
AI Engineering Academy: 2.1 RAG von Grund auf neu implementieren
skizziert.
Diese Anleitung führt Sie durch die Erstellung einer einfachen Sucherweiterungsgenerierung mit reinem Python (RAG) System. Wir werden ein Einbettungsmodell und ein großes Sprachmodell (LLM) verwenden, um relevante Dokumente zu finden und Antworten auf Benutzeranfragen zu generieren.
https://github.com/adithya-s-k/AI-Engineering.academy/tree/main/RAG/00_RAG_from_Scratch
Betroffene Schritte
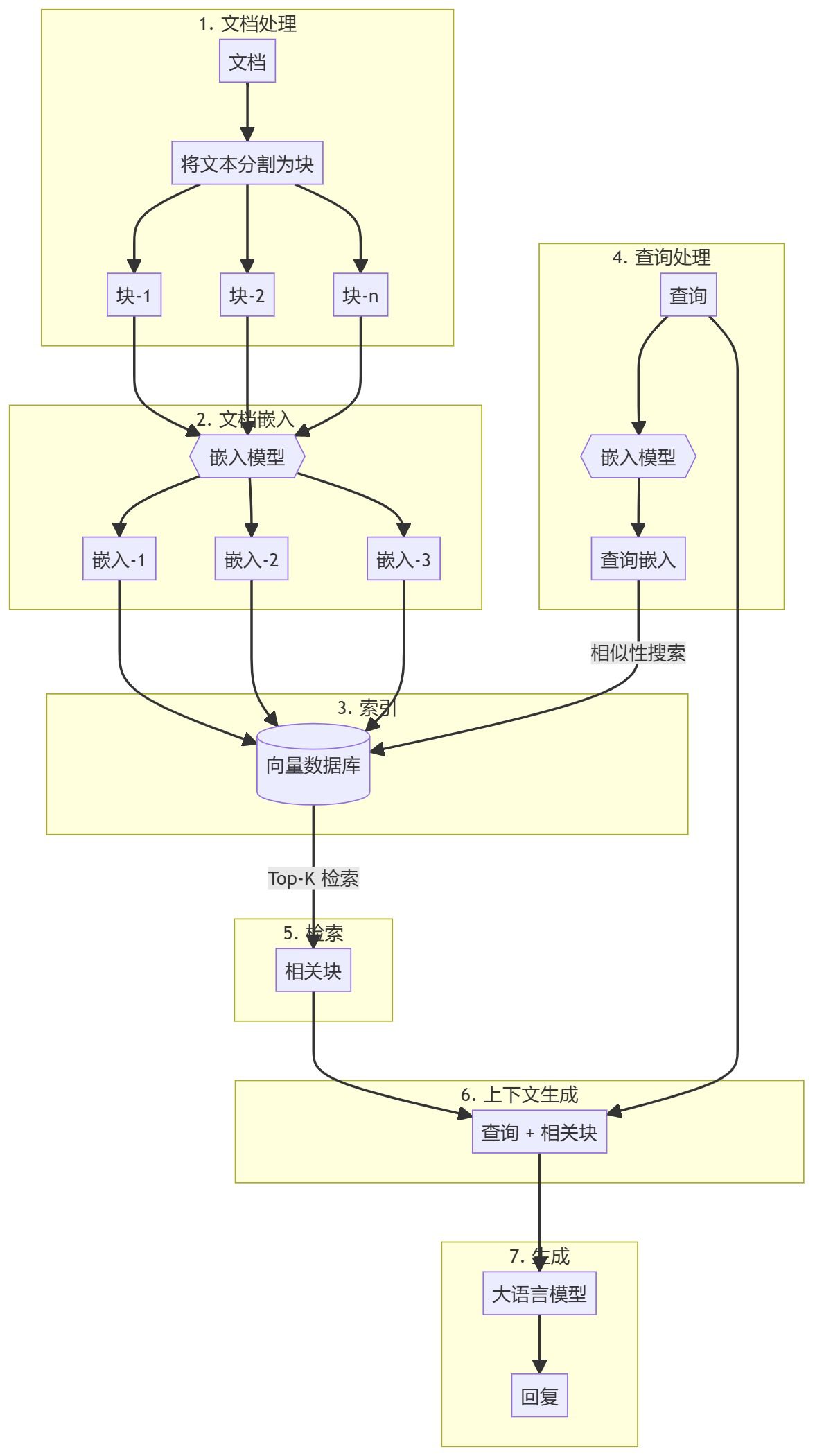
Der gesamte Prozess kann in zwei Hauptschritte unterteilt werden:
- Erstellung einer Wissensdatenbank
- erzeugter Teil
Erstellung einer Wissensdatenbank
Zunächst müssen Sie eine Wissensbasis vorbereiten (Dokumente, PDFs, Wiki-Seiten). Dies sind die Basisdaten für das Sprachmodell (LLM). Der spezifische Prozess umfasst:
- StückchenText in kleine Unterdokumente aufteilen, um die Verarbeitung zu vereinfachen.
