
2025 AI Agent Landing Outlook: eine Analyse der drei Elemente Planung, Interaktion und Gedächtnis

KI-Agenten werden zu einem viel erwarteten Paradigmenwechsel im sich schnell entwickelnden KI-Technologiebereich. AI Share, eine führende Organisation zur Bewertung von KI-Technologien, hat sich kürzlich eingehend mit dem Trend zu KI-Agenten befasst und verweist auf eine Reihe ausführlicher Artikel, die vom Langchain-Team veröffentlicht wurden, um den Lesern ein besseres Verständnis der Zukunft von Agenten zu vermitteln.
Dieser Artikel fasst die wichtigsten Ergebnisse des von Langchain veröffentlichten Berichts "State of AI Agent" zusammen, für den mehr als 1.300 Fachleute aus der Branche befragt wurden, darunter Entwickler, Produktmanager, Führungskräfte und andere Rollen. Die Ergebnisse zeigen den aktuellen Stand der Entwicklung von KI-Agenten und die Engpässe im Jahr 2024: Obwohl 90 % der Unternehmen aktiv KI-Agenten planen und einsetzen, können die Anwender Agenten aufgrund der Grenzen ihrer derzeitigen Fähigkeiten nur in bestimmten Prozessen und Anwendungsszenarien einsetzen. Die Menschen sind mehr daran interessiert, die Fähigkeiten von Agenten und die Beobachtbarkeit und Zuverlässigkeit ihres Verhaltens zu verbessern, als an Faktoren wie Kosten und Latenzzeiten. Die Beobachtbarkeit und Kontrollierbarkeit des Agentenverhaltens ist wichtiger als Kosten und Latenzzeiten.
Darüber hinaus enthält dieser Artikel eine eingehende Analyse der Schlüsselelemente des KI-Agenten aus der Reihe "In the Loop" auf der offiziellen Website von LangChain, wobei der Schwerpunkt auf den Planung, UI/UX, interaktive Innovation und Gedächtnis. Diese drei Kernelemente. In dem Artikel werden fünf Interaktionsmuster von Muttersprachlern auf der Grundlage von Large Language Models (LLMs) eingehend analysiert und drei komplexe Gedächtnismechanismen des Menschen analogisiert, um den Lesern nützliche Einblicke in das Wesen und die Schlüsselelemente von KI-Agenten zu vermitteln. Um näher an der industriellen Praxis zu sein, enthält dieser Artikel auch die Analyse der Schlüsselelemente im Abschnitt Reflexion Anhand von Interviews mit KI-Gründern und anderen Beispielen aus erster Hand wird ein Ausblick auf die wichtigsten Durchbrüche gegeben, die KI-Agenten im Jahr 2025 erreichen könnten.
Auf der Grundlage des oben beschriebenen Analyserahmens geht AI Share davon aus, dass KI-Agentenanwendungen im Jahr 2025 ein explosionsartiges Wachstum erfahren und sich allmählich zu einem neuen Paradigma der Mensch-Computer-Zusammenarbeit entwickeln werden. Was die Planungsfähigkeit von KI-Agenten betrifft, so zeigen die aufkommenden Modelle, die durch das o3-Modell repräsentiert werden, starke Reflexions- und Schlussfolgerungsfähigkeiten, was darauf hindeutet, dass sich die Entwicklung der Modelltechnologie schnell von der Reasoner- zur Agentenphase entwickelt. Mit der kontinuierlichen Verbesserung der Denkfähigkeit wird es von der Innovation der Produktinteraktion und des Speichermechanismus abhängen, ob KI-Agenten wirklich in großem Maßstab landen können, was auch eine wichtige Gelegenheit für Startups sein wird, sich zu differenzieren und einen Durchbruch zu erzielen. Auf der Interaktionsebene freut sich die Branche auf eine Revolution der Mensch-Computer-Interaktion, ähnlich dem "GUI-Moment" in der KI-Ära; auf der Speicherebene wird der Kontext zum zentralen Schlüsselwort für die Landung von Agenten, sei es die Kontext-Personalisierung auf individueller Ebene oder die Kontextvereinheitlichung auf Unternehmensebene. Context (Kontext) wird zum zentralen Schlüsselwort für Agent Landing, ob es sich nun um Personalisierung auf individueller Ebene oder Vereinheitlichung auf Unternehmensebene handelt.
01 Stand der KI-Agenten: Aktueller Stand der KI-Agentenentwicklung
Trends bei der Einführung von Agenten: Jedes Unternehmen plant aktiv den Einsatz von Agenten
Der Wettbewerb im Bereich der Agenten wird von Tag zu Tag härter. Im vergangenen Jahr sind viele beliebte Agent-Frameworks aufgetaucht. Zum Beispiel die ReAct Rahmen, der LLM für logisches Denken und Handeln, Aufgabenorchestrierung unter Verwendung des Multi-Agent-Rahmens und Methoden wie die LangGraph Dies ist ein besser zu handhabender Rahmen.
Die Begeisterung für Agenten hört nicht bei den sozialen Medien auf. Laut der Studie setzen rund 51% der befragten Unternehmen bereits Agenten in ihren Produktionsumgebungen ein. Die Studie von Langchain schlüsselt die Daten auch nach Unternehmensgröße auf und zeigt, dass mittelgroße Unternehmen mit 100-2.000 Mitarbeitern mit satten 63% die aktivsten Agent-Produktionsimplementierungen sind.
Darüber hinaus gaben 78% der Befragten an, dass sie planen, in naher Zukunft Agenten in ihren Produktionsumgebungen einzusetzen. Dies zeigt deutlich, dass branchenübergreifend ein starkes Interesse an KI-Agenten besteht, aber wie lässt sich eine echte produktionsreif (für den Einsatz in Produktionsumgebungen) Agent, bleibt für viele Unternehmen eine Herausforderung.
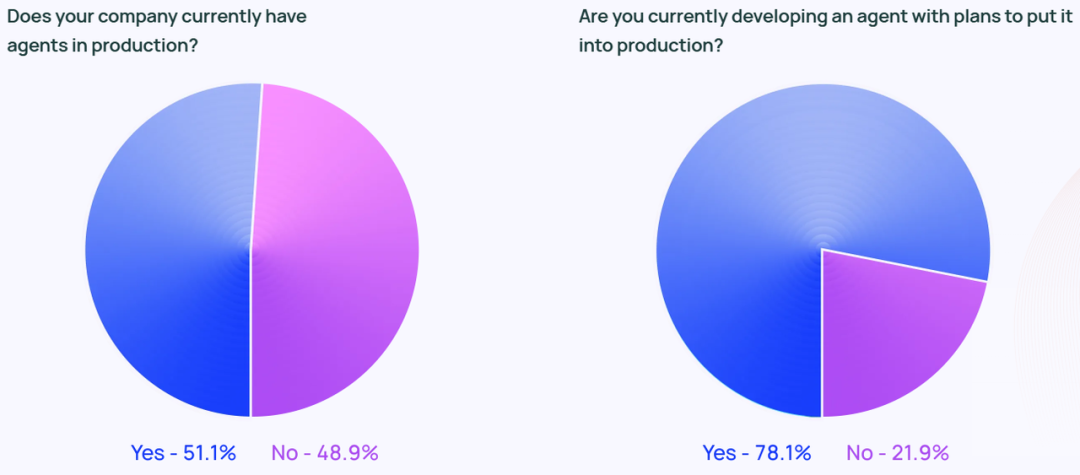
Obwohl die Technologiebranche oft als Vorreiter der Agententechnologie angesehen wird, wächst das Interesse an Agenten in allen Branchen rasch. Von den Befragten, die in Unternehmen außerhalb der Technologiebranche tätig sind, haben 90% der Organisationen Agenten in ihren Produktionsumgebungen eingesetzt oder planen dies, das ist fast derselbe Prozentsatz wie bei Technologieunternehmen (89%).
Anwendungsfall des Agenten
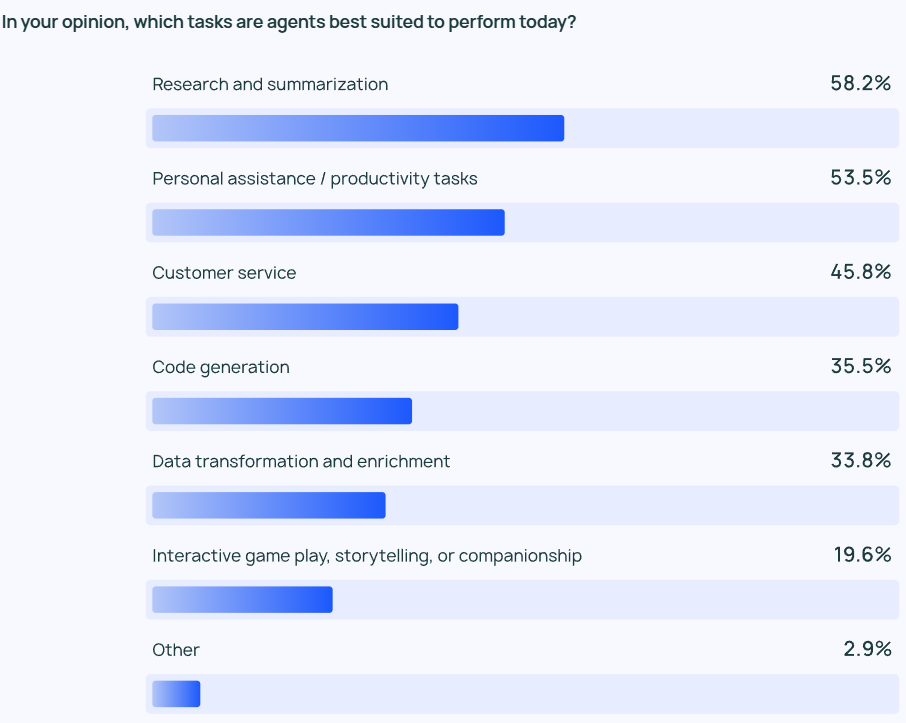
Die Ergebnisse der Untersuchung zeigen, dass der häufigste Agent Anwendungsfall (Anwendungsszenario) einschließlich Informationsrecherche und Inhaltszusammenfassung (58%), gefolgt von der Rationalisierung der Arbeitsabläufe durch maßgeschneiderte Agenten (53,5%).
Dies spiegelt die Tatsache wider, dass die Nutzer von Agentenprodukten erwarten, dass sie ihnen bei zeit- und arbeitsintensiven Aufgaben helfen. Die Nutzer können sich darauf verlassen, dass KI-Agenten schnell wichtige Informationen und Erkenntnisse aus großen Informationsmengen extrahieren, anstatt selbst große Datenmengen zu sichten und Datenprüfungen oder Forschungsanalysen durchzuführen. Ebenso können KI-Agenten bei alltäglichen Aufgaben helfen, die persönliche Produktivität steigern und es den Nutzern ermöglichen, sich auf wichtigere Aspekte ihrer Arbeit zu konzentrieren.
