
AI Engineering Academy: 2.10 Automatisierter Zusammenführungssucher
kurz
Der automatische Merge-Sucher istErweiterter Rahmen für die Abrufgenerierung (RAG)Eine High-Level-Implementierung des Der Ansatz zielt darauf ab, das Kontextbewusstsein und die Kohärenz von KI-generierten Antworten zu verbessern, indem potenziell fragmentierte und kleinere Kontexte zu größeren und umfassenderen Kontexten zusammengefasst werden.
https://github.com/adithya-s-k/AI-Engineering.academy/tree/main/RAG/05_Auto_Merging_RAG
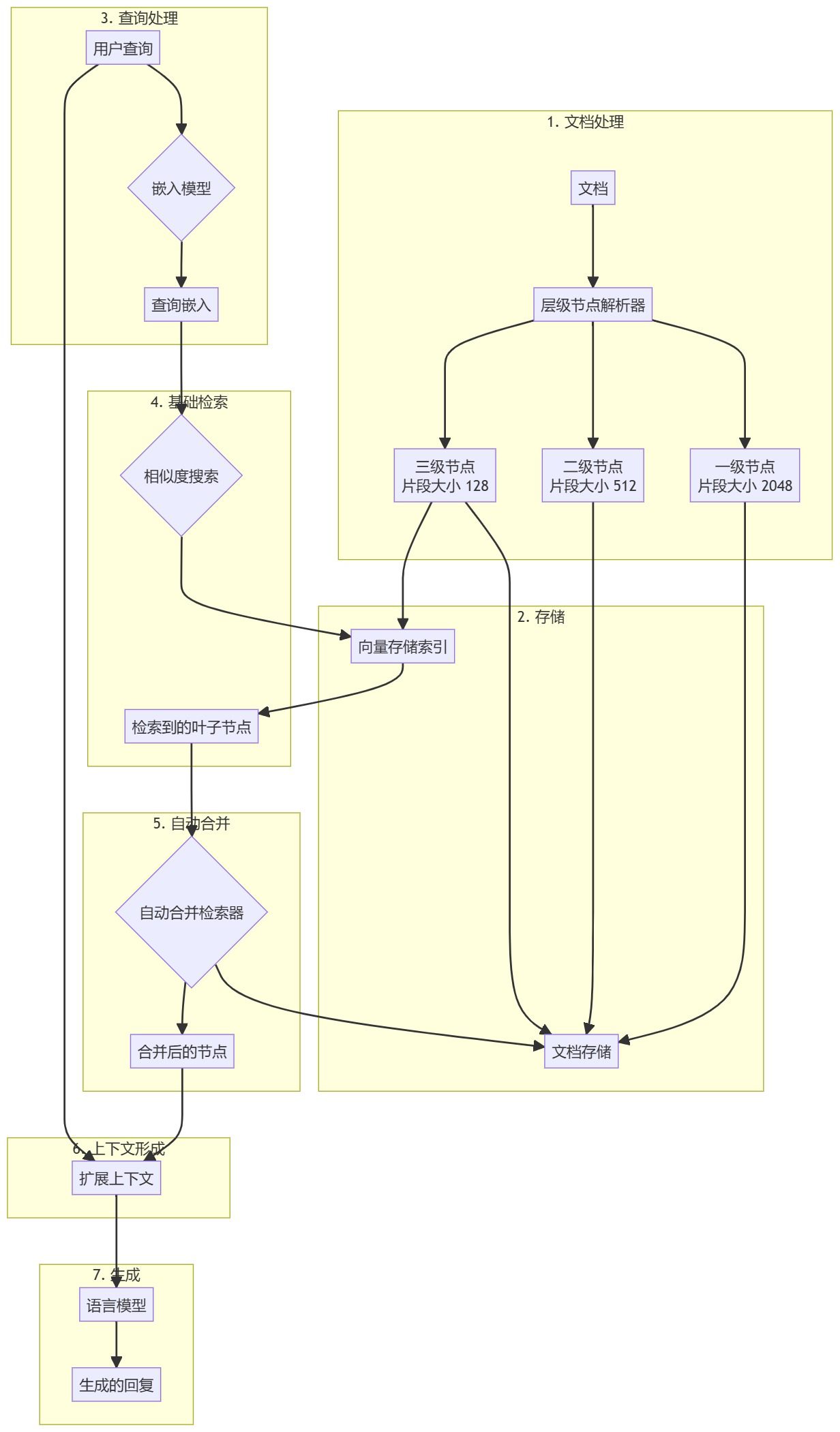
Motivation im Hintergrund
Herkömmliche Systeme zur Generierung erweiterter Suchanfragen haben oft Schwierigkeiten, die Kohärenz über größere Kontexte hinweg aufrechtzuerhalten, oder zeigen schlechte Leistungen, wenn es um Informationen geht, die sich über mehrere Textsegmente erstrecken. Auto-Merge-Retriever beheben diese Einschränkung, indem sie rekursiv Gruppen von Kindknoten zusammenführen, die auf einen Elternknoten verweisen, der einen bestimmten Schwellenwert überschreitet, und so einen umfassenderen und kohärenteren Kontext im Retrieval- und Generierungsprozess bieten.
Methodische Einzelheiten
Vorverarbeitung von Dokumenten und Erstellung von Hierarchien
- Dokument ladenLaden und Verarbeiten von Eingangsdokumenten (z.B. PDF-Dateien).
- hierarchische Auflösung: Verwendung
HierarchicalNodeParserErzeugt eine Knotenhierarchie aus einem Dokument:- Ebene 1: Blockgröße 2048
- Ebene 2: Blockgröße 512
- Ebene 3: Blockgröße 128
- Knotenpunkt-SpeicherAlle Knoten werden im Dokumentenspeicher gespeichert und die Blattknoten werden ebenfalls im Vektorspeicher indiziert.
