Top 5 KI-Inferenzplattformen, die eine kostenlose Vollversion von DeepSeek-R1 verwenden
Aufgrund des hohen Verkehrsaufkommens und eines Cyberangriffs sind die DeepSeek-Website und die App seit einigen Tagen nicht erreichbar und die API funktioniert nicht.

Zuvor haben wir bereits die Methode zur lokalen Bereitstellung von DeepSeek-R1 vorgestellt (sieheLokaler Einsatz von DeepSeek-R1), aber der durchschnittliche Benutzer ist auf eine Hardwarekonfiguration beschränkt, die es schwierig macht, selbst ein 70b-Modell zu betreiben, geschweige denn ein vollständiges 671b-Modell.
Glücklicherweise haben alle großen Plattformen Zugang zu DeepSeek-R1, so dass Sie es als flachen Ersatz ausprobieren können.
I. NVIDIA NIM-Mikrodienste
NVIDIA Build: Integrieren Sie mehrere KI-Modelle und erleben Sie sie kostenlos
Website: https://build.nvidia.com/deepseek-ai/deepseek-r1
NVIDIA hat den vollen Volumenparameter 671B des DeepSeek-R1 Modelle, die Web-Version ist einfach zu bedienen, und Sie können das Chat-Fenster sehen, wenn Sie darauf klicken:
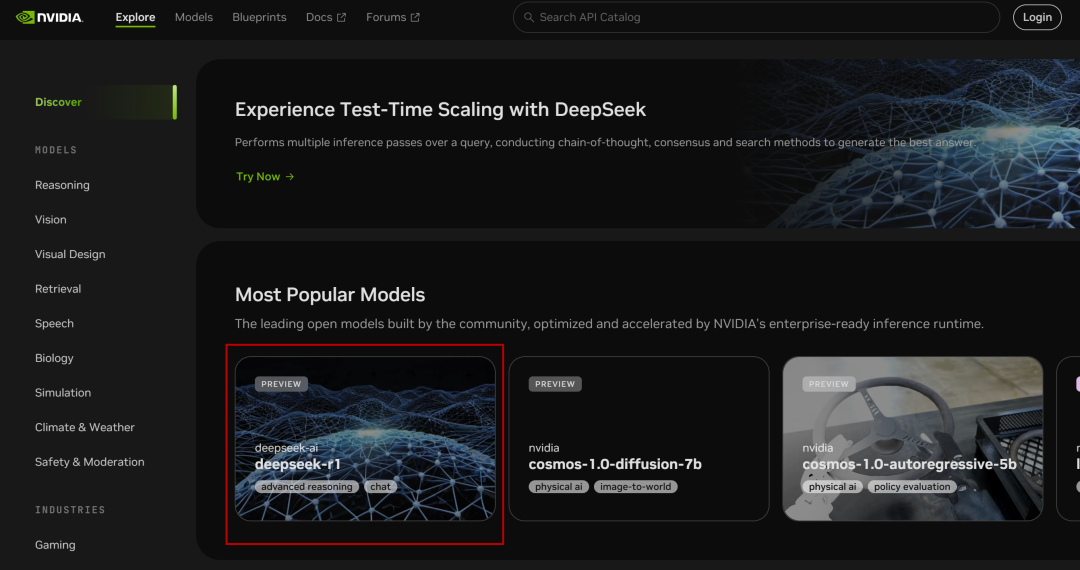