Nicht nur einzelne Benutzer, sondern auch Organisationen und Teams brauchen Effizienzsteigerungen. Der Kundendienst (45,8%) ist ein weiterer wichtiger Anwendungsbereich für Agenten. Agenten helfen Unternehmen bei der Bearbeitung von Kundenanfragen, bei der Lösung von Problemen und bei der Verkürzung der teamübergreifenden Reaktionszeiten auf Kundenanfragen. Die viert- und fünftbeliebtesten Anwendungsszenarien sind eher Low-Level-Code und Datenverarbeitung.
Überwachung: Agentenanwendungen müssen beobachtbar und kontrollierbar sein.
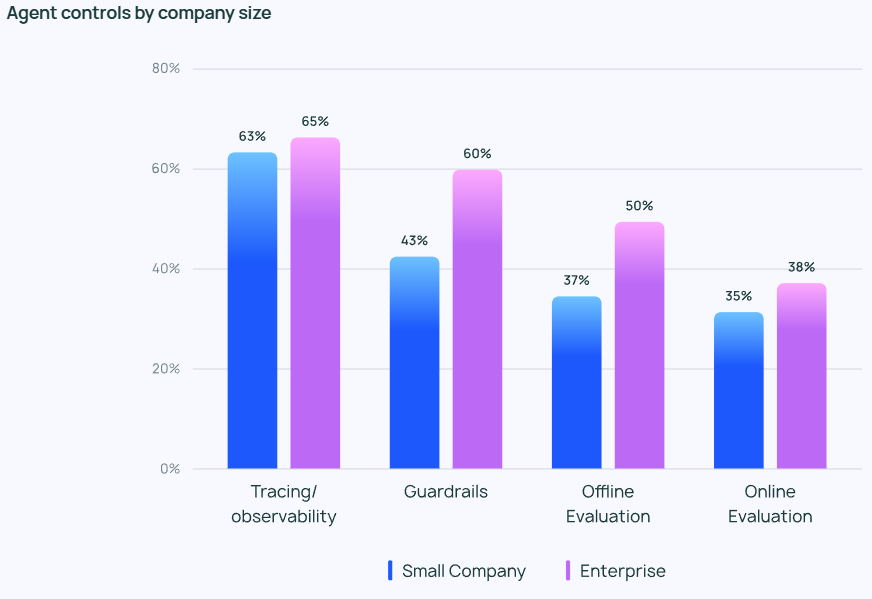
Da Agenten immer leistungsfähiger werden, ist es von entscheidender Bedeutung, ihr Verhalten effektiv zu verwalten und zu überwachen. Tracking- und Beobachtungstools werden zu einer unverzichtbaren Option im Agententechnologie-Stack eines Unternehmensanwenders und helfen den Entwicklern, Einblicke in das Verhalten und die Leistung von Agenten zu gewinnen. Viele Unternehmen verwenden auch Leitplanke um zu verhindern, dass das Verhalten des Agenten von der vordefinierten Spur abweicht.
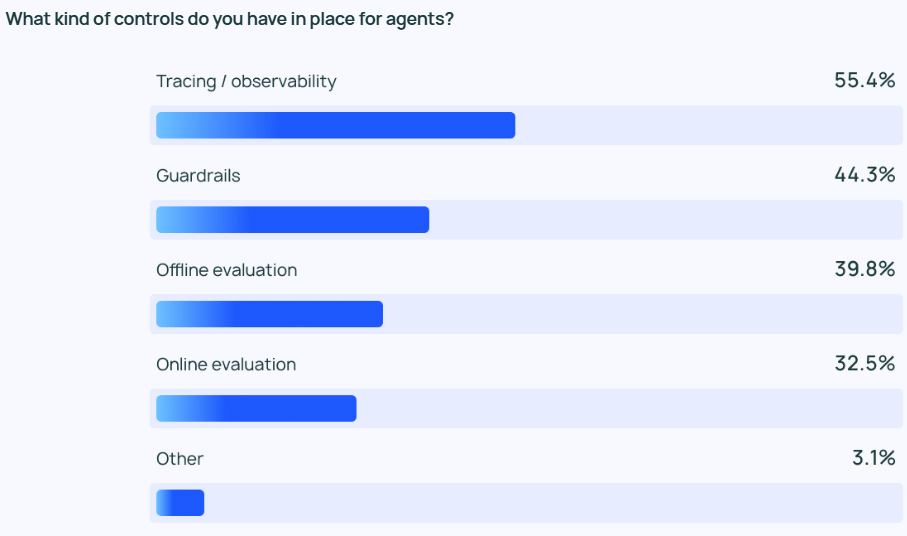
Bei der Prüfung von LLM-Anwendungen ist dieOffline-Auswertung (39,8%) wurde häufiger verwendet als die Online-Auswertung (32,5%), was die vielen Herausforderungen widerspiegelt, die sich bei der Überwachung von LLM in Echtzeit noch stellen. In den Antworten auf den offenen Fragebogen von LangChain gaben viele Unternehmen an, dass sie die Ergebnisse von Agentenantworten als zusätzliche Sicherheitsebene auch von menschlichen Experten manuell überprüfen oder bewerten lassen würden.
Trotz der Begeisterung für Agenten sind die Menschen im Allgemeinen konservativ, wenn es um die Kontrolle der Rechte von Agenten geht. Nur wenige der Befragten erlauben Agenten das freie Lesen, Schreiben und Löschen. Stattdessen gewähren die meisten Teams den Agenten nur "Nur-Lese"-Berechtigungen oder verlangen eine manuelle Genehmigung, wenn Agenten riskantere Operationen wie Schreiben oder Löschen durchführen.
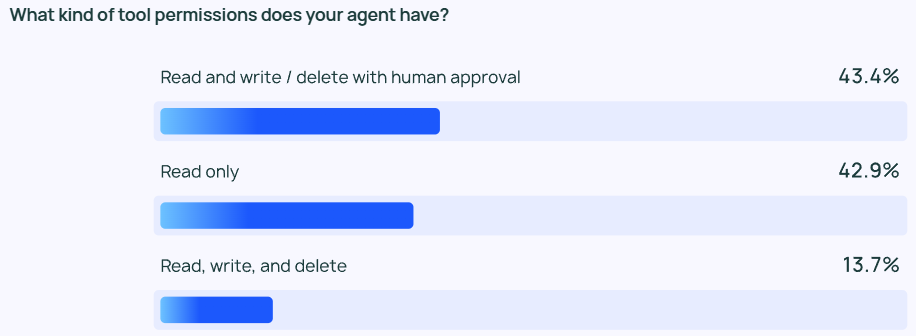
Der Schwerpunkt der Agentenkontrollen variiert je nach Größe des Unternehmens. Größere Organisationen (über 2.000 Mitarbeiter) sind oft vorsichtiger und verlassen sich stark auf "Nur-Lese"-Berechtigungen, um unnötige Risiken zu minimieren. Sie neigen auch dazu, die Leitplanke In Verbindung mit Offline-Bewertungen wird versucht, Probleme zu vermeiden, die sich negativ auf den Kunden auswirken könnten.
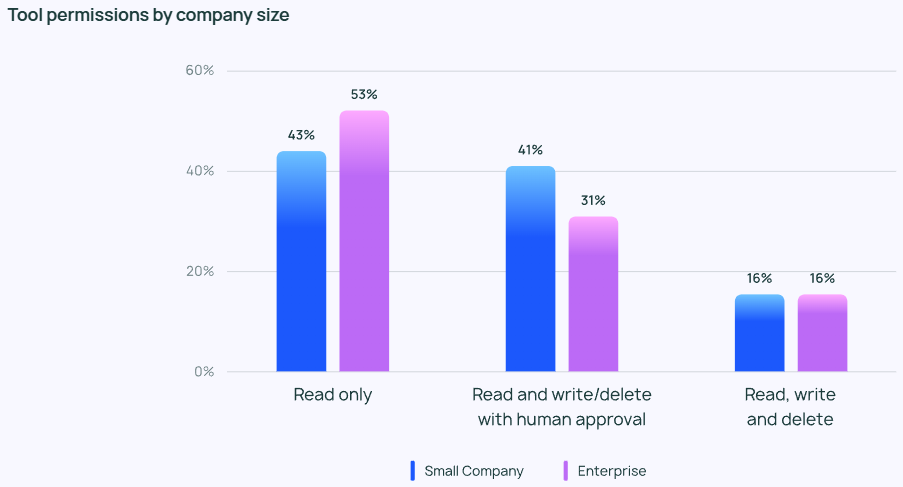
Kleinere Unternehmen und Start-ups (mit weniger als 100 Mitarbeitern) sind dagegen eher an der Überwachung von Agenten interessiert, um einen Einblick in die tatsächliche Leistung ihrer Agentenanwendungen zu erhalten (und weniger an anderen Kontrollen). Die Untersuchungen von LangChain zeigen, dass kleinere Unternehmen dazu neigen, Daten zu analysieren, um die Ergebnisse zu verstehen, während sich größere Organisationen auf den Aufbau eines ganzheitlichen Kontrollsystems konzentrieren.
Hindernisse und Herausforderungen bei der Einführung von Agenten in die Produktion
Sicherstellen, dass LLM-Ergebnisse von hoher Qualität sind Leistung bleibt eine anspruchsvolle Aufgabe. Die Antworten der Agenten müssen nicht nur sehr genau sein, sondern auch stilistisch korrekt. Dies ist ein Hauptanliegen der Agentenentwickler, mehr als doppelt so wichtig wie andere Faktoren wie Kosten und Sicherheit.
Der LLM-Agent ist im Wesentlichen ein wahrscheinlichkeitsbasiertes Inhaltsausgabemodell, was bedeutet, dass seine Ausgabe in gewisser Weise unvorhersehbar ist. Diese Unvorhersehbarkeit erhöht die Fehlerwahrscheinlichkeit und macht es für das Entwicklungsteam schwierig, sicherzustellen, dass der Agent durchgängig genaue und kontextbezogene Antworten liefert.
