AI Engineering Academy: 2.4 Daten-Chunking-Techniken für Retrieval Augmented Generation (RAG) Systeme
kurz
Das Chunking von Daten ist ein wichtiger Schritt in Retrieval Augmented Generation (RAG)-Systemen. Dabei werden große Dokumente in kleinere, handhabbare Teile zerlegt, um eine effiziente Indizierung, Abfrage und Verarbeitung zu ermöglichen. Dieses README bietet RAG Überblick über die verschiedenen in der Pipeline verfügbaren Chunking-Methoden.
https://github.com/adithya-s-k/AI-Engineering.academy/tree/main/RAG/01_Data_Ingestion
Bedeutung von Chunking in der RAG
Wirksames Chunking ist für das RAG-System von entscheidender Bedeutung, denn es kann:
- Verbessern Sie die Abrufgenauigkeit, indem Sie kohärente, in sich geschlossene Informationseinheiten erstellen.
- Verbesserung der Effizienz von Einbettungsgenerierung und Ähnlichkeitssuche.
- Ermöglicht eine präzisere Kontextauswahl bei der Erstellung von Antworten.
- Hilfe bei der Verwaltung von Sprachmodellen und eingebetteten Systemen von Token Beschränkungen.
Chunking-Verfahren
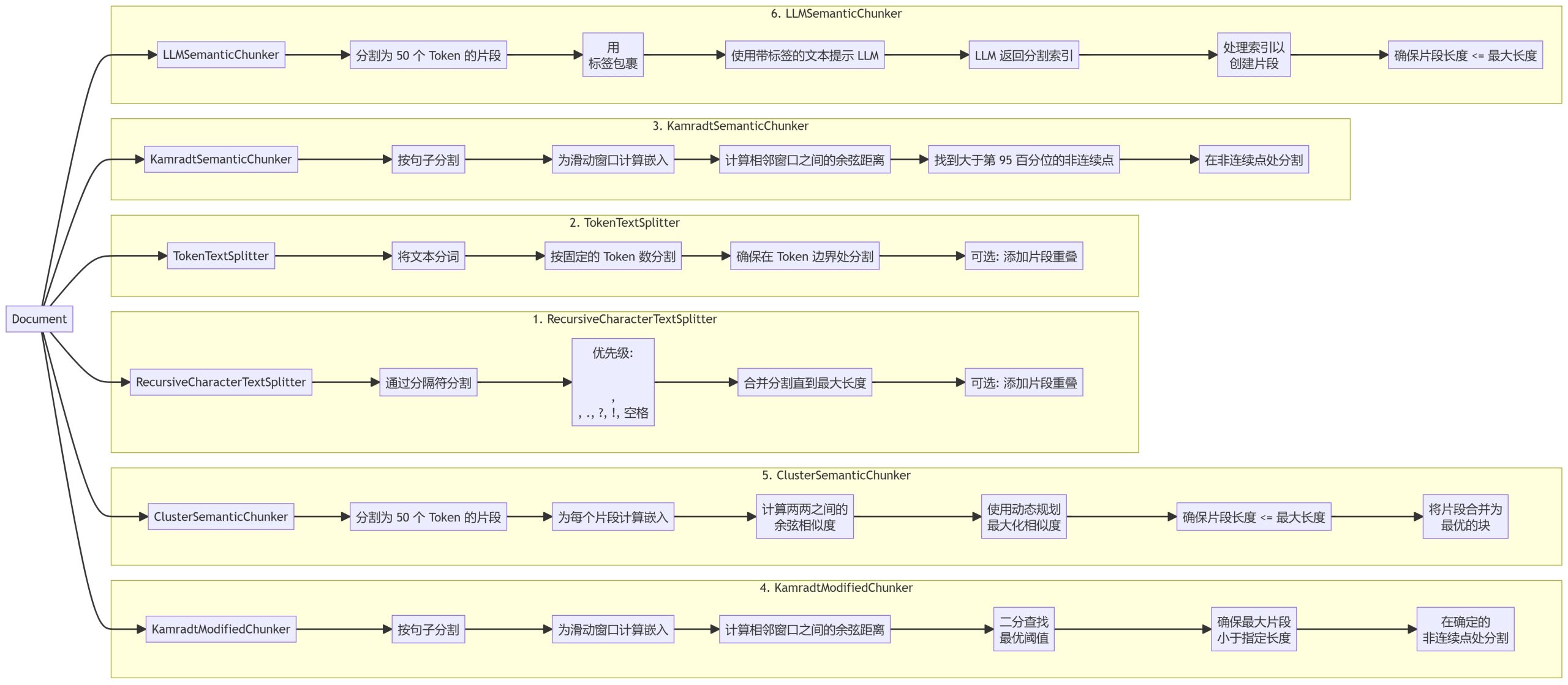
Wir haben sechs verschiedene Chunking-Methoden implementiert, die jeweils unterschiedliche Vorteile und Einsatzszenarien haben:
- RecursiveCharacterTextSplitter
- TokenTextSplitter
- KamradtSemanticChunker
- KamradtModifiedChunker
- ClusterSemanticChunker
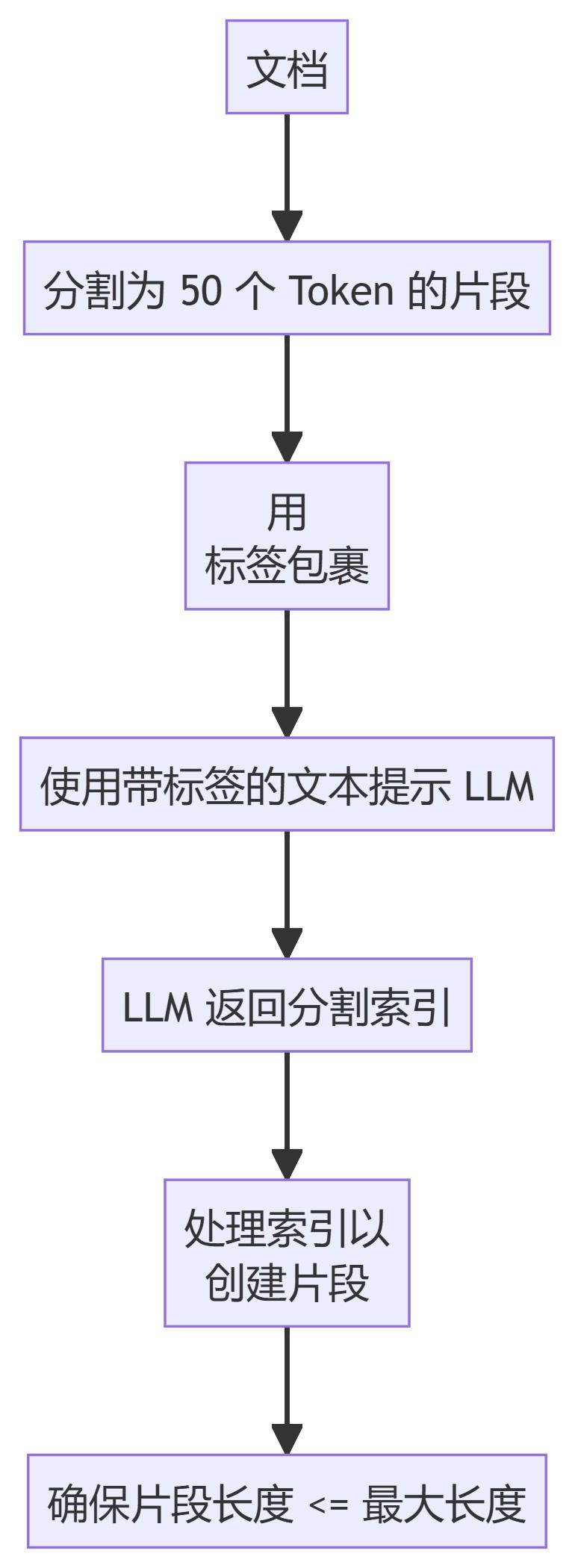
- LLMSemanticChunker
chunking
1. rekursiverZeichenTextSplitter
2. der TokenTextSplitter

3. kamradtSemantikBlocker
4) KamradtModifizierterBunker
5. clusterSemanticChunker
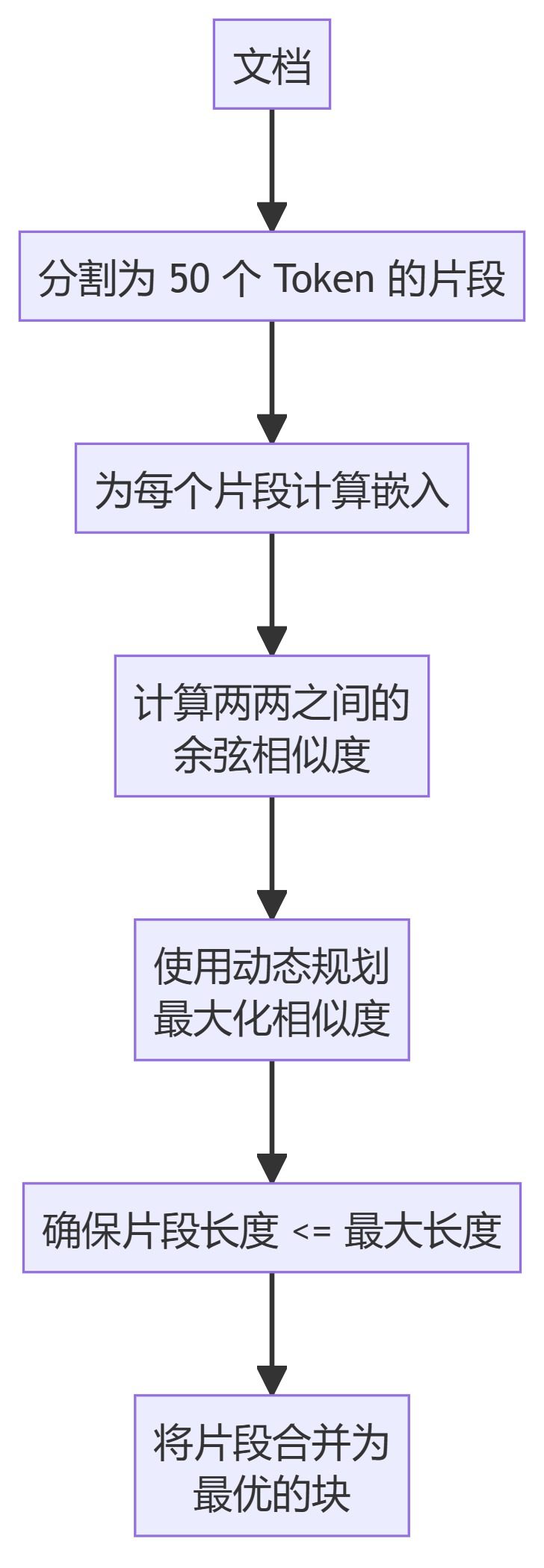
