Die erste Liste der "AI Search"-Evaluierungsbenchmarks wurde veröffentlicht! Der Vorsprung von 4o ist gering, und die großen einheimischen Modelle schneiden hervorragend ab, mit insgesamt 5 Basen, 11 Szenarien und 14 Modellen.


Die Veröffentlichung der chinesischen Big Model AI Search (SuperCLUE-AISearch) Benchmark-Evaluierung ist eine eingehende Bewertung der Fähigkeiten von Big Model in Kombination mit der Suche. Die Bewertung konzentriert sich nicht nur auf die grundlegenden Fähigkeiten des Big Model, sondern untersucht auch seine Leistung in Szenarioanwendungen. Die Evaluierung deckt 5 Grundfähigkeiten ab, wie z.B. das Abrufen von Informationen und die Beschaffung aktueller Informationen, sowie 11 Szenarioanwendungen, wie z.B. Nachrichten und Lebensanwendungen, um die Leistung des Modells bei der Kombination von Suche in verschiedenen Grundfähigkeiten und Szenarioanwendungen umfassend zu testen. Für das Bewertungsschema siehe: "AI Search" Benchmark Evaluation Scheme Release. Diesmal haben wir die KI-Suchfähigkeiten von 14 repräsentativen großen Modellen aus dem In- und Ausland bewertet, und im Folgenden finden Sie den detaillierten Bewertungsbericht.
Zusammenfassung der AI-Suchauswertung
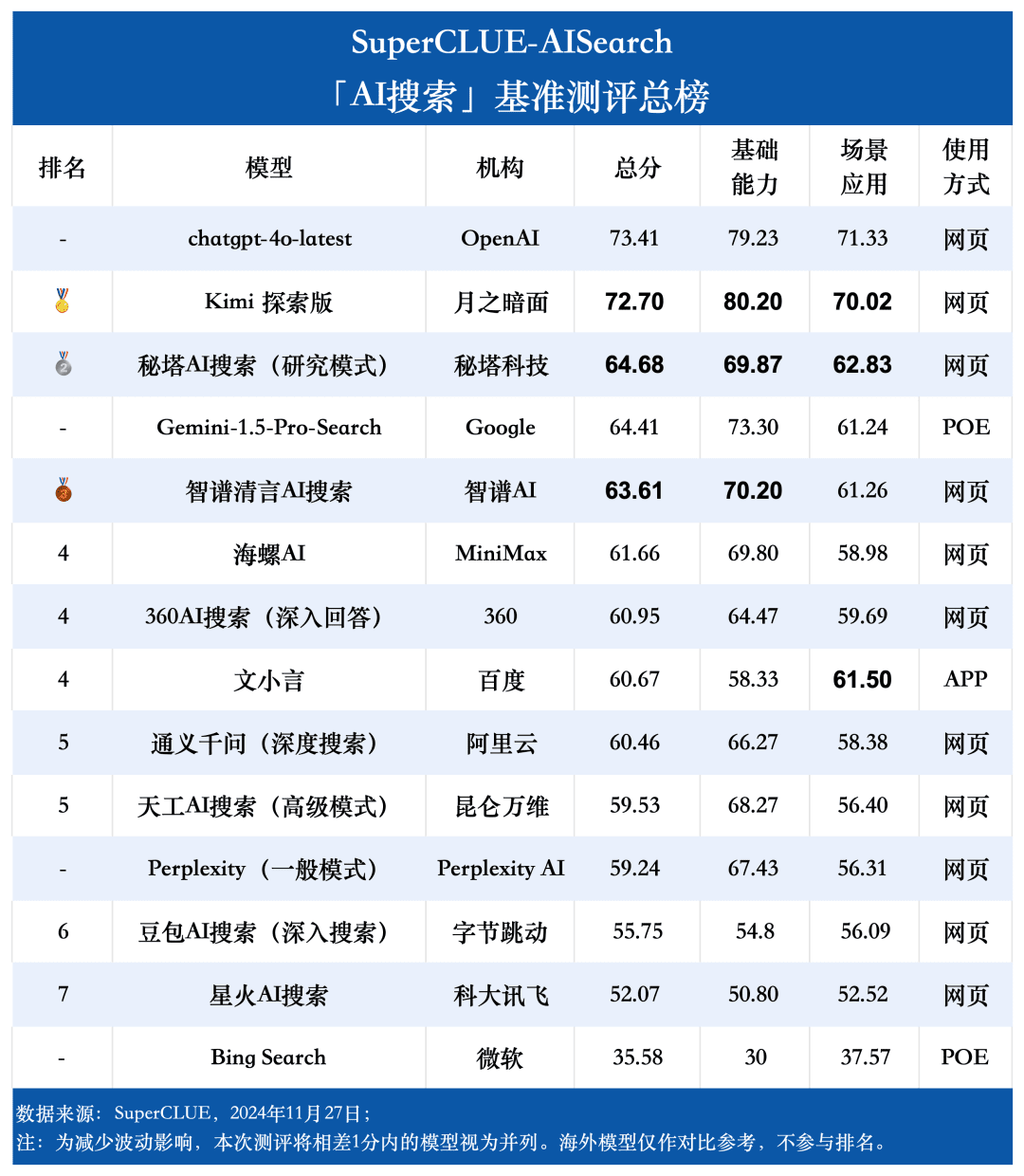
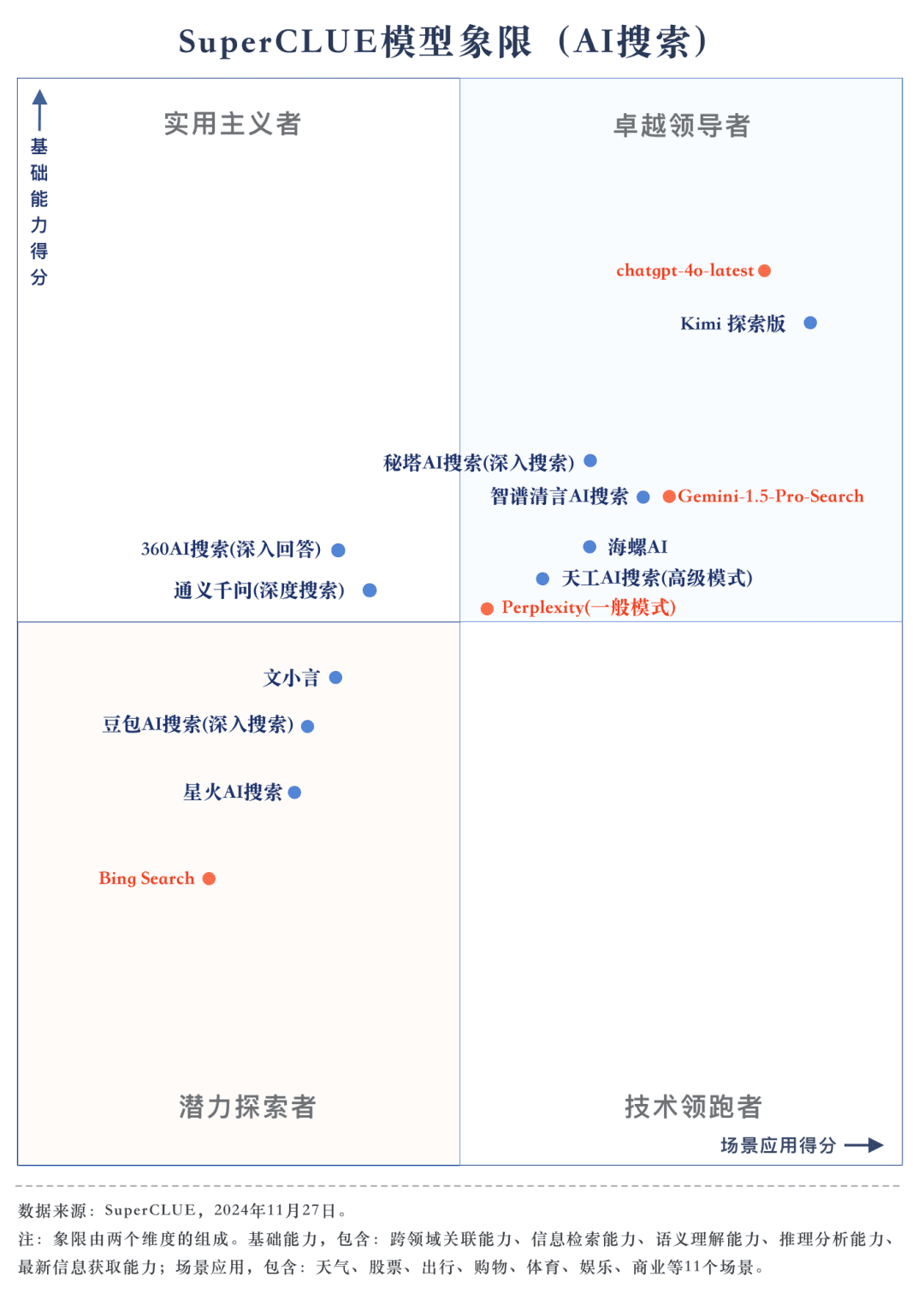
Messstelle 1chatgpt-4o-latest führt die KI-Suchliste an, gefolgt von Kimi Explorer, zwischen denen nur 0,71 Punkte liegen. chatgpt-4o-latest erzielte in dieser Bewertung 73,41 Punkte mit ausgezeichneter Leistung und lag damit vor den anderen teilnehmenden Modellen. Inzwischen hat das große einheimische Modell Kimi Bemerkenswert ist auch die Leistung der Explorer Edition, die in der Szenarioanwendung bei den Themen Shopping und Kultur gut abschneidet und hervorragende KI-Suchfähigkeiten sowie eine ausgezeichnete umfassende Leistung in mehreren Dimensionen zeigt.