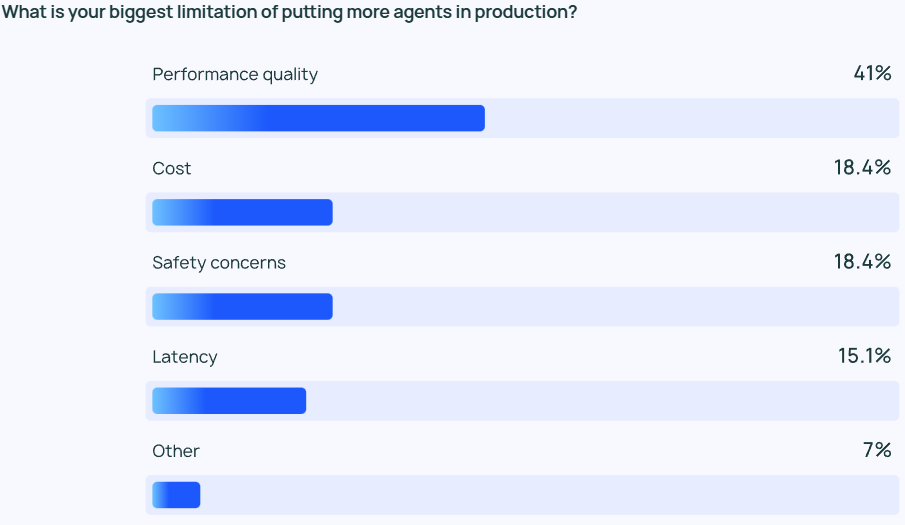
Für kleinere UnternehmenQualität der Leistung Dies ist besonders wichtig, da 45,81 TP3T der kleineren Unternehmen dies als wichtigstes Anliegen einstufen, gegenüber 22,41 TP3T für die Kosten (das zweitwichtigste Anliegen). Diese Diskrepanz unterstreicht die Tatsache, dass eine zuverlässige, qualitativ hochwertige Leistung von entscheidender Bedeutung ist, wenn es darum geht, den Übergang von Agenten aus der Entwicklungsphase in die Produktionsphase eines Unternehmens zu fördern.
Sicherheit ist auch für große Unternehmen von entscheidender Bedeutung, die strenge Compliance-Anforderungen einhalten und mit Kundendaten sorgfältig umgehen müssen.
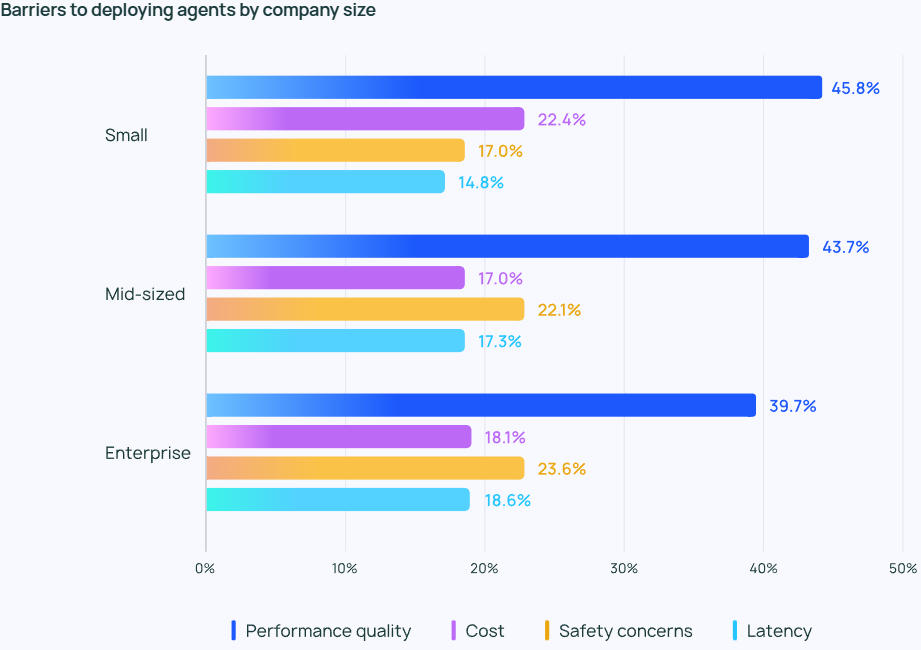
Aus den Antworten auf den offenen Fragebogen von LangChain ging hervor, dass viele Unternehmen noch immer Vorbehalte haben, in die Entwicklung und Erprobung von Agenten zu investieren. Zwei wesentliche Hindernisse wurden häufig genannt: Erstens erfordert die Entwicklung von Agenten ein hohes Maß an Fachwissen und die Notwendigkeit, ständig die neuesten Technologien zu verfolgen, und zweitens ist der Zeitaufwand für die Entwicklung und den Einsatz eines Agenten hoch, aber es besteht immer noch Ungewissheit darüber, ob er zuverlässig arbeiten und die erwarteten Vorteile bringen kann.
Andere aufkommende Themen
In der offenen Fragerunde bewerteten die Befragten den KI-Agenten vor allem wegen seiner folgenden Fähigkeiten:
- Verwaltung von Mehrschrittaufgaben. Der KI-Agent ist in der Lage, tiefer gehende Überlegungen anzustellen und den Kontext zu verwalten, so dass er komplexere Aufgaben erfüllen kann.
- Automatisierung von sich wiederholenden Aufgaben. Der KI-Agent gilt nach wie vor als wichtiges Werkzeug für die Erledigung automatisierter Aufgaben, das den Nutzern hilft, ihre Zeit für kreativere Arbeiten zu nutzen.
- Einsatzplanung und Zusammenarbeit. Bessere Fähigkeiten zur Aufgabenplanung stellen sicher, dass der richtige Agent zur richtigen Zeit am richtigen Problem arbeitet, was besonders in Multi-Agent-Systemen wichtig ist.
- Menschenähnliches Denken. Im Gegensatz zu herkömmlichen LLMs kann ein KI-Agent seinen Entscheidungsprozess nachvollziehen und dabei auch frühere Entscheidungen auf der Grundlage neuer Informationen überprüfen und revidieren.
Darüber hinaus nannten die Befragten zwei zentrale Erwartungen an die Zukunft der KI-Agenten:
- Was Sie von einem Open-Source-KI-Agenten erwarten können. Das Interesse an quelloffenen KI-Agenten ist groß, und viele glauben, dass kollektive Intelligenz das Innovationstempo der Agententechnologie beschleunigen kann.
- Erwartungen an leistungsfähigere Modelle. Viele freuen sich auf den nächsten Sprung nach vorn für KI-Agenten, die von größeren, leistungsfähigeren Modellen angetrieben werden, wenn Agenten in der Lage sein werden, komplexere Aufgaben mit größerer Effizienz und Autonomie zu bewältigen.
In der Fragerunde erwähnten viele Befragte auch die größte Herausforderung bei der Agentenentwicklung: das Verständnis des Agentenverhaltens. Einige Ingenieure sagten, dass sie Schwierigkeiten hatten, das Verhalten des Agenten zu verstehen, wenn sie ihn dem Unternehmen vorstellten. Stakeholder Sie haben Schwierigkeiten, die Fähigkeiten und das Verhalten eines KI-Agenten zu erklären. Während Visualisierungs-Plug-ins das Verhalten des Agenten bis zu einem gewissen Grad erklären können, bleibt LLM in den meisten Fällen eine "Black Box". Die zusätzliche Last der Interpretierbarkeit liegt nach wie vor beim Entwicklungsteam.
02 Analyse der Kernelemente eines KI-Agenten
Vor der Veröffentlichung des State of AI Agent-Berichts hatte das Langchain-Team bereits den Agentenraum auf der Grundlage des von ihnen entwickelten Langraph-Frameworks erforscht und mehrere Artikel zur Analyse der Schlüsselkomponenten eines KI-Agenten über den In the Loop-Blog veröffentlicht. In diesem Artikel fassen wir die wichtigsten Inhalte der In the Loop Artikelserie zusammen und analysieren die Schlüsselelemente des Agenten im Detail.
Um die Kernelemente eines Agenten besser verstehen zu können, müssen wir zunächst ein besseres Verständnis für die Agentisches System Definition. LangChain-Gründer Harrison Chase gibt die folgende Definition eines KI-Agenten:
💡
AI Agent ist ein System, das LLM verwendet, um Entscheidungen über den Kontrollfluss von Anwendungen zu steuern.
Ein KI-Agent ist ein System, das ein LLM verwendet, um den Kontrollfluss einer Anwendung zu bestimmen.
In Bezug auf die Art und Weise, wie der Agent eingesetzt wird, stellt der Artikel die Kognitive Architektur Das Konzept. kognitive Architektur Es geht darum, wie der Agent denkt und wie das System den Code oder die Prompts orchestriert, die das LLM steuern. Das Verständnis der kognitiven Architektur hilft uns, einen Einblick in die Arbeitsweise des Agenten zu gewinnen:
- Kognitiv. Der Agent verwendet das LLM für semantische Schlussfolgerungen, um zu bestimmen, wie das LLM zu kodieren oder aufzufordern ist.
- Architektur. Agentensysteme beinhalten immer noch viele technische Verfahren, die denen traditioneller Systemarchitekturen ähneln.
Das nachstehende Diagramm zeigt die verschiedenen Ebenen der Kognitive Architektur Beispiel:
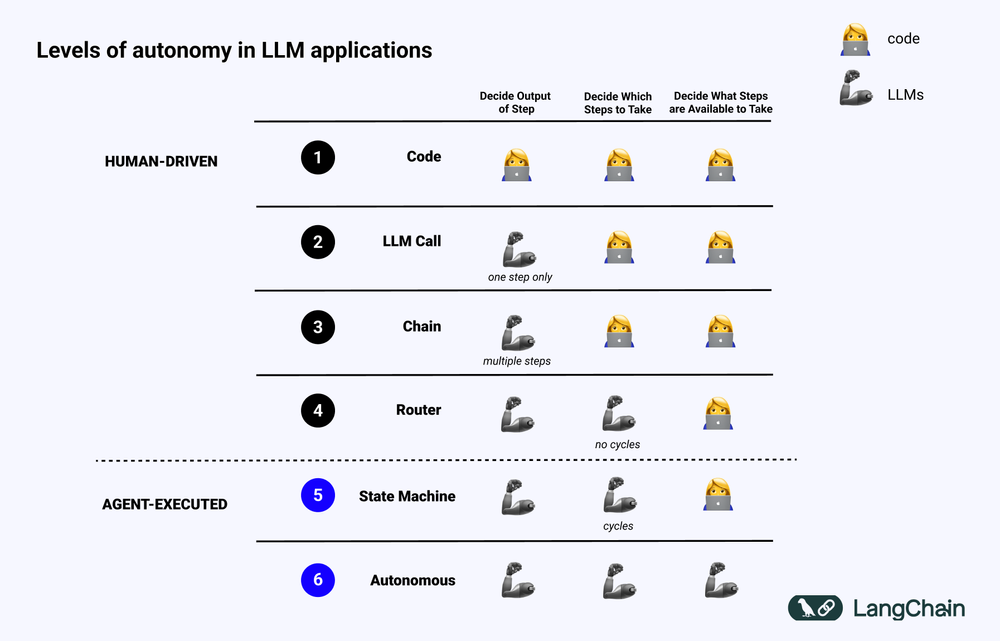
- Standardisierter Software-Code (Code). Alle Logik ist Harter Code Bei der Implementierung werden die Eingabe- und Ausgabeparameter direkt im Quellcode verankert. Dieser Ansatz stellt keine kognitive Architektur dar, da es keine kognitiv Teil.