6. LLMSemanticChunker
Methode Beschreibung
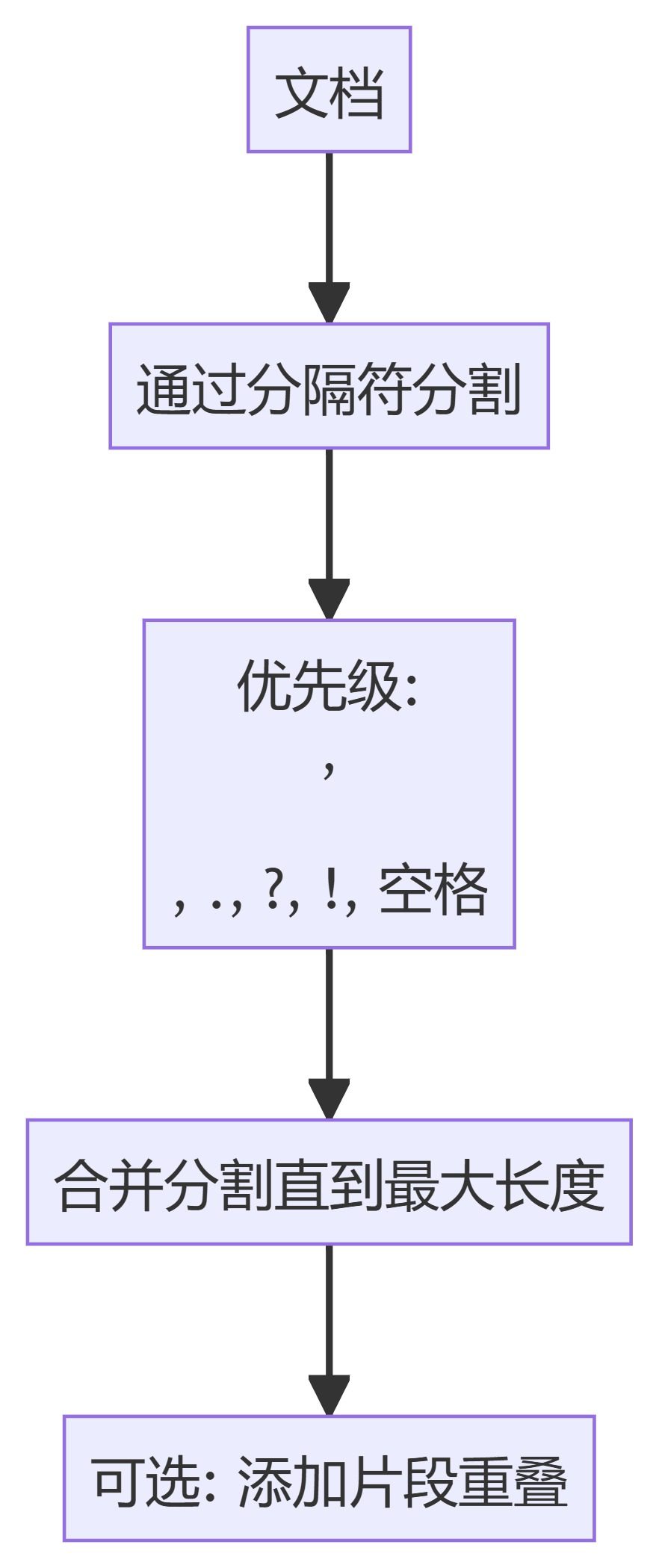
- RecursiveCharacterTextSplitterAufteilung von Text auf der Grundlage einer Hierarchie von Begrenzungszeichen, wobei natürliche Trennpunkte im Dokument bevorzugt werden.
- TokenTextSplitterZerlegt Text in Blöcke mit einer festen Anzahl von Token, wobei sichergestellt wird, dass die Aufteilung an den Tokengrenzen erfolgt.
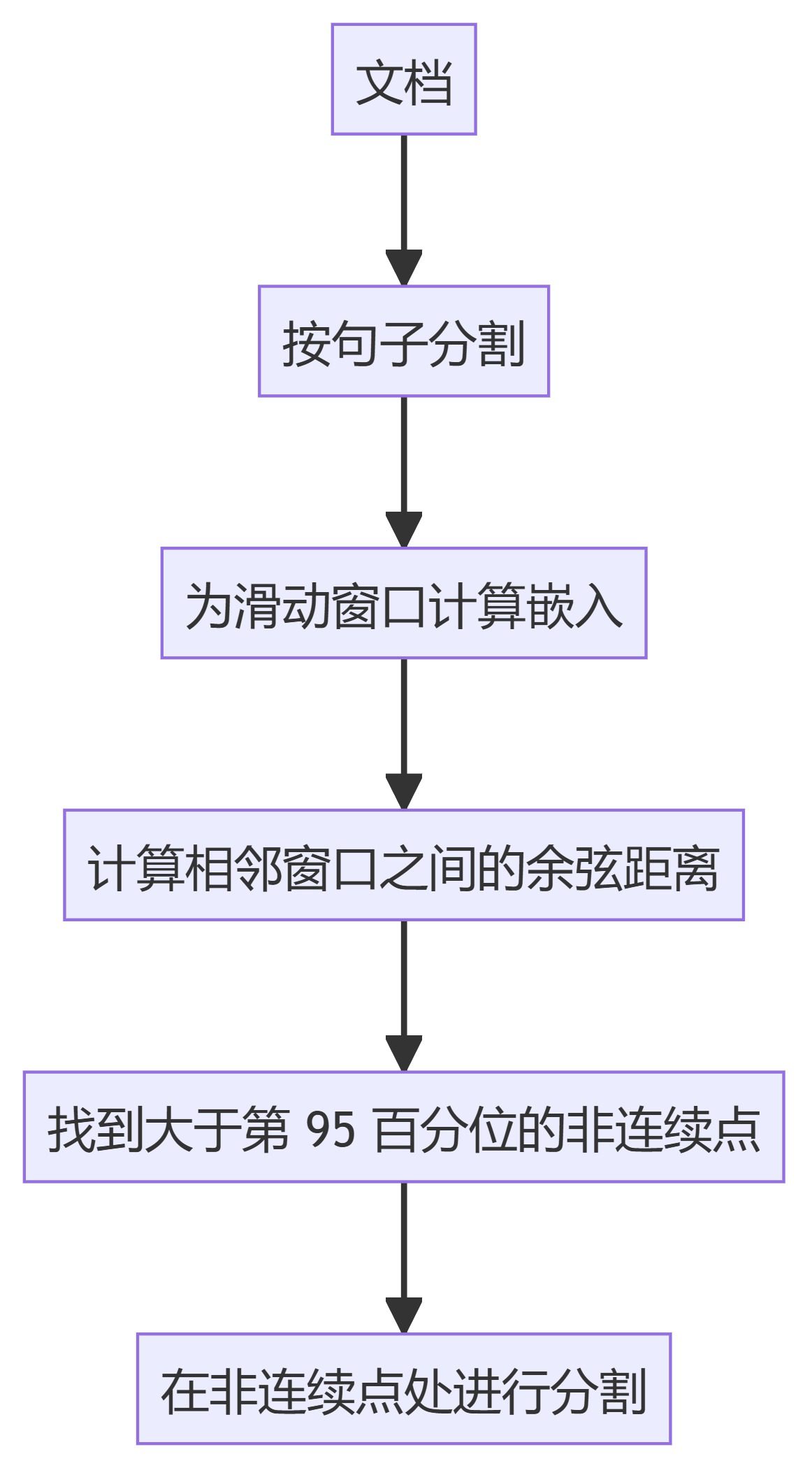
- KamradtSemanticChunkerSliding-Window-Einbettungen verwenden, um semantische Diskontinuitäten zu erkennen und den Text entsprechend zu segmentieren.
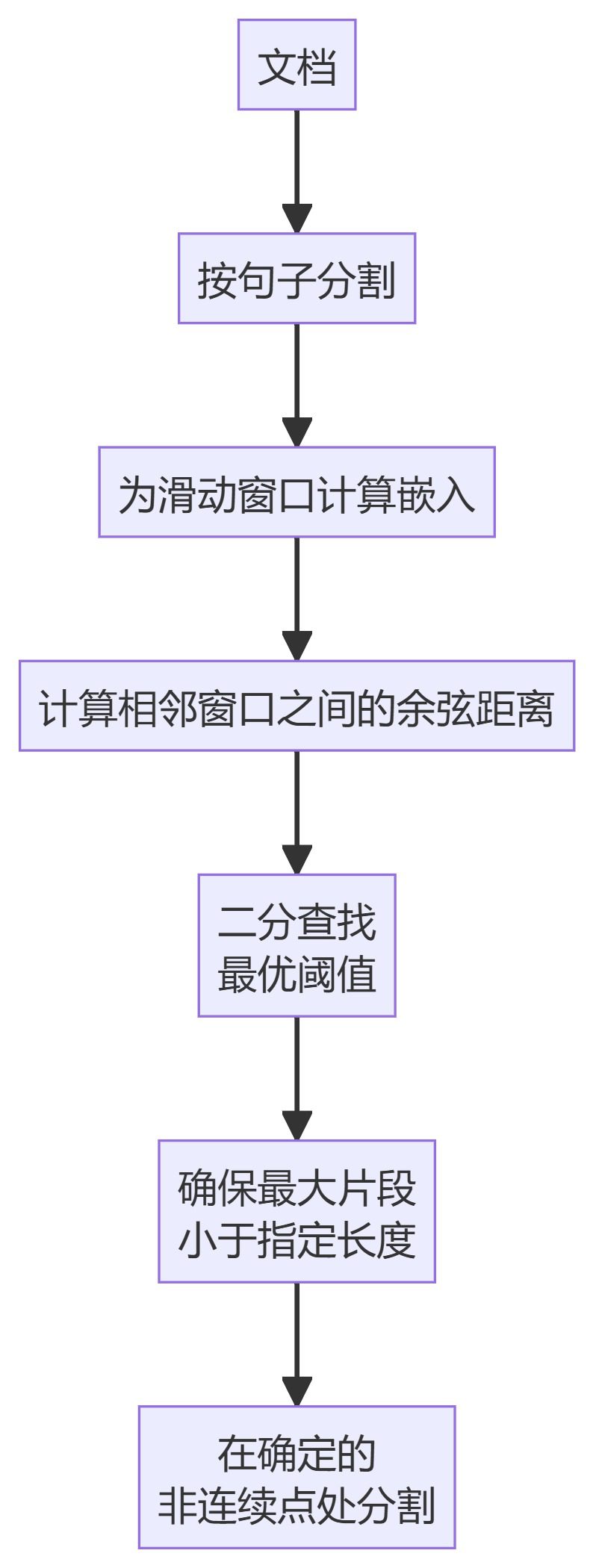
- KamradtModifiedChunkerKamradtSemanticChunker: Eine verbesserte Version von KamradtSemanticChunker, die die Bisektionssuche verwendet, um den optimalen Schwellenwert für die Segmentierung zu finden.
