AlphaCodium: Der Weg in eine neue Welt der Codegenerierung, vom Hint Engineering zum Process Engineering

Original: [Modernste Codegenerierung mit AlphaCodium - Vom Prompt Engineering zum Flow Engineering]
Von Tal Ridnik

AlphaCodium: Der Weg in eine neue Welt der Codegenerierung, vom Hint Engineering zum Process Engineering
durchblättern
Die Herausforderungen bei der Codegenerierung unterscheiden sich von denen der gewöhnlichen Verarbeitung natürlicher Sprache - sie beinhalten die strikte Einhaltung der syntaktischen Regeln der Zielprogrammiersprache, die Identifizierung von Normal- und Grenzfällen, die Beachtung zahlreicher Details in der Problemspezifikation und die Bewältigung anderer Probleme und Anforderungen, die für den Code spezifisch sind. Infolgedessen sind viele der Optimierungstechniken, die üblicherweise im Bereich der natürlichen Sprachgenerierung eingesetzt werden, möglicherweise nicht für Codegenerierungsaufgaben geeignet.
In dieser Studie schlagen wir eine neue Methode zur Codegenerierung vor, die AlphaCodium -- Ein testbasierter, schrittweiser, auf den Code ausgerichteter, iterativer Behandlungsprozess. Dieser Ansatz verbessert die Fähigkeit des Large Language Model (LLM), mit Codeproblemen umzugehen, erheblich.
Wir haben AlphaCodium an einem anspruchsvollen Codegenerierungsdatensatz, CodeContests, getestet, der Wettbewerbsprogrammierthemen von Plattformen wie Codeforces enthält. Unser Ansatz erzielt bei diesen Tests durchweg signifikante Leistungssteigerungen.
Zum Beispiel verbesserte sich die Genauigkeit (pass@5) von GPT-4 im Validierungsdatensatz von 19% auf 44% mit einem einzigen gut gestalteten direkten Hinweis, nachdem das AlphaCodium-Verfahren eingesetzt wurde.AlphaCodium übertrifft nicht nur frühere Forschungen wie AlphaCode, sondern benötigt auch deutlich weniger Rechenressourcen AlphaCodium.
Wir sind der Meinung, dass viele der in dieser Arbeit entwickelten Grundsätze und bewährten Verfahren allgemein auf eine Vielzahl von Aufgaben bei der Codegenerierung anwendbar sind. Unser neuestes Open-Source-Projekt [AlphaCodiumUnsere AlphaCodium-Lösung für CodeContests wird in ] zur Verfügung gestellt, mit vollständiger Datenauswertung und Benchmarking-Skripten für weitere Forschung und Erkundung durch die Gemeinschaft.
CodeContests-Datensatz-Parsing
[Code-Wettbewerbe] ist ein anspruchsvoller Programmierdatensatz von Google Deepmind. Er basiert auf Daten wie [CodeforcesEine Wettbewerbs-Programmierplattform wie ] bietet eine Auswahl von etwa 10.000 Programmierthemen, die zum Trainieren und Bewerten großer Sprachmodelle (große Sprachmodelle wie GPT oder DeepSeek) Fähigkeit, komplexe Programmierprobleme zu lösen.
In dieser Studie ging es nicht darum, ein völlig neues Modell zu entwickeln, sondern vielmehr darum, einen Programmierprozess zu schaffen, der auf eine Vielzahl von großen Sprachmodellen anwendbar ist, die bereits in der Lage sind, Codieraufgaben zu bewältigen. Daher konzentrieren wir uns auf die Validierungs- und Testmengen von CodeContests, die aus 107 und 165 Programmierproblemen bestehen. Abbildung 1 zeigt ein Beispiel für ein typisches Problem aus diesem Datensatz:

Abbildung 1: Ein Standardproblem in CodeContests.
Jedes Problem enthält eine Beschreibung des Problems und einige öffentlich verfügbare Testdaten, die direkt als Modelleingabe verwendet werden können. Die Herausforderung besteht darin, ein Verfahren zu schreiben, das für jede legitime Eingabe die richtige Antwort liefert. Darüber hinaus gibt es einen nicht öffentlich zugänglichen Testsatz, der zur Bewertung der Korrektheit des eingereichten Programms verwendet wird.