- LLM-Aufruf. Mit Ausnahme einer kleinen Menge an Datenvorverarbeitung beruht der Großteil der Funktionalität einer Anwendung auf einem einzigen LLM-Aufruf. Ein einfacher Chatbot fällt normalerweise in diese Kategorie.
- Kette. Eine Reihe von LLM-Aufrufen, bei denen Chain versucht, ein komplexes Problem in Schritte zu zerlegen und verschiedene LLMs aufzurufen, um sie nacheinander zu lösen. Das komplexe RAG (Search Enhanced Generation)-Systeme fallen in diese Kategorie: Der erste LLM wird beispielsweise zur Suche und Abfrage aufgerufen, der zweite LLM zur Generierung der Antwort.
- Router. In allen drei Systemen kennt der Benutzer alle Schritte, die das Programm ausführen wird, im Voraus. In der Router-Architektur kann der LLM jedoch selbständig entscheiden, welche LLMs er aufruft und welche Schritte er durchführt. Dies erhöht die Zufälligkeit und Unvorhersehbarkeit des Systems.
- Zustandsmaschine. Durch die Kombination des LLM mit dem Router wird die Unvorhersehbarkeit des Systems weiter erhöht. Da diese Kombination eine Schleife bildet, kann das System den LLM theoretisch unendlich oft aufrufen.
- Agentisches System. Oft auch bezeichnet als "Autonomer Agent (Autonomer Agent)" Bei der Verwendung eines Zustandsautomaten gibt es immer noch Beschränkungen für die Operationen, die das System ausführen kann, und für die Prozesse, die ihnen folgen. Bei der Verwendung eines Zustandsautomaten gibt es immer noch einige Einschränkungen in Bezug auf die Operationen, die das System durchführen kann, und den Ablauf nach der Durchführung der Operationen. Bei der Verwendung eines autonomen Agenten werden diese Einschränkungen jedoch aufgehoben. Der LLM hat volle Autonomie bei der Entscheidung, welche Schritte zu unternehmen sind und wie die verschiedenen LLMs zu programmieren sind, was durch die Verwendung von verschiedenen Prompts, Tools oder Code erreicht werden kann.
Kurz gesagt, je mehr ein System "Agentisch" Je mehr das LLM bei der Bestimmung des Systemverhaltens eine Rolle spielt, desto größer ist die Rolle des LLM bei der Bestimmung des Systemverhaltens.
Schlüsselelemente des Agenten: Planungsfähigkeit
Die Zuverlässigkeit von Agenten ist ein Problem in der derzeitigen Anwendungspraxis. Viele Unternehmen haben Agenten auf der Grundlage von LLM entwickelt, geben aber die Rückmeldung, dass die Planungs- und Schlussfolgerungsfähigkeiten der Agenten unzureichend sind. Was bedeutet also die Planungs- und Schlussfolgerungsfähigkeit von Agenten?
Agent's Planung im Gesang antworten Begründungen Kompetenz, die sich auf die Fähigkeit von LLM bezieht, zu denken und Entscheidungen darüber zu treffen, welche Maßnahmen ergriffen werden sollten. Dies beinhaltet sowohl kurzfristige als auch langfristige Argumentation . LLM muss alle verfügbaren Informationen auswerten und dann entscheiden: Welche Schritte muss ich unternehmen, um mein Endziel zu erreichen? Was ist der wichtigste erste Schritt, den ich zu diesem Zeitpunkt unternehmen muss?
In der Praxis verwenden die Entwickler in der Regel Funktionsaufruf Technik, die es dem LLM ermöglicht, die auszuführende Aktion auszuwählen. Funktionsaufruf ist eine Funktion, die der LLM-API erstmals im Juni 2023 von OpenAI hinzugefügt wurde. Mit dem Funktionsaufruf können Benutzer JSON-Strukturen für verschiedene Funktionen bereitstellen und LLM eine (oder mehrere) dieser Strukturen abgleichen lassen.
Um eine komplexe Aufgabe erfolgreich abzuschließen, muss ein Agentensystem in der Regel eine Reihe von Vorgängen nacheinander ausführen. Langfristige Planung und Argumentation Eine sehr komplexe Herausforderung für den LLM: Erstens muss der LLM eine langfristige Aktionsplanung in Betracht ziehen und diese dann auf die kurzfristigen Aktionen abstimmen, die im Moment ergriffen werden müssen; zweitens werden, während der Agent mehr und mehr Operationen durchführt, die Ergebnisse der Operationen kontinuierlich an den LLM zurückgemeldet, was zu einer kontinuierlichen Vergrößerung des Kontextfensters führt, was dazu führen kann, dass der LLM "abgelenkt wird "und die Leistung verringert.
Der einfachste Weg, die Planungsfähigkeiten zu verbessern, besteht darin, sicherzustellen, dass die LLM über alle Informationen verfügen, die sie benötigen, um vernünftig zu denken und zu planen. Das hört sich einfach an, aber die Realität ist, dass die Informationen, die dem LLM übermittelt werden, oft nicht ausreichen, um ihm zu ermöglichen, vernünftige Entscheidungen zu treffen. Das Hinzufügen eines Suchschritts oder die Optimierung der Eingabeaufforderung kann eine einfache Verbesserung sein.
Wenn Sie noch einen Schritt weiter gehen wollen, sollten Sie die Anpassung der kognitive Architektur . Es gibt zwei Haupttypen von kognitiven Architekturen, die zur Verbesserung der Argumentationsfähigkeit des Agenten eingesetzt werden können: Generische kognitive Architektur im Gesang antworten Bereichsspezifische kognitive Architekturen.
1. allgemeine kognitive Architektur
Generische kognitive Architektur kann auf eine Vielzahl unterschiedlicher Aufgabenszenarien angewendet werden. Zwei repräsentative generische Architekturen wurden von Wissenschaftlern vorgeschlagen: "Architektur "Planen und Lösen im Gesang antworten Reflexion Architektur.
"Architektur "Planen und Lösen Sie wurde erstmals in dem Papier Plan-and-Solve Prompting: Improving Zero-Shot Chain-of-Thought Reasoning by Large Language Models vorgestellt. Bei dieser Architektur erstellt ein Agent zunächst einen detaillierten Plan und führt dann jeden Schritt des Plans Schritt für Schritt aus.
Reflexion Architektur wurde in dem Papier Reflexion: Language Agents with Verbal Reinforcement Learning vorgestellt. In dieser Architektur führt ein Agent eine Aufgabe aus und fügt dann eine explizite "Reflexion". Schritte, um zu beurteilen, ob ihre Aufgaben korrekt ausgeführt werden. Ohne auf die spezifischen Details dieser beiden Architekturen einzugehen, wird der interessierte Leser auf die beiden oben genannten Originalarbeiten verwiesen.
Obwohl die Architekturen "Planen und Lösen" und "Reflexion" ein gewisses theoretisches Verbesserungspotential aufweisen, sind sie oft zu allgemein, um für den Produktionseinsatz von Agenten nützlich zu sein. (Anmerkung des Übersetzers: Zum Zeitpunkt der Veröffentlichung dieses Papiers war die o1-Modellfamilie noch nicht freigegeben).
2. bereichsspezifische kognitive Architektur
Im Gegensatz zu generischen kognitiven Architekturen verwenden viele Agentensysteme die Bereichsspezifische kognitive Architekturen . Dies spiegelt sich in der Regel in einem domänenspezifischen Kategorisierungs- oder Planungsschritt sowie in einem domänenspezifischen Validierungsschritt wider. Die in generischen kognitiven Architekturen vorgestellten Planungs- und Reflexionsideen können in domänenspezifischen kognitiven Architekturen übernommen und angewendet werden, müssen aber in der Regel domänenspezifisch angepasst und optimiert werden.
Eine Arbeit von AlphaCodium ist ein hervorragendes Beispiel für eine bereichsspezifische kognitive Architektur. Das Team von AlphaCodium hat dies mit Hilfe der so genannten "Strömungstechnik". (im Grunde eine andere Art, kognitive Architekturen zu beschreiben), die damals den neuesten Stand der Technik darstellten.
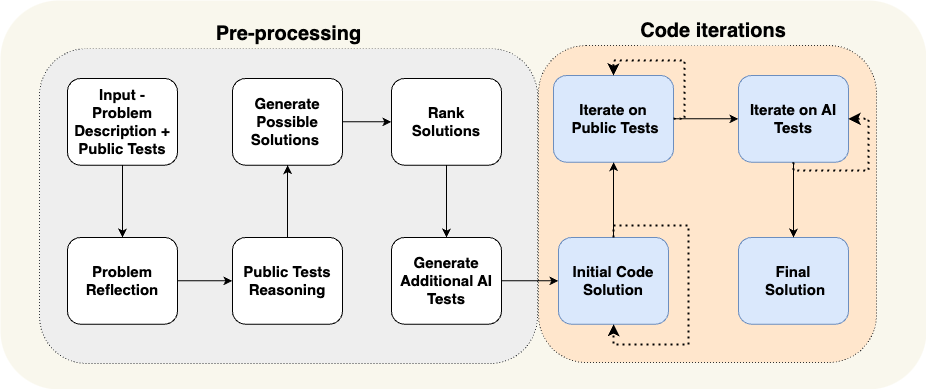
Wie in der obigen Abbildung dargestellt, sind die Prozesse des AlphaCodium-Agenten so konzipiert, dass sie für das zu lösende Programmierproblem äußerst relevant sind. Sie informieren den Agenten detailliert über die Aufgaben, die er schrittweise erledigen muss: erst einen Testfall vorschlagen, dann eine Lösung vorschlagen, dann weitere Testfälle iterieren und so weiter. Diese kognitive Architektur ist in hohem Maße domänenspezifisch, nicht generisch und lässt sich nur schwer direkt auf andere Domänen verallgemeinern.