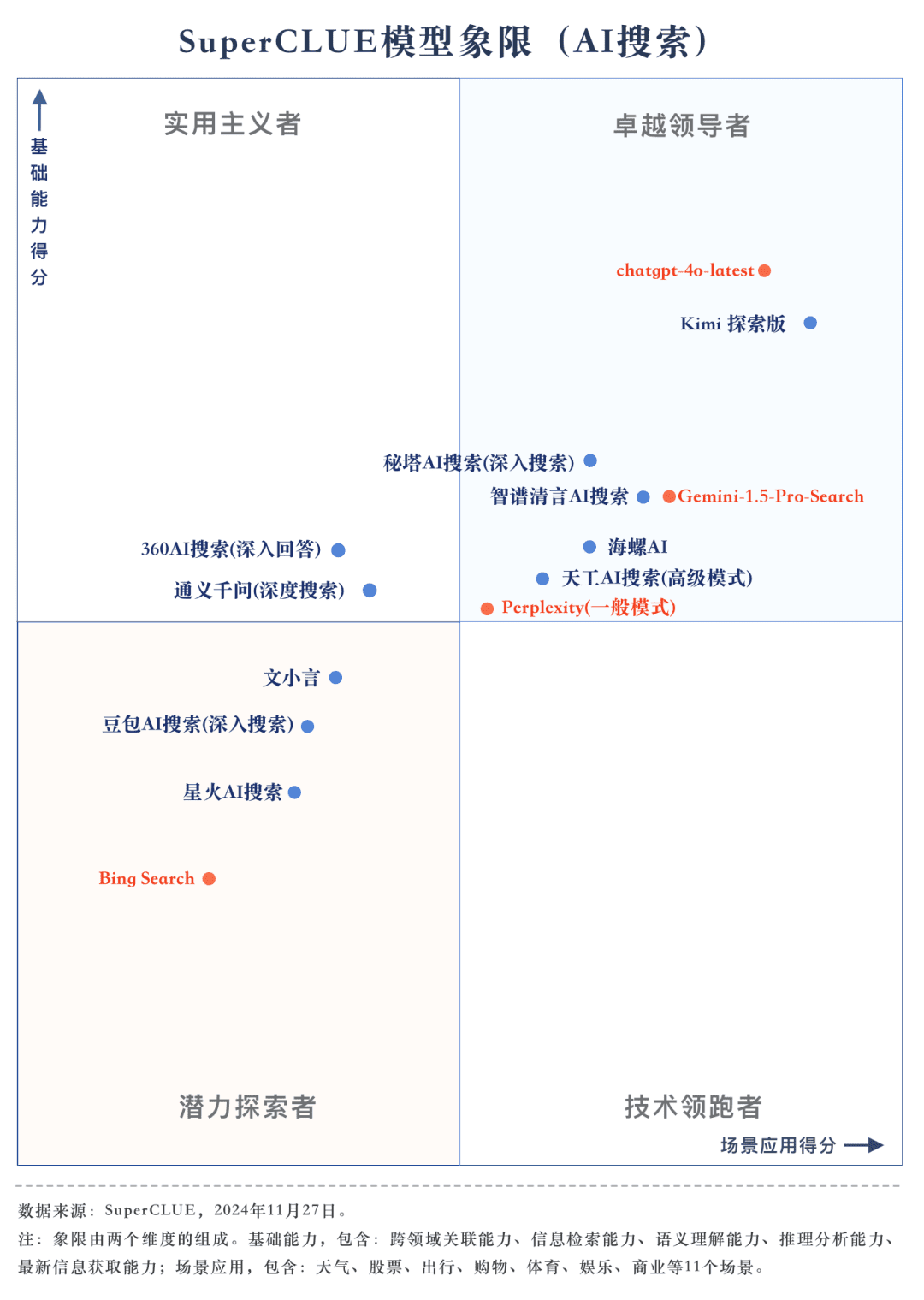
Messstelle 2Aus den Bewertungsergebnissen geht hervor, dass inländische große Modelle wie Secret Tower AI Search (Forschungsmodus), Wisdom Spectrum Clear Speech AI Search und Conch AI in Bezug auf die Gesamtleistung beeindruckender sind und mit dem großen Modell Gemini-1.5-Pro-Search aus Übersee gleichziehen. Abgesehen davon ist die Leistung mehrerer inländischer großer Modelle in der Mitte der Gesamtleistung wie 360AI Search (ausführliche Antwort), Wen XiaoYin, Tongyi QianQi (Tiefensuche) und andere große Modelle nicht ähnlich und zeigt einen kleinen Unterschied.
Messstelle 3Die Modelle zeigen unterschiedliche Leistungsgrade in verschiedenen Anwendungsszenarien. Bei der Bewertung der KI-Suche haben wir uns auch auf die Leistung der einzelnen großen Modelle in verschiedenen Anwendungsszenarien konzentriert. Die einheimischen großen Modelle schnitten in Szenarien wie Wissenschaft und Technologie, Kultur, Wirtschaft und Unterhaltung relativ gut ab und zeigten hervorragende Fähigkeiten bei der Informationssuche und -integration sowie bei der Erfassung der Aktualität von Informationen. Es gibt jedoch noch Spielraum für inländische große Modelle, sich in Anwendungsszenarien wie Aktien und Sport zu verbessern.
