
AI Full-Stack-Tool Open Source! Nehmen Sie mit Ollama+Qwen2.5-Code runbolt.new, ein Klick, um eine Website zu generieren!
KI-Programmierwerkzeuge sind in letzter Zeit sehr gefragt, von Cursor, V0, Bolt.new und seit kurzem auch Windsurf.
In diesem Beitrag sprechen wir zunächst über die Open-Source-Lösung Bolt.new, die in nur vier Wochen seit der Markteinführung einen Umsatz von 4 Millionen US-Dollar erzielt hat.

Nicht hilfreich ist die WebsiteGeschwindigkeitsbeschränkungen beim InlandszugangundKontingent an kostenlosen Token ist begrenzt.
Die Aufgabe von Monkey ist es, die Software lokal zu betreiben, damit mehr Menschen sie nutzen können und die KI schneller zum Einsatz kommt.
Die heutige Aktie.Führt Sie durch ein großes Modell mit lokalen Ollama eingesetzt, treibende bolt.newDer KI-Programmierer, der erkannt hat Token Freiheit.
1. eine Einführung in Bolt.new
Bolzen.neu Es handelt sich um eine SaaS-basierte KI-Codierungsplattform mit zugrundeliegender LLM-gesteuerter Intelligenz, kombiniert mit WebContainers-Technologie, die die Codierung und Ausführung innerhalb des Browsers ermöglicht, mit den Vorteilen von:
- Unterstützung von Front-End- und Back-End-Entwicklung zur gleichen Zeit.;
- Visualisierung der Projektordnerstruktur.;
- Selbst gehostete Umgebung mit automatischer Installation von Abhängigkeiten (z.B. Vite, Next.js, etc.).;
- Betrieb eines Node.js-Servers von der Bereitstellung bis zur Produktion
SchraubeDas Ziel von .new ist es, die Entwicklung von Webanwendungen einem größeren Personenkreis zugänglich zu machen, so dass auch Programmieranfänger ihre Ideen in einfacher natürlicher Sprache umsetzen können.
Das Projekt wurde offiziell als Open-Source-Projekt freigegeben: https://github.com/stackblitz/bolt.new
Die offizielle Open-Source-Software bolt.new bietet jedoch nur eine begrenzte Modellunterstützung, und viele unserer inländischen Partner sind nicht in der Lage, die LLM-API in Übersee aufzurufen.
Es gibt einen Gott in der Gemeinschaft. bolt.new-any-llmDie Unterstützung vor Ort ist vorhanden. Ollama Modell, werfen Sie unten einen Blick auf die Praxis.
2. lokaler Einsatz von Qwen2.5-Code
Vor einiger Zeit hat Ali die Qwen2.5-Coder-Serie von Modellen freigegeben, von denen das 32B-Modell in mehr als zehn Benchmark-Evaluierungen die besten Open-Source-Ergebnisse erzielt hat.
Es verdient es, das leistungsfähigste Open-Source-Modell der Welt zu sein und übertrifft sogar GPT-4o in einer Reihe von Schlüsselfunktionen.
Das Ollama-Modell-Repository ist auch für qwen2.5-coder live:
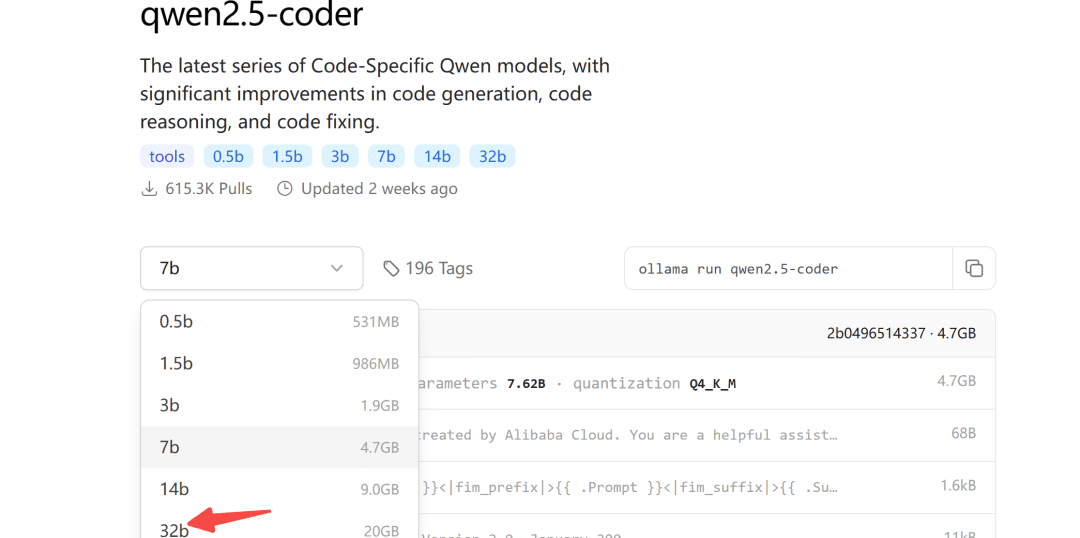
Ollama ist ein gerätefreundliches Werkzeug für die Bereitstellung großer Modelle.