Auf der rechten Seite befindet sich auch die Code-Seite:
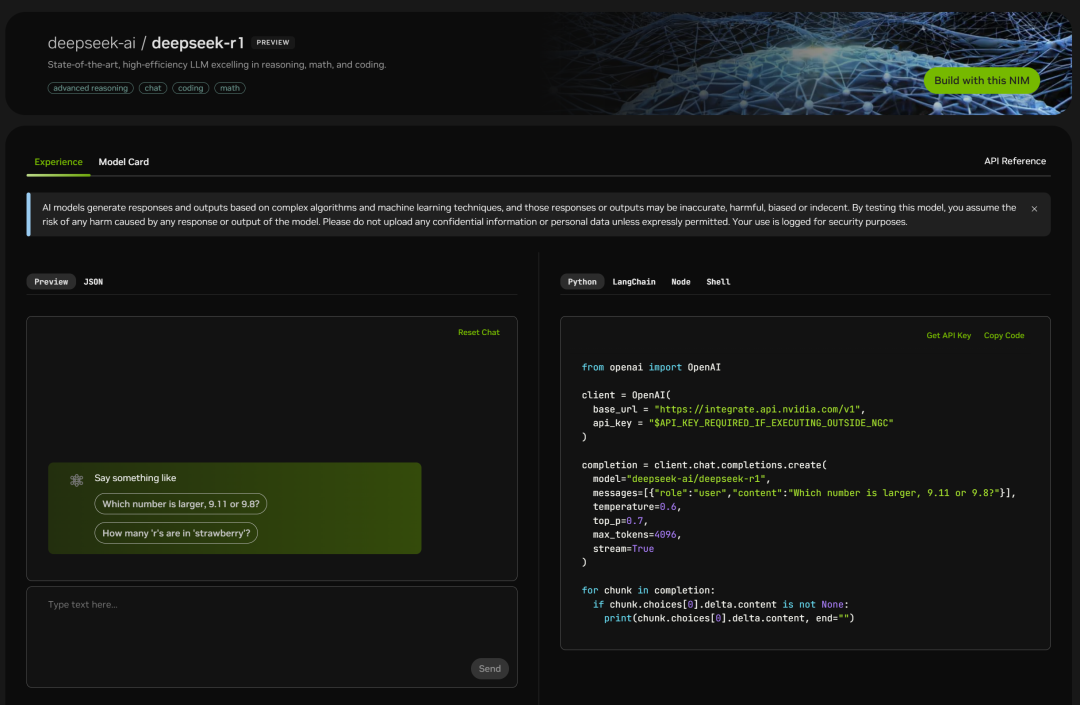
Testen Sie es einfach:

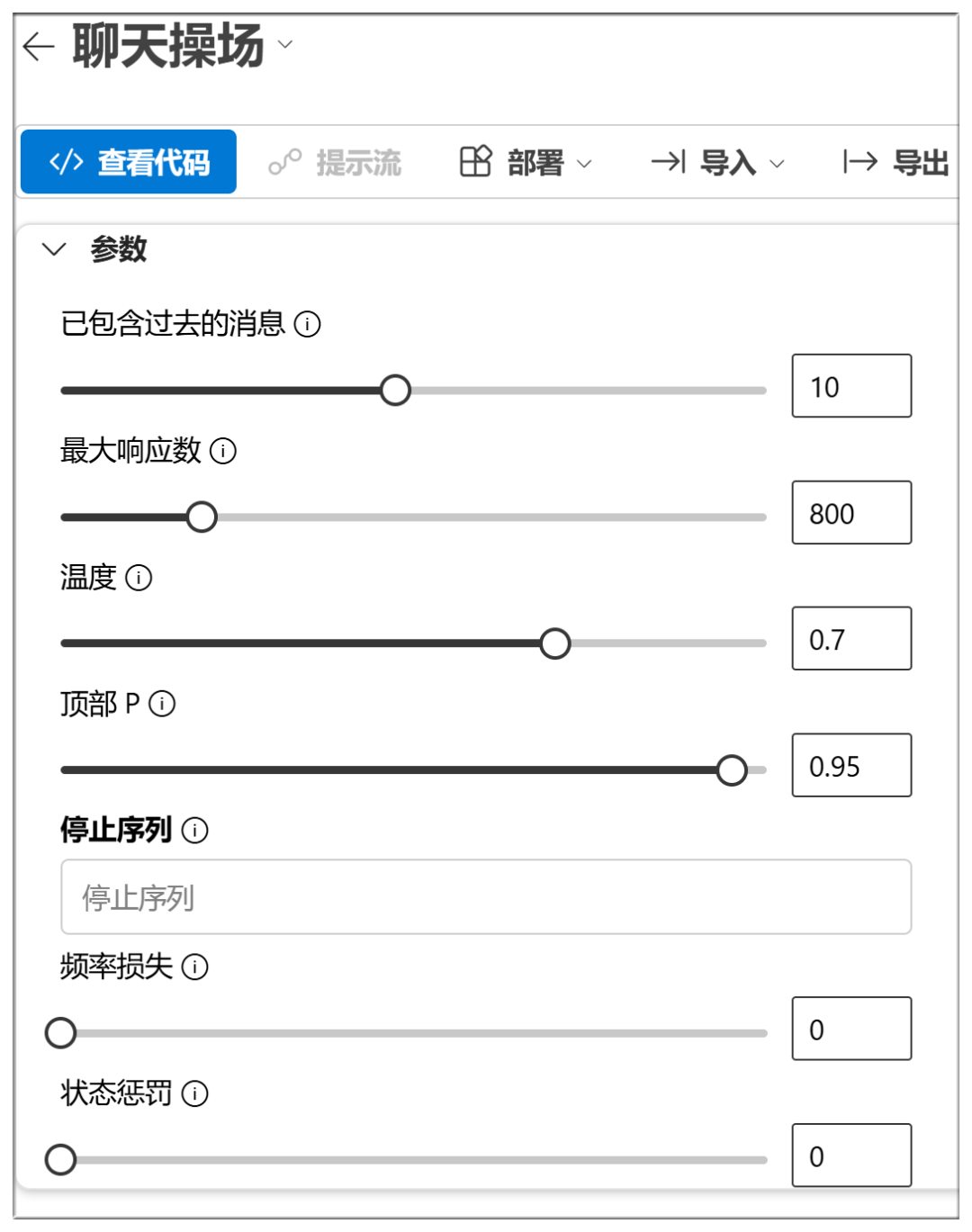
Unterhalb der Chatbox können Sie auch einige Parameter einschalten (die in den meisten Fällen voreingestellt werden können):
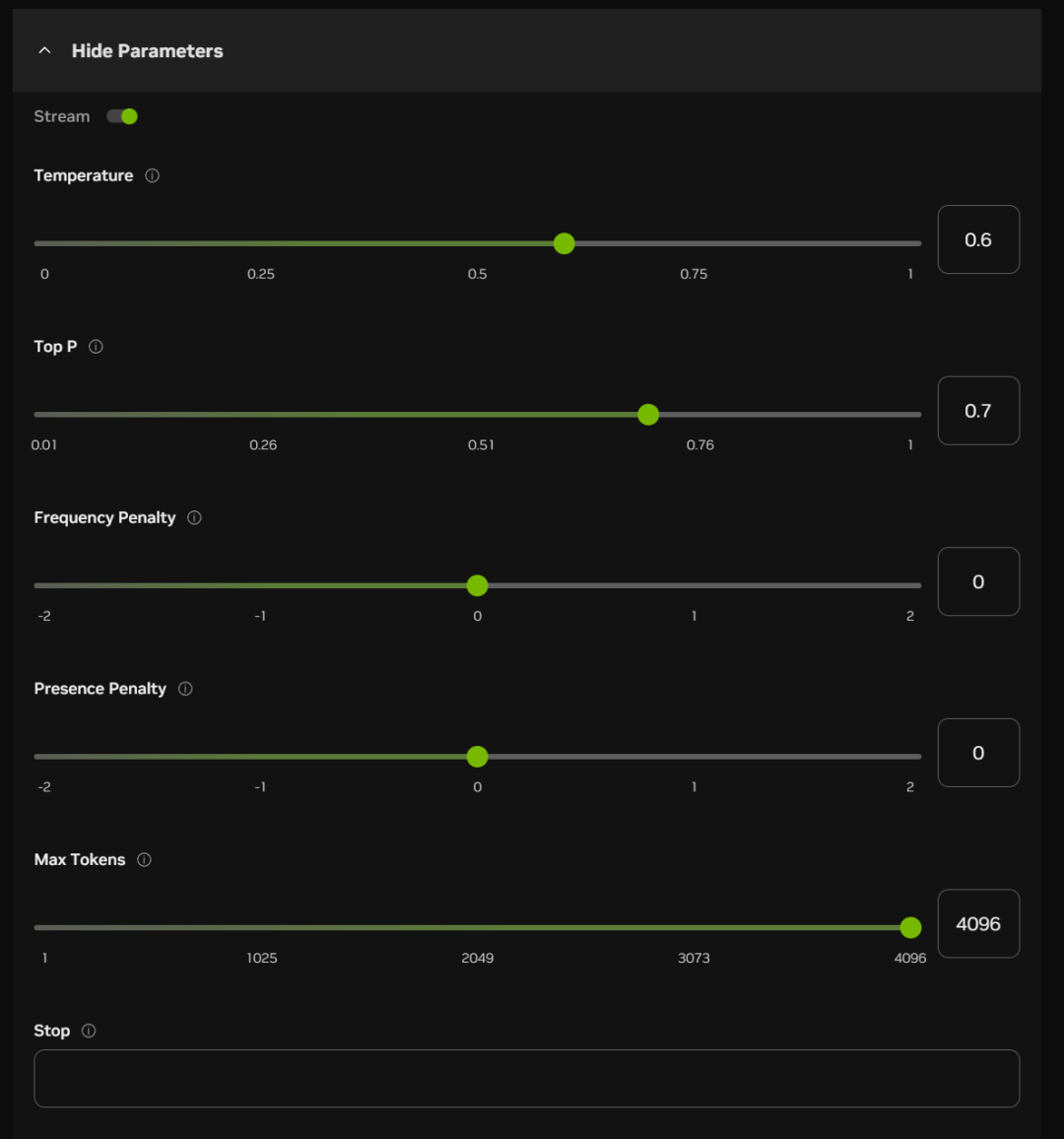
Die ungefähre Bedeutung und Funktion dieser Optionen ist im Folgenden aufgeführt:
Temperatur:
Je höher der Wert, desto zufälliger ist die Ausgabe und desto kreativer können die Antworten ausfallen.
Oben P (nukleare Probenahme):
Höhere Werte halten mehr Token von wahrscheinlicher Qualität zurück und erzeugen mehr Vielfalt
Häufigkeit der Strafe:
Höhere Werte bestrafen hochfrequente Wörter stärker und reduzieren Ausführlichkeit oder Wiederholungen
Strafe für Anwesenheit:
Je höher der Wert, desto eher ist das Modell geneigt, neue Wörter auszuprobieren
Maximale Token:
Je höher der Wert, desto länger ist die potenzielle Länge der Antwort
Halt!
Stoppen Sie die Ausgabe, wenn bestimmte Zeichen oder Sequenzen generiert werden, um zu verhindern, dass die Generierung zu lange dauert oder die Themen ausgehen.