Warum sind CodeContests ein idealer Datensatz zum Testen der Programmierleistung von großen Sprachmodellen? Erstens enthalten die CodeContests im Gegensatz zu anderen Programmierwettbewerben eine große Menge an privaten Testdaten (etwa 200 Testfälle pro Problem), um die Genauigkeit der Bewertung zu gewährleisten. Die Problembeschreibungen in CodeContests sind typischerweise sowohl komplex als auch detailliert und voller Nuancen, die die Lösung beeinflussen (ein typisches Beispiel ist in Abbildung 1 dargestellt). Dieses Design simuliert die Komplexität realer Probleme und zwingt das Modell dazu, mehrere Faktoren zu berücksichtigen, was im Gegensatz zu einigen der einfacheren und unkomplizierteren Datensätze steht (z. B. [HumanEval]) steht in krassem Gegensatz dazu. Ein typisches HumanEval-Programmierproblem ist in Anhang 1 dargestellt.
Abbildung 2 veranschaulicht, wie das Modell das Problem in Abbildung 1 eingehend analysiert. Durch die eingehende Analyse des Problems wird das Problem klarer und strukturierter, was unterstreicht, wie wichtig ein tieferes Verständnis des Problems während des Programmierprozesses ist.

Abbildung 2: Von der KI generierte Selbstreflexion für das in Abbildung 1 beschriebene Problem.
Vorgeschlagene Methodik
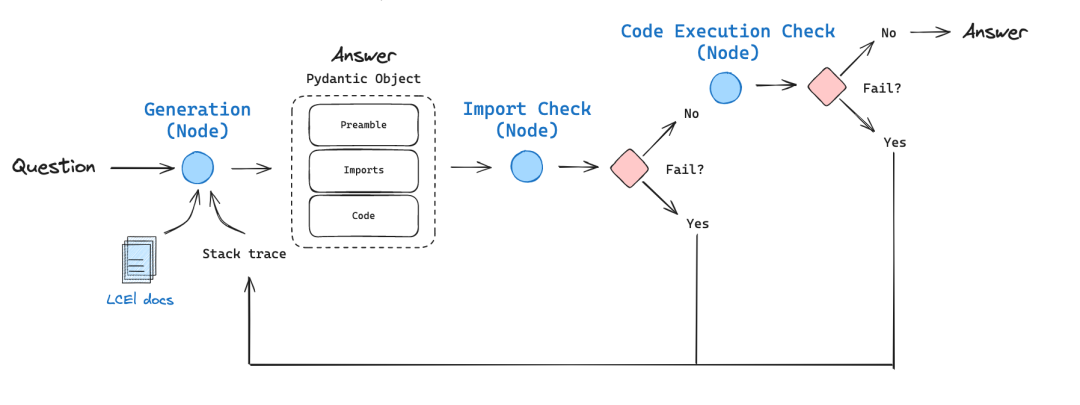
Bei der Bewältigung der komplexen Herausforderungen der Codegenerierung haben wir festgestellt, dass weder die Optimierung mit nur einer Eingabeaufforderung noch die Eingabeaufforderungen zum kontinuierlichen Denken die Problemlösungseffizienz von Large Language Models (LLMs) bei CodeContest erheblich verbessert haben. Dies liegt daran, dass die Modelle oft Schwierigkeiten haben, das Problem vollständig zu verstehen, und daher immer wieder Code produzieren, der falsch ist oder neue Testfälle nicht bewältigen kann. Ansätze, die auf die allgemeine Verarbeitung natürlicher Sprache anwendbar sind, sind möglicherweise nicht ideal für Codegenerierungsaufgaben. Solche Aufgaben bergen ein großes Potenzial, z. B. die wiederholte Ausführung des generierten Codes und seine Überprüfung anhand bekannter Beispiele. Im Gegensatz zu Cue-Optimierungstechniken in der regulären Verarbeitung natürlicher Sprache stellen wir fest, dass die Lösung des CodeContest-Problems durch Codegenerierung und Testen speziell für dieArbeitsabläufeeffektiver zu gestalten. Der Prozess dreht sich umIteration (math.)Der Prozess entfaltet sich, d. h. wir führen den generierten Code kontinuierlich aus und optimieren ihn, damit er die Input-Output-Tests besteht. Die beiden wichtigsten Aspekte dieses code-spezifischen Prozesses sind:
(a) Generierung zusätzlicher Daten in der Vorverarbeitungsphase, z. B. Selbstreflexion und Argumentation für offene Testfälle, um den iterativen Prozess zu unterstützen, und (b) Ergänzung der offenen Testfälle durch zusätzliche, von der KI generierte Testfälle. In Abb. 3 ist der Prozess dargestellt, den wir zur Lösung des Race-Programming-Problems entwickelt haben:

Abbildung 3: Das vorgeschlagene AlphaCodium-Verfahren.

Abbildung 3 Build-Vorverarbeitung und Code-Iterationsfluss
Der Prozess in Abbildung 3 ist in zwei Hauptphasen unterteilt:
- Vorverarbeitung In der ersten Phase denken wir über das Problem mit Hilfe der natürlichen Sprache nach, was ein linearer Prozess ist.