Verbesserter Arbeitsablauf bei der Suchgenerierung
- Vorverarbeitung der AbfrageBenutzeranfragen: Verwenden Sie das gleiche Einbettungsmodell wie für Dokumentenblöcke, um Benutzeranfragen zu verarbeiten.
- Einfache SucheDer Base Searcher führt eine erste Ähnlichkeitssuche durch, um relevante Blattknoten zu finden.
- Automatisches Zusammenführen::
AutoMergingRetrieverDie abgerufenen Blattknoten werden analysiert, und die Teilmenge der Blattknoten, die über einen bestimmten Schwellenwert hinaus auf den übergeordneten Knoten verweisen, wird rekursiv "zusammengeführt". - Kontexterweiterung (Datenverarbeitung)Die zusammengeführten Knoten bilden einen erweiterten Kontext und werden mit der ursprünglichen Abfrage zusammengeführt.
- Generierung einer AntwortGenerierung von Antworten durch Einspeisung von Erweiterungskontexten und Abfragen in das Large Language Model (LLM).
Hauptmerkmale des automatisierten Zusammenführungssuchers
- Hierarchische Darstellung von DokumentenHierarchie: Pflegen Sie eine mehrstufige Hierarchie von Dokumentenblöcken.
- Effiziente BasissucheAchieving fast and accurate preliminary information retrieval using vector similarity searches.
- Dynamische KontexterweiterungAutomatisches Zusammenfügen zusammengehöriger Textblöcke zu größeren, kohärenteren Zusammenhängen.
- Flexible UmsetzungKann für eine breite Palette von Dokumenttypen und Sprachmodellen verwendet werden.
Vorteile dieser Methode
- Verbesserung der kontextuellen KohärenzBieten Sie einen kohärenteren und vollständigeren Kontext für das größere Sprachmodell, indem Sie zusammenhängende Textabschnitte zusammenführen.
- Flexible Anpassbarkeit der SucheDer Merge-Prozess passt sich automatisch an die Anfrage und die Suchergebnisse an, um kontextbezogene Informationen zu liefern.
- Effiziente SpeicherstrukturA fast implementation of basic retrieval of leaf nodes while maintaining a hierarchical structure.
- Möglichkeit zur Verbesserung der AntwortqualitätEs wird erwartet, dass der erweiterte Kontext zu genaueren und detaillierteren Antworten des Sprachmodells führt.
Ergebnisse
Die experimentellen Ergebnisse zeigen, dass der Vergleich zwischen dem automatischen Merge-Sucher und dem Basis-Sucher:
- Ähnliche Leistung bei den Metriken für Korrektheit, Relevanz, Genauigkeit und semantische Ähnlichkeit.
- Im paarweisen Vergleich bevorzugten 52,5%-Nutzer die Antwort des Auto-Merge-Suchers.
Diese Ergebnisse zeigen, dass die Leistung des automatisierten Merge Searchers mit den traditionellen Suchmethoden vergleichbar oder ihnen sogar leicht überlegen ist.
zu einem Urteil gelangen
Der automatische Merge-Sucher bietet eine fortschrittliche Methode zur Verbesserung der RAG Abrufprozess im System. Durch die dynamische Zusammenführung relevanter Textblöcke zu größeren, kohärenteren Kontexten werden einige der Beschränkungen herkömmlicher, auf Textblöcken basierender Abrufverfahren überwunden. Während die ersten Ergebnisse positive Aussichten zeigen, wird erwartet, dass weitere Forschung und Optimierung die Antwortqualität und Kohärenz deutlich verbessern.
Vorbedingungen
Um dieses System zu implementieren, benötigen Sie:
- Ein großes Sprachmodell, das in der Lage ist, Text zu generieren (z. B. GPT-3.5-turbo, GPT-4).
- Ein Einbettungsmodell zur Umwandlung von Textblöcken und Abfragen in Vektordarstellungen.
- Vektordatenbanken für eine effiziente Ähnlichkeitssuche (z. B. FAISS).
- Eine Dokumentenablage zur Speicherung der gesamten Knotenhierarchie.
- Angebot
LlamaIndexBibliothek, die Folgendes enthältHierarchicalNodeParserim Gesang antwortenAutoMergingRetrieverVerwirklichung. - Ausreichende Rechenressourcen für die Verarbeitung und Speicherung großer Dokumentensammlungen.
- Vertrautheit mit der Programmiersprache Python für Implementierung und Tests.
Anwendungsbeispiel
from llama_index.core import StorageContext, VectorStoreIndex
from llama_index.core.node_parser import HierarchicalNodeParser
from llama_index.core.retrievers import AutoMergingRetriever
# 将文档解析为节点层级
node_parser = HierarchicalNodeParser.from_defaults()
nodes = node_parser.get_nodes_from_documents(docs)
# 设置存储上下文
storage_context = StorageContext.from_defaults()
storage_context.docstore.add_documents(nodes)
# 创建基础索引和检索器
leaf_nodes = get_leaf_nodes(nodes)
base_index = VectorStoreIndex(leaf_nodes, storage_context=storage_context)
base_retriever = base_index.as_retriever(similarity_top_k=6)
# 创建自动合并检索器
retriever = AutoMergingRetriever(base_retriever, storage_context, verbose=True)
# 在查询引擎中使用自动合并检索器
query_engine = RetrieverQueryEngine.from_args(retriever)
response = query_engine.query(query_str)© urheberrechtliche Erklärung
Artikel Copyright AI-Austauschkreis Alle, bitte nicht ohne Erlaubnis vervielfältigen.
Ähnliche Artikel


Keine Kommentare...