Fallstudie: Die Vision von Reflection AI-Gründer Laskin für die Zukunft der Agenten
Im Interview von Sequoia Capital mit Misha Laskin, dem Gründer von Reflection AI, teilt Misha Laskin seine Vision für die Zukunft von Agent: durch die Kombination von Suchfunktion für RL (Reinforcement Learning) In Verbindung mit LLM konzentriert sich Reflection AI auf die Entwicklung von Agentenmodellen mit überlegener Leistung. Misha Laskin und Mitbegründer Ioannis Antonoglou (Leiter von AlphaGo, AlphaZero, Gemini RLHF) konzentrieren sich auf das Training von Agentenmodellen, die speziell für die Agentischer Arbeitsablauf Modellierung des Designs. Die wichtigsten Ideen aus den Interviews werden im Folgenden vorgestellt:
- Tiefe ist die wichtigste fehlende Zutat für einen KI-Agenten. Aktuelle Sprachmodelle zeichnen sich zwar durch eine große Bandbreite an Wissen aus, aber es fehlt ihnen an der Tiefe, die für die zuverlässige Erfüllung komplexer Aufgaben erforderlich ist. Misha Laskin argumentiert, dass die Lösung des "Tiefenproblems" entscheidend für die Entwicklung wirklich fähiger KI-Agenten ist. "Fähigkeit" bezieht sich in diesem Zusammenhang auf die Fähigkeit eines Agenten, komplexe Aufgaben in mehreren Schritten zu planen und auszuführen.
- Die Kombination von Lernen und Suchen ist der Schlüssel zu übermenschlichen Leistungen. Mit Blick auf den Erfolg von AlphaGo betonte Misha Laskin, dass die tiefgreifendste Idee in der KI in der effektiven Kombination von **Lernen** (basierend auf LLM) und **Suchen** (Finden des optimalen Pfades) besteht. Dieser Ansatz ist entscheidend für die Entwicklung von Agenten, die den Menschen bei komplexen Aufgaben übertreffen.
- Die Nachschulung und die Modellierung der Belohnungen stellen eine große Herausforderung dar. Im Gegensatz zu Spielen mit expliziten Belohnungsmechanismen fehlen bei realen Aufgaben meist explizite Belohnungssignale. Wie entwickelt man zuverlässige Belohnungsmodell Die größte Herausforderung besteht darin, einen zuverlässigen KI-Agenten zu schaffen.
- Universalagenten sind vielleicht näher, als wir denken. Misha Laskin prognostiziert, dass wir nur noch drei Jahre von der Erreichung der "digitale AGI (digitale allgemeine künstliche Intelligenz)". Dieser beschleunigte Zeitplan unterstreicht die Dringlichkeit einer raschen Entwicklung von Agentenfähigkeiten bei gleichzeitiger Berücksichtigung von Sicherheits- und Zuverlässigkeitsaspekten. Dieser beschleunigte Zeitplan unterstreicht die Dringlichkeit der raschen Entwicklung von Agentenfähigkeiten bei gleichzeitiger Berücksichtigung von Sicherheits- und Zuverlässigkeitsaspekten.
- Der Weg zu Universalagenten erfordert eine Methode. Reflection AI konzentriert sich auf die Erweiterung der funktionalen Grenzen des Agenten, beginnend mit spezifischen Umgebungen wie Browsern, Code-Editoren und Computerbetriebssystemen. Ihr ultimatives Ziel ist die Entwicklung Universal-Agenten Dadurch sind sie in der Lage, Aufgaben in einer Vielzahl unterschiedlicher Bereiche zu übernehmen und sind nicht auf bestimmte Aufgaben beschränkt.
UI/UX Interaktion Innovation
Die Interaktion zwischen Mensch und Computer (Human-Computer Interaction, HCI) wird in den kommenden Jahren zu einer der wichtigsten Forschungsrichtungen in der KI werden. Agentensysteme unterscheiden sich stark von herkömmlichen Computersystemen, und neue Merkmale wie Latenzzeiten, Unzuverlässigkeit und natürlichsprachliche Schnittstellen stellen neue Herausforderungen dar. Daher ist eine neue Art von UI/UX (Benutzeroberfläche/Benutzererfahrung) Paradigmen werden sich herausbilden. Obwohl sich Agentensysteme noch im Anfangsstadium der Entwicklung befinden, gibt es eine Reihe von UX-Paradigmen, die sich abzeichnen. Jedes dieser Paradigmen wird im Folgenden näher erläutert.
1. konversationelle Interaktion (Chat UI)
Konversationelle Interaktion (Chat UI) In der Regel gibt es zwei Haupttypen: Streaming-Chat im Gesang antworten Nicht-Streaming-Chat .
Streaming-Chat ist das heute am weitesten verbreitete UX-Paradigma. Es handelt sich im Wesentlichen um einen Chatbot, der den Denkprozess und das Verhalten des Agenten aufgreift und in ein menschenähnliches Dialogformat überführt. Stream Stil an den Benutzer zurück. ChatGPT Er ist ein typischer Vertreter des Streaming-Chat. Dieser Interaktionsmodus scheint einfach zu sein, ist aber aus folgenden Gründen sehr effektiv: Erstens können die Nutzer natürliche Sprache verwenden, um einen direkten Dialog mit den LLMs zu führen, und es gibt fast keine Kommunikationsbarrieren zwischen Nutzern und LLMs; zweitens dauert es in der Regel einige Zeit, bis die LLMs ihre Aufgaben erledigt haben, und die Streaming-Verarbeitung ermöglicht es den Haushalten, den Ausführungsfortschritt von Hintergrundaufgaben in Echtzeit zu erfahren; drittens können die LLMs manchmal Fehler machen, und die Chat-Schnittstelle bietet eine Drittens können LLMs manchmal Fehler machen, und die Chat-Schnittstelle bietet den Nutzern eine freundliche Möglichkeit, LLMs auf natürliche Weise zu korrigieren und anzuleiten, die sich daran gewöhnt haben, während des Chat-Prozesses Folgegespräche und Wiederholungen zu führen, um schrittweise Anforderungen zu klären und Probleme zu lösen.
Allerdings.Streaming-Chat Es gibt auch einige Einschränkungen. Erstens ist der Streaming-Chat noch ein relativ neues Benutzererlebnis und wird noch nicht allgemein von unseren gängigen Chat-Plattformen (z. B. iMessage, Facebook Messenger, Slack usw.) übernommen; zweitens ist das Benutzererlebnis des Streaming-Chats für Aufgaben mit langer Laufzeit etwas unzureichend, und die Benutzer müssen unter Umständen lange in der Chat-Oberfläche verweilen und darauf warten, dass der Agent die Aufgabe abschließt; drittens muss der Streaming-Chat in der Regel von menschlichen Benutzern ausgelöst werden, was bedeutet, dass während der Ausführung von Aufgaben immer noch ein großes Maß an menschlicher Beteiligung (Human-in-the-tray) erforderlich ist. Drittens werden Streaming-Chats in der Regel von menschlichen Benutzern ausgelöst, was bedeutet, dass bei der Ausführung von Aufgaben durch den Agenten immer noch ein hohes Maß an menschlicher Beteiligung (Human-in-the-loop) erforderlich ist.
Nicht-Streaming-Chat Der Hauptunterschied zum Streaming-Chat besteht darin, dass die Antworten des Agenten in Batches zurückgegeben werden. Der LLM arbeitet geräuschlos im Hintergrund, so dass der Benutzer nicht ungeduldig auf eine unmittelbare Antwort des Agenten warten muss. Das bedeutet, dass sich ein Chat ohne Streaming einfacher in bestehende Arbeitsabläufe integrieren lässt. Die Benutzer sind es gewohnt, ihren Freunden eine SMS zu schicken, warum also nicht auch mit KI "simsen"? Non-Streaming-Chat wird die Interaktion mit komplexeren Agentensystemen natürlicher und einfacher machen. Da komplexe Agentensysteme oft lange brauchen, um zu laufen, können Benutzer frustriert sein, wenn sie eine sofortige Antwort vom Agenten erwarten. Durch den nicht-gestreamten Chat wird die Erwartung einer sofortigen Antwort teilweise aufgehoben, so dass komplexere Aufgaben leichter zu bewältigen sind.
Die folgende Tabelle gibt einen Überblick Streaming-Chat im Gesang antworten Nicht-Streaming-Chat Die Vor- und Nachteile der

2. die Hintergrundumgebung (Ambient UX)
Wie bereits erwähnt, können Nutzer aktiv Nachrichten an die KI senden. Chat UI (Chat-Schnittstelle) Aber wie können wir mit einem Agenten interagieren, wenn er einfach nur still im Hintergrund läuft? Aber wie interagieren wir mit einem Agenten, wenn er einfach nur still im Hintergrund läuft?
Um das Potenzial des Agentensystems voll ausschöpfen zu können, müssen wir das HCI-Paradigma so verändern, dass KI in der Backend-Umgebung (Ambient UX) die im Hintergrund laufen. Wenn Aufgaben im Hintergrund verarbeitet werden, können die Benutzer in der Regel längere Zeiten für die Aufgabenerledigung tolerieren (weil sie weniger Bedarf an der Latenzzeit Erwartungen). Dadurch hat der Agent mehr Zeit, um mehr Aufgaben auszuführen, und kann im Allgemeinen mehr Überlegungen sorgfältiger und effizienter anstellen als bei der Chat-UX.
Darüber hinaus werden in Backend-Umgebung (Ambient UX) Der Einsatz eines Agenten in einer Chat-Schnittstelle trägt dazu bei, die Fähigkeiten der menschlichen Benutzer selbst zu erweitern. Chat-Schnittstellen beschränken die Benutzer in der Regel auf eine Aufgabe zur gleichen Zeit. Wenn der Agent jedoch in einer Hintergrundumgebung läuft, ist es möglich, mehrere Agenten zu unterstützen, die gleichzeitig an mehreren Aufgaben arbeiten.
Der Schlüssel zu einer zuverlässigen Arbeit eines Agenten im Hintergrund liegt darin, das Vertrauen der Benutzer in den Agenten aufzubauen. Wie kann man dieses Vertrauen aufbauen? Eine einfache Idee ist, dem Benutzer genau zu zeigen, was der Agent tut. Wenn alle Schritte, die der Agent ausführt, in Echtzeit angezeigt werden, kann der Benutzer beobachten, was passiert. Auch wenn diese Schritte nicht so unmittelbar sind wie das Streaming einer Antwort, sollte der Benutzer sie jederzeit anklicken können, um den Fortschritt der Ausführung des Agenten zu sehen. Außerdem ist es wichtig, dass der Benutzer nicht nur sehen kann, was der Agent tut, sondern dass er auch die Möglichkeit hat, Fehler des Agenten zu korrigieren. Wenn der Benutzer beispielsweise feststellt, dass der Agent in Schritt 4 (von 10) eine falsche Entscheidung getroffen hat, hat er die Möglichkeit, zu Schritt 4 zurückzugehen und das Verhalten des Agenten in irgendeiner Weise zu korrigieren.