Überblick über die Liste
Einführung in SuperCLUE-AISearch
SuperCLUE-AISearch ist ein umfassendes Evaluierungsset für chinesische KI-Suchmodelle, das als Referenz für die Bewertung der Fähigkeiten von KI-Suchmodellen im chinesischen Bereich dienen soll.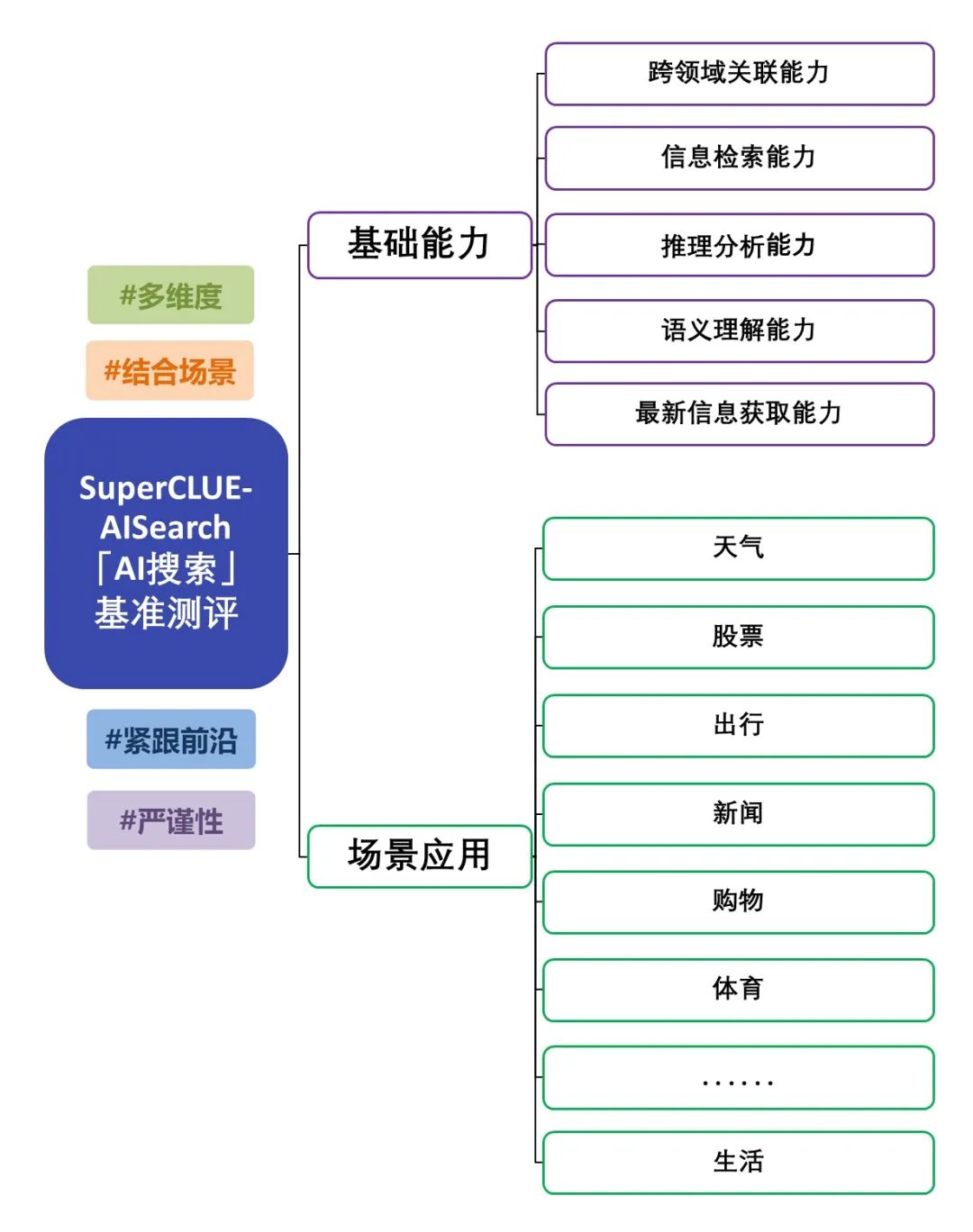
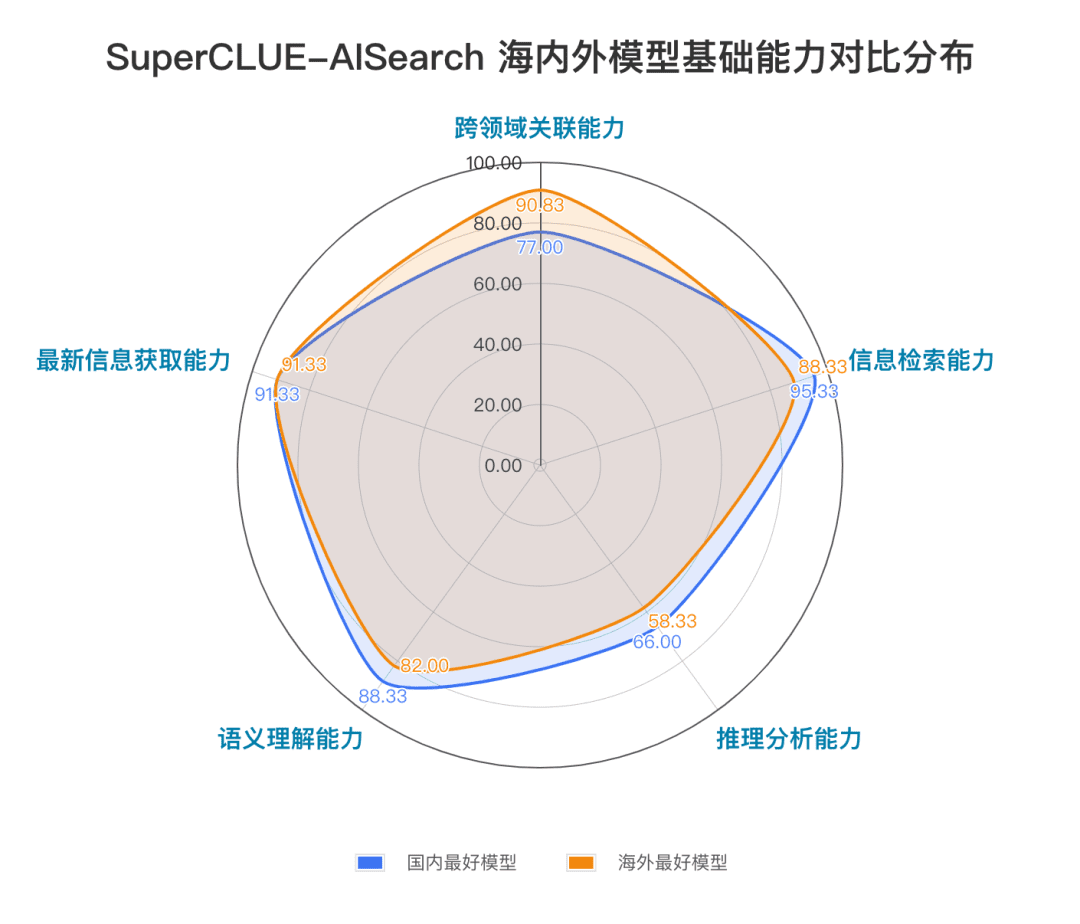
Zu den grundlegenden Fähigkeiten gehören fünf Fähigkeiten, die für KI-Suchaufgaben erforderlich sind: bereichsübergreifende Relevanz, Informationsbeschaffung, semantisches Verständnis, Beschaffung aktueller Informationen und logisches Denken.
Die Szenario-Anwendungen umfassen 11 Szenarien, die bei KI-Suchaufgaben häufig vorkommen: Wetter, Aktien, Reisen, Nachrichten, Shopping, Sport, Unterhaltung, Bildung, Reisen, Wirtschaft, Kultur, Technologie, Gesundheit und Leben.
Methodik
Im Rahmen des feinkörnigen SuperCLUE-Bewertungsansatzes wird ein spezieller Satz von Messungen erstellt, und jede Dimension wird auf einer feinkörnigen Ebene bewertet, so dass ein detailliertes Feedback gegeben werden kann.
1) Aufbau der Messgeräte
Prozess der Erstellung eines chinesischen Promptes: 1. Bezugnahme auf einen bestehenden Prompt ---> 2. Schreiben eines chinesischen Promptes ---> 3. Testen ---> 4. Modifizierung und Fertigstellung eines chinesischen Promptes; Erstellung eines eigenen Bewertungssatzes für jede Dimension.
2) Scoring-Methode
Der Bewertungsprozess beginnt mit der Interaktion des Modells mit dem Datensatz, der anhand der gestellten Fragen verstanden und beantwortet werden muss.
Die Bewertungskriterien umfassen die Dimensionen Denkprozess, Problemlösungsprozess, Reflexion und Anpassung.
Die Bewertungsregeln kombinieren eine automatisierte quantitative Bewertung mit einer Überprüfung durch Experten, um effizient zu bewerten und gleichzeitig sicherzustellen, dass die Bewertung wissenschaftlich und fair ist.
3) Kriterien für die Punktevergabe
Für die Bewertung der Antwortqualität der einzelnen Makromodelle bei den Bewertungsaufgaben wurden zwei Bewertungskriterien verwendet, um die subjektiven bzw. objektiven Fragen im Bewertungssatz zu bewerten. Diese Kriterien wurden bei der Bewertung unterschiedlich gewichtet, um die Leistung der Makromodelle bei der KI-Suchaufgabe vollständig widerzuspiegeln.