2.1 Modell-Download
Was die Größe des herunterzuladenden Modells betrifft, so können Sie diese je nach Ihrem eigenen Videospeicher wählen, wobei für das 32B-Modell mindestens 24G Videospeicher garantiert sind.
Im Folgenden wird dies anhand des Modells 7b demonstriert:
ollama pull qwen2.5-coder
2.2 Modelländerungen
Da Ollama standardmäßig maximal 4096 Token ausgibt, ist dies für Codegenerierungsaufgaben eindeutig unzureichend.
Zu diesem Zweck müssen die Modellparameter geändert werden, um die Anzahl der Kontext-Token zu erhöhen.
Erstellen Sie zunächst eine neue Modeldatei und füllen Sie diese aus:
FROM qwen2.5-coder
PARAMETER num_ctx 32768
Dann beginnt die Modellumwandlung:
ollama create -f Modelfile qwen2.5-coder-extra-ctx
Nach erfolgreicher Konvertierung können Sie sich die Modellliste erneut ansehen:

2.3 Modellläufe
Prüfen Sie schließlich auf der Serverseite, ob das Modell erfolgreich aufgerufen werden kann:
def test_ollama():
url = 'http://localhost:3002/api/chat'
data = {
"model": "qwen2.5-coder-extra-ctx",
"messages": [
{ "role": "user", "content": '你好'}
],
"stream": False
}
response = requests.post(url, json=data)
if response.status_code == 200:
text = response.json()['message']['content']
print(text)
else:
print(f'{response.status_code},失败')
Wenn alles in Ordnung ist, können Sie es in bolt.new aufrufen.
3) Bolt.new läuft lokal
3.1 Lokaler Einsatz
Stufe1: Laden Sie bolt.new-any-llm herunter, das lokale Modelle unterstützt:
git clone https://github.com/coleam00/bolt.new-any-llm
Stufe2: Erstellen Sie eine Kopie der Umgebungsvariablen:
cp .env.example .env
Stufe3: Ändern Sie die Umgebungsvariable inOLLAMA_API_BASE_URLErsetzen Sie sie durch Ihre eigene:
# You only need this environment variable set if you want to use oLLAMA models
# EXAMPLE http://localhost:11434
OLLAMA_API_BASE_URL=http://localhost:3002
Stufe4Abhängigkeiten installieren (mit lokal installiertem Node)
sudo npm install -g pnpm # pnpm需要全局安装
pnpm install
Stufe5: Ein-Klick-Bedienung
pnpm run dev
Die folgende Ausgabe zeigt an, dass der Startvorgang erfolgreich war:
➜ Local: http://localhost:5173/
➜ Network: use --host to expose
➜ press h + enter to show help
3.2 Demonstration der Auswirkungen
Im Browser öffnenhttp://localhost:5173/Das Modell vom Typ Ollama wird ausgewählt:
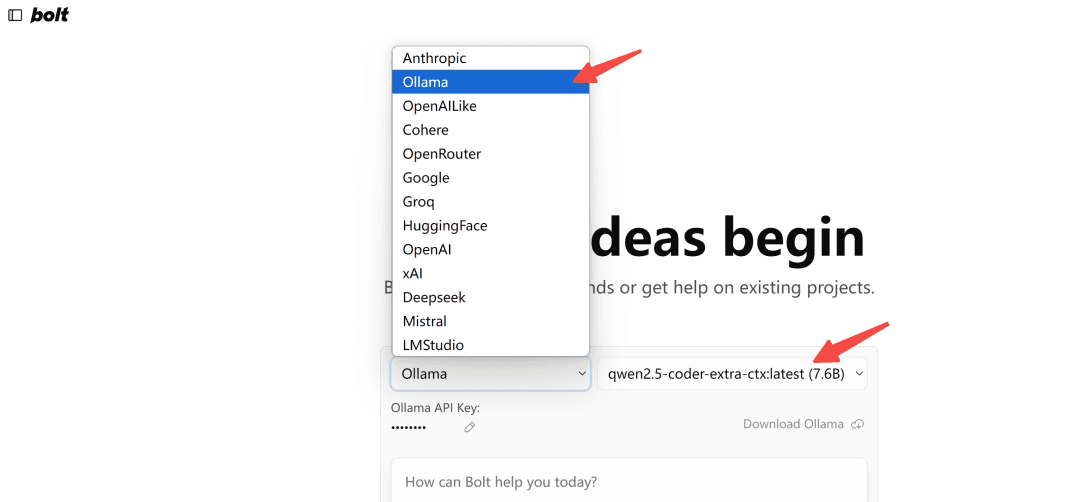
Hinweis: Wenn beim ersten Laden das Modell in Ollama nicht angezeigt wird, aktualisieren Sie es ein paar Mal, um zu sehen, wie es aussieht.
Machen wir die Probe aufs Exempel.
