kombiniert mit der Darstellung der Ausrichtung Verlustfunktion und Audio VAE Optimierungstechniken ...
PixVerse V5 - Selbstentwickeltes AI-Videomodell von Aishi Technologies
PixVerse V5 ist ein großes Modell der KI-Videogenerierung, das von Aishi Technology auf den Markt gebracht wurde. Das Modell kann qualitativ hochwertige Videoinhalte auf der Grundlage von vom Benutzer eingegebenen Textbeschreibungen oder Bildern generieren und unterstützt eine Vielzahl von Stilen, wie Anime, Sci-Fi und nationalen Stil.
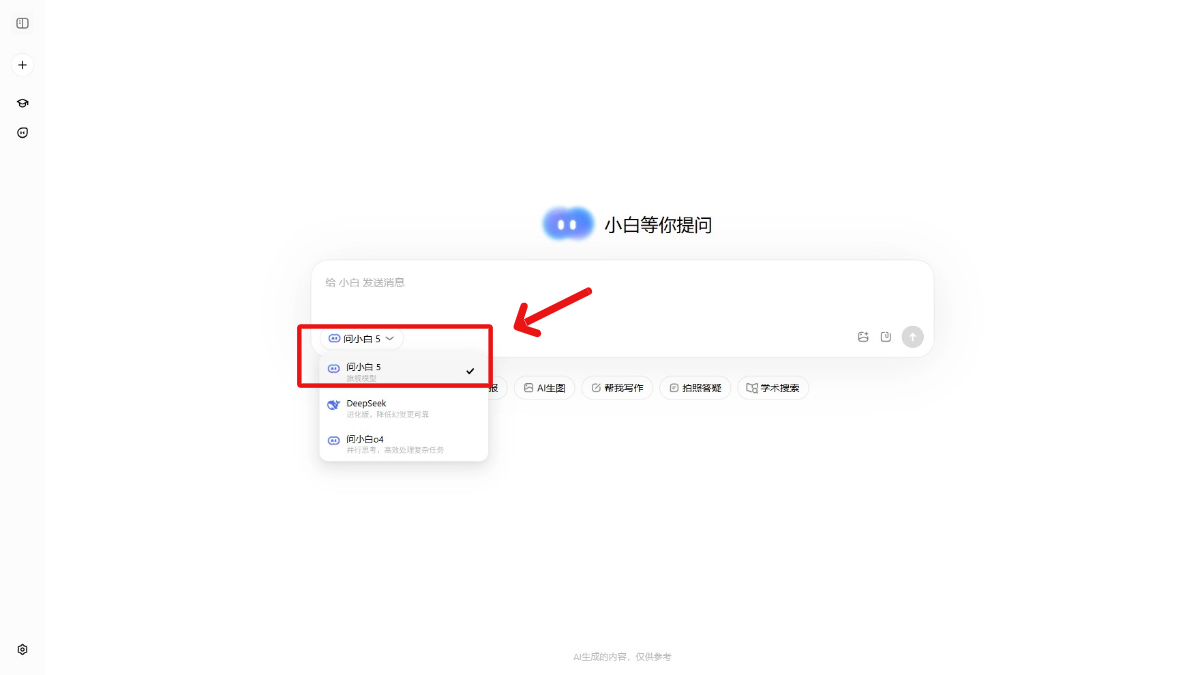
Ask White 5 - All-in-One AI Model von Ask White
Ask White 5 ist das Flaggschiff unter den "All in One"-Modellen mit einem sehr hohen Intelligenzgrad. Das Modell schneidet bei vielen Beurteilungen gut ab, wie z. B. bei der AA-Index-Kompositbeurteilung mit einem Wert von 64,7 und bei der Beurteilung der MINT-Fähigkeiten mit einem Wert von 86, der nahe an den weltweit führenden GPT-5 heranreicht.
Gemini 2.5 Flash Image - Das leistungsfähigste Modell zur Bilderzeugung und -bearbeitung von Google
Gemini 2.5 Flash Image (Codename nano banana) ist ein hochmodernes Bilderzeugungs- und -bearbeitungsmodell von Google, das die Konsistenz von Zeichen in verschiedenen Szenen beibehält und eine präzise Bildbearbeitung durch natürliche Sprache unterstützt, z. B. das Verwischen von Hintergründen und Entfernen von Flecken.

Wan2.2-S2V - Ali Tongyi Open-Source-Modell für die audiogestützte Videoerzeugung
Wan2.2-S2V ist ein Open-Source-multimodale Video-Generierung Modell von Ali Tongyi, nur ein statisches Bild und ein Stück Audio, kann hochwertige digitale menschliche Video zu erzeugen, und unterstützt eine Vielzahl von Bildtypen und Rahmen.
Kostenloser Kurs über ChatGPT Tip Engineering für Entwickler von Ernest Ng
ChatGPT Tip Engineering for Developers ist ein gemeinsamer Kurs von DeepLearning.AI und OpenAI für Entwickler, in dem Isa Fulford und Andrew Ng zeigen, wie man Large Language Models (LLM) verwendet...
Ask o4 - Ein von Ask o4 eingeführtes paralleles Denkmodell, das 8 Denkwege gleichzeitig eröffnet
Ask White o4 ist ein innovatives paralleles Denkmodell, das acht Denkpfade gleichzeitig öffnet, das Problem aus mehreren Perspektiven analysiert und automatisch die optimale Lösung herausfiltert. Das Modell beinhaltet fortschrittliche Long-CoT-Verstärkungslern- und Prozessbelohnungs-Lerntechniken, verfügt über leistungsstarke Deep-Reasoning-Fähigkeiten und erbringt gute Leistungen bei komplexen Aufgaben.