Das Bewertungssystem SuperCLUE-AISearch ist so konzipiert, dass subjektive Fragen mit 5 Punkten bewertet werden, die aus den Dimensionen Informationsnutzen, analytische Genauigkeit und Klarheit des Ausdrucks stammen, wobei der Informationsnutzen 60%, die analytische Genauigkeit 20% und die Klarheit des Ausdrucks 20% ausmacht. Die Bewertungskriterien für objektive Fragen werden mit 5 Punkten bewertet, die aus den Dimensionen Informationsgenauigkeit und Klarheit des Ausdrucks stammen, wobei die Informationsgenauigkeit 80% und die Klarheit des Ausdrucks 20% ausmacht. Die objektiven Fragen werden mit 5 Punkten bewertet, und zwar in zwei Dimensionen: Genauigkeit der Information und Klarheit des Ausdrucks, wobei die Genauigkeit der Information 80% und die Klarheit des Ausdrucks 20% ausmacht. 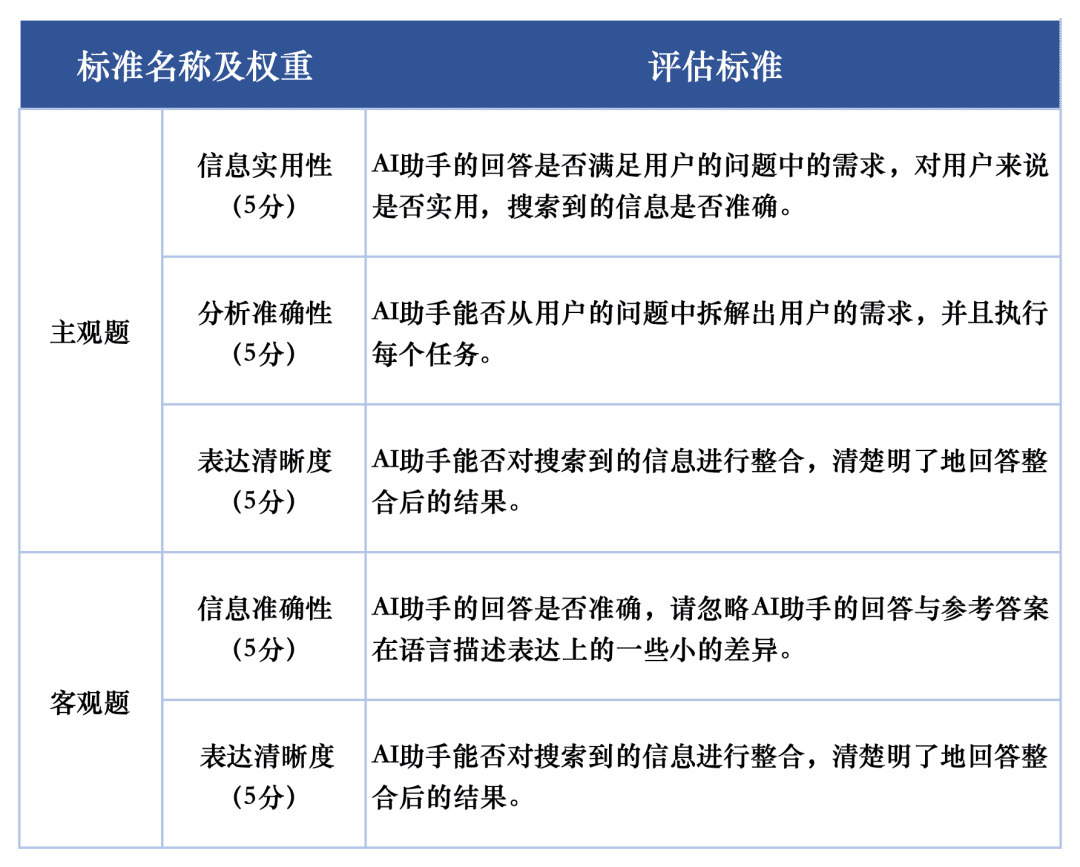
Beispiel für eine Bewertung
Aufforderungswort Aufforderung: Wann und wo wurde das bemannte Raumschiff Shenzhou 19 gestartet und wer waren die Astronauten bei dieser Gelegenheit?
Antwort: In den frühen Morgenstunden des 30. Oktober war der Start des bemannten Raumschiffs Shenzhou XIX vom Jiuquan Satellite Launch Centre ein voller Erfolg. Die Besatzung der bemannten Mission Shenzhou-19 bestand aus den drei Astronauten Cai Xuzhe, Song Lingdong und Wang Haize.
Musterantwort:
Schiedsrichter Supermodel (chatgpt-4o-latest):
Bewerten Sie diese Antwort wie folgt:
Die Antwort des KI-Assistenten lieferte genau die Startzeit und den Standort des bemannten Raumschiffs Shenzhou XIX sowie die Liste der Astronauten. Die Antwort enthielt jedoch keine Angaben zu den Hauptzielen und zum Inhalt der Mission, so dass das Bedürfnis des Nutzers, die Einzelheiten der Mission zu erfahren, nicht vollständig befriedigt wurde. Darüber hinaus könnte der Abschnitt über die persönlichen Profile der Astronauten, obwohl