- einbetten.Berechnung der numerischen Einbettung für jeden Unterdokumentenblock, um die semantische Ähnlichkeit der Anfrage zu verstehen.
- auf HaldeSpeichern Sie diese Einbettungen so, dass sie schnell abgerufen werden können. Obwohl es üblich ist, Vektorspeicher/Datenbanken zu verwenden, zeigt dieses Tutorial, dass dies nicht notwendig ist.
erzeugter Teil
Wenn eine Benutzeranfrage eingegeben wird, wird eine Einbettung für die Anfrage berechnet und die relevantesten Unterdokumentblöcke werden aus der Wissensbasis abgerufen. Diese relevanten Blöcke werden an die Benutzeranfrage angehängt, um einen Kontext zu bilden, und in den LLM eingespeist, um eine Antwort zu generieren.
1. umweltbezogene Einstellungen
Es gibt einige Pakete, die installiert werden müssen, bevor Sie beginnen können.
sentence-transformersEinbettungen: Dient der Erzeugung von Einbettungen für Dokumente und Abfragen.numpy: für Ähnlichkeitsvergleiche.scipy: für erweiterte Ähnlichkeitsberechnungen.wikipedia-apiWikipedia: Wird verwendet, um Wikipedia-Seiten als Wissensbasis zu laden.textwrapFormatierung des Ausgabetextes.
!pip install -q sentence-transformers
!pip install -q wikipedia-api
!pip install -q numpy
!pip install -q scipy
2. das Laden des Einbettungsmodells
Lassen Sie uns ein eingebettetes Modell laden. Dieses Lernprogramm verwendet die gte-base-en-v1.5.
from sentence_transformers import SentenceTransformer
model = SentenceTransformer("Alibaba-NLP/gte-base-en-v1.5", trust_remote_code=True)
Über das Modell
gte-base-en-v1.5 Model ist ein quelloffenes englisches Modell, das vom Alibaba NLP-Team bereitgestellt wird. Es ist Teil der GTE-Familie (Generic Text Embedding), die für die Erzeugung hochwertiger Einbettungen für eine Vielzahl von Aufgaben der natürlichen Sprachverarbeitung entwickelt wurde. Das Modell ist für die Erfassung der semantischen Bedeutung von englischem Text optimiert und kann für Aufgaben wie Satzähnlichkeit, semantische Suche und Clustering verwendet werden.trust_remote_code=True Parameter ermöglichen die Verwendung von benutzerdefiniertem Code im Zusammenhang mit dem Modell, um sicherzustellen, dass es wie erwartet funktioniert.
3. die Beschaffung von Textinhalten aus Wikipedia und deren Aufbereitung
- Ein Wikipedia-Artikel wird zunächst als Wissensbasis geladen. Der Text wird in überschaubare Abschnitte (Unterdokumente) aufgeteilt, in der Regel in Absätze.
from wikipediaapi import Wikipedia wiki = Wikipedia('RAGBot/0.0', 'en') doc = wiki.page('Hayao_Miyazaki').text paragraphs = doc.split('\n\n') # 分块 - Es gibt zwar viele Chunking-Strategien, aber viele von ihnen sind möglicherweise nicht anwendbar. Am besten überprüfen Sie Ihre Knowledge Base (KB), um die am besten geeignete Strategie zu ermitteln. In diesem Beispiel wird nach Absatz gechunkert.