Aufgrund der zunehmenden Zahl weißer Freier (siehe die Anzahl der Personen in der Warteschlange im nachstehenden Schaubild) liegt die NIM derzeit etwas zurück:
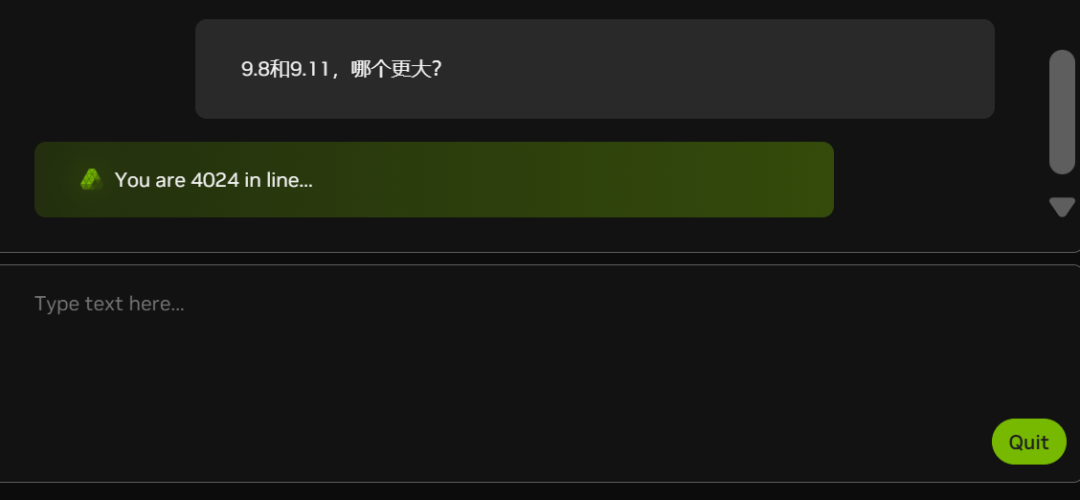
Gibt es bei NVIDIA auch zu wenig Grafikkarten?
Die NIM-Microservices unterstützen auch API-Aufrufe zu DeepSeek-R1, aber Sie müssen sich für ein Konto mit einer E-Mail-Adresse anmelden:
Das Anmeldeverfahren ist relativ einfach und erfordert lediglich eine E-Mail-Verifizierung:

Nach der Registrierung können Sie oben rechts in der Chat-Oberfläche auf "Mit dieser NIM bauen" klicken, um einen API-Schlüssel zu generieren. Derzeit erhalten Sie für die Registrierung 1.000 Punkte (1.000 Interaktionen), die Sie aufbrauchen und dann mit einer neuen E-Mail-Adresse erneut registrieren können.