er sehr ausführlich ist, das Interesse der Nutzer überfordert haben. Es wird daher empfohlen, eine kurze Beschreibung der Missionsziele und der Hauptaufgaben in die Antwort aufzunehmen, um den Bedürfnissen der Nutzer besser gerecht zu werden.1. Informationsnutzen (5 Punkte):
Der KI-Assistent gab die Startzeit, den Startort und die Liste der Astronauten für Shenzhou XIX an und befriedigte damit das Bedürfnis des Benutzers nach diesen grundlegenden Informationen. Die Hauptziele der Mission und der Inhalt der Mission wurden jedoch nicht erwähnt, so dass das Bedürfnis des Benutzers, die Details der Mission zu erfahren, nicht vollständig befriedigt wurde. Daher wurde der Informationsnutzen mit der Note 4 bewertet.
Punktzahl: 4/52. Genauigkeit der Analyse (5 Punkte):
Der KI-Assistent entnahm der Frage des Nutzers die wichtigsten Informationen wie Startzeit, Ort und Liste der Astronauten und erstellte ein detailliertes persönliches Profil. Allerdings ging er nicht auf die Missionsziele und den Hauptinhalt der Mission ein und erfüllte die Bedürfnisse des Nutzers nicht vollständig. Daher wurde die Genauigkeit der Analyse mit 4 bewertet.
Punktzahl: 4/53. Klarheit des Ausdrucks (5 Punkte):
Die Antworten des KI-Assistenten sind klar strukturiert und enthalten übersichtliche und leicht verständliche Informationen. Der Abschnitt über das persönliche Profil ist detailliert und macht es dem Nutzer leicht, den Hintergrund des Astronauten zu verstehen. Daher wird die Klarheit des Ausdrucks mit 5 bewertet.
Punktzahl: 5/5 zusammengesetzte Punktzahl = 4*0,6 + 4*0,2 + 5*0,2 = 4,2 Kombiniert man die oben genannten Punkte, ergibt sich eine zusammengesetzte Punktzahl für die Antwort des KI-Assistenten von 4,2. (von 5 Punkten)
Teilnehmende Modelle