- Wenn Sie sehen möchten, wie diese Blöcke aussehen, können Sie die
textwrapBibliothek und drucken Sie ihn Absatz für Absatz aus.import textwrap for i, p in enumerate(paragraphs): wrapped_text = textwrap.fill(p, width=100) print("-----------------------------------------------------------------") print(wrapped_text) print("-----------------------------------------------------------------") - Enthält das Dokument Bilder und Tabellen, empfiehlt es sich, diese separat zu extrahieren und mit Hilfe eines visuellen Modells einzubetten.
4. die Einbettung von Dokumenten
- Als nächstes wird das Modell durch den Aufruf der Funktion
encodeMethode, die Textdaten entgegennimmt (z. B.paragraphs) als eingebettet kodiert.docs_embed = model.encode(paragraphs, normalize_embeddings=True) - Diese Einbettungen sind dichte Vektordarstellungen des Textes, die die semantische Bedeutung erfassen und es dem Modell ermöglichen, den Text in mathematischer Form zu verstehen und zu verarbeiten.
- Wir normalisieren hier die Einbettung.
- Was ist Normalisierung? Bei der Normalisierung werden die Einbettungswerte so angepasst, dass sie ein einheitliches Paradigma haben (d. h. eine Vektorlänge von 1).
- Warum normalisieren? Die normalisierte Einbettung stellt sicher, dass die Abstände zwischen Vektoren in erster Linie Unterschiede in der Richtung und nicht in der Größe widerspiegeln. Dies verbessert die Leistung des Modells bei Ähnlichkeitssuchaufgaben, bei denen die "Nähe" oder "Ähnlichkeit" zwischen Texten verglichen wird.
- am Ende
docs_embedist eine Sammlung von Vektordarstellungen von Textdaten, wobei jeder Vektor folgenden Werten entsprichtparagraphsEin Absatz in der Liste. - ausnutzen
shapeum die Anzahl der Blöcke und die Dimension jedes Einbettungsvektors zu sehen (die Größe des Einbettungsvektors hängt von der Art des Einbettungsmodells ab).docs_embed.shape - Sie können auch sehen, wie die tatsächliche Einbettung aussieht, die eine Reihe von normalisierten Werten ist.
docs_embed[0]
5. die Einbettung von Abfragen
Betten Sie die Beispiel-Benutzerabfrage in ähnlicher Weise ein wie das eingebettete Dokument.
query = "What was Studio Ghibli's first film?"
query_embed = model.encode(query, normalize_embeddings=True)
Sie können prüfen query_embed Form, um die Dimension der eingebetteten Abfrage zu bestätigen.
query_embed.shape
6. den der Abfrage am nächsten liegenden Absatz zu finden
Eine der einfachsten Möglichkeiten, die relevantesten Teile des Inhalts zu finden, ist die Berechnung des Punktprodukts von Dokumenteinbettungen und Abfrageeinbettungen.
a. Berechnung des Punktprodukts
Das Punktprodukt ist eine mathematische Operation, bei der die entsprechenden Elemente von zwei Vektoren (oder Matrizen) multipliziert und summiert werden. Es wird häufig verwendet, um die Ähnlichkeit zwischen zwei Vektoren zu messen.
(Beachten Sie, dass das Punktprodukt berechnet wird, indem man die query_embed (Transponierung des Vektors).
import numpy as np
similarities = np.dot(docs_embed, query_embed.T)
b. Verstehen der Punktprodukte und ihrer Formen
NumPy-Arrays von .shape Eigenschaft gibt ein Tupel zurück, das die Dimensionen des Arrays darstellt.
similarities.shape
Die erwartete Form in diesem Code ist wie folgt:
- für den Fall, dass
docs_embedhat die Form von (n_docs, n_dim):- n_docs ist die Anzahl der Dokumente.