- Code-Iteration Phase, einschließlich mehrerer iterativer Sitzungen, in denen wir Code für verschiedene Tests generieren, ausführen und korrigieren.
In Tabelle 1 werden diese verschiedenen Phasen im Einzelnen dargestellt:
| Name der Bühne | Leitbild |
| Problem Reflexion | Fassen Sie das Problem in Form von prägnanten Aufzählungspunkten zusammen, die die Ziele, Inputs, Outputs, Regeln, Einschränkungen und andere wichtige Details des Problems enthalten. |
| Logische Analyse der offenen Testfälle | Beschreiben Sie, wie die Eingaben zu jedem Testfall zu einer bestimmten Ausgabe führen. |
| Konzeptualisierung möglicher Lösungen | Schlagen Sie 2-3 mögliche Lösungen vor und beschreiben Sie diese in allgemein verständlicher Form. |
| Bewertung der Lösung | Bewerten Sie die verschiedenen möglichen Lösungen und wählen Sie die beste aus, wobei Sie die Korrektheit, Einfachheit und Robustheit der Lösung berücksichtigen. (Es ist nicht notwendig, sich auf die effizienteste Option zu beschränken). |
| Ergänzende AI-Tests | Ergänzen Sie das Problem mit 6-8 verschiedenen Arten von Input-Output-Tests, die versuchen, Situationen und Aspekte abzudecken, die von den ursprünglichen offenen Testfällen nicht abgedeckt werden. |
| Ursprüngliches Code-Programm | Das Ziel dieser Phase ist es, einen ersten Lösungscode für das Problem zu erstellen. Es ist wichtig, dass dieser Code so nah wie möglich an der richtigen Antwort liegt, damit er im anschließenden Korrekturprozess eher erfolgreich ist. Der Betriebsablauf ist wie folgt: - Wählen Sie ein mögliches Szenario aus, schreiben Sie den entsprechenden Code dafür und probieren Sie ihn in ausgewählten öffentlichen Testfällen und KI-Tests aus. - Wiederholen Sie diesen Vorgang, bis der Test bestanden ist oder die maximale Anzahl der Versuche erreicht ist. - Der erste Code, der den Test besteht, oder der Code, dessen Ausgabe der richtigen Antwort am nächsten kommt, wird als Basiscode für die nachfolgenden Schritte verwendet. |
| Iterative Optimierung der offenen Testfälle | Nehmen Sie den Basiscode als Ausgangspunkt, führen Sie ihn nach und nach in offenen Testfällen aus und optimieren Sie ihn. Wenn der Code in einem der Tests ein Problem hat, versuchen Sie, es anhand der Fehlermeldung zu beheben. |
| Iterative Optimierung für AI-Tests | Fortsetzung der iterativen Optimierung von KI-generierten Tests. Anwendung von "Testankern" (eine Technik zur Fixierung bestimmter Elemente in Tests, um den Code genauer zu debuggen und zu verbessern). |
Tabelle 1: Charakterisierung der AlphaCodium-Phasen.
Bei der Untersuchung des vorgeschlagenen Prozesses haben wir einige tiefgreifende Einsichten gewonnen.
erstenskumulierte KenntnisseStufen des Prozesses: Wir beginnen mit einfachen Aufgaben und fordern uns nach und nach mit komplexeren Problemen heraus. Zum Beispiel lernen wir im ersten Schritt des Prozesses, der _Selbstreflexion_, Wissen, das in den nachfolgenden, schwierigeren Schritten genutzt werden kann, wie zum BeispielErarbeitung möglicher Lösungen. Die Vorverarbeitungsphase des Prozesses führt zu Ergebnissen, die den anspruchsvollsten und kritischsten Teil des Prozesses vorantreiben: die Iteration des Codes, bei der wir tatsächlich versuchen, einen Code zu schreiben, der das Problem korrekt löst.
Nächste.Die Generierung zusätzlicher AI-Tests ist einfacher als die Generierung eines vollständigen Lösungscodes -- Dieser Prozess stützt sich stark auf das Verständnis des Problems und grundlegende Brute-Force-Lösungen oder logisches Denken, ohne dass das Problem vollständig gelöst werden muss, um nützliche Eingabe-Ausgabe-Testpaare zu erzeugen. Dies unterscheidet sich vom Schreiben eines vollständigen und korrekten Lösungscodes, bei dem wir eine vollständige algorithmische Lösung entwickeln müssen, die auf jedes Eingabe-Ausgabe-Testpaar korrekt reagieren kann. Infolgedessen können wir mehr KI-Tests erstellen und sie zur Optimierung der Codeerstellungsphase verwenden, wie in Abbildung 4 dargestellt. Wir können die Effektivität dieser zusätzlichen Tests noch weiter steigern, indem wir das Modell bitten, sich auf die Bereiche zu konzentrieren, die von den ursprünglichen öffentlichen Testfällen nicht abgedeckt werden, wie z. B. die Behandlung großer Eingaben, Randfälle usw.