Um den aktuellen Entwicklungsstand inländischer und internationaler Großmodelle in Bezug auf die KI-Suchfähigkeit umfassend zu messen, wurden 4 ausländische Modelle und 10 inländische repräsentative Modelle für diese Bewertung ausgewählt.
In Anbetracht der Tatsache, dass viele große Modelle im In- und Ausland in der Regel zwei oder mehr Versionen anbieten, darunter die normale Version und die Version mit vertiefter Suche, verwenden wir in diesem Modellauswahlverfahren ein einheitliches Kriterium: Wenn ein Modell mit einer Version mit vertiefter Suche oder Analyse ausgestattet ist, wählen wir die Version mit der stärksten Suchfunktion für eine umfassende Bewertung aus. 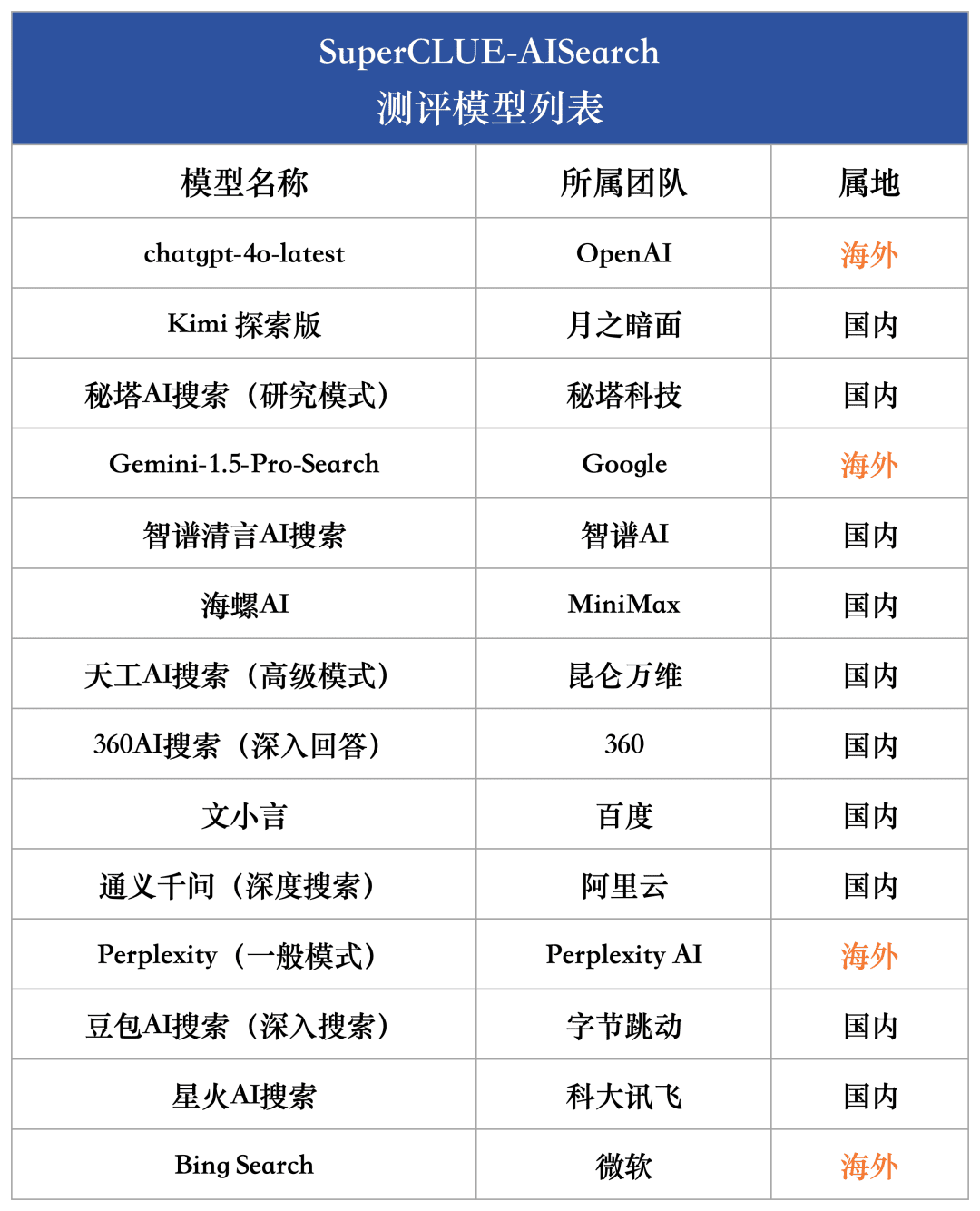
Ergebnisse der Bewertung
Gesamtliste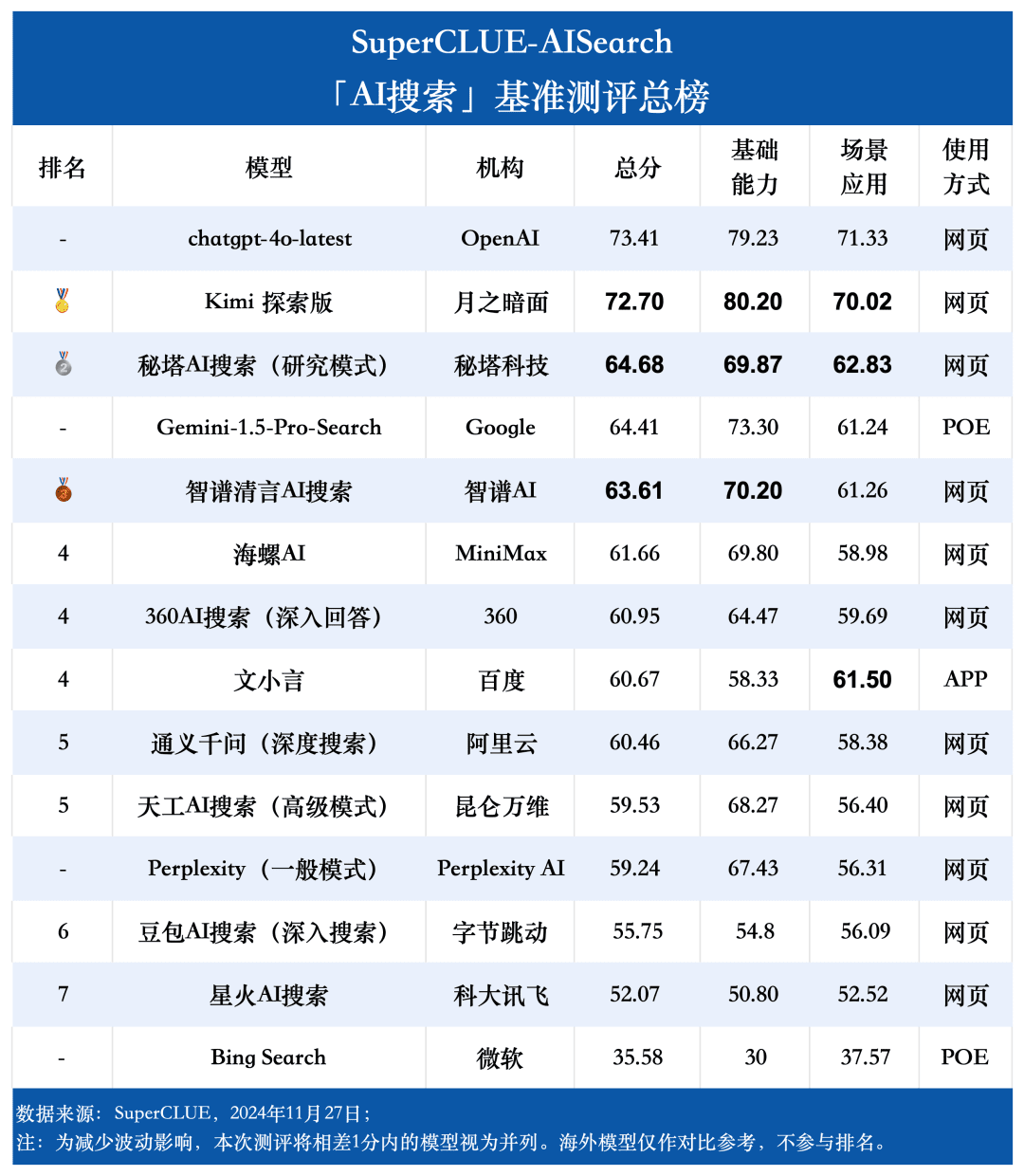
Liste der Grundfähigkeiten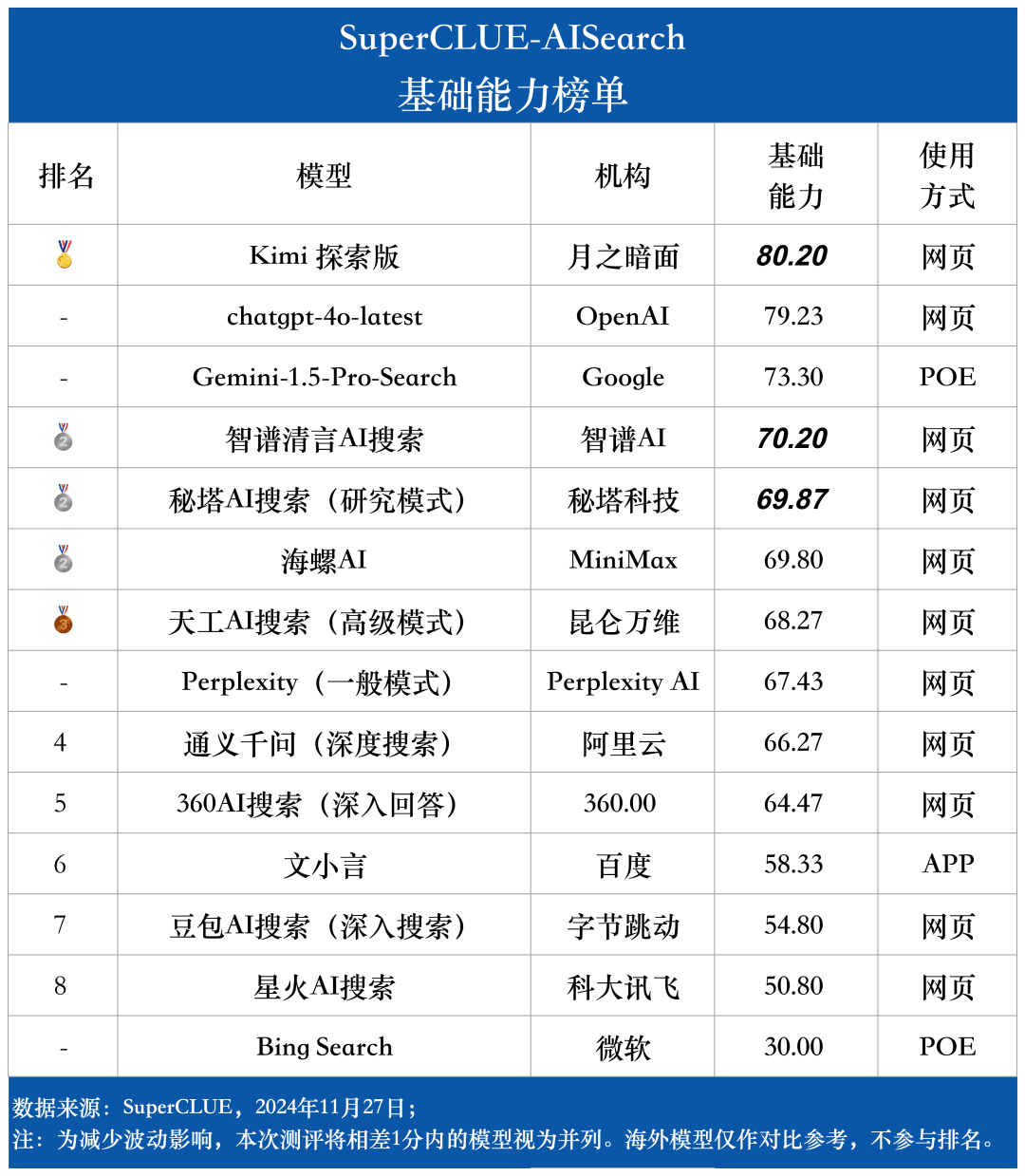
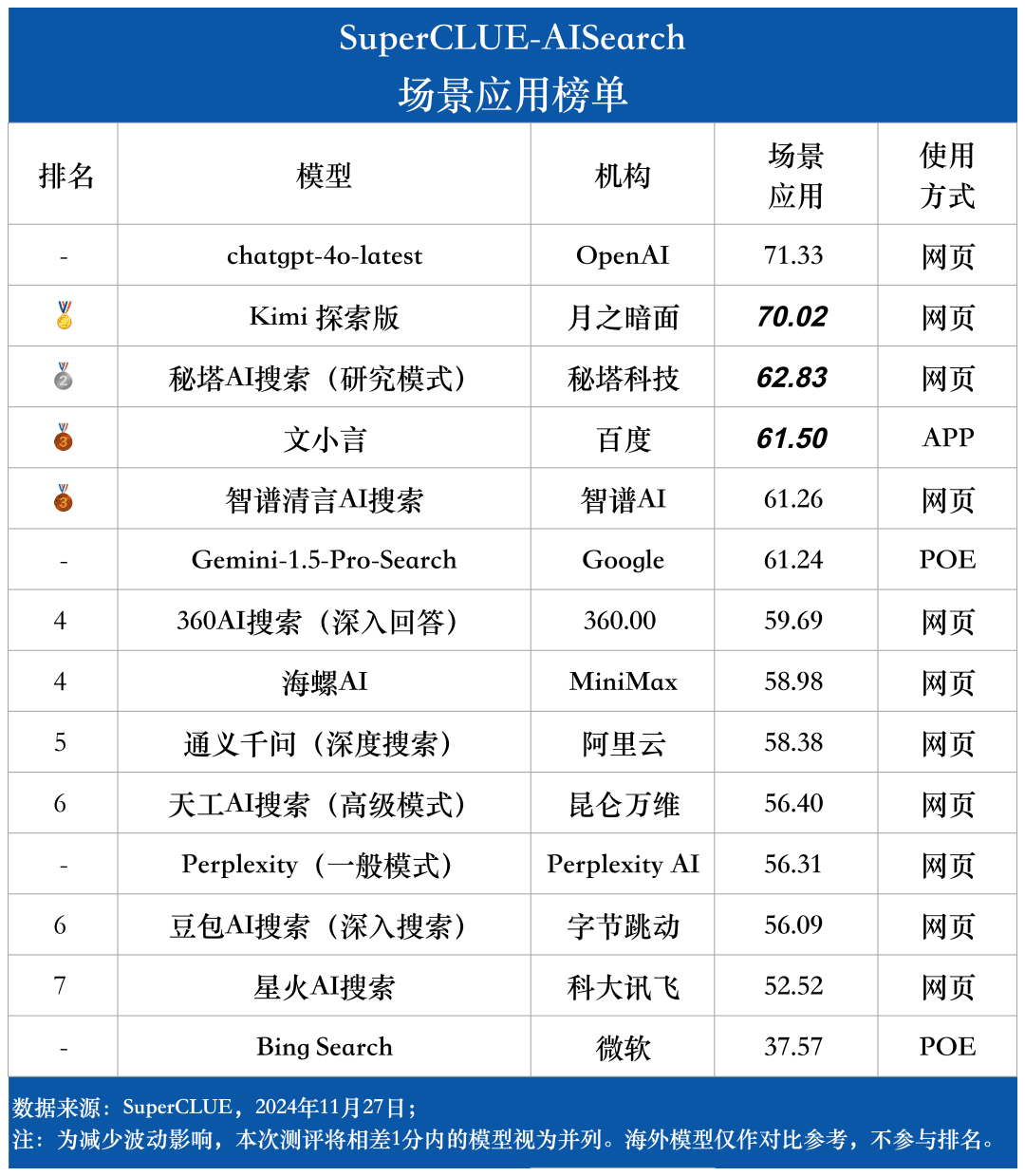
Szenario Anwendungsliste
Liste der subjektiven Fragen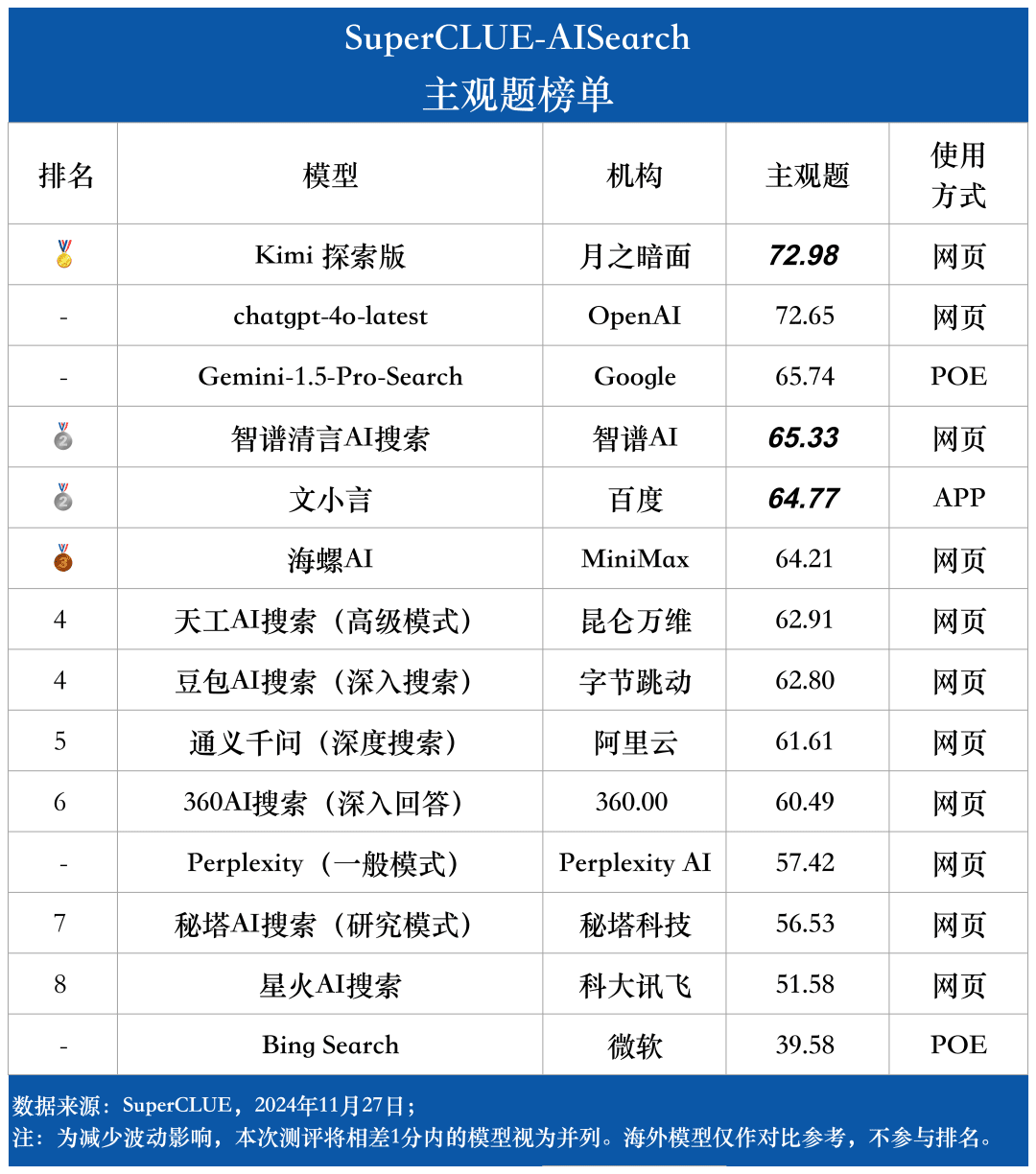
Liste der objektiven Fragen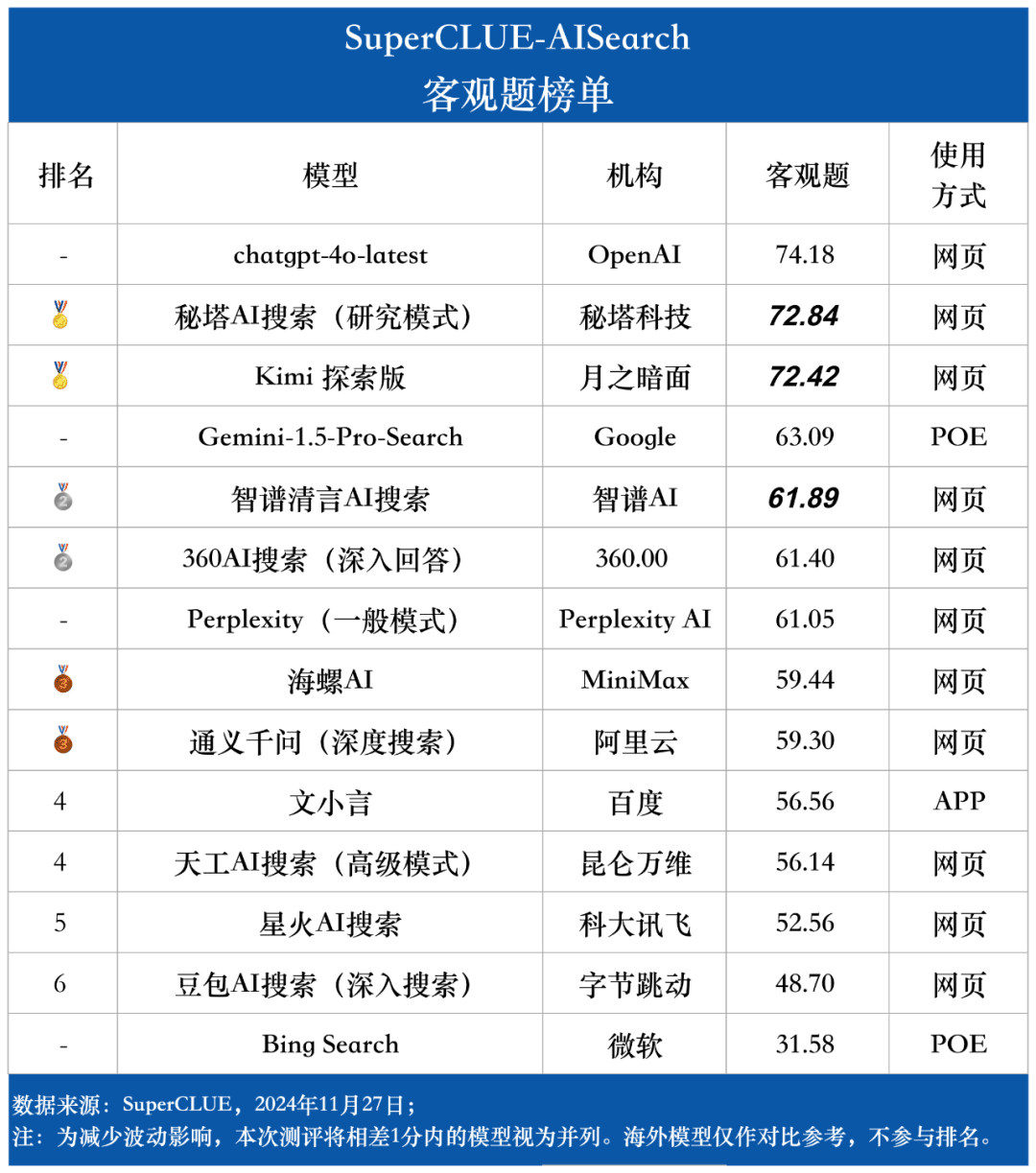
Beispiel für einen Modellvergleich
Beispiel 1 Grundlegende Fähigkeiten - logisches Denken und analytische Fähigkeiten
Aufforderung: "Warum wird die Struktur des GPT-1-Modells verwendet? Transformator Anstelle von LSTM?"
Vergleich der Modellantworten (von 5):
[Kimi Explorer]: 4 Punkte 
[chatgpt-4o-latest]: 3,9 Punkte 
[Skyworks KI-Suche (erweiterter Modus)]: 3,4 Punkte 
Beispiel 2 Grundlegende Kompetenzen - bereichsübergreifende Verknüpfungen
PromptPrompt: "Bitte helfen Sie mir herauszufinden, welche Anwendungen der Computer Vision Technologie in der Landwirtschaft möglich sind und wählen Sie 3 davon aus und beschreiben Sie kurz jede davon."
Vergleich der Modellantworten (von 5):
[Geheime Turm-KI-Suche (Forschungsmodus)]: 4 Punkte 
[Wen Xiaoyan]: 3,4 Punkte 
[Starfire AI Search]: 3 Punkte 
Beispiel 3 Anwendungsszenario - Aktien