- n_dim ist die in jedem Dokument eingebettete Dimension.
query_embed.Twird die Form (n_dim, 1) haben, da wir mit einer einzigen Abfrage vergleichen.- dot-product
similaritiesDie Form des Arrays ist (n_docs,), was bedeutet, dass es sich um ein 1-dimensionales Array (Vektor) mit n_docs-Elementen handelt. Jedes Element stellt den Ähnlichkeitswert zwischen der Abfrage und einem bestimmten Dokument dar. - Warum die Form überprüfen? Wenn man sicherstellt, dass die Form wie erwartet ist (n_docs,), wird bestätigt, dass das Punktprodukt korrekt durchgeführt wurde und dass die Ähnlichkeitswerte für jedes Dokument korrekt berechnet wurden.
Sie können drucken similarities Array, um die Ähnlichkeitswerte zu überprüfen, wobei jeder Wert einem Punktproduktergebnis entspricht:
print(similarities)
c. Interpretation des Punktprodukts
Das Punktprodukt zwischen zwei Vektoren (Einbettungen) misst ihre Ähnlichkeit: höhere Werte zeigen eine größere Ähnlichkeit zwischen der Anfrage und dem Dokument an. Wenn die Einbettungen normalisiert sind, sind diese Werte direkt proportional zur Kosinusähnlichkeit zwischen den Vektoren. Wenn sie nicht normalisiert sind, zeigen sie immer noch die Ähnlichkeit an, spiegeln aber auch die Größe der Einbettung wider.
d. Identifizieren Sie die 3 ähnlichsten Dokumente
Um die 3 ähnlichsten Dokumente auf der Grundlage ihrer Ähnlichkeitswerte zu finden, können Sie den folgenden Code verwenden:
top_3_idx = np.argsort(similarities, axis=0)[-3:][::-1].tolist()
- np.argsort(similarities, axis=0). Diese Funktion paart die
similaritiesDer Index des Arrays wird sortiert. Zum Beispiel, wennsimilarities = [0.1, 0.7, 0.4](math.) Gattungnp.argsortwird zurückgegeben[0, 2, 1]Die Indizes der Mindest- und Höchstwerte sind 0 bzw. 1. - [-3:]: Bei dieser Aufteilung werden die 3 Indizes mit den höchsten Ähnlichkeitswerten ausgewählt (die letzten 3 Elemente nach der Sortierung).
- [::-1]: Dieser Vorgang kehrt die Reihenfolge um, so dass der Index in absteigender Reihenfolge der Ähnlichkeit sortiert wird.
- tolist(). Konvertiert ein indiziertes Array in eine Python-Liste. Ergebnis:
top_3_idxEin Index, der die 3 ähnlichsten Dokumente in absteigender Reihenfolge der Ähnlichkeit enthält.
e. Extraktion der ähnlichsten Dokumente
most_similar_documents = [paragraphs[idx] for idx in top_3_idx]
- Liste Abgeleitet: Diese Zeile erstellt eine Datei namens
most_similar_documentsDie Liste derparagraphsDie Liste, die demtop_3_idxDer eigentliche Absatz des Indexes. - Absätze[idx]. in Bezug auf
top_3_idxDieser Vorgang ruft den entsprechenden Absatz für jeden Index in der Datei
f. Formatierung und Anzeige der ähnlichsten Dokumente
CONTEXT Die Variable wird zunächst mit einer leeren Zeichenkette initialisiert und dann in einer Aufzählungsschleife mit dem Zeilenumbruchtext des ähnlichsten Dokuments ergänzt.
CONTEXT = ""
for i, p in enumerate(most_similar_documents):
wrapped_text = textwrap.fill(p, width=100)
print("-----------------------------------------------------------------")
print(wrapped_text)
print("-----------------------------------------------------------------")
CONTEXT += wrapped_text + "\n\n"
7. eine Antwort generieren
Jetzt haben wir eine Abfrage und zugehörige Inhaltsblöcke, die zusammen an das Large Language Model (LLM) übergeben werden.
a. Erklärung zur Recherche
query = "What was Studio Ghibli's first film?"
b. Erstellen Sie eine Eingabeaufforderung
prompt = f"""
use the following CONTEXT to answer the QUESTION at the end.
If you don't know the answer, just say that you don't know, don't try to make up an answer.