Endlich.Mehrere Schritte können zu einem einzigen Large Language Model (LLM)-Aufruf kombiniert werden -- Der in Abbildung 3 dargestellte Prozess ist eine konzeptionelle Demonstration, die die wichtigsten Schritte des Prozesses hervorhebt. In der Praxis können wir durch die Strukturierung der Ausgabe (siehe nächster Abschnitt) mehrere Schritte zu einem einzigen großen Sprachmodellaufruf zusammenfassen, um Ressourcen zu sparen oder die Leistung des Modells zu verbessern, wenn bestimmte Aufgaben gleichzeitig bearbeitet werden.

Abbildung 4. zeigt die Verbesserungen, die durch die Anwendung des AlphaCodium-Verfahrens erzielt wurden.
Modelle haben oft Probleme, wenn sie Codeprobleme nur auf der Grundlage von direkten Hinweisen lösen. Die Iteration mit öffentlich verfügbaren Testfällen stabilisiert und verbessert die Lösung, hinterlässt aber "blinde Flecken", weil die öffentlich verfügbaren Testfälle nicht umfassend genug sind. Wenn wir den gesamten AlphaCodium-Prozess nutzen, einschließlich der Vorverarbeitungsphase und der Iteration von öffentlichen und KI-generierten Tests, können wir die Qualität der Lösung weiter verbessern und die Erfolgsquote der Problemlösung erheblich steigern.
Designkonzepte für Code
In diesem Abschnitt stellen wir einige Designkonzepte, Techniken und Best Practices vor, die wir bei der Lösung von Codegenerierungsproblemen als nützlich empfunden haben. Der AlphaCodium-Prozess, den wir in Abbildung 3 vorstellen, macht ausgiebig Gebrauch von diesen Designkonzepten:
YAML-strukturierte Ausgabe: Ein wichtiger Bestandteil des von uns vorgeschlagenen Prozesses ist die Verwendung von strukturierten Ausgaben - das Modell muss eine YAML-formatierte Ausgabe erzeugen, die einer bestimmten Pydantic-Klasse entspricht. Ein Beispiel:
...
Ihr Ziel ist es, mögliche Lösungen zu finden.
Sicherstellen, dass die Ziele, Regeln und Beschränkungen des Problems in jedem Programm vollständig berücksichtigt werden.
Die Ausgabe muss ein YAML-Objekt sein, das dem Typ $P PossibleSolutions gemäß der folgenden Pydantic-Definition entspricht:
class Solution(BaseModel).
name: str = Field(description="Name der Lösung")
content: str = Field(description=Beschreibung der Lösung")
why_it_works: str = Field(description="Warum diese Lösung funktioniert. Muss speziell auf die Regeln und Ziele des Problems abgestimmt sein.")
complexity: str = Field(description="Die Komplexität der Lösung")
class PossibleSolutions(BaseModel).
possible_solutions: List[Solution] = Field(max_items=3, description="Eine Liste von möglichen Lösungen für das Problem. Stellen Sie sicher, dass jede Lösung die Regeln und Ziele des Problems vollständig berücksichtigt und eine vernünftige Laufzeit auf einem modernen Computer hat - nicht mehr als drei Sekunden für Problemeinschränkungen mit einer großen Anzahl von Eingaben.")
Tabelle 2: Beispiele für strukturierte Eingabeaufforderungen (Phase "Generate Possible Solutions").
Die strukturierte Ausgabe reduziert die Komplexität des "cue engineering" und die Notwendigkeit des Hackens und stellt stattdessen komplexe Aufgaben in einer einfachen, codeähnlichen Weise dar. Sie ermöglicht es auch, komplexe Antworten zu erhalten, die mehrere Stufen umfassen und logische und organisierte Denkprozesse widerspiegeln.
Obwohl die neue Version von GPT die [JSON-StilWir sind jedoch der Meinung, dass insbesondere bei Aufgaben der Codegenerierung die YAML-Ausgabe besser geeignet ist, wie im Anhang beschrieben.
