

综合介绍
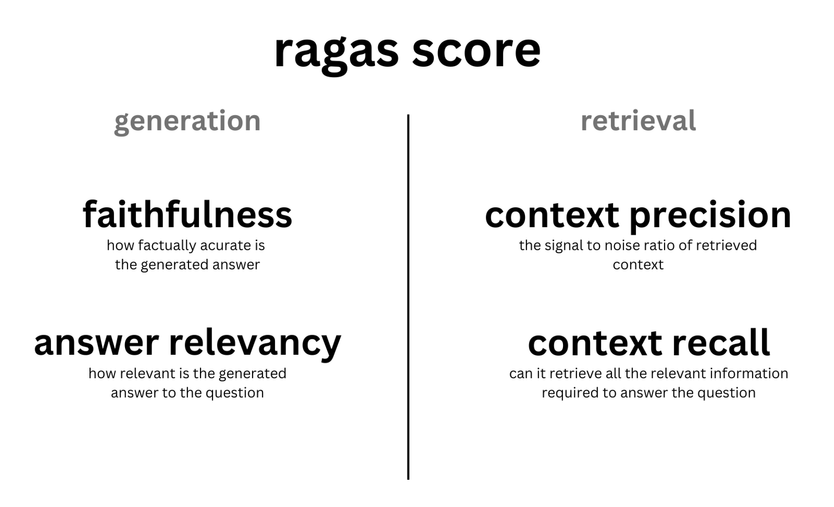
zChunk是由ZeroEntropy开发的一种新型分块策略,旨在为通用语义分块提供解决方案。该策略基于Llama-70B模型,通过提示生成分块,优化了文档的分块过程,确保在信息检索时保持高信噪比。zChunk特别适用于需要高精度检索的RAG(检索增强生成)应用,解决了传统分块方法在处理复杂文档时的局限性。通过zChunk,用户可以更有效地将文档分割成有意义的块,从而提高信息检索的准确性和效率。
Your job is to act as a chunker.
You should insert the "段" throughout the input.
Your goal is to separate the content into semantically relevant groupings.
方法和 LLM OCR 的局限性:光鲜外表下的文档解析难题 提到的PROMPT有一些共性。

功能列表
- 基于Llama-70B的分块算法:利用Llama-70B模型生成提示,进行语义分块。
- 高信噪比分块:优化分块策略,确保检索到的信息具有高信噪比。
- 多种分块策略:支持固定大小分块、基于嵌入相似度的分块等多种策略。
- 超参数调优:提供超参数调优管道,用户可以根据具体需求调整分块大小和重叠参数。
- 开源代码:提供完整的开源代码,用户可以自由使用和修改。
使用帮助
安装流程
- 克隆仓库:
git clone https://github.com/zeroentropy-ai/zchunk.git
cd zchunk
- 安装依赖:
pip install -r requirements.txt
使用方法
- 准备输入文件:将需要分块的文档保存为文本文件,例如
example_input.txt。 - 运行分块脚本:
python test.py --input example_input.txt --output example_output.txt
- 查看输出文件:分块结果将保存在
example_output.txt中。
详细功能操作流程
- 选择分块策略:
- NaiveChunk:固定大小分块,适用于简单文档。
- SemanticChunk:基于嵌入相似度的分块,适用于需要保持语义完整性的文档。
- zChunk Algorithm:基于Llama-70B模型的提示生成分块,适用于复杂文档。
- 调整超参数:
- 分块大小:可以通过调整参数
chunk_size来设置每个分块的大小。 - 重叠比例:通过参数
overlap_ratio设置分块之间的重叠比例,确保信息的连续性。
- 分块大小:可以通过调整参数
- 运行超参数调优:
python hyperparameter_tuning.py --input example_input.txt --output tuned_output.txt
该脚本将根据输入文档自动调整分块大小和重叠比例,生成最优分块结果。
- 评估分块效果:
- 使用提供的评估脚本对分块结果进行评估,确保分块策略的有效性。
python evaluate.py --input example_input.txt --output example_output.txt
示例
假设我们有一段美国宪法的文本,需要进行分块:
原始文本:
Section. 1.
All legislative Powers herein granted shall be vested in a Congress of the United States, which shall consist of a Senate and House of Representatives.
Section. 2.
The House of Representatives shall be composed of Members chosen every second Year by the People of the several States, and the Electors in each State shall have the Qualifications requisite for Electors of the most numerous Branch of the State Legislature.
No Person shall be a Representative who shall not have attained to the Age of twenty five Years, and been seven Years a Citizen of the United States, and who shall not, when elected, be an Inhabitant of that State in which he shall be chosen.
使用zChunk算法进行分块:
- 选择提示词:选择一个特殊的、不在语料库中的标记(例如“段”)。
- 插入提示词:让Llama在用户消息中插入该标记。
SYSTEM_PROMPT (简化版):
你的任务是作为一个分块器。
你应该在输入中插入“段”标记。
你的目标是将内容分成语义相关的组。
- 生成分块:
Section. 1.
All legislative Powers herein granted shall be vested in a Congress of the United States, which shall consist of a Senate and House of Representatives.段
Section. 2.
The House of Representatives shall be composed of Members chosen every second Year by the People of the several States, and the Electors in each State shall have the Qualifications requisite for Electors of the most numerous Branch of the State Legislature.段
No Person shall be a Representative who shall not have attained to the Age of twenty five Years, and been seven Years a Citizen of the United States, and who shall not, when elected, be an Inhabitant of that State in which he shall be chosen.段
通过这种方式,我们可以将文档分割成语义相关的块,每个块都可以独立检索,提高了信息检索的信噪比和准确性。
优化
- 通过本地推理Llama,可以高效地处理整个段落,并检查logprobs以确定分块位置。
- 处理450,000字符大约需要15分钟,但如果优化代码,可以显著减少时间。
基准测试
- zChunk在LegalBenchConsumerContractsQA数据集上的检索比和信号比得分高于NaiveChunk和语义分块方法。
通过zChunk算法,我们可以在不依赖正则表达式或手动创建规则的情况下,轻松分割任何类型的文档,提高RAG应用的效率和准确性。
© 版权声明
文章版权归 AI分享圈 所有,未经允许请勿转载。
相关文章

暂无评论...