CONTEXT: {CONTEXT}
QUESTION: {query}
"""
c. Einrichten von OpenAI
- Installieren Sie OpenAI, um auf das Large Language Model (LLM) zuzugreifen und es zu nutzen.
!pip install -q openai - Aktivieren Sie den Zugriff auf OpenAI-API-Schlüssel (kann in den Geheimnissen in Google Colab eingestellt werden).
from google.colab import userdata userdata.get('openai') import openai - Erstellen Sie einen OpenAI-Client.
from openai import OpenAI client = OpenAI(api_key=userdata.get('openai'))
d. Rufen Sie die API auf, um eine Antwort zu generieren.
response = client.chat.completions.create(
model="gpt-4o",
messages=[
{"role": "user", "content": prompt},
]
)
- client.chat.completions.create. Diese Methode ruft ein großes chatbasiertes Sprachmodell auf, um eine neue Antwort zu erstellen (zu generieren).
- Kunde. Stellt ein API-Client-Objekt dar, das eine Verbindung zu einem Dienst (in diesem Fall OpenAI) herstellt.
- chat.completions.create. Geben Sie an, dass Sie die Erstellung einer chatbasierten Generation beantragen.
Weitere Informationen zu den Parametern, die an die Methode
- model="gpt-4o". Gibt das Modell an, das zur Erzeugung der Antwort verwendet wird." gpt-4o" ist eine spezifische Variante des GPT-4-Modells. Verschiedene Modelle können unterschiedliche Verhaltensweisen, Feinabstimmungsmethoden oder Fähigkeiten haben, daher ist die Angabe des Modells wichtig, um sicherzustellen, dass das gewünschte Ergebnis erzielt wird.
- Nachrichten. Dieser Parameter ist eine Liste von Nachrichtenobjekten zur Darstellung des Dialogverlaufs. Dies ermöglicht dem Modell, den Kontext des Chats zu verstehen. In diesem Beispiel geben wir nur eine Nachricht in der Liste an:
{"role": "user", "content": prompt}. - Rolle. "Benutzer" bezeichnet die Rolle des Absenders der Nachricht, d. h. des Benutzers, der mit dem Modell interagiert.
- Inhalt. Enthält den eigentlichen Text der vom Benutzer gesendeten Nachricht. Die Variable prompt enthält diesen Text, den das Modell als Eingabe für die Generierung der Antwort verwenden wird.
e. In Bezug auf die eingegangenen Antworten
Wenn Sie eine Anfrage an eine API wie das OpenAI GPT-Modell stellen, um eine Chat-Antwort zu generieren, wird die Antwort normalerweise in einem strukturierten Format zurückgegeben, in der Regel ein Wörterbuch.
Diese Struktur umfasst in der Regel:
- Auswahlmöglichkeiten. Eine Liste (Array), die mehrere mögliche, vom Modell generierte Antworten enthält. Jedes Element in dieser Liste stellt eine mögliche Antwort oder einen Abschluss dar.
- Nachricht. Ein Objekt oder Wörterbuch in jeder Auswahl, das den tatsächlichen Inhalt der vom Modell erzeugten Nachricht enthält.
- Inhalt. Der Textinhalt der Nachricht, d.h. die eigentliche Antwort oder Vervollständigung, die vom Modell erzeugt wird.
f. Gedruckte Antworten
print(response.choices[0].message.content)
Wir wählen choices Der erste Eintrag in der Liste und dann der Zugriff auf eine der message Objekt. Schließlich greifen wir auf das message den Nagel auf den Kopf treffen content das den tatsächlichen, vom Modell generierten Text enthält.
zu einem Urteil gelangen
Damit ist unsere Erklärung zum Aufbau von RAG-Systemen von Grund auf abgeschlossen. Es wird dringend empfohlen, dass Sie Ihr erstes RAG-Setup zunächst in reinem Python erstellen, um besser zu verstehen, wie diese Systeme funktionieren.
© urheberrechtliche Erklärung
Artikel Copyright AI-Austauschkreis Alle, bitte nicht ohne Erlaubnis vervielfältigen.
Ähnliche Artikel




Keine Kommentare...