PromptPrompt: "Bitte nennen Sie mir einige wichtige Bullenmärkte bei A-Aktien in den letzten Jahren und die dazugehörigen Daten (z. B. Zeitpunkt des Beginns, Dauer, Anstiegsrate, Höchst- und Tiefststände usw.)." Vergleich der Modellantworten (von 5 Punkten): [Gemini-1.5-Pro-Search]: 3,2 Punkte 
[Smart Spectrum Clear Speech AI Search]: 3,3 Punkte 
Bing-Suche]: 2,6 Punkte 
Beispiel 4 Szene Bewerbung - Leben
Aufforderung: "Wie viele Millionen Einheiten wurden von Januar bis Oktober dieses Jahres in China produziert bzw. verkauft, und um wie viel Prozent sind sie im Vergleich zum Vorjahreszeitraum gestiegen?"
Vergleich der Modellantworten (von 5):
[Tongyi Tausend Fragen (vertiefte Suche)]: 4,2 Punkte 
[360AI-Suche (vertiefte Antwort)]: 3,8 Punkte 
Bewertung der menschlichen Konsistenz
Um die wissenschaftliche Validität der automatisierten Bewertung großer Modelle zu gewährleisten, haben wir die menschliche Konsistenz von GPT-4o-0513 in der KI-Suchbewertungsaufgabe bewertet.
Die spezifische Arbeitsmethode ist wie folgt: Fünf Modelle werden ausgewählt, und jedes Modell wird unabhängig von einer Person für verschiedene Dimensionen der subjektiven und objektiven Fragen bewertet und dann für die Mittelwertbildung entsprechend den Bewertungskriterien gewichtet. Wir berechnen die Differenz zwischen den menschlichen Bewertungen und den Modellbewertungen für jede Frage und summieren sie dann, um den durchschnittlichen Abstand für jede Frage als Bewertungsergebnis der menschlichen Konsistenzbewertung zu erhalten.
Die durchschnittlichen Endergebnisse lauten wie folgt: Das durchschnittliche Abweichungsergebnis betrug (in Prozent): 5,1 Punkte
Aufgrund der hohen Zuverlässigkeit dieser automatischen Bewertung.
Evaluierungsanalyse und Schlussfolgerung
1.AI Suche umfassende Fähigkeit, chatgpt-4o-latest halten führende.