Die NIM-Microservices-Plattform bietet auch Zugang zu vielen anderen Modellen:
II. Microsoft Azure
Website:
https://ai.azure.com
Mit Microsoft Azure können Sie einen Chatbot erstellen und mit dem Modell über einen Chat-Spielplatz interagieren.
Die Anmeldung bei Azure ist mit viel Aufwand verbunden: Zunächst müssen Sie ein Microsoft-Konto erstellen (melden Sie sich einfach an, wenn Sie bereits eines haben):
Für die Erstellung eines Kontos ist auch eine E-Mail-Verifizierung erforderlich:
Beweise zum Schluss, dass du ein Mensch bist, indem du 10 aufeinanderfolgende Fragen aus der Unterwelt beantwortest:

Es reicht nicht aus, hierher zu kommen, um ein Abonnement abzuschließen:
Überprüfen Sie die Handynummer sowie die Kontonummer und andere Informationen:
Wählen Sie dann "Keine technische Unterstützung":

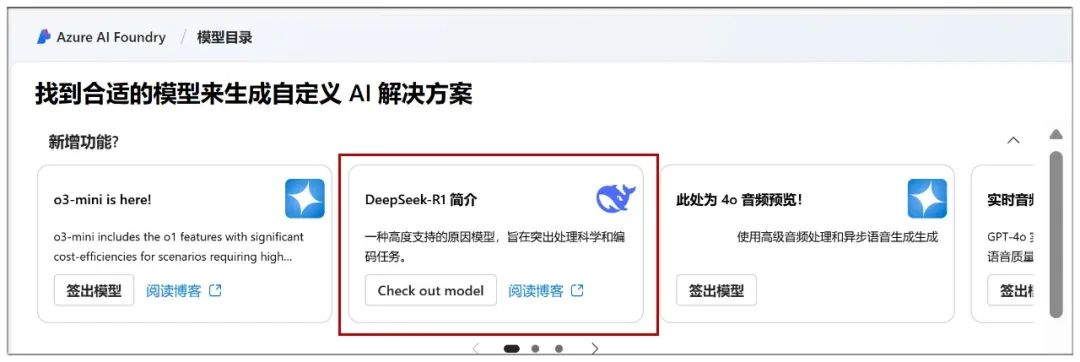
