
AI Engineering Academy: 2.15 ColBERT RAG (BERT-basiertes postkontextuelles Interaktionsmodell)
ColBERT (Contextualised Post-Cultural Interaction based on BERT) unterscheidet sich von dem traditionellen Modell der dichten Einbettung. Im Folgenden wird kurz beschrieben, wie ColBERT funktioniert:
- Einbettung der Token-SchichtIm Gegensatz zur direkten Erstellung einzelner Vektoren für ein ganzes Dokument oder eine Abfrage, erstellt ColBERT einen einzelnen Vektor für jedes Dokument. Token Erzeugt den Einbettungsvektor.
- Nach der InteraktionBei der Berechnung der Ähnlichkeit zwischen einer Abfrage und einem Dokument wird jedes Abfrage-Token mit jedem Dokument-Token verglichen, anstatt direkt den Gesamtvektor zu vergleichen.
- MaxSim BetriebColBERT findet für jedes Abfrage-Token die maximale Ähnlichkeit mit einem beliebigen Token im Dokument und summiert sie, um einen Ähnlichkeitswert zu erhalten.
Anmerkungen: https://github.com/adithya-s-k/AI-Engineering.academy/tree/main/RAG/10_ColBERT_RAG
Der nächste Schritt besteht darin, anhand von Abbildungen im Detail zu zeigen, wie ColBERT in der Praxis eingesetzt wird. RAG in einem Prozess arbeiten, bei dem die Verarbeitung auf Token-Ebene und die Post-Interaktionsmechanismen im Vordergrund stehen.
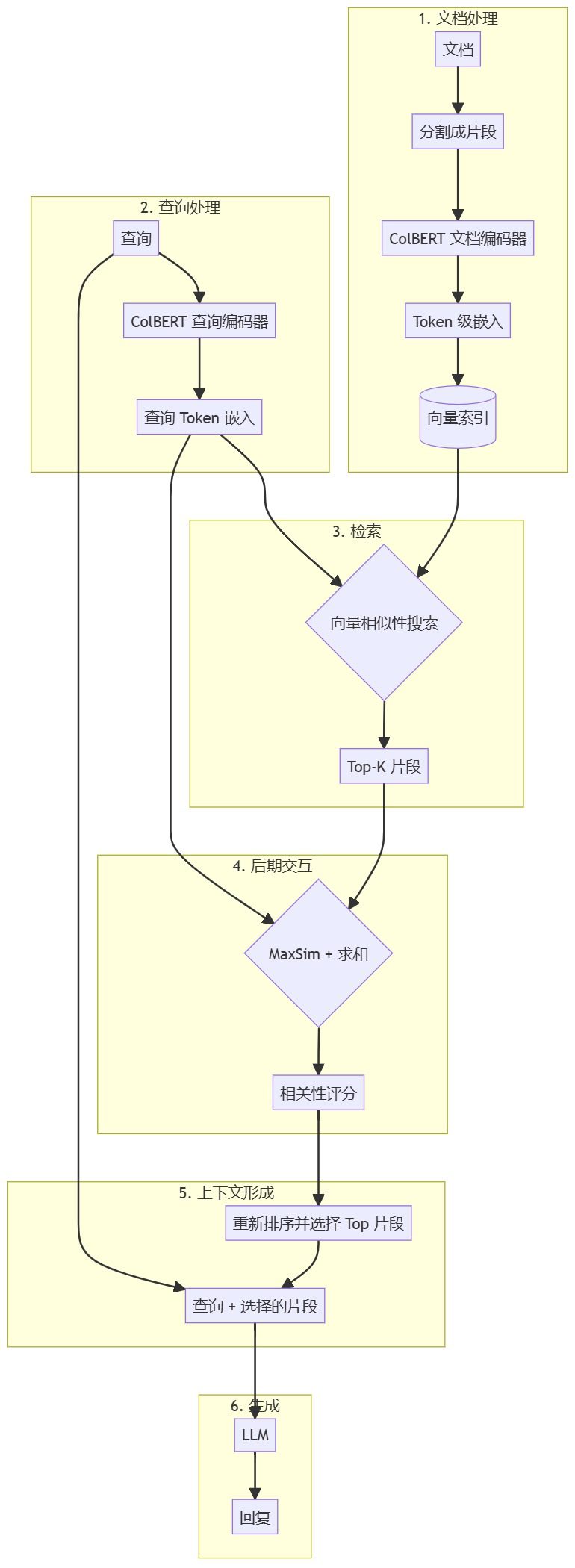
Dieses Diagramm zeigt die Gesamtarchitektur der ColBERT-basierten RAG-Pipeline, wobei die Verarbeitung auf Token-Ebene und die Post-Interaktion im ColBERT-Ansatz im Vordergrund stehen.
Lassen Sie uns nun ein detaillierteres Diagramm erstellen, das die Einbettung auf Token-Ebene und die Post-Interaktionsmechanismen von ColBERT hervorhebt:

Diese Grafik veranschaulicht dies:
- Wie Dokumente und Abfragen als Einbettungen auf Token-Ebene durch BERT und lineare Schichten verarbeitet werden.
- Wie jedes Abfrage-Token mit jedem Dokument-Token im Post-Interaktions-Mechanismus verglichen wird.
- MaxSim-Operation und dem anschließenden Summierungsschritt, um den endgültigen Korrelationswert zu ermitteln.
Diese Diagramme zeigen genauer, wie ColBERT innerhalb der RAG-Pipeline funktioniert, wobei der Ansatz auf Token-Ebene und die Mechanismen der späten Interaktion hervorgehoben werden. Dieser Ansatz ermöglicht es ColBERT, feinere Informationen aus Abfragen und Dokumenten zu erhalten, was zu detaillierteren Übereinstimmungen und einer potenziell besseren Abrufleistung im Vergleich zu herkömmlichen dichten Einbettungsmodellen führt.
© urheberrechtliche Erklärung
Artikel Copyright AI-Austauschkreis Alle, bitte nicht ohne Erlaubnis vervielfältigen.
Ähnliche Artikel



Keine Kommentare...