Analyse der Aufzählungspunkte - Wenn ein Large Language Model (LLM) mit der Analyse eines Problems beauftragt wird, werden in der Regel bessere Ergebnisse erzielt, wenn die Ausgabe in einem Bullet-Points-Format angefordert wird. Aufzählungspunkte fördern ein tieferes Verständnis des Problems und zwingen das Modell, die Ausgabe in logische semantische Bereiche zu unterteilen, wodurch die Qualität der Ergebnisse verbessert wird. Im Fall des Bullet-Point-Problems zur Selbstreflexion (siehe Abbildung 2) steht beispielsweise jeder Bullet-Point für ein semantisches Verständnis eines anderen Teils des Problems - allgemeine Beschreibung, Ziele und Regeln, Input-Struktur und Output-Struktur.
Große Sprachmodelle können besser modularen Code erzeugen - Wenn wir das Large Language Model (LLM) einen langen Block einzelner Funktionen schreiben lassen, stoßen wir oft auf Probleme: Der Code enthält oft Fehler oder Logiklöcher. Schlimmer noch, solch große und monolithische Code-Blöcke können spätere Iterationen zur Fehlerbehebung behindern. Selbst wenn Fehlerinformationen bereitgestellt werden, ist es für das Modell schwierig, das Problem zu lokalisieren und zu beheben. Wenn wir das Modell jedoch ausdrücklich anweisen, "_den generierten Code in mehrere kleine subfunktionale Module aufzuteilen und ihnen sinnvolle Namen zu geben_", werden die Ergebnisse viel besser sein, mit weniger Fehlern im generierten Code und einer höheren Erfolgsquote in der iterativen Korrekturphase.
Die Bedeutung einer flexiblen Entscheidungsfindung und einer doppelten Validierung - Große Sprachmodelle haben oft Schwierigkeiten mit Codeaufgaben, die durchdachte, rationale Schlussfolgerungen und die Fähigkeit erfordern, ernsthafte, nicht routinemäßige Entscheidungen zu treffen. Wenn zum Beispiel zusätzliche Tests für ein Problem erstellt werden, enthalten die vom Modell generierten Tests oft Fehler. Um dieses Problem zu lösen, führen wir den Prozess der doppelten Validierung ein. Bei diesem Prozess wird das Modell nach der Erzeugung der ersten Ausgabe aufgefordert, dieselbe Ausgabe erneut zu erzeugen und sie gegebenenfalls zu korrigieren. Nachdem das Modell zum Beispiel seine eigenen AI-Tests als Eingabe erhalten hat, muss es diese Tests neu generieren und die Fehler darin (falls vorhanden) rechtzeitig korrigieren. Wir haben festgestellt, dass dieser doppelte Validierungsschritt das Modell nicht nur zum kritischen Denken und Überlegen anregt, sondern auch effektiver ist als direkte Ja/Nein-Fragen wie "Ist dieser Test korrekt?" wie Ja/Nein-Fragen.
Entscheidungen hinauszögern, direkte Fragen vermeiden, Raum für Erkundungen geben - Wenn wir komplexe Fragen direkt an das Modell stellen, erhalten wir oft falsche oder unrealistische Antworten. Wir haben daher einen Ansatz gewählt, der dem ähnelt, den Karpathy im folgenden Tweet beschreibt: Wir sammeln schrittweise Daten und gehen allmählich von einfachen zu komplexen Aufgaben über:
- Beginnend mit den einfachsten Aufgaben, d.h. Selbstreflexion über das Problem und Überlegungen zu offenen Testfällen.
- Gehen Sie dann dazu über, zusätzliche AI-Tests und mögliche Lösungen für das Problem zu entwickeln.
- Erst nachdem wir die Antworten des Modells auf die oben genannten Aufgaben erhalten haben, gehen wir zum eigentlichen iterativen Prozess der Codegenerierung und der Durchführung von Korrekturen über.

Karpathy: Das passt perfekt zum "Bedarf an einem großen Sprachmodell (LLM)". Token Die Idee des "Denkens". In manchen Fällen dient die Gedankenkette lediglich als zusätzlicher Informationsspeicher, anstatt andere, wichtigere Funktionen zu erfüllen.
Ein weiteres Beispiel: Anstatt eine einzige algorithmische Lösung zu wählen, bewerten und bewerten wir mehrere mögliche Lösungen und geben den am besten bewerteten für die erste Codeerstellung den Vorrang. Da Modelle schief gehen können, ziehen wir es vor, irreversible Entscheidungen zu vermeiden, und lassen stattdessen Raum für Exploration und Code-Iterationen, die verschiedene mögliche Lösungen ausprobieren.