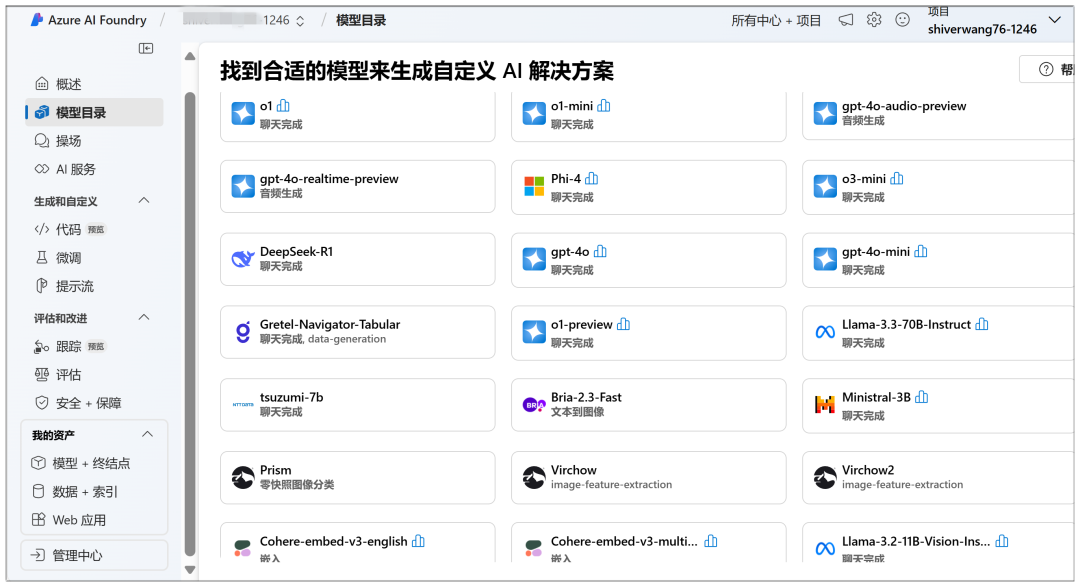
Hier können Sie das Cloud-Deployment starten, im "Model Catalogue" sehen Sie das DeepSeek-R1-Modell an prominenter Stelle:
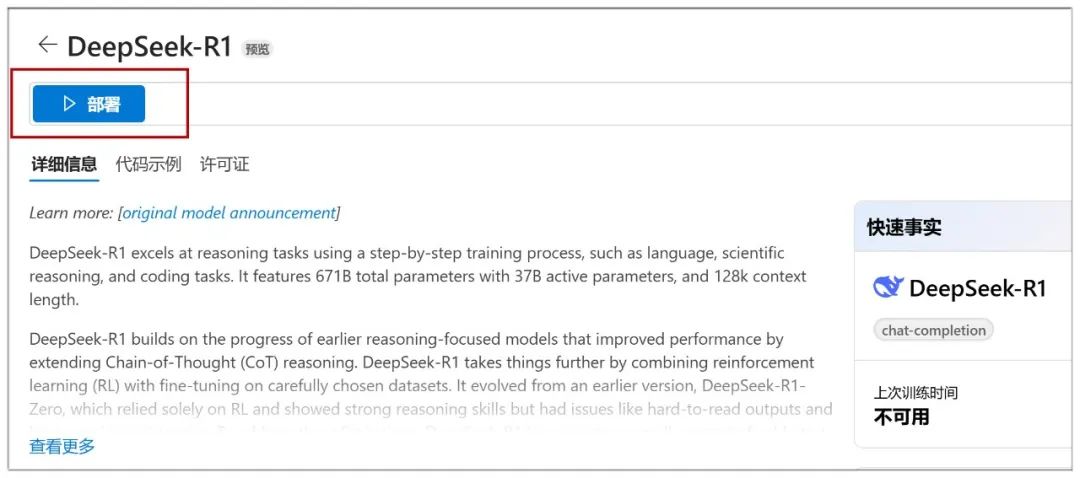
Klicken Sie dann auf der nächsten Seite auf "Bereitstellen":
Als nächstes müssen Sie "Neues Projekt erstellen" wählen:
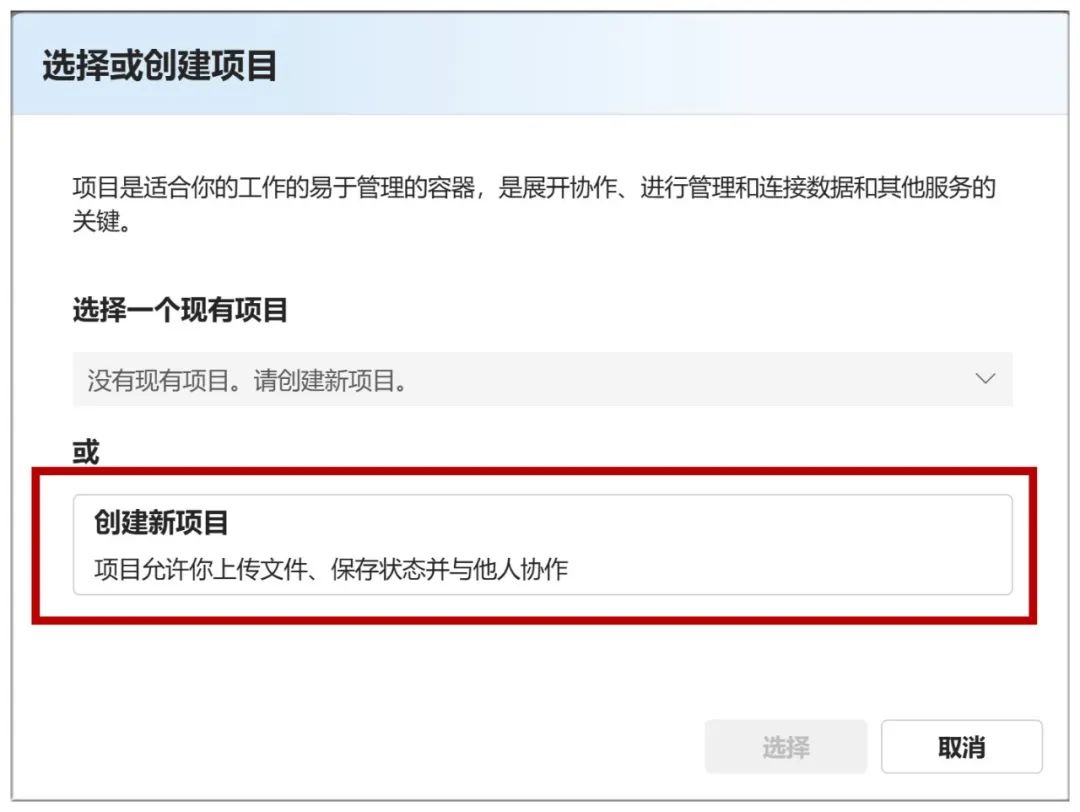
Geben Sie dann alle Standardwerte ein und klicken Sie auf "Weiter":
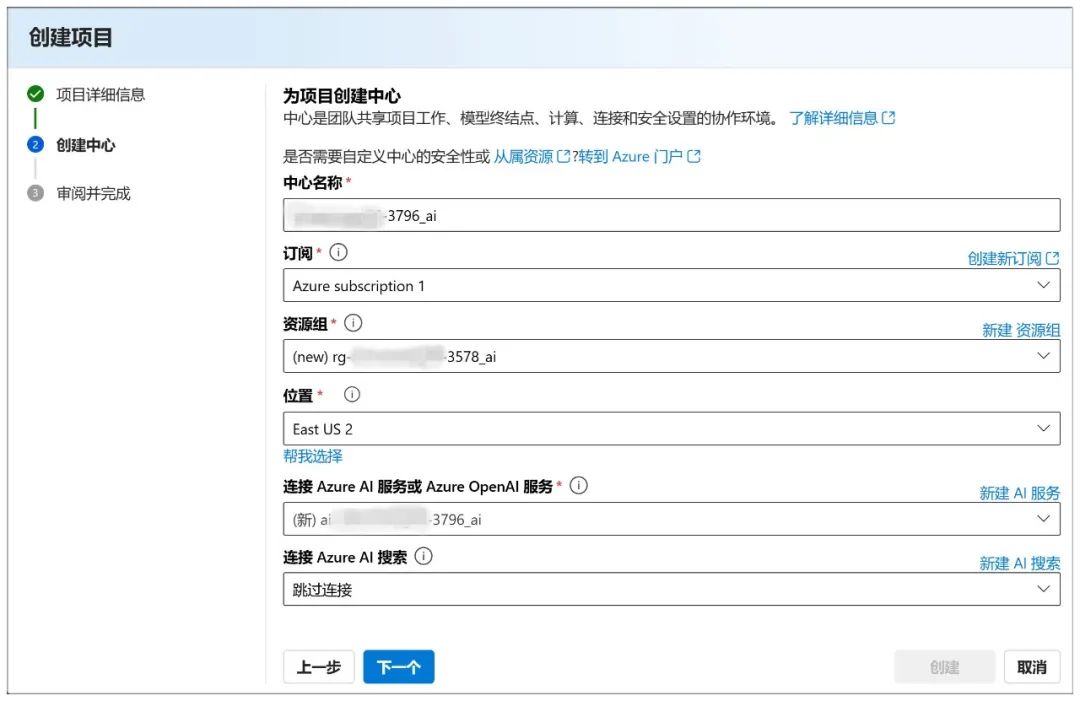
Klicken Sie anschließend auf "Erstellen":
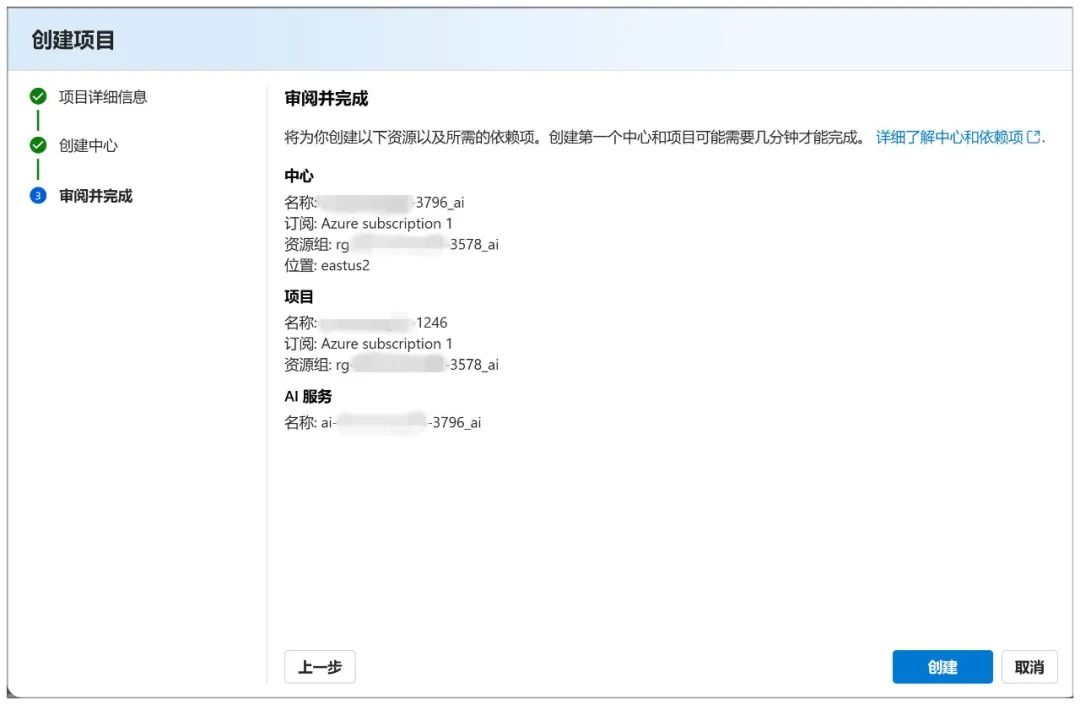
Die Erstellung unter dieser Seite beginnt, und es dauert eine Weile zu warten:
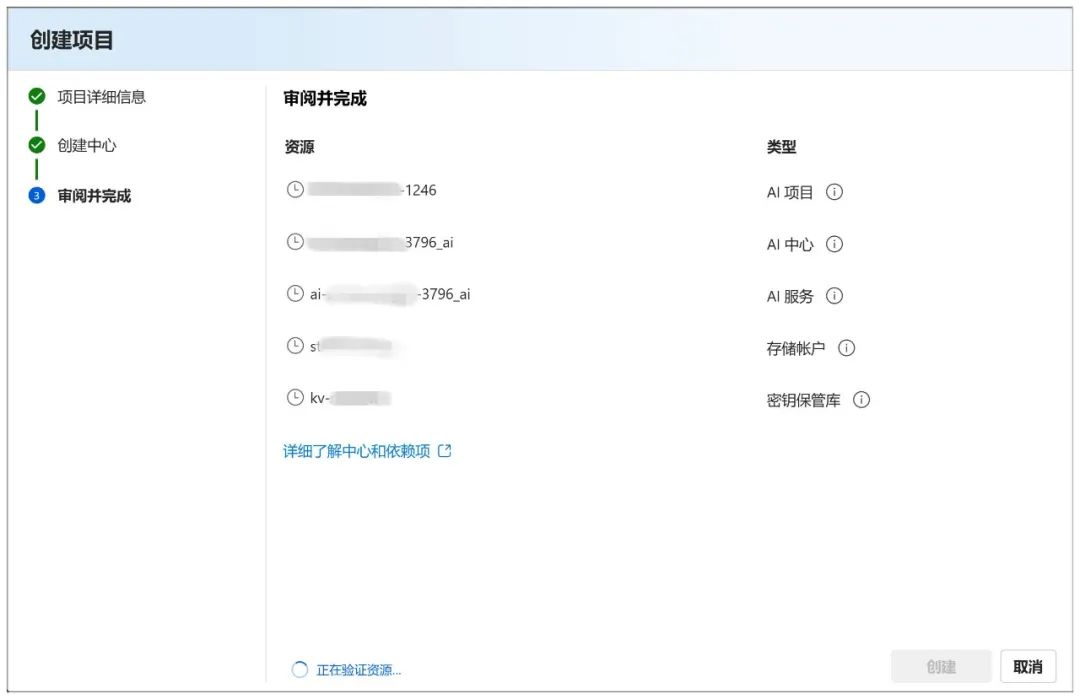
Wenn Sie fertig sind, gelangen Sie auf diese Seite, wo Sie auf "Bereitstellen" klicken können, um zum nächsten Schritt zu gelangen:
Sie können auch unter "Preise und Bedingungen" oben nachsehen, ob die Nutzung kostenlos ist:
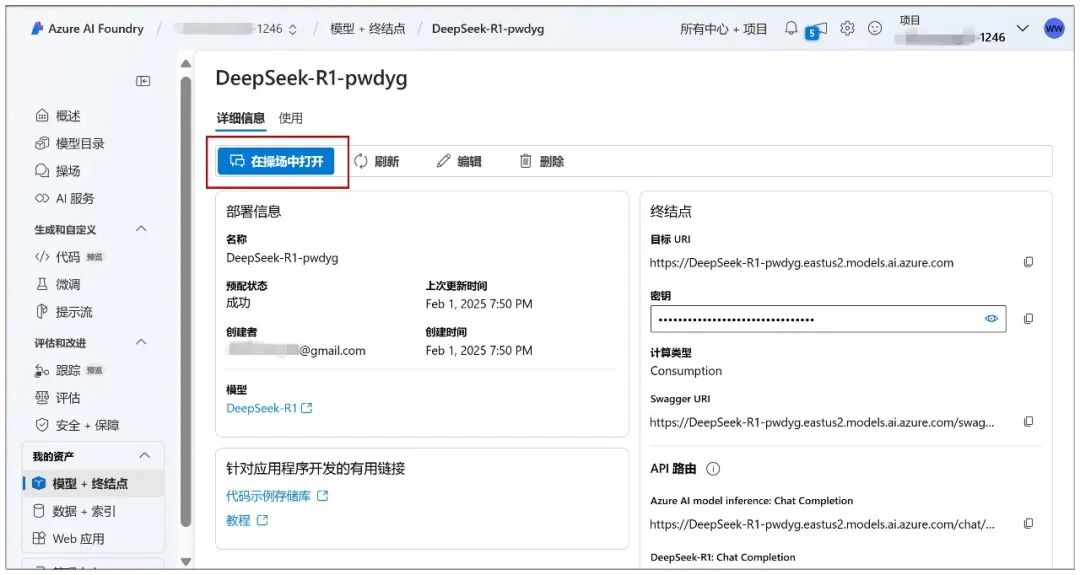
Fahren Sie auf dieser Seite fort, indem Sie auf "Deployment" und dann auf "Open in Playground" klicken:
Dann kann der Dialog beginnen:
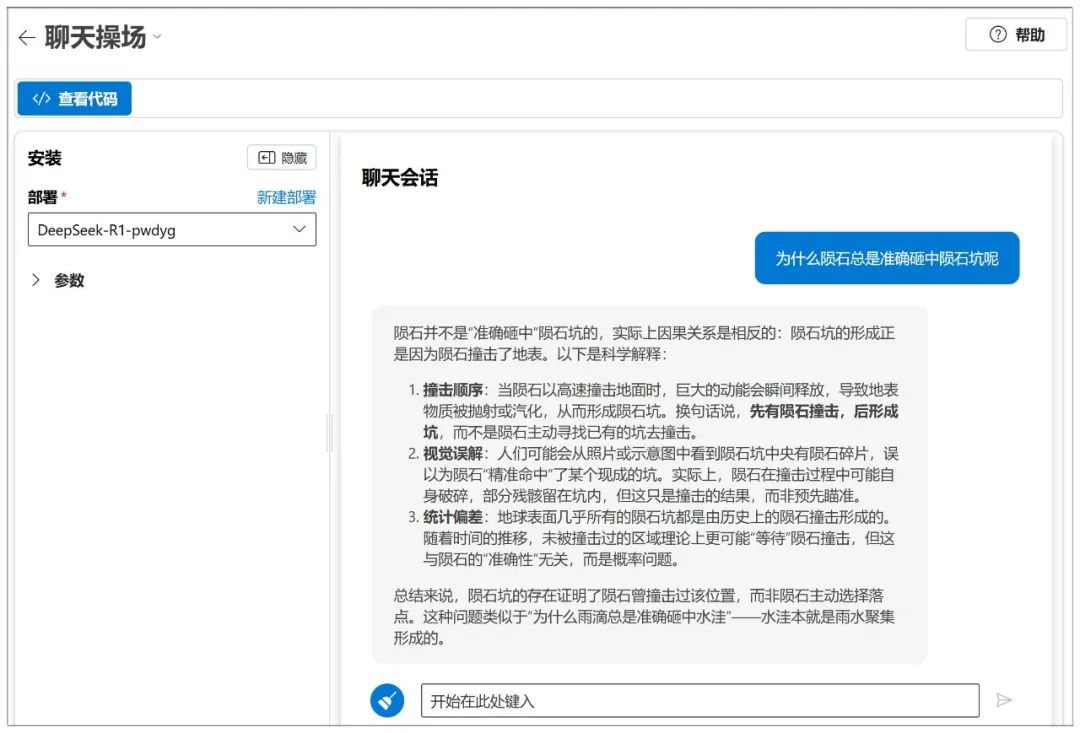
Azure verfügt auch über eine NIM-ähnliche Parametereinstellung:
Als Plattform gibt es viele Modelle, die eingesetzt werden können:
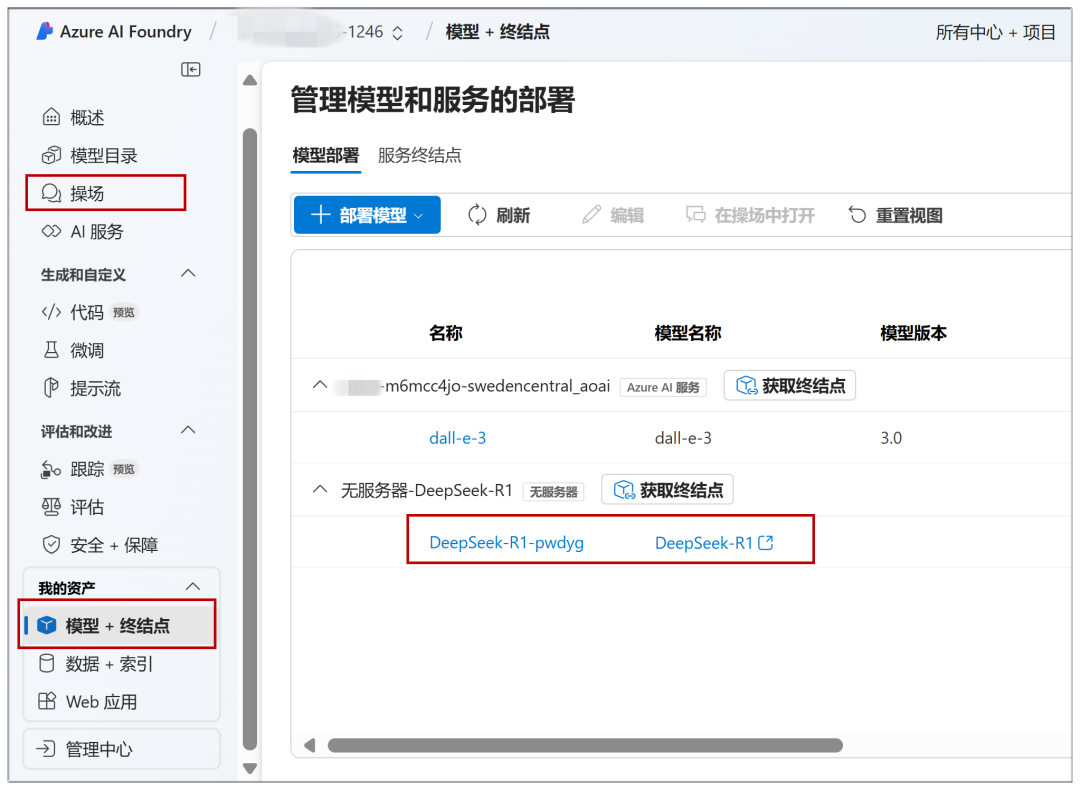
Auf bereits eingesetzte Modelle kann in Zukunft über "Playground" oder "Model + Endpoint" im linken Menü schnell zugegriffen werden:
III. Amazon AWS
Website:
https://aws.amazon.com/cn/blogs/aws/deepseek-r1-models-now-available-on-aws
Der DeepSeek-R1 ist ebenfalls an prominenter Stelle zu sehen und aufgereiht.