写一个网页端贪吃蛇游戏
Auf der linken Seite.流程执行und auf der rechten Seite ist der代码编辑Bereich, unter dem sich die终端Bereich. Das Schreiben von Code, die Installation von Abhängigkeiten und Terminalbefehle werden von AI!
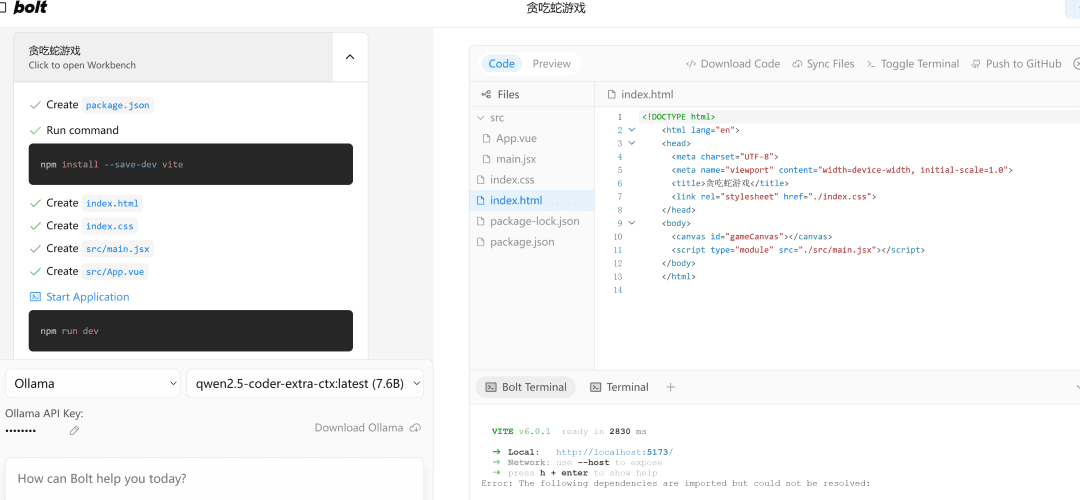
Wenn es auf einen Fehler stößt, geben Sie einfach den Fehler an, führen Sie es erneut aus, und wenn es keinen Fehler gibt, wird die rechte SeitePreviewDie Seite wird erfolgreich geöffnet.
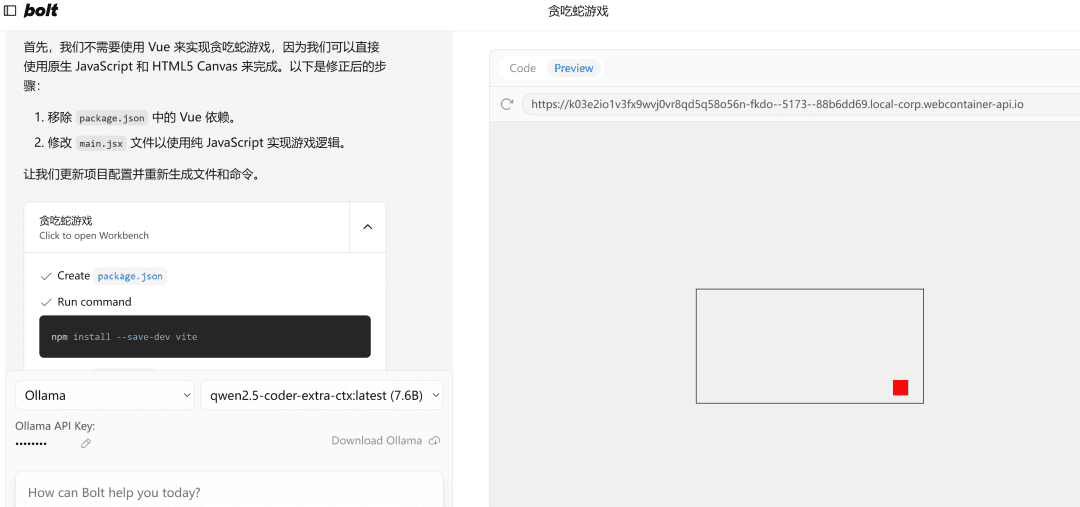
Hinweis: Da in dem Beispiel ein kleines 7b-Modell verwendet wird, werden die Ergebnisse deutlich besser, wenn Sie ein 32b-Modell verwenden müssen.
am Ende schreiben
Dieser Artikel führt Sie durch einen lokalen Einsatz des qwen2.5-Codemodells und steuert erfolgreich das KI-Programmiertool bolt.new.
Verwenden Sie es, um die Front-End-Projekt zu entwickeln ist immer noch recht mächtig, natürlich, um es gut zu nutzen, wissen einige grundlegende Front-und Back-End-Konzepte, wird doppelt so effektiv sein.
© urheberrechtliche Erklärung
Artikel Copyright AI-Austauschkreis Alle, bitte nicht ohne Erlaubnis vervielfältigen.
Ähnliche Artikel



Keine Kommentare...