Prüfdübel-Technologie - Trotz zweifacher Validierung können einige KI-generierte Tests immer noch falsch sein. Das wirft ein Problem auf: Wenn ein Test fehlschlägt, wie können wir feststellen, ob es sich um ein Problem mit dem Code oder einen Fehler im Test selbst handelt? Wenn wir das Modell direkt danach fragen, was falsch ist, erhalten wir oft unrealistische Antworten, was manchmal zu falsch geändertem Code führt. Um diese Herausforderung zu bewältigen, haben wir einen Ansatz namens "Testanker" eingeführt:
- Iterieren Sie zunächst mit Tests, die öffentlich verfügbar und als korrekt bekannt sind. Sobald dieser Schritt abgeschlossen ist, werden alle bestandenen Tests als Benchmark-Tests (Ankertests) bezeichnet.
- Beginnen Sie dann, die von der KI erstellten Tests nacheinander zu überprüfen.
- Diejenigen, die den Test bestehen, werden in die Anker-Testliste aufgenommen.
- Schlägt der Test fehl, wird standardmäßig festgestellt, dass der Code falsch ist, und es wird versucht, den Code zu korrigieren. Wichtig ist, dass der korrigierte Code auch alle bestehenden Ankertests bestehen muss.
Auf diese Weise schützen Ankertests davor, dass wir unseren Code falsch korrigieren, wenn wir ihn korrigieren. Eine weitere Verbesserung für Ankerpunkttests ist die Sortierung der KI-generierten Tests nach Schwierigkeitsgrad. Dadurch sind Ankertests zu Beginn des iterativen Prozesses leichter verfügbar und bieten zusätzliche Sicherheit beim Umgang mit komplexeren KI-Tests, insbesondere bei KI-Tests, die mit größerer Wahrscheinlichkeit eine falsche Ausgabe haben. Diese Strategie erhöht effektiv die Stabilität und Zuverlässigkeit des Testprozesses, insbesondere bei komplexen und anspruchsvollen KI-Tests.
am Ende
Vergleich von Direct Tips mit AlphaCodium
In Abbildung 5 vergleichen wir die Ergebnisse von AlphaCodium mit denen einer einzigen gut konzipierten direkten Hinweismethode. Das Bewertungskriterium ist pass@k (Erfolgsrate bei der Lösung des Problems), d.h. der Anteil der Lösungen, die durch die Verwendung von k für jedes Problem generiert wurden.

Abbildung 5: Vergleich der AlphaCodium-Methode mit der direkten Cueing-Methode bei verschiedenen Modellen.
Es zeigt sich, dass der AlphaCodium-Ansatz die Leistung von Large Language Models (LLMs) bei der Lösung von Programmierproblemen mit CodeContests signifikant und konsistent verbessert. Diese Schlussfolgerung gilt sowohl für Open-Source-Modelle (z. B. DeepSeek) als auch für Closed-Source-Modelle (z. B. GPT), sowohl auf Validierungs- als auch auf Test-Sets.
Vergleich mit anderen Studien:
In Tabelle 3 zeigen wir die Ergebnisse von AlphaCodium im Vergleich zu anderen Methoden in der Literatur.
| Modellierung | Datensatz | Methodologien | Ergebnis |
| GPT-3.5 | Validierungssatz | AlphaCodium (pass@5) | 25% |
| GPT-3.5 | Validierungssatz | CodeChain (pass@5) | 17% |
| GPT-3.5 | Testsatz | AlphaCodium (pass@5) | 17% |
| GPT-3.5 | Testsatz | CodeChain (pass@5) | 14% |
| GPT-4 | Validierungssatz | AlphaCodium (pass@5) | 44% |
| DeepMind-Feinabstimmung | Validierungssatz | AlphaCode (Pass@10@1K) | 17% |
| DeepMind-Feinabstimmung | AlphaCode (Pass@10@100K) | 24% | |
| GPT-4 | Testsatz | AlphaCodium (pass@5) | 29% |
| DeepMind-Feinabstimmung | Testsatz | AlphaCode (Pass@10@1K) | 16% |
| DeepMind-Feinabstimmung | Testsatz | AlphaCode (Pass@10@100K) | 28% |
| Gemini-Pro | AlphaCode2: Vergleichsergebnisse für AlphaCode2 werden in den bestehenden CodeContests-Versionen nicht gemeldet. Laut Technischer Bericht über AlphaCode2Die Forscher verglichen die Ergebnisse von AlphaCode mit denen von AlphaCode2 auf einem unveröffentlichten Datensatz und stellten eine signifikante Verringerung der Anzahl der Aufrufe des großen Sprachmodells (LLM) fest (@100) schneidet AlphaCode2 vergleichbar ab wie AlphaCode, da beide 29%, Pass@10. |
Tabelle 3: Vergleich von AlphaCodium mit anderen Forschungsarbeiten in der Literatur

Abbildung 6: Vergleich der Effizienz.