Dieser Ansatz kombiniert das Benutzer-Agent-Interaktionsmodell Vom "In-the-Loop" zum "On-the-Loop". . "On-the-loop". Das Modell setzt voraus, dass das System in der Lage ist, dem Benutzer alle vom Agenten ausgeführten Zwischenschritte zu zeigen, so dass der Benutzer den Arbeitsablauf während der Ausführung einer Aufgabe unterbrechen, ein Feedback geben und dann dem Agenten erlauben kann, die nachfolgenden Aufgaben auf der Grundlage des Feedbacks des Benutzers auszuführen.
AI-Software-Ingenieur Devin ist repräsentativ für die Implementierung von UX-ähnlichen Anwendungen. Die Laufzeit eines Devin ist in der Regel lang, aber der Benutzer kann alle Schritte, die der Agent ausführt, deutlich sehen, zu einem bestimmten Zeitpunkt zum Entwicklungszustand zurückkehren und von diesem Zustand aus Korrekturanweisungen erteilen. Nur weil ein Agent im Hintergrund läuft, bedeutet das nicht, dass er völlig autonom Aufgaben ausführen muss. Es kann vorkommen, dass ein Agent nicht weiß, was er als Nächstes tun soll, oder dass er nicht weiß, wie er die Frage eines Benutzers beantworten soll. In diesem Fall muss der Agent proaktiv die Aufmerksamkeit des menschlichen Benutzers auf sich ziehen und ihn um Hilfe bitten.
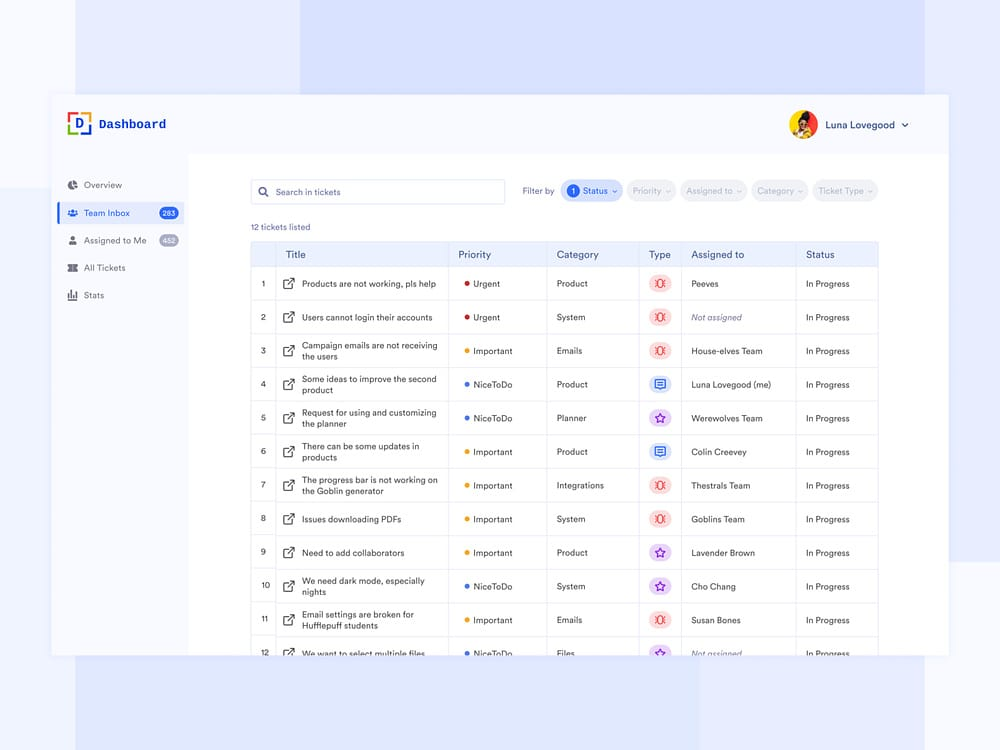
E-Mail-Assistentin Ja Ambient UX (Hintergrundumgebung) Ein weiterer Anwendungsfall für LangChain. Der Gründer von LangChain, Harrison Chase, baut einen E-Mail-Assistenten, der zwar einfache E-Mails automatisch beantworten kann, aber in manchen Fällen muss Harrison Aufgaben, die sich nicht automatisieren lassen, manuell erledigen, z. B.: Überprüfung komplexer LangChain-Fehlerberichte, die Überprüfung komplexer LangChain-Fehlerberichte, die Entscheidung, ob er an einer Besprechung teilnehmen soll, usw. In diesen Fällen benötigt der E-Mail-Assistent einen effizienten Weg, um Harrison mitzuteilen, dass er menschliche Hilfe benötigt, um die Aufgabe weiter zu erledigen. Anstatt Harrison direkt um Antworten zu bitten, bittet der Agent Harrison um Input zu bestimmten Aufgaben, und dann kann der Agent dieses menschliche Feedback nutzen, um eine qualitativ hochwertige E-Mail zu schreiben oder eine Einladung zu einer Besprechung im Kalender zu planen.
Derzeit hat Harrison diesen E-Mail-Assistenten in seinem Slack-Arbeitsbereich eingerichtet. Wenn der Agent menschliche Unterstützung benötigt, sendet er eine Frage an Harrisons Slack, die Harrison im Dashboard beantworten kann - eine Interaktion, die sich nahtlos in Harrisons täglichen Arbeitsablauf einfügt. Diese Art der Interaktion fügt sich nahtlos in den täglichen Arbeitsablauf von Harrison ein. Diese Art von UX ähnelt der UX, die Kunden zur Unterstützung des Dashboards verwenden. Die Dashboard-Oberfläche zeigt deutlich alle Aufgaben, für die der Assistent menschliche Hilfe benötigt, die Priorität der Anfrage und andere relevante Daten.
3 Tabellenkalkulation UX

Tabellenkalkulation UX Es handelt sich um eine sehr intuitive und benutzerfreundliche Interaktion, die sich besonders für Stapelverarbeitungsaufträge eignet. In der Tabellenkalkulationsschnittstelle kann jede Tabelle oder sogar jede Spalte als separater Agent für die Recherche und Verarbeitung bestimmter Aufgaben behandelt werden. Diese Stapelverarbeitungsfunktion ermöglicht es den Benutzern, ihre Interaktion mit mehreren Agenten einfach zu erweitern.
Tabellenkalkulation UX Es gibt auch noch andere Vorteile. Das Tabellenkalkulationsformat ist eine UX, mit der die meisten Benutzer vertraut sind, so dass es sich leicht in bestehende Arbeitsabläufe integrieren lässt. Diese Art von UX ist ideal für Data Enrichment-Szenarien, bei denen jede Spalte der Kalkulationstabelle ein anderes Datenattribut darstellen kann, das erweitert werden muss.
Exa AI, Clay AI, Manaflow und andere haben die Tabellenkalkulation UX Es folgt ein Beispiel für Manaflow. Nachfolgend ein Beispiel für Manaflow Tabellenkalkulation UX Wie sie sich auf die Interaktionsabläufe von Agenten auswirkt.
Fallstudie: Wie Manaflow Spreadsheets für Agenteninteraktionen nutzt
Manaflow wurde von Minion AI inspiriert, dem Unternehmen, für das sein Gründer Lawrence gearbeitet hat. Das Kernprodukt von Minion AI ist der Web Agent. Der Web Agent kann die lokalen Google Chrome Browser und ermöglicht es den Nutzern, über den Webagenten mit verschiedenen Webanwendungen zu interagieren, z. B. Flüge online zu buchen, E-Mails zu versenden, Autowäschen zu buchen usw. Inspiriert von Minion AI hat sich Manaflow dafür entschieden, den Agenten direkt mit Tools wie Tabellenkalkulationen arbeiten zu lassen. Das Manaflow-Team ist der Meinung, dass Agenten nicht gut darin sind, direkt mit menschlichen Benutzeroberflächen zu arbeiten, und dass das, was Agenten wirklich gut können, sind Codierung Manaflow ist weltweit das erste seiner Art. Mit Manaflow kann der Agent Python-Skripte, Datenbankschnittstellen und API-Schnittstellen direkt von der Benutzeroberfläche aus aufrufen und dann Operationen direkt in der Datenbank durchführen, wie z. B. das Lesen von Daten, die Planung, den Versand von E-Mails und vieles mehr.
Der Arbeitsablauf von Manaflow sieht folgendermaßen aus: Die wichtigste interaktive Schnittstelle von Manaflow ist eine Tabellenkalkulation (Manasheet). Jede Spalte im Manasheet stellt einen Schritt im Arbeitsablauf dar, und jede Zeile entspricht einem KI-Agenten, der eine bestimmte Aufgabe ausführt. Jeder Manasheet-Arbeitsablauf ist in natürlicher Sprache programmierbar (so dass auch nicht-technische Benutzer Aufgaben und Schritte in natürlicher Sprache beschreiben können). Jedes Manasheet hat einen internen Abhängigkeitsgraphen, der die Reihenfolge der Ausführung für jede Spalte festlegt. Diese Ausführungsreihenfolge wird den Agenten in jeder Zeile zugewiesen, die Aufgaben parallel ausführen und Prozesse wie Datenumwandlung, API-Aufrufe, Abruf von Inhalten und Nachrichtenübermittlung bearbeiten:
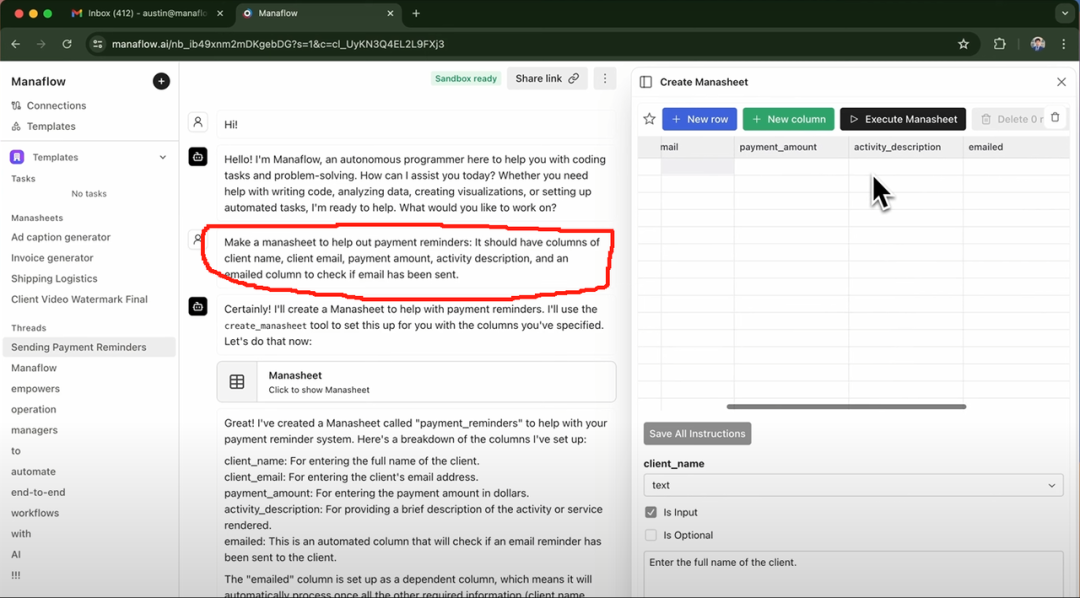
Manasheets können auf verschiedene Weise erstellt werden. Die häufigste Methode ist die Eingabe eines Befehls in natürlicher Sprache, wie der im roten Kasten oben. Wenn Sie beispielsweise Massen-E-Mails mit Preisinformationen an Ihre Kunden senden möchten, können Sie über die Chat-Schnittstelle eine Eingabeaufforderung eingeben, woraufhin der Agent automatisch ein Manasheet generiert. Das Manasheet zeigt Ihnen unter anderem den Namen des Kunden, seine E-Mail-Adresse, seine Branche und ob die E-Mail versendet wurde oder nicht. Benutzer können einfach auf die Schaltfläche "Manasheet ausführen" klicken, um den Massenversand von E-Mails durchzuführen.