Wie aus den Bewertungsergebnissen hervorgeht, verfügt chatgpt-4o-latest (73,41 Punkte) über eine ausgezeichnete Gesamtleistung und führt den SuperCLUE-AISearch-Benchmark an. Es ist nur 0,71 Punkte höher als das beste einheimische Modell, Kimi Explorer.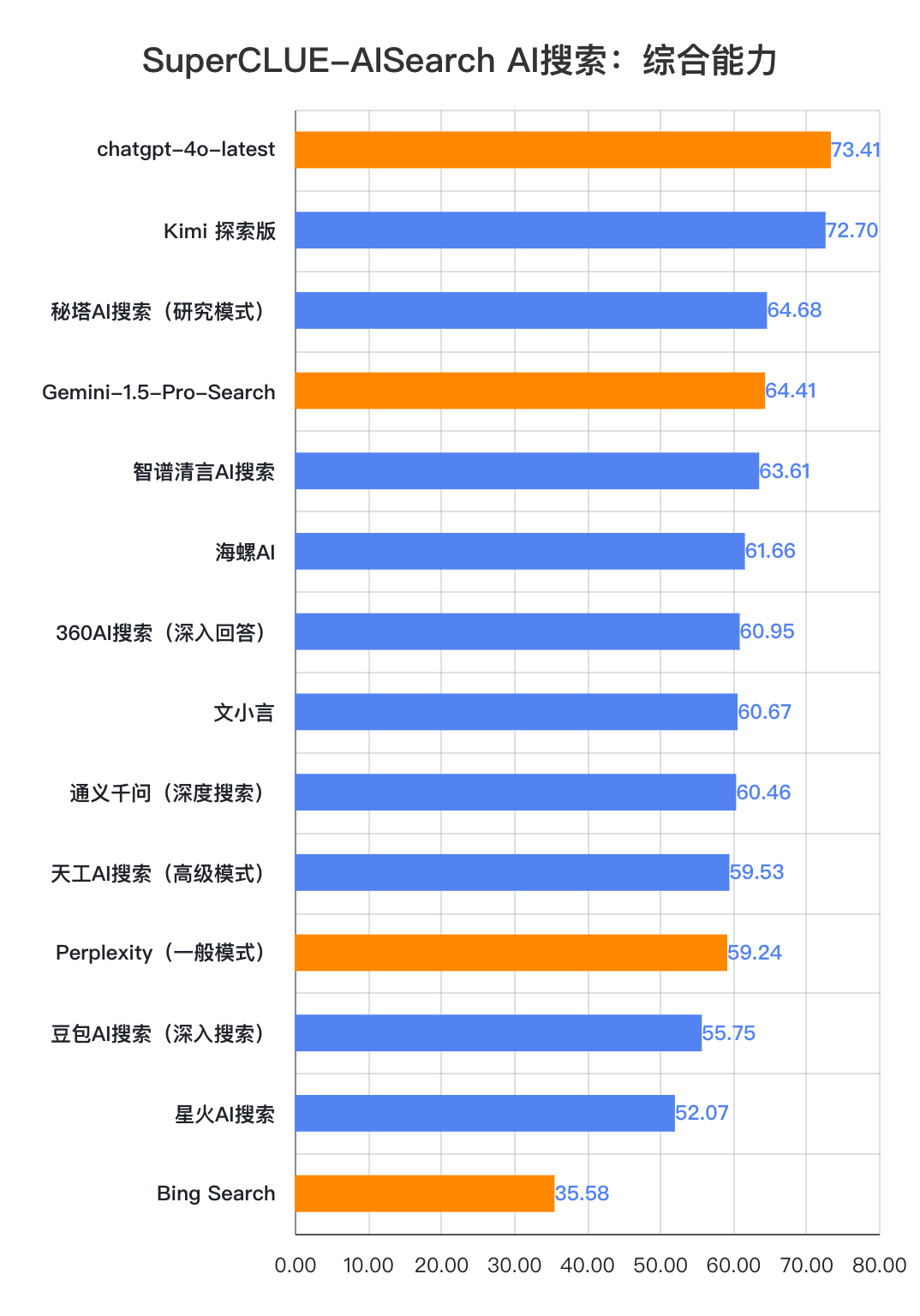
2. die Gesamtleistung der großen Haushaltsmodelle ist recht beeindruckend, mit relativ geringen Unterschieden zwischen den Modellen
Aus den Bewertungsergebnissen geht hervor, dass einheimische Modelle wie Secret Tower AI Search (Forschungsmodell), Wisdom Spectrum Clear Speech AI Search und Conch AI in Bezug auf die grundlegenden Fähigkeiten relativ gut abschneiden und in der Lage sind, mit dem großen Modell Gemini-1.5-Pro-Search aus Übersee gleichzuziehen. Insgesamt ist die Leistung einiger inländischer Modelle im Mittelfeld der Gesamtergebnisse, wie z. B. Conch AI, Wen Xiaoyin und Tongyi Qianqian (Tiefensuche), nicht mit den Modellen vergleichbar und zeigt einen kleinen Unterschied.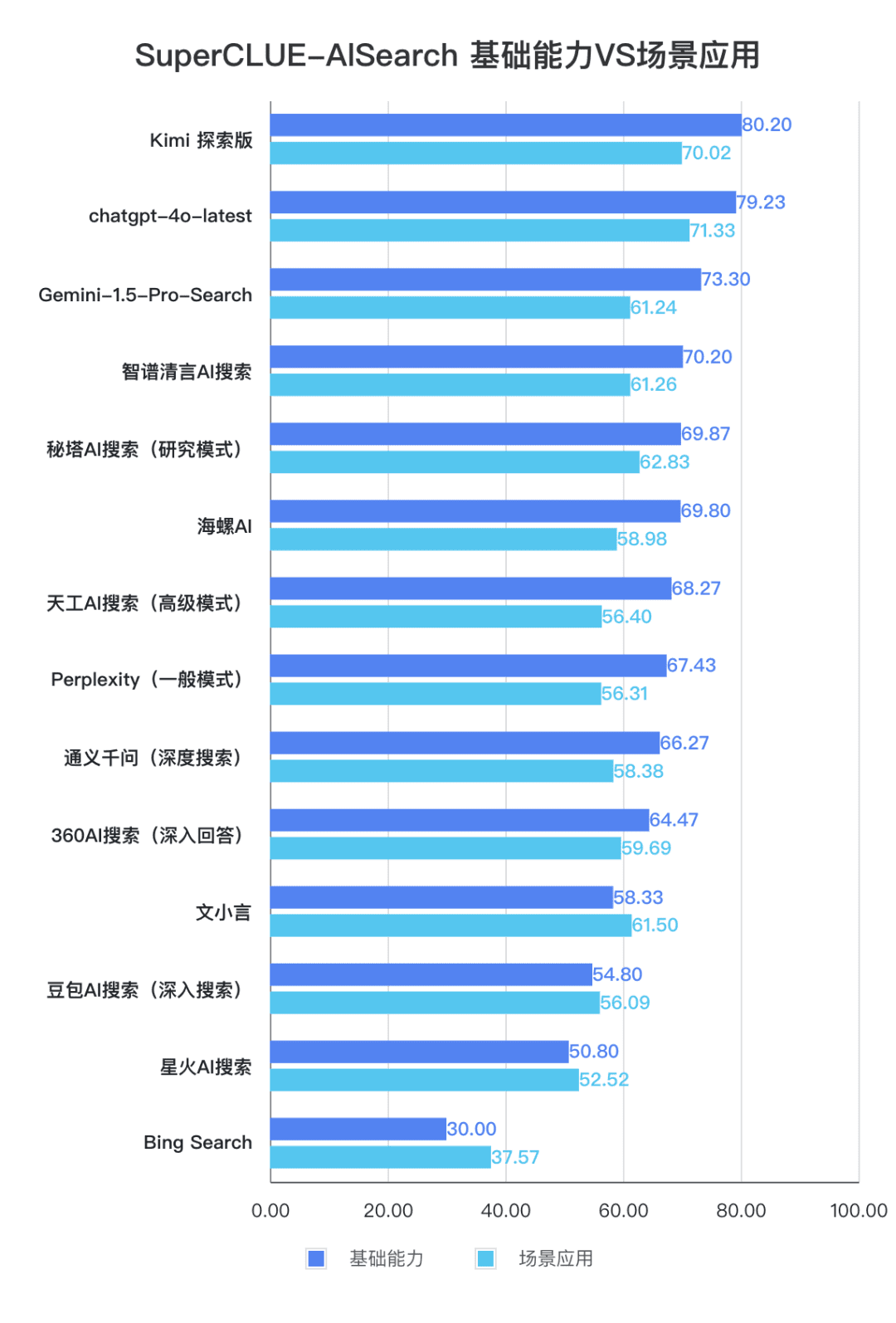
(3) Das Modell zeigt unterschiedliche Leistungsniveaus in verschiedenen Anwendungsszenarien.
Bei der Untersuchung der KI-Suche haben wir uns auf die Leistung der Modelle in verschiedenen Anwendungsszenarien konzentriert. Das einheimische große Modell schneidet in den Bereichen Wissenschaft und Technologie, Kultur, Wirtschaft und Unterhaltung relativ gut ab, kann die Aktualität von Informationen genau erfassen und zeigt eine gute Fähigkeit, Informationen abzurufen und zu integrieren. In den Bereichen Aktien und Sport sind die inländischen großen Modelle jedoch noch deutlich verbesserungsfähig.
Bei der KI-Suche muss das Modell beispielsweise die Suchanforderungen des Nutzers genau zerlegen, die richtigen relevanten Webseiten mit genauen zeitabhängigen Informationen suchen und schließlich die Informationen integrieren, um eine Kopie der Antwortergebnisse zu erstellen, die für den Nutzer praktisch sind. Die derzeitige Beobachtung zeigt, dass einheimische große Modelle manchmal nicht in der Lage sind, den Suchbedarf genau zu analysieren, und dass sie bei der Integration von Informationen manchmal auf irrelevante Webinhalte verweisen, was in bestimmten Szenarien zu einer schlechten Leistung der einheimischen großen Modelle führt.
© urheberrechtliche Erklärung
Artikel Copyright AI-Austauschkreis Alle, bitte nicht ohne Erlaubnis vervielfältigen.
Ähnliche Artikel



Keine Kommentare...