Die Abbildung zeigt, dass der AlphaCodium-Ansatz unter einer Vielzahl von Modellen und Bewertungskriterien eine hervorragende Leistung zeigt, insbesondere bei der Lösung von Programmieraufgaben mit großen Sprachmodellen. Diese vergleichenden Ergebnisse demonstrieren nicht nur die technische Innovation von AlphaCodium, sondern unterstreichen auch seine Effektivität und Anwendbarkeit in realen Anwendungen.
Insgesamt demonstriert AlphaCodium sein bemerkenswertes Potenzial im Bereich der intelligenten Programmierung, insbesondere bei der Verbesserung der Fähigkeit großer Sprachmodelle, komplexe Programmierprobleme zu bewältigen. Diese Ergebnisse liefern wichtige Erkenntnisse für zukünftige Forschung und Entwicklung und bieten wertvolle Hinweise für die weitere Entwicklung und Optimierung großer Sprachmodelle.
Abbildung 6: Vergleich der Effizienz. Hier sehen Sie, wie AlphaCodium im Vergleich zu anderen Lösungen in Bezug auf die Genauigkeit und die Anzahl der LLM-Aufrufe (Large Language Model) abschneidet. Im Vergleich zu AlphaCode benötigt AlphaCodium tausendmal weniger LLM-Aufrufe, um eine ähnliche Genauigkeit zu erreichen.
Wenn wir AlphaCodium mit demselben GPT-3.5-Modell und dem Kriterium "5 Versuche zum Bestehen" vergleichen [CodeChainDer Vergleich mit [ ] zeigt, dass AlphaCodium besser abschneidet. Im Vergleich zu [AlphaCodeBeim Vergleich der Methoden von [AlphaCode] ist zu beachten, dass AlphaCode eine andere Strategie zur Codegenerierung verwendet: Es optimiert ein spezielles Modell zur Lösung des Codierungsproblems, generiert eine große Anzahl von Codierungsszenarien, klassifiziert diese und wählt schließlich aus den Hauptklassifizierungen eine Anzahl von Szenarien zur Einreichung aus. Zum Beispiel bedeutet "10 Versuche aus 100.000 Lösungen", dass es 100.000 Lösungen generiert, sie klassifiziert und dann 10 auswählt, um sie einzureichen.AlphaCode verwendet ein speziell optimiertes Modell, das eine höhere Anzahl von LLM-Aufrufen verwendet, ähnlich einer erschöpfenden Strategie. Nichtsdestotrotz schnitt AlphaCodium besser ab, was die Spitzenergebnisse angeht.
Es ist auch erwähnenswert, dass weder AlphaCode noch CodeChain replizierbare Lösungen anbieten, einschließlich vollständiger End-to-End-Evaluierungsskripte. Es gibt viele Details, die bei der Bewertung der Ergebnisse berücksichtigt werden müssen, wie z. B. die Behandlung von Themen mit mehreren Lösungen, Fehlertoleranzmechanismen, Timeout-Probleme und so weiter. Unser Vergleich basiert auf den Daten, die in den Veröffentlichungen der beiden Autoren enthalten sind. Um jedoch die Zuverlässigkeit und Reproduzierbarkeit zukünftiger Vergleiche zu gewährleisten, stellen wir einen vollständigen Satz reproduzierbarer Codes und Auswertungsskripte zur Verfügung.
Vergleich der Rechenleistung: AlphaCode vs. AlphaCode2
Im AlphaCodium-Prozess erfordert die Lösung jedes Problems etwa 15-20 Aufrufe des Large Language Model (LLM), was bedeutet, dass bei fünf Versuchen etwa 100 Aufrufe des LLM erforderlich sind.
Und AlphaCode gibt nicht ausdrücklich an, wie viele Aufrufe des großen Sprachmodells pro Problem erforderlich sind. Wenn wir davon ausgehen, dass es einmal pro Versuch aufgerufen wird (was noch unbekannt ist und tatsächlich mehr sein könnte), dann müsste es für jeden der 10 Versuche, die aus den 100.000 Lösungen gefiltert wurden, das große Sprachmodell 1 Million Mal aufrufen, was vier Größenordnungen mehr ist als AlphaCodium. Die Ergebnisse, die wir gesehen haben, zeigen jedoch, dass AlphaCodium viel besser abschneidet, wie in Abbildung 3 deutlich zu sehen ist.