- ClusterSemanticChunkerAufteilung des Textes in Abschnitte (Chunks), Berechnung der Einbettungen und Verwendung der dynamischen Programmierung, um optimale Abschnitte auf der Grundlage semantischer Ähnlichkeit zu erstellen.
- LLMSemanticChunkerSprachmodellierung verwenden, um geeignete Segmentierungspunkte im Text zu identifizieren.
Verwendung
Um diese Chunking-Methoden in Ihrem RAG-Prozess zu verwenden:
- durch (eine Lücke)
chunkersModul, um die benötigten Chunker zu importieren. - Initialisieren Sie den Chunker mit geeigneten Parametern (z. B. maximale Chunk-Größe, Überlappung).
- Übergeben Sie Ihr Dokument an den Chunker, um Chunking-Ergebnisse zu erhalten.
Beispiel:
from chunkers import RecursiveCharacterTextSplitter
chunker = RecursiveCharacterTextSplitter(chunk_size=1000, chunk_overlap=200)
chunks = chunker.split_text(your_document)
Wie man eine Chunking-Methode wählt
Die Wahl der Chunking-Methode hängt von Ihrem spezifischen Anwendungsfall ab:
- Für eine einfache Textaufteilung können Sie RecursiveCharacterTextSplitter oder TokenTextSplitter verwenden.
- Wenn eine semantische Segmentierung erforderlich ist, sollten Sie KamradtSemanticChunker oder KamradtModifiedChunker in Betracht ziehen.
- Für fortgeschritteneres semantisches Chunking verwenden Sie ClusterSemanticChunker oder LLMSemanticChunker.
Faktoren, die bei der Auswahl einer Methode zu berücksichtigen sind:
- Dokumentstruktur und Inhaltstypen
- Erforderliche Chunk-Größe und Überlappung
- Verfügbare Computerressourcen
- Spezifische Anforderungen an das Retrievalsystem (z. B. vektorbasiert oder schlagwortbasiert)
Es ist möglich, verschiedene Methoden auszuprobieren und diejenige zu finden, die Ihren Dokumentations- und Abrufanforderungen am besten entspricht.
Integration mit RAG-Systemen
Nach Abschluss des Chunking werden in der Regel die folgenden Schritte durchgeführt:
- Erzeugung von Einbettungen für jeden Chunk (für vektorbasierte Retrievalsysteme).
- Indizieren Sie diese Chunks in dem gewählten Retrievalsystem (z. B. Vektordatenbank, invertierter Index).
- Bei der Beantwortung einer Abfrage werden die Indexbrocken im Abrufschritt verwendet.
© urheberrechtliche Erklärung
Artikel Copyright AI-Austauschkreis Alle, bitte nicht ohne Erlaubnis vervielfältigen.
Ähnliche Artikel


Keine Kommentare...