Amazon AWS Registrierungsprozess und Microsoft Azure ist fast so mühsam, müssen beide in der Zahlungsmethode zu füllen, sondern auch Telefon Verifizierung + Stimme Überprüfung, hier wird nicht im Detail zu beschreiben:
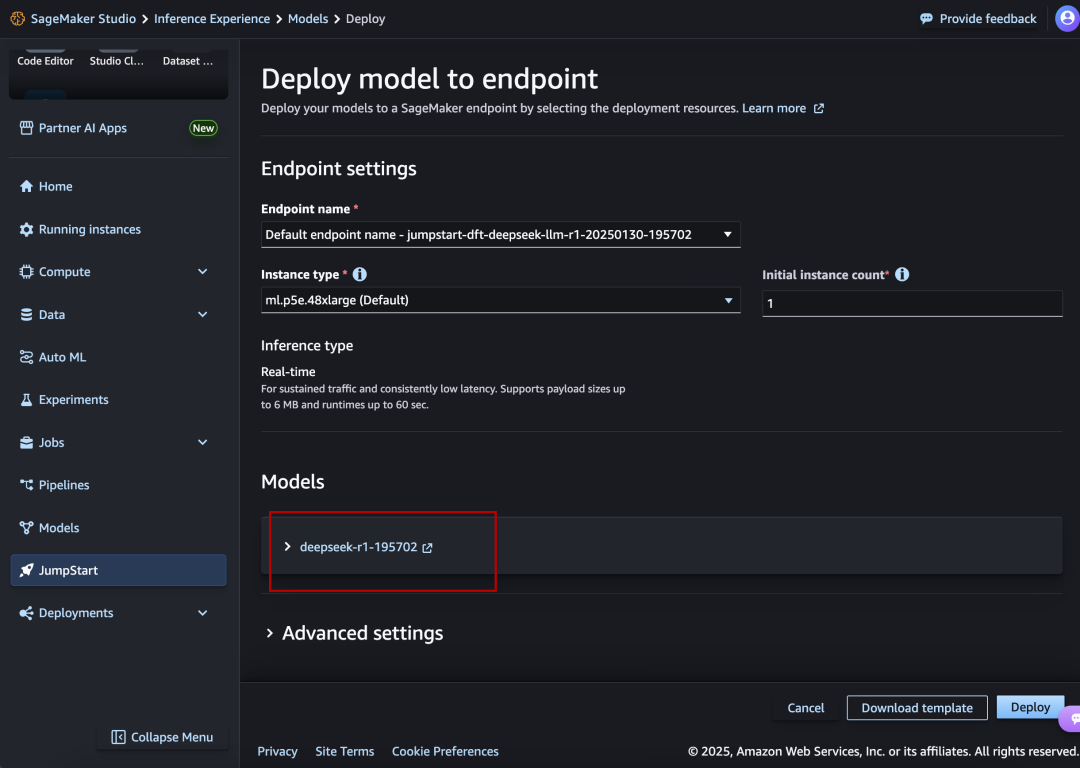
Der genaue Bereitstellungsprozess ist ähnlich wie bei Microsoft Azure:
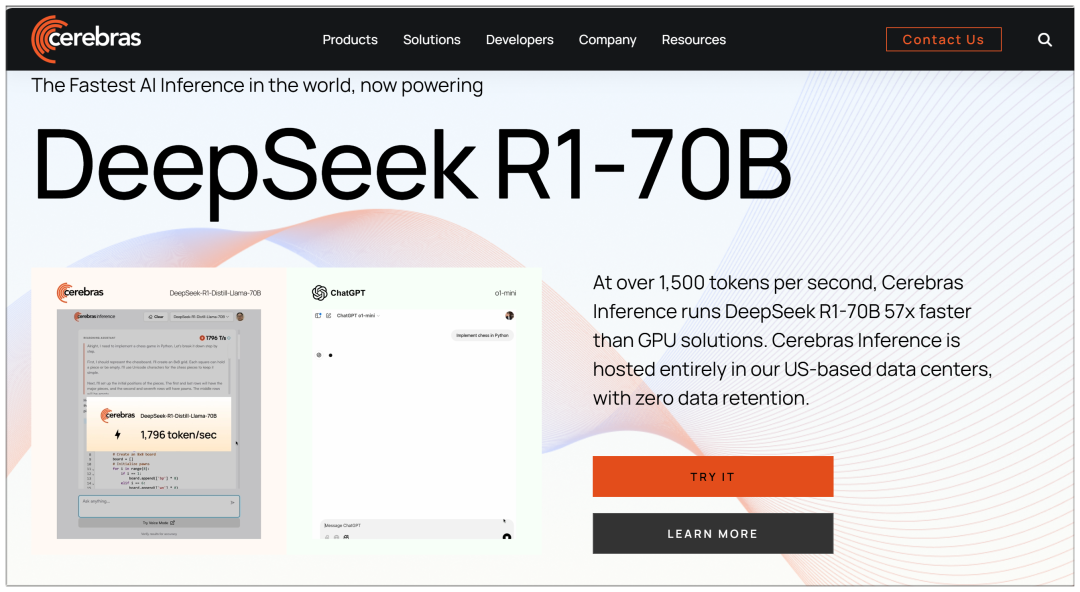
IV. Zerebralien
Cerebras: die weltweit schnellste KI-Inferenz- und High-Performance-Computing-Plattform auf dem Markt
Website: https://cerebras.ai
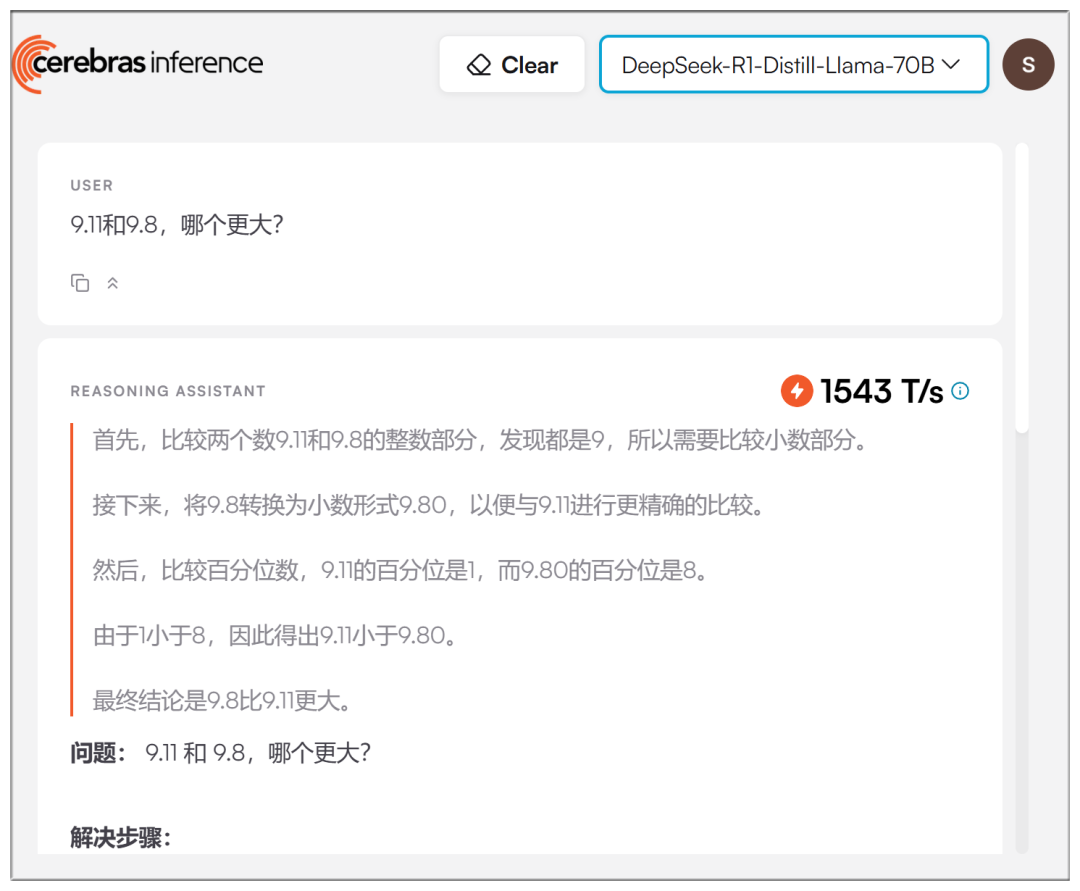
Im Gegensatz zu mehreren großen Plattformen verwendet Cerebras ein 70b-Modell und behauptet, "57 Mal schneller als GPU-Lösungen" zu sein:
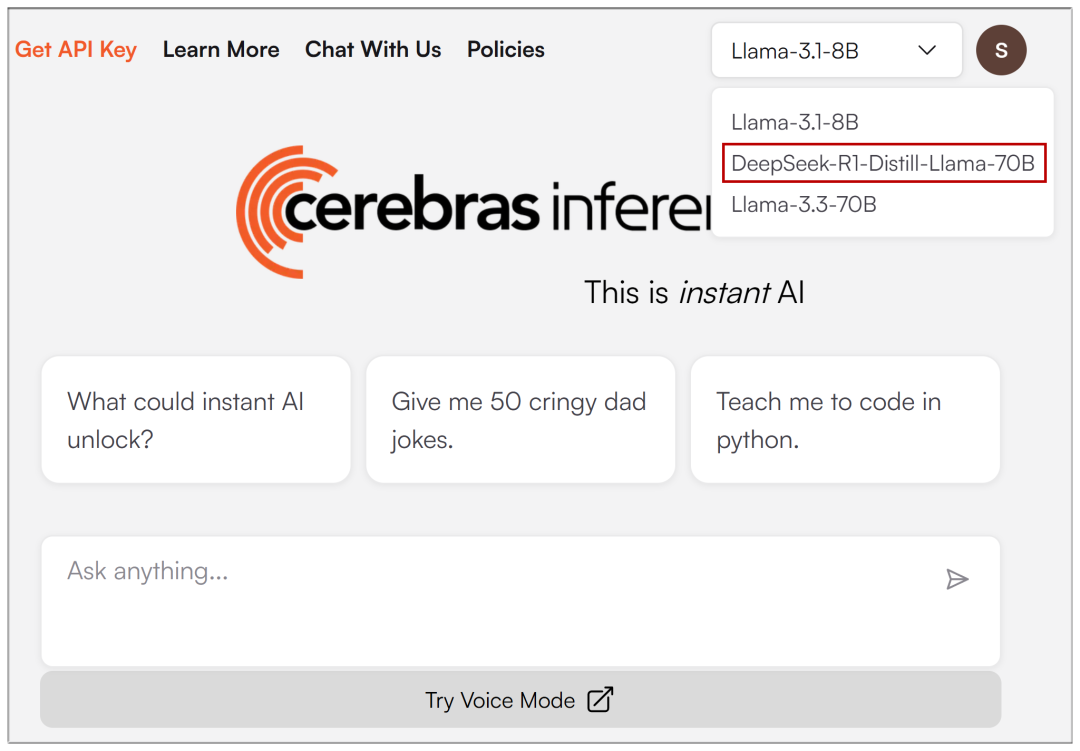
Sobald die E-Mail-Registrierung eingegeben ist, können Sie im Dropdown-Menü oben DeepSeek-R1 auswählen:
Die realen Geschwindigkeiten sind tatsächlich schneller, wenn auch nicht so übertrieben wie behauptet:
V. Groq
Groq: Anbieter von Lösungen zur Beschleunigung von KI-Big-Model-Inferenzen, kostenlose Hochgeschwindigkeitsschnittstelle für Big Models
Website: https://groq.com/groqcloud-makes-deepseek-r1-distill-llama-70b-available

Sobald die E-Mail registriert und eingegeben ist, stehen auch Modelle zur Auswahl:

Es ist auch schnell, aber auch hier fühlt sich 70b ein bisschen zurückgebliebener an als die Cerebras?
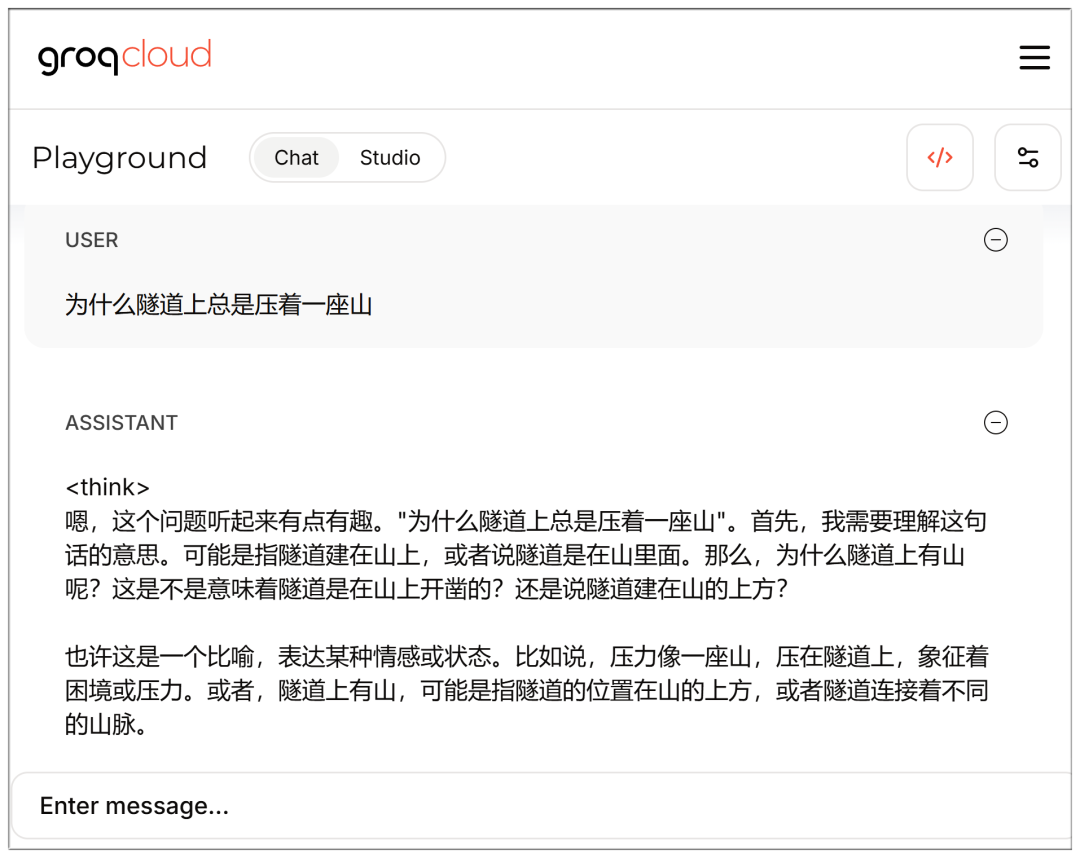
Beachten Sie, dass Sie direkt auf die Chat-Schnittstelle zugreifen können, wenn Sie eingeloggt sind:
https://console.groq.com/playground?model=deepseek-r1-distill-llama-70b
Vollständige DeepSeek V3 und R1 Liste:
AMD
AMD Instinct™ GPUs treiben DeepSeek-V3 an: Revolutionierung der KI-Entwicklung mit SGLang (AMD Instinct™ GPUs treiben DeepSeek-V3 an: Revolutionierung der KI-Entwicklung mit SGLang)
NVIDIA
DeepSeek-R1 NVIDIA-Modellkarte (DeepSeek-R1 NVIDIA-Modellkarte)
Microsoft Azure
Ausführung von DeepSeek-R1 auf einer einzelnen NDv5 MI300X-VM (Ausführung von DeepSeek-R1 auf einer einzelnen NDv5 MI300X VM)
Baseten
https://www.baseten.co/library/deepseek-v3/
Novita AI
Novita AI verwendet SGLang mit DeepSeek-V3 für OpenRouter (Novita AI verwendet SGLang zur Ausführung von DeepSeek-V3 für OpenRouter)
ByteDance Volcengine
Das DeepSeek-Modell in Originalgröße landet auf der Volcano Engine!
DataCrunch
Einsatz von DeepSeek-R1 671B auf 8x NVIDIA H200 mit SGLang (Einsatz von DeepSeek-R1 671B auf 8x NVIDIA H200 mit SGLang)
Hyperbolisch
https://x.com/zjasper666/status/1872657228676895185
Vultr
Einsatz des Deepseek V3 Large Language Model (LLM) mit SGLang (Wie man mit SGLang einsetzt) Deepseek V3 Large Language Modelling (LLM))
RunPod
Was ist neu für die serverlose LLM-Nutzung in RunPod im Jahr 2025? (Welche neuen Funktionen werden von Serverless LLM in RunPod im Jahr 2025 genutzt?)
© urheberrechtliche Erklärung
Artikel Copyright AI-Austauschkreis Alle, bitte nicht ohne Erlaubnis vervielfältigen.
Ähnliche Artikel



Keine Kommentare...