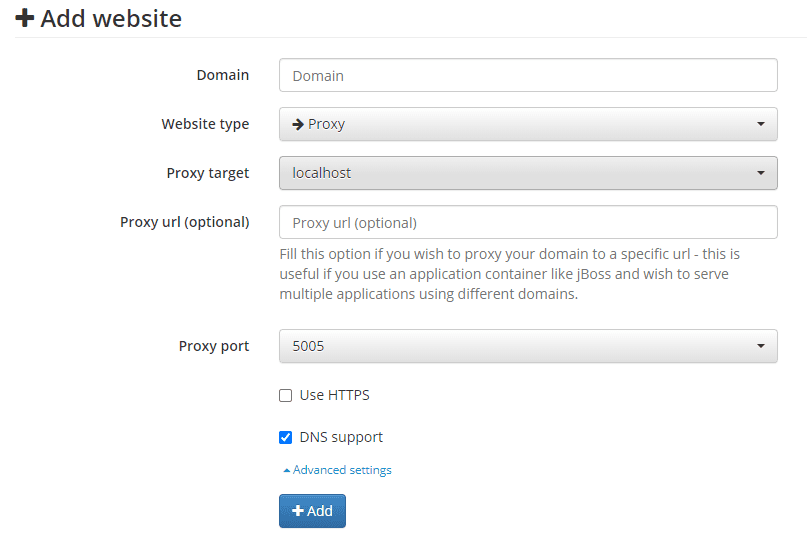
Aggregator: Agenten-Crawling- und Aggregationsplattform aus einer Hand, kostenloser Agentenpool (bitte vorschriftsmäßig verwenden)
Allgemeine Einführung
Aggregator ist ein Open-Source-Projekt, das entwickelt wurde, um einen kostenlosen Proxy-Pool zu erstellen, der eine Vielzahl von verfügbaren Proxy-Knoten crawlen kann. Die Plattform hat ein flexibles Plug-in-System, können Benutzer nach den besonderen Bedürfnissen der Ziel-Site, durch Plug-ins, um bestimmte Funktionen zu erreichen. Das Projekt wird hauptsächlich verwendet, um Crawling-Techniken zu lernen, verboten für alle illegalen Aktivitäten.
Funktionsliste
- Agent PoolbauAutomatisches Crawlen und Aggregieren von Proxy-Knoten aus mehreren Quellen, um einen hochwertigen Proxy-Pool zu bilden.
- steckbares SystemUnterstützung für benutzerdefinierte Plug-ins, um den spezifischen Anforderungen verschiedener Websites gerecht zu werden.
- AutomatisierungEinschließlich automatischer Anmeldung, automatischer Registrierung, Zusammenfassung von Abonnements und anderer Funktionen zur Vereinfachung der Benutzerbedienung.
- Unterstützung von mehreren ProtokollenUnterstützt eine Vielzahl von Proxy-Protokollen, wie z. B. HTTP, HTTPS, SOCKS, usw.
- Open Source und Unterstützung durch die GemeinschaftDas Projekt ist quelloffen, und die Nutzer können die Funktionen verändern und erweitern und erhalten Unterstützung durch die Community.
Hilfe verwenden
Einbauverfahren
- Vorbereitung der UmweltStellen Sie sicher, dass Python 3.6 oder höher installiert ist.
- Klonprojekt: Verwendung
git clone https://github.com/wzdnzd/aggregatorBefehl, um das Projekt lokal zu klonen. - Installation von Abhängigkeiten: Wechseln Sie in das Projektverzeichnis und führen Sie
pip install -r requirements.txtInstallieren Sie die erforderlichen Abhängigkeiten. - KonfigurationsdateiÄndern nach Bedarf
config.yamlKonfigurationsdatei zum Festlegen der Parameter für Crawl-Ziel und Agentenpool. - Laufende Projekte: Umsetzung
python collect.pyUm das Crawlen von Proxy-Knoten zu starten, führen Siepython process.pyVerarbeitungs- und Aggregationsmittel.
Verwendungsprozess
- Starten Sie den Crawler: Lauf
python collect.pyBeginnen Sie mit dem Crawlen der Proxy-Knoten, und das System wird sie automatisch gemäß den Einstellungen in der Konfigurationsdatei crawlen. - Verarbeitung von Daten: Lauf
python process.pyDie gecrawlten Proxy-Knoten werden verarbeitet und gefiltert, um die hohe Qualität des Proxy-Pools zu gewährleisten. - Plug-in-VerwendungJe nach den Bedürfnissen der Zielsite schreiben oder verwenden Sie ein vorhandenes Plugin, das in der
pluginsVerzeichnis, wird es automatisch geladen und ausgeführt. - AutomatisierungKonfigurieren Sie das automatische Einchecken, die automatische Registrierung und andere Funktionen und führen Sie die entsprechenden Skripte aus, um einen automatischen Betrieb zu erreichen.
- Ergebnisse anzeigenNach Abschluss der Verarbeitung werden die Daten des Agentenpools in einer bestimmten Datei gespeichert und können bei Bedarf vom Benutzer verwendet werden.
Detaillierte Vorgehensweise
- Agent PoolbauDas System holt sich regelmäßig Proxy-Knoten aus verschiedenen Quellen und überprüft sie, um die hohe Qualität und Verfügbarkeit des Proxy-Pools sicherzustellen.
- steckbares SystemBenutzer können benutzerdefinierte Plug-ins schreiben, die auf den spezifischen Anforderungen der Zielsite basieren und im
pluginsVerzeichnis, lädt das System diese Plugins automatisch und führt sie aus. - AutomatisierungAutomatisches Einchecken, automatische Registrierung und andere Funktionen über die Konfigurationsdatei einrichten; das System führt diese Vorgänge regelmäßig aus, um die tägliche Arbeit des Benutzers zu erleichtern.
- Unterstützung von mehreren ProtokollenDas System unterstützt eine Vielzahl von Proxy-Protokollen wie HTTP, HTTPS, SOCKS usw. Der Benutzer kann das geeignete Proxy-Protokoll für seine Bedürfnisse auswählen.
© urheberrechtliche Erklärung
Artikel Copyright AI-Austauschkreis Alle, bitte nicht ohne Erlaubnis vervielfältigen.
Verwandte Beiträge


Keine Kommentare...