4. generative UI
"Generative UI". Es gibt im Wesentlichen zwei verschiedene Umsetzungen.
Die erste Möglichkeit besteht darin, dass das Modell selbstständig die erforderlichen UI-Komponenten . Dies ist vergleichbar mit Websim und andere Produkte. Im Hintergrund schreibt der Agent in erster Linie den Roh-HTML-Code und hat damit die volle Kontrolle über die Darstellung der Benutzeroberfläche. Der Nachteil dieses Ansatzes ist jedoch, dass die Qualität der resultierenden Web-App sehr unsicher ist und die Benutzererfahrung variieren kann.
Ein anderer, eingeschränkterer Ansatz besteht darin, eine Reihe häufig verwendeter UI-Komponenten vorzudefinieren und sie dann durch die Werkzeugaufrufe um UI-Komponenten dynamisch zu rendern. Wenn LLM beispielsweise die Wetter-API aufruft, wird das Rendering der UI-Komponente "Wetterkarte" ausgelöst. Da die gerenderten UI-Komponenten vordefiniert sind (und der Benutzer mehr Optionen hat), wird die resultierende UI ausgefeilter sein, aber ihre Flexibilität wird etwas eingeschränkt sein.
Fallstudie: Personal AI product dot
Persönliche AI-Produkte Punkt Ja Generative UI Das beste Beispiel dafür. dot wurde als das "beste persönliche KI-Produkt" im Jahr 2024 gefeiert.
Punkt Ja Neu Computer Das Starprodukt des Unternehmens. Das Ziel von dot ist es, ein langfristiger digitaler Begleiter für die Nutzer zu sein, nicht nur ein effizientes Aufgabenmanagement-Tool. Wie Jason Yuan, Mitbegründer von New Computer, sagt, ist das Anwendungsszenario von dot "wenn man nicht weiß, wohin man gehen, was man tun oder was man sagen soll, wendet man sich an dot". Hier sind ein paar typische Anwendungsfälle für dot:
- Jason Yuan, der Gründer von New Computer, bittet dot oft um Empfehlungen für Nachtbars, in der Hoffnung, sich zu betrinken". Nach Monaten der nächtlichen Bargespräche stellte Jason Yuan eines Tages dot eine ähnliche Frage, und dot begann Jason zu sagen, dass er "so nicht weitermachen könne".
- Der Fast Company-Reporter Mark Wilson verbrachte ebenfalls einige Monate mit dot. Einmal teilte er dot ein handgeschriebenes "O" mit, das er in einem Kalligraphiekurs geschrieben hatte. Überraschenderweise zeigte dot sofort ein Foto von Mark Wilsons handgeschriebenem "O" von ein paar Wochen zuvor und lobte ihn für seine "große Verbesserung" in Kalligraphie.
- Da die Nutzer dot immer länger nutzen, ist dot in der Lage, ein tieferes Verständnis für ihre Interessen und Vorlieben zu gewinnen. Wenn dot zum Beispiel erfährt, dass ein Nutzer gerne Cafés besucht, wird es dem Nutzer aktiv nahegelegene Qualitätscafés empfehlen, die Gründe für die Empfehlung ausführlich erläutern und den Nutzer fragen, ob er/sie am Ende navigieren möchte.
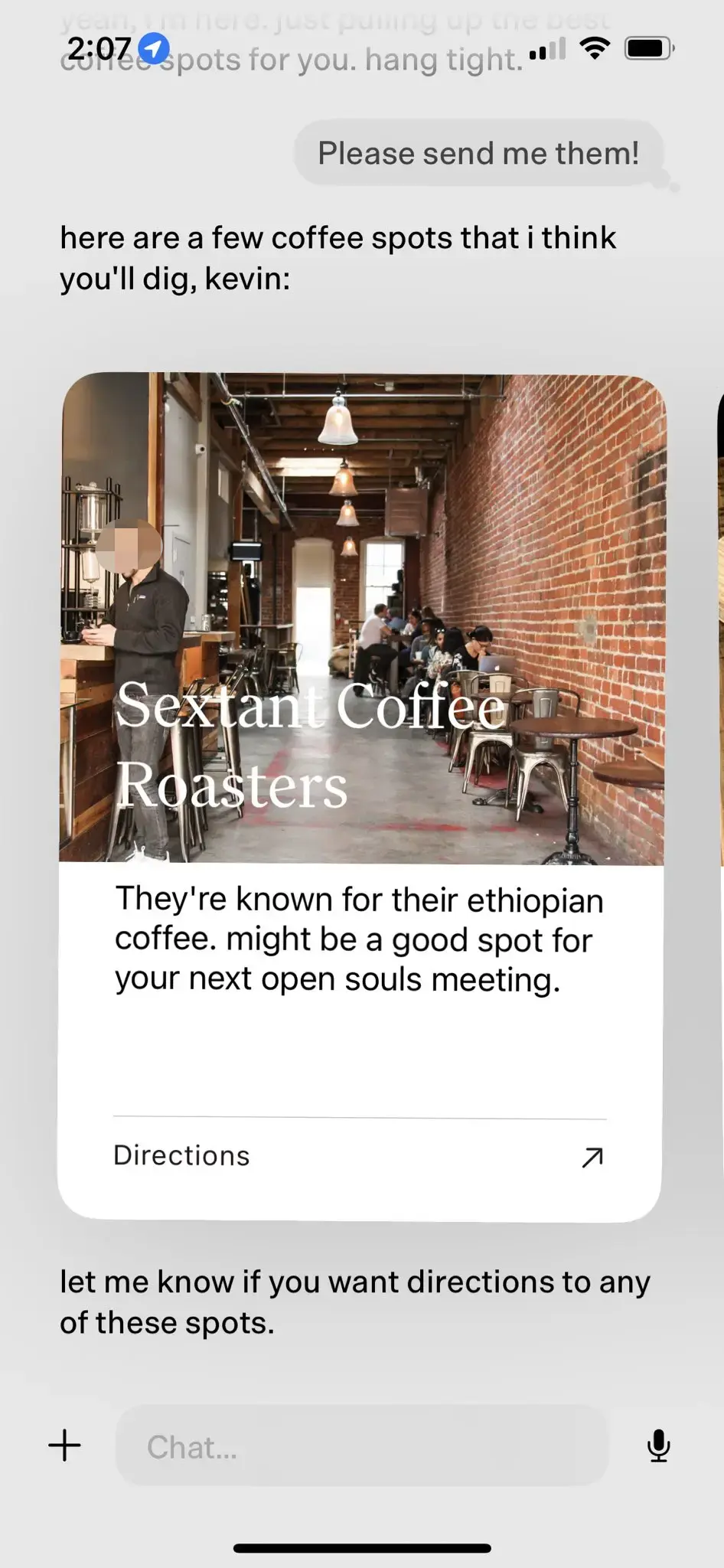
Im obigen Fall der Cafe-Empfehlung realisiert dot den natürlichen Effekt der Mensch-Computer-Interaktion auf der Basis von LLM-native durch vordefinierte UI-Komponenten.
5. kollaborative UX
Welche Art von Mensch-Computer-Interaktionsmodell entsteht, wenn ein Agent und ein menschlicher Nutzer zusammenarbeiten? Ähnlich wie bei Google Docs können mehrere Nutzer in Echtzeit zusammenarbeiten, um dasselbe Dokument zu schreiben oder zu bearbeiten. Was ist, wenn einer der Mitwirkenden ein Agent ist?
Geoffrey Litt mit Ink & Switch Patchwork-Projekt Das ist Mensch-Maschine. Kollaborative UX Das Patchwork-Projekt ist ein großartiges Beispiel dafür, worum es bei OpenAI geht. (Anmerkung des Übersetzers: OpenAIs kürzlich veröffentlichtes Canvas-Produktupdate könnte durch das Patchwork-Projekt inspiriert worden sein).
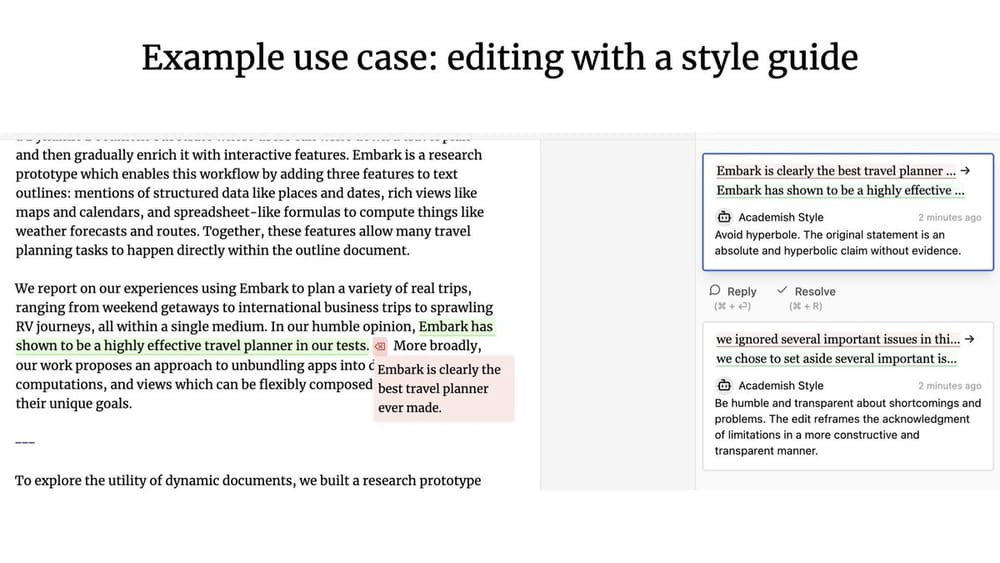
Kollaborative UX Im Gegensatz zu den zuvor diskutierten Ambient UX (Hintergrundumgebung) Worin besteht der Unterschied? Nuno, der Gründungsingenieur von LangChain, betont, dass der Hauptunterschied zwischen den beiden Systemen in der Verfügbarkeit der Gleichzeitigkeit ::
- existieren Kollaborative UX In diesem Fall müssen der menschliche Benutzer und der LLM in der Regel gleichzeitig arbeiten und das Arbeitsprodukt des jeweils anderen als Input verwenden.