Eine kürzlich veröffentlichte Studie namens AlphaCode2 ([...Technischer Bericht]), in der die Forscher ein Modell namens Gemini-Pro evaluierten, das auf Programmierprobleme abgestimmt ist. In der Studie wurde auch das Benchmarking von CodeContests untersucht, allerdings unter Verwendung einer unveröffentlichten aktualisierten Version. Dem AlphaCode2-Bericht zufolge erreicht AlphaCode2 mit nur etwa 100 Stichproben das Leistungsniveau, das AlphaCode mit Millionen von Stichproben erreicht, was es mehr als 10.000 Mal effizienter als AlphaCode macht. Infolgedessen sind sowohl AlphaCode2 als auch AlphaCodium in Bezug auf die Anzahl der großen Sprachmodellaufrufe viel effizienter als AlphaCode.
AlphaCode2 setzt jedoch ein ausgeklügeltes System ein, das speziell für CodeContests-Wettbewerbe entwickelt wurde.FeintuningDas AlphaCodium-Modell basiert auf einem modernen Basismodell, während AlphaCodium ein unverändertes generisches Modell verwendet. Dennoch verbessert AlphaCodium die Leistung des Modells ohne zusätzliche Daten und teure Trainingsphasen.
anhang
1) Ein Beispiel für eine manuelle Bewertung eines Codeproblems:
/*
Prüft in einer Zahlenmenge, ob es zwei Zahlen gibt, deren Abstand kleiner als ein bestimmter numerischer Schwellenwert ist. >>>
has_close_elements({1.0, 2.0, 3.0}, 0.5) false >>>
has_close_elements({1.0, 2.8, 3.0, 4.0, 5.0, 2.0}, 0.3) true
*/
#include
#include
#include
using namespace std;
bool has_close_elements(vector numbers, float threshold){
Tabelle 4.Das Problem ist relativ intuitiv und einfach, ohne viele Details oder Feinheiten, über die das Modell nachdenken muss.
2) Warum die YAML-Ausgabe für Codegenerierungsaufgaben besser geeignet ist als die JSON-Ausgabe
Die neue Version von GPT hat zwar [native UnterstützungWir sind jedoch der Meinung, dass für die Codegenerierung die YAML-Ausgabe besser geeignet ist. Der Grund dafür ist, dass der generierte Code häufig einfache und doppelte Anführungszeichen sowie Sonderzeichen enthält. Im JSON-Format ist es für LLM schwierig, diese Zeichen korrekt zu platzieren, da die JSON-Ausgabe von doppelten Anführungszeichen umgeben sein muss. Die YAML-Ausgabe hingegen [Annahme von BlockskalarenWenn Sie den YAML-Stil verwenden, befolgen Sie einfach die Einrückungsregeln und jeder korrekt eingerückte Text oder Code ist legal. Darüber hinaus enthält die YAML-Ausgabe weniger Token, was niedrigere Kosten und schnellere Inferenzzeiten sowie eine bessere Qualität bedeutet, da sich das Modell auf weniger unkritische Token konzentrieren muss. Hier ein Beispiel für den Vergleich von JSON- und YAML-Ausgabe (mit [https://platform.openai.com/tokenizer] erzeugt):
json importieren
yaml importieren
s1 = 'print("doppelte Anführungszeichenfolge")'
s2 = "print('einfache Anführungszeichenfolge')"
s3 = 'print("""dreifache Anführungszeichenfolge""")'
s4 = f"{s1}\n{s2}\n{s3}"
# Erstellen eines Wörterbuchs mit Schlüsseln als Variablennamen und Werten als Zeichenketten
data = {'s1': s1, 's2': s2, 's3': s3, 's4': s4}
# Konvertierung eines Wörterbuchs in eine Zeichenkette im JSON-Format
json_data = json.dumps(data, indent=2)
print(json_data)
# Konvertierung von Wörterbüchern in Zeichenketten im YAML-Format im Block-Skalar-Stil
yaml_data = yaml.dump(data, indent=2, default_style='|')
drucken(yaml_data)
Ausgabe.
Tabelle 5.
JSON-Ausgabe:

Abbildung 7: Beispiel für Token-Zählung mit JSON-Ausgabe.
Ein Beispiel für eine YAML-Ausgabe ist unten abgebildet:

Abbildung 8: Beispiel einer Token-Zählung mit YAML-Ausgabe.
Es liegt auf der Hand, dass die Erzeugung von Code, bei dem nur die korrekte Einrückung beibehalten wird, nicht nur prägnanter und klarer ist, sondern auch die Fehlerquote verringert.
© urheberrechtliche Erklärung
Artikel Copyright AI-Austauschkreis Alle, bitte nicht ohne Erlaubnis vervielfältigen.
Ähnliche Artikel



Keine Kommentare...