- existieren Ambient UX (Hintergrundumgebung) In diesem Fall läuft der LLM kontinuierlich im Hintergrund, während der Benutzer sich auf andere Aufgaben konzentrieren kann und den Status des Agenten nicht in Echtzeit im Auge behalten muss.
Speicher
Speicher Es ist von entscheidender Bedeutung, die Benutzerfreundlichkeit von Agent zu verbessern. Stellen Sie sich vor, Ihr Kollege erinnert sich nie an das, was Sie ihm gesagt haben, und bittet Sie immer wieder, das Gleiche zu wiederholen - das wäre eine schreckliche Erfahrung für die Zusammenarbeit. Es ist üblich zu erwarten, dass LLM-Systeme von Natur aus in der Lage sind, sich zu erinnern, wahrscheinlich weil LLMs in gewisser Weise der menschlichen Kognition sehr ähnlich sind. LLMs haben jedoch keine inhärenten Erinnerungsfähigkeiten.
Agent's Speicher Das Design muss auf die spezifischen Bedürfnisse des Produkts selbst zugeschnitten sein. Unterschiedliche UX-Paradigmen bieten auch unterschiedliche Methoden zum Sammeln von Informationen und zur Aktualisierung von Feedback. Anhand der Gedächtnismechanismen von Agentenprodukten können wir verschiedene Arten von High-Level-Gedächtnismustern beobachten, die bis zu einem gewissen Grad die menschlichen Gedächtnisarten nachahmen.
In dem Papier "CoALA: Cognitive Architectures for Language Agents" werden die Arten des menschlichen Gedächtnisses den Gedächtnismechanismen von Agenten zugeordnet, die in der folgenden Abbildung dargestellt sind:
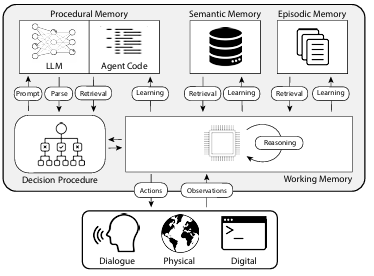
1. prozedurales Gedächtnis
Prozedurales Gedächtnis Es ist eine Art, über Folgendes zu sprechen Wie man Aufgaben ausführt des Langzeitgedächtnisses, ähnlich wie der Kernsatz von Anweisungen im menschlichen Gehirn.
- Menschliches prozedurales Gedächtnis. Denken Sie zum Beispiel daran, wie man Fahrrad fährt.
- Das prozedurale Gedächtnis des Agenten. Das CoALA-Papier beschreibt das prozedurale Gedächtnis als eine Kombination aus LLM-Gewichten und Agentencode, die grundlegend bestimmt, wie der Agent arbeitet.
In der Praxis hat das Langchain-Team keine Agentensysteme gefunden, die ihre LLMs automatisch aktualisieren oder ihren Code neu schreiben. Einige Agentensysteme haben jedoch die Fähigkeit, ihre LLMs dynamisch zu aktualisieren. System-Eingabeaufforderung Der Fall für.
2. semantisches Gedächtnis
Semantisches Gedächtnis Es handelt sich um eine langfristige Wissensreserve zur Speicherung von Faktenwissen.
- Semantisches Gedächtnis beim Menschen. Besteht aus verschiedenen Informationen, z. B. Fakten, Konzepten und Beziehungen zwischen ihnen, die in der Schule gelernt wurden.
- Semantisches Gedächtnis für Agenten. Das CoALA-Papier beschreibt das semantische Gedächtnis als einen Speicher für Faktenwissen.
In der Praxis wird das semantische Gedächtnis eines Agenten in der Regel durch die Verwendung von LLM zur Extraktion von Informationen aus dem Dialog- oder Interaktionsprozess des Agenten erreicht. Die genaue Art und Weise, wie die Informationen gespeichert werden, hängt in der Regel von der jeweiligen Anwendung ab. In nachfolgenden Dialogen ruft das System dann diese gespeicherten Informationen ab und fügt sie in die System-Eingabeaufforderung um die Reaktion des Agenten zu beeinflussen.
3. episodisches Gedächtnis
Episodisches Gedächtnis Wird verwendet, um sich an bestimmte vergangene Ereignisse zu erinnern.
- Situationsbezogenes Gedächtnis beim Menschen. Das Situationsgedächtnis wird verwendet, wenn sich eine Person an bestimmte Ereignisse (oder "Episoden") aus der Vergangenheit erinnert.
- Situationsgedächtnis für Agenten. Im CoALA-Papier wird das Situationsgedächtnis als eine Sequenz definiert, in der die vergangenen Handlungen eines Agenten gespeichert sind.
Das Szenario-Gedächtnis wird in erster Linie verwendet, um sicherzustellen, dass der Agent die erwarteten Leistungen erbringt. In der Praxis wird das Szenario-Gedächtnis normalerweise über die Few-Shots Aufforderung Methode zu erreichen. Wird das System in der Anfangsphase durch die Few-Shots Aufforderung Wenn der Agent die Anweisung erhält, den Vorgang korrekt auszuführen, kann er diese Methode direkt wiederverwenden, wenn er in Zukunft vor ähnlichen Problemen steht. Wenn es hingegen keine wirksame Methode gibt, die den Agenten anleitet, korrekt zu arbeiten, oder wenn der Agent ständig neue Arbeitsmethoden ausprobieren muss, dann ist die Semantisches Gedächtnis noch mehr an Bedeutung gewinnen.Episodisches Gedächtnis Die Rolle in diesen Szenarien ist relativ begrenzt.
Zusätzlich zu den Arten von Speichern, die in Agent aktualisiert werden müssen, müssen die Entwickler Folgendes berücksichtigen So aktualisieren Sie den Speicher des Agenten . Derzeit gibt es zwei Hauptmethoden zur Aktualisierung des Agentenspeichers:
Die erste Methode ist "auf dem heißen Weg (Aktualisierung des heißen Weges)" . In diesem Modell merkt sich das Agentensystem die relevanten Sachinformationen in Echtzeit, bevor es eine Antwort erzeugt (normalerweise durch einen Tool-Aufruf). ChatGPT verwendet derzeit diesen Ansatz, um seinen Speicher zu aktualisieren.
Die zweite Methode ist "im Hintergrund (Hintergrundaktualisierung)" . In diesem Modus läuft ein Hintergrundprozess am Ende der Sitzung asynchron und aktualisiert den Speicher des Agenten im Hintergrund.
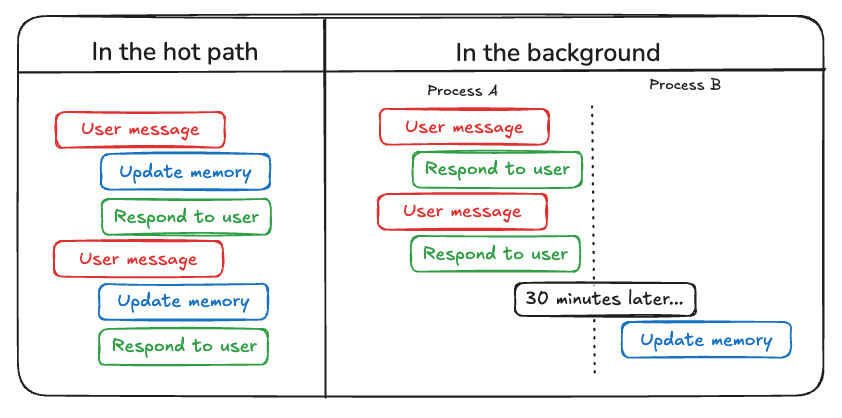
"auf dem heißen Weg (Aktualisierung des heißen Weges)" Der Nachteil dieser Methode besteht darin, dass vor der Rückgabe einer Antwort eine gewisse Anzahl von Latenzzeit . Darüber hinaus muss sie folgende Aspekte einbeziehen Speicherlogik zusammen mit Sachbearbeiterlogik Enge Integration.
"im Hintergrund (Hintergrundaktualisierung)" Methode vermeidet das oben genannte Problem effektiv, erhöht nicht die Antwortzeit und die Speicherlogik relativ unabhängig bleiben können. Allerdings "im Hintergrund (Hintergrundaktualisierung)" Es hat auch seine eigenen Mängel: Der Speicher wird nicht sofort aktualisiert, und es ist eine zusätzliche Logik erforderlich, um zu bestimmen, wann der Aktualisierungsprozess im Hintergrund beginnen soll.
Ein weiterer Ansatz für die Aktualisierung von Speichern ist das Feedback der Nutzer, ähnlich wie bei der Episodisches Gedächtnis besonders relevant. Wenn ein Nutzer zum Beispiel eine hohe Bewertung für eine Agenteninteraktion abgibt (Positives Feedback), kann der Agent diese Rückmeldung speichern, um sie in ähnlichen Szenarien in der Zukunft abrufen zu können.
Auf der Grundlage der obigen Zusammenstellung ist AI Share der Ansicht, dass die gleichzeitige Entwicklung und der kontinuierliche Fortschritt der drei Schlüsselelemente, nämlich der Planungsfähigkeit, der Interaktionsinnovation und des Speichermechanismus, im Jahr 2025 hoffentlich zu mehr praktischen KI-Agentenanwendungen führen und uns in eine neue Ära der Mensch-Maschine-Kollaboration einführen wird.
© urheberrechtliche Erklärung
Artikel Copyright AI-Austauschkreis Alle, bitte nicht ohne Erlaubnis vervielfältigen.
Ähnliche Artikel


Keine Kommentare...